
Abstract
A previous study (Schneider, Daneman, Murphy, & Kwong See, 2000) found that older listeners’ decreased ability to recognize individual words in a noisy auditory background was responsible for most, if not all, of the comprehension difficulties older adults experience when listening to a lecture in a background of unintelligible babble. The present study investigated whether the use of a more intelligible distracter (a competing lecture) might reveal an increased susceptibility to distraction in older adults. The results from Experiments 1 and 2 showed that both normal-hearing and hearing-impaired older adults performed poorer than younger adults when everyone was tested in identical listening situations. However, when the listening situation was individually adjusted to compensate for age-related differences in the ability to recognize individual words in noise, age-related difference in comprehension disappeared. Experiment 3 compared the masking effects of a single-talker competing lecture to a babble of 12 voices directly after adjusting for word recognition. The results showed that the competing lecture interfered more than did the babble for both younger and older listeners. Interestingly, an increase in the level of noise had a deleterious effect on listening when the distractor was babble but had no effect when it was a competing lecture. These findings indicated that the speech comprehension difficulties of healthy older adults in noisy backgrounds primarily reflect age-related declines in the ability to recognize individual words.
Similar content being viewed by others


Introduction
Conducting a conversation in everyday situations often is quite challenging both perceptually and cognitively. For example, imagine that you have arranged to have lunch with your nephew who has been out of the country for 3 years. Both of you are interested in catching up on what each other has been doing. When you arrive at the restaurant just shortly before noon, there is music playing in the background, and the waiter seats you at a table with a good view but one that is near the air conditioner. Hence, the background noise level makes it somewhat difficult to hear one another. Unfortunately, just shortly after you are seated, the regular noonday patrons begin to arrive, and soon the multiple conversations that ensue create a babble of voices. Finally, to make matters worse, a member of the company you work for, who doesn’t know you, is seated at the table next to you and begins to talk with his lunch partner about impending layoffs at your firm. As a result, you and your nephew have to raise your voices to be heard, and both of you find it increasingly difficult to follow, comprehend, and digest what the other is saying. As a result, you miss much of what your nephew said, and your lack of understanding makes the conversation both difficult and uncomfortable.
The preceding scenario illustrates how competing sound sources—the air conditioner, a babble of voices, and a single person talking—can interfere with communication and social interaction in our everyday life, and this may be especially exacerbated for an older person. All three of these sound sources present a perceptual challenge to the extent that the energy in them overlaps that of the target voice both temporally and spectrally. This kind of interference, in which the competing sound sources simultaneously activate overlapping regions along the basilar membrane of the inner ear, thereby overwhelming the signal, often is referred to as energetic masking. Competing sound sources, in addition to producing energetic masking, also can interfere with comprehending the target speech at levels beyond the periphery. For example, the babble of background voices, in addition to energetically masking the speech target, could elicit phonemic activity. This competing activation could make it more difficult to access the meaning of the words in the target speech. Because this interference is occurring after basilar membrane processing of the auditory input, it is classified as informational interference or informational masking (Durlach et al., 2003). In contrast, because a steady-state noise is unlikely to elicit any lexical activity, its effects on performance are considered to be primarily energetic.
Informational masking can also occur when the speech target is being processed at higher-level linguistic and cognitive levels. For example, the overheard conversation at the other table could compete with your nephew’s voice for your attention. Hence, any sound that competes with the speech signal for a listener’s attention could interfere with the processing of the speech signal because of the demands it places on working memory resources. All simultaneously presented competing sounds will energetically mask the speech signal. In addition, any competing sound that elicits linguistic activity, or diverts attention from the target speech, is likely to produce informational masking. We investigated the extent to which two types of informational maskers—multi-talker babble versus a single competing talker—interfere with a listener’s ability to comprehend spoken language and whether there any age differences with respect to the degree of interference produced by these two types of maskers.
These two types of maskers (babble vs. competing talker), in addition to energetically masking the speech target, are likely to produce different amounts of informational masking. Because individual words are not, in general, recognizable in multi-talker babble, the degree of informational interference is likely to be considerably less than that produced when the masker is single-talker intelligible speech. In the latter case, the competing signal is much more likely to compete with the target speech for the listener’s attention, and initiate higher-order, post-lexical processing of the competing speech. For instance, when the language of the competing talker is understood by the listener, it produces a greater degree of interference with speech recognition, comprehension, and memory than when the competing speech is in a language foreign to a listener (Tun, O’Kane, & Wingfield, 2002; Rhebergen., Versfeld,, & Wouter, 2005; Van Engen & Bradlow, 2007; Van Engen, 2010; Brouwer, Van Engen, Calandruccio, & Bradlow, 2012). It also is the case that competing speech in the same language is a less effective masker when it is heavily accented than when it is not (Calandruccio, Dhar, & Bradlow, 2010). Because competing speech in the listener’s native language is more likely to compete for her or his attention than a multi-talker babble, and because it is likely to elicit competing activity at higher levels of linguistic and cognitive processing, it is a more potent informational masker than a babble of unintelligible voices.
Another factor that is likely to increase the potency of a competing speech masker is the acoustic similarity between the target voice and the competing voice. For example, Humes, Lee, and Coughlin (2006) have shown that informational masking is greater when the competing talker is of the same gender as the target talker. In addition, a number of studies have shown that informational masking effects are maximal when the speech target and the competing speech appear to originate from the same point in space (Freyman, Helfer, McCall, & Clifton, 1999; Freyman, Balakrishnan, & Helfer, 2001). Li, Daneman, Qi, & Schneider (2004) investigated the degree to which spatially separating a target sentence from two competing sentences provided a release from masking and found that younger and older adults reaped the same benefit from spatial separation. To investigate whether there were age differences when the acoustic similarity between masker and target sentences was increased, Agus, Akeroyd, Gatehouse, and Warden (2009) had both target and masker sentences spoken by the same person. These investigators found that younger and older adults benefited to the same degree when the informational content of the competing sentence was reduced by replacing the competing sentence with an amplitude modulated noise having the same amplitude envelope as the sentence, but being unintelligible. Hence these two studies suggest that when sentence level material is used, the amount of informational masking is the same for younger and older adults (for a review of informational masking of speech by speech using sentence level material, see Schneider, Li, & Daneman, 2007; Schneider, Pichora-Fuller, & Daneman, 2010).
While there have been many studies of how various types of maskers affect the recognition and comprehension of single words and short sentences (Humes, Kidd, & Lentz, 2013; Schneider, Pichora-Fuller, & Daneman, 2010), relatively little is known about the effects of babble and competing speech on the comprehension of the kinds of complex and extended spoken discourse that are encountered in everyday situations. To ensure greater ecological validity, in this study the target speech consisted of lengthy lectures (8-13 minutes in length) on familiar topics (e.g., careers, food, speech making), and the masker was either the same kind of lengthy lecture, or 12-talker babble. To maximize the degree of informational masking in this study, both the target lecture and competing lecture were in the same voice and were presented over the same earphone.
Schneider et al. (2000) investigated whether there were age-related differences in comprehending lengthy lectures in a background of 12-talker babble and whether these differences reflected age-related declines in hearing or cognition. They asked normal-hearing younger and older listeners and hearing-impaired older listeners to answer questions concerning the content of lectures (8-13 minutes in length) either in quiet or a background of 12-talker babble. Some of the questions were about the specific details of the lecture, and some were more integrative and general. To determine the effect of hearing capacity on performance, in one experiment the signal level and babble level were individually adjusted to ensure that each participant was equally likely to hear individual words without the help of context (hereafter referred to as recognition of the individual words being spoken), whereas in another experiment no adjustment was made, so both the target lecture and babble distractor were presented at the same levels to all listeners. The results showed that when target levels and signal-to-noise ratios (SNRs) were individually adjusted in both younger and older adults to make it equally difficult for all individuals to recognize the individual words, good-hearing younger and older adults, as well as hearing-impaired older adults, were equally adept at answering questions when the lectures were presented either in quiet or in a background babble. However, when no adjustments were made, neither older group could recall as many details of the lectures as their younger counterparts did. The study suggested that older adults can perform as well as younger adults in listening comprehension tasks even when the target listening materials are relatively complex, as long as they can hear the individual words comprising the lecture as well as can their younger counterparts. However, when older listeners’ ability to recognize individual words is impaired for any reason, their ability to comprehend speech will be compromised.
In Schneider et al. (2000), the masker was unintelligible 12-talker babble, in which individual words were largely unrecognizable, and both the spectrum of the babble masker and its amplitude envelope differed substantially from that of the lecturer’s voice. This naturally raised the question as to whether age differences would emerge if a more meaningful and acoustically similar distractor was used as a masker. Older adults could be more distracted by complex and meaningful competing stimuli than are younger adults because of age-related declines in inhibitory control. A number of studies have shown that aging is associated with a reduced ability to ignore irrelevant information that is presented visually (Hasher & Zacks, 1988; Lustig, Hasher, & Zacks, 2007) or aurally (Bell, Buchner, & Mund, 2008). In a typical reading-with-distraction experiment (Carlson, Hasher, Zacks, & Connelly, 1995; Connelly, Hasher, & Zacks, 1991; Darowski, Helder, Zacks, Hasher, & Hambrick, 2008; Dywan & Murphy, 1996; Kim, Hasher, & Zacks, 2007), younger and older participants are required to read short prose passages out loud, while distracting words are interspersed into the text with a distinct font style (upright font) different from the target words (italic font). The participants’ task is to attend only to the target texts and ignore the distractor. It is usually found that older adults’ reading speed is disproportionately slowed down by the distracting words than is that of their younger counterparts compared with baseline (reading with no distracting words), and older adults are less likely to correctly recall or identify aspects of the target passage.
However, few of the studies that have claimed that older adults are more susceptible to informationally complex distractors took age-related sensory decline into consideration. Indeed, previous studies have indicated that age-related declines in spoken word recognition are responsible for most—if not all—of older adults’ difficulty in hearing in noise (Avivi-Reich, Daneman, & Schneider, 2014; Divenyi & Haupt, 1997a, 1997b; Helfer & Wilber, 1990; Humes & Christopherson, 1991; Humes & Roberts, 1990; Jerger, Jerger, & Pirozzolo, 1991; McCoy et al., 2005; Murphy, Daneman, & Schneider, 2006; Murphy, McDowd, & Wilcox, 1999; van Rooij, Plomp, & Orlebeke, 1989). Therefore, in the present study we used the same procedure as in Schneider et al. (2000) to adjust individually the listening situation (by manipulating the target level and the SNR), so that both younger and older adults were equally likely to recognize the individual words being spoken. We hypothesize that if comprehension in older adults is primarily limited by their inability to recognize the individual words being spoken, age difference should be minimized if not eliminated in the present task when age-related differences in word recognition are no longer a factor, even though the distractor in the present study is acoustically similar to the target and semantically meaningful. However, it has been argued that older adults are less able to inhibit the processing of irrelevant but meaningful information (e.g., the inhibitory deficit hypothesis; Hasher & Zacks, 1988). Consequently, adjusting for differences in speech recognition may not be sufficient to eliminate age differences in comprehending lectures when there is a competing meaningful distractor.
Experiments 1 and 2 adopted the same paradigm and lecture listening materials as in Schneider et al. (2000), except that instead of 12-talker babble, another lecture, spoken by the same person, was used as the masker, with both lectures presented monaurally to the right ear. We used the same voice for both the target and distracting lectures to maximize the amount of informational masking. The greater the similarity in voices, the more difficult it should be to inhibit the processing of irrelevant information. Hence, the use of the same voice for both target and masker should enhance the effects of any inhibitory deficit in older normal-hearing and hearing-impaired adults.
The difference between the two experiments was that in Experiment 1, all participants were tested in identical listening situations (same signal level and same SNR for everyone), whereas in Experiment 2 the signal level and SNR were individually adjusted to equate for individual differences in word recognition, so that every participant was equally capable of recognizing the individual words being spoken. The logic motivating Experiments 1 and 2 is as follows. If age differences in listening comprehension are largely attributable to the greater difficulty that older listeners have in hearing individual words in noise, we might expect large age differences in comprehending lectures when there is an informationally complex competing background (another lecture in the same voice) as in Experiment 1. However, these should be eliminated or reduced in Experiment 2 when we experimentally equate all individuals with respect to spoken word recognition. This would replicate the results of Schneider et al. (2000) where the competing sound source was unintelligible babble. If, on the other hand, group differences persisted after experimentally adjusting for individual and group differences in spoken word recognition in Experiment 2, we would have to conclude that age-related changes in spoken word recognition cannot account for all of the age-related differences in comprehending spoken language when there is competing speech in the background. Experiment 3 directly compared the distracting effects of single-talker competing speech and 12-talker babble after adjusting for individual differences in word recognition. This experiment allowed us to calibrate the relative amount of interferences produced by these two maskers, again after equating for word recognition. We expected that a competing lecture would have a more deleterious effect on comprehension than competing babble when presented at comparable SNRs.
Experiment 1
In Experiment 1, normal-hearing younger and older adults and hearing-impaired older adults listened to target lectures presented with a meaningful competing lecture played in the background.Footnote 1 Both the target and distractor were played monaurally to the right ear over a headphone. Immediately following each lecture, participants answered detail and integrative questions concerning the target lecture. The levels of the target and competing lectures were set to 62 and 69 dB SPL, respectively, for all listeners. Based on Schneider et al.’s (2000) study with babble as a masker, we would expect to find age-related differences in comprehension performance when there is no control for age-related difference in spoken word recognition.
Method
Participants
The participants in Experiment 1 consisted of 18 normal-hearing younger adults (6 males), 18 older adults (5 males) with normal hearing for their age, and 18 older adults (11 males) with mild-to-moderate hearing loss. Older normal-hearing participants were required to have a pure tone threshold of 25 dB HL or lower from 0.25 to 3 kHz, with balanced hearing in the two ears (≤15-dB difference between ears at these frequencies). Older adults with audiometric thresholds in this range are usually considered to have normal hearing for their age (ISO 7029-2000) and are referred to in this paper as normal-hearing older adults. In contrast, none of the participants in the hearing impaired group met the audiometric hearing criteria stated above and had hearing thresholds ≥ 30 dB HL at one or more frequencies between 0.25 and 3 kHz. The ages and years of education of all participants appear in Table 1, along with those of the participants in Experiments 2 and 3. A three-group (Young, Normal-Hearing Old, and Hearing-Impaired Old) by three-experiment (1, 2, and 3) between-subjects ANOVA failed to reveal any effect of Group (F[2,132] < 1), Experiment (F[2, 132] < 1), or Group X Experiment interaction (F[3,132] < 1) on Years of Education. Hence there is no indication that Years of Education differed across Groups or Experiments. However, a two-group (Normal-Hearing Old, and Hearing-Impaired Old) by three-experiment (1, 2, and 3) between-subjects ANOVA on the participants’ age found a significant effect of group (F[1.83] = 25.27, p < 0.001, ηp 2 = 0.233) but no signficant effect of Experiment (F[2,83] < 1) or Experiment X Group interaction (F[1,83] = 2.98, p = 0.088, ηp 2 = 0.033). Hence, the participants in the older hearing-impaired group were significantly older than those in the older normal-hearing group.
The younger adults were students from the University of Toronto Mississauga. They participated in the study to fulfill a course requirement or were paid $10/hour compensation. All the older adults were volunteers from the local community, and each of them was paid $10/hour for participating. Only participants who reported that they were in good health and had no history of serious pathology (e.g., stroke, head injury, neurological disease, seizures) were included in the study, and they were all fluent English speakers.Footnote 2
Auditory measures
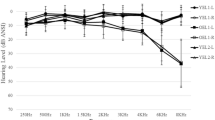
All of the younger and normal hearing older participants in Experiment 1 had pure-tone, air-conduction thresholds ≤25 dB HL between 0.25 and 3 kHz (ANSI S3.6-1996) in both ears, with the interaural difference ≤15 dB between 0.25 and 3 kHz, and the older participants had normal hearing for their age (International Organization for Standardization [ISO] 7029-2000, ISO 2000). In contrast, none of the participant in the hearing impaired groups met the audiometric hearing criteria stated above. All had hearing thresholds ≥30 dB HL in at least one frequency level between 0.25 and 3 kHz, with HLs ≤60 dB for frequencies ≤2 kHz, and ≤70 dB at 3 kHz. None of these individuals wore hearing aids or had a history of hearing disorders or hearing diseases. The audiometric hearing thresholds of the three different groups, averaged across both ears, are presented in Fig. 1.

Cognitive measures
Vocabulary
Participants were given the Mill Hill Vocabulary Scale (Raven, 1965) to assess their vocabulary knowledge. In this 20-item synonym test, participants matched each test item with its closest synonym from a list of six alternatives (maximum score = 20). The average scores on this test are presented in Table 1, along with the scores of the individuals in the other two experiments.
Reading comprehension skill
All participants were administered the Nelson-Denny test of reading comprehension (Brown, Bennett, & Hanna, 1981). Participants had to read 8 short passages, and answer 36 multiple-choice questions on them. They were given 20 minutes to complete the test. Participants were given a reading comprehension score based on the number of questions answered correctly (maximum score = 36). One older hearing-impaired participant in Experiment 2 did not complete this test because this person had to leave early for an appointment. The scores of the different groups of participants on this reading comprehension test are also presented in Table 1.
Working memory span
The Reading Span test (Daneman & Carpenter, 1980) was used to assess participants’ working memory capacity. In this task, participants were presented with progressively longer sets of unrelated sentences on a computer screen. Set size ranged from 2 to 5 sentences, with 5 sets at each size for a total of 70 sentences, and the sentences were presented on the screen one by one. Set sizes were presented in ascending order. The participant’s task was to read each sentence out loud, and memorize the last word of each sentence for immediate recall at the end of the set. The total number of correctly recalled last words was used as the participant’s working memory span (maximum score = 70). One older hearing-impaired participant in Experiment 2 did not complete this test because of difficulty in reading the sentences, and another older normal-hearing participant in Experiment 3 also did not complete the test because she was not feeling well. The average scores of the different groups of participants on this working memory test are presented in Table 1, along with those of Experiments 2 and 3.
To evaluate whether there were any differences among the samples in the three different experiments, separate three-group (Young, Normal-Hearing Old, and Hearing-Impaired Old) by three-experiment (1, 2, and 3) between-subjects ANOVAs were conducted on each of these variables. There were no significant effects of Experiment, nor significant Experiment X Group interactions for Nelson-Denny scores (Experiment: F[2, 131] < 1; Group X Experiment: F[3, 131] = 1.12, p = 0.345, ηp 2 = 0.025); Working Memory Scores (Experiment: F[2, 130] < 1; Group X Experiment: F[3, 130] = 1.92, p = 0.130, ηp 2 = 0.042); or Mill Hill Vocabulary (Experiment: F[2,132] = 1.21, p = 0.303, ηp 2 = 0.018; Group X Experiment: F[3,132] < 1). However, there were significant Group Main Effects for Nelson-Denny scores (F[2, 131] = 17.79, p < 0.001, ηp 2 = 0.214); Working-Memory Scores (F[2, 130] = 16.067, p < 0.001, ηp 2 = 0.198); and Mill-Hill scores (F[2, 132] = 9.05, p < 0.001, ηp 2 = 0.121). Significant differences among the three groups for these three cognitive tests (LSD post hoc tests were used) are indicated in Table 1. Hence, there is no evidence that there were any differences across Experiments with respect to these three cognitive measures nor any evidence of Group by Experiment interactions. Normal-hearing younger participants had significantly higher reading span and working memory scores than did older normal-hearing participants, who, in turn, had significantly higher scores than older, hearing-impaired participants. By way of contrast, both older groups had equivalent vocabulary scores that were higher than those of the younger group.
Listening comprehension task
Materials and apparatus
We used the same six lectures as in Schneider et al. (2000). The lectures were chosen from Efficient Reading (Brown, 1984) and were recorded by a male actor at a sampling rate of 24,414 Hz. The six lecture topics were (a) “Your voice gives you away”; (b) “Of happiness and despair we have no measure”; (c) “Mark Twain's speech making strategy”; (d) “Feeding the mind”; (e) “Ten tips to help you write better”; and (f) “Which career is the right one for you.” The lectures were 8 to 17 minutes in length (mean: 13.2 minutes) and were read at a speaking rate of approximately 120 words/min.
Digital recordings of these lectures were converted to voltages using the Tucker Davis (DD1) digital-to-analog converter. We used programmable attenuators (Tucker Davis PA4) to set the target lecture level and the SNR between target lecture and competing lecture. After passing through the attenuators, target and competing lectures (or babble) were added together and presented to the participants over the right side of a calibrated set of Sennheiser HD265 headphones within a double-walled sound-attenuating chamber whose background noise was <20 dB SPL. Earphones were calibrated using Brüel & Kjær Head and Torso simulator (Type 4218 C) and Portable PULSE system (Type 3560 C).
Procedure
Stimuli were presented monaurally over the right headphone with the competing lecture beginning 5 s after the target lecture. Immediately following each lecture, participants were asked to answer 10 multiple-choice questions (4 alternatives per question) about it. The questions were presented in written form. Five were detail questions concerning a specific item of information that was mentioned explicitly once during the lecture. For example, one of the detail questions from "Which career is the right one for you" was "The job of bookkeeper is classed as (a) a social job; (b) a realistic job; (c) a conventional job; or (d) an investigative job." Five were integrative questions which required the listener to identify or infer the overall gist of the lecture. For example, an integrative question concerning the same lecture was "The selection is given chiefly to help listeners (a) know the satisfactions of certain types of jobs; (b) know the key characteristics of success; (c) choose a career; or (d) know what interest patterns to note."
In this experiment, the three shortest lectures (mean length = 10.8 minutes) were used as the target lectures, whereas the three longest lectures (mean length = 15.6 minutes) were used as the competing lectures. For each participant, two target lectures were selected from the three shortest lectures and the two competing lectures from the three longest lectures. The nine possible combinations of target and competiting lectures were counterbalanced across the 18 participants in each age group. The target lecture was played to the right ear at 62 dB SPL for all participants; the competing lecture was presented to the right ear as well but 5 s after the target lecture had started, and at a level of 69 dB SPL, for a SNR = −7 dB for everyone. Participants were instructed to pay attention to the lecture which started first and to ignore the lecture that started second. They were warned that the two lectures were spoken by the same person.
After answering questions concerning the second target lecture, participants were asked to answer five detailed questions about the competing lecture, even though the participants had been asked to ignore it in the first place. Because the competing lecture was always longer than the target, it was cut off when the target lecture was finished. Therefore, we only counted the detail questions that could possibly be answered based on the cutoff point (the maximum number of detail questions that were scored ranged from 3-5 out of 5, depending on the particular combination of target and competing lectures). Peformance on this surprise test measured the degree of intrusion of material from the to-be-ignored lecture.
Statistical analyses
Because assumptions concerning homogeneity of variance can be violated when the dependent variable is a percentage, we conducted Levene’s test of the homgeneity assumption in all three experiments. The assumption of homogeneity of variance was rejected (α = 0.05) in only 1 of the 19 cases where it could be tested across the three experiments. Because we would expect 1 rejection out of 20 tests by chance alone, we assumed the homogeneity assumption was met in all of the ANOVAs performed when the dependent variable was percent correct.
With respect to the ANOVAs on the integrative and detail questions about the target stories in Experiments 1, 2, and 3, we also tested the null hypothesis that the observed covariance matrices of the dependent variables were equal across groups. This null hypothesis was not rejected in any of the 3 experiments.
Finally, in Experiment 2, where there were 3 masker levels, thereby permitting tests of sphericity for F-tests involving masker level, there was no evidence of a violation of sphericity for the interaction between Masker Level and Question Type (p = 0.706) but a marginally significant (p = 0.052) violation of sphericity for the main effect of masker level. However, applying a Greenhouse-Geisser correction to tests involving Masker Level as a factor had a negligible effect on significance levels. Therefore, we assumed that the dependent variable (percent correct responses) satisfied the assumptions for an analysis of variance within the general linear model, and that no corrections for violations of sphericity were required.
Results and discussion
Figure 2 plots the average number of correctly answered detail (left) and integrative (right) questions for normal-hearing younger, normal-hearing older, and hearing-impaired older adults. As Fig. 2 shows, detail questions were answered correctly more often than integrative questions. Also, normal-hearing younger adults answered more detail and integrative questions correctly than did normal-hearing older adults and hearing-impaired older adults. In turn, normal-hearing older adults answered more detail and integrative questions than did hearing-impaired older adults. Thus, it appears that when a meaningful distractor is present, listening comprehension in older adults was poorer than in younger adults, and particularly so if older adults had poor hearing.

Average percentage of detail and integrative questions answered correctly by younger adults, older adults with normal hearing, and hearing-impaired older adults in the presence of a competing lecture in Experiment 1. Listening conditions were identical for all three groups of participants. Standard error bars are shown. The dotted line indicates chance level performance
These results were confirmed by a mixed-design ANOVA (3 Groups × 2 Question Types), with Group as the between-subjects factor, and Question Type as the within-subject factor. The ANOVA showed main effects of Group (young NH > old NH > old HI, respectively), F (2, 51) = 20.37, p < 0.001, ηp 2 = 0.444, and of Question Type (detail > integrative), F (1, 51) = 54.25, p < 0.001, ηp 2 = 0.515, but no significant interaction, F (2, 51) = 2.82, p = 0.069, ηp 2 = 0.099. Hence, the extent of the difference in performance on detail and integrative questions was essentially the same for young normal-hearing, old normal-hearing, and old hearing-impaired individuals. Post-hoc LSD tests indicated that the young normal-hearing participants answered more questions correctly than either old, normal-hearing (p = 0.017) or old hearing-impaired (p < 0.001) participants, and the old normal-hearing participants answered more questions correctly than did old hearing-impaired participants (p < 0.001).
To check whether performance was limited by a floor effect, we compared the performance on detail and integrative questions for each group to chance level (25 %). The t-tests indicated that each groups’ performance for both question types was significantly above chance (all ps < 0.02, one-tailed) except for the hearing-impaired older group when answering the integrative questions (t [17] = −0.176, p = 0.431, one-tailed). Hence, performance on the integrative questions may have been limited by a floor effect.
It should be noted that in Experiment 1 there are both bottom-up, acoustic-level cues and top-down, knowledge-driven cues that are available to support stream segregation. At the acoustic level, the target lecture is presented at a level that is 7 dB lower than that of the competing lecture. This level difference is a bottom-up acoustic cue that can be used to focus attention on the target lecture. Because the target lecture starts 5 s before the competing lecture, the listener is given advanced information as to the nature of the target topic which can be used to maintain attention to the target stream. Because the three groups differ in both age and hearing status, it is difficult to pinpoint the contribution of age-related deficiencies in hearing versus potential age-related differences in the ability to use top-down cues to maintain attention on, and efficient processing of, the target lecture.
The poorer performance of the hearing-impaired older adults compared to the normal-hearing older adults is most likely due to their hearing impairment. However, because the hearing-impaired older adults were significantly older, and had lower vocabulary and reading comprehension scores than their normal-hearing counterparts, it is possible that some portion of the poorer listening comprehension in the hearing-impaired group could be due to their poor cognitive performance on these two measures, which may reflect the age difference between the two older groups. The poorer performance of older adults compared to younger adults could reflect poorer hearing in the older group or age-related declines in the cognitive functions supporting spoken language comprehension, or both of these factors. The relative contributions of hearing loss versus cognitive decline will be addressed in Experiment 2.
To investigate whether there were group differences in susceptibility to intrusions from the competing lecture, we examined the degree to which participants were able to answer detail questions about the competing lecture they heard last. The percentage of questions correctly answered were 48 %, 30 %, and 41 % for normal-hearing younger, normal-hearing older, and hearing-impaired older participants, respectively. A between-subjects ANOVA performed on these three groups failed to reveal any significant differences among them with respect to the percentage of questions about the competing lecture that were correctly answered (F [2, 51] = 2.09, p = 0.135, ηp 2 = 0.076). Because a one-tailed t-test indicated that the percentage of questions correctly answered concerning the competing lectures was significantly above chance level for the participants in this experiment (t [53] = 3.962, p < 0.001), we concluded that at least some information from the competing lecture was being processed and stored in memory and that the amount of information recalled did not differ significantly with the age or hearing status of the participants.
Experiment 2
The results of Experiment 1 suggested that older adults, especially those with poor hearing, were at a disadvantage relative to younger adults at understanding lectures presented in meaningful competing speech when all individuals were tested under comparable listening conditions. The next question was whether the age difference would disappear if we individually adjusted the target and masker levels, so that each participant was equally likely to recognize the individual words being spoken. Adjusting the listening situation to ensure equivalent levels of lexical access when individual words were masked by a babble of voices should compensate, at least in part, for age-related hearing declines that may be inhibiting lexical access by interfering with phonetic and phonemic encoding of sounds. If these age-related declines in hearing are primarily responsible for the poorer performance of the two older groups in Experiment 1, then age-related differences in spoken-language comprehension should be substantially reduced or eliminated in Experiment 2.
Experiment 2 was similar to Experiment 1 with two differences. First, each participant listened to three lectures instead of two. One of the lectures was presented in quiet, another was presented in the presence of a low level of competing speech, and the third was presented in the presence of a high level of competing speech. Second, in Experiment 2 the listening situation was adjusted to compensate for individual differences in the listener’s ability to recognize words in multi-talker babble (Schneider et al., 2000) by presenting the target lecture at a level that was 45 dB above each individual’s babble threshold, and adjusting the level of the competing lecture to compensate for an individual’s ability to recognize words masked by a babble of voices. The predictions were as follows. If the ability to recognize the individual words being spoken was the primary reason for the poorer performance of older adults in Experiment 1, then we would expect comparable performance from all three groups when the target lecture was masked by a competing lecture. However, if the older adults’ poorer performance in Experiment 1 was due primarily to an inhibitory deficit, or any other age-related declines in the linguistic and cognitive functions supporting spoken-language comprehension when the target lecture was masked by a competing lecture, then adjusting the listening situation to ensure equal levels of word recognition should not substantially affect age differences in spoken language comprehension. When the target lecture is presented in quiet at the same sensation level to younger and normal-hearing older adults, we would expect the recognition of the individual words being spoken to be comparable and near perfect for both groups. Hence, we would not expect performance differences between the younger and older normal-hearing groups. However, because word recognition in quiet is affected by hearing loss even when the target speech material is adjusted for babble thresholds (Pichora-Fuller, Schneider, & Daneman, 1995), we might expect to find the older hearing-impaired group to comprehend less than the younger and older normal-hearing groups. The finding that equating the three groups of listeners with respect to word recognition led to minimal differences in spoken language comprehension among these three groups strongly suggests that the age-related differences in comprehension observed in Experiment 1 are primarily a result of the age-related differences in hearing.
Method
Participants
The participants in Experiment 2 consisted of 18 normal-hearing younger adults (5 males), 18 normal hearing older adults (5 males), and 18 older adults (5 males) with mild-to-moderate hearing loss. Their ages and years of education appear in Table 1. They were recruited from the same pool of participants as the volunteers in Experiment 1, and were subject to the same inclusion criteria as the volunteers in Experiment 1. Their audiometric thresholds are displayed in Fig. 1.
Additional auditory measures
Babble threshold test
In Experiments 2, an adaptive two-interval forced-choice procedure was used to determine detection thresholds for the 12-talker babble stimuli. In this procedure, a 1.5-s babble segment was played in one of two randomly chosen intervals. The two intervals began 1.5 s after the listener pressed the start button, and were separated by a 1.5-s silent period. A green and a red light on the response box were matched to the two intervals, and the listener’s task was to identify the interval containing the babble segment by pressing the corresponding green or red button. Immediate feedback was provided. A three-down, one-up adaptive staircase procedure (Levitt, 1971) was used to determine the babble threshold for each person’s right ear. Table 1 presents the average right-ear babble thresholds for each of the three groups of participants in both this experiment and in Experiment 3. A three-group (Young, Normal-Hearing Old, and Hearing-Impaired Old) by two-experiment (2, and 3) between-subjects ANOVA failed to reveal any Group X Experiment interaction (F[1,81] < 1). The effect of Group was highly significant (F[2,81] = 66.12, p < 0.001, ηp 2 = 0.621). The effect of Experiment did reach significance in this instance (F[1,81] = 4.74, p = 0.032, ηp 2 = 0.055). Hence there is some evidence that the participants in Experiment 3 had lower right-ear Babble thresholds than those in Experiment 2. Post-hoc LSD tests indicated that young, normal-hearing participants had significantly lower babble thresholds than older-normal hearing participants, who, in turn, had significantly lower babble thresholds than older, hearing-impaired participants.
R-SPIN test
In the revised Speech Perception in Noise test (R-SPIN, Bilger, Nuetzel, Rabinowitz, & Rzeczkowski, 1984), the listener is asked to repeat the final word in a sentence presented in a background of babble and indicate whether the final word was predictable from the context. Sentences are presented in lists of 50, with 25 of them containing final words that are predictable from the context (e.g., “The boat sailed along the coast”) and 25 containing final words that have low predictability (e.g., “Peter knows about the raft”), but only the responses for the low-context sentences were used for determining the R-SPIN thresholds. Sentences and babble were presented to the right ear. The average SPL of the sentences was set 45 dB higher than the individual listener’s right-ear babble threshold, and at least two lists were employed to bracket the 50 % point on the psychometric function relating percent correct identification to SNR for low-context, sentence-final words. The SNR corresponding to the 50 % point (the low-context R-SPIN threshold) was then determined through linear interpolation. The R-SPIN thresholds also are presented in Table 1, along with those of Experiment 3. A three-group (Young, Normal-Hearing Old, and Hearing-Impaired Old) by two-experiment (2 and 3) between-subjects ANOVA failed to reveal any effect of Experiment (F[2, 132] < 1), or Group X Experiment interaction (F[3,132] < 1). However, the Group main effect was highly significant (F[2, 81] = 44.65, p < 0.001, ηp 2 = 0.524). Post-hoc tests indicate that R-SPIN thresholds are equivalent for both normal-hearing groups who, in turn, have significantly lower R-SPIN thresholds than the older, hearing-impaired group.
Cognitive measures
The same three cognitive measures (vocabulary, reading comprehension, and working memory) were collected on participants in this study and appear in Table 1.
Listening comprehension task
Materials and apparatus
The lectures presented in this experiment were the same ones used in Experiment 1. In this experiment, one target lecture was presented in quiet, and the other two were presented in a low or high level of a competing lecture. In all conditions, the target lecture was presented to the right ear at 45 dB above the individual’s right-ear babble threshold.Footnote 3 The competing lecture was presented to the right ear as well, but 5 s after the target lecture had started. In the low level competing lecture condition, the SNR was set equal to the value of the listener's low-context R-SPIN threshold minus 6 dB, and in the high level competing lecture condition, the SNR was set equal to the value of the listener’s low-context R-SPIN threshold minus 12 dB.Footnote 4 For example, if a participant had a babble threshold of 21 dB SPL and a R-SPIN threshold of 3 dB, the target lecture was presented at a level of 66 dB SPL (45 + 21), and the competing lecture in the low-level competing lecture condition to 69 dB SPL to produce an SNR of −3 dB (3-6). In the high competing lecture condition, the competing lecture would be set to 75 dB SPL for this individual, resulting in an SNR of −9 dB. Another participant with better hearing, whose babble threshold was 16 dB SPL, and whose R-SPIN threshold was −2 dB, would have the target presented at 61 dB, and the masker presented at 69 in the low-level competing lecture condition for an SNR of −8 dB. The high-level competing lecture condition for this individual with better hearing would be set to 75 dB SPL to produce an SNR of −14 dB. Note that the individual with the poorer hearing has the target level presented at a higher level than the person with good hearing and at a more favorable SNR. The higher target level for the individual with poorer hearing compensates for that individual’s higher threshold for recognizing the individual words being spoken. The more favorable SNR for the individual with poorer hearing equates the two individuals with respect to their ability to recognize the individual words in the target lecture.
As in Experiment 1, participants were instructed to pay attention to the lecture which started first and to ignore the second lecture. If the level of the target lecture was more than 4 dB lower than that of the competing lecture, the participants also were told to attend to the softer lecture, with the opposite instructions being given if the target lecture was 4 dB higher than the competing lecture.Footnote 5 A counterbalancing procedure was used to ensure that an equal number of participants heard each of the three target lectures in each of the three conditions: quiet, low level competing lecture, and high level competing lecture. Order of presentation of the three conditions was counterbalanced across participants.
Procedure
Participants were given the same instructions as in Experiment 1, using the same equipment and sound-attenuating chamber.
As in Experiment 1, after answering questions concerning the last target lecture heard by a participant when it was being masked by a competing target lecture, the participant was asked to answer five detailed questions about the competing lecture, even though the participant had been asked to ignore it in the first place.
Power calculations
The results from Experiment 1 indicated that when the three groups were not equated with respect to word recognition, there were statistically significant and substantial differences in performance across the three groups. Our rationale for conducting Experiment 2 was to investigate the extent to which these groups differences were reduced or eliminated when we did equate all individuals, irrespective of the group to which they belonged, for word recognition. In an F-test, the power to reject the null hypothesis of no differences among groups when the research hypothesis is true is determined by the value of the noncentrality parameter of a noncentral F distribution (higher values yield more power). We determined (see Appendix) the expected power of an F test for group differences, assuming a 75 %, 80 %, or 90 % reduction in the estimate of the noncentrality parameter found in Experiment 1. The power to detect a group effect given a 75 % reduction was 0.8. This means that if the noncentrality parameter in Experiment 2 were to be 25 % of its corresponding value in Experiment 1, the probability of rejecting the null hypothesis would be 0.80. Hence, we would have an 80 % chance of rejecting the null hypothesis that there were no group differences if equating for word recognition reduced the noncentrality parameter to 25 % of its estimated value when we did not equate for word recognition. The powers associated with 80 and 90 % reductions were 0.7 and 0.4, respectively. See the Appendix for further details.
Results and discussion
Figure 3 plots the average number of correctly answered detail (left) and integrative (right) questions as a function of the level of the competing lecture (quiet, low, high) for the normal hearing younger, normal hearing older, and hearing-impaired older participants. As in Experiment 1, this figure indicates that the percentage of correctly answered questions was greater for detail than for integrative questions. It also suggests that for detail, but not for integrative questions, more questions were answered correctly when the target lecture was presented without a competing lecture. There was an indication that in a quiet background the hearing-impaired group answered fewer detail questions correctly than did the other two normal-hearing groups. Finally, there does not appear to be any differences in performance across listener groups (young NH, old NH, old HI) in the presence of a competing lecture. A mixed-design ANOVA (2 Question Types × 3 Competitor Levels × 3 Groups, with Question Type and Competitor Level as the within-subject factors, and Group as the between-subjects factor) did not find any evidence that performance was affected by Group (F [2, 51] = 2.86, p = 0.066, ηp 2 = 0.101), and there were no significant interactions between Group and the other factors (Competitor Level X Group, F[4,102] = 1.03, p = 0.67, ηp 2 = 0.023; Question Type X Group, F[2, 51] < 1, ηp 2 = 0.020; Competitor Level X Question Type X Group, F[4,102] < 1, ηp 2 = 0.037). The lack of any significant effect of Group suggests that the higher-level post-lexical processes involved in spoken-language comprehension are capable of sustaining the same level of performance in each of the three groups when adjustments are made to equate all listeners with respect to word recognition, and that the group differences in comprehension found in Experiment 1 were primarily due to age-related changes in hearing.

Average percentage of detail and integrative questions answered correctly by younger adults, older adults with normal hearing, and hearing-impaired older adults in quiet and in two levels of a competing lecture in Experiment 2. Both the signal level and the levels of the background lectures (when present) were adjusted for individual differences in word recognition (see text). Standard error bars are shown. The dotted line indicates chance level performance
The percentage of detail questions answered correctly was higher than the percentage of integrative question answered correctly, (F [1, 51] = 99.90, p < 0.001, ηp 2 = 0.662). There was also a significant main effect of Competitor Level (F [2, 102] = 7.330, p = 0.001, ηp 2 = 0.126), which was qualified by a significant interaction between Question Type and Competitor Level (F [2, 102] = 22.876, p < 0.001, ηp 2 = 0.310).
Because there was a significant interaction between Question type and Competitor Level, we carried out separate mixed-design ANOVAs for detail and integrative questions, with Competitor Level as a within-subject variable, and Group as a between-subjects variable. For detail questions there was a significant main effect of Competitor Level with the percentage of correctly answered detail questions being greater in the absence of a competing lecture than in the presence of one (F [2, 102] = 22.336, p < 0.001, ηp 2 = 0.305) but no Group effect (F [2, 51] < 1, ηp 2 = 0.027), and no interaction between Competitor Level and Group (F [4, 102] = 1.16, p = 0.33, ηp 2 = 0.043). Follow-up pairwise comparisons with respect to Competitor Level indicated that more detail questions were correctly answered in the quiet condition than in the presence of either a low-level or high-level competitor (F [1,53] = 39.77, p < 0.001, and F [1,53] = 27.85, p < 0.001, respectively), with no significant difference between the low- and high-level conditions (F [1,53] < 1).
For integrative questions, neither the main effect of Competitor Level, nor Group, nor the interaction between Competitor Level and Group was significant (F [2,102] < 1, ηp 2 = 0.011, F [2, 51] = 2.90, p = 0.064, ηp 2 = 0.102, and F [4,102] < 1, ηp 2 = 0.007,for the Competitor Level main effect, Group main effect, and Competitor Level × Group interaction effect, respectively). Hence, there is no evidence to support the hypothesis that the ability to integrate information gleaned from the lecture is affected by the background level of the lecture or that it differs among the group of participants. It is possible that the lack of a group effect for the integrative questions may be due to the fact that declines in performance in the older groups were limited by a floor effect since these groups were performing close to chance level. Another possible reason for this result is that correct recognition of detail information is not necessarily required in order to get the overall ‘gist’ of the passage. Hence, integrative questions may simply be less susceptible to the presence of competing sound sources.
To investigate whether there were group differences in susceptibility to intrusions from the competing lecture, an ANOVA was performed on the data for the surprise test with Group as a between-subjects factor. The percentage of correctly answered detail questions from the competing lecture (46.55 %, 32.65 %, and 43.75 % for young normal-hearing, old normal-hearing, and old hearing-impaired participants, respectively) did not differ significantly from one another (F [2, 33] < 1, ηp 2 = 0.042), which indicated that all groups of participants were equally likely to remember the same number of details for the distracting lectures. Moreover, a one-tailed t-test indicated that the participants in this Experiment were processing and storing information from the competing lecture above chance levels (t [35] = 3.211, p = 0.003). Hence the evidence supports the hypothesis that the participants in Experiment 2 were processing and storing at least some information from the competing lecture, and that the amount of information recalled from the competing lecture did not differ with respect to age and hearing status.
Experiment 3
Experiment 3 compared two types of maskers—12-talker babble and single-talker competing speech—in a within-subject design, and examined the degree to which age differences between younger and older normal-hearing adults might be affected by the informational complexity of the masker. More specifically, the lectures in Experiments 1 and 2 were used as the target speech, and the masker was either 12-talker babble (Schneider et al., 2000) or similar lectures spoken by the same person.
Note that a babble of voices is acoustically more dissimilar to the target lecture than a competing lecture. Note also that a competing lecture is more likely to initiate competing activity in the syntactic, semantic, and linguistic processes supporting spoken-language comprehension. Both of these factors make the competing lecture more of an informational masker than a babble of voices.Footnote 6 However, it is not clear as to which masker (babble or a competing lecture) provides a greater degree of energetic masking.
Multi-talker babble is a broadband distractor. Previous research shows that a larger number of interfering talkers (e.g., 8 compared to 2 talkers) reduces target speech intelligibility due to the gradually increased spectral-temporal saturation (Boulenger, Hoen, Ferragne, Pellegrino, & Meunier, 2010; Brungart, Simpson, Ericson, & Scott, 2001; Hoen et al., 2007). Single-talker competing speech, on the other hand, may only mask limited frequencies of target speech at one given time, and the pauses between clauses or sentences could provide listeners with the opportunity to listen in the gaps (Peters, Moore, & Baer, 1998). Hence, even a same voice masker (which would have the same long-term spectrum as the target voice) could produce a lesser amount of energetic masking because the peaks and troughs in the amplitude of the masking voice would not necessarily occur at the same point of time as those of the target voice. For example, a spoken word in the target stream could occur during a pause in the masker voice, producing very little energetic masking at that point of time. Therefore, from an energetic masking point of view, multi-talker babble might produce more masking than single-talker competing speech.
However, single-talker competing speech may cause more informational masking than babble mainly for two reasons. Firstly, the competing speech is acoustically more similar to the target speech than is babble due to the prosodic and fine structure similarities, not to mention that the target and distracting lectures share the same voice. Considering that acoustic similarity is one of the most important determining factors for ease of stream segregation and level of informational masking (Agus, Akeroyd, Gatehouse, et al., 2009; Drullman & Bronkhorst, 2004; Durlach et al., 2003; Ezzatian, Li, Pichora-Fuller, & Schneider, 2012), we would expect the competing speech to produce more informational masking than 12-talker babble. Second, the semantic content in the competing speech is capable of activating the same semantic and linguistic process as the target speech; thus, it may interfere with comprehension of the target speech at more central levels (Boulenger et al., 2010; Rossi-Katz & Arehart, 2009). Taken together, it is reasonable to predict that single-talker speech may be more distracting than 12-talker babble.
The purpose of Experiment 3 was to examine the effect of competitor type, competitor level, and age on informational masking. A similar methodology to that of Experiment 2 was adopted here. Normal hearing younger listeners and normal hearing older listeners were presented with four lectures in a 2 (Competitor Type: babble vs. competing lecture) × 2 (Competitor Level: low vs. high) within-subject design. As in Experiment 2, the level of the target lecture was set to 45 dB above each listener’s babble threshold, with the SNR in the low Competitor Level condition set at each individual’s R-SPIN threshold −6 dB, whereas the SNR in the high Competitor Level condition was set at each individual’s R-SPIN threshold −12 dB.
Method
Participants
The participants in Experiment 3 consisted of 16 normal-hearing younger adults (5 males) and 16 normal hearing older adults (5 males). Their ages and years of education appear in Table 1. They were recruited from the same pool of participants as the volunteers in Experiments 1 and 2 and were subject to the same inclusion criteria as the volunteers in those experiments. Their audiometric thresholds are displayed in Fig. 1.
Auditory measures
Both babble threshold and low-context R-SPIN thresholds of each of the participants were determined following the procedures described in the “Method” Section of Experiment 2 and appear in Table 1.
Cognitive measures
The same three cognitive measures (vocabulary, reading comprehension, and working memory) were collected on participants in this study and appear in Table 1.
Materials and apparatus
In Experiment 3, the four shorter lectures were used as targets, and the two longer ones were used as competitors. Each participant listened to four lectures monaurally over the right headphone: two were presented with babble as a masker, and the other two were presented with a competing lecture as the masker. Also, two of the lectures were presented in the low distractor level condition, and the other two in the high distractor level condition, so the experiment was a 2 (distractor type: babble vs. lecture) × 2 (distractor level: high vs. low) within-subject design. The target lecture was presented to the right ear 45 dB above the level of each individual’s right-ear babble threshold. The distractor (babble or competing lecture) was presented to the right ear as well, but it started 5 s after the target lecture had started. In the low distractor level condition the SNR was set to −6 dB lower than the listener's low-context SPIN threshold, and in the high distractor level condition it was set −12 dB lower. Order of presentation of the four conditions was counterbalanced across participants. The four target lectures and two masking lectures appeared equally often in each of the four conditions.
Procedure
Participants were given the same instructions as in Experiment 1, using the same equipment and sound-attenuating chamber.
After answering questions concerning the last target lecture heard by a participant when it was being masked by a competing target lecture, the participant was asked to answer five detailed questions about the competing lecture, even though the participant had been asked to ignore it in the first place. In addition, in Experiment 3 only, after each lecture, participants also rated how difficult it was to understand the lecture on a scale from 1 to 7 (with 7 being the most difficult).
Results and discussion
Figure 4 plots the percentage of correctly answered detail and integrative questions as a function of Age (younger vs. older), Competitor Type (lecture vs. babble) and the level at which the competitor was presented (low vs. high). As in Experiments 1 and 2, more detail than integrative questions were answered correctly in all conditions. However, the difference in performance between detail and integrative questions appears to be larger when the masker was babble than when it was a competing lecture. Consistent with Experiment 2, the level of the competing lecture does not appear to affect performance for detail questions. However, performance on detail questions appears to decrease with an increase in masker level when the masker is babble. Finally, for integrative questions, the level of the masker does not appear to have any systematic effect on performance.

Average percentage of detail and integrative questions answered correctly by younger and older adults in Experiment 3 as a function of competitor type (babble vs. lecture) and the level at which the competitor was presented (high vs. low). Both the signal level and the levels of the background lectures (when present) were adjusted for individual differences in word recognition (see text). Standard error bars are shown. The dotted line indicates chance level performance
This pattern of results was confirmed by a 2 (Question Type: detail vs. integrative) × 2 (Competitor Type: babble vs. lecture) × 2 (Age: younger vs. older) × 2 (Competitor Level: low vs. high) mixed-design ANOVA with Question Type, Competitor Type, and Competitor Level as within-subject factors, and age as a between-subjects factor. Neither the main effect of Age (F[1,30] =1.03, p = 0.318, ηp 2 = 0.033) nor any of the interactions of Age with the other factors were found to be significant (ps> 0.15, for all interactions between Age and the other factors, ηp 2 < 0.063 for all interactions between Age and the other factors). The main effect of Competitor Level was not significant (F [1,30] = 1.02, p = 0.321, ηp 2 = 0.033), whereas the main effect of Competitor Type was (F [1,30] = 24.84, p < 0.001, ηp 2 = 0.453), but these two main effects were qualified by an interaction between Competitor Type and Competitor Level (F [1,30] = 4.26, p = 0.048, ηp 2 = 0.124). The main effect of Question Type was significant (F [1,30] = 70.55, p < 0.001, ηp 2 = 0.702) as was the interaction between Competitor Type and Question Type (F [1,30] = 13.21, p = 0.001, ηp 2 = 0.306). Finally, the three-way interaction between Competitor Type, Competitor Level, and Question Type was marginally significant (F [1,30] = 4.10, p = 0.052, ηp 2 = 0.120). No other significant interactions were observed.
Because there was no main effect of age, nor any interactions involving age, we collapsed over age. Figure 5 plots the percentage of correctly answered detail and integrative questions for the two levels of babble and competing lecture. This figure shows that when the distractor was babble, the percentage of correctly answered detail questions decreased with an increase in the level of the babble distractor. The figure also shows that fewer detail questions were answered correctly when the distractor was a competing lecture than when the distractor was babble. Moreover, the level of the competing lecture did not appear to affect performance. A repeated measures ANOVA on detail questions confirmed that there was a significant main effect of Competitor Type (F [1, 31] = 36.62, p < 0.001, ηp 2 = 0.542), and a significant interaction between Competitor Type and Competitor level (F [1, 31] = 6.70, p = 0.015, ηp 2 = 0.178). The main effect of Competitor Level was not significant (F [1,31] = 2.131, p = 0.155, ηp 2 = 0.064). Hence, for detail questions, the level of the distractor affects performance only when the competitor is babble.

Percentage of detail and integrative questions correctly answered (collapsed across age groups) for two different levels of either a babble or lecture competitor when target and competitor levels were adjusted to compensate for individual differences in word recognition in Experiment 3. Standard error bars are shown. The dotted line indicates chance level performance
The most likely reason for the interaction between level and masker type is that the particular SNRs employed in this experiment affected the similarity, and hence the informational interference between the target and competing lectures. In the low distractor level condition, the SNR was set at 6 dB lower than the individual’s SPIN threshold, and in the high distractor level condition it was set at 12 dB lower. Because the average SPIN thresholds for younger and older adults in Experiment 3 were 3.69 dB and 4.19 dB respectively, in the low distractor level condition the average SNR at which the target lecture was presented was approximately −6 + 4 = −2 dB, whereas in the high distractor level condition it was approximately −12 + 4 = −8 dB. However, performance did not differ across these two SNRS, producing a plateau in the function relating performance to SNR.
Freyman et al. (1999) also reported a similar plateau in the function relating performance to SNR for SNRs between −10 and −4 when a sentence target spoken by a female was masked by another sentence spoken by a different female whenever the target and masker were perceived to originate from the same source, as was the case in our experiments. However, when the sentence target was masked by speech spectrum noise, no such plateau was observed. In that case, decreasing the SNR always resulted in a decrease in performance. Such an effect also was noted by Egan, Carterette, and Thwing (1954).
What could be the reason for such a plateau when speech is masked by speech but not when it is masked either by steady-state noise or babble? From an energetic masking point of view, we would expect comprehension to suffer when the SNR is decreased, as was the case when the masker was babble. However, for single-talker competing speech, the increase in energetic masking that occurs when the SNR is reduced from −2 dB to −8 dB may have been counterbalanced by a decrease in the amount of informational masking associated with a change from −2 dB to −8 dB. From an informational masking point of view, the acoustic similarity between the target and the competing lectures would be greater for an SNR of −2 than it would be at an SNR of −8 dB. Hence, an increase in dissimilarity between the target and masker may have counterbalanced a decrease in SNR.
No such interaction between Competitor Type and Competitor Level was observed for integrative questions. When only integrative questions were considered, a repeated measures ANOVA did not reveal main effects of Competitor Level (F [1,31] < 1, ηp 2 = 0.001), Competitor Type (F [1,31] = 2.49, p = 0.125, ηp 2 = 0.074), nor any interaction between the two (F [1,31] < 1, ηp 2 = 0.000). Hence, in Experiment 3, neither Competitor Type nor Competitor Level significantly affected performance on integrative questions. However, the lack of effects for integrative questions may be due, in part, to the fact that performance for integrative questions was quite close to chance levels.
In Experiment 3, participants also rated each target lecture with respect to how difficult it was to understand. Figure 6 shows how subjective ratings of difficulty were affected by competitor type (babble vs. competing lecture), competitor level (low vs. high), and age (young normal hearing versus old normal hearing). Figure 6 suggests that it is more difficult to understand a lecture in the presence of a competing lecture than in the presence of babble. There also is some indication that perceived difficulty increases with competitor level for babble maskers, with the opposite appearing to occur when the competitor is a lecture. A two Age × 2 Competitor Type × 2 Competitor Level ANOVA revealed a significant main effect of Competitor Type (F [1, 30] = 182.45, p < 0.001, ηp 2 = 0.859) and a significant interaction between Competitor Type and Competitor Level (F [1, 30] = 6.10, p = 0.019, ηp 2 = 0.169). The main effect of Age, as well as any interaction between Age and the other factors failed to reach significance (all ηp 2 < 0.030). Hence, the age of the listeners did not affect how difficult it was to understand the target lectures when the SNRs were adjusted to compensate for age-related declines in speech recognition.

Perceived difficulty in listening to the target lecture in the presence of either a lecture or babble competitor for normal-hearing younger and older participants at two different levels of the competitor when target and competitor levels were adjusted to compensate for individual differences in word recognition in Experiment 3. Standard error bars are shown
To investigate whether there was an age difference in susceptibility to intrusions from the competing lecture, we examined performance on the surprise test. Younger and older adults had exactly the same percentage of correct responses for distractor details (48.33 %), which indicated that both age groups were equally likely to remember the details of the distracting lectures. Moreover, a one-tailed t-test indicated that the participants in this experiment were processing and storing information from the competing lecture above chance levels (t [31] = 5.042, p < 0.001). Hence, the evidence supports the hypothesis that the participants in Experiment 3 were processing and storing at least some information from the competing lecture, and that the amount of information recalled from the competing lecture did not differ with respect to age.
The results of Experiment 3 demonstrated the following three points: (1) single-talker competing speech was more distracting than 12-talker babble; (2) older and younger adults were equally distracted by maskers in a situation in which the listening situation was individually adjusted for age differences in word recognition, and (3) increasing the distractor level negatively affected speech comprehension when the masker was babble but had no effect when the masker was a competing lecture in the same voice.
Contribution of cognitive abilities to speech comprehension in experiments 1-3
Because the comprehension, interpretation, and recall of information presented in these target lectures is likely to place demands on a number of linguistic and cognitive processes, we also obtained measures of vocabulary knowledge, reading comprehension, and working memory in all but three of the participants in these experiments. To evaluate the relative contributions of these three measures, for each individual, we averaged the percentage of both detail and integrative questions answered across all conditions in which the target lecture was presented in the presence of a competing lecture. We then centered these averaged scores within each combination of experiment (Experiments 1, 2, and 3) and group (young normal hearing, old normal hearing, old hearing impaired) to remove any Group × Experiment differences in performance. We then collapsed over old normal-hearing and old hearing-impaired individuals to form two groups (old and young) and centered each of the three measures within each of the two groups to control for level differences between the two groups. The contribution of these three measures to speech comprehension when a competing lecture was present was investigated in the following model
where y is the centered speech comprehension score, MH is the centered Mill Hill score, ND is the centered Nelson Denny score, and WM is the centered working memory score. This model was able to account for 18.1 % of the variance in the centered speech comprehension scores. To see whether there were age differences with respect to the contribution of these three variables, we tested the joint null hypothesis that a Young = a Old ; b Young = b Old ; and c Young = c Old . This null hypothesis could not be rejected (F [3,131] = 2.15, p = 0.097). We collapsed the data over Age to arrive at a model in which
To determine which variables contributed significantly to speech comprehension, we tested the null hypothesis that a = c = 0. This null hypothesis could not be rejected (F [2, 134] < 1). These results suggest that the contributions of these three factors to performance does not differ with Age and that the only measure that is significantly (but weakly) correlated with performance is reading comprehension (r = 0.37). The fact that reading comprehension is the best predictor of speech comprehension is not surprising given that the reading comprehension test taps many of the same comprehension skills that are essential for understanding the spoken lectures and answering the comprehension questions.
General discussion
In three experiments, we examined the manner and extent to which a meaningful and acoustically similar lecture might interfere with comprehension of a target lecture and also evaluated whether or not there were any age differences with respect to the degree of interference produced by the competing lecture. The results showed that older adults did experience more difficulties than younger adults in speech comprehension under identical listening situations (Experiment 1). However, after adjusting the listening situation to compensate for each listener’s ability to recognize individual words (Experiments 2), age differences in listening comprehension were no longer evident, even for an older hearing-impaired group.
It is especially interesting that the participants in the older hearing-impaired group performed as well as the participants in the other two groups when all participants were equated for spoken-word recognition. The hearing-impaired older adults not only had poorer hearing than the normal-hearing older adults (greater degree of hearing loss, higher babble, and R-SPIN thresholds, they also had significantly lower working memory and reading comprehension scores than normal-hearing older adults (Fig. 1; Table 1). Although equating individuals in both groups for recognition of individual words might be expected to compensate for the poorer hearing of the hearing-impaired older adults, we would not necessarily expect it to compensate for their poorer working memory and reading comprehension abilities. Yet when all three groups were equated for the recognition of the individual words being spoken, group differences in the ability to answer questions concerning the target lectures disappeared. This suggests that the primary factor that is responsible for group differences with respect to comprehending and remembering the information contained in these lectures is the ability of individuals to recognized the individual words when the lectures are masked either by a competing lecture in the same voice or by multi-talker babble. Hence, adjusting the level of the target lecture, and the SNR at which it is presented, is sufficient to eliminate comprehension differences between younger normal-hearing and older hearing-impaired individuals when listening to a lecture masked by another lecture despite: 1) 16-dB difference in babble thresholds; 2) 7.5-dB difference in R-SPIN thresholds; 3) 55-year-age difference, 4) 17 % decline in working memory capacity, and 5) 32 % decline in reading comprehension. With respect to this issue, it is important to note that the older adults’ vocabulary knowledge exceeds that of the younger adults by 12 %. Hence, once both younger and older adults are equated for word recognition, the superior vocabulary knowledge may allow them to offset age-related declines in working memory and reading comprehension (Schneider, Avivi-Reich, & Daneman, 2016).
Experiment 3 directly compared the disruptiveness of babble versus that of a competing lecture in the same voice, again when the level of the distractor was adjusted for individual differences in babble thresholds and in speech recognition thresholds. The results of Experiment 3 showed: 1) that normal-hearing older adults performed as well as their younger counterparts; 2) that a competing lecture was more disruptive than babble for all listeners; and 3) that higher levels of the babble distractor were more disruptive than lower levels, but this was not true for competing lectures.
Source of age differences in spoken language comprehension
Previous studies, using babble as a masker, have shown that older adults cannot answer as many questions as can younger adults concerning the content of lectures (Schneider et al., 2000) and of two-person dialogues (Murphy et al., 2006) when all listeners are tested under identical acoustical conditions. However, when the listening conditions in these studies were individually adjusted to make it equally difficult for all listeners to recognize the individual words in the lecture, these age differences largely disappeared. The authors have interpreted these results as supporting the hypothesis that the presence of age differences in spoken language comprehension primarily reflect the deleterious effect that age-related changes in hearing have on lexical access. Clearly, if access to the lexicon is impeded, one would expect losses in spoken-language comprehension. In older adults, lexical access could be impeded by age-related changes in the cognitive and language-specific processes involved in lexical access (see Rönnberg et al., 2013, for a model of how top-down, knowledge-driven processes support spoken word recognition when listening becomes difficult, and Vadin et al., 2013 and Zekveld et al., 2006, for the role of frontal attention systems in lexical access). Alternatively, lexical access could be poorer in older normal-hearing and hearing-impaired adults, because the acoustic signal is degraded by peripheral changes in auditory processing. If poorer lexical access is due in whole or in part to age-related declines in the cognitive and language-specific processes involved in lexical access, then improving the SNR would likely not be sufficient to completely overcome all lexical processing deficiencies in older adults. For example, it might be case that even after adjusting the SNR to compensate for age-related deficiencies in word recognition, older adults might depend more on the top-down processes supporting lexical access than do younger adults. This increased draw on cognitive resources in support of word recognition in older compared with younger adults might deplete the pool of cognitive and attentional resources needed to comprehend and remember the information that was heard. Hence, age-related differences in spoken language comprehension might persist even after all individuals are equated for word recognition in babble. On the other hand, if lexical access difficulties in older adults are primarily caused by age-related degradation of the auditory signal, adjusting the SNR to achieve equivalent levels of word recognition in all individuals would not impose a higher draw on cognitive and attentional resources in older adults than in younger adults. As long as the pool of available resources in both age groups is sufficient to handle the comprehension task, age-related differences in spoken-language comprehension would be minimized. However, if the pool of resources available to support spoken-language comprehension was smaller in older than in younger adults (Craik & Byrd, 1982), we would expect age differences in comprehension to persist. Because boosting the signal and increasing the SNR restored comprehension in these two older groups to levels characteristic of younger adults, and because differences in the informational interference due to the use of different maskers (babble vs. competing lecture) also did not result in an age difference in spoken-language comprehension, the findings suggests that the primary source of age-related difficulties in spoken-language comprehension in these experiments is due to the effects that declines in hearing have on spoken word recognition.
The current results also suggest that when the target speech is presented in a quiet background at a level that is adjusted to take into account the individual’s speech reception threshold (e.g., their babble threshold), age-related comprehension differences are minimized, if not completely eliminated. In a cross-sectional study spanning a large age range, Sommers, Hale, Myerson, Rose, Tye-Murray, and Spehar (2011) found that when speech was presented at a high but comfortable level, speech comprehension remained relatively unchanged until approximately age 65 years. Beyond this age, these investigators found that speech comprehension declined with age even after controlling for an individual’s audiometric threshold. There also is a hint of this in our study in the hearing-impaired older adults, who, in addition to being hearing impaired, were significantly older than our group of normal-hearing older adults and had significantly lower working memory and reading comprehension scores. When the lecture was presented in a quiet background, this older hearing-impaired group in Experiment 2 answered fewer detail questions correctly than did the younger or older normal hearing participants, although this result was not statistically significant. In a quiet background, the pattern of results in this study and in Sommers et al. could be due to age-related changes in hearing other than hearing loss or to age-related changes in cognition (because the hearing-impaired group was older than the normal-hearing group and had poorer scores on two of the three cognitive tests). A number of studies have documented that there are age-related losses in neural synchrony, temporal resolution, or other age-related changes in more central auditory processes that could degrade the auditory input (Frisina & Frisina, 1997; Frisina et al., 2001; Heinrich & Schneider, 2006; Pichora-Fuller et al., 2007; Schneider & Pichora-Fuller, 2001; Wang et al., 2011). To the extent that such auditory abilities decline with age and are relatively independent of audibility, they could lower the ability of older adults to recognize words in a quiet background, above and beyond that due to audibility. The finding that group differences were minimized when we adjusted for individual differences in word recognition is consistent with the notion that age-related declines in comprehension are primarily due to age-related changes in the auditory processes leading up to word recognition.
It also is important to note that our results do not imply that the processes leading to word recognition and spoken-language comprehension are always equivalent in younger and older adults. A number of studies have noted age-related deterioration in phonological processing that is not accompanied by age-related changes in semantic processing (Burke & Shafto, 2008, for a review). In addition, the degree of activation in the brain regions subsuming phonetic and semantic processes appears, in general, to be greater for older than for younger adults (Diaz, Johnson, Burke, & Madden, 2014). Hence adjusting the listening situation to produce equivalent word recognition in younger and older adults need not imply that lexical access is achieved in the same manner in both age groups. Moreover, recent results indicate that the relative contribution of specific cognitive processes to the comprehension of overheard dialogues (two-person conversations) or trialogues (3-person conversations) differ not only with age but also with listening difficulty (Avivi-Reich et al., 2014, Avivi-Reich, Jakubczyk, Daneman, & Schneider, 2015). For example, in certain listening situations, older adults’ performance is better predicted by their vocabulary knowledge than by their reading comprehension, with the opposite being true for younger adults. This suggests that when listening becomes difficult, older adults tend to rely more on those cognitive abilities that are preserved with age to maintain good comprehension than do their younger counterparts (Schneider, Avivi-Reich, & Daneman, 2016). Hence, the pattern of results in this study should not be interpreted as requiring that the cognitive processes involved in word recognition and language comprehension be identical in younger and older adults, only that they are equally effective once we equate for word recognition.
How the informational complexity of the masker affects speech comprehension
The primary purpose of the current study was to investigate whether age differences in comprehension would manifest themselves after compensating for age-related changes in spoken word recognition, when the competing masker was not only highly interpretable (a competing lecture), but also acoustically similar to the target voice. The cognitive aging literature suggests a number of reasons why a competing lecture should interfere with the comprehension of a target lecture even when the listening situation has been adjusted to compensate for age-related changes in spoken word recognition.
One factor that would suggest that compensating for age-related differences in spoken-word recognition might not be sufficient to eliminate age-related differences in comprehension is that older adults often are considered to be more distractible than younger adults and unable to inhibit the processing of irrelevant information (the inhibitory deficit hypothesis; Hasher & Zacks, 1988). According to this theory, a competing lecture in the same voice should be more distracting than an uninterpretable babble of difference voices. Figure 4 shows that both younger and older adults answered fewer questions correctly when the masker was a competing lecture than when it was babble, even when the ratio of the sound pressure in the target to that of the masker was the same for both kinds of maskers. Given that the competing lecture is more distractible than babble, we might have expected older adults to be more adversely affected by the competing lecture than younger adults, but this was not the case (Fig. 4). Moreover, both younger and older adults did not differ with respect to the amount of information they had gleaned from the competing lecture when they were unexpectedly queried about its contents. Hence, the findings of the present study, along with those of previous studies (Schneider et al., 2000; Murphy et al., 2006; Murphy et al., 1999), suggest that when age-related deficits in spoken word recognition are taken into consideration, older listeners are capable of ignoring the irrelevant auditory distractors just as well as are their younger counterparts.
One reason why the inhibitory deficit hypothesis might not have been supported in the present study may have had to do with the fact that the task was an auditory one. In most of the studies that have found age-related inhibitory deficits, the target and distracting materials were presented visually, whereas in the present study both the target and distracting materials were presented aurally. In a critical review about age-related distraction, Guerreiro, Murphy, and Van Gerven (2010) examined the role of sensory modality in older adults’ susceptibility to distractions. They compared four different paradigms: visual task with visual distraction, auditory task with auditory distraction, visual task with auditory distraction, and auditory task with visual distraction. One of their findings was that age-related distraction was more likely to happen when irrelevant information was presented in the visual modality rather than in the auditory modality. Guerreiro et al. (2010) attributed this phenomenon to differences in modality-specific neural mechanisms, and explained that “distractors presented through the auditory modality can be filtered at both central and peripheral neurocognitive levels. In contrast, distractors presented through the visual modality are primarily suppressed at more central levels of processing, which may be more vulnerable to aging” (p. 975). If this were the case, we should expect less, if any, age difference in listening-in-noise tasks compared with visual tasks.
Finally, Experiment 3 indicated that single-talker competing speech was much more distracting than babble. The babble (providing that its spectral composition is similar to that of the single-talker masker) is likely to produce more energetic masking than a single-talker masker, because there are fewer dips in the amplitude envelope of the babble than there are in the amplitude envelope of the single-talker masker. Single-talker competing speech, on the other hand, causes both energetic and informational masking (Brungart et al., 2001; Brungart, 2001). The level of energetic masking it produces depends on the momentary intensity of the competing speech relative to the target speech, whereas the level of informational masking is modulated by the acoustic similarity between the two voices, as well as the linguistic and semantic content of the competing message. In the current study, both the target and distracting lectures were presented through the right earphone, and spoken by the same person, so that the acoustic similarity of the two streams was high, presumably leading to a high degree of informational masking. In addition, the semantic content of the masker would likely increase the amount of informational masking; thus the level of informational masking should be higher for the single-talker masker than for the babble masker. The fact that performance was worse when the masker was single-talker speech than when it was babble (when babble and the single-talker masker were played at equivalent SNRs) indicates that there was a greater degree of informational masking for the speech masker than for the babble masker. Hence, in everyday listening situations (such as listening to a lecture), the informational content of other competing sounds will modulate the degree of comprehension of and memory for the target lecture.
Limitations of the present study
The results of this study and others suggest that age differences in the ability to answer questions concerning the content of lectures and multi-talker conversations are minimized or even eliminated when adjustments are made to the SNR to insure that all listeners are equally likely to recognize the individual words being spoken. In these studies, the questions are asked immediately following the heard material and therefore place minimal demands on memory. Moreover, these lectures and conversations are contextually rich. The question remains whether equating for word recognition will successfully minimize age-related differences spoken language comprehension when, for instance, the memory demands imposed by the task are more stringent. Indeed, a number of studies suggest that an increase in the memory demands imposed by the listening comprehension task could lead to age-related differences in performance.
For example, age differences in the ability to recall the second of two unrelated spoken words do not disappear when the SNR is individually adjusted to achieve equal word recognition in younger and older adults (Murphy, Craik, Li, & Schneider, 2000; Heinrich, Schneider, & Craik, 2008; Heinrich & Schneider, 2011). In these studies there is no contextual support for the memory task. We might expect age-related differences in speech comprehension to manifest themselves more fully in tasks where the memory demands are high and contextual support is low (see Schneider, Avivi-Reich, Leung, & Heinrich, 2016, for a discussion of this issue). In a recent longitudinal study of older adults, Payne et al. (2014) found that memory for spoken discourse was highly correlated with measures of within-person fluid intelligence. However, their spoken discourse memory task required participants to listen to audiotape recordings of a passage and then, immediately after hearing the passage, write down everything they could remember. Note that the memory load for this free-recall task is considerably greater than the one employed here where the participants were only required to answer multiple-choice (recognition memory) questions concerning the heard material. Given the heightened memory task demands in the Payne et al. longitudinal study, and the finding that equating for individual word recognition in a paired-associates memory task does not eliminate age differences in performance, we might expect age differences to emerge in a task that required listeners to write down all that they heard in a background of noise, even after equating all listeners with respect to spoken word recognition. Unfortunately, no hearing measures were included in the Payne et al. study, and the presence or absence of noise in the testing situation is not documented. It would be interesting to repeat the Payne et al. study in the presence of different kinds of competing maskers, after individual adjustments have been made in the SNR to equate all listeners with respect to recognition of individual words being spoken.
A second limitation concerns possible floor effects with respect to answering integrative questions concerning the lectures. An examination of Figs. 3, 4, 5 and 6 shows that performance on integrative questions was quite close to chance levels when the masker was a competing lecture. The restricted range found for integrative question may not have been sufficiently large to allow differences among the groups to emerge. It may be premature to conclude that equating all listeners with respect to spoken word recognition eliminates age differences with respect to integrative questions.
It also should be noted that, even though there was no evidence of any age differences once listeners were equated for word recognition, this does not prove that this manipulation eliminated all age differences in spoken-language comprehension. It does, however, provide strong evidence that equating for word recognition does, at the very least, substantially reduce age differences in comprehension. First, we noted that the estimate of effect size for the main effect of age that was observed without adjusting for word recognition in Experiment 1 was ηp 2 = 0.444. However, none of the four tests involving age in Experiment 2, and none of the eight tests involving age in Experiment 3 reached significance. Moreover, none of the effect sizes observed for these 12 independent tests involving age exceeded ηp 2 = 0.101. Hence the evidence suggests that the size of the age effect is reduced by at least 75 %, if not totally eliminated.
Finally, one should not conclude from these findings that cognitive factors do not contribute to spoken language comprehension, and/or that there are no age differences in the manner in which spoken-language comprehension is achieved. Schneider, Avivi-Reich & Daneman (2016) have shown that even after all listeners have been experimentally equated for word recognition, individual differences in performance are highly correlated with tests of vocabulary knowledge and reading comprehension. Interestingly, while both vocabulary knowledge and reading comprehension are correlated with listening comprehension in both younger and older adults when listening is easy, when listening becomes very difficult, reading comprehension accounts for much more of the variance in listening comprehension in younger adults whereas vocabulary knowledge is the best predictor of listening comprehension in older adults. Hence the manner in which older adults achieve levels of comprehension that are comparable to those of younger adults appears to change with age.
Summary
The present results support the hypothesis that the primary reason why older adults find it difficult to comprehend a lecture or follow a conversation in noisy environments is that they simply cannot hear the individual words being spoken. They also show that making the competitor more intelligible and acoustically similar to the target (e.g., switching from a babble masker to a competing lecture) makes it more difficult to comprehend what is being said, presumably because it increases the degree of informational masking. The present results do not imply that equating younger and older adults with respect to word recognition will eliminate age-related differences on all tasks involving spoken language. For example, age differences in the ability to recall the second of two unrelated spoken words do not disappear when the SNR is individually adjusted to achieve equal word recognition in younger and older adults (Murphy, Craik, Li, & Schneider, 2000; Heinrich, Schneider, & Craik, 2008; Heinrich & Schneider, 2011). Age differences might manifest themselves in listening tasks that place greater demands on memory. However, the evidence does support the notion that when listening to connected discourse (lectures, and two- or three-person conversations), age-related differences in comprehension primarily, but not exclusively (Murphy et al. 2006), appear to be the consequence of age-related changes in the auditory processes that support the recognition of spoken words.
Notes
Older adults with hearing loss were included in the design because of the prevalence of hearing loss in the population of older adults and because of the strong correlation between hearing loss and cognition in this population (Lindenberger and Baltes, 1994). Hence, we would expect participants in the hearing-impaired group to be somewhat older (because hearing loss increases with age) and to have lower scores on cognitive tests.
Participants were either native English speakers or learned English in an English-speaking country before age 5 years. English was the first language of 44 of 54 young normal-hearing participants, 49 of 54 normal-hearing older participants, and 35 of 36 hearing-impaired older participants. Thirty-eight of 54 young normal-hearing young participants were born in English Canada, as were 31 of 54 normal-hearing older participants, and 22 of 36 hearing-impaired older adults.
We presented the story 45 dB above the listener’s babble threshold to ensure that the information carried by frequencies in speech range was well above threshold for all listeners.
SNR values of −6 and −12 were chosen based on pretests that indicate that these levels would produce percent correct responses above chance level but below those expected in quiet.
In a pilot experiment, some of the participants tended to listen to the wrong lecture, so we decided to tell them whether to listen to the softer or louder voice in order to give them more cues regarding which lecture to follow.
Note that because the competing lecture was more acoustically similar and more informationally complex than a babble of voices, it would not be possible in this experiment to distinguish between the degree to which the acoustic similarity of the target to the masker as opposed to the difference in the degree to which competing activity elicited in the syntactic, semantic, and linguistic systems by a masker might be responsible for any age differences in performance.
References
Agus, T. R., Akeroyd, M. A., Gatehouse, S., & Warden, D. (2009). Informational masking in young and elderly listeners for speech masked by simultaneous speech and noise. The Journal of the Acoustical Society of America, 126(4), 1926–1940. doi:10.1121/1.3205403
Avivi-Reich, M., Daneman, M., & Schneider, B. A. (2014). How age and linguistic competence alter the interplay of perceptual and cognitive factors when listening to conversations in a noisy environment. Frontiers in Systems Neuroscience, 8(21), 1–17. doi:10.3389/fnsys.2014.00021
Avivi-Reich, M., Jakubczyk, A., Daneman, M., & Schneider, B. A. (2015). How age, linguistic status, and the nature of the auditory scene alter the manner in which listening comprehension is achieved in multitalker conversations. Journal of Speech, Language, and Hearing Research, 58, 1570–1591.
Bell, R., Buchner, A., & Mund, I. (2008). Age-related differences in irrelevant-speech effects. Psychology and Aging, 23(2), 377–391. doi:10.1037/0882-7974.23.2.377
Bilger, R. C., Nuetzel, J. M., Rabinowitz, W. M., & Rzeczkowski, C. (1984). Standardization of a test of speech perception in noise. Journal of Speech and Hearing Research, 27(1), 32–48. Retrieved from http://www.ncbi.nlm.nih.gov/pubmed/6717005
Boulenger, V., Hoen, M., Ferragne, E., Pellegrino, F., & Meunier, F. (2010). Real-time lexical competitions during speech-in-speech comprehension. Speech Communication, 52(3), 246–253. doi:10.1016/j.specom.2009.11.002
Brouwer, S., Van Engen, K. J., Calandruccio, L., & Bradlow, A. R. (2012). Journal of the Acoustical Socieity of America, 131, 1449–1464.
Brown, J. I. (1984). Efficient reading (6th ed.). Lexington: D. C. Heath and Company. Retrieved from http://www.worldcat.org/title/efficient-reading/oclc/10996103
Brown, J. I., Bennett, J. M., & Hanna, G. (1981). Nelson-Denny reading test. Chicago: Riverside.
Brungart, D. S. (2001). Informational and energetic masking effects in the perception of two simultaneous talkers. The Journal of the Acoustical Society of America, 109(3), 1101–1109. doi:10.1121/1.1345696
Brungart, D. S., Simpson, B. D., Ericson, M. A., & Scott, K. R. (2001). Informational and energetic masking effects in the perception of multiple simultaneous talkers. The Journal of the Acoustical Society of America, 110(5), 2527–2538. doi:10.1121/1.1408946
Burke, D. M., & Shafto, M. A. (2008). Language and aging. In F. I. M. Craik & T. A. Salthouse (Eds.), The handbook of aging and cognition (3rd ed., pp. 373–443). New York: Psychology Press.
Calandruccio, L., Dhar, S., & Bradlow, A. R. (2010). Speech-on-speech masking with variable access to the linguistic content of the masker speech. Journal of the Acoustical Society of America, 128(2), 860–869.
Carlson, M. C., Hasher, L., Zacks, R. T., & Connelly, S. L. (1995). Aging, distraction, and the benefits of predictable location. Psychology and Aging, 10(3), 427–436. Retrieved from http://www.ncbi.nlm.nih.gov/pubmed/8527063
Connelly, S. L., Hasher, L., & Zacks, R. T. (1991). Age and reading: The impact of distraction. Psychology and Aging, 6(4), 533–541. doi:10.1037/0882-7974.6.4.533
Craik, F. I. M., & Byrd, M. (1982). Aging and cognitive deficits: The role of attentional resources. In F. I. M. Craik & S. Trehub (Eds.), Aging and cognitive processes (pp. 191–211). New York: Plenum Press.
Daneman, M., & Carpenter, P. A. (1980). Individual differences in working memory and reading. Journal of Verbal Learning and Verbal Behavior, 19(4), 450–466. doi:10.1016/S0022-5371(80)90312-6
Darowski, E. S., Helder, E., Zacks, R. T., Hasher, L., & Hambrick, D. Z. (2008). Age-related differences in cognition: The role of distraction control. Neuropsychology, 22(5), 638–644. doi:10.1037/0894-4105.22.5.638
Diaz, M. T., Micah, A. J., Burke, D. M., & Madden, D. J. (2014). Journal of Cognitive Neuroscience, 26(12), 2798–2811.
Divenyi, P. L., & Haupt, K. M. (1997a). Audiological correlates of speech understanding deficits in elderly listeners with mild-to-moderate hearing loss. II. Correlation analysis. Ear and Hearing, 18(2), 100–113. Retrieved from http://www.ncbi.nlm.nih.gov/pubmed/9099559
Divenyi, P. L., & Haupt, K. M. (1997b). Audiological correlates of speech understanding deficits in elderly listeners with mild-to-moderate hearing loss. III. Factor representation. Ear and Hearing, 18(3), 189–201.
Drullman, R., & Bronkhorst, A. W. (2004). Speech perception and talker segregation: Effects of level, pitch, and tactile support with multiple simultaneous talkers. The Journal of the Acoustical Society of America, 116(5), 3090. doi:10.1121/1.1802535
Durlach, N. I., Mason, C. R., Shinn-Cunningham, B. G., Arbogast, T. L., Colburn, H. S., & Kidd, G. (2003). Informational masking: Counteracting the effects of stimulus uncertainty by decreasing target-masker similarity. The Journal of the Acoustical Society of America, 114(1), 368–379. doi:10.1121/1.1577562
Dywan, J., & Murphy, W. E. (1996). Aging and inhibitory control in text comprehension. Psychology and Aging, 11(2), 199–206. Retrieved from http://www.ncbi.nlm.nih.gov/pubmed/8795048
Egan, J. P., Carterette, E. C., & Thwing, E. J. (1954). Some factors affecting multi-channel listening. Journal of the Acoustical Socieity of America, 26, 774–782.
Ezzatian, P., Li, L., Pichora-Fuller, M. K., & Schneider, B. A. (2012). The effect of energetic and informational masking on the time-course of stream segregation: Evidence that streaming depends on vocal fine structure cues. Language & Cognitive Processes, 27(7-8), 1056–1088. doi:10.1080/01690965.2011.591934
Freyman, R. L., Balakrishnan, U., & Helfer, K. S. (2001). Spatial release from informational masking in speech recognition. Journal of the Acoustical Society of America, 109, 2112–2122.
Freyman, R. L., Helfer, K. S., McCall, D. D., & Clifton, R. K. (1999). The role of perceived spatial separation in the unmasking of speech. Journal of the Acoustical Society of America, 106, 3578–3588.
Frisina, D. R., & Frisina, R. D. (1997). Speech recognition in noise and presbycusis: Relations to possible neural sites. Hearing Research, 106, 95–104.
Frisina, D. R., Frisina, R. D., Snell, K. B., Burkard, R., Walton, J. P., & Ison, J. R. (2001). Auditory temporal processing during aging. In P. R. Hof & C. V. Mobb (Eds.), Functional neurobiology of aging (pp. 565–579). New York: Academic Press.
Guerreiro, M. J. S., Murphy, D. R., & Van Gerven, P. W. M. (2010). The role of sensory modality in age-related distraction: A critical review and a renewed view. Psychological Bulletin, 136(6), 975–1022. doi:10.1037/a0020731
Hasher, L., & Zacks, R. T. (1988). Working memory, comprehension, and aging: A review and a new view. In G. Bower (Ed.), The psychology of learning and motivation (Vol. 22, pp. 193–225). San Diego: Academic Press. Retrieved from http://www.sciencedirect.com/science/article/pii/S0079742108600419
Heinrich, A., & Schneider, B. A. (2006). Age-related changes in within- and between-channel gap detection using sinusoidal stimuli. Journal of the Acoustical Society of America, 119, 2316–2326.
Heinrich, A., & Schneider, B. A. (2011). Elucidating the effects of aging on remembering perceptually distorted word-pairs. Quarterly Journal of Experimental Psychology, 64, 186–205.
Heinrich, A., Schneider, B. A., & Craik, F. I. M. (2008). Investigating the influence of continuous babble on auditory short-term memory performance. Quarterly Journal of Experimental Psychology, 61, 735–751.
Helfer, K. S., & Wilber, L. A. (1990). Hearing loss, aging, and speech perception in reverberation and noise. Journal of Speech and Hearing Research, 33(1), 149–155. Retrieved from http://www.ncbi.nlm.nih.gov/pubmed/2314073
Hoen, M., Meunier, F., Grataloup, C.-L., Pellegrino, F., Grimault, N., Perrin, F., … Collet, L. (2007). Phonetic and lexical interferences in informational masking during speech-in-speech comprehension. Speech Communication, 49(12), 905–916. doi:10.1016/j.specom.2007.05.008
Humes, L. E., & Christopherson, L. (1991). Speech identification difficulties of hearing-impaired elderly persons: The contributions of auditory processing deficits. Journal of Speech and Hearing Research, 34(3), 686–693. Retrieved from http://www.ncbi.nlm.nih.gov/pubmed/2072694
Humes, L. E., Kidd, G. R., & Lentz, J. J. (2013). Auditory and cognitive factors underlying individual differences in aided speech-understanding among older adults. Frontiers in Systems Neuroscience, 7, 55.
Humes, L. E., Lee, J. H., & Coughlin, M. P. (2006). Auditory measures of selective and divided attention in young and older adults using single-talker competition. Journal of the Acoustical Society of America, 120, 2926–2937.
Humes, L. E., & Roberts, L. (1990). Speech-recognition difficulties of the hearing-impaired elderly: The contributions of audibility. Journal of Speech and Hearing Research, 33(4), 726–735. Retrieved from http://www.ncbi.nlm.nih.gov/pubmed/2273886
Jerger, J., Jerger, S., & Pirozzolo, F. (1991). Correlational analysis of speech audiometric scores, hearing loss, age, and cognitive abilities in the elderly. Ear and Hearing, 12(2), 103–109. doi:10.1097/00003446-199104000-00004
Kim, S., Hasher, L., & Zacks, R. T. (2007). Aging and a benefit of distractibility. Psychonomic Bulletin & Review, 14(2), 301–305. Retrieved from http://www.pubmedcentral.nih.gov/articlerender.fcgi?artid=2121579&tool=pmcentrez&rendertype=abstract
Levitt, H. (1971). Transformed up-down methods in psychoacoustics. The Journal of the Acoustical Society of America, 49(2B), 467–477. doi:10.1121/1.1912375
Li, L., Daneman, M., Qi, J., & Schneider, B. A. (2004). Does the information content of an irrelevant source differentially affect spoken word recognition in younger and older Adults? Journal of Experimental Psychology: Human Perception and Performance, 30, 1077–1091.
Lindenberger, U., & Baltes, P. B. (1994). Sensory functioning and intelligence in old age: A sensory connection. Psychology and Aging, 9, 339–355.
Lustig, C., Hasher, L., & Zacks, R. T. (2007). Inhibitory deficit theory: Recent developments in a “New View.”. In C. M. MacLeod & D. S. Gorfein (Eds.), Inhibition in cognition (pp. 145–162). Washington, DC: American Psychological Association. doi:10.1037/11587-008
McCoy, S. L., Tun, P. A., Cox, L. C., Colangelo, M., Stewart, R. A., & Wingfield, A. (2005). Hearing loss and perceptual effort: Downstream effects on older adults’ memory for speech. The Quarterly Journal of Experimental Psychology A, Human Experimental Psychology, 58(1), 22–33. doi:10.1080/02724980443000151
Murphy, D. R., Craik, F. I. M., Li, K., & Schneider, B. A. (2000). Comparing the effects of aging and background noise on short-term memory performance. Psychology and Aging, 15, 323–334.
Murphy, D. R., Daneman, M., & Schneider, B. A. (2006). Why do older adults have difficulty following conversations? Psychology and Aging, 21(1), 49–61. doi:10.1037/0882-7974.21.1.49
Murphy, D. R., McDowd, J. M., & Wilcox, K. A. (1999). Inhibition and aging: Similarities between younger and older adults as revealed by the processing of unattended auditory information. Psychology and Aging, 14(1), 44. doi:10.1037/0882-7974.14.1.44
Payne, B. R., Gross, A. L., Parisi, J. M., Sisco, S. M., Stine-Morrow, E. A. L., Marsiske, M., & Rebox, G. W. (2014). Modelling longitudinal changes in older adults' memory for spoken discourse: Findings from the ACTIVE cohort. Memory, 22(8), 990–1001.
Peters, R. W., Moore, B. C., & Baer, T. (1998). Speech reception thresholds in noise with and without spectral and temporal dips for hearing-impaired and normally hearing people. The Journal of the Acoustical Society of America, 103(1), 577–587. doi:10.1121/1.421128
Pichora-Fuller, M. K., Schneider, B. A., MacDonald, E., Pass, H. E., & Brown, S. (2007). Temporal jitter disrupts speech intelligibility. Hearing Research, 223, 114–121.
Pichora-Fuller, M. K., Schneider, B. A., & Daneman, M. (1995). How young and old adults listen to and remember speech in noise. Journal of the Acoustical Society of America, 97, 593–608.
Raven, J. C. (1965). The mill hill vocabulary scale. London: H.K. Lewis.
Rhebergen, K. S., Versfeld, N. J., & Wouter, A. D. (2005). Release from information masking by time reversal of native and non-native interfering speech. Journal of the Acoustical Society of America, 118, 1274–1277.
Rönnberg, J., Lunner, T., Zekveld, A., Sörqvist, P., Danielsson, H., Lyxell, B., … Rudner, M. (2013). The Ease of Language Understanding (ELU) model: theoretical, empirical, and clinical advances. Frontiers in Systems Neuroscience. 7 (31), 1–17. doi:10.3389/fnsys.2013.0003
Rossi-Katz, J., & Arehart, K. H. (2009). Message and talker identification in older adults: Effects of task, distinctiveness of the talkers’ voices, and meaningfulness of the competing message. Journal of Speech, Language, and Hearing Research, 52(2), 435–453. doi:10.1044/1092-4388(2008/07-0243)
Schneider, B. A., Avivi-Reich, M., Leung, C., & Heinrich, A. (2016). How age and linguistic competence affect memory for heard information. Frontiers in Psychology, 7, 618. doi:10.3389/fpsyg.2015.0618
Schneider, B. A., Avivi-Reich, M., & Daneman, M. (2016). How spoken language comprehension is achieved by older listeners in difficult listening situations. Experimental Aging Research, 42, 31–49.
Schneider, B. A., Daneman, M., Murphy, D. R., & Kwong See, S. T. (2000). Listening to discourse in distracting settings: The effects of aging. Psychology and Aging, 15(1), 110–125. doi:10.1037//0882-7974.15.1.110
Schneider, B. A., Li, L., & Daneman, M. (2007). How competing speech interferes with speech comprehension in everyday listening situations. Journal of the American Academy of Audiology, 18, 578–591.
Schneider, B. A., & Pichora-Fuller, M. K. (2001). Age-related changes in temporal processing: Implications for listening comprehension. Seminars in Hearing, 22, 227–239.
Schneider, B. A., Pichora-Fuller, M. K., & Daneman, M. (2010). Effects of senescent changes in audition and cognition on spoken language comprehension. In S. Gordon-Salant, R. D. Frisina, A. N. Popper, & R. R. Fay (Eds.), The aging auditory system: Springer handbook of auditory research (Vol. 34, pp. 167–210). New York: Springer. doi:10.1007/978-1-4419-0993-0
Sommers, M. S., Hale, S., Myerson, J., Rose, N., Tye-Murray, N., & Spehar, B. (2011). Listening comprehension across the adult lifespan. Ear and Hearing, 32(6), 775–781. doi:10.1097/AUD.0b013e3182234cf6
Tun, P. A., O'Kane, G., & Wingfield, A. (2002). Distraction by competing speech in young and older adult listeners. Psychology and Aging, 17, 453–467.
Vadin, K. I., Kuchinsky, S. E., Cute, S. L., Ahistrom, J. B., Dubno, J. R., & Eckert, M. A. (2013). The cingulo-opercular network provides word-recognition benefit. The Journal of Neuroscience, 33(48), 18979–18986.
Van Engen, K. J. (2010). Similarity and familiarity: Second language sentence recognition in first- and second-language multi-talker babblea. Speech Communication, 52, 943–953.
Van Engen, K. J., & Bradlow, A. R. (2007). Sentence recognition in native- and foreign-language multi-talker background noise. Journal of the Acoustical Society of America, 121, 519–526.
Van Rooij, J. C. G. M., Plomp, R., & Orlebeke, J. F. (1989). Auditive and cognitive factors in speech perception by elderly listeners. I: Development of test battery. The Journal of the Acoustical Society of America, 86(4), 1294–1309. doi:10.1121/1.398744
Wang, M., Wu, X., Li, L., & Schneider, B. A. (2011). The effects of age and interaural delay on detecting a change in interaural correlation: The role of temporal jitter. Hearing Research, 275, 139–149.
Zekveld, A. A., Heslenfeld, D. J., Festen, J. M., & Schoonhoven, R. (2006). Top-down and bottom-up processes in speech comprehension. NeuroImage, 32, 1826–1836.
Acknowledgments
This research was supported by grants from the Canadian Institutes of Health Research (MOP-15359, TEA-12497) and Natural Sciences and Engineering Research Council of Canada (RGPIN 2690-02, RGPIN 9952-13). The authors thank Jane Carey, Lulu Li, and Michelle Bae for assistance in recruiting participants and collecting data. The authors also thank James Qi for his work programming the experiments.
Author information
Authors and Affiliations
Corresponding author
Appendix
Appendix
When the research hypothesis is true, the ratio of the mean square in the numerator (MS num ) to the mean square in the denominator (MS den ) takes on a non-central F distribution, F non − cent [df num , df den , λ, x], whose parameters are the degrees of freedom in the numerator, df num , the degrees of freedom in the denominator, df den , and the noncentrality parameter, λ, with \( x=\frac{M{S}_{num}}{M{S}_{den}}. \) The larger the value of λ, the more likely it is that the null hypothesis will be rejected. When the null hypothesis is true, the ratio of MS num /MS den is distributed according to a central F distribution, F[df num , df den , f] with the same number of degrees of freedom and a noncentrality parameter equal to 0. The criterion separating the acceptance from the rejection region for a test of the null hypothesis with a type I error of α is the value of the F-ratio (x crit ) such that
The power of the test, β, therefore is β = 1 - \( \underset{0}{\overset{x_{crit}}{\int }}{F}_{non- cent}\left[d{f}_{num},d{f}_{den},\lambda, x\right]dx \)
In Experiment 1, the estimated value of λ for the main effect of Group was 40.743. The estimated power associated with this value of λ was .99995. We then investigated how power would be affected by a reduction in this noncentrality parameter. Reducing the value of λ to 25 % of is estimated value in Experiment 1 reduced the power to 0.8. Hence if equating all of the groups with respect to word recognition reduced the noncentrality parameter by 75 %, the probability of rejecting the null hypothesis given this reduction would be approximately 0.8. A further reduction of the value of λ to 20 % of is estimated value in Experiment 1 reduced the power to 0.7. Finally, if equating all groups with respect to word recognition reduced the value of λ by 90 % there still would be a 40 % chance of rejecting the null hypothesis.
Rights and permissions
About this article

Cite this article
Lu, Z., Daneman, M. & Schneider, B.A. Does increasing the intelligibility of a competing sound source interfere more with speech comprehension in older adults than it does in younger adults?. Atten Percept Psychophys 78, 2655–2677 (2016). https://doi.org/10.3758/s13414-016-1193-5
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13414-016-1193-5