
Abstract
A key tenet of feature integration theory and of related theories such as guided search (GS) is that the binding of basic features requires attention. This would seem to predict that conjunctions of features of objects that have not been attended should not influence search. However, Found (1998) reported that an irrelevant feature (size) improved the efficiency of search for a Color × Orientation conjunction if it was correlated with the other two features across the display, as compared to the case in which size was not correlated with color and orientation features. We examined this issue with somewhat different stimuli. We used triple conjunctions of color, orientation, and shape (e.g., search for a red, vertical, oval-shaped item). This allowed us to manipulate the number of features that each distractor shared with the target (sharing) and it allowed us to vary the total number of distractor types (and, thus, the number of groups of identical items: grouping). We found that these triple conjunction searches were generally very efficient—producing very shallow Reaction Time × Set Size slopes, consistent with strong guidance by basic features. Nevertheless, both of the variables, sharing and grouping, modulated performance. These influences were not predicted by previous accounts of GS; however, both can be accommodated in a GS framework. Alternatively, it is possible, though not necessary, to see these effects as evidence for “preattentive binding” of conjunctions.
Similar content being viewed by others


In a typical visual scene, many objects will share features with each other: The scene may include several big things, several blue things, several shiny things, and so forth. Consequently, looking for a specific object is likely to entail search for a conjunction of features (e.g., the big, blue, shiny thing). Conjunction searches have been a subject of considerable interest in the visual search literature for many years. In her original “feature integration theory” (FIT), Treisman classified conjunction searches as “serial,” as contrasted with “parallel” feature searches (Treisman & Gelade, 1980). Central evidence for this claim came from the functions relating set size (the number of items in a search display) to reaction time (RT). For salient features (e.g., red among green or big among small), the slope of the RT × Set Size function was near zero, suggesting no additional cost of added distractor items. For conjunction searches, in contrast, RT increased linearly with set size. Each additional distractor imposed a cost. The data were consistent with a serial search through the items at a rate of 20–40 items per second. It should be noted that the same data are also consistent with various versions of parallel models in which all items are processed at the same time (Townsend, 1971; Townsend & Wenger, 2004), but in which noise or capacity limitations cause a rise in RTs with set size (Palmer, 1995).
A key theoretical claim of FIT was that the features forming conjunctions could not be “bound” without the application of selective attention. However, whether or not conjunction identification required serial binding, subsequent work made it clear that conjunction search did not need to be particularly inefficient. With salient component features, conjunction searches tended to produce RT × Set Size slopes that were intermediate between the most efficient feature searches and the least efficient basic searches in which items were big enough to be identified without requiring fixation (e.g., Ts among Ls or 2s among 5s; Dick, Ullman, & Sagi, 1987; Egeth, Virzi, & Garbart, 1984; McLeod, Driver, Dienes, & Crisp, 1991; Nakayama & Silverman, 1986; Treisman & Sato, 1990; Wolfe, Cave, & Franzel, 1989). A continuum of search efficiency runs from highly efficient feature searches to inefficient searches for items defined by their spatial configurations (like Ts and Ls; Wolfe, 1998).
Guided search (GS) theory is one approach to understanding this continuum (Eckstein, 1998; Wolfe, 1994, 2007; Wolfe et al., 1989). GS preserves the central role for binding via selective attention. According to GS, relatively efficient conjunction search occurs because basic features can be used to guide attention to items that are more likely to be the target item. Thus, in a search for a red vertical item, attention can be guided to red items and to vertical items, the intersection of those two sets being an excellent place to look for red vertical items. The claim of FIT and GS is that the red vertical item is not bound and recognized until the item falls under the “spotlight” of selective attention. Various other experimental results (Driver, McLeod, & Dienes, 1992; Duncan, 1995; Enns & Rensink, 1990; Roggeveen, Kingstone, & Enns, 2004) and various other theoretical formulations have proposed that features can be bound without the need to focus selective attention on the item (McElree & Carrasco, 1999; Palmer, 1995). The “similarity” model proposed by Duncan and Humphreys (1989) put an emphasis on the role of grouping of items by similarity, including the grouping of items whose similarity was based on the binding of features without attention (Humphreys, Quinlan, & Riddoch, 1989). GS argued against such preattentive binding (Wolfe, 1992).
Found (1998) put these competing claims to an interesting test. He had participants search for tilted red lines among tilted white and vertical red lines. The critical manipulation was an irrelevant variation in a third variable, size: Items were either big or small, and the size of items was either correlated with the color and orientation of items or it was not. In the correlated case, within a trial, all items of one conjunction type had the same size and all items of the other conjunction type had the other size. For example, red vertical items might be big, whereas all white tilted items might be small; however, the specific relationship between size and the Orientation × Color varied from trial to trial. When size was uncorrelated, the size varied randomly with the Orientation × Color conjunctions within a trial, with the restriction that half of the elements in a trial were big and half were small. In both cases, the target item was equally likely to be either big or small; thus, size was uninformative of target presence. Found reasoned that GS should not care about whether or not the irrelevant size variable was tied to the task-relevant feature dimensions. If features were processed independently prior to the arrival of attention, the contributions of size would be the same in the two conditions. However, the results showed that the strongly correlated case was more efficient. Found argued that the size-correlated case had two groups of items (e.g., big red vertical and small white tilted), whereas the size-uncorrelated case had four. That is, the displays with more and smaller groups looked “noisier” and were somewhat harder to search through. Found considered this to be consistent with a similarity theory in which “preattentive vision delivers bound sets of features that relate to the same segmented object” (Found, 1998, p. 1123), and not consistent with GS, which would not deliver such preattentive bindings. Proulx (2007) expanded on these considerations and found that salient, task-irrelevant singleton features influence search efficiency. This led Proulx to propose that both GS and similarity theory understate the role of bottom-up saliency in conjunction searches (Proulx, 2007).
Good evidence suggests that feature conjunctions can influence behavior even for conjunction items that GS and similar serial theories assume are available only preattentively or with minimal attention. For example, Mordkoff, Yantis, and Egeth (1990) had observers look for red X targets in displays with other items that could be red or Xs, but not both. In displays of two or six items, the critical comparison was between trials with one or two red Xs: RTs are faster with two Xs (redundancy gain; see also Pashler, 1987). Importantly for the argument, the RTs were faster than would be predicted if each conjunction needed to be processed separately (Mordkoff et al., 1990). Mordkoff et al. argued that, in a redundant display, both red Xs can be processed as conjunctions of red and X at the same time.
Converging evidence for this sort of preattentive processing of conjunctions has come from Mordkoff and Halterman’s (2008) “correlated flankers task.” In the standard flanker task, observers might be shown groups of three letters and told to hit the left key if the middle letter was an A and the right key if the middle letter was a B (B. A. Eriksen & Eriksen, 1974; C. W. Eriksen & Hoffman, 1973). The standard finding is that it will take a little longer to respond if the flanking letters are incongruent with the central letter (BAB and ABA) than if the flankers are congruent (AAA, BBB). In Mordkoff and Halterman’s version of the task, the target was a color–shape conjunction (e.g., a red square), and the flankers were other conjunctions that could be correlated with the target. Thus, blue diamond flankers might be correlated with the red square, though blue and diamond by themselves were not. These conjunctive flankers had an effect on RTs to the target, indicating that the combination of blue and diamond has been registered.
There is a long-running debate about the source of the flanker effect. The original hypothesis was that the flanker effect was evidence that the flanker letters were processed without attention, because attention was directed to the central letter. Later work questioned the assumption that one could completely deny attention to the flankers. For instance, Lavie and Tsal (1994) argued that, if the central task was not very demanding, some attentional resources would spill over to process the flankers. Kyllingsbæk, Sy, and Giesbrecht (2011) demonstrated that this load effect on the flanker task can also be explained by a parallel model with limited processing capacity and limited visual working memory. Regardless of one’s position on this continuing debate (see, e.g., Lavie & Torralbo, 2010; Tsal & Benoni, 2010), results like those of Mordkoff and Halterman (2008) do indicate that, under some circumstances, the conjoint appearance of basic features in an object can be processed with little or no attention.
Krummenacher and colleagues found evidence for coactivation of multiple features in visual search tasks (Krummenacher, Grubert, & Müller, 2010; Krummenacher, Müller, & Heller, 2001, 2002). As in the Mordkoff work, conjunctions of color and shape produced RTs that were too fast to be explained if the two features were not being combined in some manner. Their “dimension-weighting” solution to this problem was a modification of GS.
In this article, we use higher-order conjunctions to revisit this issue of preattentive processing of the combinations of basic features. By “higher-order conjunctions,” we mean targets that are defined by more than two features. In the real world, most objects in a complex environment would need to be defined by multiple features. Moreover, as will be seen, higher-order conjunctions give us other tools with which to address the questions of conjunctive target feature guidance and preattentive effects of feature conjunctions separately. Earlier work with triple conjunctions has provided evidence for an ability to guide attention on the basis of multiple dimensions (Dehaene, 1989; Quinlan & Humphreys, 1987). Consistent with either GS or similarity theory, it is easier to find a triple conjunction if distractors share just one feature with the target than if they share two (Wolfe et al., 1989). Typically, some features seem to guide more effectively than others, with color being a frequent winner (Williams & Reingold, 2001).
The basic puzzle
Figure 1 illustrates the basic challenge to models like GS posed by Found’s (1998) work. The target in each case is a horizontal red rectangle. This is a triple conjunction task because some distractor items are red, some are horizontal, and some are rectangles; no single feature is adequate to do the task. In each case, one third of the items have the target properties. That is, both examples contain one third red items, one third horizontal, and one third rectangles. A standard model with separate representations for each dimension would see no preattentive differences between the two conditions. The difference between the conditions lies in the combinations of the features. On the left, every combination of the three values of the three feature dimensions is present, leading to a display with a target and 26 distractor types. On the right, only three of the 26 distractor types are used. However, the distributions of the individual features are the same in both displays; each feature is represented equally often. It is probably intuitively clear that the three-distractor case is easier than the 26-distractor case. Experiment 1a tested this intuition and showed that it can be supported by data.

It seems intuitively clear (and will be shown empirically below) that it is harder to find a red, horizontal rectangle in the left image than in the right, even though both sets of stimuli have 1/3 red items, 1/3 horizontal items, and 1/3 rectangular shapes
Experiment 1a
In seven experiments, we examined the guidance of attention in visual search for targets defined by three or six features. We looked for and found evidence that cannot be explained by guidance by representations of independent stimulus attributes, and we considered whether these findings might require a mechanism of preattentive binding. In Experiment 1a, we provided empirical support for the impression that triple conjunctions are easier to find when there are fewer types of distractor items.
Method
Participants
Thirteen paid volunteers (nine men, four women) participated in the experiment. Age information was available for 12 of the 13 participants; for these participants, the age range was 19 to 47. The participants had normal or corrected-to-normal 20/25 vision, no history of eye or muscular disorders, and no color vision deficits when tested on Ishihara’s tests for color blindness (Ishihara, 1987). All participants gave informed consent prior to participation. One participant was excluded from the data analysis due to excessive miss rates. The miss rates of this participant exceeded the mean miss rate across all other participants by over two standard deviations.
Apparatus
The stimuli were presented on Apple Macintosh OS X 10.5.8 computers. The experiments were run using the Psychophysics Toolbox in MATLAB 7.5.0 (R2007b). Each computer was connected to a 20-in. CRT screen, and the screen resolution was 1,280 × 960 pixels with a refresh rate of 85 Hz. Participants freely viewed the screen at a distance of approximately 60 cm, and responses were collected using a standard U.S. Apple keyboard.
Stimuli
The stimulus set consisted of elements that had one of three features in each of the three feature dimensions of color, shape, and orientation. A stimulus element could be red (RGB: 200, 0, 0), green (RGB: 0, 170, 45), or blue (RGB: 0, 230, 230); vertical (0º), oblique (45º), or horizontal (90º); and rectangular, oval, or jagged. Thus, 27 types of feature conjunctions were possible (see Fig. 2 for the basic stimulus set).

The 27 items, defined by 3 colors × 3 shapes × 3 orientations
In Experiment 1a, all participants searched for the same target: a red, vertical rectangle. Four distractor sets were used. In the first distractor set, all of the possible conjunction types, excluding the target, made up the set (as in the first display in Fig. 1). We call this the 26-conjunction (26D) set. Distractor Sets 2 and 3 each consisted of three conjunction types. These two conditions differed in how many features each distractor type shared with the target. In one of the three-distractor conditions, the distractors were red vertical ovals (sharing two features with the target), blue horizontal rectangles (one shared feature), and green oblique zigzag shapes (no shared features). This condition will be designated 3D(012). In the other three-distractor condition, the distractors were red oblique ovals, green vertical zigzag shapes, and blue horizontal rectangles. Each distractor shared one feature with the target; hence, this condition is designated 3D(1). The fourth and last distractor set in Experiment 1a was a 5D set and consisted of a red, vertical zigzag shape (sharing two features); a red vertical oval (also sharing two); a green oblique rectangle (sharing one); a blue, horizontal zigzag shape (sharing none); and a blue horizontal oval (sharing none). In the 26D and 3D sets, the proportions of basic features remained the same: one third of the items having each color, each orientation, and each shape. In the 5D set, there were fewer representations of green, rectangular, and oblique than of the other features. Importantly, in all conditions, the distractors shared one feature with the target, on average.
The display set size was 27 on half of the trials and 54 on the other half. These set sizes were picked so that all 26 distractors plus a target could be presented on a single trial. When distractor sets were subsets of the full set, distractors were repeated in a display. Equal (or almost equal) numbers of each distractor were presented on each trial. When the number of distractors did not divide evenly into the set size (in the 5D condition), the required additional distractors were drawn at random without replacement from the current distractor set.
The stimuli were presented on a white background (RGB: 255, 255, 255) in an 8 × 8 matrix, with a diameter of 950 pixels and centered on the screen. The stimulus elements were randomly presented in the 64 tiles of the matrix. Each element was placed in the center of a randomly chosen unoccupied tile and jittered a few pixels in order to avoid the alignment of elements.
Procedure
Participants were instructed to look for the target, defined by three target features (i.e., the red vertical rectangle), and to respond as quickly and accurately as possible as to whether the target element was present or absent. The target remained the same across the whole experiment. Responses were made by pressing the predetermined “present” or “absent” key on the keyboard. The two response keys were marked by a red and a blue sticker on top of the A key and the L key, respectively. Participants were instructed to place each of their index fingers on top of each of the two keys. Targets were present on half of the trials.
Each trial followed the same sequence of events. First, the description of the three target features appeared in the center of the screen for 500 ms, accompanied by a warning beep. This was followed by a stimulus display that remained present on screen until the participant responded. After the response, a screen showing the trial number, accuracy feedback, and RT for that trial was displayed for 500 ms. If an error response was made, three error beeps would sound, concurrent with the presentation of the feedback screen. After the feedback, the next trial was initiated after a 1,000-ms delay.
Participants started the experiment by completing 10–30 practice trials and 900 experimental trials with presentations of all display types intermixed pseudorandomly.
Data analysis
The RT data were trimmed by removing “outlier” trials with RTs more than three standard deviations greater than the mean for that participant. Trials with RTs below 200 ms were also removed from the analysis.
The RT data and accuracy data were examined separately through repeated measures analyses of variance (ANOVAs) with the factors Distractor Condition and Set Size. In the following analysis, Greenhouse–Geisser-corrected p values are reported where Mauchly’s test revealed that sphericity could not be assumed. The analyses were carried out separately for target-present and target-absent trials. For the RTs, we were particularly interested in whether the distractor sets significantly influenced search efficiency. Hence, when the general RT ANOVA revealed a significant interaction between set size and distractor condition, the relevant distractor conditions were compared by post-hoc ANOVAs or Student’s t tests. Post-hoc p values were Bonferroni–Holm corrected. For the error data, our primary interest was to ensure that speed–accuracy trade-offs were not contributing substantially to any RT differences for the various distractor conditions. Therefore, when the error rate ANOVA revealed a significant effect of distractor set, the error rates were investigated further. For all ANOVAs, generalized eta square (ges) is reported for effect sizes.
Results and discussion
Using the outlier procedure described above, 2.1 % of the trials were removed from further analysis. Mean RTs are shown in Fig. 3. First, they confirm that triple conjunction searches are very efficient when the target shares an average of one feature with the distractors. Note that all target-present slopes are less than 5 ms/item. Second, the results show reliable differences between the conditions, even though the feature maps should be equivalent in four of the five conditions (the 5D condition had slightly fewer green, oblique, and rectangular items).

Reaction times
The RT ANOVAs revealed that the effects of distractor condition and the interaction between distractor condition and set size were significant, for both target-present and target-absent trials (see Table 1). In general, RTs increased and search efficiency decreased when the number of conjunction types in the distractor sets increased. For the target-present trials, the two 3D–26D slope comparisons were significant, as was the 5D–3D(1) comparison. For the target-absent trials, all slope comparisons except for the 3D(1)–3D(012) comparison were significant. The results thus indicate that the searches were more efficient when fewer conjunction types were present, and that this pattern was more pronounced for the target-absent trials.
Error rates
Out of the 5,602 target-present trials that were not removed by the outlier procedure, 255 errors occurred, in addition to 115 error trials out of the 5,337 target-absent trials. Investigations of the error rates revealed no significant effects for the target-present trials. For the target-absent trials, we found a significant main effect of distractor set (see Table 2); however, none of the separate distractor-type comparisons revealed any significant effects. Numerically, the error rates followed the pattern suggested by the RTs, with higher error rates for the 26D condition (5.6 % errors), intermediate for the 5D condition (1.7 %), and lowest for the 3D conditions (<0.1 %). The error rate analyses thus did not suggest a speed–accuracy trade-off.
Experiment 1b: Replication
The results of Experiment 1a clearly indicated that the efficiency of search cannot be explained entirely by the activity in individual feature maps or their linear sum. If that were the case, there should have been no difference between the 26D and 3D searches. Even though all of these searches were very efficient, the 3D searches were easier than the 26D case.
In Experiment 1a, all participants searched for the same red horizontal rectangle. Moreover, replication is good practice. Accordingly, Experiment 1b was a replication of Experiment 1a with modest modifications. The 5D condition was dropped, and the target conjunction varied between participants.
Method
Participants
Thirteen paid volunteers participated in the experiment (11 women, two men), with an age range of 20–51 years. All gave informed consent.
Target
The target conjunction was chosen randomly from the set of 27 stimulus elements for each participant and remained the same for the whole experiment for that participant.
Distractor conditions
Only the 26D(012), 3D(1), and 3D(012) distractor conditions of Experiment 1a were used. In Experiment 1b, the 3D distractor sets differed from participant to participant, since they were tied to the identity of the target.
Procedure
Participants started the experiment with 24 practice trials and continued for 600 experimental trials. After the practice trials, participants were informed of their average RT and error percentage and were instructed to be both fast and accurate. After every 100 trials, participants were encouraged to take a short break and informed of their average RT and error rate.
Results and discussion
The outlier procedure resulted in a loss of less than 1.5 % of the trials. Figure 4 presents the participants’ mean RTs for the three different distractor conditions as a function of set size for the target-present and target-absent trials. As can be seen (cf. Fig. 4 and Table 3), the basic pattern of results is similar to the one from Experiment 1a, with the 26D being harder than the 3D condition. In addition, we see an RT difference between the 3D(1) and 3D(012) conditions; however, no significant effect on search slopes is visible. The differences seen here between 3D(012) and 3D(1) will be of interest in later experiments, and had only been very weakly seen in Experiment 1a. The fragility of these differences may relate to a floor effect: Both 3D(012) and 3D(1) are very efficient searches.

Error rates
For the target-present trials, 351 error trials occurred, out of the 3,805 trials not discarded as outliers. We observed main effects of distractor condition and set size (see Table 2), but no significant post-hoc comparisons. For the target-absent trials, participants made the wrong response on only 70 trials, out of the 3,779 target-absent trials that were not discarded as outliers. For these 70 trials, we found a significant main effect of distractor condition, and comparisons revealed that errors occurred more often in the 3D(1) condition than in the 26D(012) condition (see Table 4; mean difference = .049). No other effects reached significance.
Discussion of Experiments 1a and 1b
Overall, the results of Experiments 1a and 1b suggest that search efficiency is influenced by the mix of distractor types in this triple conjunction search, even though the distribution of features is the same in all conditions (with small differences in the 5D condition). This result is in general agreement with the results of Found (1998; see also Krummenacher et al., 2001, 2002; Mordkoff & Halterman, 2008; Mordkoff et al., 1990; Takeda, Phillips, & Kumada, 2007). Consistent with previous work, these are highly efficient triple conjunction searches. A standard guided search account would propose that this efficiency arises from the intersection of three sources of guidance. Using the target of Experiment 1a, attention would be guided to red, to vertical, and to rectangular shapes. Guidance of this sort, however, should be the same for all conditions and would not explain the differences between conditions. Similarly, it is not obvious how dimension weighting (Krummenacher et al., 2001, 2002) would explain these effects. Why, then, do the results differ?
One possible account for these differences occurs to almost everyone who introspects about these stimuli. Looking at Fig. 1, might the 3D condition be easier because participants can select the red group and then look for a unique item in that subset? Participants certainly can search through subsets (e.g., Egeth et al., 1984). This subset search strategy would be effective in the 5D and 3D conditions, but not in the 26D condition. The subset search strategy would be most efficient for the 3D(1) condition, for which subsets defined by any of the target features would allow for target identification based on any of the two other target features. For the 3D(012) and 5D conditions, the efficiency of the subset strategy would depend on the feature defining the subset. Experiment 2 tested this subset search hypothesis.
Experiment 2
In Experiment 2, we investigated whether the differences in search efficiency that we had observed in Experiments 1a and 1b were caused by the adoption of a subset search strategy. To test this, we constructed a new distractor condition and had participants do a search task that could only be completed by the use of a subset search. The distractor set contained 19 different conjunction types: All the possible blue and green conjunction types (see Fig. 2) and, crucially, only one of the red conjunction types. This red element was repeated nine times, thereby creating a group of similar red elements among the heterogeneous blue and green elements. On half of the trials, a single instance of a second type of red element was present. This was the target item. The participants were requested to report whether there was an oddball in the red subset; thus, the only way to solve the task was to use a subset search strategy.
Method
Participants
The same 13 volunteers as in Experiment 1a were tested. The task turned out to be very difficult, and five participants missed the target on more than 20 % of the trials. To be sure that we were not analyzing search patterns derived from unconventional search termination strategies, we analyzed RTs both including and excluding these participants. For the analysis excluding the five participants with high miss errors, age information was available for seven of the eight participants, with a range from 20 to 46 years old; four were men.
Distractor set
Only one type of distractor condition was used, the red subset distractor condition. All of the 18 blue and green conjunction types were present in the distractor set. Furthermore, on each trial, one of the nine red conjunction types was randomly chosen and repeated nine times, forming a group of similar red elements.
Target
On each target-present trial, one of the remaining eight red conjunction types was randomly chosen to be the oddball target.
Procedure
The participants were instructed to report whether an oddball was present among the group of similar red items. Participants started the experiment by completing 30 practice trials. The practice trials continued directly into the 300 experimental trials.
Results and discussion
Less than 1 % of the trials were removed by the outlier procedure. Figure 5 reproduces the data of Experiment 1a for the eight participants with reasonable error rates in Experiment 2. The diamonds in Fig. 5 depict the mean RTs for those eight participants as a function of display size for the subset search of Experiment 2. It should be clear that the subset search condition is notably slower than the slowest of the conditions from Experiment 1a.

Reaction times
RTs in the subset condition of Experiment 2 were compared with RTs in the distractor conditions of Experiment 1a by repeated measures ANOVAs both for all of the participants and for the eight participants whose miss rates were acceptable (see Table 5). All effects were significant and were further explored by planned comparisons.
The RTs for the subset condition were significantly higher than those for all of the distractor conditions of Experiment 1a. For the target-present trials, the mean RT difference between conditions ranged from 321 to 459 ms for the eight low-error participants (324 to 497 ms for all participants), the F(1, 7) statistic ranged from 19.90 to 34.01 for the eight low-error participants [F(1, 10) ranged from 38.00 to 50.02 for all participants], and all p values were below .004 and all ges > .65. A similar pattern was apparent for the target-absent trials. Here, the mean RT difference ranged from 494 to 1,141 ms for the eight participants (555 to 1,116 ms for all participants), F(1, 7) ranged from 11.35 to 24.27 [F(1, 10) for all participants ranged from 13.00 to 22.44], and all p values were below .015 and all ges > .45.
Comparisons revealed that the subset search slopes were significantly higher than the slopes for almost all other distractor conditions, when considering all participants (for the target-present trials, the comparison with the 26D condition only trended toward significance). When looking only at the eight participants who had reasonable error rates, the differences weakened. All comparisons were significant for the target-absent trials; however, for the target-present trials, only the comparison with the 3D(1) condition was significant; the 3D(012) and 5D comparisons trended toward significance. Overall, search was slower and less efficient in the subset condition than in the 5D and 3D conditions of Experiment 1a, for which a subset search strategy would have been possible.
Error rates
Looking at the errors for the eight participants with reasonable miss rates, we found 95 errors out of the 1,193 target-present trials, and 15 errors out of the 1,183 target-absent trials that were not removed as outliers. The error rate data did not indicate that the increase in search slopes for the subset condition was caused by a change in speed–accuracy settings (see Tables 2 and 4). Overall, error rates were higher in the subset condition for target-present trials, whether or not the participants with the highest error rates were included in the analyses.
In general, the analyses suggested that participants were substantially worse at performing the subset search than performing any of the distractor conditions of Experiment 1a. Participants had a tendency to miss the targets in the subset search, whether or not the participants with the highest miss error rates were included in the analyses. Overall, the results from Experiment 2 clearly suggest that the participants were not applying a subset search strategy in Experiments 1a and 1b. Although a slight RT cost might have been expected due to the cost of using a variable conjunction target in Experiment 2, as compared to a constant conjunction target in Experiment 1a (<100 ms; cf. Kristjánsson, Wang, & Nakayama, 2002), the subset costs that we found were substantially larger than this (>300 ms). The subset searches were significantly slower and less efficient than the distractor conditions for which a subset search strategy would have been possible. For the target-absent trials, the subset search was even less efficient than the 26D condition. Thus, though introspection often suggests a subset search strategy in conjunction searches, the data suggest that subset searches are slower and/or less efficient than what we assume to be “guided” searches for targets defined by specified features. A similar conclusion was reached by Friedman-Hill and Wolfe (1995), who performed a comparable experiment with two-dimensional conjunctions.
Discussion of Experiments 1 and 2
The number of distractor types and their similarity with the target influence the slopes and intercepts of RT × Set Size functions, even when the distribution of basic features is held constant [i.e., the 26D, 3D(012), and 3D(1) conditions]. In the visual search literature, RT × Set Size slopes are taken to reflect the efficiency of the search process itself, whereas changes in the intercept reflect nonsearch processes, including those in initial stages of visual processing or relatively late decision processes. Looking at Fig. 5, for example, the slope of the 26D condition is elevated relative to the 3D conditions. This presumably reflects some slowing of search. The intercept is elevated for the 26D absent trials. In this experiment, observers were probably slightly more reluctant to commit to an “absent” response in the “noisier” 26D condition. Both aspects of these results demonstrate that performance on these tasks can be influenced by something beyond the distribution of basic features. The massive, ~300-ms elevation of the intercept in the subset condition presumably reflects the two-step nature of that task: Get the subset, then examine the subset for the target. The fact that this is so much slower than performance in the normal triple conjunction tasks is strong evidence that observers do not do two-step subset searches in the 3D, 5D, and 26D conditions.
How, then, should we explain the differences between the conditions? The results are inconsistent with linearly summed guidance from three independent feature maps, as in standard GS. It is not obvious how a dimension-weighting account (Krummenacher et al., 2001, 2002) would explain this pattern of results, nor is it clear why a parallel-coactivation account (Mordkoff et al., 1990) would produce, for example, slower RTs for the 26D conditions. This is not to say that any of these approaches is inconsistent with the results, only that each of the approaches would need to consider how to accommodate those results.
Two forms of interaction seem plausible.
-
Factor 1: Target–distractor similarity, or “sharing”
Returning to Fig. 1, if the target is a red, horizontal, rectangle, the distractors can share either zero, one, or two features with that target. In the three-distractor-type example in Fig. 1, each distractor shares just one feature with the target (e.g., the red tilted ovals share only redness with red vertical rectangles). It is known that search becomes harder if the number of shared features is increased (Wolfe et al., 1989). In the 26-distractor condition, some distractors share two features with the target, some one, and others zero. The average is one shared feature. However, if the effects of sharing are not linear, the presence of distractors sharing two features might explain why the targets are harder to find in the 26D condition. Experiment 1a did not provide strong support for this hypothesis, since conditions 3D(012) and 3D(1) produced very similar results, even though 3D(012) has a mix of distractors sharing zero, one, and two features, whereas 3D(1) has distractors sharing just one feature with the target. However, as we noted above, the failure to find a difference between these conditions might be a floor effect, since 3D(1) and 3D(012) are both very efficient searches.
-
Factor 2: The number of element types in the displays, or “grouping”
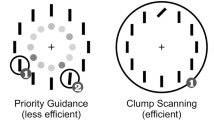
For each feature dimension, there are three groups of features (e.g., red, green, and blue groups). In the 3D conditions, these three groups have exactly the same spatial distribution for each feature dimension. In the 26D condition, on the other hand, the three groups are never aligned across feature dimensions. In guided search and related models, the activity from feature maps is pooled into a cross-feature, attentional “priority” map (Serences & Yantis, 2006). Attention is guided to peaks of activity in that map. Some studies have reported evidence of feature coactivation prior to selection (e.g., Weidner & Müller, 2009, 2013), suggesting that this pooling in not necessarily additive. From a bottom-up perspective, the 3D condition, with its aligned groups, might be less “noisy” than a 26D condition, with unaligned groups. This point is graphically illustrated in Fig. 15 later in this article.
Experiments 1a and 1b are consistent with a role for a Grouping factor, but the topic requires further testing. In Experiment 3, we examined the relative contributions of grouping and sharing by using conditions in which the sharing variable might not be lost to a floor effect.
Experiment 3
Experiment 3 repeated the most efficient and least efficient conditions of Experiments 1a and 1b. These were the 26D condition with all distractor types present and the 3D(1) condition, in which three distractor types were present, each sharing one feature with the target. Experiment 3 introduced two new, intermediate conditions with 12 types of distractors. In the 12D(1) condition, all distractors shared exactly one feature with the target, similar to the 3D(1) set. In the 12D(012) condition, the distractors shared zero, one, or two features with the target. In the 26D condition, the distractors also shared zero, one, or two features with the target. Note that, as before, all of these stimulus conditions had equivalent representations in separate feature maps: On average in each condition, one third of the items were red, one third blue, and one third green. The same held for the distributions of orientation and shape. Thus, the only changes between the distractor conditions were with respect to the conjunctions of the features, implemented in the number of groups and the sharing distributions.
Method
Participants
Thirteen participants (ten women, three men) served as paid volunteers in this experiment. Their ages ranged from 19 to 45 years. All gave informed consent.
Distractor conditions
Four different distractor conditions were used, as described above. The exact stimulus elements were randomly drawn on each trial, for all the distractor sets for which this was possible [i.e., not the 26D(012) and the 12D(1) sets, in which all appropriate stimuli were needed on each trial]. Importantly, in all four distractor conditions, all features were equally represented across displays.
Target
The participants searched for a red, vertical rectangle.
Procedure
The experiment started with 32 practice trials—two trials in every condition (4 distractor sets × 2 set sizes × 2 target present/absent). Each participant served in 800 experimental trials, yielding 50 observations per condition per participant.
Results
Less than 2 % of the trials were removed by the outlier procedure. Figure 6 presents the participants’ mean RTs for the four different distractor conditions as a function of set size for target-present and target-absent trials. The results replicate the earlier results and now add a clear difference between 12D(1) and 12D(012) conditions.

RT × Set Size functions for the conditions of Experiment 3. Error bars represent ±1 within-observer SEMs using the method of Cousineau (2005), corrected as suggested by Morey (2008; Cousineau & O’Brien, 2014). The first number in the condition label gives the number of distractors. The parenthetical numbers state whether the distractors all differ by one feature from the target (1) or by zero, one, or two features (012)
Reaction times
The ANOVA for the target-present RTs revealed a main effect of distractor condition, F(3, 36) = 25.43, GGe = 0.43, p < .001, ges = .09, and set size, F(1, 12) = 26.81, p < .001, ges = .10, but no significant interaction. Further analyses of the RTs based on sharing and groups confirmed what is evident from Fig. 6: Sharing influenced the RTs significantly—the 12D(012) condition had significantly higher RTs than the 12D(1) condition, F(1, 12) = 25.04, p < .001, ges = .41, mean difference = 84.62 ms, whereas, in this case, grouping had no significant effect on the RTs. The 12D(012) condition did not differ significantly from the 26D(012) condition, F(1, 12) = 7.21, p = .825, ges < .01, mean difference = –5.23 ms, nor did the 12D(1) condition differ significantly from the 3D(1) condition, F(1, 12) = 0.03, p = .870, ges = 0.41, mean difference = 1.17 ms.
Analyses of the target-absent RTs revealed significant main effects of distractor condition, F(3, 36) = 40.49, GGe = 0.38, p < .001, ges = .24, and set size, F(1, 12) = 31.55, p < .001, ges = .14, as well as a significant interaction between the two, F(3, 36) = 20.79, p < .001, ges = .03. RT comparisons based on sharing and grouping revealed significant effects of both factors—the 26D(012) condition was significantly slower than the 12D(012) condition (grouping), F(1, 12) = 7.39, p = .019, ges = 0.06, mean difference = 42.18 ms; the 12D(1) condition was significantly slower than the 3D(1) condition (grouping), F(1, 12) = 21.24, p = .001, ges = .48, mean difference = 130.49 ms; and the 12D(012) condition was significantly slower than the 12D(1) condition (sharing), F(1, 12) = 79.66, p < .001, ges = .52, mean difference = 153.53 ms. The comparisons of the target-absent slopes were not as consistent, and revealed significant differences between the 12D(012) and 12D(1) conditions, F(1, 12) = 17.82, p = .002, ges = .04, and the 12D(1) and 3D(1) conditions, F(1, 12) = 20.60, p = .002, ges = .14. However, the 26D(012) and 12D(012) conditions did not differ significantly from each other: F(1, 12) = 0.56, p = .469, ges < 0.01.
Error rates
Out of the 5,174 target-present trials not discarded as outliers, 386 error trials occurred, and out of the 5,056 target-absent trials, 109 had errors. ANOVAs revealed significant main effects of distractor condition and set size for both the target-present and target-absent trials, but no interaction (see Table 2). Comparisons based on sharing and grouping revealed that the miss error rates were significantly higher in the 3D(1) condition than in the 12D(1) condition. False alarm error rates were significantly higher for the 12D(012) condition than for the 12D(1) condition (see Table 4).
Discussion
On the face of it, the results from Experiment 3 might seem to be at odds with the findings of Experiments 1a and 1b. In Experiments 1a and 1b, no evidence for an effect of shared features was apparent in the comparison between conditions 3D(012) and 3D(1). In Experiment 3, however, we found clear evidence that condition 12D(012) was harder than 12D(1). Indeed, in Experiment 3, at least for the target-present trials, all of the difference between the 26D and 3D conditions might be explained by the sharing factor. The 3D(1) and 12D(1) target-present results were essentially identical, although they differed in grouping. This conclusion is somewhat challenged by the absent trials, among which 12D(1) was more difficult than 3D(1)—evidence for an effect of grouping. We speculate that, like Experiments 1a and 1b, Experiment 3 suffered from a floor effect. In Experiment 3, the 12D(1) and 3D(1) conditions may have produced the same results because those searches were about as fast and efficient as they could be. In Experiments 1a and 1b, on the other hand, the 3D(1) and 3D(012) conditions were maximally fast and efficient. Both sharing and grouping can be seen when the tasks are made a little more difficult.
Experiment 4
The interpretation of the preceding experiments is complicated by some rather high miss error rates. Comparisons between conditions may have been contaminated by speed–accuracy trade-offs. Thus, in Experiment 4, we replicated the important conditions using a localization task: A target was present on every trial, and the participants marked the location of the target with a mouse click. This strongly discouraged errors.
Method
Participants
Twelve paid participants (seven women, five men) took part in the experiment, with an age range of 19–55 years. All gave informed consent.
Distractor conditions
The five different distractor conditions of Experiments 1b and 3 were replicated in Experiment 4: 26D(012), 12D(012), 3D(012), 12D(1), and 3D(1). The conditions were intermixed within a block of trials.
Target
For each participant, a target was randomly drawn from the stimulus set. The target element remained the same across the experiment.
Procedure
The participants’ task was to find the target and to click on it with a computer mouse as quickly as possible. The target was present on all trials. An arrow indicated the mouse position on the screen and always appeared in the center of the screen when the trial started. Participants were allowed an error margin of 20 pixels outside the target element when they made the click. Each participant served in 500 experimental trials, equaling 50 observations per data point. The participants started the experiment with a short training session of 30 trials.
Results
Trials with RTs more than three standard deviations from the mean of that participant or faster than 500 ms were counted as outliers and removed from further analysis. Out of the 6,000 trials that were completed by the 12 participants, 98 were removed as outliers. Participants’ mean RTs for the five different distractor conditions are depicted as a function of set size in Fig. 7 and show effects of both grouping and sharing.

Reaction times
The ANOVA revealed significant main effects of set size, F(1, 11) = 37.77, p < .001, ges < .01, and distractor condition, F(4, 44) = 48.12, GGe = 0.57, p < .001, ges = .06, as well as a significant interaction, F(4, 44) = 2.93, p = .025, ges = .01. Instead of comparing the individual distractor conditions, we further analyzed the data with a 2 × 2 × 2 repeated measures ANOVA with the factors Set Size (27 or 54), Sharing (1 or 012), and Groups (3D or 12D), leaving out the 26D(012) distractor condition. This analysis revealed main effects of set size, F(1, 11) = 29.41, p < .001, ges = .08; sharing, F(1, 11) = 174.63, p < .001, ges = .05; and groups, F(1, 11) = 9.47, p = .010, ges = .06. The Set Size × Sharing interaction was also significant, F(1, 11) = 8.04, p = .016, ges = .01. No other interactions were significant.
Error rates
Across all participants, there were 33 error trials (less than 0.6 % of the trials) among the 5,902 trials not removed by the outlier procedure. An ANOVA of these errors revealed no systematic patterns; none of the effects were significant.
Discussion
Experiment 4 again confirmed the basic result that the distribution of distractor features influences visual search, even if the distribution of the individual features is the same. Because the results were broadly similar to those of the previous experiments, Experiment 4 indicated that the previous results were not driven by differences in speed–accuracy trade-offs.
In this version of the experiment, both sharing and the number of conjunction groups had effects on the time that it took participants to locate the target, though only the Sharing factor affected search efficiency.
Experiment 5: Accuracy measures
In Experiment 4, performance was pushed away from the floor effects of the previous experiments by forcing the participants to localize a target on every trial. This approach eliminated speed–accuracy trade-offs but imposed a high decision criterion. In Experiment 5, we went one step farther and presented stimuli briefly, thereby letting the criterion vary freely, driving performance away from high accuracy and allowing us to see whether evidence for sharing and grouping could be found in brief presentations. These temporal constraints are of interest because a number of studies have suggested that similarity effects develop gradually as stimulus presentation time passes (Lamberts, 1998; Verghese & Nakayama, 1994). Similarly, some aspects of attentional guidance to feature conjunctions appear to be time dependent (Kunar, Flusberg, Horowitz, & Wolfe, 2007; Kunar, Flusberg, & Wolfe, 2008). By looking at performance at very short exposure durations, we were able to investigate whether the grouping and sharing effects come into play at distinct points in time of the processing and whether either of the effects takes precedence over the other.
Method
Participants
Ten paid participants (seven women, three men) volunteered for the experiment, with an age range of 18–54 years. All gave informed consent.
Apparatus
For Experiment 5, the stimuli were presented on an Apple iMac OS X 10.6.8 computer, and the experiment was run using the Psychophysics Toolbox in MATLAB 7.4.0 (R2007a).
Stimuli
The following distractor conditions were used: 12D(012), 12D(1), 3D(012), and 3D(1). Due to the brief exposure durations, the stimulus presentation matrix was reduced to a 7 × 7 matrix with a diagonal of 680 pixels: The set size was either 12 or 36.
Target
For each participant, a target was randomly drawn from the stimulus set. The target elements remained the same across the experiment.
Procedure
The participants’ task was to report whether the target was present or absent. Stimulus displays were presented briefly and were postmasked by a pattern mask that covered the stimulus presentation matrix (see Fig. 8). On half of the trials, the exposure duration was 110 ms; on the other half of the trials, it was 200 ms. The participants started the experiment with an extensive training session of 400 trials, to get used to the very short exposure durations. After the training session, participants continued into the 1,600 experimental trials.

Example of the mask used in Experiment 5
Results
On the basis of the accuracy data, d' and criteria (Green & Swets, 1966) were computed for each participant at each exposure duration, set size, and distractor condition. The computed d' values are depicted in Fig. 9, and the criteria are shown in Fig. 10. Figure 9 shows a pattern of accuracy similar to the pattern of RTs in, for example, Fig. 7 (remembering that higher d' and lower RTs are the markers of better performance). It is interesting to note that the criteria (Fig. 10) broadly follow the pattern shown in d' (Fig. 9): As the task gets harder, criteria become more liberal, with participants becoming more inclined to guess that a target might be present. These patterns were investigated separately for d' and criterion using repeated measures ANOVAs with the factors Set Size, Exposure Duration, Sharing, and Groups.

Change in d' values for the four conditions of Experiment 5. Note that worse performance is lower on these graphs

Criterion values for the four conditions of Experiment 5
d' analysis
The ANOVA revealed that all main effects were significant (see Table 6). Exposure duration did not have a significant influence on any of the two conjunctive effects. Interestingly, the Sharing × Groups interaction was also significant. Comparisons revealed that groups had no significant influence when all distractors shared one feature with the target [i.e., 3D(1) vs. 12D(1); see Table 6 and also Fig. 9]. However, the number of groups did influence d’ when the number of features shared varied [3D(012) vs. 12D(012)]. The sharing distribution, on the other hand, had a significant influence on d', irrespective of the number of groups in the displays.
Criteria
Similar to the d' analysis, the ANOVA for the criteria revealed that all main effects were significant. Comparisons based on sharing and groups revealed that both components had significant effects across all the sharing and group combinations (see Table 6).
Discussion
The results of Experiment 5 demonstrated that the effects of both grouping and sharing can be seen in accuracy data at very short exposure durations of 110 and 200 ms. The effects do not appear to develop over the time range investigated here, and neither comes into play before the other. However, the effects of grouping are statistically reliable only when the sharing varies from zero to two features. This is interesting, since, for these short exposure durations, it cannot be argued that the conditions with one shared feature are at ceiling. The results thus suggest that the Sharing factor may be, in some sense, dominant over grouping.
Experiment 6
In Experiment 6 we returned to RT measures, to explore the causes of the sharing effect. Specifically, the significant effect of sharing distribution on search efficiency in the previous experiments suggested that a linear increase in the number of features that a distractor shared with the target did not produce a linear increase in the probability that the distractor would attract attention in the course of search. We hypothesized that items sharing no or one feature with the target were similarly unlikely to be attended, whereas items sharing two features were significantly more disruptive. In order to test this hypothesis, Experiment 6 compared searches in which all of the distractors shared no features with the target to those in which all distractors shared one feature with the target and those in which all distractors shared two features with the target.
Four conditions were created in Experiment 6. Two of these were replications of the distractor conditions from previous experiments: 3D(1), in which each of the three distractors shared one feature with the target, and 3D(012), in which one of the three distractors shared no features with the target, another shared one feature, and the third shared two features. The third condition was 3D(0), in which all distractors shared no features with the target, making this a particularly easy feature search, because the target was unique in color, shape, and orientation. The final condition was 3D(2), in which each distractor shared two features with the target. In all cases, the target was a red, vertical rectangle. Note that in this experiment, it was not the case that the distribution of features was the same across conditions. In conditions 3D(1) and 3D(012), as before, 1/3 of the items were red, green, and blue, and so on. In condition 3D(0), the target features were unique in the display. In condition 3D(2), 2/3 of the items were red, 2/3 vertical, and 2/3 rectangular. The purpose of the experiment was to examine the function relating shared features to search efficiency and to see where 3D(012) would lie on that function.
Method
Participants
A total of 15 participants (nine women, six men) took part in the experiment, with an age range of 18–49 years. All were paid and gave informed consent.
Procedure
Participants were tested on four blocks of trials, corresponding to the 3D(0), 3D(1), 3D(2), and 3D(012) conditions described above. In all, they performed 20 practice trials and 200 experimental trials. Targets were present on 50 % of the trials, and participants gave a forced choice present–absent response via the keyboard.
Results
Two of the participants were removed because their data sets were incomplete. Two others were removed for excessive errors (>25 % in some conditions). The remaining 11 participants had an age range of 20–49 years, and four were men. Trials with RTs more than three standard deviations from the mean or faster than 150 ms were counted as outliers and removed from further analysis [1.5 % of trials; note that the lower cutoff of 150 ms was used here because the blocks of 3D(0) trials produced very fast RTs, meaning that 200-ms RTs were more likely to be real responses]. Participants’ mean RTs for the four different conditions are depicted as a function of set size in Fig. 11. It is clear that distractors that share two features with the target are far more disruptive than distractors sharing one feature or no features.

RT × Set Size functions for the conditions of Experiment 6. Error bars represent within-observer SEMs, calculated by using the Cousineau–Morey method (Cousineau & O’Brien, 2014; Morey, 2008). All conditions have three distractor types, differing in how many features each distractor shares with the target
Reaction times
The target-present RTs revealed significant effects of distractor condition, F(3, 30) = 28.73, GGe = 0.38, p < .001, ges = .48, and set size, F(1, 10) = 39.87, p < .001, ges = .034, together with a significant interaction, F(3, 30) = 17.81, GGe = .65, p < .001, ges = .06. Comparisons of the RTs (see Table 7) revealed that the 3D(012) condition was not significantly slower than the 3D(1) condition, though the difference trended toward significance. The 3D(012) condition was faster than the 3D(2) condition, confirming the extra cost of distractors sharing two features with the target. Regarding search efficiency, the 3D(012) slope was only significantly different from the 3D(2) slope, not from the 3D(1) slope. However, as we discussed earlier, these searches were very fast and likely susceptible to floor effects.
A similar pattern of results was evident for the target-absent trials: distractor condition, F(3, 30) = 56.69, GGe = .39, p < .001, ges = .60; set size, F(1, 10) = 64.32, p < .001, ges = .09; and a significant interaction, F(3, 30) = 23.82, GGe = 0.44, p < .001, ges = .09. For the target-absent trials, RT comparisons revealed the same pattern as for the target-present trials: Participants were significantly slower at quitting the search in the 3D(012) condition than in the 3D(0) condition; the difference trended toward significance when compared to the 3D(1) condition; but performance was faster than in the 3D(2) condition. Although the target-absent slopes for the 3D(012) condition did not differ significantly from the 3D(1) slopes, they were significantly lower than those for the 3D(2) condition.
Error rates
Out of the 5,676 no-outlier target-present trials, there were 417 errors. The target-present error rate ANOVA revealed significant effects of distractor condition and set size, together with a significant interaction (see Table 2). Participants made significantly more errors in the 3D(2) condition than in the 3D(012) or 3D(1) condition (see Table 4). No other comparisons were significant. For the 5,649 no-outlier target-absent trials, only 66 false alarms occurred. We found a significant interaction between set size and distractor condition. The main effects did not reach significance.
Discussion
As is clear from Fig. 11, the relationship of search efficiency to number of shared features is distinctly nonlinear. The 3D(0) condition is more efficient than 3D(1), but 3D(2) is much less efficient than 3D(1). This function explains why 3D(012) is somewhat slower than 3D(1), though not significantly so in this experiment: The harm to performance produced by distractors sharing two features with the target outweighed the benefits produced by distractors sharing no features with the target. The same account would explain the difference between the 12D(1) and 12D(012) conditions of Experiments 3, 4, and 5. The interaction between a target of one type and different mixtures of distractors is systematic, but not trivial to model; obviously, we cannot just average the number of shared features. If so, conditions in which all items shared one feature with the target would be the same as the (012) conditions. Nor can we simply average the slopes of the 3D(0), 3D(1), and 3D(2) conditions to get the 3D(012) result. Experiment 7 reinforced this point by extending the results to six-dimensional conjunctions.
Experiment 7
At the outset of this article, we noted that most objects in the real world would be defined by conjunctions of multiple features. In the experiments to this point, we had extended the usual two-dimensional conjunctions to three dimensions. In Experiment 7, we went to six dimensions to provide evidence that the rules that apply to simpler conjunctions continue to apply as the conjunctions become more complex. In particular, this allowed us to examine the effects of the number of shared features over a wider range than had hitherto been possible.
Method
Participants
Ten participants (five women, five men) volunteered for the experiment, with an age range of 18–47 years. All were paid and gave informed consent.
Stimulus set
Examples of the stimuli are shown in Fig. 12. These stimuli take advantage of the fact that it is possible to guide attention to features of the whole object and, at the same time, to features of a part (Bilsky & Wolfe, 1995; Wolfe, Friedman-Hill, & Bilsky, 1994). Thus, whereas search for a conjunction of two colors is inefficient (Wolfe et al., 1990), search for an object defined by the conjunction of the whole and the color of a part is much more efficient. In Experiment 7, as is shown in Fig. 12, each stimulus element consisted of two components—a smaller figure (part) embedded within a larger figure (whole). The whole and the part of an element each varied in shape, orientation, and color—similar to the stimuli of the preceding experiments. Here, the colors could be red, green, yellow, and blue; the orientations were vertical, horizontal, oblique, and unoriented (all sides of the shape having equal length); and the shapes were rectangular, oval, and jagged. The whole and the part always had two different colors. The orientation and shape features could be the same for the whole and for the part of a stimulus element. The background color of the stimulus display was black (RGB: 0, 0, 0). This yielded a set of over 2,000 possible items.

Six-dimensional conjunctions used in Experiment 7. Each item had a color, orientation, and shape, as well as a part with its own color, orientation, and shape. The target is a yellow vertical rectangle with a red, oblique, oval part. Although it may not be obvious, in this example, each distractor shares exactly two features with the target
Distractor conditions
Five different distractor conditions were used in this experiment. For all five conditions, the distractor set consisted of six different types of conjunction elements. In the first condition, all distractors shared exactly one feature with the target; in the second condition, all distractors shared exactly two features with the target; and so on until the fifth distractor condition, in which all of the distractors each shared exactly five features with the target. Thus, the distractor conditions of the present experiment were 6D(1), 6D(2), 6D(3), 6D(4), and 6D(5). The features that the distractors of a given condition shared with the target were evenly distributed among the distractors. That is, for the 6D(1) condition, each distractor shared a different feature with the target, out of the possible six features. Note that the experimental setup did not allow for equal distributions of the 11 individual features among the parts and the wholes: As feature sharing increased, the number of different features that were represented in the displays decreased. In the example given in Fig. 12, the target is a yellow, vertical rectangle with a red, oblique, vertical part. Each item shares two features with the target. Thus, the item directly below the target shares the “rectangular” feature of the whole and the “red” feature of the part.
Target
For each participant, a target was randomly drawn from the stimulus set. The target element remained the same across the experiment.
Procedure
The participants’ task was to report whether the target was present or absent. The target was present on half of the trials, and the set size was 18 on half of the trials and 36 on the other half. The experiment was blocked by distractor condition. Each block began with 30 practice trials that continued directly into 300 experimental trials. The order of the blocks was randomized across participants.
Results
In all, 3.6 % of the trials were discarded as outliers. The mean RTs for the remaining trials are depicted for each distractor condition as a function of set size in Fig. 13. Slopes and error rates are plotted as a function of the number of shared features in Fig. 14. The basic result is clear: Search becomes slower, less efficient, and less accurate as the number of shared features increases. Search is very efficient if distractors share only one or two features with the target. By the time that targets differ in only one feature, the search is quite difficult. The search slopes of 38.3 ms/item for target-present and 62.9 ms/item for target-absent trials undoubtedly underestimate the true inefficiency of the 6D(5) condition, since miss errors also rose markedly with the number of shared features; miss errors were 19 % for set size 18 and 23 % for set size 36 in the 6D(5) condition.

Reaction times
Analysis of the RTs for target-present trials revealed significant effects of distractor condition, F(4, 36) = 73.26, GGe = 0.45, p < .001, ges = .80, and set size, F(1, 9) = 104.63, p < .001, ges = .22, as well as a significant interaction, F(4, 36) = 15.78, GGe = 0.36, p < .001, ges = .12. Similarly, the target-absent trials revealed significant effects of distractor condition, F(4, 36) = 75.91, GGe = 0.46, p < .001, ges = .80, and set size, F(1, 9) = 133.93, p < .001, ges = .28, along with a significant interaction, F(4, 36) = 28.43, p < .001, ges = .09. In general, RTs and search slopes increased with the number of features that distractors shared with the target. [For all RT comparisons based on one step—e.g., share 1 vs. share 2—this increase was highly significant in every step for both target-present and target-absent trials, F(1, 9) = 13.54 to 128.18 , all ps ≤ .005, ges > .50. The decrease in search efficiency was only significant in two of the one-step comparisons for the target-present trials {6D(2)–6D(3): F(1, 9) = 10.26, p = .032, ges = .07; 6D(3)–6D(4): F(1, 9) = 36.71, p < .001, ges = .21}, and in one step for the target-absent trials {6D(2)–6D(3): F(1, 9) = 17.19, p = .010, ges = 0.9}.]
Error rates
Miss error rates are plotted in Fig. 14 (right panel) and clearly covary with slope. On average, participants made 12.1 % miss errors and 1.3 % false alarm errors across the experimental conditions. For the target-present trials, we found significant main effects of distractor condition and set size on the miss error rates (see Table 2). Miss errors increased with set size and with the number of shared features. The interaction was not significant. None of the effects were significant for the target-absent (false alarm) error rates.

Slopes (left panel) and miss error rates (right panel) as a function of number of shared features in Experiment 7. The dotted lines in the left panel show the data from Experiment 6 for comparison. Error bars represent ±1 within-observer SEMs using the method of Cousineau (2005), corrected as suggested by Morey (2008; see also Cousineau & O’Brien, 2014)
Discussion
The results of Experiment 7 extend the investigation of the Sharing factor from the earlier experiments. When the number of features that are shared with the target is relatively low (≤3), the shared features have an accelerating, nonlinear influence on search efficiency (see Fig. 14, left graph). This is in broad agreement with Duncan and Humphrey’s (1989) observation that search difficulty increases as target–distractor (T–D) similarity increases. The other tenet of similarity theory is that search becomes easier as distractor–distractor (D–D) similarity increases. For the present experiment, D–D similarity actually increased as the number of T–D shared features increased. For example, when the target shared five features with the distractors, a red target would necessarily be presented in a field with mostly red distractors. Apparently, in the present experiment, the T–D costs overwhelmed the D–D benefits. Thus, even more dramatic increases in search slopes might be expected if the distractor feature distribution could be held constant across conditions.
In the GS model (Wolfe, 1994; Wolfe et al., 1989), the efficiency of search depends on what proportion of the distractors on a given trial have greater “activation” than the targets. In the present experiment, we can imagine the target as being the sum of six random, positive signals. A distractor from the 6D(5) set would be the sum of five such signals, a distractor from the 6D(4) set would be the sum of four, and so on. A range of variations on this simple model would produce results that are qualitatively similar to the results in Fig. 14.
The nonlinear effects of T–D similarity can be seen by comparing the slope results of Experiment 6 (dashed lines in the left panel of Fig. 14) with those from Experiment 7 (solid lines). Note that the results are rather similar when targets share one feature with the distractor, whether that feature is one of three (Exp. 6) or one of six (Exp. 7). However, when target and distractors shared two features, search was more difficult in Experiment 6 than in Experiment 7, presumably because a distractor with two of three target features is markedly more similar to the target than is a distractor with two of six target features.
General discussion
To briefly summarize, across all of our experiments, we found evidence that conjunctive variations of features influence search difficulty. Experiments 1a and 1b confirmed that triple conjunction search is influenced by the mix of features in the distractors in the search display. Search is somewhat harder when more distractor types are in the displays, even if those search displays have the same feature content. Experiment 2 showed that this is not a result of a “subset search” strategy. Experiments 1a, 1b, and 2 support the role of a Grouping factor—that the number of different conjunctions in a display influences search. That is, displays with just three groups of distractors are easier to search than displays with 26 groups. Experiments 3 and 4 demonstrated the importance of the Sharing factor—how many features a distractor shares with the target. Experiment 5 confirmed that these effects are in play even at very short exposure durations, and suggested that feature sharing may be a stronger driver of performance than is grouping. Experiment 6 showed that the impact of shared features is nonlinear: Sharing two of three features with the target is markedly worse than sharing one, whereas sharing no features is only a bit better than sharing one. Finally, Experiment 7 extended this result to six-dimensional conjunctions, showing a nonlinear function relating search efficiency to number of shared features.
Extending guided search
How do the findings presented here change our understanding of the guidance of attention in visual search for conjunctions? In the guided search model, the slope of the RT × Set Size function (at least, for target-present trials) reflects the average proportion of distractors that are selected before the target is selected (Wolfe, 1994, 2007; Wolfe et al., 1989). In GS, that selection is based on a combination of bottom-up, stimulus-driven activation (salience) and top-down, user-driven activation. Thus, a red item among green items has high bottom-up salience, regardless of the identity of the target. If the target is known to be, for example, a red, vertical, rectangular item, all red items, all vertical items, and all rectangular items will receive some top-down activation on the basis of the features that they share with the target. Top-down and bottom-up activation are summed across features into a “priority” map (Serences & Yantis, 2006). The relative priority of the target produces the efficiency of search. This could be calculated in various ways, but one useful proposal has come from Moran, Zehetleitner, Müller, and Usher (2013), who suggested that
The results of the experiments reported here show that the probability of selecting a target cannot be a simple linear function of the number of target features that are present in the displays. If the function were linear, the slope for 3D(2) would be roughly twice that for 3D(1), because the sum of all priorities in 3D(2) would be twice that for 3D(1), and consequently, the probability of selecting a target on the current step would be reduced by half. Moreover, the sums of priorities would be the same in 3D(1) and 3D(012) conditions. Instead, the data suggest that distractors that share two out of three features with the target have a high probability of having a larger activation than the target element. Distractors that share one out of three features with the target have a much lower probability of having larger activation than the target element, yet not quite as low as the probability for distractors sharing zero features. The results are in line with a signal detection account of the selection process (see Fig. 15), similar to earlier proposals for target selection in GS (Wolfe, 1994). Here, selection priority is determined by signal strength, which is computed as the sum of target feature signals, bottom-up signals plus some Gaussian noise. In this case, there will be a high probability of selecting a distractor when the distribution of the distractor signal overlaps with the body of the target signal distribution, as illustrated in Fig. 15. The influence of distractors quickly drops, and then levels off when only the tail of target and distractor signal distributions overlap. As we noted above, this nonlinear probability function would account for the difference between 3D(1) and 3D(012).

Three hypothetical distributions of signal strength for elements with varying average signal strengths. As can be seen, the overlap between the distribution with the highest average (the solid line) and the other distributions quickly drops. In this example, although the distances between the distribution averages are linear, the overlaps between distributions are not. The probability that a signal drawn from the low average distribution (dotted line) will be higher than a signal drawn from the high average distribution (solid line) is less than half the probability that a signal drawn from the medium average distribution (striped line) will be higher than a signal from the high average distribution (cf. the dark gray and light gray areas)
The foregoing discussion gives an account of the sharing effect, but it would not explain grouping effects, since the priority calculations just described operate at the level of isolated items in the display. However, as Proulx (2007) pointed out, previous accounts of conjunction search effects may have over-relied on top-down signals. Indeed, by looking more closely at the bottom-up signals that feed into the overall priority map, we can account for the grouping effects in the present studies. First, it is known that bottom-up salience is dependent on neighborhood effects. Thus, a green item is salient if it is surrounded by red. The same green is less salient if it is surrounded by yellow, even if red items are present elsewhere in the display (Nothdurft, 1993). This is cartooned in Fig. 16. The figure shows examples of 3D(012) and 26D(012) trials. The figure shows the boundaries of the sets of red, vertical, and rectangular objects in both cases. In this experiment, these boundaries would often be locations with high local contrast, and thus with high bottom-up salience. Note that other boundaries could be drawn: blue versus green, jagged versus oval, and so forth. It should be clear that the 26D condition produces a much “noisier” landscape of bottom-up saliency than does the 3D condition. Note that all of these local contrasts between items should be thought of as noise; they do not help the participant to find the target, which is found by guiding attention to red, to vertical, and to rectangles. In 3D(012), on the right of Fig. 15, the local contrasts in each feature line up with each other. In 26D(012), they do not line up. If we assume that the sum of three aligned local contrasts is less than three times as attention-grabbing as a single-feature local contrast, then the 26D(012) condition would be “noisier” than the 3D(012). A similar observation was noted by Rosenholtz and colleagues in relation to visual scene complexity (Rosenholtz, Li, & Nakano, 2007). When feature covariance is high, scenes appear to be less cluttered, and a larger range of target feature combinations are salient, thus giving a plausible account of the basic grouping effect in these experiments.

In the 3D(012) conditions (right), groups of items based on features line up across different attributes. Thus, the red, jagged, and vertical groups are similar. In the 26D(012) condition (left), this is not the case
Preattentive binding
The original motivation for this work was to examine the mechanisms that could lead to the conjunctive effects on search efficiency that were reported by Found (1998). Our results support the claim that conjunctive feature variation can influence search efficiency. However, following the argument laid out above, this does not need to imply preattentive feature binding: The grouping and sharing effects allow the results to be explained within the context of a model, like guided search, that does not permit preattentive binding. At the same time, it must be noted that the present results do not rule out the possibility of preattentive binding. Certainly, there is evidence for preattentive interactions between separate dimensions like color and orientation. For example, Houck and Hoffman (1986) showed that a McCollough (1965) effect could be obtained with stimuli that were largely unattended. In the McCollough effect, participants adapt to orthogonal colored gratings—for instance, red verticals and green horizontals. This produces an orientation-contingent color aftereffect. Vertical black and white gratings would now appear tinged green, whereas horizontal gratings would appear pink. If no interaction between color and orientation occurred without attention, this should not happen if the stimuli are unattended, but it does happen.
In a quite different task, the presence of a combination of two feature dimensions can be responded to more quickly than would be predicted by independent processing of those dimensions (e.g., Krummenacher et al., 2001, 2002; Mordkoff & Danek, 2011; Mordkoff et al., 1990; Weidner & Müller, 2013). Specifically, violations of Miller’s (1982) race model inequality suggest that cross-dimensional target signals are combined, or coactivate, prior to selection. We have not made this adjustment, but it seems likely that a nonlinear effect of sharing features could be incorporated into Mordkoff’s coactivation work or into the Krummenacher et al. dimension-weighting account, in order to accommodate the Sharing factor in the triple conjunction experiments reported here. Grouping effects, although not a specific part of these accounts, are not antithetical to them, either.
Some debate has surrounded the interpretation of the conjunction detections that violate Miller’s (1982) race model inequality. Mordkoff, Yantis, and Egeth (1990), among others, have argued that violation of the race model inequality implies that features for more than one object can be bound in parallel (see also Mordkoff & Danek, 2011). On the other hand, several results have suggested that the preselective coactivation does not entail recognition (e.g., Weidner & Müller, 2013). Krummenacher, Grubert, and Müller (2010), for example, found that the race model inequality was not violated for single-element redundant-target trials, thereby indicating that coactivations are separate from recognition processes. In general, it seems quite clear that different dimensions interact at early stages of neural processing in the visual system (Seymour, Clifford, Logothetis, & Bartels, 2010). This could be taken as evidence for preattentive binding (e.g., Mordkoff & Halterman, 2008). Others have used similar results to argue that the whole idea of binding is an “ill-posed” problem (Di Lollo, 2012). However, if binding is thought of as a required step en route to object recognition, then co-occurrence (and coactivation) is not the same as binding, though the distinction can be hard to see in many laboratory tasks (Krummenacher et al., 2010; Wolfe, 2012). For example, a standard search for a red vertical line among red horizontal and green vertical distractors could be performed on the basis of either binding or the co-occurrence of features, because one could find a red vertical on the basis of the place where red and vertical co-occurred, or by finding a preattentively bound red vertical object. The distinction between co-occurrence and binding is clearer when visual search tasks are devised in which the same features co-occur in the targets and distractors, differing only in the arrangement of those features. Under these conditions, search tends to be markedly inefficient, and the evidence for preattentive binding becomes hard to find (Wolfe & Bennett, 1997). Thus, in Fig. 17, search for the plus with a gray horizontal component is inefficient because, we would argue, prior to the arrival of attention, all of these items are both black and gray and vertical and horizontal. That is, all of the bags of features are the same, and co-occurrence is not enough to do the task.

Stimuli in which preattentive binding does not appear to happen: Find the plus sign with black vertical and gray horizontal components (from Wolfe & Bennett, 1997)
In conclusion, search for higher-order conjunctions can be very efficient. This efficiency can be explained by proposing very effective guidance of attention to target items on the basis of top-down knowledge of the target features. The simplest accounts of this guidance are inadequate, as Found (1998) noted 16 years ago. It is possible that these deviations from simplicity reflect preattentive binding of conjunctions. However, it is not necessary to invoke binding without attention. A nonlinear effect of the number of shared features and/or a nonlinearity in bottom-up local salience could also account for these effects.
References
Bilsky, A. B., & Wolfe, J. M. (1995). Part–whole information is useful in visual search for size × size but not orientation × orientation conjunctions. Perception & Psychophysics, 57, 749–760. doi:10.3758/BF03206791
Cousineau, D. (2005). Confidence intervals in within-subject designs: A simpler solution to Loftus and Masson’s method. Tutorials in Quantitative Methods for Psychology, 1, 42–45.
Cousineau, D., & O’Brien, F. (2014). Error bars in within-subject designs: A comment on Baguley (2012). Behavior Research Methods. doi:10.3758/s13428-013-0441-z
Dehaene, S. (1989). Discriminability and dimensionality effects in visual search for featural conjunctions: A functional pop-out. Perception & Psychophysics, 46, 72–80. doi:10.3758/BF03208076
Di Lollo, V. (2012). The feature-binding problem is an ill-posed problem. Trends in Cognitive Sciences, 16, 317–321. doi:10.1016/j.tics.2012.04.007
Dick, M., Ullman, S., & Sagi, D. (1987). Parallel and serial processes in motion detection. Science, 237, 400–402.
Driver, J., McLeod, P., & Dienes, Z. (1992). Motion coherence and conjunction search: Implications for guided search theory. Perception & Psychophysics, 51, 79–85. doi:10.3758/BF03205076
Duncan, J., & Humphreys, G. W. (1989). Visual search and stimulus similarity. Psychological Review, 96, 433–458. doi:10.1037/0033-295X.96.3.433
Eckstein, M. P. (1998). The lower visual search efficiency for conjunctions is due to noise and not serial attentional processing. Psychological Science, 9, 111–118. doi:10.1111/1467-9280.00020
Egeth, H. E., Virzi, R. A., & Garbart, H. (1984). Searching for conjunctively defined targets. Journal of Experimental Psychology: Human Perception and Performance, 10, 32–39. doi:10.1037/0096-1523.10.1.32
Enns, J. T., & Rensink, R. A. (1990). Influence of scene-based properties on visual search. Science, 247, 721–723.
Eriksen, B. A., & Eriksen, C. W. (1974). Effects of noise letters upon the identification of a target letter in a nonsearch task. Perception & Psychophysics, 16, 143–149. doi:10.3758/BF03203267
Eriksen, C. W., & Hoffman, J. E. (1973). The extent of processing of noise elements during selective encoding from visual displays. Perception & Psychophysics, 14, 155–160. doi:10.3758/BF03198630
Found, A. (1998). Parallel coding of conjunctions in visual search. Perception & Psychophysics, 60, 1117–1127. doi:10.3758/BF03206162
Friedman-Hill, S., & Wolfe, J. M. (1995). Second-order parallel processing: Visual search for the odd item in a subset. Journal of Experimental Psychology: Human Perception and Performance, 21, 531–551. doi:10.1037/0096-1523.21.3.531
Green, D. M., & Swets, J. A. (1966). Signal detection theory and psychophysics. New York, NY: Wiley.
Houck, M. R., & Hoffman, J. E. (1986). Conjunction of color and form without attention: Evidence from an orientation-contingent color aftereffect. Journal of Experimental Psychology: Human Perception and Performance, 12, 186–199. doi:10.1037/0096-1523.12.2.186
Humphreys, G. W., Quinlan, P. T., & Riddoch, M. J. (1989). Grouping processes in visual search: Effects with single and combined-feature targets. Journal of Experimental Psychology: General, 118, 258–279.
Ishihara, S. (1987). Test for colour-blindness. Tokyo, Japan: Kanehara.
Kristjánsson, Á., Wang, D. L., & Nakayama, K. (2002). The role of priming in conjunctive visual search. Cognition, 85, 37–52. doi:10.1016/S0010-0277(02)00074-4
Krummenacher, J., Grubert, A., & Müller, H. J. (2010). Inter-trial and redundant-signals effects in visual search and discrimination tasks: Separable pre-attentive and post-selective effects. Vision Research, 50, 1382–1395. doi:10.1016/j.visres.2010.04.006
Krummenacher, J., Müller, H. J., & Heller, D. (2001). Visual search for dimensionally redundant pop-out targets: Evidence for parallel-coactive processing of dimensions. Perception & Psychophysics, 63, 907–917. doi:10.3758/BF03194446
Krummenacher, J., Müller, H. J., & Heller, D. (2002). Visual search for dimensionally redundant pop-out targets: Parallel-coactive processing of dimensions is location specific. Journal of Experimental Psychology: Human Perception and Performance, 28, 1303–1322. doi:10.1037/0096-1523.28.6.1303
Kunar, M. A., Flusberg, S. J., Horowitz, T. S., & Wolfe, J. M. (2007). Does contextual cuing guide the deployment of attention? Journal of Experimental Psychology: Human Perception and Performance, 33, 816–828. doi:10.1037/0096-1523.33.4.816
Kunar, M. A., Flusberg, S. J., & Wolfe, J. M. (2008). Time to guide: Evidence for delayed attentional guidance in contextual cueing. Visual Cognition, 16, 804–825. doi:10.1080/13506280701751224
Kyllingsbæk, K., Sy, J. L., & Giesbrecht, B. (2011). Understanding the allocation of attention when faced with varying perceptual load in partial report: A computational approach. Neuropsychologia, 49, 1487–1497. doi:10.1016/j.neuropsychologia.2010.11.039
Lamberts, K. (1998). The time course of categorization. Journal of Experimental Psychology: Learning, Memory, and Cognition, 24, 695–711. doi:10.1037/0278-7393.24.3.695
Lavie, N., & Torralbo, A. (2010). Dilution: A theoretical burden or just load? A reply to Tsal and Benoni (2010). Journal of Experimental Psychology: Human Perception and Performance, 36, 1657–1664.
Lavie, N., & Tsal, Y. (1994). Perceptual load as a major determinant of the locus of selection in visual attention. Perception & Psychophysics, 56, 183–197. doi:10.3758/BF03213897
McCollough, C. (1965). Color adaptation of edge-detectors in the human visual system. Science, 149, 1115–1116.
McElree, B., & Carrasco, M. (1999). The temporal dynamics of visual search: Evidence for parallel processing in feature and conjunction searches. Journal of Experimental Psychology: Human Perception and Performance, 25, 1517–1539. doi:10.1037/0096-1523.25.6.1517
McLeod, P., Driver, J., Dienes, Z., & Crisp, J. (1991). Filtering by movement in visual search. Journal of Experimental Psychology: Human Perception and Performance, 17, 55–64. doi:10.1037/0096-1523.17.1.55
Miller, J. (1982). Divided attention: Evidence for coactivation with redundant signals. Cognitive Psychology, 14, 247–279. doi:10.1016/0010-0285(82)90010-X
Moran, R., Zehetleitner, M., Müller, H. J., & Usher, M. (2013). Competitive guided search: Meeting the challenge of benchmark RT distributions. Journal of Vision, 13(8), 24. doi:10.1167/13.8.24
Mordkoff, J. T., & Danek, R. H. (2011). Dividing attention between color and shape revisited: Redundant targets coactivate only when parts of the same perceptual object. Attention, Perception, & Psychophysics, 73, 103–112. doi:10.3758/s13414-010-0025-2
Mordkoff, J. T., & Halterman, R. (2008). Feature integration without visual attention: Evidence from the correlated flankers task. Psychonomic Bulletin & Review, 15, 385–389. doi:10.3758/PBR.15.2.385
Mordkoff, J. T., Yantis, S., & Egeth, H. E. (1990). Detecting conjunctions of color and form in parallel. Perception & Psychophysics, 48, 157–168. doi:10.3758/BF03207083
Morey, R. D. (2008). Confidence intervals from normalized data: A correction to Cousineau (2005). Tutorial in Quantitative Methods for Psychology, 4, 61–64.
Nakayama, K., & Silverman, G. H. (1986). Serial and parallel processing of visual feature conjunctions. Nature, 320, 264–265.
Nothdurft, H.-C. (1993). Saliency effects across dimensions in visual search. Vision Research, 33, 839–844.
Palmer, J. (1995). Attention in visual search: Distinguishing four causes of a set size effect. Current Directions in Psychological Science, 4, 118–123. doi:10.1111/1467-8721.ep10772534
Pashler, H. (1987). Detecting conjunctions of color and form: Reassessing the serial search hypothesis. Perception & Psychophysics, 41, 191–201.
Proulx, M. J. (2007). Bottom-up guidance in visual search for conjunctions. Journal of Experimental Psychology: Human Perception and Performance, 33, 48–56. doi:10.1037/0096-1523.33.1.48
Quinlan, P. T., & Humphreys, G. W. (1987). Visual search for targets defined by combinations of color, shape, and size: An examination of the task constraints on feature and conjunction searches. Perception & Psychophysics, 41, 455–472. doi:10.3758/BF03203039
Roggeveen, A. B., Kingstone, A., & Enns, J. T. (2004). Influence of inter-item symmetry in visual search. Spatial Vision, 17, 443–464.
Rosenholtz, R., Li, Y., & Nakano, L. (2007). Measuring visual clutter. Journal of Vision, 7(2), 17.1–17.22. doi:10.1167/7.2.17
Serences, J. T., & Yantis, S. (2006). Selective visual attention and perceptual coherence. Trends in Cognitive Sciences, 10, 38–45. doi:10.1016/j.tics.2005.11.008
Seymour, K., Clifford, C. W., Logothetis, N. K., & Bartels, A. (2010). Coding and binding of color and form in visual cortex. Cerebral Cortex, 20, 1946–1954. doi:10.1093/cercor/bhp265
Takeda, Y., Phillips, S., & Kumada, T. (2007). A conjunctive feature similarity effect for visual search. Quarterly Journal of Experimental Psychology, 60, 186–190.
Townsend, J. T. (1971). A note on the identification of parallel and serial processes. Perception & Psychophysics, 10, 161–163.
Townsend, J. T., & Wenger, M. J. (2004). The serial–parallel dilemma: A case study in a linkage of theory and method. Psychonomic Bulletin & Review, 11, 391–418. doi:10.3758/BF03196588
Treisman, A. M., & Gelade, G. (1980). A feature-integration theory of attention. Cognitive Psychology, 12, 97–136. doi:10.1016/0010-0285(80)90005-5
Treisman, A., & Sato, S. (1990). Conjunction search revisited. Journal of Experimental Psychology: Human Perception and Performance, 16, 459–478. doi:10.1037/0096-1523.16.3.459
Tsal, Y., & Benoni, H. (2010). Diluting the burden of load: Perceptual load effects are simply dilution effects. Journal of Experimental Psychology: Human Perception and Performance, 36, 1645–1656. doi:10.1037/a0018172
Verghese, P., & Nakayama, K. (1994). Stimulus discriminability in visual search. Vision Research, 34, 2453–2461. doi:10.1016/0042-6989(94)90289-5
Weidner, R., & Müller, H. J. (2009). Dimensional weighting of primary and secondary target-defining dimensions in visual search for singleton conjunction targets. Psychological Research, 73, 198–211.
Weidner, R., & Müller, H. J. (2013). Dimensional weighting in cross-dimensional singleton conjunction search. Journal of Vision, 13(3), 25:1–22. doi:10.1167/13.3.25
Williams, D. E., & Reingold, E. M. (2001). Preattentive guidance of eye movements during triple conjunction search tasks: The effects of feature discriminability and saccadic amplitude. Psychonomic Bulletin & Review, 8, 476–488. doi:10.3758/BF03196182
Wolfe, J. M. (1992). “Effortless” texture segmentation and “parallel” visual search are not the same thing. Vision Research, 32, 757–763.
Wolfe, J. M. (1994). Guided Search 2.0: A revised model of visual search. Psychonomic Bulletin & Review, 1, 202–238. doi:10.3758/BF03200774
Wolfe, J. M. (1998). What can 1 million trials tell us about visual search? Psychological Science, 9, 33–39. doi:10.1111/1467-9280.00006
Wolfe, J. M. (2007). Guided Search 4.0: Current progress with a model of visual search. In W. D. Gray (Ed.), Integrated models of cognitive systems (pp. 99–119). New York, NY: Oxford University Press.
Wolfe, J. M. (2012). The binding problem lives on: Comment on Di Lollo. Trends in Cognitive Sciences, 16, 307–308. doi:10.1016/j.tics.2012.04.013
Wolfe, J. M., & Bennett, S. C. (1997). Preattentive object files: Shapeless bundles of basic features. Vision Research, 37, 25–43. doi:10.1016/S0042-6989(96)00111-3
Wolfe, J. M., Cave, K. R., & Franzel, S. L. (1989). Guided search: An alternative to the feature integration model for visual search. Journal of Experimental Psychology: Human Perception and Performance, 15, 419–433. doi:10.1037/0096-1523.15.3.419
Wolfe, J. M., Friedman-Hill, S. R., & Bilsky, A. B. (1994). Parallel processing of part/whole information in visual search tasks. Perception & Psychophysics, 55, 537–550. doi:10.3758/BF03205311
Wolfe, J. M., Yu, K. P., Stewart, M. I., Shorter, A. D., Friedman-Hill, S. R., & Cave, K. R. (1990). Limitations on the parallel guidance of visual search: Color × Color and Orientation × Orientation conjunctions. Journal of Experimental Psychology: Human Perception and Performance, 16, 879–892. doi:10.1037/0096-1523.16.4.879
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Nordfang, M., Wolfe, J.M. Guided search for triple conjunctions. Atten Percept Psychophys 76, 1535–1559 (2014). https://doi.org/10.3758/s13414-014-0715-2
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13414-014-0715-2