
Abstract
Memory plays a critical role in time estimation, yet detailed mechanisms underlying temporal memory have not been fully understood. The current functional magnetic resonance imaging (fMRI) study investigated memory phenomena in absolute identification of time durations and line lengths. In both time and length identification, participants responded faster to end-of-range stimuli (e.g., the shortest or longest items of the stimulus set) than to middle stimuli. Participants performed worse in the incongruent condition (mismatch between time and length in the stimulus position) than in the congruent condition, indicating cross-dimensional interference between time and length. Both phenomena reflect increased difficulty of retrieving information relevant to the current context in the presence of context-irrelevant information. A region in the lateral inferior prefrontal cortex showed a greater response to the middle stimuli and in the incongruent condition suggesting greater demands for controlled memory retrieval. A cognitive model based on the ACT-R (Adaptive Control of Thought – Rational) declarative memory mechanisms accounted for the major behavioral and imaging results. The results suggest that contextual effects in temporal memory can be understood in terms of domain-general memory principles established outside the time estimation domain.
Similar content being viewed by others


Introduction
Memory plays a significant role in time estimation (Baudouin, Vanneste, Pouthas, & Isingrini, 2006; Brown, 1997; McCormack, Brown, Smith, & Brock, 2004). According to the scalar expectancy theory (Gibbon, Church, & Meck, 1984), comparison between the content of working memory and a value sampled from long-term memory allows one to reproduce a duration experienced in the past. In the multiple time-scale model (Staddon & Higa, 1999), time estimation is based on the association between specific time durations and specific amounts of decay in memory. Several efforts have been made to develop and specify models of temporal memory to address questions such as how temporal representations are developed (Jones & Wearden, 2003) and retained over delay (Droit-Volet, Wearden, & Delgado-Yonger, 2007), and how interference occurs in temporal memory (Ogden, Wearden, & Jones, 2008).
One of the questions that have not been fully addressed by the above-mentioned efforts is how temporal memory relates to non-temporal memory, and whether temporal memory could be understood in terms of general memory principles. A few researchers have investigated whether principles developed outside the time estimation domain could account for temporal memory. Brown, McCormack, Smith, and Stewart (2005) modeled performance in identification and bisection of temporal durations based on Parducci’s (1965) range frequency theory. McCormack, Brown, Maylor, Richardson, and Darby (2002) modeled performance in temporal absolute identification with an exemplar model based on principles originally developed to account for absolute identification in nontemporal dimensions. Taatgen and Van Rijn (2011) modeled a memory-mixing phenomenon in temporal reproduction using the domain-general memory mechanisms in the ACT-R cognitive architecture (Anderson et al., 2004).
We are interested in whether a domain-general approach can be used to understand various context effects in time estimation. Studies have shown that judgment of duration is often influenced by other durations present in the environment. When multiple durations are experienced in the same experimental context, participants tend to overestimate shorter durations and underestimate longer durations, moving their mean estimate towards a “central tendency” (Gu & Meck, 2011; Lejeune & Wearden, 2009; Taatgen & Van Rijn, 2011). When participants classify stimulus durations as being closer to the short or the long standard, their bisection point (i.e., the duration that produces 50 % Long response) is influenced by the distributional properties of the stimuli set (Wearden & Ferrara, 1995). These and other kinds of context effects are often present in both temporal and non-temporal dimensions, which raises the question of whether context effects in temporal and non-temporal dimensions could be accounted for by common principles. While the models of temporal memory developed within the time estimation domain have not addressed this question, some of the modeling work based on the domain-general approach (Brown et al., 2005; Taatgen & Van Rijn, 2011) suggest an affirmative answer to this question.
Based on the prior work with the domain-general approach, the current study aims to investigate whether common principles can account for context effects in absolute identification of temporal and non-temporal (length) stimuli. We focus on two phenomena, the end effect and the congruity effect, which are considered below. Both can be interpreted as memory phenomena where target information processing is biased by non-target information present in the same experimental context. Although each of these effects has been fairly well studied on its own, few if any models have been developed to account for both effects in absolute identification (see Birnbaum & Jou, 1990 and Jou, 2010 for modeling work in comparative judgment). We will model them in the domain-general ACT-R declarative mechanism (Anderson et al., 2004) and test the model with both behavioral and neuroimaging data.
End effect
In the absolute identification paradigm, participants are presented with several stimuli that vary on a single physical dimension (e.g., ten stimuli with different lengths) and are asked to identify each new stimulus with a label (e.g., a number from 1 to 10). One of the common results in absolute identification is that responses are more accurate or faster to the stimuli located at the either end of the stimulus set than to the stimuli located in the middle. The end effect is typically characterized by U-shape in the accuracy profile or inverse-U shape in the response time profile as a function of stimulus position. The end effect is a robust phenomenon present after extensive practice (Weber, Green, & Luce, 1977) or changes in stimulus spacing (Lacouture, 1997), and has been found with various stimuli such as tone frequency (Brown et al., 2005; Stewart, Brown, & Chater, 2005), line lengths (Elvevåg, Brown, McCormack, Vousden, & Goldberg, 2004; Lacouture, 1997; Petrov & Anderson, 2005), and time durations (Brown et al., 2005; Elvevåg et al., 2004; Lacouture, Grondin, & Mori, 2001; McCormack et al., 2002).
According to some accounts (Berliner & Durlach, 1973; Luce, Nosofsky, Green, & Smith, 1982), the end effect reflects privileged status of end stimuli. For example, the end stimuli might be used as anchors or reference points in making judgments, and performance on middle stimuli is limited by distance from those anchors (Berliner & Durlach, 1973). According to alternative accounts (Petrov & Anderson, 2005; Stewart et al., 2005), the end effect arises because the end stimuli have fewer possibilities for errors. Errors can occur in both directions for the middle stimuli but they can occur only in one direction for the end stimuli. Consistent with this claim, correction for the asymmetries of errors between end and middle stimuli markedly reduces the end effect (Weber et al., 1977). The end effect is an instance of context effects because end stimuli are always defined in terms of relative positions within stimulus set.
Congruity effect
Processing of magnitude information on one dimension can be biased by magnitude information on another dimension. Small numbers are responded to faster with the left hand while large numbers are responded to faster with the right hand (Dehaene, Bossini, & Giraux, 1993). Participants are faster to compare numerical size of two numbers when the responses based on numerical size and physical size match than when they conflict (Kaufmann et al., 2005). Time durations of stimuli with larger magnitude in numerosity, spatial, or luminance extent are judged to be longer (Xuan, Zhang, He, & Chen, 2007). Durations presented in the right space are overestimated whereas the same durations in the left space are underestimated (Vicario et al., 2008). Judgments are faster when short and long durations are responded to with left and right hands, respectively, than with the opposite mapping (Vallesi, Binns, & Shallice, 2008).
This cross-dimensional interference resembles findings in classical interference paradigms in which participants make responses based on the task-relevant information inhibiting prepotent responses based on the task-irrelevant information. In the Stroop task (Stroop, 1935), participants are faster in naming the ink color of a word when the word meaning matches the ink color (congruent) than when it does not (incongruent). The prefrontal cortex (Bench et al., 1993; Carter, Mintun, & Cohen, 1995; Pardo, Pardo, Janer, & Raichle, 1990; Taylor, Kornblum, Lauber, Minoshima, & Koeppe, 1997) tends to show a greater activity in the incongruent versus congruent condition of the Stroop task, indicating a greater control for selecting the context-relevant response (Cohen, Braver, & O’Reilly 1996; Taylor et al., 1997). A greater prefrontal response has also been found in the incongruent condition of the number-size interference task (Ansari, Fugelsang, Dhital, & Venkatraman, 2006; Kaufmann et al., 2005).
Brain region in ACT-R
ACT-R (Adaptive Control of Thought – Rational) is an integrated theory of human cognition (Anderson et al., 2004). ACT-R consists of multiple modules each dedicated to a specific functionality (e.g., visual module involved in processing visual stimuli) and a central procedural system that coordinates activities of those modules. Each module has a specific set of operations defined for it and includes an associated buffer that facilitates communication with the procedural system and other modules. For instance, the procedural system can access information currently available in the visual buffer (e.g., a red stimulus) and use that information to make a request to the motor module (e.g., press a key). The ACT-R theory specifies how long a module will take to process information. Combinations of those predictions can be compared with behavioral response times. In addition, activities of these modules have been associated with specific brain regions and predictions can be compared with fMRI activity (Anderson, Fincham, Qin, & Stocco, 2008; Borst & Anderson, 2014).
The current study focuses on a predefined region in the lateral inferior prefrontal cortex (LIPFC) that spans the inferior frontal sulcus and includes parts of Brodmann areas 9, 45, and 46. This region has been mapped to activity in the ACT-R declarative module responsible for controlled retrieval of learned information. While prefrontal cortex has been associated with memory processes (Funahashi, Bruce, & Goldman-Rakic, 1989; Goldman-Rakic, 1995; Miller & Cohen, 2001), there are continuing discussions regarding the specific functions of the different sub-regions within the prefrontal cortex (D'Esposito, Aguirre, Zarahn, Ballard, Shin, & Lease, 1998; Miller & Cohen, 2001; Petrides, 1994). The particular predefined region used here is one that was initially defined in Anderson, Qin, Sohn, Stenger, and Carter (2003) and has been consistently used in multiple imaging studies conducted by members of our group. These studies have demonstrated that this region responds to various retrieval manipulations including strength of memory, recency, and frequency of memory access (Danker, Gunn, & Anderson, 2008; Sohn, Goode, Stenger, Carter, & Anderson, 2003; Sohn et al., 2005). In Danker, Gunn, and Anderson (2008), this region more precisely reflected retrieval demands predicted by an ACT-R model of paired associate memory in comparison with other prefrontal regions as described in Thompson-Schill et al. (1997) and Dobbins and Wagner (2005).
Although the mapping between memory retrieval and the predefined LIPFC region has been established mainly in the domain of semantic and episodic memory, we predicted that the same mapping would apply to the domains of temporal and spatial memory. It has been shown that Brodmann areas 9 and 46 are involved in memory of various stimulus types (D'Esposito et al., 1998; Petrides, Alivisatos, Evans, & Meyer, 1993; Rowe & Passingham, 2001). These areas have also been associated with memory processes in time estimation (Harrington, Haaland, & Knight, 1998; Lewis & Miall, 2006; Rao, Mayer, & Harrington, 2001). For instance, a greater dorsolateral prefrontal activation was found in the phase of time discrimination associated with comparison of duration representations and response selection, but not in the phase associated with encoding and temporary maintenance (Rao et al., 2001). In Lewis and Miall (2006), greater activations in dorsolateral and ventrolateral prefrontal cortices in time estimation tasks compared with non-temporal control tasks were interpreted to reflect storage and recall of temporal memory. These results are consistent with the view that regions in the prefrontal cortex that are modulated by memory load can respond to different types of stimulus information (Nystrom et al., 2000; Rao, Rainer, & Miller, 1997).
Based on the view that the end effect arises due to competition from adjacent stimuli (Petrov & Anderson, 2005), we predicted a greater LIPFC response to the middle stimuli associated with a greater retrieval demand. We also expected a greater LIPFC response when responses based on temporal and non-temporal information are incongruent than when they are congruent due to a greater control in retrieving context-relevant information. This prediction is consistent with the ACT-R model of the Stroop task (Lovett, 2005) that assumes additional memory retrieval when the dimension of retrieved information does not match the target task dimension. We predicted that retrieval time of the cognitive model in ACT-R would map onto the LIPFC response to the end and congruity effects. The declarative module would be engaged for longer period of time in the middle and incongruent conditions due to the additional retrieval activities.
Methods
Participants
Thirty right-handed participants (19 female, aged 18–27 years, mean age 21.6 years) were recruited from the local community. Informed consent approved by Carnegie Mellon University Institutional Review Board (IRB) was obtained from each participant.
Stimuli and design
Each trial started with a white horizontal line presented in the center of the black background. The line stimuli varied both in time duration of presentation and physical length. One of the four durations (T1: 300, T2: 500, T3: 700, T4: 900 in ms) and one of the four lengths (L1: 125, L2: 175, L3: 225, L4: 275 in pixels (px); 2.58, 3.62, 4.65, 5.68 in degree visual angles, respectively) were randomly selected for each stimulus. For each stimulus, stimulus position in time duration could be equal to or different from stimulus position in length. There were 16 possible combinations of the durations and lengths.
Participants identified each stimulus based on the task-relevant dimension by selecting one of the four colors associated with unique fingers on a response glove. In the time identification task, the shortest duration (T1) was mapped with red (index), the second shortest (T2) with green (middle), the third shortest (T3) with blue (ring), and the longest (T4) with yellow (little). The same mapping applied to the length task (e.g., L1 mapped with red color and index key).
The experiment had a 2-task (time, length) × 2-position (end, middle) × 2-congruity (identical, incongruent) within-subject design. Task refers to which stimulus dimension participants attend in order to identify stimuli. Position refers to whether a stimulus is located at either end of the stimulus set. Congruity refers to whether the stimulus position in the task-relevant dimension matches the stimulus position in the task-irrelevant dimension. We define “inter-dimensional distance” as the absolute difference between stimulus positions in the two dimensions. For example, a stimulus with a duration of 300 ms (T1) and length of 225 px (L3) has the inter-dimensional distance of 2. We will focus on the contrast between 0 (identical) and 2 (incongruent) because these distances represent all values in stimulus position whereas an inter-dimensional distance of 3 only has stimuli that have values of 1 or 4 and an inter-dimensional distance of 1 has an over-representation of values of 2 and 3.
Experimental procedure
Participants completed an outside-scanner practice session followed by a functional magnetic resonance imaging (fMRI) session. During the practice session, participants received a written instruction and performed one block of the time identification task and one block of the length identification task in a random order. The fMRI session had nine time blocks and nine length blocks in a random order. The two blocks from the practice session and the first two blocks (one time block and one length block) performed during the structural scan were excluded from the analysis.
Each block started with a screen that indicated which dimension (time or length) to attend to identify stimuli during the block. This was followed by four reference stimuli successively presented in a random order. The reference stimuli were horizontal lines in four different colors (red, green, blue, and yellow). Each reference stimulus had one of four durations (T1 through T4) and one of the four lengths (L1 through L4). The color of each reference stimulus indicated stimulus position on the task-relevant dimension. For example for the time block, a red line had a duration of 300 ms (T1) and could have any of the four length values. Participants were instructed to learn the mapping between colors and the stimuli on the task-relevant dimension. No response was required during this phase. The color-stimulus mapping was held constant across blocks.
The reference stimuli were followed by 24 trials in which participants identified each stimulus based on the task-relevant dimension. In each trial (Fig. 1), participants were presented with a sample stimulus followed by a response prompt (question mark). Participants had to respond within 2 s from the prompt onset. A response made after the time limit was considered as a timeout. Either immediately after a response or at the time limit, participants were presented with a fixation screen followed by a feedback screen. The feedback screen was identical to the sample stimulus screen in both duration and length of stimulus except for two additional features: (1) The feedback stimulus was in the color correctly associated with the sample stimulus in the task-relevant dimension (e.g., red for 300-ms sample duration in the time block), and (2) the feedback screen showed whether the response was right, wrong, or timed out. The feedback screen was followed by another fixation screen. The two fixations surrounding the feedback screen served as jitters to achieve a better temporal resolution for the fMRI analysis. A random duration was selected from a uniform distribution of 3–7 s and was randomly distributed to the two jittered fixations. Each fixation lasted for at least 500 ms. Each block lasted for approximately 3 min. Each participant took about an hour and a half to complete the experiment.

The procedure of an experimental trial. Participants estimated duration or length of sample stimulus and made a response within 2 s from the onset of response prompt (?). Immediately after the response or the 2-s time limit, participants were presented with a fixation screen, followed by feedback and another fixation screen
fMRI data acquisition
Images were acquired using gradient echo-echo planar image (EPI) acquisition on a 3 T Verio Scanner using a 32-channel RF head coil, with 2-s repetition time (TR), 30-ms echo time (TE), 79° flip angle, and 20-cm field of view (FOV). Both experiments acquired 34 axial slices on each TR using a 3.2-mm thick, 64×64 matrix. This produces voxels that are 3.2 mm high and 3.125 × 3.125 mm2. The anterior commissure-posterior commissure (AC-PC) line was on the eleventh slice from the bottom scan slice. Acquired images were pre-processed and analyzed using AFNI (Cox, 1996; Cox & Hyde, 1997). Functional images were motion-corrected using 6-parameter 3D registration, slice-time centered at 1 s, and normalized such that voxel time series within blocks had mean value of 100. Functional data were then co-registered to a common reference structural MRI by means of a 12-parameter 3D registration and smoothed with a 6-mm full-width-at-half-maximum 3D Gaussian filter to accommodate individual differences in anatomy.
fMRI data analysis
Our primary goal was to understand condition-dependent differences in the time courses of brain activity. A general linear model (GLM) was used to estimate hemodynamic response functions (HRFs) using a finite impulse response (FIR) basis set of eight TRs from the onset of the sample stimulus. Separate first-level design matrices were constructed for analyzing time blocks and length blocks. In each case, the design matrix consisted of seven model variables and a baseline model of an order-4 polynomial to account for general signal drift. The model variables corresponded to the 2×4 cells of position (end and middle) by inter-dimensional distance (0 through 3). Note that middle stimuli cannot show inter-dimensional distance of 3 by definition, hence there were only seven cells. While all seven cells were modeled in the GLM, subsequent analyses focus on the inter-dimensional distance levels of 0 (identical) and 2 (incongruent). Each GLM yielded seven conditions × eight time lags = 56 beta weights per voxel for each participant. Group-level analyses were performed on these first-level beta estimates. Both whole-brain exploratory analyses and predefined region of interest (ROI) analyses of average beta weight per region were conducted. The predefined LIPFC region is defined as a rectangular region that measures approximately 16 mm wide, 16 mm long, and 13 mm high (5 × 5 × 4 voxels from the functional acquisition matrix) centered at Talairach coordinates x = +/−43, y = 23, and z = 24. This region spans the inferior frontal sulcus and includes parts of Brodmann areas 9, 45, and 46.
Results
Behavioral
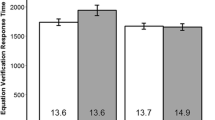
Data from one length block from one of the participants was not collected due to a technical problem. Timeout trials (3.37 % of all trials) and trials with response times shorter than 100 ms (.88 % of all trials) were excluded from the analysis. The probability of correct response was measured by dividing the number of correct trials by the sum of the number of correct trials and the number of incorrect trials. The mean and standard error of mean in each condition can be found in Table 1 . For response time, all trials were analyzed regardless of accuracy. A 2-task × 2-position × 2-congruity repeated measures ANOVA was performed on each performance measure. With respect to accuracy, participants performed significantly worse in the time task (F(1,29) = 157.06, p < .001, η 2 ρ =.844), with the middle stimuli (F(1,29) = 9.22, p = .005, η 2 ρ =.241), and in the incongruent (F(1,29) = 31.84, p < .001, η 2 ρ =.523) condition. Both the end effect (F(1,29) = 18.55, p < .001, η 2 ρ =.390) and the congruity effect (F(1,29) = 7.48, p = .011, η 2 ρ =.205) were greater in the time task. The congruity effect was greater for the end stimuli (F(1,29) = 12.41, p = .001, η 2 ρ =.300). The three-way interaction did not reach significance (F(1,29) = 3.45, p = .073, η 2 ρ =.106). With respect to latency, participants were significantly slower in the time task (F(1,29) = 244.61, p < .001, η 2 ρ =.894), with the middle stimuli (F(1,29) = 156.96, p < .001, η 2 ρ =.844), and in the incongruent (F(1,29) = 29.64, p < .001, η 2 ρ =.505) condition. There were significant interactions between congruity and task (F(1,29) = 11.10, p = .002, η 2 ρ =.277) and between congruity and position (F(1,29) = 4.41, p = .045, η 2 ρ =.132). The three-way interaction was significant (F(1,29) = 8.53, p = .007, η 2 ρ =.227).
Figure 2A (solid lines) displays probability of correct response (left) and response time (right) as a function of stimulus position. Overall, participants performed more accurately and responded faster in the length task. Response-time profile exhibits a robust inverse-U shape in both tasks. Figure 2B (solid bars) compares performance in the end (stimulus 1 and 4 in Fig. 2A) and middle (stimulus 2 and 3) conditions. With respect to probability of correct response, the end effect is present in the time task (t(29) = 4.34, p < .001) but not in the length task (t(29) = .81, p = .422). With respect to response time, the end effect is significant in both the time (t(29) = 10.76, p < .001) and length (t(29) = 8.17, p < .001) tasks. Figure 2C (solid bars) compares performance in the identical and incongruent conditions. With respect to probability of correct response, the congruity effect was significant in both tasks (time: t(29) = 5.37, p < .001, length: t(29) = 2.39, p = .023), but to a greater extent in the time task. With respect to response time, the congruity effect was present only in the time task (t(29) = 5.98, p < .001).

Performance of human participants (H) and model (M). Probability of correct response (left) and response time (right) as a function of stimulus position (A, solid: participants, dashed: model), end vs. middle stimuli (B, solid: participants, striped: model), and identical versus incongruent stimuli (C, solid: participants, striped: model) for each task
Imaging data
In addition to a block excluded from behavioral analysis, data from four blocks (1 % of the imaging data) were additionally excluded due to technical difficulties encountered during data collection. Both correct and incorrect trials were included in the analysis.
Figure 3 plots the beta weights (percent change from the baseline value of 100) in the LIPFC across eight scans (16 s) from the stimulus onset scan. Typically stimulus presentation, judgment, and response generation were completed by the end of the first scan and the lagged hemodynamic response peaks two to three scans later. We performed a 2-task × 2-position × 2-congruity × 8-scan repeated measures ANOVA.Footnote 1 The position x scan (F(7,175) = 4.09, p < .001, η 2 ρ =.141) and congruity × scan (F(7,175) = 2.64, p = .013, η 2 ρ =.095) interactions were both significant. The task × scan (F(7,175) = 1.89, p = .074, η 2 ρ =.07) interaction did not reach significance. In addition, there were significant main effects of scan (F(7,175) = 14.43, p < .001, η 2 ρ =.366) and position (F(1,25) = 8.36, p = .008, η 2 ρ =.251). The main effects of task (F(1,25) = 1.54, p = .226, η 2 ρ =.058) and congruity (F(1,25) = .04, p = .836, η 2 ρ =.002) were not significant.

The beta weights in the LIPFC region over eight scans for the effects of task (A), position (B), and congruity (C). Scan 1 corresponds to the onset of sample stimulus
For the purpose of straightforward comparison with model results, we extracted a single measure by subtracting the average response on earlier scans (scan 2–3) from the average on the later scans (scan 4–6). We performed a 2-task × 2-position × 2-congruity repeated measures ANOVA on this measure. These differences in LIPFC activation were significantly greater in the time task (F(1,25) = 5.23, p = .031, η 2 ρ =.173), with the middle stimuli (F(1,25) = 10.95, p = .003, η 2 ρ =.305), and in the incongruent (F(1,25) = 6.02, p = .022, η 2 ρ =.194) condition. None of the interactions was significant. The mean beta difference in each condition can be found in Table 1 .
We further performed an exploratory analysis to find regions that show differential engagement over scans to retrieval manipulations. Table 2 lists the regions that showed significant task × scan, position × scan, or congruity × scan interaction, with at least 29 contiguous voxels at p = .0025. These parameter values yield regions with a corrected brain-wise significance level of p < 0.05 as determined by simulation (Cox & Hyde, 1997). For the task × scan interaction, most of the regions showed greater response to the time task. Those regions included middle/inferior frontal gyrus and medial frontal gyrus. Insula and caudate also responded greater to the time task, consistent with their involvement in temporal processing (Lewis & Miall, 2006; Pouthas et al., 2005; Rao et al., 2001; Tregellas, Davalos, & Rojas, 2006). However, it remains uncertain whether their response reflects specific involvement of those regions in temporal processing or greater difficulty of the time task. For the position × scan interaction, most of the regions with a greater response to the end stimuli are part of the default network that tends to show greater deactivation with increasing cognitive load (McKiernan, Kaufman, Kucera-Thompson, & Binder, 2003; Sreenivas, Boehm, & Linden, 2012). The right middle frontal gyrus slightly overlaps with our LIPFC region and showed a greater response to the middle stimuli. The regions with a congruity × scan interaction included bilateral middle frontal gyri and parietal cortex that have been associated with interference resolution (Bunge, Ochsner, Desmond, Glover, & Gabrieli, 2001; Carter et al., 1995; Taylor et al., 1997).
Modeling
The imaging results supported the notion that both end effect and congruity effect could be explained in terms of demand of controlled memory retrieval subserved by the LIPFC region. We modeled the behavioral results in the ACT-R declarative system and compared the imaging results with the model’s prediction on memory retrieval time. Once we had fit the latency, we tested the correspondence between retrieval time prediction and the LIPFC response. Before elaborating on how the model performs the task, we will first offer a brief overview of the declarative system of ACT-R.
In ACT-R, declarative knowledge (facts such as “2+3=5”) is represented in structures called chunks. Each chunk is associated with an activation value that reflects the likelihood that information will be useful in the future. The activation value (Ai) of a chunk is the sum of base-level activation, spreading activation, and noise:
The base-level activation (Bi) reflects the recency and frequency of use of the chunk i. The spreading activation (ΣWjSji) reflects the effect of the current context defined as the set of retrieval cues on the retrieval process. Wj is the attentional weight to retrieval cue j. Sji is the strength of association between retrieval cue j and chunk i (i.e., the likelihood of which retrieval cue j predicts chunk i information). The chunk with the highest activation has the highest likelihood of retrieval if the activation value is above a threshold. Retrieval time of chunk is based on the following equation:
where F is the latency factor parameter and f is the latency exponent parameter.
Time estimation in ACT-R
In ACT-R, time estimation is achieved through the processing in the temporal module (Taatgen, Van Rijn, & Anderson, 2007) based on the internal clock model (Matell & Meck, 2000) and its interaction with the rest of the system. In the temporal module, a pacemaker starts incrementing pulses in the temporal buffer once a start signal is given. When time estimation finishes, pulse accumulation stops and the temporal buffer can be cleared. The number of accumulated pulses corresponds to the estimated time duration. The pulse length keeps increasing as time progresses, which makes time estimates more accurate for shorter durations than for longer durations.Footnote 2
The ACT-R model of absolute identification
Our modelFootnote 3 starts with four time chunks (T1 through T4) and four length chunks (L1 through L4) in the declarative memory that represent the task stimuli. These chunks hold the mapping between the stimulus values and the correct responses. For example, chunk T1 is associated with “time” task, duration of 300 ms, and “j” response key. To produce the correct answer the model must retrieve the chunk that matches the current stimulus. The time to retrieve a chunk and its probability of being retrieved is controlled by its level of activation, which can be influenced by the spread of activation from elements in the imaginal buffer.
The imaginal buffer holds three retrieval cues that represent the current context: Knowledge about the task (task cue: “time” or “length”), the estimated duration (time cue: τ1, τ2, τ3, or τ4), and the estimated length (length cue: λ1, λ2, λ3, or λ4) of the current stimulus. Each retrieval cue sends activation to each chunk in the declarative memory. As specified in Eq. 1, spreading activation is determined by the attentional weightFootnote 4 (Wj) multiplied by the association strength (Sji) between a retrieval cue and a chunk. The attentional weights for all cues were equal and so the critical factor is the strength of associations which were set as follows:
-
1.
The association is .2 between task cue and a chunk with matching task dimension (e.g., time and T2) and 0 otherwise (e.g., time and L2).
-
2.
Within a dimension, cues have an associative strength of 1 to matching chunks (e.g., τ1 and T1), .99 to chunks with one distance away (e.g., τ1 and T2), and 0 to chunks further away.
-
3.
Across dimensions, there are weaker associations that also depend on inter-dimensional distance (e.g., .99 between τ1 and L1, 0 between chunks further away).
The exact values are not critical but serve to capture task relevance (1 above), intra-dimensional similarity (2 above), and inter-dimensional similarity (3 above).
Figure 4 shows how the model performs the task. The model starts each trial with a task cue and neither of time and length cues in the imaginal buffer. We assumed that length estimation takes place automatically regardless of the current task. When a sample stimulus appears in the screen, length of the line (in pixels) is available in the vision module. There is noise in the length information that is large enough to lead to a wrong selection of length cue in about 10 % of the total trials. While attending the line, the model makes a request to the temporal module to start pulse accumulation. In the length task, when the response prompt appears, the model starts retrieving a response without estimating duration of the stimulus. In the time task, when the response prompt appears, the model uses the pulse count in the temporal buffer to select a time cue. The noise in the time accumulation is sufficient to result in a wrong selection of time cue in about 30 % of the total trials.

The flow of control in the model of absolute identification
Retrieval of response is influenced by spreading activation from the current task and the encoded stimulus information. Due to the encoding noise and bias from task-irrelevant dimension, the model does not always retrieve the correct chunk. If the retrieved chunk matches the retrieval cues, the model makes a keypress response using the key associated with the chunk. However, despite the biasing of activation from the current task chunk in the imaginal buffer, the retrieved chunk may not match the task cue (e.g., length chunk is retrieved in the time task). In this case, the model makes another retrieval request restricting the retrieval to the chunks in the relevant dimension (“check-dimension”).Footnote 5 Similarly, despite the biasing activation from the imaginal buffer, the retrieved chunk may match the task cue but may not match the time cue in the time task or length cue in the length task (e.g., T2 is retrieved when the time cue is τ1). Again in this case, the model makes another retrieval request (“check-estimate”) restricting the retrieval to the chunks in the relevant dimension.Footnote 6
It is possible for the model to spend multiple retrieval attempts trying to retrieve the chunk that contains the correct response. Given that participants had a response deadline, the model estimates time since prompt onset in order to avoid timeout trials. It stops trying to retrieve the correct chunk when it is close to the response deadline, and responds with the currently retrieved chunk, typically leading to an error.
Modeling task, end, and congruity effects
Task effect
We set higher base-level activation values for the length chunks (.1) than for the time chunks (0) such that retrieval takes shorter for the length chunks (Eq. 2).Footnote 7 Higher base-level activation also leads to occasional retrieval of a length chunk in the time task, which increases the likelihood of firing the check-dimension production (i.e., longer response time). The absence of cross-dimensional interference (no time estimation) also contributes to better performance in the length task.
End effect
In the incorrect trials, participants were more likely to choose a “neighbor” (i.e., one distance off from the target stimulus) than the other stimuli located further away.Footnote 8 In the model, the association strength (.99) between a pair of a retrieval cue and a chunk in the matching dimension with distance 1 (neighbor) is almost as high as the association strength (1.0) between a pair with distance 0 (target). Activation noise is often large enough to overcome the difference in the association strength, resulting in the retrieval of a wrong neighbor instead of the target. Wrong retrievals occur more frequently for the middle stimuli that have more neighbors, which increases likelihood of firing the check-estimate production and costs response time.
Congruity effect
The model only produces the congruity effect in the time task. In the time task, the length information is encoded before the time information and its presence facilitates performance in the identical condition and interferes with performance in the incongruent condition. For instance, when the length and time cues are λ3 and τ4 respectively, spreading activation from λ3 length cue can bias the model to retrieve an incorrect chunk T3 (inter-dimensional distance 0 from λ3) instead of the correct chunk T4 (inter-dimensional distance 1 from λ3).
Model results
The results of the model performance from 30 runs and model parameters can be found in Fig. 2 and Table 3, respectively. The model (Fig. 2A, dashed lines) captures the overall performance difference between the tasks. One major deviation is in probability of correct response where the model exhibits the U-shape profile in the length task while participants do not.Footnote 9 In response time, the model captures the end effect in both tasks exhibiting reversed U-shape function.
With respect to the end and congruity effects, we can assess whether the model reproduces the effects that are found for both tasks in accuracy and latency. With respect to latency, the model matches all the results – end effects for both time and length but a congruity effect only for time. For accuracy, the major discrepancy arises from the fact that participants do not show a rise in accuracy for length 4 stimuli (see Fig. 2A) whereas the model predicts such an effect. The model predicts a rise because the same amount of noise in the length perception was applied to all four stimuli and end stimuli have the advantage of errors only occurring to one side. This results in a prediction of an end effect for length stimuli in Fig. 2B and a prediction of higher overall accuracy for length stimuli in Fig. 2C. Over the eight retrieval conditions (Table 1 ), the model’s accuracy has a .93 correlation with participants’ accuracy and the model’s latency has a .98 correlation with participants’ latency.
The latency measure includes not only the time during which the model was engaged in memory retrieval but also the time during which extra activities such as response preparation took place. We measured the times during which different modules in the model were engaged in each trial. Figure 5 plots mean engagement times in five ACT-R modules (primary y-axis) and the LIPFC activation (secondary y-axis) in different retrieval conditions. As expected, the declarative module’s engagement time is positively correlated with the LIPFC activity (correlation r = .83, p = .011).Footnote 10 The only other module whose activity is significantly correlated with LIPFC is the procedural module (r = .82, p = .012) that selects and executes a check production for each additional memory retrieval. The motor module (mean: 191 ms) is engaged when the model makes a keypress response at the end of each trial. In about 75 % of the total trials in which the model makes a different response from a preceding trial, the motor response takes 200 ms. In the rest of the trials where the model repeats the previous response, the response takes shorter (150 ms) because no new finger movement is programmed. The visual module (mean: 220 ms) is engaged when the model encodes sample stimulus (85 ms) and prompt stimulus (85 ms) and when it is cleared at the end of each trial (50 ms). The imaginal module takes 200 ms for creating a chunk to store task and stimulus information in each trial. The motor, visual, and imaginal modules show almost constant engagements times across retrieval conditions.Footnote 11 The overall results show that only those modules whose activities are directly involved in memory retrieval significantly correlate with the LIPFC activity.

The engagement times of five modules (primary y-axis) and LIPFC activation (secondary y-axis) in the retrieval conditions
We fit the retrieval time to each individual subject and estimated for each an intercept and a slope. According to the ACT-R model, LIPFC activity should be proportional to retrieval time. Because the relationship is proportional, it predicts that when we regress activation on retrieval time the intercept should be zero. While a t-test indicated that the mean intercept was not significantly different from zero (t(25) = -1.54, p = .134), the Scaled JZS Bayes factor (Rouder, Speckman, Sun, Morey, & Iverson, 2009) was 1.37 (scale r = .5) which was not strong enough to favor the null hypothesis. The slope was significantly positive as predicted (t(25) = 2.94, p < .01, Scaled JZS Bayes factor = 6.82).
Discussion
The current study investigated the mechanisms of the end effect and the congruity effect in time and length identification. The response time profile exhibited the inverse-U shape in both tasks, consistent with the end effect in absolute identification (e.g., Lacouture et al., 2001; Petrov & Anderson, 2005; Weber et al., 1977). Consistent with the cross-dimensional interference (e.g., Dormal & Pesenti, 2007; Xuan et al., 2007) and the Stroop effect (Stroop, 1935), participants performed worse when task-relevant information and task-irrelevant information conflicted than when they matched.
The imaging results showed that the LIPFC region responded to both position and congruity manipulations. The greater LIPFC response to the middle stimuli aligns with the view that the end effect arises because of interference from adjacent stimuli (Petrov & Anderson, 2005; Stewart et al., 2005). The LIPFC response was also greater in the incongruent condition. Frontal involvement in the Stroop task (Carter et al., 1995; Pardo et al., 1990; Taylor et al., 1997) has been associated with cognitive control (Drewe, 1975; MacDonald, Cohen, Stenger, & Carter, 2000) and monitoring goal-relevant representation (Wagner, Maril, Bjork, & Schacter, 2001). Based on the view that the LIPFC region reflects the demand for controlled memory retrieval (Danker et al., 2008; Sohn et al., 2003; Sohn et al., 2005), we argue that this region exerted a greater control for retrieving information relevant to the current context in the presence of context-irrelevant information such as neighboring stimuli and task-irrelevant stimulus dimension.
To test whether these effects are consistent with general principles of memory, we modeled them in the ACT-R architecture. The ACT-R model predicted greater memory retrieval demands in the middle and incongruent conditions based on the assumption that spreading activation from context-irrelevant information biases retrieval of context-relevant information. The model also produced retrieval time estimates that positively correlated with the LIPFC response. The modeling results support the mapping between memory retrieval and the LIPFC region established in previous studies (e.g., Anderson et al., 2003), and further extends this mapping to memory in the psychophysical domain, supporting the claim that the ACT-R declarative memory mechanism is domain general (Danker et al., 2008).
The spreading activation mechanism has accounted for various context effects in memory research outside the time estimation domain. For example, it accounts for the fan effect (Anderson, 1974) which refers to a phenomenon that as the number of facts associated with a particular concept increases, participants take a longer time to retrieve a fact about the concept. We showed that the memory mechanism developed and validated outside the time estimation domain could explain context effects in temporal and spatial dimensions. The modeling results also provide comparisons between temporal and non-temporal memory, which could contribute to answering a question of whether temporal memory involves special mechanisms.
Limitations and future directions
We discuss two major limitations of the current study that should be considered when interpreting our results. First, one cannot rule out an alternative explanation that our imaging results may reflect time-on-task effects rather than memory retrieval demand. While there is some evidence (Danker, 2010) that effects in our LIPFC region do not simply reflect time-on-task, but specifically reflect memory retrieval time, this claim needs further investigation. Second, our modeling results do not allow one to map LIPFC exclusively with the declarative module. There is a high correlation between declarative and procedural modules’ engagement times. In addition, the zero-intercept results on LIPFC provide a fairly weak support for the null hypothesis. These limitations need to be addressed in future research by dissociating task difficulty and memory retrieval demand, and revising the cognitive model.
While the current research focused on the end effect and congruity effect, there are several other aspects of absolute identification the model can potentially account for. First, the set size effect refers to the decrease in accuracy and increase in latency as the number of items to identify increases. The set size effect has been shown in both temporal (Lacouture et al., 2001) and non-temporal dimensions (Kent & Lamberts, 2005; Lacouture & Marley, 1995). We predict that the spreading activation mechanism can account for the set size effect. As the set size increases, there would be greater competition among the candidate chunks during retrieval, which would result in lower performance. Second, studies on absolute identification (Brown et al., 2005; Ward & Lockhead, 1970) have shown that response in the current trial tends to be assimilated with the stimulus from the most recent trial. It has also been found that feedback influences sequential dependencies of the current response on the immediately preceding stimulus versus the immediately preceding response (Mori & Ward, 1995). This assimilative sequential effect can be modeled by the blending mechanism in ACT-R (Lebiere, Gonzalez, & Martin, 2007). The blending mechanism allows retrieval of an aggregation of a set of related facts instead of a single fact, and has been used to model sequential effects in time estimation (Moon & Anderson, 2013; Taatgen & Van Rijn, 2011). One could also incorporate feedback evaluation process to the model and test its predictions on sequential dependencies.
Conclusion
We investigated two context effects present in temporal and non-temporal identification and tested whether both could be captured by common principles developed outside the time estimation domain. The results suggest that the current approach along with previous efforts in modeling temporal phenomena in cognitive architecture (Moon & Anderson, 2013; Taatgen & Van Rijn, 2011) can be used for investigating a wide range of context effects in the temporal domain. By modeling context effects in both temporal and non-temporal domains, one can answer whether principles developed outside the temporal domain apply to understanding context effects in time. We argue that domain general principles can provide a better understanding of some phenomena in temporal memory.
Notes
Four outlier participants with LIPFC response more than three times the interquartile range above the third quartile or below the first quartile were excluded from the analysis.
The following equations describe how the initial (t0) and the nth (tn) pulse lengths are computed: t 0 = start + ε1, t n = a*t n-1 + ε2 (start: value of the :time-master-start-increment parameter, a: value of the time-mult parameter, b: value of the time-noise parameter. ε1: noise generated with the act-r-noise command with an s (scale parameter of logistic distribution) of b*5*start, ε2: noise generated with the act-r-noise command with an s of b*a*tn-1).
The model is available at the publication page of the ACT-R website (act-r.psy.cmu.edu/publication/) under the title of this paper.
Source activation of the imaginal buffer (:imaginal-activation = 1.0) divided by the number of retrieval cues.
The check-dimension production is based on a strategy adopted in the model of the Stroop task (Lovett, 2005). The Stroop model occasionally checks whether the processed dimension matches the instructed dimension. In this model, a prepotent dimension (word-association) is automatically processed, and this leads to errors in incongruent trials unless the model corrects its response by checking the task dimension. Without the check-dimension production, the current model predicts lower accuracy and shorter response times in the time task because it occasionally responds based on the length dimension.
The arrows in Fig. 4 represent possible paths of the model before it makes a response. After the retrieve-response production fires, either of the check-dimension, check-estimate, and respond productions can fire depending on the retrieval outcome. After the check-dimension production fires, either check-estimate or respond production can fire. After the check-estimate production fires, either the check-estimate production fires again (if the retrieved chunk still does not match the estimate), or the respond production fires. After either check-dimension or check-estimate production fires (both productions restrict retrieval to the chunks in the relevant dimension), the check-dimension production cannot fire any more because the subsequently retrieved chunk is in the relevant dimension.
In the Stroop model (Lovett, 2005), word-association chunks were set to have higher base-level activation than color-association chunks reflecting greater prior practice at retrieving word-related information.
Most of the errors (90 % in the time task, 95 % in the length task) made by participants were over/underestimation by 1.
With the same amount of random noise applied to estimated length regardless of stimulus position, the accuracy profile exhibits the U-shape profile typically found with psychologically spaced stimuli (e.g., Stewart et al., 2005). In contrast, temporal noise increases with stimulus duration in ACT-R by default, which allows the model to capture the performance decrement with stimulus duration without additional assumptions.
We also performed the correlation analysis on four brain regions associated with the modules in Fig. 5. The correlations with retrieval time were .01 (p = .981) for fusiform (Talairach coordinates x = ±41, y = −61, z = −9; associated with visual module), .34 (p = .4) for motor (±42, −20, 50; manual), .59 (p = .123) for parietal (±24, -63, 40; imaginal), and .68 (p = .062) for caudate (±13, 10, 7; procedural).
The engagement times in the visual and imaginal modules were constant, and thus correlation is not available. The correlation between the motor module and LIPFC was not significant yet negative (r = −.45, p = .258) because response frequency varied across stimulus positions.
References
Anderson, J. R. (1974). Retrieval of propositional information from long-term memory. Cognitive Psychology, 5, 451–474.
Anderson, J. R., Bothell, D., Byrne, M. D., Douglass, S., Lebiere, C., & Qin, Y. L. (2004). An integrated theory of the mind. Psychological Review, 111(4), 1036–1060.
Anderson, J. R., Fincham, J. M., Qin, Y., & Stocco, A. (2008). A central circuit of the mind. Trends in Cognitive Sciences, 12(4), 136–143.
Anderson, J. R., Qin, Y. L., Sohn, M. H., Stenger, V. A., & Carter, C. S. (2003). An information-processing model of the BOLD response in symbol manipulation tasks. Psychonomic Bulletin & Review, 10(2), 241–261.
Ansari, D., Fugelsang, J. A., Dhital, B., & Venkatraman, V. (2006). Dissociating response conflict from numerical magnitude processing in the brain: An event-related fMRI study. NeuroImage, 32(2), 799–805.
Baudouin, A., Vanneste, S., Pouthas, V., & Isingrini, M. (2006). Age-related changes in duration reproduction: Involvement of working memory processes. Brain and Cognition, 62(1), 17–23.
Bench, C. J., Frith, C. D., Grasby, P. M., Friston, K. J., Paulesu, E., Frackowiak, R. S. J., & Dolan, R. J. (1993). Investigations of the functional anatomy of attention using the Stroop test. Neuropsychologia, 31(9), 907–922.
Berliner, J. E., & Durlach, N. I. (1973). Intensity perception. IV. Resolution in roving-level discrimination. The Journal of the Acoustical Society of America, 53(5), 1270–1287.
Birnbaum, M. H., & Jou, J.-W. (1990). A theory of comparative response times and “difference” judgments. Cognitive Psychology, 22(2), 184–210. doi:10.1016/0010-0285(90)90015-V
Borst, J. P., & Anderson, J. R. (2014). Using the ACT-R cognitive architecture in combination with fMRI data. In B. U. Forstmann & E.-J. Wagenmakers (Eds.), An introduction to model-based cognitive neuroscience. New York: Springer.
Brown, S. W. (1997). Attentional resources in timing: Interference effects in concurrent temporal and nontemporal working memory tasks. Perception & Psychophysics, 59(7), 1118–1140.
Brown, G. D. A., McCormack, T., Smith, M., & Stewart, N. (2005). Identification and bisection of temporal durations and tone frequencies: Common models for temporal and nontemporal stimuli. Journal of Experimental Psychology: Human Perception and Performance, 31(5), 919–938.
Bunge, S. A., Ochsner, K. N., Desmond, J. E., Glover, G. H., & Gabrieli, J. D. (2001). Prefrontal regions involved in keeping information in and out of mind. Brain, 124(10), 2074–2086.
Carter, C. S., Mintun, M., & Cohen, J. D. (1995). Interference and facilitation effects during selective attention: An H2 15O PET study of Stroop task performance. NeuroImage, 2(4), 264–272.
Cohen, J. D., Braver, T. S., & O’Reilly, R. C. (1996). A computational approach to prefrontal cortex, cognitive control and schizophrenia: Recent developments and current challenges. Philosophical Transactions of the Royal Society, B: Biological Sciences, 351(1346), 1515–1527.
Cox, R. W. (1996). AFNI: Software for analysis and visualization of functional magnetic resonance neuroimages. Computers and Biomedical Research, 29(3), 162–173.
Cox, R. W., & Hyde, J. S. (1997). Software tools for analysis and visualization of fMRI data. NMR in Biomedicine, 10(4–5), 171–178.
Danker, J. F. (2010). Left ventrolateral prefrontal cortex activity during retrieval reflects the difficulty of accessing information in memory (Unpublished doctoral dissertation). Carnegie Mellon University, Pittsburgh, PA.
Danker, J. F., Gunn, P., & Anderson, J. R. (2008). A rational account of memory predicts left prefrontal activation during controlled retrieval. Cerebral Cortex, 18(11), 2674–2685.
Dehaene, S., Bossini, S., & Giraux, P. (1993). The mental representation of parity and number magnitude. Journal of Experimental Psychology: General, 122(3), 371–396.
D'Esposito, M., Aguirre, G. K., Zarahn, E., Ballard, D., Shin, R. K., & Lease, J. (1998). Functional MRI studies of spatial and nonspatial working memory. Cognitive Brain Research, 7(1), 1–13.
Dobbins, I. G., & Wagner, A. D. (2005). Domain-general and domain-sensitive prefrontal mechanisms for recollecting events and detecting novelty. Cerebral Cortex, 15, 1768–1778. doi:10.1093/cercor/bhi054
Dormal, V., & Pesenti, M. (2007). Numerosity-length interference: A Stroop experiment. Experimental Psychology, 54(4), 289.
Drewe, E. A. (1975). Go-no go learning after frontal lobe lesions in humans. Cortex, 11(1), 8–16.
Droit-Volet, S., Wearden, J., & Delgado-Yonger, M. (2007). Short-term memory for time in children and adults: A behavioral study and a model. Journal of Experimental Child Psychology, 97(4), 246–264. doi:10.1016/j.jecp.2007.02.003
Elvevåg, B., Brown, G. D. A., McCormack, T., Vousden, J. I., & Goldberg, T. E. (2004). Identification of tone duration, line length, and letter position: An experimental approach to timing and working memory deficits in schizophrenia. Journal of Abnormal Psychology, 113(4), 509–521. doi:10.1037/0021-843X.113.4.509
Funahashi, S., Bruce, C. J., & Goldman-Rakic, P. S. (1989). Mnemonic coding of visual space in the monkey’s dorsolateral prefrontal cortex. Journal of Neurophysiology, 61, 331–349.
Gibbon, J., Church, R. M., & Meck, W. H. (1984). Scalar timing in memory. Annals of the New York Academy of Sciences, 423(1), 52–77.
Goldman-Rakic, P. S. (1995). Cellular basis of working memory. Neuron, 14, 477–485. doi:10.1016/0896-6273(95)90304-6
Gu, B.-M., & Meck, W. (2011). New perspectives on Vierordt’s law: Memory-mixing in ordinal temporal comparison tasks. Multidisciplinary Aspects of Time and Time Perception, 6789, 67–78.
Harrington, D. L., Haaland, K. Y., & Knight, R. T. (1998). Cortical networks underlying mechanisms of time perception. The Journal of Neuroscience, 18(3), 1085–1095.
Jones, L. A., & Wearden, J. H. (2003). More is not necessarily better: Examining the nature of the temporal reference memory component in timing. The Quarterly Journal of Experimental Psychology. B, Comparative and Physiological Psychology, 56(4), 321–343. doi:10.1080/02724990244000287
Jou, J. (2010). The serial position, distance, and congruity effects of reference point setting in comparative judgments. The American Journal of Psychology, 123(2), 127–136. Retrieved from http://www.ncbi.nlm.nih.gov/pubmed/20518431
Kaufmann, L., Koppelstaetter, F., Delazer, M., Siedentopf, C., Rhomberg, P., Golaszewski, S., Felber, S., & Ischebeck, A. (2005). (2005). Neural correlates of distance and congruity effects in a numerical Stroop task: An event-related fMRI study. NeuroImage, 25(3), 888–898.
Kent, C., & Lamberts, K. (2005). An exemplar account of the bow and set-size effects in absolute identification. Journal of Experimental Psychology. Learning, Memory, and Cognition, 31(2), 289–305. doi:10.1037/0278-7393.31.2.289
Lacouture, Y. (1997). Bow, range, and sequential effects in absolute identification: A response-time analysis. Psychological Research, 60(3), 121–133.
Lacouture, Y., Grondin, S., & Mori, S. (2001). Absolute identification of temporal intervals: Preliminary data. In E. Sommerfeld, R. Kompass, & T. Lachmann (Eds.), Proceedings of the Seventeenth Meeting of the International Society of Psychophysics (pp. 493–498). Berlin, Germany: Pabst Science Publishers.
Lacouture, Y., & Marley, A. A. J. (1995). A mapping model of bow effects in absolute identification. Journal of Mathematical Psychology, 39(4), 383–395. doi:10.1006/jmps.1995.1036
Lebiere, C., Gonzalez, C., & Martin, M. K. (2007). Instance-based decision making model of repeated binary choice. In R. L. Lewis, T. A. Polk, & J. E. Laird (Eds.), Proceedings of the Eighth International Conference on Cognitive Modeling (pp. 67–72), Ann Arbor, MI: University of Michigan
Lejeune, H., & Wearden, J. (2009). Vierordt’s The Experimental Study of the Time Sense (1868) and its legacy. European Journal of Cognitive Psychology, 21(6), 941–960.
Lewis, P. A., & Miall, R. C. (2006). A right hemispheric prefrontal system for cognitive time measurement. Behavioral Processes, 71(2–3), 226–234.
Lovett, M. C. (2005). A strategy-based interpretation of Stroop. Cognitive Science, 29(3), 493–524.
Luce, R. D., Nosofsky, R. M., Green, D. M., & Smith, A. F. (1982). The bow and sequential effects in absolute identification. Perception & Psychophysics, 32(5), 397–408.
MacDonald, A. W., Cohen, J. D., Stenger, V. A., & Carter, C. S. (2000). Dissociating the role of the dorsolateral prefrontal and anterior cingulate cortex in cognitive control. Science, 288(5472), 1835–1838.
Matell, M. S., & Meck, W. H. (2000). Neuropsychological mechanisms of interval timing behavior. Bioessays, 22(1), 94–103.
McCormack, T., Brown, G. D. A., Maylor, E. A., Richardson, L. B. N., & Darby, R. J. (2002). Effects of aging on absolute identification of duration. Psychology and Aging, 17(3), 363–378. Retrieved from http://www.ncbi.nlm.nih.gov/pubmed/12243379
McCormack, T., Brown, G. D. A., Smith, M. C., & Brock, J. (2004). A timing-specific memory distortion effect in young children. Journal of Experimental Child Psychology, 87(1), 33–56.
Mckiernan, K. A., Kaufman, J. N., Kucera-Thompson, J., & Binder, J. R. (2003). A parametric manipulation of factors affecting task-induced deactivation in functional neuroimaging. Journal of Cognitive Neuroscience, 15(3), 394–408.
Miller, E. K., & Cohen, J. D. (2001). An integrative theory of prefrontal cortex function. Annual Review of Neuroscience, 24, 167–202. doi:10.1146/annurev.neuro.24.1.167
Moon, J., & Anderson, J. R. (2013). Timing in multitasking: Memory contamination and time pressure bias. Cognitive Psychology, 67(1–2), 26–54.
Mori, S., & Ward, L. M. (1995). Pure feedback effects in absolute identification. Perception & Psychophysics, 57(7), 1065–1079. Retrieved from http://www.ncbi.nlm.nih.gov/pubmed/8532496
Nystrom, L. E., Braver, T. S., Sabb, F. W., Delgado, M. R., Noll, D. C., & Cohen, J. D. (2000). Working memory for letters, shapes, and locations: fMRI evidence against stimulus-based regional organization in human prefrontal cortex. NeuroImage, 11, 424–446. doi:10.1006/nimg.2000.0572
Ogden, R. S., Wearden, J. H., & Jones, L. A. (2008). The remembrance of times past: Interference in temporal reference memory. Journal of Experimental Psychology. Human Perception and Performance, 34(6), 1524–1544. doi:10.1037/a0010347
Pardo, J. V., Pardo, P. J., Janer, K. W., & Raichle, M. E. (1990). The anterior cingulate cortex mediates processing selection in the Stroop attentional conflict paradigm. Proceedings of the National Academy of Sciences of the United States of America, 87(1), 256–259.
Parducci, A. (1965). Category judgment: A range-frequency model. Psychological Review, 72(6), 407–418. Retrieved from http://www.ncbi.nlm.nih.gov/pubmed/5852241
Petrides, M. (1994). Frontal lobes and behaviour. Current Opinion in Neurobiology. doi:10.1016/0959-4388(94)90074-4
Petrides, M., Alivisatos, B., Evans, A. C., & Meyer, E. (1993). Dissociation of human mid-dorsolateral from posterior dorsolateral frontal-cortex in memory processing. Proceedings of the National Academy of Sciences of the United States of America, 90(3), 873–877.
Petrov, A. A., & Anderson, J. R. (2005). The dynamics of scaling: A memory-based anchor model of category rating and absolute identification. Psychological Review, 112(2), 383–416.
Pouthas, V., George, N., Poline, J. B., Pfeuty, M., VandeMoorteele, P. F., Hugueville, L., Ferrandez, A. M., Lehéricy, S., LeBihan, D., & Renault, B. (2005). Neural network involved in time perception: An fMRI study comparing long and short interval estimation. Human Brain Mapping, 25(4), 433–441.
Rao, S. M., Mayer, A. R., & Harrington, D. L. (2001). The evolution of brain activation during temporal processing. Nature Neuroscience, 4(3), 317–323.
Rao, S. C., Rainer, G., & Miller, E. K. (1997). Integration of what and where in the primate prefrontal cortex. Science, 276, 821–824. doi:10.1126/science.276.5313.821
Rouder, J. N., Speckman, P. L., Sun, D., Morey, R. D., & Iverson, G. (2009). Bayesian t tests for accepting and rejecting the null hypothesis. Psychonomic Bulletin & Review, 16(2), 225–237. doi:10.3758/PBR.16.2.225
Rowe, J. B., & Passingham, R. E. (2001). Working memory for location and time: Activity in prefrontal area 46 relates to selection rather than maintenance in memory. NeuroImage, 14(1), 77–86.
Sohn, M. H., Goode, A., Stenger, V. A., Carter, C. S., & Anderson, J. R. (2003). Competition and representation during memory retrieval: Roles of the prefrontal cortex and the posterior parietal cortex. Proceedings of the National Academy of Sciences of the United States of America, 100(12), 7412–7417.
Sohn, M. H., Goode, A., Stenger, V. A., Jung, K. J., Carter, C. S., & Anderson, J. R. (2005). An information-processing model of three cortical regions: Evidence in episodic memory retrieval. NeuroImage, 25(1), 21–33.
Sreenivas, S., Boehm, S. G., & Linden, D. E. J. (2012). Emotional faces and the default mode network. Neuroscience Letters, 506(2), 229–234.
Staddon, J., & Higa, J. (1999). Time and memory: Towards a pacemaker-free theory of interval timing. Journal of the Experimental Analysis of Behavior, 71(2), 215–251.
Stewart, N., Brown, G. D., & Chater, N. (2005). Absolute identification by relative judgment. Psychological Review, 112(4), 881–911.
Stroop, J. R. (1935). Studies of interference in serial verbal reactions. Journal of Experimental Psychology, 18(6), 643–662.
Taatgen, N., & Van Rijn, H. (2011). Traces of times past: Representations of temporal intervals in memory. Memory & Cognition, 39(8), 1546–1560.
Taatgen, N. A., Van Rijn, H., & Anderson, J. (2007). An integrated theory of prospective time interval estimation: The role of cognition, attention, and learning. Psychological Review, 114(3), 577–598.
Taylor, S. F., Kornblum, S., Lauber, E. J., Minoshima, S., & Koeppe, R. A. (1997). Isolation of specific interference processing in the Stroop task: PET activation studies. NeuroImage, 6(2), 81–92.
Thompson-Schill, S. L., D’Esposito, M., Aguirre, G. K., & Farah, M. J. (1997). Role of left inferior prefrontal cortex in retrieval of semantic knowledge: A reevaluation. Proceedings of the National Academy of Sciences of the United States of America, 94, 14792–14797. doi:10.1073/pnas.94.26.14792
Tregellas, J. R., Davalos, D. B., & Rojas, D. C. (2006). Effect of task difficulty on the functional anatomy of temporal processing. NeuroImage, 32(1), 307–315.
Vallesi, A., Binns, M. A., & Shallice, T. (2008). An effect of spatial-temporal association of response codes: Understanding the cognitive representations of time. Cognition, 107(2), 501–527.
Vicario, C. M., Pecoraro, P., Turriziani, P., Koch, G., Caltagirone, C., & Oliveri, M. (2008). Relativistic compression and expansion of experiential time in the left and right space. PLoS ONE, 3(3), e1716.
Wagner, A. D., Maril, A., Bjork, R. A., & Schacter, D. L. (2001). Prefrontal contributions to executive control: fMRI evidence for functional distinctions within lateral prefrontal cortex. NeuroImage, 14(6), 1337–1347.
Ward, L. M., & Lockhead, G. R. (1970). Sequential effects and memory in category judgments. Journal of Experimental Psychology, 84(1), 27–34.
Wearden, J., & Ferrara, A. (1995). Stimulus spacing effects in temporal bisection by humans. The Quarterly Journal of Experimental Psychology, 48(4), 289–310.
Weber, D. L., Green, D. M., & Luce, R. D. (1977). Effects of practice and distribution of auditory signals on absolute identification. Perception & Psychophysics, 22(3), 223–231.
Xuan, B., Zhang, D., He, S., & Chen, X. C. (2007). Larger stimuli are judged to last longer. Journal of Vision, 7(10), 1–5.
Acknowledgments
This research was supported by National Institute of Mental Health Grant MH068243.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Moon, J., Fincham, J.M., Betts, S. et al. End effects and cross-dimensional interference in identification of time and length: Evidence for a common memory mechanism. Cogn Affect Behav Neurosci 15, 680–695 (2015). https://doi.org/10.3758/s13415-015-0348-5
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13415-015-0348-5