
Abstract
In competitive markets, market segmentation is a critical point of business, and it can be used as a generic strategy. In each segment, strategies lead companies to their targets; thus, segment selection and the application of the appropriate strategies over time are very important to achieve successful business. This paper aims to model a strategy-aligned fuzzy approach to market segment evaluation and selection. A modular decision support system (DSS) is developed to select an optimum segment with its appropriate strategies. The suggested DSS has two main modules. The first one is SPACE matrix which indicates the risk of each segment. Also, it determines the long-term strategies. The second module finds the most preferred segment-strategies over time. Dynamic network process is applied to prioritize segment-strategies according to five competitive force factors. There is vagueness in pairwise comparisons, and this vagueness has been modeled using fuzzy concepts. To clarify, an example is illustrated by a case study in Iran's coffee market. The results show that success possibility of segments could be different, and choosing the best ones could help companies to be sure in developing their business. Moreover, changing the priority of strategies over time indicates the importance of long-term planning. This fact has been supported by a case study on strategic priority difference in short- and long-term consideration.
Similar content being viewed by others

Background
Porter 1980) described a category scheme including three general types of strategies: Cost leadership, differentiation, and market segmentation which are commonly used by various businesses to achieve and maintain competitive advantages. These three generic strategies are defined along two dimensions: strategic scope and strategic strength. Strategic scope is a demand-side dimension and looks at the size and composition of the market you intend to target. Strategic strength is a supply-side dimension and looks at the strength or core competency of the firm. Market segmentation is narrow in scope when both cost leadership and differentiation are relatively broad in market scope. Market segmentation divides the market into homogeneous groups of individual markets with similar purchasing response as a number of smaller markets have differences based on geography, demographics, firm graphics, behavior, decision-making processes, purchasing approaches, situation factors, personality, lifestyle, psychographics, and product usage (Aaker 1995; Bonoma and Shapiro 1983; Dickson 1993; Kotler 1997; Bock and Uncles 2002; Nakip 1999; File and Prince 1996). The results of segmentation could be improved considerably if information on competitors is considered in the process of market segmentation (Söllner and Rese 2001). Market segmentation allows the marketing program to focus on a special part of the market to increase its competitiveness by applying various strategies. These strategies can be new products development, differentiated marketing communications, advertisements creation, different customer services development, prospects targeting with the greatest potential profits, and multi-channel distribution development. Many researchers developed the evaluation and selection of market segmentation methods to achieve more customer satisfaction by focusing on marketing programs designed to satisfy customer requirements efficiently. The vast majority of decision-making methods have focused on evaluating the different segmentation methods and techniques (Kuo et al. 2002; Lu 2003; Coughlan and Soberman 2005; Liu and Serfes 2007; Ou et al. 2009; Phillips et al. 2010; Tsai et al. 2011a, 2011b). In the market segment evaluation and selection, there are four stages or procedures that were introduced by Montoya-Weiss and Calentone (2001): problem structuring, segment formation, segment evaluation and selection, and description of segment strategy.
Distinction of segmentation at a strategic or at an operational level has been made by several authors such as Goller et al. (2002) and Sausen et al. (2005). The general assumption behind the dimension is that there is a fundamental difference in how the firm is affected by the segmentation (Clarke and Freytag 2008). At a strategic level, the consideration is on the top management level and concerns the creation of missions and strategic intent, and can become closely linked to the capabilities and nature of the organization (Jenkins and McDonald 1997). At the operational level, there is a concern for planning and operational schemes for reaching target segments with an effectively adjusted offering as well as monitoring the performance (Albert 2003). In a competitive market, strategies are critical points of business, which lead the companies towards their vision as their final destination. Strategy description and selection is an important part of strategic management process. Many approaches, techniques, and tools can be used to analyze strategic cases in this process (Dincer 2004). Ray (2000) applied strategic segmentation where, prior to price competition, each firm targets the information to specific consumers who are informed by a firm that they can buy from it.
Among the strategic tools, SPACE matrix (Rowe et al. 1982) is a common method. It is used as a strategy description and success evaluation technique that includes two dimensions: internal perspectives (financial strength (FS) and competitive advantage (CA)) and external perspectives (environmental stability (ES) and industry strength (IS)).
All marketing strategies include a search for competitive advantages (Bharadwaj and Varadarajan 1993; Day and Wensley 1988; Varadarajan and Cunningham 1995; Hunt and Arnett 2004). According to Söllner and Rese (2001), ‘The consideration of competitive structure provides additional basic information on segment formation’ and ‘The consideration of competitive structure facilitates the selection of promising segments’. SPACE matrix is a support tool for decision-making process, and it is very useful when the market competitiveness is a critical point of decision-making process. In this method, internal and external perspectives are evaluated according to the overall situation of the company in the market to build strategies basing on the factors in the four main groups (FS, CA, ES, and IS). These generic strategies are termed as ‘defensive’, ‘aggressive’, ‘conservation’, and ‘competitive’ which can be broken from the main strategies. Moreover, the SPACE matrix can indicate success possibility through the algebraic summation of the evaluated factor scores within its two dimensions (Figure 1).

Space graph and generic strategies.
In a dynamic and ever-changing world, the time frame is important for a segmentation process (Nakip 1999; Freytag and Clarke 2001). Market segments and strategies can be selected based on a set of factors and sub-factors which vary over time. In competitive markets, the effects of time are more sensible on prioritization. It means that their priorities could be changed particularly when the factors are time-dependent. Saaty (2007) extended the analytic hierarchy process (AHP)/analytic network process (ANP) to deal with time-dependent priorities and referred them as dynamic hierarchy process (DHP)/dynamic network process (DNP). In his method, prioritization is done by considering the changes in the market over time, which affect the importance of factors. Moreover, the fuzzy concept has been applied to solve the problem due to the vagueness of the importance and the priorities of these factors. Below, Table 1 shows the recent works on this subject and summarizes their main considerable issues. As presented in the table, this work ‘considers risk’ and ‘factors interdependency’ in studying and in ‘selecting the segment-strategies over time’.
As it is observed in the above table, recent researches have considered the important factors of this problem, but none of them provides a comprehensive model. Also, time-dependent decision making is an affective item that is provided in this paper, which was not considered in previous works.
In this paper, a strategy-aligned fuzzy approach is developed to select the best segment-strategy in market segment evaluation and selection problem. A modular decision-making process is implemented in two stages:
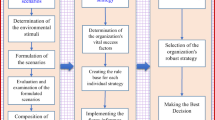
The first one selects the segments with more chance of success which has an acceptable risk in a competitive market according to their situation in the SPACE matrix. As the first contribution, by applying the SPACE matrix method, competition is taken into account by defining the distance of segments from the best situation of competitive advantage. On the other hand, this method can give an overall view of the competitive advantage of all segments with a risk evaluation of choosing the segments in a simple graph. The second stage is segment-strategy selection, considering that priorities change over time, by dynamic network process. As the second contribution, segments are selected by considering the effect of time on the decision-making criteria. Moreover, the effects of strategies on changing the priorities are considered over time, and the trend of segment-strategy priorities can be determined in various time horizons. Porter's (1980) five force factors and sub-factors have been applied as well known decision-making criteria in dealing with competitive advantage. This approach defines the risk level of the segments; thus, decision makers (DMs) could select the appropriate segments according to their acceptable risk levels. Furthermore, they could select more exact strategies by focusing on selected segment. In addition, the proposed DNP method enables them to analyze segment-strategies over time, and this ability could affect their decision. The steps of the proposed DSS are shown in Figure 2.

The steps of the proposed DSS.
The rest of this paper is organized as follows: In the ‘Methods’ section, the dynamic network process is shown including the explanation of its applications in the next section. The ‘Fuzzy fundamental’ section presents a brief overview of the fuzzy concepts. In section ‘Fuzzy dynamic network process’, the fuzzy DNP calculation method is presented. In the ‘Results and discussion’ section, a procedure for segment-strategy selection is introduced, including how to select an optimum solution. A case study with its computational results is also presented for the proposed model. The final section gives the conclusions and future works.
Methods
Time-dependent analytic network process
Market segment evaluation and selection can be classified as a multi-criteria decision-making (MCDM) problem. AHP is the well known and the most widely used method among several MCDM approaches such as SAW, MEW, TOPSIS, and ELECTRE. AHP was introduced by Saaty (1980) for decision-making as a theory of relative measurement based on paired comparisons used to derive normalized absolute scales of numbers, the elements of which are then used as priorities. The ANP was developed and implemented by Saaty (1996) as an AHP with feedback. The ANP feedback approach replaces hierarchies with networks in which the relationships among the levels are not easily represented as higher or lower, dominant or subordinate, and direct or indirect (Meade and Sarkis 1999). In AHP and ANP, static and derived numbers are used to represent priorities. When the priorities vary across the time, AHP and ANP need to be dynamic through the use of numbers or functions and then derive either numbers that represent functions like expected values, or derive functions directly to represent priorities. Saaty (2007) extended the AHP/ANP to deal with time-dependent priorities and referred them as DHP/DNP. In this way, Saaty (2007) presented two methods: the (1) numerical solution of the principal eigenvalue problem by raising the matrix to powers and the (2) analytical solution of the principal eigenvalue problem by solving algebraic equations of degree n. In ANP, the problem is to obtain the limiting result of powers of the super-matrix with dynamic priorities. Because its size will increase in the near future, the super-matrix would have to be solved numerically (Saaty 2007). In the numerical solution, the best fitting curves for the components of the eigenvector were obtained by plotting the principal eigenvector for the indicated values of t. In the analytical solution for the pairwise comparison judgments in dynamic conditions, Saaty (2007) purposed some functions for the dynamic judgments, which are given in Table 2.
To solve the problem and to obtain the time-dependent principal eigenvector, Saaty (2007) introduced the numerical approach by simulation, in which at first, the judgments express functionally but then derives the eigenvector from the judgments for a fixed instant of time, substitutes the numerical values of the eigenvectors obtained for that instant in a super-matrix, solves the super-matrix problem, and derives the priorities for the alternatives. This process is repeated for different values of time, which generates a curve for the priorities of the alternatives and then approximates these values by curves with a functional form for each component of the eigenvector. This procedure is used in this paper to obtain the priorities of the alternatives in fuzzy dynamic network process (FDNP).
Why dynamic network process?
In a decision-making process of selecting market segments, priorities are calculated based on competitive factors with respect to some important criteria such as the effects of the interdependency among the factors and the trend of segment-strategy priorities in various time horizons. Dynamic network process as a powerful decision-making method can cover these important criteria by considering interdependency in networks in a dynamic decision-making process. Thus, DNP is a more useful method that can be applied to prioritize the alternatives in comparison with other decision-making processes.
Fuzzy fundamental
Fuzzy set theory was introduced by Zadeh (1965) to deal with the uncertainty caused by imprecision and vagueness in real world conditions. A fuzzy set is a class of objects with a continuum of grades of membership, which assigns to each object a grade of membership ranging between zero and one (Kahraman et al. 2003).
A triangular fuzzy number (TFN; ) with its membership function is shown in Figure 3. TFN can be denoted by (l, m, u), where the triplet (l, m, u) are crisp numbers and l ≤ m ≤ u. These parameters l, m and u denote the smallest possible value, the most promising value, and the largest possible value, respectively. The triplet (l, m, u) as a TFN has a membership function with following form:

A triangular fuzzy number. The broken line is a guide to present the position of the most promising value of a TFN (m), while the solid line denotes the membership values of a TFN.
Fuzzy operations for TFNs
Let and be two TFNs; there are some primary fuzzy operations as bellow (Keufmann and Gupta 1991; Kahraman et al. 2002):
-
1)
Addition of two fuzzy numbers:
-
2)
Multiplication of two fuzzy numbers:
-
3)
Multiplication of a crisp number k and a fuzzy number:
-
4)
Division of two fuzzy numbers:
-
5)
Addition of two fuzzy numbers:
-
6)
Multiplication of two fuzzy numbers:
-
7)
Multiplication of a crisp number k and a fuzzy number:
-
8)
Division of two fuzzy numbers:
Linguistic variables and fuzzy numbers
Linguistic variables represent an opinion independent of measuring system. While variables in mathematics usually take numerical values, in fuzzy logic applications, the non-numeric linguistic variables are often used to facilitate the expression of rules and facts (Zadeh et al. 1996). The fuzzy scale regarding the relative importance to measure the relative weights is proposed by Kahraman et al. (2006). This scale was used to solve fuzzy decision-making problems (Kahraman et al. 2006; Tolga et al. 2005; Dağdeviren and Yüksel 2010) in the literature of strategic management. This scale was later used by Mikhailov (2000, 2003) in fuzzy prioritization approach. Linguistic scales for difficulty and importance are shown in Table 3 and Figure 4, and the linguistic values and the mean of fuzzy numbers are shown in Table 4 and Figure 5.

The membership functions of linguistic variables for importance weights. EI, equally important; WMI, weakly more important; SMI, strongly more important; VSMI, very strongly more important; AMI, absolutely more important. The broken line is a guide to present the position of the most promising value of a TFN (m), while the solid line denotes the membership values of a TFN.

The membership functions of linguistic variables for ratings. VH, very high; VL, very low; H, high; L, low; M, medium. The broken line is a guide to present the position of the most promising value of a TFN (m), while the solid line denotes the membership values of a TFN.
Why fuzzy logic?
In most of cases, pairwise comparisons are vague because every decision has its special specifications. Using fuzzy numbers is a powerful tool to overcome the uncertainty and vagueness of data. On the other hand, pairwise comparisons with linguistic variables are easier for experts. Fuzzy set theory was introduced by Zadeh (1965) to deal with uncertainty due to imprecision and vagueness; since then, many applications have been developed in fuzzy decision-making processes. For computational efficiency, trapezoidal or triangular fuzzy numbers are usually used to represent fuzzy numbers (Klir and Yuan 1995). In this paper, TFNs are used to make the mathematics manageable and easy to understand, and to facilitate presentation of the case.
Fuzzy dynamic network process
Mikhailov (2000, 2003) developed a fuzzy prioritization approach with the advantage of the measurement of consistency indexes for the fuzzy pairwise comparison matrices. In other methods (Buckley 1985; Chang 1996; Cheng 1997; Deng 1999; Leung and Cao 2000), it is not possible to determine the consistency ratios of fuzzy pairwise comparison matrices without conducting an additional study. Mikhailov (2000, 2003) introduced three stages:
-
1)
Statement of the problem
-
2)
Assumptions of the fuzzy prioritization method
-
3)
Solving the fuzzy prioritization problem that has survived as follows:
In a decision making problem with n elements, decision maker provides a set of of m ≤ n (n - 1) / 2 pairwise comparison judgments, where i = 1, 2, …, n - 1, j = 2, 3, …, n, j > i, represented as triangular fuzzy numbers . A crisp priority vector w = (w1, w2, …, w n ) could reach from the problem with the fuzzy condition as follows:
where the symbol denotes ‘fuzzy equal or less than’ and with a membership function of inequality shown as follows:
There are two main assumptions that the solution of prioritization is based on. The first one is the existence of non-empty fuzzy feasible area P on the (n - 1) dimensional simplex Qn - 1:
where the membership function of the fuzzy feasible area is given by:
The second one is a priority vector that is selected with having the highest degree of membership in the aggregated membership function (4).
The maximum decision rule from the Game Theory is used to solve the fuzzy prioritization problem. The maximum prioritization problem (5) is extended as follows:
subject to:
With regard to the membership function (2), problem (6) can be transferred into another form that is shown as follows:
The non-linear problem (7) will be optimized where λ = λ* and W = W*, and the fuzzy judgment will be satisfied if the λ* is positive. Also, it can be applied as the consistency measure of the initial set of fuzzy judgments. When the value of λ* is negative, the solution ratios approximately satisfy all double-side inequalities (1), that means, the fuzzy judgments are inconsistent. To obtain the time-dependent principal eigenvector, W* should be calculated for different values of time Nt. These eigenvectors (W*) are used to generate a curve that shows the alternative priority in each period. The alternative curves are gathered in a graph that could help DMs to select the best option.
Results and discussion
Procedure of segment-strategy selection
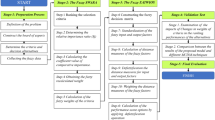
In this section, a procedure for segment-strategy selection is developed in ten steps to select the best potential segment with its strategies by considering an acceptable risk and in five competitive forces factors which have been developed by Porter (1980). According to this procedure, the market segments and strategies are selected in two main modules of a decision support system. In the first step, the risk amount is assigned by SPACE matrix method, and the segments are filtered based on special acceptable risk level which has been defined by DMs. In the second step, there are some segments which come from the first step. For every segment, some strategies are defined according to their position on SPACE matrix. DNP method in fuzzy environment has been applied to rank the segment-strategies.
Regarding this model, DM will be able to select the segments that have more chance of success according to their risk amount and to select proper strategies in each segment with competitive conditions. These steps are defined as follows:
Step 1. Segment filtering based on risk amount
-
1
Develop appropriate factors based on SPACE dimensions including internal perspectives (FS and CA) and external perspectives (ES and IS)
-
2
Assign relevant scores for each factor of segments and compute the total score in each dimension (internal and external); then, trace the position of each segment on SPACE graph
-
3
Assign a proper risk level for each segment and omit the segments which are out of the acceptable risk level (ARL)
-
4
Define feasible strategies for each segment and make a list of segment-strategy
Step 2. Select the best segment-strategy
-
1
Develop proper factors to choose the best segment-strategy, considering the vision statement
-
2
Compare factors for each alternative by considering the time variation and determine the effect of factors on each other
-
3
Calculate the score by FDNP for each segment-strategy according to the five competitive force factors
-
4
Make a discussion based on the score and choose the best segment-strategy
A case study is illustrated to select an optimum segment-strategy for a special coffee product in Iran market with regard to the procedure that was introduced before. While coffee is not technically a commodity, coffee is bought and sold by roasters, investors, and price speculators as a tradable commodity insofar as coffee has been described by many, including historian Pendergrast (1999), as the world's ‘second most legally traded commodity’. Decaffeination is the act of removing caffeine from coffee beans. As of 2009, progress towards growing coffee beans that do not contain caffeine is still continuing (Mazzafera et al. 2009). Consumption of decaffeinated coffee appears to be as beneficial as caffeine-containing coffee in regard to all-cause mortality, according to a large prospective cohort study (Brown et al. 1993). Decaffeinated products are produced in a coffee firm in Iran as a special product that can be put into the narrow markets from a demand perspective, particularly in the Middle East area. In Middle East, tea is a more popular beverage than coffee. This decreases the demand of coffee as a substitute product (especially decaffeinated coffee which has not existed before) in comparison with tea.
To focus on a special part of the market to increase competitiveness, a committee defines five segments (Table 5) to develop decaffeinated coffee around the Middle East. This committee includes business and market experts which have more than eight years of experience in sales or marketing in the Middle East. This committee consists of six managers within the company, who are professional in market with high experience in strategy development. All data have been collected by a team of market research experts to present to the committee to evaluate and segment the market, define and select factors and sub-factors, develop strategies, and execute pairwise comparisons in the decision-making process.
Segment filtering based on risk amount
Definition of segment positions
After developing the appropriate factors based on SPACE dimensions, DMs assign a relevant score to each sub-factor for each segment (Table 6).
The scores should be between 0 to 6, where 6 indicates the best condition and 0 indicates the worst for positive factors (financial strength and industry strength) and vice versa for negative factors (environmental stability and competitive advantage). For example, the amount of product distribution power (CA5) which is a sub-factor of competitive advantage as a negative factor is 1 in S5, which means there are suitable conditions to distribute the products in S5 in comparison with the competitors. On the other hand, the amount of Profitability (IS3) as a positive factor of industry strength is 6 in S1, which means there are suitable conditions to produce the product with high profitability in S1 in comparison with other products in the other segments. According to these scores, total scores are calculated in each dimension of SPACE matrix using (8) and (9). The position of each segment is traced on SPACE graph according to the obtained pairs. It could assign a proper risk amount to each segment. Segment filtering will be done according to the assigned risk amounts and by a certain acceptable risk level.
( x j, yj) shows the position of segment j, where x and y are horizontal and vertical dimensions of the SPACE matrix, respectively. These pairs are calculated based on the sub-factor scores in two dimensions, where x is calculated by (8) and y by (9).
The position of each segment has been calculated based on the sub-factor scores:
The position of S1 is (2,1), and in this way, other positions are calculated as follows:
Definition of risk levels
Different points on SPACE matrix show the success possibility of each segment that is considered as risk amount of segments. The most possibility occurs when financial strength and industry strength get the most score as positive factors, and environmental stability and competitive advantage get the lowest score as negative factors. So, the pair (6, 6) has the most success possibility with lowest risk amount in the SPACE matrix, and the pair (-6,-6) has the most risk amount. Risk of other points is defined based on their distance from (6, 6). The surface of the SPACE matrix is separated into five areas according to the distance from the best point. These areas are defined by radiuses which have been calculated based on fuzzy approach. It means that the Euclidean distance from the worst and the best points has been separated into five sections according to the linguistic values and the mean of fuzzy numbers (Table 3 and Figure 5). Thus, the Euclidean distance of each segment from the best point towards the worst point can show a level of risk.
Let (xj, yj) show the position of segment j. Let (X, Y) show the best position, and (X′, Y′) show the worst position in a SPACE graph. The risk amount of (xj, yj) is defined based on its Euclidean distance proportion that is showed as follows:
Euclidean distance proportions of all positions are calculated by (10). It helps assign linguistic variables to each position according to Table 7.
Euclidean distances and proper risk of each segment was calculated as shown in Table 8 and Figure 6. ARL is defined to filter segments according to ability of risk acceptance of DMs. In this case, low risk level is considered as maximum ARL; it means that segments with risk level higher than low are rejected. Thus, S1 and S2 are selected to define proper strategies, and S3, S4, and S5 are rejected because of their high risk levels.

Fuzzy risk definition model by SPACE graph. The success possibility shown by the spectrum (the best situation is shown as green, and the worst situation as red). VH, very high; H, high; M, medium; L, low; VL, very low.
Strategy definition
Strategy definition is done by SPACE matrix. Generic strategies of SPACE matrix are defensive, aggressive, conservative, and competitive which could be broken into the main strategies. In this case, aggressive and conservative strategies are suitable for S2, and aggressive strategies for S1. The two main strategies were defined for S2 from two different views: the first one is ‘putting decaffeinated coffee in old basket’ as conservative strategy, and the second one is ‘A new basket of decaffeinated coffee products with decaffeinated coffee stores development’ as aggressive strategy. The aggressive strategy that was defined for S1 is ‘A new basket of decaffeinated coffee and decaffeinated coffee stores development’.
Select the best segment-strategy
The five competitive forces model is a common tool used in analyzing and supporting the competitive strategic management in competitive markets. Porter (1980) developed these forces that model every single industry and market, and help DMs analyze industry competition for profitability and attractiveness. The five force factors and sub-factors in Porter's model, which are determined by the committee, are shown in Table 9.
Factors and sub-factors of Porter's (1980) five forces model are applied as decision criteria to select the best segment-strategy. FDNP is implemented to rank the segment-strategies. This method can consider all inner dependency effects among factors and sub-factors over time. Using the factors and sub-factors, a decision tree is made to rank the segment-strategies (Figure 7). The decision tree includes four levels. The first level is the decision making (choosing the best segment-strategy). The second comprise the factors and sub-factors; the third level includes the problem criteria. The fourth level consists of the alternatives.

The proposed ANP model for measuring segment-strategy level.
The local weights of the factors are calculated by a useful method that Saaty and Takizawa (1986) and Saaty (1996) presented and developed in fuzzy prioritization approach. These are the fuzzy comparison values presented in Table 10.
The non-linear programming presented as follows resulted from pairwise comparisons and was solved using the LINGO 11 (2008) software (Lindo Systems Inc., Chicago). The other weights were calculated using the same approach for each pairwise comparison matrix.
Maximize = λ
Subject to:
The effects of the interdependency among the five force factors are shown in Figure 8. The inner dependency matrix is presented in Tables 11, 12, and 13, which was defined by the expert committee to obtain the local weights of the factors.

Network framework of the five forces.
The vectors of the inner dependency weight of the factors (Tables 11, 12, and 13) are normalized to find the degree of relative impact matrix (Table 14). The final weights of the factors (wFactors) are calculated by multiplying the normalized degree matrix (Table 14) with the local weight of the factors that had been calculated before in Table 10.
In the next step, the pairwise comparisons of the sub-factors should be done with respect to each factor to calculate the local weights and global weights. Tables 15, 16, 17, 18, and 19 show the pairwise comparisons of the sub-factors and their calculated weight for each sub-factor. To calculate the global weights of each sub-factor, their calculated local weights should be multiplied with the weight of each factor directly (Table 20).
To obtain the priority of the alternatives, the alternatives are compared with respect to each sub-factor. These comparisons should be done for each time period of the planning horizon. To make a better decision, considering the facts like ‘changing future conditions’ ‘more preferred business in each time period’ and ‘changing the priority of each factor or its sub-factors’ are very important. The certain planning horizon is dependent on the strategies that the company applied to launch a product in the market. It could be considered as the product life cycle that is planned for a certain time in a certain area. In this case, 5 years of planning horizon are considered to compare the alternatives considering the sub-factors and future changes of alternative priorities. Table 21 shows the final priorities of the alternatives regarding the importance of each strategy that is planned for each segment on the specific periods. As shown in Figure 9, it is clear that the priority of segment1-startegy1 is preferred over the others at first, although its priority is decreased during the planning horizon. In the end, segment2-startegy2 becomes more interesting than the others. On the other hand, results show that the priority of segment2-startegy2 is preferred almost after 1 year; thus, it could be selected for a long-term strategic planning.

The numerical estimate for weight of each segment-strategy. Broken line, dotted line, and the solid line denote the weights of ‘segment2-strategy2’, ‘segment1-strategy1’, and ‘segment2-strategy1’ over time, respectively.
Conclusion
The purpose of the current study is to provide a modular decision support system to determine the best marketing strategy with an acceptable risk. This DSS helps companies to select appropriate segments to develop their business while they can care about their risk. Also, they can consider the effects of the strategies in their success based on priorities which may be changed over time. Two modules have been developed in this study: the first one used the SPACE matrix to allocate the risk to each segment, and the second one used FDNP method to monitor the segment-strategies over time and select the best one accordingly.
In the first module, segments have been evaluated based on the four main factors (and their sub-factors) of the SPACE matrix, and their risk have been calculated according to their success possibility. Then, the segments have been filtered with regard to their risk level which had been defined using the fuzzy approach. This method helps managers to take their acceptance risk level into consideration and leads DMs to select segments with their reasonable risk levels. Moreover, the SPACE matrix helps managers define proper strategies, too. Filtered segments help them have more suitable alternatives in the decision-making process.
In the second module, the five forces model of Porter (1980) has been developed in a decision-making process to select the best segment-strategy. Because of the changing conditions in the market and the decreasing or increasing attractiveness of the alternatives, the alternative priorities are changed over time, so the FDNP is developed to consider the variation of segment priorities. As it is clear in the numerical results, time variation could affect the DMs' decision. The priority of segment1-startegy1 is more preferred over the others at first, although its priority decreased during the planning horizon. In the end, segment2-startegy2 becomes more interesting than the others. On the other hand, results show that the priority of segment2-startegy2 is more preferred almost after 1 year; thus, it could be selected for a long-term strategic plan.
Market segmentation is one of the most important issues in marketing process of industries such as food, dairy, beverage, home care, etc. In this process, risk consideration is very essential because it may have big effects on the expected results. The proposed method in this paper could mitigate this risk by bringing the risk into calculation, and it could be applied to mitigate risk consequences. Using this method, DM could filter its alternative and will not count on segments which are in high risk space. As a result, DM will not select strategies based on high risk segments, and the company could lead its investment to the most secure space. As shown in the results, segment 5 (S5) has the maximum risk of selection because in this segment, environment stability is weaker than the other potential segments. Hence, disregarding risk factors and selecting S5 as a potential segment, the company will enter an unstable market. In this way, the other steps of strategy definition such as distribution channels, pricing, and long-term and short-term strategies will undergo selected market instability. So, disregarding the risk effects could lead a business to the spaces which can decrease the possibility of success.
On the other hand, for each segment, a special strategy could be developed while the importance of each segment-strategy has its special trend over time. Practically, when a company is going to invest on segment-strategy, it should have a serious attention on the long-term results of its decision. In this condition, having a good view on the trend of segment-strategy importance could help DMs make effective decisions over time. In considering this issue, the developed FDNP method of this paper could be applied. The application of this method in industries will be more significant when they have marketing strategies such as pricing, distribution channels, and promotion in their appropriate segment.
Considering the risk amount and competitive factors with their effects on each other will drive the company to be more successful. Analysis effects of these strategies to decrease risk amount could be helpful in making a better and more complete decision merits future research.
Authors’ information
AMN received his MSc from the Industrial Engineering Department of K. N. Toosi University of Technology of Iran. He has work experience in automotive and food production companies. Now, he is working in the PSIG Co. as Business Development Manager. His research interests are project portfolio selection, strategic management, market segmentation and multi-attribute decision making, supply chain management, and risk management. MHH received his MSc from the Industrial Engineering Department of Islamic Azad University of Qazvin. He has work experience in automotive, food and FMCG production companies. Now, he is working in Unilever Company as a demand planner. His research interests are project portfolio selection, strategic management, market segmentation, and multi-attribute decision making. SE is an assistant professor of operation research in the Islamic Azad University, Karaj Branch. He received his PhD in Operation Research and Operation Management from Science and Research Branch of the Islamic Azad University (SRBIAU), MSc from Amirkabir University of Technology (Tehran Polytechnic), and BS from Iran University of Science and Technology. His research interests include risk management, construction projects selection, fuzzy MADM, scheduling, mathematical programming, shortest path networks, and supply chain management.
References
Aaker DA: Strategic market management. New York: Wiley; 1995.
Aghdaie MH, Zolfani SH, Rezaeinia N, Mehri-Tekmeh J Paper presented at the international conference on management and service science, Wuhan, China, 12–14 August 2011. A hybrid fuzzy MCDM approach for market segments evaluation and selection 2011.
Albert TC: Need-based segmentation and customized communication strategies in a complex-commodity industry: a supply chain study. Ind Market Manag 2003,32(4):281–290. 10.1016/S0019-8501(02)00204-3
Bharadwaj SG, Varadarajan PR: Sustainable competitive advantage in service industries: a conceptual model and research propositions. J Market 1993,57(4):83–99. 10.2307/1252221
Bock T, Uncles M: A taxonomy of differences between consumers for market segmentation. IJRM 2002,19(3):215–224.
Bonoma TV, Shapiro BP: Segmenting the industrial market. Lexington: Lexington Books; 1983.
Brown CA, Bolton-Smith C, Woodward M, Tunstall-Pedoe H: Coffee and tea consumption and the prevalence of coronary heart disease in men and women: results from the Scottish Heart Health Study. J Epidemiol Commun H 1993,47(3):171–175. 10.1136/jech.47.3.171
Buckley JJ: Fuzzy hierarchical analysis. Fuzzy Set Syst 1985,17(3):233–247. 10.1016/0165-0114(85)90090-9
Chang DY: Applications of the extent analysis method on fuzzy AHP. Eur J Oper Res 1996,95(3):649–655. 10.1016/0377-2217(95)00300-2
Cheng CH: Evaluating naval tactical missile systems by fuzzy AHP based on the grade value of membership function. Eur J Oper Res 1997,96(2):343–350. 10.1016/S0377-2217(96)00026-4
Clarke AH, Freytag PV: An intra- and inter-organisational perspective on industrial segmentation: a segmentation classification framework. Eur J Marketing 2008,42(9):1023–1038.
Coughlan AT, Soberman DA: Strategic segmentation using outlet malls. IJRM 2005,22(1):61–86.
Dağdeviren M, Yüksel I: A fuzzy analytic network process (ANP) model for measurement of the sectoral competition level (SCL). Expert Syst Appl 2010,37(2):1005–1014. 10.1016/j.eswa.2009.05.074
Day GS, Wensley R: Assessing advantage: a framework for diagnosing competitive superiority. J Market 1988,52(2):1–20. 10.2307/1251261
Deng H: Multicriteria analysis with fuzzy pairwise comparison. Int J Approx Reason 1999,21(3):215–231. 10.1016/S0888-613X(99)00025-0
Dickson PR: Marketing management. Orlando: The Dryden Press; 1993.
Dincer O: Strategy management and organization policy. Istanbul: Beta Publication; 2004.
File KM, Prince RA: A psychographic segmentation of industrial family businesses. Ind Market Manag 1996,25(3):223–234. 10.1016/0019-8501(95)00080-1
Freytag PV, Clarke AH: Business to business market segmentation. Ind Market Manag 2001,30(6):473–486. 10.1016/S0019-8501(99)00103-0
Goller S, Hogg A, Kalafatis S: A new research agenda for business segmentation. Eur J Marketing 2002,36(1):252–272.
Hunt SD, Arnett DB: Market segmentation strategy, competitive advantage, and public policy: grounding segmentation strategy in resource-advantage theory. AMJ 2004,12(1):7–25.
Jenkins M, McDonald M: Market segmentation-organizational archetypes and research agendas. Eur J Marketing 1997,31(1):17–32. 10.1108/03090569710157016
Kahraman C, Ruan D, Tolga E: Capital budgeting techniques using discounted fuzzy versus probabilistic cash flows. Inform Sci 2002,142(1–4):57–76.
Kahraman C, Ruan D, Doğan I: Fuzzy group decision-making for facility location selection. Inform Sci 2003, 157: 135–153.
Kahraman C, Ertay T, Buyukozkan G: A fuzzy optimization model for QFD planning process using analytic network approach. Eur J Oper Res 2006,171(2):390–411. 10.1016/j.ejor.2004.09.016
Keufmann A, Gupta MM: Introduction to fuzzy arithmetic: theory and application. New York: VanNostrand Reinhold; 1991.
Klir GJ, Yuan B: Fuzzy sets and fuzzy logic: theory and applications. New Jersey: Prentice-Hall; 1995.
Kotler P: Marketing management: analysis, planning, implementation, and control. 9th edition. Upper Saddle River, NJ: Prentice Hall International; 1997.
Kuo RJ, Ho LM, Hu CM: Integration of self-organizing feature map and K-means algorithm for market segmentation. Compu Oper Res 2002,29(11):1475–1493. 10.1016/S0305-0548(01)00043-0
Leung LC, Cao D: On consistency and ranking of alternatives in fuzzy AHP. Eur J Oper Res 2000,124(1):102–113. 10.1016/S0377-2217(99)00118-6
LINGO 11,: Optimization modeling software for linear, nonlinear, and integer programming. Chicago: Lindo Systems Inc.; 2008.
Liu Q, Serfes K: Market segmentation and collusive behavior. Int J Ind Organ 2007,25(2):355–378. 10.1016/j.ijindorg.2006.05.004
Liu Y, Ram S, Lusch RF, Brusco M: Multicriterion market segmentation: a new model, implementation, and evaluation. Market Sci 2010,29(5):880–894. 10.1287/mksc.1100.0565
Lu CS: Market segment evaluation and international distribution centers. Transpor Res E-Log 2003,39(1):49–6. 10.1016/S1366-5545(02)00022-4
Mazzafera P, Baumann TW, Shimizu MM, Silvarolla MB: Decaf and the steeplechase towards decaffito-the coffee from caffeine-free Arabica plants. Trop Plant Biol 2009,2(2):63–76. 10.1007/s12042-009-9032-7
Meade LM, Sarkis J: Analyzing organizational project alternatives for agile manufacturing processes: an analytical network approach. Int J Prod Res 1999,37(2):241–261. 10.1080/002075499191751
Mikhailov L: A fuzzy programming method for deriving priorities in the analytic hierarchy process. J Oper Res Soc 2000,51(3):341–349.
Mikhailov L: Deriving priorities from fuzzy pairwise comparison judgments. Fuzzy Set Syst 2003,134(3):365–385. 10.1016/S0165-0114(02)00383-4
Montoya-Weiss M, Calentone RJ: Development and implementation of a segment selection procedure for industrial product markets. Market Sci 2001,18(3):373–395.
Nakip M: Segmenting the global market by usage rate of industrial products: heavy-user countries are not necessary heavy users for all industrial products. Ind Market Manag 1999,28(2):177–187. 10.1016/S0019-8501(98)00015-7
Ou CW, Chou SY, Chang YH: Using a strategy-aligned fuzzy competitive analysis approach for market segment evaluation and selection. Expert Syst Appl 2009,36(1):527–541. 10.1016/j.eswa.2007.09.018
Pendergrast M: Uncommon grounds: the history of coffee and how it transformed our world. New York: Basic Books; 1999.
Phillips JM, Reynolds TJ, Reynolds K: Decision-based voter segmentation: an application for campaign message development. Eur J Marketing 2010,44(3–4):310–330.
Porter M: Competitive strategy: techniques for analyzing industries and competitors. New York: The Free Press; 1980.
Ray S: Strategic segmentation of a market. Int J Ind Organ 2000,18(8):1279–1290. 10.1016/S0167-7187(98)00052-6
Rowe H, Mason R, Dichel K: Strategic management and business policy: A methodological approach. MA: Addison-Wesley; 1982.
Ren Y, Yang D, Diao X: Market segmentation strategy in internet market. Physica A 2010, 389: 1688–1698. 10.1016/j.physa.2009.11.023
Saaty TL: The analytic hierarchy process. New York: McGraw-Hill; 1980.
Saaty TL: Decision making with dependence and feedback: the analytic network process. Pittsburgh: RWS Publications; 1996.
Saaty TL: Time dependent decision-making, dynamic priorities in the AHP/ANP: generalizing from points to functions and from real to complex variables. Math Comput Model 2007,46(7–8):860–891.
Saaty TL, Takizawa M: Dependence and independence: from linear hierarchies to nonlinear networks. Eur J Oper Res 1986,26(22):229–237.
Sausen K, Tomczak T, Hermann A: Development of a taxonomy of strategic market segmentation: a framework for bridging the implementation gap between normative segmentation and business practice. J Strat Market 2005,13(3):151–173. 10.1080/09652540500171340
Shani A, Reichel A, Croes R: Evaluation of segment attractiveness by risk-adjusted market potential. J Trav Res 2012,51(2):166–177. 10.1177/0047287510396100
Söllner A, Rese M: Market segmentation and the structure of competition: applicability of the strategic group concept for an improved market segmentation on industrial markets. J Bus Res 2001,51(1):25–36. 10.1016/S0148-2963(99)00043-0
Tolga E, Demircan ML, Kahraman C: Operating system selection using fuzzy replacement analysis and analytic hierarchy process. Int J Prod Econ 2005,97(1):89–117. 10.1016/j.ijpe.2004.07.001
Tsai MC, Tsai YT, Lien CW: Generalized linear interactive model for market segmentation: the air freight market. Ind Market Manag 2011,40(3):439–446. 10.1016/j.indmarman.2010.06.001
Tsai MC, Yang CW, Lee HC, Lien CW: Segmenting industrial competitive markets: an example from air freight. J Air Transp Manag 2011, 17: 211–214. 10.1016/j.jairtraman.2011.01.001
Varadarajan PR, Cunningham MH: Strategic alliances: a synthesis of conceptual foundations. J Market 1995,23(4):282–296.
Xia Y: Competitive strategies and market segmentation for suppliers with substitutable products. Eur J Oper Res 2011, 210: 194–203. 10.1016/j.ejor.2010.09.028
Zadeh LA: Fuzzy sets. Inform Contr 1965,8(3):338–353. 10.1016/S0019-9958(65)90241-X
Zadeh LA, Klir GJ, Yuan B: Fuzzy sets, fuzzy logic, fuzzy systems. Hackensack: World Scientific Press; 1996.
Acknowledgments
The authors are thankful for the support of the Multicafe Co. for the research process of Iran coffee market and segment-strategies definition. The anonymous reviewers are acknowledged for their constructive comments as well as the editorial changes suggested by the language editor, which certainly improved the presentation of the paper.
Author information
Authors and Affiliations
Corresponding author
Additional information
Competing interest
The authors declare that they have no competing interests.
Authors’ contributions
MHH managed the segment-strategies development process including holding the meeting of managers' committee to gather the market information. AMN, MHH, and SE proposed the decision making process including risk mitigation approach and developed the dynamic network process via five forces model. AMN developed the fuzzy DNP to calculate the weight of factors and alternative, and the calculations by Lingo11. SE managed and supported the team to provide the steps. He also modified the process. All authors read and approved the final manuscript.
Authors’ original submitted files for images
Below are the links to the authors’ original submitted files for images.
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 2.0 International License ( https://creativecommons.org/licenses/by/2.0 ), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
About this article
Cite this article
Mohammadi Nasrabadi, A., Hosseinpour, M.H. & Ebrahimnejad, S. Strategy-aligned fuzzy approach for market segment evaluation and selection: a modular decision support system by dynamic network process (DNP). J Ind Eng Int 9, 11 (2013). https://doi.org/10.1186/2251-712X-9-11
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/2251-712X-9-11