
Abstract
There is a wide demand for people counting and pedestrian flow monitoring in large public places such as scenic tourist areas, shopping malls, stations, squares, and so on. Based on the feedback from the pedestrian flow monitoring system, resources can be optimally allocated to maximize social and economic benefits. Moreover, trampling accidents can be avoided because pedestrian guidance is carried out in time. In order to meet these requirements, we propose a method of pedestrian flow monitoring based on the received signal strength (RSS) of wireless sensor networks. This method mainly utilizes the shadow attenuation effect of pedestrians on radio frequency (RF) signals of effective links. In this paper, a deployment structure of RF wireless sensor network is firstly designed to monitor the pedestrians. Secondly, the features are extracted from the wavelet decomposition of RSS signal series with a short time. Lastly, the support vector machine (SVM) algorithm is trained by an experimental data set to distinguish the instantaneous number of pedestrian passing through the monitoring point. In the case of dense and sparse indoor personnel density, the accuracy of the SVM model is 88.9% and 94.5%, respectively. In the outdoor environment, the accuracy of the SVM model is 92.9%. The experimental results show that this method can realize the high precision monitoring of the flow of people in the context of real-time pedestrian flow monitoring.
Similar content being viewed by others

1 Introduction
Pedestrian flow monitoring is a research hotspot in the field of computer vision and intelligent monitoring [1, 2]. Pedestrian flow monitoring aims at mastering the accurate distribution of personnel density at any time, so as to create strategies for various emergencies and effectively avoid the loss of life and property of personnel [3]. Owing to the rapid growth of population, congestion and stampedes have taken place to different degrees around the world, resulting in huge economic losses and casualties. The worst was the stampede in 1990 during the Hajj to Mecca, Saudi Arabia, in which 1426 people were killed. Another example was the stampede in Ming Tong Primary School on September 26, 2014 in Yunnan Province, which killed 6 people and injured 26 students. These painful lessons are reminding us of the importance of pedestrian flow monitoring. With the great development of society, pedestrian flow monitoring has been playing an increasingly important role in security prevention, urban construction, and market decision-making, especially in crowded places such as squares, stations, and shopping malls. In addition, the realization of real-time and accurate monitoring of pedestrian flow is of great significance for commercial information collection, public security prevention and control, and rational allocation of social resources.
In recent years, with the advent of artificial intelligence, pedestrian flow monitoring has made some progress at home and abroad. For instance, Viola proposes a pedestrian flow monitoring method based on motion characteristics [4]. Antonini et al. [5] propose a track-based pedestrian flow estimation method. Meanwhile, Kong et al. [6] propose and design a pedestrian flow monitoring method based on neural network. The method extracts edge and grey level histograms as features and makes use of a feedforward neural network to establish the classification model of personnel density. Ali [7] provides a new idea for pedestrian flow monitoring by referring to particle dynamics. This method can detect and separate foreground objects in the optical flow field and carry out dynamic analysis and research on group targets. Zhou et al. [8] propose a pedestrian flow monitoring method that combines feature regression and detection, while Wu et al. [9] propose a SURF algorithm based on the linear interpolation perspective correction for large-scale personnel statistical monitoring. The performance of the above methods can be weakened under the conditions of overlapping objects and dim light. In addition, the use of cameras can also bring privacy issues. Furthermore, Li et al. [10] propose a pedestrian flow monitoring method based on smart phone. Mizutani et al. [11] propose a pedestrian flow monitoring by mobile devices. These methods require people to carry mobile devices, thus it may not be appropriate under certain circumstances.
Currently, wireless IntelliSense technology, which utilizes received signal strength (RSS) and channel state information (CSI), has been developing rapidly. The wireless IntelliSense technology does not need to configure any sensors, but only uses the link information between wireless devices for task awareness. Target tracking based on RSS information is studied in the university of Utah. Yang and Ramezani propose CSI-based systems for indoor human tracking and fall detection, respectively [12, 13]. This paper is inspired by the above research results. Therefore, we hope to find a pedestrian flow monitoring method with strong environmental applicability, high accuracy, easy installation, and low computational cost.
We face two main challenges. First, according to the phenomenon of the fading change of the RSS value between nodes in the radio frequency (RF) sensor network when the physical human body passes through the RF sensor network. We need to observe the variation of RSS characteristics and find out the relationship between different number of people in unit time and area and RSS characteristics. Second, how to use support vector machine (SVM) to model, find the best kernel function, and conduct supervised learning and classification of data.
The contributions of this paper are as follows:
-
(1)
We propose a pedestrian flow monitoring method that does not require wearable equipment and protects the privacy of pedestrians. It uses the shadow attenuation effect of pedestrians on RF signals to achieve pedestrian monitoring.
-
(2)
We use the SVM algorithm to build a model and achieve statistical classification of the number of people.
The rest of the paper is organized as follows. The second section reviews the related work briefly. The third section introduces the principle of the RSS-based pedestrian flow monitoring system. The fourth section introduces the process of data acquisition and preprocessing, wavelet analysis and SVM classification algorithm. The fifth section describes the conducted experiments and classification result. Finally, the sixth section draws conclusion.
2 Related work
At present, the methods of pedestrian flow monitoring and statistics mainly include gate statistics, infrared detection and machine vision, etc. These methods can be divided into two categories: contact methods and non-contact methods.
The contact methods mainly include two approaches: installing mechanical gate or pressure sensitive pedal at the monitoring point [14]. The mechanical gate device is convenient and the count is accurate, but the equipment installation and operation and maintenance cost of this method are high, and the pedestrians are very slow, which is easy to cause congestion, and it will also bring a very unfriendly experience and impression to pedestrians. The pressure sensitive pedal approach needs to install the pressure sensor under the floor. This approach is simple and has a higher pass efficiency, but the pressure sensitive pedal is easy to damage after long-term use, and there are obvious limitations when many people pass at the same time.
Non-contact methods mainly include infrared-based approach and vision-based approach. Lv [15] and Xu et al. [16] design a statistical scheme for the number of people in construction elevator cages based on the principle that the visual distance path of infrared optoelectronic tube will change the signal output state of the receiver after being blocked by a human body. Infrared optoelectronic tube technology has a very high accuracy for single-person detection, but when multiple people or pedestrians carry objects such as large pieces of luggage through the detection point, the statistical accuracy of the number of people will be greatly reduced.
With the rapid development of image processing and machine learning, pedestrian flow monitoring based on machine vision has become a hot research branch. A large number of research results have sprung up in recent years, most of them mainly using individual characteristics such as shape, color, outline, or population characteristics to achieve pedestrian flow monitoring through a combination of SVMs, BP neural networks, CNNs [17, 18], and other machine learning algorithms [19,20,21]. Although domestic and foreign experts and scholars have put forward many ingenious methods for the monitoring of pedestrian flow, there are still some problems and deficiencies. In real life, the accuracy of judgment will also change with differences in the environment, which greatly increases the difficulty of the monitoring of pedestrian flow. The above methods often need to carry out pedestrian estimation based on a large number of data in pedestrian flow monitoring, which greatly increases the computational complexity, consumes more computing resources, and reduces monitoring efficiency. Furthermore, it is difficult to overcome the disadvantages of vision-based methods, such as high cost, pedestrian privacy, and susceptibility to light or smoke.
In this paper, we propose a method of pedestrian flow monitoring based on RSS of RF signal. RF signal is a kind of high-frequency electromagnetic wave with long-distance transmission and see-through abilities. It is now widely applied to the fields of transportation, medical care, anti-counterfeit technology, logistics, and security protection [22,23,24]. Our method utilizes the influence of the human body on RF signals to judge and monitor pedestrian flow. By processing the received RSS data and using the SVM algorithm for classification modeling, real-time pedestrian flow monitoring can be achieved. The method does not need to touch a human’s body, and there is no requirement for pedestrians to carry equipment. It does not have an impact on people’s normal activities, nor does it affect the passage efficiency of monitoring points. Since there is no need to take photos and videos, the privacy of pedestrians is not be involved. In addition, this method has a simple requirement for equipment and cost, and it is easy to operate and has a satisfying performance. The feasibility and credibility of the method are proved by the real-time verification of the system.
3 System principle
The pedestrian flow monitoring system proposed in this paper is based on the shadow attenuation effect of the human body on RF signals. The attenuation strength of RSS signals of different links is different when different numbers of people pass through the monitoring gate. Therefore, the attenuation value of RSS of all effective wireless links is used as the classification feature to establish a classification model when different numbers of people pass through the gate so as to realize judgment of the number of pedestrians at certain time points and also obtain statistics of the pedestrian flow over given time periods. This section will elaborate the principle of the RSS-based pedestrian flow monitoring system.
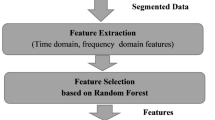
The basic block diagram of the proposed system method is shown in Fig. 1. Firstly, sufficient RSS data are collected. In the data preprocessing phase, wavelet filtering is carried out, then the output need wavelet decomposition, and the data are extracted after decomposition. Finally, the SVM model is trained to get the number of people passing through the monitoring gate.

The basic block diagram of the proposed system method
3.1 Human impact on RSS
When people pass by the wireless line-of-sight links consisting of transmitting nodes and receiving nodes, the RSS value of receiving nodes will be significantly decreased because of the human body’s absorption, reflection, and refraction of the RF signal. As shown in Fig. 2, the transmitting nodes and the receiving nodes are 2.4 m apart. When there is no person in the line-of-sight path, the mean value of RSS from receiving nodes is \(-57.5\,\hbox{dBm}\). When an adult stand in the middle of the line-of-sight path, the mean value of RSS is \(-70.0\,\hbox{dBm}\). It can be seen that the human body has a significant attenuation effect on the RSS of wireless links.

Influence of human body on received signal strength. a Experimental setup and b comparison of RSS values
3.2 Pedestrian flow impact on RSS
If L wireless sensor network nodes are installed on a gate-shaped bracket, these L nodes will form \(L(L - 1)/2\) wireless links. Figure 3 is a schematic diagram of a monitoring gate composed of 18 nodes and their wireless links. There are 153 wireless links in total, 105 of which go through the gate.
We find that when different people pass through the monitoring area through experiments, the RSS value of each wireless link will undergo different changes due to different links being blocked by the human body. For example, when different numbers of people walk through the monitoring gate shown in Fig. 3, the RSS values of the 70th wireless link (composed of nodes 5 and 14) and the 100th wireless link (composed of nodes 6 and 18) are as shown in Fig. 4. The RSS of each wireless link varies with different numbers of people passing through the monitoring area. This verifies the feasibility of pedestrian flow monitoring by using wireless link RSS based on a wireless sensor network. Therefore, different changes in RSS of links can be used as the classificational feature to estimate the number of instantaneous people.

Schematic diagram of node deployment and effective wireless link distribution

a RSS comparison diagram of the 70th wireless link and b RSS comparison diagram of the 100th wireless link
4 Algorithm
In this paper, the RSS value is utilized to monitor the pedestrian flow, and the number of people passing through is obtained by the RSS value of the link composed by the wireless sensor network. From the perspective of machine learning, this problem is a supervised multi-classification problem [25,26,27]. In the case of small data volume, the SVM can handle multiple classification problem well [28, 29]. Compared with other more complex machine learning algorithms, such as KNN, CNN, and RNN, SVM algorithm has many advantages, the most prominent two are suitable for small sample data classification and low computational complexity. This feature is especially suitable for the application of people flow monitoring based on RSS. Therefore, we adopt the SVM for obtaining the classification model of this system.
4.1 RSS data acquisition and preprocessing
The monitoring algorithm in this paper is shown in Fig. 5. In order to ensure the collection frequency of RSS values of each wireless link, the node software uses IAR to design an RSS collection program for nodes to broadcast messages according to their ID. When a sensing node receives a message packet, it must obtain the source node ID, read and calculate the RSS value of this communication wireless link, and write the RSS value to the element position corresponding to the source node ID in the RSS array. When it is the node’s turn to send a message, the saved array of RSS values are put into the message packet and broadcast. During RSS data sampling, 18 nodes constitute a polling broadcast network, and a Sink node listens and receives all the broadcasted packets, which are transmitted to the computer through the serial port and saved in TXT files.

Algorithm diagram
In the data preprocessing stage, we specify a sampling period from the start of first sensing network node sending packets to the end of the last node sending packets. Due to the dynamic changes in the environment, pedestrian interference and other factors, the data collected by the PC may be incomplete, that is, the data of a sensing node may be missing for a certain sampling period. In this paper, the algorithm designed to deal with the missing period uses the data of the previous sampling period to fill in the missing data of the current sampling period, thus improving the robustness of the algorithm in real-time pedestrian flow monitoring. We examine the received data and fill in the incomplete sampling period. Because the received RSS data are expressed in hexadecimal, it first needs to be converted to decimal for ease of processing. Then we can subtract an offset from the decimal number to get the real RSS value in dBm. After obtaining the real RSS value of each link in the wireless sensor network, the feature matrix of the effective links is obtained through feature extraction. The RSS measurement value on link i is expressed as \(y_i\), and the RSS vector of all links can be written as \({\mathrm{Y}} = {\left[ {{y_1},{y_2},{y_3}, \ldots {y_m}} \right] ^T}.\) Then the wavelet filtering is adopted to further extract precise features of RSS data of effective links.
4.2 Wavelet analysis
We use a series of low-pass filters and high-pass filters to filter the collected signal data. Low-pass filtering and high-pass filtering are both filtering methods in data processing. The rule of low-pass filtering is that the low-frequency signal can pass, and the high-frequency signal that exceeds the critical value set by the system is blocked and weakened. High-pass filtering is the opposite. Therefore, different filtering methods can be used according to different requirements. And then carry out wavelet decomposition of the output. The decomposition produces two parts whose lengths are halved: one is the approximate component of the original signal produced by the low-pass filter, and the other is the detailed component of the original signal produced by the high-pass filter. An RSS signal of length W is down sampled through a low-pass filter and a high-pass filter, the corresponding approximate component coefficient cA1 and detailed component coefficient cD1 are obtained, and the length of both component coefficients is W/2. Then, the same method is applied to cA1 for obtaining the approximate component cA2 and detailed component cD2 of the second layer. We repeat this process until we reach the preset decomposition level [30]. The decomposition process is shown in Fig. 6.

Schematic diagram of four-layer wavelet decomposition
The above process of wavelet decomposition can be expressed as the following equation:
where \({j \in \left\{ {0,1,2, \ldots } \right\} }\) is the levels of decomposition, k and n are translation coefficients, \({\mathrm{c}}_{j + 1,k}\) and \(d_{j + 1,k}\) are low-frequency approximate component coefficients and high-frequency detail component coefficients at \(2^{j}\) resolution, respectively, and \(h_{n - 2k}\) and \(g_{n - 2k}\) are low-pass filtering coefficients and high-pass filtering coefficients, respectively.
In this paper, the DB4 wavelet is adopted to carry out wavelet decomposition on received RSS measurement data. The threshold filtering method is also used to carry out signal filtering, and the threshold is set to 0.1. In this paper, if one person goes through the “gate,” the filtered waveform of the RSS value of one of the effective links can be obtained through 15-layer decomposition, as shown in Fig. 7. In the case of the same number of people passing through the gate, the same effective links have, theoretically, a small change in RF. Because the environment changes over time, the RF signal will fluctuate greatly. As can be seen from the waveform after wavelet filtering, the RSS fluctuation of the same effective link under the same condition tends to be stable, which is conducive to the establishment of the later model.

Wavelet filtering of effective link RSS value
4.3 SVM classification
The SVM is a method proposed by Vapnik et al. [31] on the basis of statistical learning theory. The SVM aims at ensuring the learning machine’s generalization ability by using the principle of structural risk minimization. Based on the statistical learning theory, the model base is established using the principle of structural risk minimization. The decision rules can still achieve lower expected risks for independent test datasets with a limited number of samples. The training process of the SVM involves finding an optimal hyperplane to partition data in high-dimensional space. The optimal hyperplane is defined as maximizing the distance from the nearest sample points to the hyperplane, and these sample points are called support vectors. SVMs have received considerable attention and have been successfully applied to many classification tasks due to their good generalization ability.
We assume that \({\mathbf{x }_i}\in {\mathbb {R}}^{n}\, \left( i = 1,2, \ldots ,N\right)\) are the input vectors, where each point \(\mathbf{x }_{i}\) belongs to one of the two classes denoted by a label \({y_i} \in \left\{ - 1, + 1 \right\}\). In the linearly separable case, the input vectors can be classified by the separating hyperplane, \(\mathbf{w }^T\mathbf{x } + b = 0\), which satisfying the condition of \({\mathrm{y}}_{i}\left( \mathbf{w }^{T}\mathbf{x }_{i} + b \right) >0\), where \(\mathbf{w }\) is the normal vector that determines the direction of the hyperplane, and b determines the distance between the hyperplane and the origin. There may exist many hyperplanes which meet this condition. In order to construct a optimal hyperplane to separate the two classes, by scaling w and b, we set \({\mathrm{y}}_{i}\left( \mathbf{w }^{T}\mathbf{x }_{i} + b\right) \ge 1\) for \(i = 1,2, \ldots ,N\). The distance from the closest point to the hyperplane is \({1 /{\left\| \mathbf{w } \right\| }}\) so that finding the optimal separating hyperplane needs maximize \(1/\Vert \mathbf{w }\Vert\) which can be converted to minimize \(\frac{1}{2}{\left\| \mathbf{w } \right\| ^2}\). The original support vector machines solved the following optimality problem:
However, most data sets in the real world cannot be completely linearly separated. Therefore, in this paper, the soft margin SVM is used to establish a pedestrian classification model. It is implemented by introducing slack variables, \({{\xi _i} \ge 0}\). This improved method allows for errors in some samples. The optimal classification hyperplane can be obtained by solving the following convex quadratic programming problem:
where \({{\xi _i}}\) are positive slack variables and C is the penalty factor controlling the tradeoff between the maximal margin and the minimal classification error. The parameter C affects the generalization ability of the SVM. If the value of C is large, it will cause overfitting to the training data. On the contrary, if it is set too small, the classifier will cause underfitting. Formula (1) can obtain its dual problem by using Lagrange multiplier method and then obtain the estimated decision function by solving the dual problem:
where \({{\alpha _i}}\left( {i = 1,2, \ldots ,N} \right)\) are the nonnegative Lagrangian multipliers. By solving the above problems, the decision function is obtained as follows:
When the input vectors are not linearly separable, we cannot process the vectors with linear classification. We need to utilize the kernel function to map input vectors to a higher-dimensional space, which turns the problem of nonlinear separability in low-dimensional space into the problem of linear separability in high-dimensional space. Then, the purpose of classification by finding the classification hyperplane can be achieved. The kernel function is as follows:
\(\phi\) is a mapping from X to the inner product feature space. Any function that satisfies Mercer’s condition can be considered as a kernel function. In the SVM, different kernel functions are selected to generate different models, and the selection of kernel functions directly determines the classification results and machine learning ability of the SVM. There are four main types of common kernel functions including linear, polynomial, gaussian, sigmoid kernel function. By using the appropriate kernel function \({\mathrm{K}}\left( \mathbf{x }_{i},\mathbf{x }_{j} \right)\) to achieve classification, the decision function is obtained as follows:
In this study, this paper chooses the linear kernel function as the kernel function of SVM to classify the experimental data. The linear kernel function is defined as follows:
SVM was originally designed for two classification problem, but since the pedestrian flow monitoring in this paper is a multi-class problem. There are roughly two implementations of SVM multi-class classification methods:
-
(1)
Modifying the algorithm of support vector machine so that multiple classification problem is realized by solving the optimization problem “at one time".
-
(2)
Constructing and combining multiple binary classifiers. The second method mainly includes one-against-rest and one-against-one. If one-against-rest method is used, M SVMs are required for M classification problems. For the ith SVM, all the samples of the ith class are labeled as positive class, and the rest samples are labeled as negative class. A test sample is labeled according to maximum output among the M classifiers. If one-against-one method is used, \(M(M - 1)/2\) SVMs are required for M classification problems. It constructs a SVM between each pair of classes and chooses the class with the most votes as the final class of the test sample.
This paper uses one-against-rest method to construct multi-classification SVM to solve the multi-class problem. The advantage of this method is that for M classification problems, only M two-class classifiers support vector machines need to be trained and the classification speed is relatively fast.
5 Experiments and results
5.1 Experimental setup
The experimental environment is set up as shown in Fig. 8. This experiment utilized 18 CC2530 nodes and a metal door frame to form a 5–8–5 gate frame. Five sensor nodes were arranged at equal intervals on both sides of the gate frame, and the receiving antennas were upward. Ten sensor nodes were distributed at equal intervals above the gate frame, and the receiving antennas were uniformly downward. This constitutes the wireless sensor network. The gate frame selected in this experiment was 2.4 m wide and 2.0 m high. It was divided into three virtual pedestrian channels (A, B, and C), each of which was 60 cm wide to ensure the normal passage of three people. During the experiment, the distance between the experimenter and the nodes on both sides was not less than 30 cm because if the experimenter was too close to the nodes on the sides, it would block the radio frequency signal and affect the normal communication between nodes, thus greatly impacting the experiment. The Sink node was placed about 5 m away from the gate frame and was connected to a laptop for uploading raw data. The SVM tool used in this experiment was the LIBSVM package running under the Windows 10 operating system.

The experimental scene (A):indoor environment
5.2 Experimental data processing
The feature vectors of wavelet domain can be obtained from original data of RSS by basic processing of the method described in the previous section. In fact, we only use the feature vectors of the effective links for model building and pedestrian flow monitoring. We need to use SVM to train an optimized classification model, and then use this model for real-time pedestrian flow monitoring. In other words, the processing of pedestrian flow monitoring based on RSS was divided into two steps:
-
(1)
Offline stage. The purpose of this stage was mainly data collection and data processing. First, the signal strength values of nobody, 1 person, 2 people, and 3 people passing through the experimental gate frame were collected as experimental samples. The RSS values of different numbers of pedestrians were calculated from received data and taken as the feature vectors. Second, the SVM algorithm was utilized to establish the classification model. Finally, we optimized the classification model. In order to reduce the impact of random interference in the experiment, multiple groups of data were collected in each case, and the collection time was as random as possible.
-
(2)
Online stage. In this stage, real-time monitoring was carried out to estimate the number of people that pass through the gate. We received the RSS values of the system nodes when pedestrians passed through the gate, and conducted data processing. Then, the processed real-time received data were taken as input to determine the number of pedestrians using the classification model. We utilized the error rate of manually derived statistics and system statistics to judge the performance of this monitoring algorithm. The formula for error rate is
$$\begin{aligned} \frac{\left| \hbox{num}_{\mathrm{actual}} - \hbox{num}_{\mathrm{system}}\right| }{\hbox{num}_{\mathrm{actual}}}*100\% \end{aligned}$$(9)\(\hbox{num}_{\mathrm{actual}}\) and \(\hbox{num}_{\mathrm{system}}\) represent the actual number of people manually counted and the number of people automatically estimated by our designed system, respectively.
In order to train the classification model, we design four off-line experiments to obtain a small data set. In the four experiments, the number of people passing through the monitoring gate at the same time was 0, 1, 2 and 3, respectively. We collected a total of 360 sets of source data, the detail of which were as follows:
-
(1)
When nobody passed through, 90 sets of data were collected. Each set lasted for 10 s to obtain about 50 cycles of sampling data.
-
(2)
Only one person passed through the monitoring gate at a time. Total 30 people took part in this experiments. The experimenter passed through one of the three virtual pedestrian channels at normal speed successively. A total of 90 groups of data were collected.
-
(3)
There were two people who passed through the monitoring point at the same time. Total 15 groups of pairs participated in the experiments. A total of 90 groups of RSS data were collected.
-
(4)
When three people passed through at the same time, 15 groups of three people participated in the experiments. Also a total of 90 groups of RSS data were collected.
5.3 Result
The received data were utilized to extract feature vectors through data processing and established classification labels. The obtained feature vectors were used as input to establish the classification model. In this paper, the identification tool was mainly LIBSVM. The selection of kernel function was determined by the accuracy(acc) of the model with different kernel functions:
where a represents the experimental data correctly classified and s represents the experimental data of all classifications. Cross validation (CV) is used to find the optimal kernel function. Table 1 shows the corresponding relationship between different kernel functions in the experiment and the accuracy of the model. As can be seen from Table 1, the linear kernel has the highest accuracy among the four commonly used kernel functions. Thus, we choose the linear kernel as the kernel function of the SVM to classify the number of people passing through the monitoring point instantaneously.
In this paper, experiments were carried out at two different places. One place is corridor in the building as shown in Fig. 8. Because the first experiment was conducted in an indoor environment, and in order to make the results more rigorous, we conducted the second experiment outdoors. In the first experiment, the system framework was placed at the gate of the second floor of the building D, Nanchang Hangkong University. Data were collected in two cases, during class and after class, to compare the impact of personnel density on the experiments. In each case, the passage of personnel in 5 periods (5 min in each period) was collected in this experiment. During the experiment, both manual counting and system counting were used. Tables 2 and 3 show the experimental results in the cases of dense personnel density and sparse personnel density, respectively.
To evaluate the performance of the proposed RSS-based pedestrian flow monitoring method, we compare the performance of the system using SVM algorithm with the other two algorithms, the algorithm based on the model of Gaussian Mixture Model (GMM)–Hidden Markov Model (HMM) [32] and the gradient boosting decision tree (GBDT) algorithm.
It can be seen from Tables 2 and 3 that the statistical error rate of the two cases is 11.1% and 5.5%, respectively. By averaging the two accuracy values, we can get the overall accuracy of 91.7%. It also can be found that when the personnel density is sparse, the system’s personnel statistics are relatively accurate; however, when the personnel density is relatively dense, the system’s estimation has certain errors. When the density of people passing through is too high, the walls and pedestrians outside the experimental area will have an impact on the experiment because of the influence of multipath reflection.
We conducted the second experiment in the corridor on the third floor between building D and building E, as shown in Fig. 9. In order to make the experimental scenario more consistent with the daily application scenario, this experiment collected a total of 6 periods (each period is a random period, ranging from 2 to 5 min). The first three groups had less people flow, while the last three groups had more people flow. During the experiment, both manual counting and system counting were used. The experimental results are shown in Table 4.

The experimental scene (B):outdoor experiment
It can be seen from Table 4 that the statistical mean error rate is 7.1%, that is, the average accuracy rate is 92.9%, which is obviously better than the compared algorithms GMM–HMM and GBDT. The six sets of data collected in this experiment all have relatively large numbers of pedestrians, however, the experimental results are satisfactory. Combining the results of the two groups of experiments, we can see that the proposed method can achieve good results, which achieves a high accuracy and can meet the needs of most pedestrian flow monitoring applications.
6 Conclusion and future work
In this paper, a pedestrian flow monitoring method based on radio frequency signals is proposed. This method mainly utilizes the shadow attenuation effect of pedestrians on RF signals of effective links, which may be blocked by pedestrians. The wavelet decomposition of RSS signal series of a short time is used as features. A SVM algorithm is trained by an experimental data set to distinguish the instantaneous number of pedestrian passing through the monitoring point. The performance of this method is verified by two online real-time experiments in indoor and outdoor, which can achieve approximate 92.9% accuracy of pedestrian flow counting. The proposed pedestrian flow monitoring method has the characteristics of strong environmental applicability, high accuracy, no privacy issues involved, easy installation, and low computational complexity. It can be a beneficial supplement to the traditional methods.
However, this method also has some limitations. For example, it can’t distinguish the direction of pedestrians, and it is not clear about the impact of the people around the monitoring point. In addition, the proposed method can only allow up to three people to pass side by side. Our future research work will focus on these issues.
Abbreviations
- RSS:
-
Received signal strength
- SVM:
-
Support vector machine
- CSI:
-
Channel state information
- RF:
-
Radio frequency
- RSSI:
-
Received signal strength indication
- CV:
-
Cross validation
References
J. Sang, W. Wu, H. Luo, H. Xiang, Q. Zhang, H. Hu, X. Xia, Improved crowd counting method based on scale-adaptive convolutional neural network. IEEE Access 7, 24411–24419 (2019). https://doi.org/10.1109/ACCESS.2019.2899939
J. Zhu, F. Feng, B. Shen, People counting and pedestrian flow statistics based on convolutional neural network and recurrent neural network. In: 2018 33rd Youth Academic Annual Conference of Chinese Association of Automation (YAC) (Nanjing, China, 18–20 May 2018), pp. 993–998. https://doi.org/10.1109/YAC.2018.8406516
R. Benenson, M. Omran, J. Hosang, B. Schiele, Ten years of pedestrian detection. In What have we learned? European Conference on Computer Vision (Springer, Cham, 2014). https://doi.org/10.1007/978-3-319-16181-5_47
P. Viola, M.J. Jones, D. Snow, Detecting pedestrians using patterns of motion and appearance. in Proceedings of the Ninth IEEE International Conference on Computer Vision Vol. 2 (Nice, France, 13–16 October 2003), pp. 734–741. https://doi.org/10.1109/ICCV.2003.1238422
G. Antonini, S.V. Martinez, M. Bierlaire, J.P. Thiran, Behavioral priors for detection and tracking of pedestrians in video sequences. Int. J. Comput. Vis. 69(2), 159–180 (2006). https://doi.org/10.1007/s11263-005-4797-0
D. Kong, D. Gray, H. Tao, A viewpoint invariant approach for crowd counting. in Proceedings of the 18th International Conference on Pattern Recognition (ICPR’06) vol. 3 (Hong Kong, China, 20–24 August 2006), pp. 1187–1190. https://doi.org/10.1109/ICPR.2006.197
S. Ali, M. Shah, A. Lagrangian, Particle dynamics approach for crowd flow segmentation and stability analysis. in Proceedings of the 2007 IEEE Conference on Computer Vision and Pattern Recognition (Minneapolis, MN, USA, 17–22 June 2007), pp. 1–6. https://doi.org/10.1109/CVPR.2007.382977
Z. Zhou, L. Xu, W. Li, People counting based on feature-regression and detection. J. Comput. Aided Des. Comput. Graph. 27, 425–432 (2015)
D. Wu, J. Wang, B. Li, T. Guo, Large crowd count based on improved surf algorithm. J. Xi’an Univ. Sci. Technol. 27, 650–655 (2015). https://doi.org/10.13800/j.cnki.xakjdxxb.2015.0520
H. Li, E.C.L. Chan, X. Guo, J. Xiao, K. Wu, L.M. Ni, Wi-counter: smartphone-based people counter using crowdsourced Wi-Fi signal data. IEEE Trans. Hum. Mach. Syst. 45(4), 442–452 (2015). https://doi.org/10.1109/THMS.2015.2401391
M. Mizutani, A. Uchiyama, T. Murakami, H. Abeysekera, T. Higashino, Towards people counting using Wi-Fi CSI of mobile devices. In 2020 IEEE International Conference on Pervasive Computing and Communications Workshops (PerCom Workshops) (23–27 March 2020), pp. 1–6. https://doi.org/10.1109/PerComWorkshops48775.2020.9156098
R. Ramezani, Y. Xiao, A. Naeim, Sensing-Fi: Wi-Fi CSI and accelerometer fusion system for fall detection. in 2018 IEEE EMBS International Conference on Biomedical Health Informatics (BHI) (Las Vegas, NV, USA, 4–7 March 2018), pp. 402–405. https://doi.org/10.1109/BHI.2018.8333453
K. Benkic, M. Malajner, P. Planinsic, Z. Cucej, Using RSSI value for distance estimation in wireless sensor networks based on zigbee. in 2008 15th International Conference on Systems, Signals and Image Processing (Bratislava, Slovakia, 25–28 June, 2008), pp. 303–306. https://doi.org/10.1109/IWSSIP.2008.4604427
Q. Zhao, The Technology Research and Implementation of Bus Passenger Flow Statistics Based on Video Analysis. Thesis for Master Degree (Chongqing University, Chongqing, China, 2016)
X. Lv, The Research and Development of Construction Hoist Remote Monitoring System. Thesis for Master Degree (Shandong University, Jinan, China, 2015)
B. Xu, J. Yang, F. Xu, M. Guo, Study of multiscale detection in near distance image for numbers of people in elevator car. in Proceedings of the 6th International Conference on Manufacturing Science and Engineering (Guangzhou, China, 28–29 November, 2015), pp. 322–328. https://doi.org/10.2991/icmse-15.2015.60
D.B. Sam, S. Surya, R.V. Babu, Switching convolutional neural network for crowd counting. in Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (Honolulu, HI, USA, 21–26 July, 2017), pp. 4031–4039. https://doi.org/10.1109/CVPR.2017.429
X. Jiang, L. Zhang, P. Lv, Y. Guo, R. Zhu, Y. Li, Y. Pang, X. Li, B. Zhou, M. Xu, Learning multi-level density maps for crowd counting. IEEE Trans. Neural Netw. Learn. Syst. 31(8), 2705–2715 (2020). https://doi.org/10.1109/TNNLS.2019.2933920
A.C. Davies, J.H. Yin, S.A. Velastin, Crowd monitoring using image processing. Electron. Commun. Eng. 7(1), 37–47 (1995). https://doi.org/10.1049/ecej:19950106
M. Rasoulidanesh, S. Yadav, S. Herath, Y. Vaghei, S. Payandeh, Deep attention models for human tracking using RGBD. Sensors 19(4), 750 (2019). https://doi.org/10.3390/s19040750
M.M. Trivedi, K.S. Huang, I. Mikic, Dynamic context capture and distributed video arrays for intelligent spaces. IEEE Trans. Syst. Man Cybern. Syst. 35(1), 145–163 (2005). https://doi.org/10.1109/TSMCA.2004.838480
I. Ashraf, S. Hur, Y. Park, Indoor positioning on disparate commercial smartphones using Wi-Fi access points coverage area. Sensors 19(19), 4351 (2019). https://doi.org/10.3390/s19194351
X. Guo, L. Li, N. Ansari, B. Liao, Accurate WiFi localization by fusing a group of fingerprints via a global fusion profile. IEEE Trans. Veh. Technol. 67(8), 7314–7325 (2018). https://doi.org/10.1109/TVT.2018.2833029
H. Jin, A. Titus, Y. Liu, Y. Wang, Z. Han, Fault diagnosis of rotary parts of a heavy-duty horizontal lathe based on wavelet packet transform and support vector machine. Sensors 19(19), 4069 (2019). https://doi.org/10.3390/s19194069
V.N. Vapnik, The Nature of Statistical Learning Theory (Springer, New York, 1995), pp. 119–176
H. Zhang, Y. Guo, D. Zanotto, Accurate ambulatory gait analysis in walking and running using machine learning models. IEEE Trans. Neural Syst. Rehabil. Eng. 28(1), 191–202 (2020). https://doi.org/10.1109/TNSRE.2019.2958679
X. Wei, H. Shen, M. Kleinsteuber, Trace quotient with sparsity priors for learning low dimensional image representations. IEEE Trans. Pattern Anal. Mach. Intell. 42(12), 3119–3135 (2020). https://doi.org/10.1109/TPAMI.2019.2921031
X. Xie, S. Sun, Multi-view support vector machines with the consensus and complementarity information. IEEE Trans. Knowl. Data Eng. 32(12), 2401–2413 (2020). https://doi.org/10.1109/TKDE.2019.2933511
L. Liu, W. Huang, C. Wang, Hyperspectral image classification with kernel-based least-squares support vector machines in sum space. IEEE J. Topics Appl. Earth Observ. 11(4), 1144–1157 (2018). https://doi.org/10.1109/JSTARS.2017.2768541
J. Li, X. Cui, H. Song, Z. Li, J. Liu, Threshold selection method for UWB TOA estimation based on wavelet decomposition and kurtosis analysis. J. Wirel. Comput. Netw. 2017, 1–10 (2017). https://doi.org/10.1186/s13638-017-0990-4
V.N. Vapnik, Statistical Learning Theory (Wiley, New York, 1998)
M. Gao, Research of Human Traffic Monitoring Method Based on Radio Frequency Sensor Network. Thesis for Master Degree (Nanchang Hangkong University, Nanchang, China, 2018)
Funding
This research was funded by the National Natural Science Foundation of China, Grant Nos. 61501218 and 61906041.
Author information
Authors and Affiliations
Contributions
Conceptualization, ZY and KH; methodology, ZY and JW; software, JW; validation, ZY, JW and KH; formal analysis, JW; investigation, ZY; resources, JW; data curation, JW; writing–original draft preparation, ZY; writing–review and editing, ZY and KH; visualization, JW; supervision, KH; project administration, ZY; funding acquisition, KH. All authors have read and agreed to the published version of the manuscript. All authors read and approved the final manuscript.
Authors' information
Zhiyong Yang received the Ph.D. degree in communication and information system from Sun Yat-sen University, Guangzhou, China, in 2013. He is currently a Lecturer with the School of Software, Nanchang Hangkong University, Jiangxi, China. His research interests include compressed sensing, sensor-less sensing, and wireless sensor networks.
Jing Wen received the B.S. degree in software engineering from Gannan Normal University, Ganzhou, China, in 2020. Now she is currently working toward the M.S. degree with the School of Software in Nanchang Hangkong University, Jiangxi, China. Her research interests include sensor-less sensing and machine learning.
Kaide Huang received the B.S. and Ph.D. degrees from Sun Yat-sen University, Guangzhou, China, in 2011 and 2016, respectively. In 2016, he joined the Computer Network Information Center, Chinese Academy of Sciences, Guangzhou, where he was an Assistant Chief Engineer, from 2017 to 2018. He is currently an Associate Researcher with the School of Mathematics and Big Data, Foshan University, Guangdong, China. His research interests include compressed sensing, signal reconstruction, wireless sensor networks, and control systems.
Corresponding author
Ethics declarations
Competing interests
The authors declare that they have no competing interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Yang, Z., Wen, J. & Huang, K. A method of pedestrian flow monitoring based on received signal strength. J Wireless Com Network 2022, 2 (2022). https://doi.org/10.1186/s13638-021-02079-y
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s13638-021-02079-y