
Abstract
The role of attention in visual memory remains controversial; while some evidence has suggested that memory for binding between features demands no more attention than does memory for the same features, other evidence has indicated cognitive costs or mnemonic benefits for explicitly attending to bindings. We attempted to reconcile these findings by examining how memory for binding, for features, and for features during binding is affected by a concurrent attention-demanding task. We demonstrated that performing a concurrent task impairs memory for as few as two visual objects, regardless of whether each object includes one or more features. We argue that this pattern of results reflects an essential role for domain-general attention in visual memory, regardless of the simplicity of the to-be-remembered stimuli. We then discuss the implications of these findings for theories of visual working memory.
Similar content being viewed by others

When a claim seems too good to be true, it meets with persistent skepticism. One such claim in cognitive psychology, that maintaining multifeature visual objects requires no more attention than memorizing the same number of unifeature visual objects (Luck & Vogel, 1997), has endured a barrage of hypothesis tests that have yielded mixed evidence. If binding requires attention, performing nonvisual but attention-demanding tasks while maintaining visual memoranda should impair memory for binding more than memory for features, yet much evidence has suggested otherwise. While the predicted interaction that would disconfirm Luck and Vogel’s claim has been reported (Brown & Brockmole, 2010), it has also eluded investigators, despite earnest attempts to find it (e.g., Allen, Baddeley, & Hitch, 2006; Allen, Hitch, Mate, & Baddeley, in press).
Evaluation of this claim is essential for advancing theories of working memory. Understanding binding influences assumptions about the proper unit of measurement in working memory (Cowan, 2001; Cowan & Rouder, 2009) and also underlies the debate on how attention and storage are related. This is most clearly evident when comparing two proposed versions of Baddeley’s multicomponent model (Baddeley, 2000; Baddeley, Allen, & Hitch, 2011). When addressing the limitations of his three-component model (Baddeley, 1986), Baddeley (2000) proposed a domain-general episodic buffer, capable of maintaining bindings between features initially encoded into the domain-specific buffers. Information was believed to move to the episodic buffer via the central executive. Consistent with the conclusions of Wheeler and Treisman (2002), who failed to replicate Luck and Vogel’s (1997) claim, Baddeley (2000) proposed that the domain-specific visual–spatial buffer maintained features separately, and that maintenance of binding occurred after applying attention. This assumption led to a series of hypothesis tests, in which Allen, Baddeley, and Hitch (2006) compared memory for bound objects and for features during an attention-demanding backward-counting task. Allen et al. (2006) found no evidence that the concurrent task impacted memory for multifeature objects any more than memory for unifeature objects, an outcome at odds with Baddeley’s (2000) proposal. The replicability of these findings (e.g., Allen, Hitch, & Baddeley, 2009; Allen et al., in press) and their consistency with complementary tests of the attentional costs of maintaining feature bindings (e.g., Delvenne & Bruyer, 2004; Delvenne, Cleeremans, & Laloyaux, 2010; Gajewski & Brockmole, 2006; Luck & Vogel, 1997; Vogel, Woodman, & Luck, 2001) led Baddeley et al. (2011) to propose that feature binding can be maintained within the domain-specific visual buffer without any additional involvement from the central executive.
However, this proposal neglects a robust and consistent finding: In each iteration of the basic experimental design of Allen et al. (2006), performing a nonvisual task concurrently with a visual recognition memory task reduced accuracy, sometimes considerably. This has been shown to occur with four (Allen et al., 2006) or three (Allen et al., in press; Brown & Brockmole, 2010) memoranda; during backward counting (Allen et al., 2006); with concurrent tasks carried out during encoding and maintenance periods (Allen et al., 2006) or during encoding, maintenance, and test (Allen et al., in press; Brown & Brockmole, 2010); and with encoding times varying from 250 to 1,000 ms. Furthermore, other researchers have also reported interference between nonvisual tasks and visual recognition, whether the interference occurred during encoding (Dell’Acqua & Jolicœur, 2000) or retention (Phillips & Christie, 1977; Stevanovski & Jolicœur, 2007). Any model of working memory should be able to explain why interference is so consistently observed between nonvisual attention-demanding tasks and visual short-term memory storage.
We therefore aimed to replicate and extend the work of Allen et al. (2006, in press) and of Brown and Brockmole (2010) by examining the effects of a nonvisual secondary task on memory for visual objects with one or more features. Our design included innovations that added to the previous work. First, we included study displays of only two objects. Possibly the elusiveness of the interaction between attention condition and visual materials has been related to visual memory limits: If participants are given more visual memoranda than they can comprehend, perhaps any concurrent task would provoke strong interference, obscuring this interaction. If this were in fact the case, the discrepancies between Brown and Brockmole’s and Allen et al.’s observations could have occurred because Brown and Brockmole happened to sample a group of participants with somewhat higher visual memory capacities. Second, we subjected our data to Bayesian analysis of variance (ANOVA; Rouder, Morey, Speckman, & Province, in press). Whereas a typical analysis would not allow for the interpretation of null effects, this Bayesian technique would allow us to evaluate the strength of the evidence against including an interaction in the ANOVA model.
Including trials with only two visual items would also yield theoretically important evidence regarding interference with visual memory. In verbal memory, small amounts of information can be retained without dual-task costs, but when verbal lists reach or exceed capacity, dual-task costs appear (Baddeley & Hitch, 1974; Morey & Cowan, 2004). If we observed dual-task costs even with subcapacity visual memory loads, this would cast further doubt on whether visual recognition tasks access a strictly visual, domain-specific resource (Cowan & Morey, 2007; Saults & Cowan, 2007; Vergauwe, Dewaele, Langerock, & Barrouillet, 2012).
Finally, we planned to compare correct rejections of feature lures across groups in order to compare feature memory during binding with feature memory when binding was not required. Despite the different contexts in which each group studied the color–shape stimuli, these feature lures could be rejected when participants remembered all of the features of a dimension. Similar analyses have previously suggested that maintaining binding can boost memory for the weaker of two features (C. C. Morey, 2009, 2011). Replicating this finding with two visual feature dimensions would give further insight into whether features are maintained differently when binding is required, as compared to when it is not.
Method
Participants
The participants were recruited from the psychology student population at the University of Groningen and indicated consent in writing. One participant with inadequate color vision was excluded from the analyses, along with 13 participants who responded below chance in the tone categorization task, leaving a sample with N = 102 (37 males, 65 females), 19–33 years old (M = 22.09, SD = 2.43).
Apparatus and stimuli
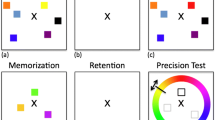
The participants worked in private booths, and the stimuli and responses were controlled using E-Prime (Schneider, Eschmann, & Zuccolotto, 2002). To-be-remembered stimuli were chosen from the shapes and colors depicted in Fig. 1. Stimuli were always presented in one of eight fixed locations, taken from the perimeter of an imaginary central circle.

Stimulus sets, procedure, and test types. In all groups, 50 % of the tests were targets and 50 % lures. The color set included red, orange, yellow, green, blue, purple, pink, and brown (the shades are taken from the standard colors in the MS Office palette). Stimulus presentation for the feature-only group is not depicted; these participants observed either unidimensional gray shapes or colored arcs at study
In the tone categorization task, participants judged three tones (220, 460, and 620 Hz) as low, medium, or high by pressing “1,” “2,” or “3,” respectively, on the number keypad.
Procedure
Each session began with a color blindness screening (adapted from Ishihara, 1966). An experimenter then explained the instructions to the participant and supervised a practice session, comprising eight trials of the visual memory task, ten tone classification trials, and eight dual-task trials. After the practice session, the participant completed the remainder of the trials independently.
Each trial began with a 1,000-ms fixation cross (+), followed by a 500-ms array of two, three, or four objects. Three within-subjects retention conditions were randomly mixed. In some trials, a probe appeared after only 900 ms, similar to retention intervals that have been used previously (e.g., Allen et al., 2006; Allen et al., in press; Brown & Brockmole, 2010). Sometimes a probe appeared after an unfilled period of 4,100 ms. In concurrent tone trials, two tones were presented during a 4,100-ms retention interval, and participants were encouraged to judge the tones as quickly as possible. The first tone always occurred 100 ms after the offset of the study array, and the second tone occurred 1,200 ms after the first tone. Responses were recorded for 1,800 ms after the onset of each tone. To encourage participants not to ignore the tones, a warning appeared between trials whenever a participant’s cumulative accuracy dropped below 50 %. The retention interval was followed by the presentation of a probe color, shape, or colored shape, shown at the center of the screen.
Participants in the binding-probe group (N = 24) always experienced bound color–shape probes, and thus needed to try to remember color–shape binding throughout the session. These participants indicated at test whether that particular colored shape had been part of the study array. Half of the probes were targets, in which the same colored shape was studied, and the remaining trials were equally divided between three types of lure probes: (1) recombined lures included a studied shape and a studied color that came from different studied objects, (2) shape lures included an unstudied shape presented in a studied color, and (3) color lures included a studied shape presented in an unstudied color.
In the remaining three groups, participants were probed with single features. In the mixed feature-probe group (N = 28), participants observed colored shapes at study and a gray shape or a colored arc at test and indicated whether that shape or color had been present in the study array. Targets, lures, and color and shape probes occurred with equal probabilities. Participants in the mixed feature-probe group did not need to attend to color–shape bindings explicitly, but they never knew in advance which feature would be tested in a trial, and so must have tried to remember both colors and shapes throughout the session. Participants in the blocked feature-probe group (N = 33) experienced the same task as participants in the mixed feature-probe group, except that the tests of color and shape recognition were presented in separate blocks, so that the participant knew at study which dimension would be tested. Participants in the feature-only group (N = 17) were shown either unifeature colored arcs or gray shapes in each study display, in separate blocks, with unifeature probes. Even implicit color–shape binding would of course be impossible in the feature-only group; we therefore took performance in these conditions to be our simplest measure of visual short-term memory.
Results
For all analyses, we set a criterion of p < .05 for declaring statistical significance and report generalized eta-square values to convey effect size (see Bakeman, 2005). We first report analyses of hit rate (correctly responding that a target was present at study) minus false alarm rate (incorrectly responding that a lure was present at study). Because we tested memory for several items with a single probe, hits – false alarms (H-FAs) is an appropriate measure of discrimination (Rouder, Morey, Morey, & Cowan, 2011). Figures 2 and 3 provide mean H-FAs for each manipulated variable in each group to show the robustness of the effects and to help readers compare these results to previous findings. However, to simplify hypothesis testing, we report ANOVAs collapsing across all set sizes and for set size 2 to support our claim that the secondary task impairs visual memory even for materials that should be within normal visual short-term memory capacity. We further evaluated nonsignificant interactions by comparing Bayes factors (Rouder et al., in press). Bayes factors enable comparisons of models within an ANOVA design, which would give us the power to evaluate the evidence in the data for the absence of an interaction, without requiring interpretation of a nonsignificant p value. Finally, we compared rates of correct rejections of features lures as a means of comparing feature memory during binding with separate-feature memory (cf. C. C. Morey, 2011).

Discrimination accuracy for bound probes and for color-feature probes under each of the encoding conditions. Error bars represent standard errors of the means, with the Cosineau–Morey correction applied (R. D. Morey, 2008)

Discrimination accuracy for bound probes and for shape-feature probes under each of the encoding conditions. Error bars represent standard errors of the means, with the Cosineau–Morey correction applied (R. D. Morey, 2008)
Discrimination: hits – false alarms
Consistent with previous research (e.g., Allen et al., 2006), the preliminary analyses showed that in the feature-probe groups, color discrimination was superior to shape discrimination. We therefore compared binding discrimination to color and shape discrimination in separate analyses, so as to avoid reporting interactions that might be due to differences between color and shape feature discrimination, rather than between feature and binding discrimination.
Binding versus color features
We carried out a two-way ANOVA on H-FAs with Task Group (binding probes, mixed feature probes, blocked feature probes, and features only) as a between-subjects factor and Retention Condition (900 ms, 4,100 ms, or 4,100 ms with tones) as a within-subjects factor. This analysis revealed significant main effects of retention condition [F(2, 196) = 161.15, MSE = 0.02, \( \eta_G^2 = .{34} \)] and group [F(3, 98) = 15.87, MSE = 0.07, \( \eta_G^2 = .{25} \)], but no interaction [F(6, 196) = 1.80, \( \eta_G^2 = .0{2} \)]. Participants performed best with the 900-ms retention interval (M = .74), poorer with the unfilled 4,100-ms interval (M = .65), and even worse with a filled 4,100-ms retention interval (M = .43, FLSD = .04). Bonferroni-corrected t tests indicated that discrimination was lower in the binding-probe group (M = .44) than in the mixed-feature group (M = .58), and that the latter was lower than discrimination in the blocked-feature (M = .70) and feature-only (M = .69) groups, which did not significantly differ (p ≈ 1). Means for all combinations of these conditions (plus set size) are given in Fig. 2.
This analysis provides no evidence that a secondary task impairs memory for binding any more than memory for features. We computed Bayes factors (Rouder et al., in press) for each combination of the main effects and interaction in our ANOVA model, so that the Bayes factors could then be compared. The model including main effects of group and retention condition yielded the highest Bayes factor (BF = 48.91), followed by the model including both main effects and their interaction (BF = 45.67). Using these values, we calculated the Bayes factor between the two models, whose interpretation is straightforward: The evidence provided in the data for the simpler model is greater by a factor of 1,768:1.
Examining the means in Fig. 2 makes clear how unfailingly the concurrent task impaired recognition, consistent with the observation that storing visual memoranda draws upon domain-general attention resources. We repeated the ANOVA above including only the displays of two stimuli, to provide an even stronger test of this hypothesis. Here, we did observe a significant Retention Condition × Group interaction [F(6, 196) = 3.11, MSE = 0.03, \( \eta_G^2 = .0{4} \)], and investigated by carrying out two follow-up ANOVAs, one comparing the 900-ms and 4,100-ms unfilled retention intervals, and one comparing the 4,100-ms unfilled and filled retention intervals. When comparing the short and long conditions, the interaction remained significant [F(3, 98) = 3.39, MSE = .03, \( \eta_G^2 = .03 \)]; in the binding-probe and mixed-feature groups, larger differences were observed between the 900-ms and 4,100-ms retention intervals (cf. the light and medium gray circles in Fig. 2, upper panels) than in the blocked-feature and feature-only groups (Fig. 2, lower panels). However, considering the 4,100-ms filled and unfilled retention intervals, group and retention condition did not interact significantly [F(3, 98) = 0.92, \( \eta_G^2 = .00{9} \)], even if we limited the analysis to comparisons between only the binding-probe and blocked-feature groups [F(1, 55) = 2.90, \( \eta_G^2 = .0{1} \)] or the binding-probe and feature-only groups [F(1, 39) = 0.12, \( \eta_G^2 < .001 \)].
Binding versus shape features
We carried out the ANOVAs described above including binding probes and shape feature probes, observing main effects of retention condition [F(2, 196) = 147.64, MSE = .02, \( \eta_G^2 = .{33} \)] and group [F(3, 98) = 3.02, MSE = 0.09, \( \eta_G^2 = .06 \)], but no interaction [F(6, 196) = 0.41, \( \eta_G^2 = .004 \)]. As in the previous analysis, discrimination was best with the 900-ms interval (M = .60), was significantly lower with the unfilled 4,100-ms interval (M = .49), and was lower still with the filled 4,100-ms interval (M = .26; FLSD = .04). Levels of group were less distinct in this analysis than in the binding versus color analysis. Bonferroni-corrected t tests indicated significant differences between the mixed-feature group (M = .38) and both the blocked-feature (M = .50) and feature-only (M = .49) groups, but no other comparisons were statistically significant. According to a Bayes factor analysis, models excluding the interaction were preferred. The model with the highest Bayes factor included only the retention condition effect (BF = 42.65), followed by the model including both main effects (BF = 42.04). The best model including the interaction yielded a Bayes factor of 38.21. Comparing these models, the retention-condition-effect model was preferred to the two-effect model by a factor of 4:1, but both of these models were preferred to the best model including the interaction by factors of at least 6,910:1.
We repeated this ANOVA including only the two-item trials. Only a main effect of retention condition was observed [F(2, 196) = 96.29, MSE = 0.04, \( \eta_G^2 = .28 \)], with levels ordered in the same manner as in the prior analyses (refer to Fig. 3). Neither the effect of group (F = 1.53, \( \eta_G^2 = .0{3} \)) nor the interaction (F = 1.52, \( \eta_G^2 = .02 \)) was statistically significant.
Correct lure rejections
Comparing correct rejections of feature lures across the binding and feature-only groups gives some idea of whether feature memory itself differs when remembering bindings is an explicit task goal (C. C. Morey, 2011). Even though participants in the binding-probe condition made a judgment about a colored shape, recalling which features had been present could aid in the correct rejection of feature lures, in which an unstudied feature was part of the test probe. A plausible benefit that might come with intentional binding is superior memory for the features involved, particularly the weaker features (C. C. Morey, 2009, 2011). These benefits should appear as improved retention of larger numbers of features when maintaining binding was necessary.
We therefore ran an ANOVA on correct-rejection rates with Group as a between-subjects factor and Set Size as a within-subjects factor, separately for shape feature lures, which focused on the weaker feature according to the discrimination analyses. We observed significant main effects of group [F(3, 98) = 4.37, MSE = 0.05, \( \eta_G^2 = .08 \)] and set size [F(2, 196) = 63.05, MSE = 0.01, \( \eta_G^2 = .{18} \)], as well as an interaction of these factors [F(6, 196) = 3.38, MSE = .01, \( \eta_G^2 = .0{3} \)]. We conducted follow-up ANOVAs in order to diagnose the meaning of this interaction, including combinations of three task groups. An analysis including only the feature-probe groups yielded no significant Group × Set Size interaction (F = 2.07, p > .06). Analyses excluding each other group but including the binding-probe group always yielded significant Group × Set Size interactions (Fs from 3.02 to 4.60). This suggests that in the full analysis, the Group × Set Size interaction reflects differences between the binding-probe and feature-probe groups. Furthermore, in an analysis including only the binding-probe and features-only groups, no interaction emerged (F = 1.06). This is consistent with the idea that remembering a colored shape is more like remembering a unidimensional object than like remembering the features of multidimensional objects.
Figure 4 depicts correct-rejection rates as a function of group, feature dimension, and set size. In the binding-probe group, set size had a smaller effect on shape correct rejections than that seen in the mixed- and blocked-feature-probe groups. This suggests that the interaction reflects a steeper cost for encoding more items in the conditions in which bound features were studied but only one feature was tested than in the binding-probe condition, in which remembering binding was necessary for making correct responses.

Mean correct rejections of color and shape lures, by task group and set size. Error bars represent standard errors of the means, with the Cosineau–Morey correction applied (R. D. Morey, 2008)
Discussion
Consistent with the claim that remembering bindings between features requires no more attention than does remembering the features themselves, these analyses yielded no evidence of differential effects of dividing attention during retention of bindings or of features only. Regardless of the number of visual memoranda or the number of features per object, performing simple nonvisual judgments during maintenance provoked robust interference. Comparison of Bayes factors, which allowed us to weigh the evidence for an interaction in these data, yielded no reason to believe that an interaction between group and retention condition was present in these data. We therefore conclude that the persistent secondary-task costs that we observed were similar for binding and feature judgments, replicating the results of Allen et al. (2006, in press).
Importantly, we also confirmed that performing a nonvisual, attention-demanding task provoked a concurrent cost even when only two objects were to be remembered. This finding—along with our analysis of lure correct rejections, showing that weaker features benefited from maintenance during binding (see Fig. 4)—is also difficult to reconcile with models proposing that visual features are maintained separately (e.g., Wheeler & Treisman, 2002). Our results also tended to suggest that recognition of bound objects (as measured by H-FAs) tended to be less accurate than recognition of separate features, something that is not clearly consistent with the idea that maintaining bound objects costs no more than maintaining separate features (e.g., Luck & Vogel, 1997). Together, it seems that maintaining multifeature objects conveys both cognitive benefits and costs (C. C. Morey, 2009, 2011), but that maintaining any sort of visual memoranda implicates general attentional processes.
Our results join others that have shown interference between maintenance of visual information and performance of some nonvisual task (e.g., Saults & Cowan, 2007; Stevanovski & Jolicœur, 2007; Vergauwe et al., 2012) in challenging theories proposing separate resources for domain-general attentional processes and visual–spatial storage. Research using other techniques has already hinted at close relationships between visual short-term memory and visual working memory (e.g., Miyake, Friedman, Rettinger, Shah, & Hegarty, 2001) and suggested that storage capacity in visual short-term memory is strongly related to attentional selection (Vogel, McCollough, & Machizawa, 2005). Other work has explicitly suggested that verbal information has access to more resources than does visual–spatial information (e.g., Camos, Lagner, & Barrouillet, 2009; Camos, Mora, & Oberauer, 2011; Hudjetz & Oberauer, 2007; Morey & Mall, 2012). While the evidence suggests that verbal memoranda have access to both domain-specific and domain-general working memory resources (Jarrold, Tam, Baddeley, & Harvey, 2011), isolating analogous domain-specific visual working memory resources has proved to be more difficult; here, we have shown that even small amounts of unidimensional visual memoranda cannot be held without cost during a nonvisual task. Going forward, greater consideration should be given to understanding the relationships between general attention and visual memory, regardless of whether bindings are to be remembered. Specifically, further consideration should be given to the idea that visual maintenance is carried out not within a domain-specific buffer, but instead within a domain-general system such as the focus of attention (Cowan, 2001).
References
Allen, R. J., Baddeley, A. D., & Hitch, G. J. (2006). Is the binding of visual features in working memory resource-demanding? Journal of Experimental Psychology: General, 135, 298–313. doi:10.1037/0096-3445.135.2.298
Allen, R. J., Hitch, G. J., & Baddeley, A. D. (2009). Cross-modal binding and working memory. Visual Cognition, 17, 83–102. doi:10.1080/13506280802281386
Allen, R. J., Hitch, G. J., Mate, J., & Baddeley, A. D. (in press). Feature binding and attention in working memory: A resolution of previous contradictory findings. Quarterly Journal of Experimental Psychology. doi:10.1080/17470218.2012.687384
Baddeley, A. (1986). Working memory. Oxford: Oxford University Press, Clarendon Press.
Baddeley, A. (2000). The episodic buffer: A new component of working memory? Trends in Cognitive Sciences, 4, 417–423. doi:10.1016/S1364-6613(00)01538-2
Baddeley, A. D., Allen, R. J., & Hitch, G. J. (2011). Binding in visual working memory: The role of the episodic buffer. Neuropsychologia, 49, 1393–1400. doi:10.1016/j.neuropsychologia.2010.12.042
Baddeley, A. D., & Hitch, G. J. (1974). Working memory. In G. H. Bower (Ed.), The psychology of learning and motivation: Advances in research and theory (Vol. 8, pp. 47–89). New York: Academic Press.
Bakeman, R. (2005). Recommended effect size statistics for repeated measures designs. Behavior Research Methods, 37, 379–384.
Brown, L. A., & Brockmole, J. R. (2010). The role of attention in binding visual features in working memory: Evidence from cognitive ageing. Quarterly Journal of Experimental Psychology, 63, 2067–2079. doi:10.1080/17470211003721675
Camos, V., Lagner, P., & Barrouillet, P. (2009). Two maintenance mechanisms of verbal information in working memory. Journal of Memory and Language, 61, 457–469.
Camos, V., Mora, G., & Oberauer, K. (2011). Adaptive choice between articulatory rehearsal and attentional refreshing in verbal working memory. Memory & Cognition, 39, 231–244. doi:10.3758/s13421-010-0011-x
Cowan, N. (2001). The magical number 4 in short-term memory: A reconsideration of mental storage capacity. Behavioral and Brain Sciences, 24, 87–185. doi:10.1017/S0140525X01003922
Cowan, N., & Morey, C. C. (2007). How can dual-task working memory retention limits be investigated? Psychological Science, 18, 686–688. doi:10.1111/j.1467-9280.2007.01960.x
Cowan, N., & Rouder, J. N. (2009). Comment on “Dynamic shifts of limited working memory resources in human vision. Science, 323, 877.
Dell’Acqua, R., & Jolicœur, P. (2000). Visual encoding of patterns is subject to dual-task interference. Memory & Cognition, 28, 184–191. doi:10.3758/BF03213798
Delvenne, J.-F., & Bruyer, R. (2004). Does visual short-term memory store bound features? Visual Cognition, 11, 1–27.
Delvenne, J.-F., Cleeremans, A., & Laloyaux, C. (2010). Feature bindings are maintained in visual short-term memory without sustained focused attention. Experimental Psychology, 57, 108–116. doi:10.1027/1618-3169/a000014
Gajewski, D. A., & Brockmole, J. R. (2006). Feature bindings endure without attention: Evidence from an explicit recall task. Psychonomic Bulletin & Review, 13, 581–587. doi:10.3758/BF03193966
Hudjetz, A., & Oberauer, K. (2007). The effects of processing time and processing rate on forgetting in working memory: Testing four models of the complex span paradigm. Memory & Cognition, 35, 1675–1684.
Ishihara, S. (1966). Tests for colour blindness. Tokyo: Kanehara Shuppan.
Jarrold, C., Tam, H., Baddeley, A. D., & Harvey, C. E. (2011). How does processing affect storage in working memory tasks? Evidence for both domain-general and domain-specific effects. Journal of Experimental Psychology: Learning, Memory, and Cognition, 37, 688–705. doi:10.1037/a0022527
Luck, S. J., & Vogel, E. K. (1997). The capacity of visual working memory for features and conjunctions. Nature, 390, 279–281. doi:10.1038/36846
Miyake, A., Friedman, N. P., Rettinger, D. A., Shah, P., & Hegarty, M. (2001). How are visuospatial working memory, executive functioning, and spatial abilities related? A latent-variable analysis. Journal of Experimental Psychology: General, 130, 621–640.
Morey, C. C. (2009). Integrated cross-domain object storage in working memory: Evidence from a verbal-spatial memory task. Quarterly Journal of Experimental Psychology, 62, 2235–2251.
Morey, C. C. (2011). Maintaining binding in working memory: Comparing the effects of intentional goals and incidental affordances. Consciousness and Cognition, 20, 920–927.
Morey, C. C., & Cowan, N. (2004). When visual and verbal memories compete: Evidence of cross-domain limits in working memory. Psychonomic Bulletin & Review, 11, 296–301. doi:10.3758/BF03196573
Morey, C. C., & Mall, J. T. (2012). Cross-domain interference costs during concurrent verbal and spatial serial memory tasks are asymmetric. Quarterly Journal of Experimental Psychology, 65, 1777–1797. doi:10.1080/17470218.2012.668555
Morey, R. D. (2008). Confidence intervals from normalized data: A correction to Cousineau (2005). Tutorials in Quantitative Methods for Psychology, 4, 61–64.
Phillips, W. A., & Christie, D. F. (1977). Interference with visualization. Quarterly Journal of Experimental Psychology, 29, 637–650.
Rouder, J. N., Morey, R. D., Morey, C. C., & Cowan, N. (2011). How to measure working memory capacity in the change detection paradigm. Psychonomic Bulletin & Review, 18, 324–330. doi:10.3758/s13423-011-0055-3
Rouder, J. N., Morey, R. D., Speckman, P. L., & Province, J. M. (in press). Default Bayes factors for ANOVA designs. Journal of Mathematical Psychology. doi:10.1016/j.jmp.2012.08.001
Saults, J. S., & Cowan, N. (2007). A central capacity limit to the simultaneous storage of visual and auditory arrays in working memory. Journal of Experimental Psychology: General, 136, 663–684. doi:10.1037/0096-3445.136.4.663
Schneider, W., Eschmann, A., & Zuccolotto, A. (2002). E-Prime user’s guide. Pittsburgh: Psychology Software Tools, Inc.
Stevanovski, B., & Jolicœur, P. (2007). Visual short-term memory: Central capacity limitations in short-term consolidation. Visual Cognition, 15, 532–563.
Vergauwe, E., Dewaele, N., Langerock, N., & Barrouillet, P. (2012). Evidence for a central pool of general resources in working memory. Journal of Cognitive Psychology, 24, 359–366.
Vogel, E. K., McCollough, A. W., & Machizawa, M. G. (2005). Neural measures reveal individual differences in controlling access to working memory. Nature, 438, 500–503. doi:10.1038/nature04171
Vogel, E. K., Woodman, G. F., & Luck, S. J. (2001). Storage of features, conjunctions, and objects in visual working memory. Journal of Experimental Psychology: Human Perception and Performance, 27, 92–114. doi:10.1037/0096-1523.27.1.92
Wheeler, M. E., & Treisman, A. M. (2002). Binding in short-term visual memory. Journal of Experimental Psychology: General, 131, 48–64. doi:10.1037/0096-3445.131.1.48
Author note
Thanks to Vicky Cong, Mareike Kirsch, and Antonia Südkamper for assistance with the data collection.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article
Cite this article
Morey, C.C., Bieler, M. Visual short-term memory always requires general attention. Psychon Bull Rev 20, 163–170 (2013). https://doi.org/10.3758/s13423-012-0313-z
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13423-012-0313-z