
Abstract
This paper is concerned with the problem of a passivity analysis for a class of memristor-based neural networks with multiple proportional delays and the state estimator is designed for the memristive system through the available output measurements. By constructing a proper Lyapunov-Krasovskii functional, new criteria are obtained for the passivity and state estimation of the memristive neural networks. Finally, a numerical example is given to illustrate the feasibility of the theoretical results.
Similar content being viewed by others


1 Introduction
In 1971, the memristor was proposed by Chua [1] as the fourth passive circuit element. Compared with the three conventional fundamental circuit elements (resistor, inductor, and capacitor), the memristor is a nonlinear time-varying element. The first practical memristor device was found by Strukov et al. [2] in 2008. The memristor presents the relationship between the charge (q) and flux (φ), i.e., \(\mathrm{d}\varphi=M\, \mathrm{d}q\). The memristor retains its most recent value when the voltage is turned off, so it re-expresses the retained value when it is turned on. This feature makes them useful as energy-saving devices that can compete with flash memory and other static memory devices. Some classes of memristors also have nonlinear response characteristics which makes them doubly suitable as artificial neurons.
Existing results show that the electronic synapses and neurons can represent important functionalities of their biological counterparts [3]. Recently, the simulation of different kinds of memristors has developed rapidly and the studies of memristive neural networks have aroused more attention [3–15]. In [16], Wang et al. considered the following memristive neurodynamic system:
where \(x_{i}(t)\) is the voltage of the capacitor \(\mathbb{C}_{i}\) at time t, \(\mathbb{R}_{ij}\) denotes the resistor through the feedback function \(g_{i}(x_{i}(t))\) and \(x_{i}(t)\), \(\mathcal{R}_{i}\) represents the parallel-resistor corresponding the capacitor \(\mathbb{C}_{i}\), and
Based on two kinds of memductance functions, finite-time stability criteria were obtained for memristive neural networks with stochastic perturbations. The analysis employed differential inclusions theory, finite-time stability theorem, linear matrix inequalities, and the Lyapunov functional method.
In practice, due to the finite speed of information processing and the inherent communication time of neurons, time delays are frequently encountered in many biological and artificial neural networks. As correctly pointed out in [17–20], time delays may cause undesirable dynamical network behaviors such as oscillations, divergences, and so on. Consequently, it is valuable to investigate the problems of dynamics analysis for neural networks with time delay. By using different approaches, many significant results have been reported such as the global robust passivity analysis in [17] and the passivity analysis in [18–23]. In order to investigate the effect of time delay upon the dynamics of the memristive neural networks, Wu and Zeng [10] considered the following system:
where \(\tau_{j}\) is the time delay that satisfies \(0\leq\tau_{j}\leq \tau\) (\(\tau\geq0\) is a constant). \(u_{i}(t)\) and \(z_{i}(t)\) denote external input and output, respectively, \(f_{j}(\cdot)\) is the neuron activation function satisfying \(f_{j}(0)=0\), \(a_{ij}(x_{i}(t))\) and \(b_{ij}(x_{i}(t))\) represent memristor-based weights. Based on the theories of nonsmooth analysis and linear matrix inequalities, by using a suitable Lyapunov functional, the exponential passivity was studied for the memristive neural networks with time delays.
Proportional delay is a time-varying delay with time proportionality, which is usually required in web quality of service routing decisions. Different from the constant time delay, bounded time-varying delay, and distributed delay, the proportional delay is unbounded and time-varying. Recently, routing algorithms were obtained in [24, 25] based on neural networks. These routing algorithms were proven to be able to get the exact solutions for the problems which have a high parallelism. As well known, there exists a spatial extent in neural networks as the presence of parallel pathways of different axonal sizes and lengths. Accordingly, it is reasonable to use continuously proportional delays to describe the topology structure and parameters of neural networks. The proportional delayed systems have aroused many scholars’ attention [7, 26, 27]. In [7], Wang et al. investigated the following memristive neural networks with multiple proportional delays:
where
\(x_{i}(t)\) is the voltage of the capacitor \(\mathbf{C}_{i}\) at time t, \(\mathbb{M}_{ij}\) and \(\mathbb{W}_{ij}\) denote the memductances of memristor \(R_{ij}\) and \(\hat{R}_{ij}\), respectively. \(R_{ij}\) represents the memristor between the neuron activation function \(f_{j}(x_{j}(t))\) and \(x_{i}(t)\). \(\hat{R}_{ij}\) represents the memristor between the neuron activation functions \(f_{j}(x_{j}(q_{j}t))\) and \(x_{i}(t)\). \(q_{j}t\) is a proportional delay factor satisfying \(q_{j}t=t-(1-q_{j})t\), in which \((1-q_{j})t\) corresponds to the time delay required in processing and transmitting a signal from the jth neuron to the ith neuron. By using the differential inclusion theory to handle the memristive neural networks with discontinuous right-hand side, several criteria ensuring anti-synchronization of memristive neural networks with multiple proportional delays were presented.
As well known, memristor-based neural networks are state-dependent switched nonlinear systems. The passivity theory, originating from circuit theory, is the most important issue in the analysis and design of switched systems. In the passivity theory, the passivity means that systems can keep internally stable. Therefore, the passivity theory provides a tool to analyze the stability of control systems and it has been applied in many areas. Based on the passivity theory, the authors in [28] dealt with the problems of sliding mode control for uncertain singular time-delay systems. In [29], the authors designed a mode-dependent state feedback controller by applying the passivity theory. The design of a passive controller based on the passivity analysis of nonlinear systems has become an effective way to solve practical engineering problems, for example, passivity-based control of three-phase AC/DC voltage-source converters. For details, the reader is referred to [30, 31] and the references therein. As state-dependent switched nonlinear systems, memristive neural networks include too many subsystems. The product of input and output is utilized as the energy provision of the passive systems, which embodies the energy attenuation character. Passivity analysis of memristive neural networks provides a way to understand the complex brain functionalities with the adoption of memristor-MOS technology designs [32]. In recent years, although some research results have been concerned with the passivity problem for memristive neural networks, little attention has been paid to the problem of state estimation for memristor-based neural networks with multiple proportional delays based on passivity theory. Due to the importance of proportional delays in web quality of service routing decisions, we carry out this work to shorten the gap.
Motivated by the works in [10, 32, 33] and the circuit design in [16, 34–36], a class of memristive neural networks with multiple proportional delays is considered. By constructing a proper Lyapunov-Krasovskii functional, passivity criteria are obtained for the given delayed system, and then the state estimator is designed for the memristive system through available output measurements based on passivity theory.
The rest of this paper is organized as follows. In Section 2, the corresponding delayed neurodynamic equation for the presented memristive circuit is established and preliminaries are given. The theoretic results are derived in Section 3. In Section 4, the validity of the theoretical analysis is discussed through a numerical example.
2 Model description and preliminaries
In this paper, we consider the following memristor-based neural networks with multiple proportional delays which is unbounded:
or equivalently
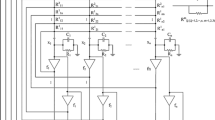
System (2.1) can be implemented by the large-scale integration circuits as shown in Figure 1, and system (2.1) can be obtained using Kirchhoff’s current law. \(x(t)=[x_{1}(t),x_{2}(t), \ldots, x_{n}(t)]^{T}\in\mathbb{R}^{n}\) is the voltage of the capacitor \(\mathbf{C}_{i}\) at time t, \(\rho(t)=[\rho_{1}(t),\rho_{2}(t),\ldots, \rho_{n}(t)]^{T}\) represents the proportionality delay factor and \(0< q_{j}\leq1\), \(\rho_{j}(t)=t-(1-q_{j})t\), where \((1-q_{j})t\) is the time delay required in processing and transmitting a signal between neurons and \((1-q_{j})t\) is a time-varying continuous function satisfying \((1-q_{j})t\rightarrow+\infty\) as \(q_{j}\neq1\), \(t\rightarrow+\infty\). \(f_{j} (x_{j}(t) )\) and \(f_{j} (x_{j}(\rho_{j}(t)) )\) are the nonlinear neuron activation functions of the jth neuron at time t and \(q_{j}t\), respectively. \(I(t)=[I_{1}(t),I_{2}(t),\ldots ,I_{n}(t)]^{T}\) is the input vector at time t, \(y(t)=[y_{1}(t),y_{2}(t),\ldots, y_{n}(t)]^{T}\in\mathbb{R}^{n}\) denotes the output vector of the networks. \(D=\operatorname{diag}(d_{1}, d_{2},\ldots, d_{n})\) describes the rate with which each neuron will reset its potential to the resting state in isolation when disconnected from the networks and external inputs. \(A (x(t) )= (a_{ij} (x_{i}(t) ) )_{n\times n}\) and \(B (x(t) )= (a_{ij} (x_{i}(t) ) )_{n\times n}\) represent the memristor-based connection weight matrices, and
in which \(\mathbf{W}_{ij}\) and \(\mathbf{M}_{ij}\) denote the memductances of memristors \(\mathbf{R}_{ij}\) and \(\mathbf{F}_{ij}\). Here \(\mathbf{R}_{ij}\) represents the memristor across \(x_{j}(t)\) and the feedback function \(f_{j}(x_{j}(t))\), and \(\mathbf{F}_{ij}\) represents the memristor across \(x_{j}(t)\) and the feedback function \(f_{j} (x_{j}(\rho_{j}(t)) )\). According to the feature of the memristor and the current voltage characteristic, we have
for \(i,j=1,2,\ldots,n\), where \(\hat{a}_{ij}\), \(\check{a}_{ij}\), \(\hat {b}_{ij}\) and \(\check{b}_{ij}\) are constants. Obviously, the memristive neural network model (2.1) is a state-dependent switched nonlinear system.

The circuit of memristive neural networks ( 2.1 ). \(x_{i}(t)\) is the state of the ith subsystem, \(\mathbf{R}_{ij}\) and \(\mathbf{F}_{ij}\) represent the memristors, \(f_{j}\) is the amplifier, \(\mathbf{R}_{i}\) and \(\mathbf{C}_{i}\) are the resistor and capacitor, \(I_{i}\) is the external input, and \(i,j=0,1,\ldots, n\).
System (2.1) is established based on the following assumption:
-
(A1):
The neural activation function \(f_{i}(\cdot)\) satisfies Lipschitz condition with a Lipschitz constant \(k_{i}\), i.e.,
$$\bigl\vert f_{i}(u)-f_{i}(v)\bigr\vert \leq k_{i}\vert u-v\vert , \quad i=1,2,\ldots,n, \forall u,v\in R \text{ and } u\neq v, $$where u and v are known constant scalars and \(f_{i}(0)=0\).
Denote \(D=\operatorname{diag} (d_{1}, d_{2}, \ldots, d_{n} )\). \(I_{n}\) is an \(n\times n\) identity matrix. For the symmetric matrix T, \(\mathbf{T}>0\) (\(\mathbf{T}<0\)) means that T is a positive definite (negative definite) matrix, and \(\mathbf{T}\geq0\) (\(\mathbf {T}\leq0\)) means that T is a semi-positive definite (semi-negative definite) matrix. For matrices \(\mathbf {Q}=(q_{ij})_{n\times n}\) and \(\mathbf{H}=(h_{ij})_{n\times n}\), \(\mathbf {Q}\gg \mathbf{H}\) (\(\mathbf{Q}\ll \mathbf{H}\)) means that \(q_{ij}\geq h_{ij}\) (\(q_{ij}\leq h_{ij}\)), for \(i,j=1,2,\ldots,n\). And by the interval matrix \([\mathbf {Q},\mathbf{H}]\), it follows that \(\mathbf{Q}\ll \mathbf{H}\). For any matrix \(\mathbf{L}=(l_{ij})_{n\times n}\in[\mathbf{Q},\mathbf{H}]\), it means \(\mathbf{Q}\ll\mathbf{L}\ll\mathbf{H}\), i.e., \(q_{ij}\leq l_{ij}\leq h_{ij}\) for \(i,j=1,2,\ldots,n\). The symmetric terms in a symmetric matrix are denoted by ‘∗’.
Definition 1
[37]
Let \(G\subseteq\mathbb{R}^{n}\), \(x\mapsto H(x)\) is called a set-valued map from \(G\hookrightarrow\mathbb {R}^{n}\), if, to each point x of a set \(G\subseteq\mathbb{R}^{n}\), there corresponds a nonempty set \(H(x)\subseteq\mathbb{R}^{n}\).
Definition 2
[37]
A set-valued map H with nonempty values is said to be upper semi-continuous at \(x_{0}\in G\subseteq\mathbb{R}^{n}\), if for any open set M containing \(H(x_{0})\), there exists a neighborhood N of \(x_{0}\) such that \(H(N)\subseteq M\). \(H(x)\) is said to have a closed (convex, compact) image if, for each \(x\in G\), \(H(x)\) is closed (convex, compact).
Definition 3
[38]
For the differential system \(\dot{x}=h(t,x)\), where \(h(t,x)\) is discontinuous in x, the set-valued map of \(h(t,x)\) is defined as
where \(B(x,\epsilon)=\{y:\|y-x\|\leq\epsilon\}\) is the ball of center x and radius ϵ; the intersection is taken over all sets M of measure zero and over all \(\epsilon>0\); and \(\mu(M)\) is the Lebesgue measure of the set M.
A Filippov solution of system \(\dot{x}=h(t,x)\), with initial condition \(x(0)=x_{0}\) is absolutely continuous on any subinterval \(t\in[t_{1},t_{2}]\) of \([0,T]\), which satisfies \(x(0)=x_{0}\), and the differential inclusion:
Definition 4
A constant vector \(x^{\ast}=(x^{\ast}_{1}, x^{\ast }_{2}, \ldots, x^{\ast}_{n})\) is said to be an equilibrium point of system (2.1), if for \(i=1, 2, \ldots, n\),
where \(K(\mathcal{P})\) denotes the closure of the convex hull of the set \(\mathcal{P}\).
Lemma 1
[39]
System (2.1) has at least one equilibrium point.
Proof
Consider the following set-valued map:
From Definitions 1-3, we can see that the set-valued map \(x_{i}\multimap H_{i}(t,x_{i})\) is upper semi-continuous with nonempty compact convex values, and
is bounded since \(f_{j}(\cdot)\) is bounded. According to Kakutani’s fixed point theorem, there exists at least one fixed point of \(H(t, x)\), which is also an equilibrium point of system (2.1).
Considering the following nonlinear transformation:
we can prove that system (2.1) is equivalent to the following neural networks with multiple constant delays and time-varying coefficients:
in which \(\tau_{j}=-\log q_{j}\geq0\), \(u_{i}(t)=I_{i}(e^{t})\).
The initial conditions of system (2.6) are assumed to be
where \(\phi_{i}(t)=(\phi_{1}(t),\phi_{2}(t),\ldots,\phi_{n}(t))\in \mathcal{C}([-\tau,0],\mathbb{R}^{n})\), \(\mathbb{R}^{n}\) is n-dimensional Euclidean space. \(\mathcal{C}([-\rho,0],\mathbb {R}^{n})\) is a Banach space of all continuous functions with the Euclidean norm.
It is easy to see that the weight \(a_{ij}(x_{i}(t))\) switches between two different constant values \(\hat{a}_{ij}\) and \(\check{a}_{ij}\), and \(b_{ij}(x_{i}(t))\) switches between \(\hat{b}_{ij}\) and \(\check{b}_{ij}\). Consequently, the combination number of the possible form of the connection weight matrices \(A(x(t))\) and \(B(x(t))\) is \(2^{2n^{2}}\). So, we can order these \(2^{2n^{2}}\) cases in the following way:
Then, at any fixed time \(t\geq0\), the form of \(A(x(t))\) and \(B(x(t))\) must be one of the \(2^{2n^{2}}\) cases. For \(l\in\{1, 2, \ldots, 2^{2n^{2}}\}\), at any fixed time t, we define the characteristic function of \(A_{l}\) and \(B_{l}\) as follows:
We can easily obtain \(\sum_{l=1}^{2^{2n^{2}}}\pi_{l}(t)=1\). Thus, the memristive neural network model (2.2) can be rewritten as
According to (2.2) and (2.8), we can obtain
□
Definition 5
[40]
The system (2.6) is said to be passive if there exists a scalar \(\gamma\geq0\) such that, for all \(t_{p}\geq0\) and all solutions of system (2.6) with \(z(0)=0\), the formula
holds, where \(y(t)=(y_{1}(t),y_{2}(t),\ldots ,y_{n}(t))^{T}\), \(u(t)=(u_{1}(t),u_{2}(t),\ldots,u_{n}(t))^{T}\).
The product of input and output is regarded as the energy provision for the passivity of the systems in Definition 5, which embodies the energy attenuation character of system. By the control theories, we know that the passive properties of systems can keep the systems internally stable. Passive systems only burn energy while there is no energy production. Accordingly, by nature, passivity embodies a characteristic of the energy consumption of system. We know that the power flow is usually made to meet the energy conservation and the passive systems do not produce energy [32], i.e.,
3 Main results
In this section, we present our passivity analysis results of system (2.1) and develop a passivity-based approach dealing with the state estimation problem for system (2.1).
Denote by I an n-dimensional identity matrix. For convenience, we use the following notations:
where
3.1 Passivity analysis
Theorem 3.1
Suppose the assumption (A1) holds and
where \(\Pi= A_{l}+A^{T}_{l}+\Lambda-\Lambda\Gamma-\Gamma^{T}\Lambda^{T}\), system (2.1) is passive in the sense of Definition 5.
Proof
Define a Lyapunov-Krasovskii functional \(V(z(t))\):
Calculating the derivative of \(V(z(t))\) along the positive half trajectory of system (2.6), we obtain
where
in which \(\widetilde{\Pi}= A(z(t))+A^{T}(z(t))+\Lambda-\Lambda\Gamma-\Gamma^{T}\Lambda^{T}\).
According to (2.9), we obtain
It follows from (3.3) and (3.4) that
Integrating (3.5) with respect to t over the time period from 0 to \(t_{p}\), we have
for \(z(0)=0\). Since \(V(0,z(0))=0\) and \(V(t_{p},z(t_{p}))\geq0\), we get
Therefore, the memristive neural network (2.1) is passive in the sense of Definition 5. This completes the proof. □
Remark 1
In Theorem 3.1, Lyapunov stability theory is employed to investigate the passivity of system (2.1). Actually, we can find that passivity is a higher abstraction level of stability in the process of the proof, and the corresponding Lyapunov function (3.2) can be regarded as the storage function.
When the input is \(I(t)=(I_{1}(t),I_{2}(t),\ldots,I_{n}(t))^{T}=(0,0,\ldots ,0)^{T}\), by using standard arguments as Theorem 3.1, we can derive the stability conditions for system (2.1).
Corollary 3.1
Suppose the assumption (A1) holds and
where \(\Pi=A_{l}+A^{T}_{l}+\Lambda-\Lambda\Gamma-\Gamma^{T}\Lambda ^{T}\), system (2.1) is globally asymptotically stable while the input \(I(t)=(I_{1}(t),I_{2}(t),\ldots,I_{n}(t))^{T}=(0,0,\ldots,0)^{T}\).
3.2 State estimation based on passivity
In the following, we design a state estimator for neural networks (2.1) based on passivity theory as follows:
where \(\overline{x}_{i}(t)\) is the estimation of the ith neuron state, \(\overline{y}_{i}(t)\) is the output vector of the ith state estimator, \(J_{i}(t)\) is the control input vector, \(m_{i}\) is the estimation gain weight, and \(m_{i}\) is a known constant.
Define the estimation error \(r(t)=x(t)-\overline{x}(t)\) and the output error \(\tilde{y}=y(t)-\overline{y}(t)\). Then the error state system can be expressed by
where \(\overline{a}_{ij} (r_{i}(t) )=a_{ij} (x_{i}(t) )-a_{ij} (\overline{x}_{i}(t) )\), \(\overline{b}_{ij} (r_{i}(t) )=b_{ij} (x_{i}(t) )-b_{ij} (\overline{x}_{i}(t) )\), \(\overline{f}_{i} (r_{i}(t) )=f_{i} (x_{i}(t) )-f_{i} (\overline{x}_{i}(t) )\), \(\overline{f}_{i} (r_{i}(\rho_{j}(t)) )=f_{i} (x_{i}(\rho_{j}(t)) )-f_{i} (\overline{x}_{i}(\rho_{j}(t)) )\).
Define
then system (3.8) is equivalent to the following neural networks with multiple constant delays:
in which \(\tau_{j}=-\log q_{j}\geq0\), \(u_{i}(t)=J_{i}(e^{t})\).
The initial conditions of system (3.10) are assumed to be
where \(\varphi_{i}(t)=(\varphi_{1}(t),\varphi_{2}(t),\ldots,\varphi _{n}(t))\in\mathcal{C}([-\tau,0],\mathbb{R}^{n})\), \(\mathbb{R}^{n}\) is n-dimensional Euclidean space. \(\mathcal{C}([-\rho,0],\mathbb {R}^{n})\) is Banach space of all continuous functions with the Euclidean norm.
Theorem 3.2
Suppose the assumption (A1) holds. If there exists \(M=\operatorname{diag}(m_{1},m_{2},\ldots, m_{n})\) such that
where \(\Pi=A_{l}+A^{T}_{l}+\Lambda-\Lambda\Gamma-\Gamma^{T}\Lambda ^{T}-\Lambda M-M^{T}\Lambda^{T}\), the estimation error system (3.8) is passive and M is the gain matrix of the state estimator (3.7).
Proof
Define a Lyapunov-Krasovskii functional \(V(x(t))\):
Calculating the derivative of \(V(w(t))\) along the positive half trajectory of system (3.10), we obtain
where
in which \(\widetilde{\Pi}= A(w(t))+A^{T}(w(t))+\Lambda-\Lambda\Gamma-\Gamma^{T}\Lambda ^{T}-\Lambda M-M^{T}\Lambda^{T}\).
According to (2.9), we obtain
It follows from (3.13) and (3.14) that
Integrating (3.15) with respect to t over the time period from 0 to \(t_{p}\), we have
for \(w(0)=0\). Since \(V(0,w(0))=0\) and \(V(t_{p},w(t_{p}))\geq0\), we get
Therefore, the estimation error system (3.8) is passive in the sense of Definition 5. This completes the proof. □
When the control input \(J(t)=(J_{1}(t),J_{2}(t),\ldots ,J_{n}(t))^{T}=(0,0,\ldots,0)^{T}\), by using standard arguments as Theorem 3.2, we can derive the stability conditions for system (3.8).
Corollary 3.2
Suppose the assumption (A1) holds. If there exists \(M=\operatorname{diag}(m_{1},m_{2},\ldots,m_{n})\) such that
where \(\widetilde{\Pi}= A_{l}+A^{T}_{l}+\Lambda-\Lambda\Gamma-\Gamma^{T}\Lambda^{T} -\Lambda M-M^{T}\Lambda^{T}\), the estimation error system (3.8) is globally asymptotically stable, while the control input is \(J(t)=(J_{1}(t),J_{2}(t),\ldots ,J_{n}(t))^{T}=(0,0,\ldots,0)^{T}\) and M is the gain matrix of the state estimator (3.7).
4 Numerical simulation
In this section, we give an example to illustrate the feasibility of the theoretical results.
Example 4.1
Consider the two-neuron memristive uncertain neural network model
where \(f_{1}(x)=f_{2}(x)= \frac{1}{2} (|x+1|-|x-1| )\), \(\rho _{1}(t)=t-(1-q_{1})t\), \(\rho_{2}(t)=t-(1-q_{2})t\), \(q_{1}=0.6\), \(q_{2}=0.5\), and
In system (4.1), we derive that
is negative definite.
By applying Theorem 3.1, the passivity of system (4.1) can be achieved with the input \(I_{1}(t)=1+\sin t\), \(I_{2}(t)=2+\sin t\). Meanwhile, according to the Corollary 3.1, system (4.1) is globally asymptotically stable with the input \(I_{1}(t)=I_{2}(t)=0\). The simulations of the state curves for system (4.1) with and without the input are depicted in Figure 2 and Figure 3, respectively. Obviously, system (4.1) is a state-dependent switched system. By Figure 2, we see that system (4.1) with input \(I(t)=(1+\sin(t), 2+\sin(t))^{T}\) can keep internally stable. By adopting the product of input and output as the energy provision, it embodies energy attenuation character. That is, the passive system (4.1) will not produce energy by itself. From Figure 3, it follows that system (4.1) with input \(I(t)=(0,0)^{T}\) is globally stable. One might see that passivity is at a higher abstraction level of stability by contrast.

The state curves of system ( 4.1 ) with input \(\pmb{I(t)= (1+\sin(t),2+\sin(t) )^{T}}\) and different initial values.

The state curves of system ( 4.1 ) with different initial values and the input \(\pmb{I(t)= (0,0 )^{T}}\) .
We develop a state estimator for neural networks (4.1) as follows:
where \(J_{1}(t)=1+\sin(t)\), \(J_{2}(t)=2+\sin(t)\) and the other parameters are the same as system (4.1). Then the error state system can be expressed by
In system (4.5), we derived
which is negative definite.
By applying Theorem 3.2, the passivity of system (4.6) can be achieved with the control input \(J_{1}(t)=1+\sin t\), \(J_{2}(t)=2+\sin t\) (see Figure 4). Meanwhile, according to the Corollary 3.2, the system (4.6) is globally asymptotically stable with the control input \(J_{1}(t)=J_{2}(t)=0\). The responses of the error dynamics (4.5), which converges to zero with the estimation gain matrix \(K=I\) can be seen in Figure 5 when the control input \(J(t)=0\), i.e., the effectiveness of the state estimator for neural networks (4.1) is demonstrated.

The state curves of error system ( 4.5 ) with control input \(\pmb{J(t)= (1+\sin(t),2+\sin(t) )^{T}}\) and different initial values.

It must be pointed out that, in system (4.1), if we let
and the other parameters are the same as above, we obtain
We see that Θ is not negative definite, i.e., the conditions in Theorem 3.1 and Corollary 3.1 are not satisfied. From Figure 6 and Figure 7, we can see that system (4.1) is still passive and stable for the input \(I(t)= (1+\sin(t),2+\sin(t) )^{T}\) and \(I(t)= (0,0 )^{T}\), respectively. That is to say, conditions in Theorem 3.1 and Corollary 3.1 are sufficient but not necessary.


5 Concluding remarks
In this paper, we considered a class of memristor-based neural networks with unbounded multiple proportional delays for the designed circuits. By combining differential inclusions with set-valued maps, we obtained the existence of the solutions for the given delayed system. Based on the Lyapunov-Krasovskii functional method, passivity criteria were given and the state estimator was designed for the memristive system through available output measurements based on passivity theory. In system (2.1), we assumed that the decay process of neurons is instantaneous, while, in fact, time is required to isolate the static state. Time delay in the leakage term is introduced to describe the phenomenon which has a great negative impact on the stability of neural networks. On the other hand, distributed delays have caused attention to describe the existence of distribution of conduction velocities along parallel pathways or distribution of propagation delays over a period of time. Accordingly, time delay in the leakage term and distributed delays should be taken into consideration. In the near future, we will analyze memristor-based neural networks with leakage delay and distributed delays, which may reveal more electric properties of the memristor.
References
Chua, LO: Memristor - the missing circuit element. IEEE Trans. Circuit Theory 18(5), 507-519 (1971)
Strukov, DB, Snider, GS, Stewart, DR, Williams, RS: The missing memristor found. Nature 453, 80-83 (2008)
Pershin, YV, Ventra, MD: Experimental demonstration of associative memory with memristive neural networks. Neural Netw. 23(7), 881-886 (2010)
Li, RX, Cao, JD: Stability analysis of reaction-diffusion uncertain memristive neural networks with time-varying delays and leakage term. Appl. Math. Comput. 278, 54-69 (2016)
Wang, FZ, Helian, N, Wu, S, Yang, X, Guo, Y, Lim, G, Rashid, MM: Delayed switching applied to memristor neural networks. J. Appl. Phys. 111(7), 07E317/1-07E317/3 (2012)
Wang, L, Li, H, Duan, S, Huang, T, Wang, H: Pavlov associative memory in a memristive neural network and its circuit implementation. Neurocomputing 171, 23-29 (2016)
Wang, W, Li, L, Peng, H, Kurths, J, Xiao, J, Yang, Y: Anti-synchronization control of memristive neural networks with multiple proportional delays. Neural Process. Lett. 43, 269-283 (2016)
Wang, W, Li, L, Peng, H, Xiao, J, Yang, Y: Synchronization control of memristor-based recurrent neural networks with perturbations. Neural Netw. 53, 8-14 (2014)
Wu, AL, Zeng, ZG: Exponential stabilization of memristive neural networks with time delays. IEEE Trans. Neural Netw. Learn. Syst. 23(12), 1919-1929 (2012)
Wu, AL, Zeng, ZG: Exponential passivity of memristive neural networks with time delays. Neural Netw. 49, 11-18 (2014)
Wu, AL, Zeng, ZG, Fu, CJ: Dynamic analysis of memristive neural system with unbounded time-varying delays. J. Franklin Inst. 351, 3032-3041 (2014)
Yang, S, Li, C, Huang, T: Exponential stabilization and synchronization for fuzzy model of memristive neural networks by periodically intermittent control. Neural Netw. 75, 162-172 (2016)
Zhang, GD, Shen, Y, Wang, LM: Global anti-synchronization of a class of chaotic memristive neural networks with time-varying delays. Neural Netw. 46, 1-8 (2013)
Zhang, ZX, Mou, SS, Lam, J, Gao, HJ: New passivity criteria for neural networks with time-varying delay. Neural Netw. 22(7), 864-868 (2009)
Zhu, S, Shen, Y, Chen, GC: Exponential passivity of neural networks with time-varying delay and uncertainty. Phys. Lett. A 375(2), 136-142 (2010)
Wang, W, Li, L, Peng, H, Kurths, J, Xiao, J, Yang, Y: Finite-time anti-synchronization control of memristive neural networks with stochastic perturbations. Neural Process. Lett. 43, 49-63 (2016)
Balasubramaniam, P, Nagamani, G: Global robust passivity analysis for stochastic fuzzy interval neural networks with time-varying delays. Expert Syst. Appl. 39(1), 732-742 (2012)
Li, HY, Lam, J, Cheung, KC: Passivity criteria for continuous-time neural networks with mixed time-varying delays. Appl. Math. Comput. 218, 11062-11074 (2012)
Zhu, S, Shen, Y: Passivity analysis of stochastic delayed neural networks with Markovian switching. Neurocomputing 74(10), 1754-1761 (2011)
Zhu, J, Zhang, QL, Yuan, ZH: Delay-dependent passivity criterion for discrete-time delayed standard neural network model. Neurocomputing 73(7-9), 1384-1393 (2010)
Balasubramaniam, P, Nagamani, G: Passivity analysis of neural networks with Markovian jumping parameters and interval time-varying delays. Nonlinear Anal. Hybrid Syst. 4(4), 853-864 (2010)
Balasubramaniam, P, Nagamani, G: Passivity analysis for uncertain stochastic neural networks with discrete interval and distributed time-varying delays. J. Syst. Eng. Electron. 21(4), 688-697 (2010)
Balasubramaniam, P, Nagamani, G: A delay decomposition approach to delay-dependent passivity analysis for interval neural networks with time-varying delay. Neurocomputing 74(10), 1646-1653 (2011)
Liu, J, Yuan, DF, Ci, S, Zhong, YJ: A new QoS routing optimal algorithm in mobile ad hoc network based on Hopfield neural network. Adv. Neural Netw. 3498, 343-348 (2005)
Gargi, R, Chaba, Y, Patel, RB: Improving the performance of dynamic source routing protocal by optimization of neural networks. Int. J. Comput. Sci. Issues 9(4), 471-479 (2012)
Zhou, LQ: Delay-dependent exponential synchronization of recurrent neural networks with multiple proportional delays. Neural Process. Lett. 42, 619-632 (2015)
Zhou, LQ, Zhang, YY: Global exponential stability of a class of impulsive recurrent neural networks with proportional delays via fixed point theory. J. Franklin Inst. 353, 561-575 (2016)
Wu, L, Zheng, WX: Passivity-based sliding mode control of uncertain singular time-delay systems. Automatica 45(9), 2120-2127 (2009)
Ma, C, Zeng, Q, Zhang, L, Zhu, Y: Passivity and passification for Markov jump genetic regulatory networks with time-varying delays. Neurocomputing 136, 321-326 (2014)
Lee, T: Lagrangian modeling and passivity-based control of three-phase AC/DC voltage-source converters. IEEE Trans. Ind. Electron. 51(4), 892-902 (2004)
Wang, JH: Passivity-Based Control Theory and Its Applications. Publishing House of Electronics Industry, Beijing (2010)
Wu, AL, Zeng, ZG: Passivity analysis of memristive neural networks with different memductance functions. Commun. Nonlinear Sci. Numer. Simul. 19, 274-285 (2014)
Hua, CC, Yang, X, Yan, J, Guan, XP: New stability criteria for neural networks with time-varying delays. Appl. Math. Comput. 218, 5035-5042 (2012)
Wen, S, Huang, T, Zeng, Z, Chen, Y, Li, P: Circuit design and exponential stabilization of memristive neural networks. Neural Netw. 63, 48-56 (2014)
Wen, S, Bao, G, Zeng, Z, Chen, Y, Huang, T: Global exponential synchronization of memristor-based recurrent neural networks with time-varying delays. Neural Netw. 48, 195-203 (2013)
Wen, S, Zeng, Z, Huang, T, Yu, X: Noise cancellation of memristive neural networks. Neural Netw. 60, 74-83 (2014)
Aubin, J, Frankowska, H: Set-Valued Analysis. Birkhäuser, Boston (2009)
Filippov, A: Differential Equations with Discontinuous Right Hand Sides. Kluwer Academic, Boston (1988)
Wu, AL, Zeng, ZG: An improved criterion for stability and attractability of memristive neural networks with time-varying delays. Neurocomputing 145, 316-323 (2014)
Li, C, Liao, X: Passivity analysis of neural networks with time delay. IEEE Trans. Circuits Syst. II, Express Briefs 52(8), 471-475 (2005)
Acknowledgements
The authors would like to thank all the anonymous reviewers and the editors for their helpful advice and hard work. This work was supported by NNSF of China (11371368, 11071254) and HEBNSF of China (A2014506015).
Author information
Authors and Affiliations
Corresponding author
Additional information
Competing interests
The authors declare that they have no competing interests.
Authors’ contributions
JL carried out the theoretical calculation and numerical simulation, and drafted the manuscript. RX participated in the theoretical calculation and helped to draft the manuscript. All authors read and approved the final manuscript.
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Liu, J., Xu, R. Passivity analysis and state estimation for a class of memristor-based neural networks with multiple proportional delays. Adv Differ Equ 2017, 34 (2017). https://doi.org/10.1186/s13662-016-1069-y
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s13662-016-1069-y