
Abstract
A central function of the brain is to track the dynamic statistical regularities in the environment – such as what predicts what over time. How does this statistical learning process alter sensory and attentional processes? Drawing upon animal conditioning and predictive coding, we developed a learning procedure that revealed two distinct components through which prior learning-experience controls attention. During learning, a visual search task was used in which the target randomly appeared at one of several locations but always inside an encloser of a particular color – the learned color served to direct attention to the target location. During test, the color no longer predicted the target location. When the same search task was used in the subsequent test, we found that the learned color continued to attract attention despite the behavior being counterproductive for the task and despite the presence of a completely predictive cue. However, when tested with a flanker task that had minimal location uncertainty – the target was at the fixation surrounded by a distractor – participants were better at ignoring distractors in the learned color than other colors. Evidently, previously predictive cues capture attention in the same search task but can be better suppressed in a flanker task. These results demonstrate opposing components – capture and inhibition – in experience-driven attention, with their manifestations crucially dependent on task context. We conclude that associative learning enhances context-sensitive top-down modulation while it reduces bottom-up sensory drive and facilitates suppression, supporting a learning-based predictive coding account.
Similar content being viewed by others
Our sensory environment contains rich statistical regularities that also change from time to time. Discerning and tracking predictive relations is a central function of the brain. As we are discovering what predicts what, attention gradually drifts to the predictive features, imbuing them with a higher top-down priority than other features. At the same time, with higher attention priority, predictive features receive deeper processing in the sensory system. This raises the question, when the predictive relations no longer exist, do these predictive features continue to enjoy a higher attention priority, or are they easier to suppress, to allow attention to be better deployed to other information?
Addressing this question is crucial for understanding how attention is controlled or driven by prior learning experience (Aslin, 2014; Yu & Dayan, 2005) – that is, experience-driven attention. This basic question also has direct clinical relevance, for abnormal attentional bias, such as to threat, plagues the attention system of patients inflicted with anxiety disorders (Bar-Haim, Lamy, Pergamin, Bakermans-Kranenburg, & van Ijzendoorn, 2007), and training of attention allocation promises to modify maladaptive bias and reduce clinical symptoms (Bar-Haim, 2010; MacLeod & Clarke, 2015).
The ground work on experience-driven attention can be traced to Shiffrin and Schneider (1977). After multiple days of training in visual search for target objects, they found that when the target objects become irrelevant and a new set of objects become the targets, prior targets continue to attract attention and impede the detection of the current targets (see also Kyllingsbaek, Schneider, & Bundesen, 2001; Kyllingsbaek, Van Lommel, Sorensen, & Bundesen, 2014). This training-induced sensitization in attention has also been found to affect subsequent bistable perception, an effect that can last for days or longer (Tseng, Gobell, & Sperling, 2004; Tseng, Vidnyanszky, Papathomas, & Sperling, 2010).
Recent work has shifted gears to investigate persistent attentional effects after short-term learning of predictive relations. Short-term training can be sufficient for learning. For example, statistical regularities such as the spatial layout of objects (Chun & Jiang, 1998) and the probability map of target locations (Geng & Behrmann, 2002; Logan, 1998; Miller, 1988) can be learned within a few hundred trials to bias attention toward the target location. Importantly, recent studies have revealed that various attentional biases – such as a positive (Jiang, Swallow, Rosenbaum, & Herzig, 2013) or a negative (Lin & Murray, 2015) bias toward a location – can persist into an altered environment where the target appears equally likely at all potential locations and the attentional bias is no longer beneficial or warranted.
On the surface, these studies appear to suggest that when predictive relations no longer exist, the predictive features may continue to enjoy a higher attention priority. It is unclear, however, whether the continued manifestation of attentional bias in these studies reflects an involuntary process, since the potential performance cost of residual bias is minimal. Consider a visual search task with a set size of two and in which the target randomly appears at one of the two locations. Adopting a biased strategy by consistently prioritizing one location, or adopting a non-biased strategy by randomly prioritizing one of the two locations over trials, the outcome would be the same: the target would appear at the prioritized location half of the time. There is evidence that when the environmental statistics are altered in such a way that renders it suboptimal, learned attentional bias may not be automatic but depend on prior monetary rewards. For example, when two colors were predictive of the target location in training but were never associated with the target location during test, the colors could continue to attract attention during test, but only when they were also paired with monetary rewards during training – the effect was abolished when monetary rewards were omitted during training (Anderson, Laurent, & Yantis, 2011).
Besides being conflicted with each other, the studies above also give scant attention to the possible role of task context. That is, the tasks in these studies generally stay the same across learning and test (but see Tseng et al., 2004; Tseng et al., 2010). Yet in our typical interaction with the world, not only can environmental statistics change but the task context frequently changes as well (Yu & Dayan, 2005). Task context can play a crucial role in attention. For attention is not a singular process but consists of at least two distinct components – prioritization of some inputs, suppression of other inputs – that are called upon differently depending on the task. For example, searching for a person wearing a red hat entails primarily prioritization of the color red, whereas waiting at a red light that is flanked by a left-turn traffic signal requires suppressing the left-turn signal (not to release the brake when it turns green).
The critical question therefore becomes whether attentional bias persists when it becomes suboptimal, and how it may manifest when the task context changes. We hypothesized a central role of task context in determining how experience-driven attention manifests. This hypothesis is based on the close relation between task context and uncertainty in the framework of predictive coding theory. Specifically, according to predictive coding, the relative influence of top-down beliefs and bottom-up sensory evidence is determined by their degrees of certainty (also known as precision or reliability, see Friston, 2008; Kersten, Mamassian, & Yuille, 2004); the higher the certainty, the higher the weight. To the extent that a global, overt change in task context usually signals an increase in the uncertainty regarding whether a prior belief still holds (Bastos et al., 2012), attentional bias – a top-down modulation that reflects the brain’s internal prediction of the world – should be sensitive to task context. Accordingly, task context may determine the continued manifestation of an enhanced top-down priority: when the task continues to entail spatial uncertainty and require spatial guidance, previously predictive cues may continue to attract attention; however, when the task changes to require attentional suppression (such as in a flanker task), previously predictive cues may no longer capture attention. Instead, considering that associative learning can lead to a reduction in sensory responses (Makino & Komiyama, 2015), we speculate that a task-irrelevant flanker in a previously predictive color may be easier to suppress, resulting in a weaker interference effect on target processing.
To test this hypothesis – that predictive features may continue to capture attention when the task context is the same, but may be easier to suppress when the task context changes to require inhibition – we adopted an associative learning procedure with a learning phase and a test phase. During learning, a target randomly appeared at one of several locations but always within an encloser of a particular color. During test, either the same search task was used but the color–target association was removed (Experiments 1–3), or a completely different task was used with minimal location uncertainty by presenting the target at the fixation surrounded by a distractor (flanker task; Experiments 4 and 5). The results showed that whereas the learned color continued to attract attention in the subsequent search task despite such behavior being suboptimal, in the flanker task distractors were better suppressed when they were in the learned color than in other colors. These findings reveal a crucial role of task context in determining how experience-driven attention unfolds – either capture or inhibition – and provide novel behavioral evidence for a learning-based predictive coding account, in which associative learning enhances context-sensitive top-down modulation while reduces bottom-up sensory drives and facilitates suppression.
Experiment 1
Method
Participants and apparatus
Sixteen college students (11 females, five males; mean age 21.6 years) with normal or corrected-to-normal vision participated in return for money or course credit. All participants in this and subsequent experiments signed a consent form approved by the local institutional review board. The sample size was based on a study using a similar visual search procedure (Anderson et al., 2011).
The participants were separated into two groups (n = 8 each): one group received accuracy feedback on each trial (feedback group); the other group did not receive any feedback (no-feedback group). For the feedback group, the stimuli were presented on a black-framed, gamma-corrected 22-in. CRT monitor (model = Hewlett-Packard p1230; refresh rate = 100 Hz, resolution = 1,024 × 768 pixels) using MATLAB (The MathWorks, Natick, MA, USA) and the Psychophysics Toolbox (Brainard, 1997; Pelli, 1997). Participants sat approximately 57 cm from the monitor while an experimenter was present. A chin rest was used to stabilize head position. The testing room had no lighting except from the computer and the monitor. For the no-feedback group, the setup was similar, except that the stimuli were presented on a black-framed 21-in. CRT monitor (model = Sony G520; refresh rate = 60 Hz; resolution = 1,024 × 768 pixels) and the viewing distance was approximately 80 cm.
Stimuli and procedure
The experiment began with a 2-min, computerized fixation training session (as in, e.g., Lin & He, 2012). During fixation training, a central dot appeared on top of a background image. The task was to fixate on the dot. Fixation stability was visualized through the appearance of the background image such that when the fixation deviated from the dot, a flash of visual noise would appear on the background image (Guzman-Martinez, Leung, Franconeri, Grabowecky, & Suzuki, 2009).
After completing fixation training, participants proceeded to the main experiment. There were two phases: a learning phase and a test phase. The learning phase included 30 practice trials in one block and 600 experimental trials in ten blocks; the test phase included 256 experimental trials in four blocks.
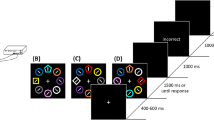
Figure 1a illustrates the procedure. In the learning phase, each trial started with a white fixation dot (diameter = 0.31°; luminance = 80.2 cd/m2) on a black background for a random duration of 400, 500, or 600 ms. The fixation was then followed by four color circles, one each in red, green, blue, and yellow (diameter = 1.6°; line width = 0.08°). The circles were equidistant from the fixation (distance from circle center to fixation = 1.5°), occupying four corners of an imaginary diamond. After a 200-ms presentation of the circles, four letters – a letter T and three letter Ls (size = 0.8° × 0.8°; in white; luminance = 80.2 cd/m2) – appeared within the circles for 800 ms (or until response). The task was to indicate whether the letter T was rotated 90° counterclockwise (i.e., left-rotated) or clockwise (i.e., right-rotated). Participants were asked to respond as quickly as possible while minimizing errors and before the letters disappeared (otherwise the trial was considered incorrect). The three Ls were rotated as well; the degree of rotation for each letter was different from each other, randomly selected on each trial from the following four possible rotations: 0°, 90°, 180°, and 270° counterclockwise.

Task design and results in Experiment 1. (a) The task in both the learning and test phases was to report whether the letter T was rotated to the left or right. Feedback on response accuracy – a minor sign if the response was incorrect, a plus sign if correct – was provided for half of the participants, but was omitted for the other half. (b) During learning, though not explicitly mentioned to the participants, the letter T always appeared within the red circle or within the green circle, counterbalanced across participants (learned color); the letter Ls appeared within circles in other colors (non-learned colors). During test, this association was removed – the letter T now appeared equally often within each circle. (c) Responses were faster when the letter T appeared within the circle in the learned color than in a non-learned color (total n = 16). This attentional bias did not depend on response feedback and it was fairly consistent across the four blocks tested. Error bars are standard errors of the mean
Crucially, though not explicitly told to the participants, the target letter T always appeared within the green circle (for half of the participants) or within the red circle (for the other half). In the feedback group, feedback on response accuracy was provided – a minus sign after an incorrect response, a plus sign after a correct one, appearing at the fixation for 1,000 ms (during practice, each incorrect response was also followed by a re-display of the original letters without the circles for 2 s). The feedback sign was followed by a 1,000-ms blank screen before the next trial started. In the no-feedback group, the feedback sign was replaced by a blank screen.
After completing the learning phase, participants proceeded to the test phase. The task was the same visual search task as in the learning phase, but with two major procedural changes. First and foremost, the target letter T now appeared equally often within each color circle: on one-fourth of trials, the target appeared within the circle in the previously predictive color (learned color); on the remaining three-fourths of trials, the target appeared within the circle in one of the other three colors (non-learned colors). Second, because the task was more difficult without a predictive cue, the target duration was increased from 800 ms to 1,200 ms. Participants were explicitly instructed that “colors/circles are irrelevant to the task and should be ignored.”
Data analysis
The primary focus was on the test. There was one within-subjects variable, target color (two levels: learned color vs. non-learned colors), and one between-subjects variable, response feedback (two levels: feedback group vs. no-feedback group).
In this and subsequent experiments, we focused on reaction times (RTs) from correct trials. RTs outside of three standard deviations in each condition were considered outliers and excluded from analysis (this procedure excluded 0.8 % trials). The same pattern of results held when outliers were not excluded.
Results
Inspired by the blocking effect in animal conditioning (Kamin, 1968) – the presence of a conditioned stimulus (associated with an unconditioned stimulus) retards learning the association between a second conditioned stimulus and the unconditioned stimulus – the main methodological innovation in Experiment 1 involved designating only one color – instead of two colors (Anderson et al., 2011) – as being predictive of the target location during training.
We first evaluate the learning process. Figure 2 shows how the RT changed across blocks in the learning phase. To evaluate learning, we fitted the learning curve using the mathematical expression, A + B × e −t/T, with three parameters: A, initial performance; B, maximum amount of learning; and T, the time constant for learning, which determines the shape of the curve (i.e., the learning rate). This learning model was compared with a one-parameter model that assumed no learning (i.e., B = 0). Table 1 summarizes the results. The learning model fitted the data well (r 2 close to 1) and significantly outperformed the no-learning model. Learning of the predictive cue–target relation was further confirmed by a large increase of RT in the test phase (when the predictive relation was removed) relative to the last block of the learning phase (feedback group: 566.8 ms vs. 434.4 ms, t(7) = 3.54, P = 0.010, d = 1.25; no-feedback group: 560.4 ms vs. 416.5 ms, t(7) = 7.29, P < 0.001, d = 2.58).

Reaction time (RT) results from the learning phase in Experiments 1–5. The letter enclosers appeared earlier than the letters in Experiment 1, but they appeared simultaneously in Experiments 2–5; the set size was four in Experiments 1 and 2, and six in Experiments 3–5. Each block included 60 trials. In all experiments, RT steadily decreased during learning (see also Table 1). The error rates results are provided in Fig. 7 in Appendix. The shaded area on each side of the line represents, for clarity, half of the standard errors of the mean
To understand how previously predictive cues affect subsequent attention deployment, next we turn to the test phase. As Fig. 1c shows, although the learned color no longer predicted the target location, responses were much faster, by 49.4 ms, when the target appeared within the circle in the learned color than in a non-learned color (538.9 ms vs. 588.3 ms). This attentional bias toward the previously predictive cue was confirmed by a mixed analysis of variance (ANOVA) with target color and response feedback as the two factors, which revealed only a significant main effect of target color (F(1, 14) = 10.97, P = 0.005, η 2 p = 0.44); the target color main effect did not interact with response feedback (attentional bias in the group with response feedback, 49.7 ms, without feedback, 51.4 ms; F(1, 14) < 0.01, P = 0.986, η 2 p < 0.01). There were no differences in error rates (learned color vs. non-learned color, 6.0 % vs. 6.8 %; all P > 0.19). These results demonstrate an attentional bias to an uninformative, perceptually nonsalient cue that was previously predictive of the target.
The attentional bias to the previously predictive color was robust across the blocks tested (blocks 1–4: 56.4 ms, 46.2 ms, 54.2 ms, and 27.6 ms). An ANOVA with the factors target color and block revealed only a main effect of target color (F(1, 15) = 11.19, P = 0.004, η 2 p = 0.43), which did not interact with block (F(3, 45) = 1.19, P = 0.325, η 2 p = 0.07). Error rates showed the same pattern as RT (attentional bias in blocks 1–4: 1.0 %, 2.6 %, 2.6 %, and −1.3 %; main effect of target color, (1, 15) = 4.22, P = 0.058, η 2 p = 0.22; other effects, all P > 0.09).
Experiment 2
The effect of learned attentional bias observed in Experiment 1 accorded with a traditional interpretation of attentional capture (Folk, Remington, & Johnston, 1992). This finding is also consistent with the observation in visual search that when two strategies are equally viable – searching for a specific feature versus searching for a singleton – participants’ choice of the strategy can be biased toward the one being used in prior training (Leber & Egeth, 2006). To further test whether attentional bias can manifest even when it is suboptimal for task performance, Experiment 2 used a test in which the target never appeared within the circle in the learned color.
Method
Participants and apparatus
A new group of 16 college students (12 females, four males; mean age 20.3 years) participated.
Stimuli and procedure
The task design was the same as the feedback group in Experiment 1 except for one critical difference and a few minor changes. During the test, the learned color only appeared on half of the trials, and on those trials a letter L, but never the target letter T, appeared within the learned-color circle. Because the learned color was absent in some trials, this procedure required a set of five colors as opposed to four; the color set now included red, green, blue, yellow, and (newly added) cyan.
Other differences were minor, as described below. As Fig. 3a illustrates, in the learning phase, the 200-ms head-start of the cue circles was omitted such that the circles and the letters now appeared simultaneously. As before, the predictive color was red or green, counterbalanced across participants, but the three colors for the three Ls were randomly selected without replacement from the remaining four colors in the color set. In total, the learning phase included 30 practice trials in one block and 600 experimental trials in ten blocks; the test phase included one block of 24 practice trials (which did not include the learned color) and 288 experimental trials in four blocks. To the extent that these minor changes in the procedure and the stimuli were orthogonal to color–target association, these changes helped to test the robustness of the effect.

Task design and results in Experiment 2. (a) The task was to report whether the letter T was rotated to the left or right; feedback on response accuracy was provided. (b) During learning the letter T was always within the learned-color circle; during test the learned color only appeared on half of the trials, in which a letter L, but never the target letter T, appeared within the learned-color circle. (c) Responses were faster when the learned color was absent than when it was present (in these trials a letter L was within the learned-color circle; n = 16). Error bars are standard errors of the mean
Data analysis
There was one within-subjects variable in the test: target color (two levels: learned-color absent vs. learned-color present).
Results
Figure 2 shows the results in the learning phase, which is well accounted for by the learning model (as detailed in Table 1). Learning of the predictive cue–target relation was further confirmed by a large increase of RT in the test phase relative to the last block of the learning phase (596.1 ms vs. 495.0 ms, t(15) = 9.02, P < 0.001, d = 2.26).
More important are the results from the test phase, where the target T never appeared within the learned-color circle. As Fig. 3c shows, responses were modestly faster, by 12.1 ms, when the learned color was absent than when it appeared but a distractor was inside the learned-color circle (590.1 ms vs. 602.1 ms; t(15) = −2.49, P = 0.025, d = −0.62). Error rates were comparable between the two conditions (5.3 % vs. 4.9 %; t(15) = 0.84, P = 0.417, d = −0.21).
This attentional bias to the learned color was largely consistent across blocks. An ANOVA on target color and block revealed a main effect of target color (F(1, 15) = 4.40, P = 0.053, η 2 p = 0.23), which did not interact with block order (blocks 1–4: 10.9 ms, 15.4 ms, −2.9 ms, and 17.9 ms; F(3, 45) = 1.47, P = 0.236, η 2 p = 0.09) – though note the apparent lack of an effect in block 3 (−2.9 ms), which might possibly reflect the noisy nature of the data. Error rates were consistent across blocks (attentional bias in blocks 1–4: −0.6 %, −0.4 %, 0.7 %, and 0.5 %; all P > 0.76).
Taken together, these results suggest that attention is biased to the previously predictive cue even when the environmental statistics are changed to render the bias detrimental for performance.
Experiment 3
To further test whether attentional bias can persist into the test phase when a new cue is presented that completely predicts the target location, Experiment 3 used a test in which color did not predict the target location, but shape did: the target was always inside a square shape, and the non-targets inside circles.
Method
Participants and apparatus
A new group of 16 college students (13 females, three males; mean age 20.7 years) participated.
Stimuli and procedure
The task design was the same as the feedback group in Experiment 1 except for one critical difference and a few minor changes. During test, the target T always appeared within a square shape (side length = 1.6°; line width = 0.12°), whereas the Ls appeared within circles. The learned color appeared on only half of the trials; in these learned-color–present trials, each of the five letter Ls and the target letter T were equally likely to be inside an encloser in the learned color. Participants were explicitly instructed to focus on the square shape to find the letter T and were informed that the color of the square was random and irrelevant to the task.
Other differences were minor, as described below. As Fig. 4a illustrates, the target display in the learning phase now included six color circles (diameter = 1.8°; line width = 0.12°); they were equidistant from the fixation cross (circle center to fixation distance = 3°), occupying six corners of an imaginary hexagon for 1,000 ms. The color set included seven colors: red, green, blue, yellow, cyan, pink, and gray. As before, the predictive color was red or green, counterbalanced across participants. The five colors for the five Ls were randomly selected without replacement from the remaining six colors of the color set. The five Ls were rotated: two Ls were rotated to the same degree, 0°, 90°, 180°, or 270° counterclockwise; the other three Ls were rotated based on the three remaining degrees of rotation. In addition, unlike Experiments 1 and 2, participants in this experiment were explicitly informed about the predictive nature of the color on the target location. In total, the learning phase included 30 practice trials in one block and 360 experimental trials in six blocks; the test phase included one block of 12 practice trials (which did not include the learned color) and 288 experimental trials in four blocks. As before, given that these incidental changes were orthogonal to color–target association, these changes served to test the robustness of the effect.

Task design and results in Experiment 3. (a) The task was to report whether the letter T was rotated to the left or right; feedback on response accuracy was provided. The set size was six (as opposed to four in Experiments 1 and 2). (b) During learning the letter T was always within the learned-color circle and participants were explicitly informed of this association. During test the learned color appeared on only half of the trials, during which each of the six letters – five Ls and one T – was equally likely to be within the learned-color encloser (1/6 probability). Crucially, participants were explicitly told that the letter T in the test would always appear within a square, whereas the five Ls would appear within circles. (c) Responses were slower when the learned color appeared in a circle enclosing a letter L than when it was absent; responses were faster when the learned color appeared in the square enclosing the letter T than when it was absent (n = 16). Error bars are standard errors of the mean
Data analysis
There was one within-subjects variable in the test: target color (three levels: learned color absent, learned color with letter T vs. learned color with letter L).
Results
Figure 2 shows the results in the learning phase, which is well accounted for by the learning model (as detailed in Table 1). Learning of the predictive cue–target relation was further confirmed by a large increase of RT in the test phase relative to the last block of the learning phase (587.9 ms vs. 540.8 ms, t(15) = 3.26, P = 0.005, d = 0.82).
The critical results are the test phase, where the learned color was no longer predictive, but instead the target T always appeared within a square (with the Ls within circles). As Fig. 4c shows, responses were faster, by 35.3 ms, when the target T appeared within the learned-color square than when an L appeared within the learned-color circle (valid vs. invalid: 569.5 ms vs. 604.8 ms; t(15) = −3.27, P = 0.005, d = −0.82). Compared with when the learned color was absent, responses were faster when the target appeared within the learned-color square, by 20.0 ms (valid vs. neutral: 569.5 ms vs. 589.5 ms; t(15) = −2.27, P = 0.038, d = −0.57) but slower when an L appeared within the learned-color circle, by 15.3 ms (invalid vs. neutral: 604.8 ms vs. 589.5 ms; t(15) = 3.63, P = 0.002, d = 0.91). Error rates were comparable across the three conditions (with T, absent, vs. with L: 5.7 %, 5.4 %, vs. 5.6 %; all P > 0.71).
This attentional bias to the learned color was overall consistent across blocks (blocks 1–4, invalid – valid: 39.2 ms, 14.1 ms, 13.4 ms, and 19.4 ms; neutral – valid: 7.3 ms, −3.7 ms, 4.9 ms, and 12.0 ms; invalid – neutral: 31.9 ms, 17.7 ms, 8.5 ms, and 7.4 ms). An ANOVA on target color and block did not reveal a significant main effect or interaction (all P > 0.17). Although the capture effect to the distractor L within the learned-color circle appeared to decline as the test progressed, a separate ANOVA on target color (invalid, neutral) and block revealed only a main effect of target color (F(1, 15) = 10.11, P = 0.006, η 2 p = 0.40), which did not interact with block (F(3, 45) = 1.66, P = 0.189, η 2 p = 0.10). Error rates showed the same pattern (blocks 1–4, invalid – valid: 2.7 %, −0.7 %, 2.1 %, and 1.2 %; neutral – valid: 3.0 %, −0.2 %, 2.4 %, and 0.3 %; invalid – neutral: −0.3 %, −0.5 %, −0.3 %, and 1.0 %); an ANOVA on target color and block did not reveal a significant main effect or interaction (all P > 0.34).
Taken together these results reveal that attention is spontaneously drawn to the previously predictive cue (e.g., the color green) even when top-down attention is set to a different feature that completely predicts the target location (e.g., a square shape).
Experiment 4
Experiments 1–3 revealed persistent attentional bias despite it being counterproductive. Attentional bias may then be considered a habitual response. If so, to the extent that “habit responses are cued by contexts” (p. 845, Wood & Neal, 2007), one may expect to see a crucial role of task context in determining how learned attentional bias manifests. This idea finds support from predictive coding, in which associative learning is thought to provide top-down predictions that are “necessarily context sensitive” (p. 698, Bastos et al., 2012).
To test the role of task context, Experiment 4 used a completely different task during test, a flanker task. The target was now at the fixation, surrounded by an enclosing distractor. By minimizing location uncertainty, spatial guidance was no longer required to find the target in the test. The effect of color was measured by the degree of shape-based response interference from the distractor.
Method
Participants and apparatus
A new group of 22 college students (13 females, nine males; mean age 21.9 years) participated. Because the test was different from that used in previous experiments, we aimed to include as many participants as possible before the semester ended.
Stimuli and procedure
The learning phase was the same as that in Experiment 3 except as noted here. On each trial the letter enclosers were equally likely to be all circles or all squares (as opposed to be circles only). As before, the predictive color was red or green, counterbalanced between participants, but the colors of the five Ls were randomly selected without replacement from the set of seven colors that excluded red and green. In other words, if green was the learned color, then red would never appear in learning (red would serve as the new color for the subsequent test), and vice versa.
The most crucial change was the task in the test. Instead of visual search, the test used a different task: a flanker response-competition task (Fig. 5a). The target display consisted of an inner object at the fixation (target) and an encloser (distractor). The task was to indicate whether the inner object was a circle (diameter = 0.78°; line width = 0.08°) or a square (side length = 0.66°; line width = 0.08°), while ignoring the encloser, which could also be a circle (diameter = 1.8°; line width = 0.16°) or a square (side length = 1.8°; line width = 0.16°). The display was presented for 2,000 ms (or until response). Critically, the colors of the target and distractor were manipulated. The color set included red, green, and yellow, with four combinations of colors for the target and the distractor: when the distractor was in a non-learned color (yellow), the target could be in the learned color or in the new color; and when the target was in a non-learned color (yellow), the distractor could be in the learned color or in the new color. Feedback for response accuracy was provided – a 1,200-ms minus sign at the fixation after each incorrect response, a 400-ms plus sign after each correct one. In total, the learning phase included 30 practice trials in one block and 480 experimental trials in eight blocks; the test phase included 12 practice trials and 144 test trials in two blocks.

Task design and results in Experiment 4. (a) Whereas the learning phase employed a visual search task, the test phase used a flanker response-competition task. Participants indicated whether the inner shape (target) was a circle or a square while ignoring the enclosing shape (distractor). The two shapes could be the same (congruent) or different (incongruent); the difference in performance between the two conditions was the flanker effect, indexing the interference arising from the processing of the enclosing shape. Feedback on response accuracy was provided. (b) When the encloser color was a non-learned color (yellow), the flanker effect was similar whether the target color was the learned color (e.g., green) or a new color not used previously during learning (e.g., red). However, when the target color was a non-learned color (yellow), the flanker effect was much reduced when the encloser was in the learned color (e.g., green) than in the new color (e.g., red; n = 22). Error bars are standard errors of the mean
Data analysis
There was one within-subjects variable in the test: target–distractor colors (four levels: target in the learned color vs. the new color, when the distractor color was the non-learned color; distractor in the learned color vs. the new color, when the target color was the non-learned color).
Results
Figure 2 shows a marked reduction in RT during the learning phase, which was well captured by the learning model as detailed in Table 1. The main focus is on the test phase.
Given that during learning color helped to guide the deployment of spatial attention to the target location whereas during test such spatial guidance was no longer needed, we did not expect the color of the target to play a substantial role in determining the extent of distractor interference in the test. This expectation was consistent with the data (Fig. 5b): when the enclosing distractor was a non-learned color (yellow), the interference effect from the distractor, as measured by the flanker effect, was not strongly modulated by the target color (learned color vs. new color: 26.4 ms vs. 34.7 ms; t(21) = −0.88, P = 0.390, d = −0.19). This pattern held for both components in the flanker effect, that is, when the target and distractor were congruent (learned color vs. new color: 493.7 ms vs. 493.5 ms; t(21) = 0.03, P = 0.977, d = 0.01) and incongruent (520.1 ms vs. 528.2 ms; t(21) = −1.35, P = 0.191, d = −0.29). Error rates showed the same pattern (congruent: 3.8 % vs. 4.0 %; incongruent: 5.7 % vs. 5.7 %; flanker effect: 1.9 % vs. 1.7 %; all P > 0.19).
The critical test is how the encloser color affected participants’ ability to ignore the encloser shape, as indexed by the flanker effect. If the learned color automatically and irresistibly captures attention regardless of the task context, then one would expect to see a larger flanker effect when the encloser was in the learned color than in a new color. On the other hand, if attentional capture to the learned color is not automatic but context dependent, then because the target location was fixed in the test and could be spatially prioritized, attention might not be biased to the learned color. Considering that the learned color was more “familiar” than the new color due to associative learning (Makino & Komiyama, 2015; Summerfield, Trittschuh, Monti, Mesulam, & Egner, 2008; Tong & Nakayama, 1999), it seems plausible that the learned color might be easier to suppress. If so, one would expect to see a smaller flanker effect when the encloser was in the learned color than in a new color.
The results support the familiarity account but not the automatic capture account. When the target color was a non-learned color (yellow), the flanker effect was much reduced for the encloser in the learned color than the new color (28.9 ms vs. 52.7 ms; t(21) = −3.26, P = 0.004, d = −0.70). The difference in the flanker effect manifested to a smaller degree in the congruent condition (learned color vs. new color: 500.0 ms vs. 489.9 ms; t(21) = 1.75, P = 0.095, d = 0.37) and to a larger degree in the incongruent condition (528.9 ms vs. 542.7 ms; t(21) = −2.87, P = 0.009, d = −0.61).
The above RT effect might be contaminated by speed–accuracy tradeoff, as error rates showed flanker effects in the reverse pattern between the learned color and the new color (2.1 % vs. −0.4 %; t(21) = 2.38, P = 0.027, d = 0.51; congruent: 3.7 % vs. 5.0 %, t(21) = −1.75, P = 0.094, d = −0.37; incongruent: 5.8 % vs. 4.6 %, t(21) = 1.52, P = 0.143, d = 0.32). To test whether speed–accuracy tradeoff alone could account for the RT effect, we excluded the top participants showing the largest reverse effects in error rates until the error-rate flanker effect was equated between the two conditions (for a similar procedure, see Lavie, Lin, Zokaei, & Thoma, 2009); this procedure excluded five participants. The RT results from the remaining participants, which were free from speed–accuracy tradeoff (error-rate flanker effects were comparable between the two color conditions; t(16) = 1.04, P = 0.316, d = 0.25), corroborated the original finding: the flanker effect was again much smaller when the encloser was in the leaned color than the new color (t(16) = −3.62, P = 0.002, d = −0.88).
We next look at the block-by-block time course of the flanker effect. As indicated above, in aggregate the flanker effect was relatively unaffected by the target color (learned color vs. new color: 26.4 ms vs. 34.7 ms). This pattern in flanker effects was consistent across the four blocks tested (learned color vs. new color, blocks 1–4: 29.1 ms vs. 31.5 ms; 26.9 ms vs. 33.1 ms; 23.1 ms vs. 42.3 ms; and 17.9 ms vs. 25.3 ms). An ANOVA on target color and block revealed neither a main effect of target color nor its interaction with block (all P > 0.33). The same was true in error rates (all s > 0.76).
On the other hand, the effect of distractor color – that in aggregate the flanker effect was reduced for the encloser in the learned color than the new color (28.9 ms vs. 52.7 ms) – was particularly pronounced in blocks 1 and 4 relative to blocks 2 and 3 (learned color vs. new color, blocks 1–4: 17.8 ms vs. 54.4 ms; 42.4 ms vs. 42.6 ms; 43.5 ms vs. 47.2 ms; and 3.8 ms vs. 62.7 ms). An ANOVA on target color and block revealed a main effect of target color (F(1, 21) = 10.70, P = 0.004, η 2 p = 0.34) that appeared to interact with block (F(3, 63) = 2.55, P = 0.064, η 2 p = 0.11). Error rates showed only a main effect of target color (F(3, 63) = 4.65, P = 0.043, η 2 p = 0.18).
Experiment 5
Experiment 5 aimed to replicate and extend Experiment 4 in two ways. First, to contrast the interference effect arising from distractors in the learned color relative to a non-learned color (rather than to a new color), so as to minimize potential differences in visual novelty (Anderson, Laurent, & Yantis, 2012) – the learned color and the non-learned color appeared equally often during training. Second, to examine whether better attentional filtering of distractors in the learned color could generalize to novel shapes not present during training.
Method
Participants and apparatus
Forty-four college students (24 females, 20 males; mean age 20.5 years) participated. They were separated into two groups (n = 22 each): the old-shape group and the new-shape group. Two participants in the old-shape group were replaced due to low accuracy in the test (accuracy outside of three standard deviations).
Stimuli and procedure
The task design was identical to Experiment 4 except for two major modifications. First, the shapes used in learning and test were varied across the two groups (Fig. 6a). For the old-shape group, as in Experiment 4, the shapes in the flanker test were the same as the visual search task (circle and square); for the new-shape group, the shapes in the flanker test (square and diamond) were distinct from the visual search task (circle). Second, for both groups, the color relation between the target and the distractor in the test was modified so that either the target color was the learned color (e.g., red) and the distractor was the non-learned color (e.g., green), or the reverse (Fig. 6b). In other words, the two pairs of colors had identical constituent colors.

Task design and results in Experiment 5. (a) In the old-shape group, the shapes in the flanker test were the same as those used in the visual search task; in the new-shape group, the shapes were distinct. (b) In the flanker test, the target color and the encloser color were always in reverse. (c) For both the old-shape group and the new-shape group (n = 22 each), the flanker effect was significantly reduced when the encloser was in the learned color (e.g., green) than in the non-learned color (e.g., red). Error bars are standard errors of the mean
Other differences were minor, as described below. For both groups, in the learning phase, the colors of the five Ls were randomly selected without replacement from the set of seven colors excluding only the learned color (as opposed to excluding both red and green). In other words, if green was the learned color, then red would be the non-learned color, and vice versa. The learning phase included 30 practice trials in one block and 480 learning trials in eight blocks; the test phase included 12 practice trials and 144 test trials in two blocks.
Data analysis
There were two factors in the test: one within-subjects variable, target–distractor colors (two levels: target in the learned color and distractor in the non-learned color vs. the reverse); one between-subjects variable, group (two levels: old-shape group vs. new-shape group).
Results and discussion
As before, Fig. 2 reveals the RT reduction during the learning phase, which was captured by the learning model (see Table 1). The main interest is the test phase, which used a flanker task. Here, the learned color was pitted against the non-learned color instead of a new color. A mixed ANOVA on the flanker effect with two factors, target–distractor colors and group, showed a main effect of target–distractor colors (F(2.5, 105.2) = 32.22, P < 0.001, η 2 p = 0.43), which did not interact with group (F(2.5, 105.2) = 0.86, P = 0.449, η 2 p = 0.02). The main effect of group was also significant (F(1, 42) = 17.17, P < 0.001, η 2 p = 0.29), showing faster overall RT in the old-shape group than in the new-shape group. Because the overall RTs of two groups differed substantially, we examined each group separately.
In the old-shape group, as Fig. 6b shows, replicating Experiment 4, the flanker effect was much reduced when the encloser was in the learned color than in the non-learned color (17.3 ms vs. 30.9 ms; t(21) = −3.53, P = 0.002, d = −0.75). The difference in the flanker effect manifested primarily in the incongruent condition (learned color vs. non-learned color: 477.2 ms vs. 490.7 ms; t(21) = −4.21, P < 0.001, d = −0.90) rather than in the congruent condition (459.9 ms vs. 459.8 ms; t(21) = 0.04, P = 0.970, d < 0.01). Error rates showed the same direction as the RT effects (congruent: 4.7 % vs. 4.7 %; incongruent: 7.6 % vs. 9.8 %; flanker effect: 2.9 % vs. 5.2 %; all P > 0.11).
Analysis of the block-by-block time course of the flanker effect revealed a consistent pattern across blocks (learned color vs. non-learned color, blocks 1–2: 20.6 ms vs. 27.4 ms and 14.7 ms vs. 27.7 ms). An ANOVA on target–distractor colors and block revealed only a main effect of target–distractor colors (F(1, 21) = 7.15, P = 0.014, η 2 p = 0.25), which did not interact with block (F(1, 21) = 0.13, P = 0.723, η 2 p < 0.01). There were no significant effects in error rates (all P > 0.13).
The results from the new-shape group additionally revealed that better attentional filtering of distractors in the learned color could generalize to novel shapes. Participants in the new-shape group also showed a reduced flanker effect when the encloser was in the learned color than in the non-learned color (20.6 ms vs. 41.3 ms; t(21) = −2.48, P = 0.022, d = −0.53). The difference in the flanker effect between the two color conditions manifested in the incongruent condition (learned color vs. non-learned color: 550.6 ms vs. 562.1 ms; t(21) = −1.42, P = 0.171, d = −0.30) and the congruent condition (530.0 ms vs. 520.8 ms; t(21) = 1.90, P = 0.071, d = 0.40). Error rates showed the same direction as the RT effects (congruent: 5.6 % vs. 6.0 %; incongruent: 9.1 % vs. 11.1 %; flanker effect: 3.5 % vs. 5.0 %; all P > 0.10).
Additional analysis on the block-by-block time course of the flanker effect showed a consistent pattern across blocks (learned color vs. non-learned color, blocks 1–2: 37.4 ms vs. 45.1 ms and 12.1 ms vs. 37.8 ms). An ANOVA on target–distractor colors and block revealed only a main effect of target–distractor colors (F(1, 21) = 3.44, P = 0.078, η 2 p = 0.14), which did not interact with block (F(1, 21) = 0.78, P = 0.387, η 2 p = 0.04). There were no significant effects in error rates (all P > 0.15).
In principle, a reduction in the flanker effect can be attributed to better distractor filtering, or more efficient target processing, or both. Experiment 4 showed that the flanker effect was not strongly modulated by the target color, implicating a more prominent role of distractor filtering. In the current experiment, because the target color and the distractor color co-varied, the role of target processing could not be definitely ruled out. A reduction in the flanker effect when the encloser was the learned color relative to the non-learned color is consistent with either one of the two possibilities: better filtering of the encloser in the learned color relative to the non-learned color, or more efficient processing of the target in the non-learned color relative to the learned color. Additional research is therefore needed to resolve this ambiguity – and to replicate the current findings.
General discussion
Inspired by animal conditioning and predictive coding, we developed an attention learning procedure to reveal that when environmental statistics changed that rendered previous attentional bias – specifically, the association of a color to the target location – suboptimal, bias to the learned color nevertheless persisted to guide spatial attention. However, when the task setting eliminated the need for spatial guidance of attention and instead required suppression, not only was attentional bias to the learned color eliminated, but participants were actually better at suppressing distractors in the learned color than other colors. These results demonstrate that previously predictive cues capture attention in the same search task but can be better suppressed in a flanker task, revealing a crucial role of task context in determining how experience-driven attention unfolds.
At first glance, the demonstration of attentional capture to the learned color seems to contradict the study reported by Anderson et al. (2011). There, when participants were trained to associate two colors with the target location (without monetary rewards – as in here), the learned colors did not capture attention in the test. A simple but crucial difference between the two studies is that, whereas two colors were predictive of the target location in Anderson et al. (2011), in the current study, only one color was predictive. Classic studies in animal learning show that the degree of association between conditioned and unconditioned stimuli crucially depends on the predictive quality of the conditioned stimulus on the unconditioned stimulus (Wagner, Logan, Haberlandt, & Price, 1968), as evidenced by Kamin’s blocking effect (Kamin, 1968). Accordingly we suggest that the null result in Anderson et al. (2011) could be attributed to the colors’ weaker predictiveness of the target location, as a result of using two – instead of one – colors as the cues.
Our results extend prior work showing persistent attentional bias after the environmental statistics have changed. For example, when an uninformative onset cue appears at a fixed location and when it is spatially and temporally close to the target, the potential distraction of the cue has been shown to induce an attentional suppression effect on the cue location, and furthermore such bias persists into a subsequent stage where the cue is actually absent (Lin & Murray, 2015). On the other hand, when a spatial location has a higher probability of containing the target, it induces an attentional attraction to that location, and such bias persists into a subsequent stage when the target is equally likely to appear at all potential locations (Jiang et al., 2013). The current results provide a significant extension, by showing that attentional bias (attraction) can persist even when the attraction leads to suboptimal performance – when the target never appears together with the previously predictive color. This result suggests that attentional bias may be characterized as a form of habitual behavior, one that is facilitated by the continuation of the context and is not wholly goal-dependent (Wood & Neal, 2007). Consistent with this goal-insensitive characteristic of habitual behavior is the observation that suboptimal attentional capture still occurs when participants are asked to attend to a different feature (shape; Experiment 3).
The demonstration of better attentional filtering of distractors in the learned color than other colors is surprising and warrants further confirmation. This finding highlights a central role of task context in determining how learned attention unfolds. The search task did not particularly demand inhibition and the spatial configuration of the stimuli did not facilitate inhibition – the target and the non-targets were randomly positioned in a circular display. In contrast, the flanker task demanded inhibition and the spatial configuration of the stimuli supported inhibition – the target and the distractor were spatially separated, each at a fixed location. Because of the clear spatial certainty of the target and the distractor in the flanker task, spatial inhibition can even be initiated early on, before the display appears. The results from the flanker task reveal that persistent attentional bias is context-dependent – the effect disappears when the task entails suppressing a fixed location – and that there is an additional component of experience-driven attention: better suppression of the learned color when the task requires so.
Better suppression of the learned color could not be explained by the physical difference between the learned color and the new color (Experiment 4) or the non-learned color (Experiment 5), as in both cases the two colors – green and red – were counterbalanced across participants. Nor could it be explained by assuming a single, saliency-elevating effect of learning, for more salient distractors are known to lead to a larger – not smaller – interference effect (Eltiti, Wallace, & Fox, 2005; Wei & Zhou, 2006). It also could not be easily explained by response learning, that by having made speeded responses to the learned color during training, subsequent responses to this learned color would be faster than to other colors (Anderson & Folk, 2014). First, as Experiment 4 shows, RT in fact did not critically depend on whether the target was in the learned color or not. Second, the reduction of the interference effect was generally attributed to the incongruent condition rather than to the congruent condition.
A viable account that remains is one based on familiarity (Anderson et al., 2012): the learned color is more familiar – and so easier to suppress – than the other color. Given that the two colors were counterbalanced and given that they were likely to be equally familiar before associative learning, one may attribute the difference in familiarity to the task, as induced by the short-term learning experience: the learned color, but not the other, being the one that was searched for.
Although more research is required for a definite conclusion, this learning-based familiarity account of suppression makes two related and reasonable assumptions. The first assumption is that repeatedly searching for the learned color makes it easier to recognize the shape of the object in the learned color. This assumption is consistent with the evidence that familiar objects – such as one’s own name (Shapiro, Caldwell, & Sorensen, 1997) and one’s own face (Tong & Nakayama, 1999) – is easier to process, requiring less attention to recognize. The second assumption is that better recognition can lead to better suppression. In principle, to suppress the surrounding distractor, one only needs to suppress the location of the distractor without having to know what the distractor is. But research on attentional load suggests that this is not always at will; in other words, when the attentional load of the task-relevant processing is low – as is the case here; a simple shape discrimination task – the processing of task-irrelevant information may be involuntary such that the identity of the distractor will also be processed (e.g., Lavie et al., 2009). If identity recognition is mandatory, then easier recognition potentially can lead to quicker suppression (cf. Tong & Nakayama, 1999).
Additional supporting evidence for the dual-component account of experience-driven attention – capture and inhibition – comes from neurophysiological research. A recent two-photon calcium imaging study in mice primary visual cortex shows that associative learning reduces responses in layer 4, which receives primarily feedforward sensory input, but enhances responses in layer 1, which receives top-down modulation (Makino & Komiyama, 2015). This suggests that associative learning may both reduce bottom-up sensory drive and enhance top-down modulation. Reduction in the sensory coding of learned stimuli may constitute a neural basis for enhanced familiarity. This interpretation accords with human neuroimaging results showing enhanced repetition suppression effects by focal attention (Murray & Wojciulik, 2004) and by perceptual expectations (Summerfield et al., 2008). It also accords with infant studies that demonstrate a decline of looking time after repeated exposure to a stimulus – reflecting an increase in familiarity (Aslin, 2014). On the other hand, enhancement in top-down modulation of learned stimuli may constitute a neural basis for attentional capture. It has been increasingly recognized that associative learning contributes to the formation of predictive models of the world (Makino & Komiyama, 2015), and crucially top-down predictions are context sensitive (Bastos et al., 2012; Friston, 2008). Accordingly, learning-based predictive coding may provide a plausible neural account for context-dependent capture and suppression: associative learning reduces bottom-up sensory drives and facilitates attentional suppression while it enhances context-sensitive top-down modulation.
More broadly, these results suggest that learning – and visual experience and history in general (e.g., Lin & Murray, 2014) – may play a more important role in attention than has been recognized. For example, attention has been shown to be sensitive to symbolic cues that are not predictive of the target location, such as the direction of eye gaze (Driver et al., 1999; Friesen & Kingstone, 1998; Langton & Bruce, 1999) and the spatial meaning of words (Hommel, Pratt, Colzato, & Godijn, 2001). It is conceivable that these attentional biases may be attributed to our past learning experience, in which we have learned to associate various cues with spatial location and direction (cf. Dodd & Wilson, 2009). This learning-based predictive coding perspective is consistent with human developmental studies showing a crucial role of learning – often in the absence of explicit reinforcement, as is the case here – in guiding the allocation of visual attention (Aslin, 2014; Troller-Renfree, McDermott, Nelson, Zeanah, & Fox, 2015). It also accords with recent theories featuring an adaptive role of associative learning in modulating inhibitory control (Verguts & Notebaert, 2009).
In conclusion, we have developed a learning procedure that reveals two distinct components that may determine how prior learning experience controls attention. The results show that previously predictive cues leave two distinct functional footprints in accordance with learning-based predictive coding: a spontaneous attentional attraction, potentially enabled by context-sensitive top-down modulation; and a goal-directed enhancement in suppression, potentially facilitated by a reduction in bottom-up sensory drive. These findings highlight two components in experience-driven attention and the important role of task contexts in determining their manifestations. By shedding light on the mechanisms of how training alters attention, these results may help guide the development of next-generation attention training protocols for rectifying maladaptive attention allocation, a deficit that characterizes people with anxiety disorders (Bar-Haim, 2010; MacLeod & Clarke, 2015) and children experiencing early environmental stress (Troller-Renfree et al., 2015).
References
Anderson, B. A., & Folk, C. L. (2014). Conditional automaticity in response selection: Contingent involuntary response inhibition with varied stimulus-response mapping. Psychological Science, 25(2), 547–554. doi:10.1177/0956797613511086
Anderson, B. A., Laurent, P. A., & Yantis, S. (2011). Value-driven attentional capture. Proceedings of the National Academy of Sciences of the United States of America, 108(25), 10367–10371. doi:10.1073/pnas.1104047108
Anderson, B. A., Laurent, P. A., & Yantis, S. (2012). Generalization of value-based attentional priority. Visual Cognition, 20(6), 647–658.
Aslin, R. N. (2014). Infant learning: Historical, conceptual, and methodological challenges. Infancy, 19(1), 2–27. doi:10.1111/Infa.12036
Bar-Haim, Y. (2010). Research review: Attention bias modification (ABM): A novel treatment for anxiety disorders. Journal of Child Psychology and Psychiatry, and Allied Disciplines, 51(8), 859–870. doi:10.1111/j.1469-7610.2010.02251.x
Bar-Haim, Y., Lamy, D., Pergamin, L., Bakermans-Kranenburg, M. J., & van Ijzendoorn, M. H. (2007). Threat-related attentional bias in anxious and nonanxious individuals: A meta-analytic study. Psychological Bulletin, 133(1), 1–24. doi:10.1037/0033-2909.133.1.1
Bastos, A. M., Usrey, W. M., Adams, R. A., Mangun, G. R., Fries, P., & Friston, K. J. (2012). Canonical microcircuits for predictive coding. Neuron, 76(4), 695–711. doi:10.1016/j.neuron.2012.10.038
Brainard, D. H. (1997). The psychophysics toolbox. Spatial Vision, 10(4), 433–436.
Chun, M. M., & Jiang, Y. (1998). Contextual cueing: Implicit learning and memory of visual context guides spatial attention. Cognitive Psychology, 36, 28–71.
Dodd, M. D., & Wilson, D. (2009). Training attention: Interactions between central cues and reflexive attention. Visual Cognition, 17(5), 736–754. doi:10.1080/13506280802340711
Driver, J., Davis, G., Ricciardelli, P., Kidd, P., Maxwell, E., & Baron-Cohen, S. (1999). Gaze perception triggers reflexive visuospatial orienting. Visual Cognition, 6(5), 509–540.
Eltiti, S., Wallace, D., & Fox, E. (2005). Selective target processing: Perceptual load or distractor salience? Perception & Psychophysics, 67(5), 876–885.
Folk, C. L., Remington, R. W., & Johnston, J. C. (1992). Involuntary covert orienting is contingent on attentional control settings. Journal of Experimental Psychology: Human Perception and Performance, 18(4), 1030–1044.
Friesen, C. K., & Kingstone, A. (1998). The eyes have it! Reflexive orienting is triggered by nonpredictive gaze. Psychonomic Bulletin & Review, 5(3), 490–495.
Friston, K. (2008). Hierarchical models in the brain. PLoS Computational Biology, 4(11), e1000211. doi:10.1371/journal.pcbi.1000211
Geng, J. J., & Behrmann, M. (2002). Probability cuing of target location facilitates visual search implicitly in normal participants and patients with hemispatial neglect. Psychological Science, 13(6), 520–525.
Guzman-Martinez, E., Leung, P., Franconeri, S., Grabowecky, M., & Suzuki, S. (2009). Rapid eye-fixation training without eyetracking. Psychonomic Bulletin & Review, 16(3), 491–496. doi:10.3758/Pbr.16.3.491
Hommel, B., Pratt, J., Colzato, L., & Godijn, R. (2001). Symbolic control of visual attention. Psychological Science, 12(5), 360–365.
Jiang, Y. V., Swallow, K. M., Rosenbaum, G. M., & Herzig, C. (2013). Rapid acquisition but slow extinction of an attentional bias in space. Journal of Experimental Psychology: Human Perception and Performance, 39(1), 87–99. doi:10.1037/a0027611
Kamin, L. (1968). "Attention-like" processes in classical conditioning. In M. R. Jones (Ed.), Miami Symposium on the Prediction of Behavior, 1967: Aversive stimulation (pp. 9–31). Coral Gables, FL: University of Miami Press.
Kersten, D., Mamassian, P., & Yuille, A. (2004). Object perception as Bayesian inference. Annual Review of Psychology, 55, 271–304. doi:10.1146/annurev.psych.55.090902.142005
Kyllingsbaek, S., Schneider, W. X., & Bundesen, C. (2001). Automatic attraction of attention to former targets in visual displays of letters. Perception & Psychophysics, 63(1), 85–98.
Kyllingsbaek, S., Van Lommel, S., Sorensen, T. A., & Bundesen, C. (2014). Automatic attraction of visual attention by supraletter features of former target strings. Frontiers in Psychology, 5, Artn 1383. doi:10.3389/Fpsyg.2014.01383
Langton, S. R. H., & Bruce, V. (1999). Reflexive visual orienting in response to the social attention of others. Visual Cognition, 6(5), 541–567.
Lavie, N., Lin, Z., Zokaei, N., & Thoma, V. (2009). The role of perceptual load in object recognition. Journal of Experimental Psychology: Human Perception and Performance, 35(5), 1346–1358. doi:10.1037/a0016454
Leber, A. B., & Egeth, H. E. (2006). Attention on autopilot: Past experience and attentional set. Visual Cognition, 14(4-8), 565–583. doi:10.1080/13506280500193438
Lin, Z., & He, S. (2012). Automatic frame-centered object representation and integration revealed by iconic memory, visual priming, and backward masking. Journal of Vision, 12(11), 1–18. doi:10.1167/12.11.24
Lin, Z., & Murray, S. O. (2014). Priming of awareness or how not to measure visual awareness. Journal of Vision, 14(1), 1–17. doi:10.1167/14.1.27
Lin, Z., & Murray, S. O. (2015). More power to the unconscious: Conscious, but not unconscious, exogenous attention requires location variation. Psychological Science, 26(2), 221–230. doi:10.1177/0956797614560770
Logan, G. D. (1998). What is learned during automatization? II. Obligatory encoding of spatial location. Journal of Experimental Psychology: Human Perception and Performance, 24(6), 1720–1736. doi:10.1037/0096-1523.24.6.1720
MacLeod, C., & Clarke, P. J. (2015). The attentional bias modification approach to anxiety intervention. Clinical Psychological Science, 3(1), 58–78.
Makino, H., & Komiyama, T. (2015). Learning enhances the relative impact of top-down processing in the visual cortex. Nature Neuroscience, 18(8), 1116–1122.
Miller, J. (1988). Components of the location probability effect in visual search tasks. Journal of Experimental Psychology: Human Perception and Performance, 14(3), 453–471.
Murray, S. O., & Wojciulik, E. (2004). Attention increases neural selectivity in the human lateral occipital complex. Nature Neuroscience, 7(1), 70–74. doi:10.1038/nn1161
Pelli, D. G. (1997). The VideoToolbox software for visual psychophysics: Transforming numbers into movies. Spatial Vision, 10(4), 437–442.
Shapiro, K. L., Caldwell, J., & Sorensen, R. E. (1997). Personal names and the attentional blink: A visual "cocktail party" effect. Journal of Experimental Psychology: Human Perception and Performance, 23(2), 504–514.
Shiffrin, R. M., & Schneider, W. (1977). Controlled and automatic human information processing: II. Perceptual learning, automatic attending, and a general theory. Psychological Review, 84, 127–190.
Summerfield, C., Trittschuh, E. H., Monti, J. M., Mesulam, M. M., & Egner, T. (2008). Neural repetition suppression reflects fulfilled perceptual expectations. Nature Neuroscience, 11(9), 1004–1006. doi:10.1038/nn.2163
Tong, F., & Nakayama, K. (1999). Robust representations for faces: Evidence from visual search. Journal of Experimental Psychology: Human Perception and Performance, 25(4), 1016–1035.
Troller-Renfree, S., McDermott, J. M., Nelson, C. A., Zeanah, C. H., & Fox, N. A. (2015). The effects of early foster care intervention on attention biases in previously institutionalized children in Romania. Developmental Science, 18(5), 713–722. doi:10.1111/desc.12261
Tseng, C. H., Gobell, J. L., & Sperling, G. (2004). Long-lasting sensitization to a given colour after visual search. Nature, 428(6983), 657–660.
Tseng, C. H., Vidnyanszky, Z., Papathomas, T., & Sperling, G. (2010). Attention-based long-lasting sensitization and suppression of colors. Vision Research, 50(4), 416–423. doi:10.1016/j.visres.2009.09.019
Verguts, T., & Notebaert, W. (2009). Adaptation by binding: A learning account of cognitive control. Trends in Cognitive Sciences, 13(6), 252–257. doi:10.1016/j.tics.2009.02.007
Wagner, A. R., Logan, F. A., Haberlandt, K., & Price, T. (1968). Stimulus selection in animal discrimination learning. Journal of Experimental Psychology, 76(2), 171–180.
Wei, P., & Zhou, X. (2006). Processing multidimensional objects under different perceptual loads: The priority of bottom-up perceptual saliency. Brain Research, 1114(1), 113–124. doi:10.1016/j.brainres.2006.07.071
Wood, W., & Neal, D. T. (2007). A new look at habits and the habit-goal interface. Psychological Review, 114(4), 843–863. doi:10.1037/0033-295x.114.4.843
Yu, A. J., & Dayan, P. (2005). Uncertainty, neuromodulation, and attention. Neuron, 46(4), 681–692. doi:10.1016/j.neuron.2005.04.026
Author information
Authors and Affiliations
Corresponding author

Rights and permissions
About this article

Cite this article
Lin, Z., Lu, ZL. & He, S. Decomposing experience-driven attention: Opposite attentional effects of previously predictive cues. Atten Percept Psychophys 78, 2185–2198 (2016). https://doi.org/10.3758/s13414-016-1101-z
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13414-016-1101-z