
Abstract
Object substitution masking (OSM) occurs when an initial display of a target and mask continues with the mask alone, creating a mismatch between the reentrant hypothesis, triggered by the initial display, and the ongoing low-level activity. We tested the proposition that the critical factor in OSM is not whether the mask remains in view after target offset, but whether the representation of the mask is sufficiently stronger than that of the target when the reentrant signal arrives. In Experiment 1, a variable interstimulus interval (ISI) was inserted between the initial display and the mask alone. The trailing mask was presumed to selectively boost the strength of the mask representation relative to that of the target. As predicted, OSM occurred at intermediate ISIs, at which the mask was presented before the arrival of the reentrant signal, creating a mismatch, but not at long ISIs, at which a comparison between the reentrant signal and the low-level activity had already been made. Experiment 2, conducted in dark-adapted viewing, ruled out the possibility that low-level inhibitory contour interactions (metacontrast masking) had played a significant role in Experiment 1. Metacontrast masking was further ruled out in Experiment 3, in which the masking contours were reduced to four small dots. We concluded that OSM does not depend on extended presentation of the mask alone, but on a mismatch between the reentrant signals and the ongoing activity at the lower level. The present results place constraints on estimates of the timing of reentrant signals involved in OSM.
Similar content being viewed by others
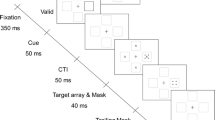
Visual masking refers to a reduction in the visibility of a briefly presented object (the target) by the presentation of a second object (the mask) in spatiotemporal proximity. Masking is known to be mediated by different mechanisms, depending on the spatiotemporal relationship between the target and the mask.
The present work is concerned with the type of masking that occurs when there is no spatial overlap between the contours of the target and the contours of the mask. Two such types of masking have been documented: metacontrast masking and object substitution masking (OSM). The two types of masking have been shown to differ in important ways, as outlined below. A principal objective of the present work was to distinguish amongst different accounts of OSM.
Object substitution masking
The display sequence in OSM begins with a brief presentation of the target and the mask, and continues with a longer display of the mask alone. When the target and the mask terminate together, the target is identified accurately. Masking develops rapidly, however, as the duration of the trailing mask is increased up to about 200 ms (Di Lollo, Enns, & Rensink, 2000).
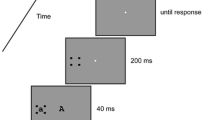
The sequence of events in OSM, also known as common-onset masking or four-dot masking, is illustrated in Fig. 1b, redrawn from Fig. 2 of Di Lollo et al. (2000). The display consists of 1–16 rings, each with a gap placed randomly at one of the cardinal orientations. The target ring is singled out by a complete ring that surrounds it, which also acts as the mask. The observer’s task is to indicate the orientation of the gap in the target ring. The typical pattern of OSM for two observers is illustrated in Fig. 2, redrawn from Fig. 3 of Di Lollo et al. (2000). As can be seen in Fig. 2, the strength of OSM increases with increments in the number of elements in the display (set size) and in the duration of the trailing mask.


A typical pattern of object substitution masking in two observers. The strength of masking increases with increments in set size and in the duration of the trailing mask. Redrawn from Fig. 3 of “Competition for Consciousness Among Visual Events: The Psychophysics of Reentrant Visual Processes,” by V. Di Lollo, J. T. Enns, and R. A. Rensink, 2000, Journal of Experimental Psychology: General, 129, p. 487. Copyright 2000 by the American Psychological Association

(a) Model illustrating the increasing difference in the strength of the representation of the mask (dotted lines) relative to that of the target and distractors (solid lines) as a function of mask duration. (b) Hypothetical results arising from the model. See the text for explanation
In the paradigm illustrated in Fig. 1b, the target and the mask have a common onset; therefore, no separate, temporally trailing onset transient is generated by the mask. This rules out onset transients as a source of masking (Enns & Di Lollo, 2000). Rather, OSM is thought to be mediated by reentrant signalling between brain regions connected by two-way pathways. In the feed-forward sweep, the neural activity triggered by the initial display ascends to higher brain regions, where it is said to activate one or more perceptual hypotheses that descend to lower levels, where they correlate themselves with the ongoing activity. Low correlations are discarded, whereas the hypothesis that yields the highest correlation is confirmed and leads to correct target identification (Di Lollo et al., 2000; Grossberg, 1995; Mumford, 1991, 1992).
Masking occurs when a mismatch arises between the reentrant signal and the ongoing activity at the lower level. The three panels in Fig. 3a illustrate the state of affairs at three durations of the trailing mask. In all three panels, the strength of the target/distractors representation triggered by the onset of the display decays as a function of time since display offset. The representation of the mask also decays as a function of time from mask offset. However, because of the longer exposure duration (indicated by the flat portion of the mask functions in Fig. 3a), the strength of the mask representation is greater than that of the target/distractors. The longer the duration of the mask, the greater the difference between the two representations at any point in time beyond mask offset. The decay functions are represented as linear for simplicity. However, the hypothesized relationships would still obtain with any other monotonically decreasing function.
The vertical segmented lines in Fig. 3a indicate the time at which the reentrant signals carrying the perceptual hypotheses arrive at the lower level. The actual time of reentry illustrated in Fig. 3a is arbitrary, but its relationship to the duration of the mask was inferred from the data in Fig. 2. With respect to masking, the important consideration is the goodness of the match between the reentrant hypothesis and the pattern of activity at the lower level at the time of reentry.
When the duration of the trailing mask is short (Fig. 3a, left-hand panel), the reentrant signals find a pattern of low-level activity that, although decayed, is of relatively uniform strength. Notably, the representation of the mask is only slightly stronger than that of the target/distractors. In this case (and assuming that the low-level representation has not decayed below a critical level), little or no masking occurs because the similarity between the reentrant hypothesis and the low-level representation mediates an adequate correlation, with ensuing confirmation of that perceptual hypothesis. This leads to accurate identification of the target, as illustrated by the short-mask-duration point in Fig. 3b.
In contrast, when the duration of the trailing mask is long (Fig. 3a, right-hand panel), the reentrant signals find a pattern of low-level activity of nonuniform strength: The strength of the target/distractors representation has decayed, but the mask remains at full strength because of the continued external input. This mismatch reduces the correlation with the reentrant hypothesis, which includes the representations of the target and the mask at equal strength. Masking occurs because the low correlation between the low-level activity and the reentrant hypothesis causes a new “mask-alone” hypothesis to be generated, consistent with the currently predominant activity at the lower level. Under these conditions, the mask-alone percept replaces the target-plus-mask percept, with consequent impairment of target identification, as is illustrated by the long-mask-duration point in Fig. 3b.
Põder’s feed-forward model of OSM
In contrast to the reentrant model outlined above, a strictly feed-forward model of OSM has been proposed by Põder (2012). This model is based on two assumptions. First, that the continued presence of the mask after the offset of the initial display adds noise, thus reducing the signal-to-noise ratio (SNR) at the target location. Because of temporal integration, the noise continues to grow while the mask remains in view. For this reason, the reduction in SNR is said to be proportional to the exposure duration of the mask alone. Second, it is assumed that masking occurs when attention is deployed to the target location and finds a degraded representation due to reduced SNR. Considered jointly, these assumptions predict the strength of masking to increase with the duration of the mask alone.
Põder (2012) provided a computational model that embodied these assumptions and produced functions that fit the OSM data reported by Di Lollo et al. (2000) quite well. This supported the conclusion that OSM can be explained on the basis of strictly feed-forward principles, without recourse to reentry.
Metacontrast masking
Metacontrast masking occurs when a brief presentation of a target stimulus is followed by the presentation of a masking stimulus whose contours are closely adjacent to—but do not overlap with—the contours of the target. The sequence of events is illustrated in Fig. 1a. The accuracy of target identification in metacontrast masking is a U-shaped function of the stimulus onset asynchrony (SOA) between the target and the mask (Breitmeyer & Öğmen, 2006; Di Lollo, von Mühlenen, Enns, & Bridgeman, 2004). The target is clearly visible at long and short SOAs, but not at intermediate SOAs.
The mechanisms thought to underlie metacontrast masking are inhibitory interactions between neurons that represent the contours of the target and the mask (Breitmeyer & Ganz, 1976; Breitmeyer & Öğmen, 2006; Weisstein, Ozog, & Szoc, 1975). Both the target and the trailing mask are said to activate two channels in the visual system: a fast transient channel that carries information regarding stimulus onset, and a slower sustained channel that carries information regarding stimulus identity. Masking occurs when activity in the fast transient channel triggered by the onset of the mask inhibits the slower sustained activity triggered by the earlier target. It is generally agreed that metacontrast masking operates at an early stage of vision, a stage characterized by contour formation.
Two characteristics of metacontrast masking are especially relevant to the present work. First, metacontrast masking does not occur—or is much reduced—in dark-adapted viewing. This is because inhibitory processes are known to be weak or absent in the dark-adapted visual system (Barlow, Fitzhugh, & Kuffler, 1957; Bischof & Di Lollo, 1995; von Békésy, 1968). Second, reducing the amount of contours in the masking stimulus results in a corresponding reduction in the strength of masking (Breitmeyer, 1984).
Theoretical predictions based on a novel OSM paradigm
The reentrant model of OSM
As we noted above, the mainstay of the object substitution account is that masking occurs when a significant non-uniformity in the strength of the ongoing activity at the lower level causes a mismatch with the reentrant hypothesis. In conventional studies of OSM (e.g., Neill, Hutchison, & Graves, 2002; Woodman & Luck, 2003), the mismatch is brought about by manipulating the exposure duration of the trailing mask (Fig. 3a). According to the reentrant-processing account, however, the essential factor in this manipulation is not the mask’s duration as such, but whether the strength of the mask representation is substantially higher than that of the target/distractors representation at the time of reentry, causing a mismatch with the perceptual hypothesis.
This conjecture was tested in the present work by changing the way in which the mismatch was brought about. Instead of manipulating the exposure duration of the mask, we manipulated the duration of a blank interstimulus interval (ISI) inserted between the initial display and a brief presentation of the mask alone, as is illustrated in Fig. 1c. We reasoned that the brief reappearance of the mask would boost the internal representation of the mask toward its original strength, thus causing a mismatch between the ongoing low-level activity and the reentrant hypothesis. In this paradigm, a mismatch should occur only when the trailing mask is displayed before the time of reentry, and the size of the mismatch should depend on the duration of the ISI, as is illustrated in Fig. 4a.

(a) Model illustrating the relationship between interstimulus interval (ISI) and differences in the strengths of the target and mask representations at the time of reentry. (b) Hypothetical results arising from the model. See the text for explanation
The left-hand panel of Fig. 4a illustrates the case in which no trailing display of the mask alone is presented. Because all parts of the display decay uniformly, no mismatch with the perceptual hypothesis occurs at the time of reentry, and the accuracy of target identification is relatively high, as is shown by the zero-ISI point in Fig. 4b. This is also the case in the right-hand panel, in which the ISI is long and the trailing mask is presented after the time of reentry, when a comparison between the reentrant hypothesis and the low-level activity had already been made. This prevents a mismatch, allowing accurate identification of the target, as is illustrated by the long-ISI point in Fig. 4b. A different picture emerges from the middle panel of Fig. 4a, however, in which the ISI is shorter than the time of reentry. In that case, the trailing mask boosts the strength of the mask representation, causing a mismatch with the reentrant hypothesis at the time of reentry. The ensuing impairment in the accuracy of target identification is illustrated by the medium-ISI point in Fig. 4b. Experiment 1 was a test of these predictions.
Põder’s feed-forward model of OSM
A different pattern of results can be predicted from Põder’s (2012) feed-forward model, in which OSM is said to arise from the reduction in SNR due to the temporal integration of the noise at the target location. Thus, increasing the exposure duration of the mask would lead to a corresponding increment in the amount of noise added to the target representation, and stronger masking would then follow.
An important characteristic of the new OSM paradigm outlined above is that the duration of the mask is fixed across all conditions. According to Põder’s (2012) assumption that the amount of accumulated noise is proportional to the duration of the mask, the amount of noise added to the target representation by the trailing mask would be invariant across conditions. On the grounds that the target representation decays during the ISI, the addition of a fixed amount of noise to the decaying representation would predict a monotonically decreasing function of target identification over ISI. The case of invariant additional noise is not dealt with explicitly in Põder’s model, but it is likely that its tenets may need revising to encompass this case.
Metacontrast masking
The new OSM paradigm outlined above (Fig. 1c) and the conventional metacontrast-masking paradigm (Fig. 1a) bear distinct similarities to one another and may, therefore, be expected to yield similar outcomes. From the perspective of metacontrast masking, the reappearance of the mask after an appropriate blank interval (see Fig. 1c) could trigger an onset transient that would interfere with the processing of the target’s contours along the sustained channel. Thus, the predicted U-shaped function in Fig. 4b would be consistent not only with a reentrant-processing account, but also with an account based on metacontrast masking. In the present work, the two accounts are decoupled in Experiments 2 and 3.
Experiment 1
Method
The data reported in the present Experiments 1 and 2 were collected from the same two observers (M.H. and R.G.) and with the same equipment, stimuli, and general procedures used in Experiments 1 and 2 of Di Lollo et al. (2000). The experiments were performed at approximately the same time as those reported in the study by Di Lollo et al. (2000). For this reason, the description of observers, equipment, and stimuli has been taken almost verbatim from that article. The description of the procedures was modified as appropriate.
Observers and apparatus
One male and one female undergraduate student with corrected-to-normal vision served as paid observers. Both were highly practiced psychophysical observers. They sat in a lightproof room and viewed the displays from a distance of 57 cm, set by a headrest. The stimuli were displayed within a 4º× 4º area in the center of the screen of a Tektronix 608 oscilloscope equipped with a fast P15 phosphor. The screen was front-illuminated with a Kodak Carousel projector fitted with a 500-W General Electric Quartzline projection lamp, attenuated to 10 cd/m2 by neutral-density filters. All stimuli were constructed with closely spaced dots. With front illumination turned on, the dots were seen as green-blue on a uniform white background. In dark-adapted viewing, as in Experiment 2, the dots were seen as light gray on a uniformly black screen (0 cd/m2). The X, Y, and Z (intensity) coordinates of each dot were stored in a fast-plotting buffer that displayed them to the screen at a rate of one dot/μs (Finley, 1985). Photometric measurements were made with a Minolta LS-100 luminance meter.
Stimuli
The stimuli are illustrated in Fig. 1b. On any given trial, the display consisted of one or more rings, each with a gap at either the top, bottom, left, or right. The thickness of each ring was approximately 1 min arc, the radius was 0.4º, and the size of the gap corresponded to a chord of 0.4º. One of the rings was singled out as the target by a slightly larger concentric ring, which also served as a mask. The radius of the masking ring was 0.5º. The observer’s task was to identify the orientation of the target’s gap. The other rings in the display functioned as distractors. The viewing area was partitioned into a notional matrix of 16 square cells, each with 1º side. Every ring, whether target or distractor, was displayed in the center of one of the notional cells.
Design and procedures
The sequence of events in Experiment 1 is illustrated in Fig. 1c. It began with a 10-ms display of all elements (target, mask, and distractors), and continued with a blank ISI whose duration was either 0, 30, 70, 150, or 310 ms, corresponding to stimulus-onset asynchronies (SOAs) of 10, 40, 80, 160, and 320 ms. The design consisted of the factorial combination of two variables: set size (number of rings in the display) and ISI. Set size was varied over five levels: 1, 2, 4, 8, or 16 rings, including the target. When the set size was equal to 1, the display contained only the target. When the set size was greater than 1, the display contained the target plus the appropriate number of distractors, distributed randomly amongst the remaining 15 locations, with the restriction that within a session, the target appeared an equal number of times in each of the 16 locations. The duration of the second frame, which contained only the mask, was 10 ms. Trials were separated by a minimum interval of 5 s.
At the beginning of each trial, a small fixation cross was presented in the center of the screen. A trial was started when the observer pressed a button in a handheld box. The observer then indicated the location of the gap in the target by pressing the appropriate button (top, bottom, left, or right) in the handheld box, guessing if not sure. One session consisted of 160 trials. Within one session, the target was displayed ten times in each of the 16 matrix locations, in a sequence that varied randomly across sessions and observers. In any given session, the number of distractors was fixed. The 25 sessions resulting from the factorial combination of five set sizes and five ISIs, were ordered randomly for each observer. The experiment was then replicated, thus yielding a total of 20 estimates per cell per condition. Each observer thus contributed a total of 8,000 trials, being the product of 25 conditions, 16 matrix locations, and 20 trials per location. The 25 sessions were spread over a period of approximately three weeks.
Results and discussion
The results of Experiment 1, averaged over all 16 target locations,Footnote 1 are shown in Fig. 5, separately for each observer. The functions exhibit the U-shaped pattern predicted by the reentrant-processing hypothesis of OSM discussed above and illustrated in Fig. 4b. Namely, accuracy of target identification was relatively high when the ISI was short or long, but was substantially impaired at an ISI of 70 ms. This is consistent with the prediction, illustrated in Fig. 4a, that masking occurs only when the trailing mask is presented before the reentrant hypotheses arrive at the lower level. The evidence in Fig. 5 strongly suggests that the reentrant signals arrive between 80 and 160 ms after the onset of the initial display. Actually, that evidence suggests a time of reentry closer to 80 than to 160 ms (somewhere between 80 and 120 ms).

Results of Experiment 1
In contrast, the nonmonotonic functions in Fig. 5 are inconsistent with Põder’s (2012) model, which, as noted above, can be used to predict a monotonically decreasing function. Clearly, in its current version, Põder’s model cannot encompass the present findings.
The functions in Fig. 5 look very much like the U-shaped functions obtained in conventional metacontrast masking, in which a briefly presented target stimulus is followed, at a variable SOA, by a masking stimulus whose contours are closely adjacent to—but do not overlap with—the contours of the target. (Breitmeyer & Öğmen, 2006; Di Lollo et al., 2004). As was noted in the foregoing discussion, it could be argued that the results of the present experiment might have arisen, at least in part, from metacontrast masking produced by inhibitory contour interactions between the target and the trailing mask. This would implicate low-level mechanisms as distinct from the high-level reentrant mechanisms hypothesized in the OSM account.
One way of distinguishing between the contributions of low-level and high-level mechanisms in the present results is suggested by Bischof and Di Lollo’s (1995) finding that metacontrast masking, which is fully evident in light-adapted viewing, is all but absent in dark-adapted viewing. In the relevant condition in Bischof and Di Lollo’s study, the observers viewed a conventional metacontrast sequence in which the mask was presented at various ISIs after the target had been turned off. The viewing was done under both light-adapted and dark-adapted conditions. The results, illustrated in their Figs. 11 and 12, showed that conventional metacontrast masking occurs in light-adapted but not (or much less so) in dark-adapted viewing. This is because low-level inhibitory contour interactions are known to be absent in scotopic vision (Barlow et al., 1957; von Békésy, 1968). In contrast, OSM is fully in evidence not only in light-adapted but also in dark-adapted viewing, namely, in the absence of inhibitory processes (Bischof & Di Lollo, 1995; Di Lollo et al., 2000). On this evidence, the low-level component, if any, in the present results could be ruled out if a pattern of results similar to that in Fig. 5 were to be obtained under dark-adapted viewing conditions. This was done in Experiment 2.
Experiment 2
Method
The observers and procedures were the same as in Experiment 1, except that the experiment was carried out in total darkness. The observers sat in a dark room for 30 min before beginning the experiment. The luminance of the stimuli was determined in a preliminary procedure in which the two observers viewed a square test patch displayed continuously on the screen. We found that when the luminance of the test patch was 3.0 cd/m2 and the stimuli were displayed for 10 ms, the gap in the rings could barely be seen by dark-adapted observers. If the luminance of the displays was reduced to that corresponding to a test patch of 2.0 cd/m2, the task of identifying the orientation of the gap was no longer feasible. Under these low-luminance conditions, any light adaptation that might have occurred during a trial was not photochemical but neural (e.g., Walraven, Enroth-Cugell, Hood, MacLeod, & Schnapf, 1990). Recovery from neural light adaptation is very fast: Baker (1963) estimated a recovery of two log units within 250 ms, which is far less than the 5-s intertrial interval.
Results and discussion
The results of Experiment 2, averaged over all 16 target locations, are shown in Fig. 6, separately for each observer. Consistent with the findings of Di Lollo et al. (2000), OSM was as much in evidence in dark-adapted viewing (Fig. 6) as in light-adapted viewing (Fig. 5). Because adapting luminance is known to have a powerful influence on low-level processes (Barlow et al., 1957; Ikeda, 1965; Sperling & Sondhi, 1968; von Békésy, 1968) but not on higher level processes (Adelson & Jonides, 1980; Coltheart, 1980; Scharf & Lefton, 1970), the finding that OSM occurred in dark-adapted viewing supports the conclusion that the results of Experiment 1 were due not to low-level processes of inhibitory contour interactions (metacontrast masking), but to higher-level processes of object substitution.

Results of Experiment 2
Experiment 3
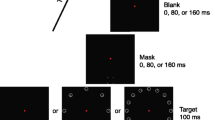
The principal objective of Experiment 3 was to provide further evidence that the results of Experiment 1 were mediated by OSM rather than by metacontrast masking. In Experiment 2, this had been done by showing that the U-shaped functions obtained in Experiment 1 (Fig. 5) were also in evidence in dark-adapted viewing (Fig. 6), an outcome inconsistent with a metacontrast account. In the present experiment, the same objective was achieved by reducing the amount of contour in the mask. It is known that metacontrast masking does not occur, or is much reduced, when the contours of the mask are sparse (Breitmeyer, 1984; Werner, 1935). In the present experiment, the contours of the mask were reduced from the solid ring used in Experiments 1 and 2 to four small dots, as is illustrated in the left-hand panel of Fig. 7. A U-shaped function of SOA would be expected on the basis of OSM, but not on the basis of metacontrast masking.

A second objective of Experiment 3 was to extend the generality of the results beyond what was obtained with highly practiced observers in Experiments 1 and 2. In the present experiment, we employed unpracticed observers: university undergraduates who participated in the experiment for course credit. Because the observers were available for only a single session, the number of trials had to be scaled down from the 8,000 in Experiments 1 and 2. This was done by using only one set size (eight elements) and only three SOAs between the initial display and the reappearance of the mask.
Method
The methods and procedures in Experiment 3 were the same as those in Experiment 1, with the following exceptions. The observers were 12 undergraduate students at Simon Fraser University who received course credit for participating in the experiment. They were naive psychophysical observers, and had normal or corrected-to-normal vision. The stimuli were presented on a BenQ XL2410T LCD screen, which is known to be free from image persistence (Lagroix, Yanko, & Spalek, 2012). The refresh rate was 120 Hz. Stimulus presentation and response collection were controlled using E-Prime software (Psychology Software Tools, Inc., Sharpsburg, PA). The display sequence, illustrated in Fig. 7a, began with a 16-ms presentation of eight rings, similar to those used in Experiments 1 and 2. The thickness of each ring was approximately 1.8 min arc. One of the rings was designated as the target by four small dots that also served as the mask. The four dots were displayed at the corners of an imaginary square surrounding the target ring. The angular size of each dot was 0.1º, and its separation from the contour of the target ring was 0.2º. The display sequence continued with the reappearance of the mask after an SOA of either 0 (no trailing mask), 80, or 320 ms, as is illustrated in Fig. 7a. The three SOAs were presented in random order for 120 trials each.
Results and discussion
The results of Experiment 3, averaged over all 12 observers, are illustrated by the solid-symbol function in Fig. 7b. The open-symbol function shows the results for the set size 8 condition in Experiment 1 (Fig. 5), averaged over the two observers. A one-way repeated measures analysis of variance performed on the results of Experiment 3 revealed a significant effect of SOA, F(2, 22) = 59.96, MSE = 23.63, p < .001, η p 2 = .85. Notably, the quadratic component accounted for a substantial proportion of the variance, F(1, 11) = 74.25, MSE = 36.71, p < .001, η p 2 = .87.
It is known that metacontrast masking is much reduced, or is entirely absent, when the mask has sparse contours—such as the four dots used in Experiment 3 (Breitmeyer, 1984; Werner, 1935). The critical consideration in this respect is that the two functions in Fig. 7b are remarkably similar to one another. Had metacontrast masking played a significant role, performance in Experiment 1 (open symbols in Fig. 7b) should have been lower than that in Experiment 3 (filled symbols in Fig. 7b). This is because the mask had far more contours in Experiment 1 than in Experiment 3. In fact, Fig. 7b reveals the opposite relationship, at least numerically.
It can be concluded, therefore, that the results of Experiment 3 arose not from low-level inhibitory contour interactions (metacontrast masking) but from higher-level processes of object substitution. Considered collectively, the results of Experiments 2 and 3 support the conclusion that the results of Experiment 1 (Fig. 5) represent the effects of OSM rather than metacontrast masking.
The sparse mask used in Experiment 3 also has clear implications for predictions based on Põder’s (2012) model. As we noted above, the principal role of the mask in that model is to add noise to the target representation, thereby reducing the SNR. On the basis of this hypothesis, the solid-ring mask used in Experiment 1 should have produced a substantially greater amount of noise relative to the four small dots used in Experiment 3. Thus, the strength of masking should have been greater in Experiment 1 than in Experiment 3. To the contrary, the functions in Fig. 7b reveal comparable levels, with performance being slightly better in Experiment 1, at least numerically.
General discussion
In the present work we tested the prediction that the important consideration in OSM is not the duration of the trailing mask, as such, but whether the strength of the low-level representation of the mask is markedly greater than that of the target/distractors representation when the perceptual hypotheses triggered by the initial display arrive at the lower level. This was done in Experiment 1 by inserting a blank ISI between the offset of the initial display (target, mask, and distractors) and a brief display of the mask alone, which was hypothesized to boost the decaying representation of the mask.Footnote 2 According to the OSM account, masking should occur only when the trailing mask is displayed before the reentrant signals arrive at the lower level. This should give rise to a U-shaped function of accuracy on ISI, as illustrated in Fig. 4b. The results of Experiment 1 confirmed this prediction. Experiment 2, conducted in dark-adapted viewing, ruled out the option that low-level inhibitory contour interactions (metacontrast masking) played a significant role in Experiment 1. Metacontrast masking was ruled out further in Experiment 3, in which the amount of masking contours was reduced to four small dots.
It is worth noting that an alternative account of OSM has been offered by Lleras and Moore (2003), who regarded OSM as an instance of object updating. That view was prompted by the finding that OSM occurs not only when the mask continues to be presented at the initial location (i.e., surrounding the target), but also when it is presented at a nearby location. This causes the mask to be seen as in motion from the initial location. Masking is then attributed to the morphing of the initial target-plus-mask representation into a representation of the mask alone.
Far from being incompatible with one another, the object-updating model (Lleras & Moore, 2003) and the object substitution model (Di Lollo et al., 2000) can be regarded as complementary. For the purpose of the present work, it is important to note that both models regard masking as arising from reentrant processing. As was pointedly noted by Moore and Lleras (2005, p. 1179) “object-mediated updating through reentrant processing involves the online overwriting of existing information.”
Beyond confirming predictions from the OSM account, the present results place constraints on estimates of the timing of reentrant signals. Given that, for OSM to occur, the trailing mask must be present at the lower level before the arrival of the reentrant signals, the lower bound for the estimated time of reentry is given by the trough of the functions in Figs. 5, 6, and 7.
Those estimates, however, do not necessarily apply to all instances of reentry. This is because the timing of reentrant signals depends on the brain regions involved. For example, one entire reentry cycle between primary visual cortex and lateral geniculate nucleus (Sillito, Jones, Gerstein, & West, 1994), or between primary visual cortex and area V5/MT (Hupé et al., 1998; Pascual-Leone & Walsh, 2001) can range between 5 and 45 ms. Temporal lags between regions of prefrontal cortex and posterior visual areas have been reported in a similar range (Cohen, Heitz, Schall, & Woodman, 2009; Gregoriou, Gotts, & Desimone, 2012; Purcell, Schall, & Woodman, 2013). As we noted above, the present results suggest a time of reentry between 80 and 120 ms. Such timing is closer to that reported by Lamme and Roelfsema (2000) and by Fahrenfort, Scholte, and Lamme (2007) for reentrant loops between area V1 and extrastriate cortex involved in figure–ground segmentation. It is plausible that the latter longer estimates may reflect the linking of activity in different regions involved in visual processing (e.g., Canolty et al., 2006; Lakatos, Karmos, Mehta, Ulbert, & Schroeder, 2008). The present estimate, therefore, is likely to pertain to long-range—as distinct from local—reentrant signalling.
An important issue should be raised regarding theoretical accounts of OSM. The original account was predicated on an interaction between set size and mask duration (Di Lollo et al., 2000). Indeed, that interaction formed the core of the computational model (CMOS) proposed by Di Lollo et al. (2000). The validity of that interaction has recently been questioned by Argyropoulos, Gellatly, Pilling, and Carter (2012), who have provided convincing evidence that the interaction reported by Di Lollo et al. (2000) arose from a ceiling constraint imposed by the upper limit of the response scale. When that constraint was removed, the response functions turned out to be parallel, indicating that the magnitude of OSM is not a function of set size. Except for set size 1, at which performance was probably constrained by a ceiling, parallel functions are also in evidence in Figs. 5 and 6, especially in the results of observer M.H. in Fig. 5.
The absence of an interaction between mask duration (or ISI) and set size is clearly inconsistent with the CMOS model, which depends critically on the spatial distribution of attention, as manipulated by set size. The absence of this interaction is also inconsistent with Põder’s (2012) model, which predicts such an interaction. These findings, however, do not impugn reentry as the critical factor in OSM, whose magnitude is defined by the difference between the lowest and highest points in the response function.
Collectively, the extant results support the twin conclusions that (a) set size modulates the overall level of performance but not the magnitude of OSM and (b) OSM occurs when a mismatch is created between the reentrant signals and the ongoing activity at the lower level, regardless of the distribution of spatial attention. These conclusions hold, whether the main manipulation involves the exposure duration of the mask alone or the ISI between the initial display and a brief presentation of the mask alone.
Notes
Drew and Vogel (2008) have shown that a repeated mask is less effective than a novel mask. It is questionable, however, whether this finding can apply directly to the present work. First, Drew and Vogel’s paradigm differed from the present one in that it involved pattern masking, with complete overlap between the target and the mask, as distinct from the nonoverlapping stimuli used in the present work. Second, Drew and Vogel (Exp. 1) found that the effectiveness of the mask decreased monotonically as the SOA between the two presentations of the mask was increased. This monotonic relationship differs sharply from the nonmonotonic function obtained in the present work, suggesting that a reduction in mask effectiveness was not a major determinant of the present results.
References
Adelson, E. H., & Jonides, J. (1980). The psychology of iconic storage. Journal of Experimental Psychology. Human Perception and Performance, 6, 486–493. doi:10.1037/0096-1523.6.3.486
Argyropoulos, I., Gellatly, A., Pilling, M., & Carter, W. (2012). Set size and mask duration do not interact in object-substitution masking. Journal of Experimental Psychology: Human Perception and Performance. doi:10.1037/a0030240
Baker, H. D. (1963). Initial stages of light and dark adaptation. Journal of the Optical Society of America, 53, 98–103. doi:10.1364/JOSA.53.000098
Barlow, H. B., Fitzhugh, R., & Kuffler, S. W. (1957). Change of organization of the receptive fields of the cat’s retina during dark adaptation. The Journal of Physiology, 137, 338–354.
Bischof, W. F., & Di Lollo, V. (1995). Motion and metacontrast with simultaneous onset of stimuli. Journal of the Optical Society of America. A, 12, 1623–1636. doi:10.1364/JOSAA.12.001623
Breitmeyer, B. G. (1984). Visual masking: An integrative approach. New York: Oxford University Press.
Breitmeyer, B. G., & Ganz, L. (1976). Implications of sustained and transient channels for theories of visual pattern masking, saccadic suppression, and information processing. Psychological Review, 83, 1–36. doi:10.1037/0033-295X.83.1.1
Breitmeyer, B. G., & Öğmen, H. (2006). Visual masking: Time slices through conscious and unconscious vision (2nd ed.). New York: Oxford University Press.
Canolty, R. T., Edwards, E., Dalal, S. S., Soltani, M., Nagarajan, S. S., Kirsch, H. E., & Knight, R. T. (2006). High gamma power is phase-locked to theta oscillations in human neocortex. Science, 313, 1626–1628. doi:10.1126/science.1128115
Cohen, J. Y., Heitz, R. P., Schall, J. D., & Woodman, G. F. (2009). On the origin of event-related potentials indexing covert attentional selection during visual search. Journal of Neurophysiology, 102, 2375–2386. doi:10.1152/jn.00680.2009
Coltheart, M. (1980). Iconic memory and visible persistence. Perception & Psychophysics, 27, 183–228. doi:10.3758/BF03204258
Di Lollo, V., Enns, J. T., & Rensink, R. A. (2000). Competition for consciousness among visual events: The psychophysics of reentrant visual processes. Journal of Experimental Psychology. General, 129, 481–507. doi:10.1037/0096-3445.129.4.481
Di Lollo, V., von Mühlenen, A., Enns, J. T., & Bridgeman, B. (2004). Decoupling stimulus duration from brightness in metacontrast masking: Data and models. Journal of Experimental Psychology. Human Perception and Performance, 30, 733–745. doi:10.1037/0096-1523.30.4.733
Drew, T. W., & Vogel, E. K. (2008). Recently attended masks are less effective. Perception & Psychophysics, 70, 96–103.
Enns, J. T., & Di Lollo, V. (2000). What’s new in visual masking? Trends in Cognitive Sciences, 4, 345–352. doi:10.1016/S1364-6613(00)01520-5
Fahrenfort, J. J., Scholte, H. S., & Lamme, V. A. F. (2007). Masking disrupts reentrant processing in human visual cortex. Journal of Cognitive Neuroscience, 19, 1488–1497. doi:10.1162/jocn.2007.19.9.1488
Finley, G. (1985). A high-speed point plotter for vision research. Vision Research, 25, 1993–1997.
Gregoriou, G. G., Gotts, S. J., & Desimone, R. (2012). Cell-type-specific synchronization of neural activity in FEF with V4 during attention. Neuron, 73, 581–594. doi:10.1016/j.neuron.2011.12.019
Grossberg, S. (1995). The attentive brain. American Scientist, 83, 438–449.
Hupé, J.-M., James, A. C., Payne, B. R., Lomber, S. G., Girard, P., & Bullier, J. (1998). Cortical feedback improves discrimination between figure and ground by V1, V2 and V3 neurons. Nature, 394, 784–787. doi:10.1038/29537
Ikeda, M. (1965). Temporal summation of positive and negative flashes in the visual system. Journal of the Optical Society of America, 55, 1527–1534. doi:10.1364/JOSA.55.001527
Lagroix, H. E., Yanko, M. R., & Spalek, T. M. (2012). LCDs are better: Psychophysical and photometric estimates of the temporal characteristics of CRT and LCD monitors. Attention, Perception, & Psychophysics, 74, 1033–1041. doi:10.3758/s13414-012-0281-4
Lakatos, P., Karmos, G., Mehta, A. D., Ulbert, I., & Schroeder, C. E. (2008). Entrainment of neuronal oscillations as a mechanism of attentional selection. Science, 320, 110–113. doi:10.1126/science.1154735
Lamme, V. A. F., & Roelfsema, P. R. (2000). The distinct modes of vision offered by feedforward and recurrent processing. Trends in Neurosciences, 23, 571–579. doi:10.1016/S0166-2236(00)01657-X
Lleras, A., & Moore, C. M. (2003). When the target becomes the mask: Using apparent motion to isolate the object-level component of object substitution masking. Journal of Experimental Psychology. Human Perception and Performance, 29, 106–120. doi:10.1037/0096-1523.29.1.106
Moore, C. M., & Lleras, A. (2005). On the role of object representations in substitution masking. Journal of Experimental Psychology. Human Perception and Performance, 31, 1171–1180. doi:10.1037/0096-1523.31.6.1171
Mumford, D. (1991). On the computational architecture of the neocortex: I. The role of the thalamo-cortical loop. Biological Cybernetics, 65, 135–145.
Mumford, D. (1992). On the computational architecture of the neocortex: II. The role of cortico-cortical loops. Biological Cybernetics, 66, 241–251.
Neill, W. T., Hutchison, K. A., & Graves, D. F. (2002). Masking by object substitution: Dissociation of masking and cuing effects. Journal of Experimental Psychology. Human Perception and Performance, 28, 682–694. doi:10.1037/0096-1523.28.3.682
Pascual-Leone, A., & Walsh, V. (2001). Fast back projections from the motion to the primary visual area necessary for visual awareness. Science, 292, 510–512. doi:10.1126/science.1057099
Põder, E. (2012). Attentional gating models of object substitution masking. Journal of Experimental Psychology: General. doi:10.1037/a0030575
Purcell, B. A., Schall, J. D., & Woodman, G. F. (2013). On the origin of event-related potentials indexing covert attentional selection during visual search: Timing of attentional selection in macaque frontal eye field and posterior event-related potentials during pop-out search. Journal of Neurophysiology, 109, 557–569. doi:10.1152/jn.00549.2012
Scharf, B., & Lefton, L. A. (1970). Backward and forward masking as a function of stimulus and task parameters. Journal of Experimental Psychology, 84, 331–338.
Sillito, A. M., Jones, H. E., Gerstein, G. L., & West, D. C. (1994). Feature-linked synchronization of thalamic relay cell firing induced by feedback from the visual cortex. Nature, 369, 479–482. doi:10.1038/369479a0
Sperling, G., & Sondhi, M. M. (1968). Model for visual luminance discrimination and flicker detection. Journal of the Optical Society of America, 58, 1133–1145. doi:10.1364/JOSA.58.001133
von Békésy, G. (1968). Mach- and Hering-type lateral inhibition in vision. Vision Research, 8, 1483–1499. doi:10.1016/0042-6989(68)90123-5
Walraven, J., Enroth-Cugell, C., Hood, D. C., MacLeod, D. I., & Schnapf, J. L. (1990). The control of visual sensitivity: Receptoral and postreceptoral processes. In L. Spillman & J. S. Werner (Eds.), Visual perception: The neurophysiological foundations (pp. 53–101). New York: Academic Press.
Weisstein, N., Ozog, G., & Szoc, R. (1975). A comparison and elaboration of two models of metacontrast. Psychological Review, 82, 325–343. doi:10.1037/0033-295X.82.5.325
Werner, H. (1935). Studies on contour: I. Qualitative analysis. The American Journal of Psychology, 47, 40–64.
Woodman, G. F., & Luck, S. J. (2003). Dissociations among attention, perception, and awareness during object-substitution masking. Psychological Science, 14, 605–611. doi:10.1046/j.0956-7976.2003.psci_1472.x
Author note
This work was supported by an Alexander Graham Bell Canada Graduate Scholarship from the Natural Sciences and Engineering Research Council of Canada (NSERC) and a Pacific Century Graduate Scholarship from the British Columbia Ministry of Advanced Education, Innovation, and Technology to A.J.; by a Canadian Foundation for Innovation New Opportunities Grant and a grant from the British Columbia Knowledge Development Fund to T.M.S.; and by Discovery Grants from NSERC to T.M.S. and V.D.L.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article
Cite this article
Jannati, A., Spalek, T.M. & Di Lollo, V. A novel paradigm reveals the role of reentrant visual processes in object substitution masking. Atten Percept Psychophys 75, 1118–1127 (2013). https://doi.org/10.3758/s13414-013-0462-9
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13414-013-0462-9