
Abstract
Received signal strength (RSS) can be used in sensor networks as a ranging measurement for positioning and localization applications. This contribution studies the realistic situation where neither the emitted power nor the power law decay exponent be assumed to be known. The application in mind is a rapidly deployed network consisting of a number of sensor nodes with low-bandwidth communication, each node measuring RSS of signals traveled through air (microphones) and ground (geophones). The first contribution concerns validation of a model in logarithmic scale, that is, linear in the unknown nuisance parameters (emitted power and power loss constant). The parameter variation is studied over time and space. The second contribution is a localization algorithm based on this model, where the separable least squares principle is applied to the non-linear least squares (NLS) cost function, after which a cost function of only the unknown position is obtained. Results from field trials are presented to illustrate the method, together with fundamental performance bounds. The ambition is to pave the way for sensor configuration design and more thorough performance evaluations as well as filtering and target tracking aspects.
Similar content being viewed by others
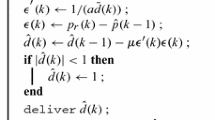

1 Introduction
Target localization based on the target's emitted energy is an attractive option in large, wireless sensor networks:
-
Simple and passive (no energy output) sensors like microphones and geophones can be used.
-
Requirements on network synchronization are moderate.
-
Data fusion requires limited communication bandwidth.
By sampling the energy as a measure of the Received Signal Strength (RSS) at geographically distributed locations and by modeling the energy decay as a function of target-sensor distance, the location of the target can be inferred. This paper focuses on centralized acoustic and seismic source localization, which is interesting to use as a part of surveillance systems for power plant protection, airport security, border control, and similar. However, the models and algorithms are applicable to general target localization based on emitted energy from the target.
Energy source localization is in focus here, but the reverse problem of navigation of one sensor ("sink") from several beacons ("sources") with known position is also covered by reversing the role of emitters and sensors. Therefore, the object to be located will be referred to as the target in this paper. An underlying assumption is that communication constraints between the sensor units make any algorithm based on the signal waveform (like coherent detection) infeasible. Communication only allows for sending RSS measurements to other sensor units.
Localization from received signal energy is of course a fairly well-studied problem, see the surveys [1–3] and the papers [4, 5], though the major part of literature addresses the related problem of localization from time of arrival (TOA) and time-difference of arrival (TDOA) measurements. Also, the standard localization application concerns radio networks, but localization in acoustic networks bears much in common. While TOA measures range and TDOA range differences computed from propagation time, energy-based localization utilizes the power decay of the involved signals.
Based on the distance power law model, the received root mean square (RMS) signal power expressed in decibels (dB) is assumed to be proportional to the logarithm of distance, and this is the main difference to time-based localization approaches. Dedicated approaches to this problem assume that the constant of proportionality (power law decay exponent) is known [4–6] or include the energy measurements as a general non-linear relation [3]. Several ad hoc methods to eliminate nuisance parameters have been proposed in this context, including taking pairwise differences or ratios of observations.
A least squares solution for energy-based methods can be found in [4], in which the power law model is verified. However, no investigations regarding proper noise models were conducted. Maximum-likelihood (ML) estimators are considered in [6, 7] based on the same power law model, but with a fixed and known power law decay exponent. The same holds for [8], but the focus is on least squares based approaches. These works consider a centralized situation, where all measurements are processed at the same location. Distributed ML is addressed in [9], where the authors consider both the power law decay exponent and source energy as unknowns.
In [7], an approach to localization based on a model in linear energy scale is presented, where the power law decay exponent is fixed to -2. In [10, 11], a similar model was used, but in logarithmic energy scale. The model is referred to as the log range linear model, where all environmental parameters including power law decay exponent appear linearly. This is of course a great advantage in estimation. The first purpose of this contribution is to use measurements from extensive field tests to validate the log range linear model.
The second contribution is to extend the theory of RSS based localization using an approach where the power law decay exponent and emitted power are explicitly removed from a set of RSS measurements using the separable least squares principle, after which the resulting problem is non-linear in target state parameters only. This leads to a standard low-dimensional nonlinear least squares (NLS) problem, where efficient numerical algorithms exist. Algorithms of different complexity and performance are outlined for this framework. Tracking algorithms are also described, which are based on stating the localization NLS problem formulation as the measurement relation in an extended Kalman filter.
The fundamental performance bound implied by the Cramér-Rao lower bound enables efficient analysis of sensor network architecture, management, and resource allocation. This bound has been analyzed thoroughly in the sensor network literature, primarily for TOA, TDOA, and angle-of-arrival (AOA), [1–3], but also for RSS [12, 13] and with specific attention to the impact from non-line-of-sight [14, 15]. The non-line-of-sight signal propagation is also related to multipath signal propagation, where the signal is reflected and is received as multiple copies, essentially as multiple non-line-of-sight signals replicas. Numerical explicit algorithms and Cramér-Rao lower bounds (CRLB) for both stationary and moving target are derived for the NLS problem formulation.
In Section 2, the RSS model is introduced and compared first to some previously proposed models and then to some simplified models useful for detection purposes. Section 3 validates the model and its assumptions using extensive field tests with acoustic and seismic signals. Section 4 presents a non-linear least squares (NLS) framework for localization, where the separable least squares (SLS) principle can be used to eliminate nuisance parameters. Localization and tracking algorithms based on this framework are overviewed in Section 5, illustrated with selected results from field trials. Finally, Section 7 concludes the paper.
2 RSS measurement model
It is assumed that the received signal strength (RSS) measured at each sensor is proportional to the target-sensor distance to the power of a constant or a parameter, the distance power law. For a motivating example, the signal from a microphone (measured in Volts) is ideally proportional to the sound pressure (in Pascal), which in turn decays inversely proportional to the sound source distance. This holds for punctual sources and free-space propagation. By identifying the RSS with the mean square of the received signal, the decay (for punctual sources in free space) is thus expected to decay inversely proportional to the distance square. However, in the non-ideal case, factors like reflection, diffraction, and refraction influence the RSS decay in a way that generally is difficult or expensive to predict. The approach here is to keep the distance power law for its simplicity, but allow for the decay exponent to adapt to the current situation. Thus, the exponent is considered as an unknown parameter.
We reason analogously in the seismic case, although the seismic wave propagation is even more involved to predict than is the acoustic. The particle amplitude of seismic surface waves (Rayleigh and Love waves) ideally decays inversely proportional to the square root distance, which is in agreement with the distance power law, although distinct from the acoustic case.
The acoustic and seismic distance power laws with unknown exponents will here be validated on data collected in fairly open terrain. Generally, the distance power law is probably too simplistic to work well in dense urban environments, where the RSS results from a superposition of multiple wave reflections with different path distances. The urban non-line-of-sight case will, however, not be treated in this text.
The RSS value itself is here computed by a first optional pre-filtering step of the raw sensor signal, then an averaging of the squared magnitude over a time window to obtain a down-sampled signal. The signals are typically sampled with 1-4 kHz, and the final RSS value is obtained with one or a few Hz sampling frequency. The pre-filter only passes signals in frequency bands of interest in the application, and the averaging reduces the variations in the RSS estimates.
2.1 Notation
The following notation will be used throughout the paper:
-
The sensor network consists of M sensor nodes. These are located at p m , where m is used for sensor index.
-
Each sensor node is equipped with several different sensors, and i indicates the sensor types. In the field tests, i = 1 corresponds to a microphone and i = 2 to a geophone.
-
There is one moving target with position x n at time n. There are N time instants in each experiment.
-
y i,n,m is the received energy, RSS, at sensor node m, observed by sensor type i, and averaged over time window n.
-
e i,n,m is additive noise with variance .
-
θ1,i,ndenotes the reference received energy for sensor type i if it would have been placed 1 m from the target, averaged over time window n.
-
θ2,i,mdenotes the attenuation or measurement error bias of sensor node m at sensor type i.
-
θ3,i,n,mdenotes the power law decay exponent, which may vary with sensor type, time, and space.
-
θ(n, m) = [θ1,n, θ2,m, θ3,n,m]Tgathers the parameters in a parameter vector
A convention is that energy variables are primarily defined in logarithmic energy scale, while a bar on a variable indicates values in linear scale. Hence, .
2.2 Parametric model
The acoustic sensor model proposed in [7] assumes a fixed power law decay exponent and additive noise in linear scale,
while the log range model in [10, 11] (assuming that θ1,i,nis constant over time, and that θ3,i,mis constant over all nodes) has a parametric path loss,
We here investigate a combined and extended model to account both for possible space and time depending parameters,
Note that (3) and (1) are identical in the noise-free case when θ3,n,m= -2 and θ2,m= 0 (no sensor biases).
It is rather obvious that the models above have a limited scope in the range ∥p m - x n ∥. First, when the target distance tends to zero, the models predict infinite RSS (in log scale). Beside saturation in the sensors, there are near-field and other effects that limit the validity for close distances. Second, when the range tends to infinity, the models (2) and (3) both predict negative infinite RSS. For large distances, the background noise will dominate the target signal in these models.
2.3 Simplified models
The problem is primarily to find the target locations x n , n = 1, 2, ..., N. The parameters in θ(n, m) are considered nuisance. Nevertheless, the dimension of θ (n and m omitted for notational simplicity) is 2(M + N + NM) and the number of target coordinate figures, assuming a moving target, is 3N. However, there are only 2NM observations, so without any further assumptions, the system of equations is under-determined, and the localization problem not well defined. The reason for initially describing this over-general model is that it will not only be used for localization, but also for model validation, where a ground truth could be used in place of otherwise unknown figures. Thus, the following sub-models are defined, which all correspond restricted versions of (3):
M0 θ = 0, that is, there is no target-dependent relation at all.
M1 θ3,i,n,m= 0 for all i, n, m. This bias model just compensates for sensor bias and common target energy for all sensors. That is, there is no range dependence of the target.
M2 θ3,i,n,m= θ3,ifor all n,m,i. This log range model assumes that the path loss is a global time-invariant constant.
Of these models, only M2 (with 5N+2M+2 unknowns) can be used for actual localization. M0 and M1 are analyzed to provide a reference to which the M2 performance and accuracy will be compared. Thus, the objective in Section 3 is to validate M2 by showing that it gives significantly better predictions of the measured y i,n,m than M0 and M1. Moreover, even though the models M0 and M1 are not suitable for localization, they can still be useful for target detection, representing the hypothesis that no target is present. The more detailed interpretation is that M0 corresponds to no observed signal and no node-specific bias, and M1 no observed signal, but a node-specific bias.
Introducing the notation
the models can be summarized as
3 Model validation
Before analyzing localization algorithms, the energy decay model will be validated on real data. Our data set contains GPS position of the target, so the relation between RSS and target-sensor distance can be analyzed given known distances.
3.1 LS estimation of θ
The models in (4) are linear in the parameters, so they can be estimated with ordinary linear least squares (LS, see [16]) techniques, provided that the target-sensor distance is known. By stacking the measurements in a column vector y, and similarly for the noise e, the target positions , the sensor node positions and parameters θ, the total model can thus be expressed as a linear regression
For example, model M2 and measurements from two sensor nodes and three time instants give the regressors
The LS solution is given by (see for instance Chapter 2 of [17])
The noise variance is estimated as
where dim(·) denotes vector dimension. The assumption here is that each sensor has the same unknown noise variance σ2. Note, however, that the parameter θ2,itakes care of individual sensor offsets per sensor type caused by for instance wind noise and background disturbances. The root mean square error is defined as . Assuming independent and equal variance noise components at each sensor node and type, the asymptotic covariance matrix for the estimated parameters is
Furthermore, since the noise variance estimate is consistent, we consider the following estimate of covariance matrix for the estimated parameters
The principle for model validation is to use a known network configuration and a known trajectory to estimate the parameters, and as performance indicators compare (i) the model residuals , (ii) the parameters with their respective confidence intervals, and the (iii) obtained RMSE for each model.
3.2 Single sensor experiments
The purpose of the first experiment is to validate the log range model under ideal conditions, where a vehicle follows a straight path and passes a single sensor node. The scenario is depicted in Figure 1, and then in addition to a microphone, the sensor node also contains a geophone for seismic signals.

Field trial setup for sensor model validation.
The positions of the vehicle and sensor are known perfectly in this experiment.
Figure 2 visualizes RSS as a function of the vehicle position x along the road, where the origin is defined as the closest point to the sensor. Results from both the microphone and the geophone are presented for comparison.

RSS in linear scale at the microphone and the geophone, respectively.
Figure 3 illustrates the same data, but with RSS as a function of range in logarithmic scale, together with the straight line adapted by the model in (4e). For example, the estimated power law exponent at the specific field trial environment is θ3 = -2.3 for the microphone (and θ3 = -2.6 for the geophone).

RSS in log scale together with a fitted linear relation as modeled in (5).
The results and conclusions from these figures, which are also supported by data from the sensor network field trials in Section 3.3, are as follows:
-
Figure 2 indicates that the microphone is subject to more noise or rather variations than the geophone, provided that the proposed models are relevant. The variations are probably due to wind gusts as well as fading effects when the ground reflected wave interferes with the line-of-sight wave. Such fading effects have been analyzed thoroughly for radio channel using the two-ray model, see for example [18].
-
Figure 2 indicates that the RSS is slightly skewed and more energy is received when the vehicle is moving away from the sensor compared to when it is moving toward the sensor at the same distances from the sensor. This is explained by the fact that there is more sound coming from the back of the vehicle, the exhaust pipe end, compared to the front.
-
Figure 3 shows that the RSS is linearly dependent of the log range, which verifies model M2. There is a slight near-field effect for the microphone, in that the RSS value saturates for short distances.
-
From Figure 3, the noise contribution as well as the fading effects appears fairly independent of range in logarithmic scale, which would confirm the assumption that noise is additive to the logarithmic RSS measurements.
3.3 Sensor network experiments
Figure 4 shows the sensor network layout when gathering our evaluation data. In total, M = 12 sensor nodes are deployed, each with a microphone and a geo-phone, as indicated in the figure. The sensor node is wireless with capability to store raw sensor data on an on-board storage medium. The geophone is stuck into the round and the microphone is placed some 10 cm above the ground level. The sampling rate for the microphone is 4 kHz, and for the geophone 1 kHz. Two different vehicles run one at a time along the track at a constant speed of 30 km/h (19 miles/h):

Sensor node locations '+' and sample trajectory 'o' for the motorcycle data set.
-
A motorcycle (MC).
-
A four-wheeled all-terrain vehicle (FW).
The two data sets denoted MC and FW contain different number of samples N. Reference positions of the targets are measured with differential GPS (DGPS) with sampling rate 1 Hz.
For least squares estimation, sensor data from the target positions in the time interval (20, 30) seconds are used. This is due to the rapidly decreasing signal quality as a function of range and that the purpose here is sensor model validation rather than tracking. The results and conclusions are as follows:
-
Table 1 shows the RMSE value of the received logarithmic energy for model M0 (raw data), model M1 and model M2, respectively. The RMSE is significantly smaller with log range in the model.
-
Table 2 shows the estimated log range parameter together with its standard deviation (square root of last diagonal element of P θ ). The standard deviation is orders of magnitude smaller than the parameter estimate, indicating an accurate estimate. The conclusion is that no generic constant, as for instance -2, should be used.
-
Figure 5 shows the estimated sensor bias. For instance, microphone number 2 has a significant bias in both data sets. The sensors themselves are factory calibrated, but the deployment may give cause to a systematic difference. These terms also capture individual background noise and line-of-sight/non-line-of-sight issues. That is, the sensor bias term is needed. On the other hand, the time-varying offset is not significantly different from zero and can be neglected for a single target passage.

Estimated sensor bias over time ( θ 1 ,i,n ) and space ( θ 2 ,m ) with sensor one as reference ( θ 1 ,i, 1 = 0). Left column for motorcycle (MC) and right column for four-wheeled ATV (FW), first row for microphones, second row for geophones.
-
Figure 6 shows the spectrum for the sensor signal between 23 and 24 s. Each vehicle seems to have a characteristic signature, with one fundamental frequency, and a lot of harmonics.

Sound spectrum for the two vehicles and two sensors, and the applied band-pass filter. Upper row for microphones, lower row for geophones. Left column for motorcycle (MC) and right column for four-wheeled ATV (FW).
-
The model residuals from both microphones and geophones are illustrated as smoothed histograms in Figure 7 and compared to Gaussian approximations. The Gaussian noise assumption is apparently quite realistic. The noise standard deviation can be set to σ ∈ (2, 3).

Smoothed histograms for all residuals, together with a Gaussian distribution with the same mean and variance.
4 Eliminating nuisance θ
The goal in this section is to eliminate the nuisance parameters θ, including the power law exponent, the emitted energy, and optionally the unknown noise variances σ.
From now on, the focus is on model M2 in (4) only. Furthermore, it is assumed that sensors and target are in the plane (p m , x n ∈ ℝ2), which means that the number of unknowns is 4N+2M+2, provided that 2 sensors per node are used (geophone and microphone). The localization algorithm described here is intended to run in a centralized fashion on a fusion node in the sensor network. For localization, the model is used at one time instant only, so the index n will be dropped for simplicity, so x n = x and N = 1. Extending the LS framework in (5) to also include the target position x gives the nonlinear least squares (NLS) problem
In this section, we assume that the noise variance σ2 is known. Also note that the parameter θ1,i,n, representing time-varying background noise in (4e) is irrelevant in this snapshot formulation, since it cannot be distinguished from the sensor-varying background noise θ2,i,m.
4.1 Separable Least Squares
Using the separable least squares (SLS, see [16]) principle, the environmental nuisance parameters can be eliminated explicitly from (6). The minimizing argument θ in (6a) can be written analytically (assuming that the measurement noise at different sensor nodes is independent) as
where . Note that the parameter estimate depends on the target location x. The matrix R(x) and vector f(x) are introduced in (7a) to get more compact notation in the following. Note also that the matrix R(x) is just a function of sensor geometry and target position. The matrix inversion can be performed analytically to get
With this matrix defined, the covariance matrix is given by
The variance of the model predictor, obtained after plugging in the parameter estimate in the model, is thus given by
This is larger than the measurement error variance σ2 alone.
In order to fit the general estimation and nonlinear filtering framework, the original RSS model in (4) and (4e) can be rewritten by introducing a virtual measurement resulting in a model with additive white Gaussian unity variance measurement errors at each sensor:
with the virtual observations
Note that the real observation y m is seen as a known input, and the virtual observation is always zero. This signal model depends on x only, and the new measurement error is additive white Gaussian with unity variance.
4.2 SNLS formulation
Using (8), (7) is now reformulated as the equivalent separable NLS (SNLS, see [16, 19]) problem
The cost function VSNLS in (9) is similar to the cost function V in (6), except that the model prediction error variance λ m is considered in the former, while the sensor measurement error variance σ2 is considered in the latter. Hence, the new weighting in the sum of least squares accounts for both measurement noise and the estimation uncertainty in the nuisance parameters. Typically, far away sensor nodes m get larger uncertainty in the parameters and thus automatically a smaller weight in the criterion.
4.3 Sensor noise variance estimation
Similar to (5d), the minimum of the sum of least squares can be taken as an estimate of the measurement variance as [20]
where the normalization with N - 2 accounts for the degrees of freedom lost by the minimization and is needed to get an unbiased variance estimate. The last equality is a consequence of the LS theory and will be used in the NLS formulation below.
5 Localization algorithms
In summary, in the previous section, we have derived the SNLS model, which in simplified cleaned up notation can be expressed as
We have here omitted the dependence of the original observation in (12a). Here, is given in (7a), c m (x) in (7d), in (7c), and λ(x) in (7d) (using the measurement variance estimate from (10)). The purpose in this section is to outline possible implementation strategies.
Extensive experiments have been performed to evaluate the potential of the proposed algorithm. Different targets (military and civilian vehicles, pedestrians etc), trajectories and sensor types and node configurations have been tested. We here present some selected results for the MC and FW as described in Section 3.3. The trajectory and sensor node layout are illustrated in Figure 4, where these are overlayed a satellite image, and Figure 8 which shows the two trajectories studied in detail. The sensor observations are downsampled to 2 Hz before estimation, all sensor nodes are carefully calibrated, and the vehicle is equipped with GPS satellite navigation for validation of the performance.

Sensor node locations and sample trajectory for MC and FW, respectively (almost the same trajectories).
5.1 Estimation criteria
The derivation in Section 4 was motivated by NLS. However, the same elimination of nuisance parameters can be applied to more general maximum-likelihood (ML) approaches, with a Gaussian assumption or with other assumptions on sensor error distributions, as summarized in Table 3. These criteria are further discussed in [3].
Figure 9 illustrates the NLS cost as function of target position x for a particular true position xo.

NLS cost function as a function of position for a certain target location indicated with dashed lines in the contour plot and the thick cross in Figure 4.
5.2 Eliminating the Noise Variance
Remember that the noise variance has been assumed to be known in the NLS approach above. To simply use, the estimated variance does not work, since
which is independent of x. The Gaussian maximum-likelihood (GML) approach (see e.g., [16]) can be used to circumvent this problem. Minimizing the GML cost with respect to σ gives a result similar to (9b),
The logarithm intuitively decreases the difference in weighting between the different sensor types compared to the case of known noise variances in (9b).
5.3 Optimization
As in any estimation algorithm, the classical choice is between a gradient and Gauss-Newton algorithm, see [21]. The basic forms are given in Table 4. These local search algorithms generally require good initialization, otherwise the risk is to reach a local minimum in the loss function V(x). Grid-based optimization does not suffer from local minima, and a proposed method is described in Section 5.3.1. However, since such methods may be practically intractable to implement due to memory requirements, we also address gradient calculations in Section 5.3.2. Today, simulation-based optimization techniques (see e.g., [22] for a survey) may also provide an alternative.
5.3.1 Grid-Based optimization
The loss function is evaluated for a set of grid points x(ℓ), which gives a set of loss function samples V(x(ℓ)). A natural approach to loss function minimization is thus to find the grid point corresponding to the lowest loss function sample, i.e.,
However, as indicated by Figure 9, a reasonable local model of the loss function V(x) close to its minimum is a quadratic function:
The matrix P x in the quadratic form coincides with a lower bound on the covariance matrix of the NLS estimate (which for Gaussian noise corresponds to the CRLB). Considering only local grid points that satisfies ∥x(ℓ)-xo∥ ≤ d x , this gives a number of scalar equations
This can be rewritten as a system of linear equations by exploiting the relation
where ⊗ denotes the Kronecker product and vec(P x ) is the vector formed by stacking covariance matrix columns. Hence, (15) can be rewritten as
where and η = [η1, η2, η3]T. Note that some rows of vec(P x ) will be identical since P x is symmetric and duplicates shall therefore be removed from η, as well as corresponding rows of φℓ. This is thus a linear regression resulting in an over-determined system if the number of local grid points are sufficiently large. Least squares provides the solution to (17), from which P x and xocan be derived.
Figure 10 illustrates the localization accuracy when the target passes the network, together with a 90% confidence interval. The confidence interval calculations are based on the estimated covariance matrix P x and an assumption of Gaussian inaccuracies. Both targets give similar results.

NLS for FW and microphone measurements.
5.3.2 Gradient derivation
The gradient H(x) = ∇ x h(v) of the model with respect to the position is instrumental in several loss function minimization algorithms, and it is the purpose here to derive the necessary equations.
First, it is easier to apply the chain rule to the expression
though the result is the same in the end. The gradient is then immediate as
The gradient of the NLS loss function V(x)) becomes a function of the gradients of and λ(x). These are all tedious but straightforward applications of the chain rule, not reproduced here. However, the gradient can be expressed as a closed expression based on the target location x and sensor locations p m .
6 Fundamental bounds
The Fisher Information Matrix (FIM) provides a fundamental estimation limit for unbiased estimators referred to as the Cramér-Rao lower bound (CRLB) [23]. This bound has been analyzed thoroughly in the literature, primarily for AOA, TOA, and TDOA, [1–3], but also for RSS [12, 13] and with specific attention to the impact from non-line-of-sight [14, 15].
In this section, the notation x = (x1, x2)Tis adopted for the two-dimensional coordinates x1 and x2, respectively. The Fisher Information Matrix J(x) is defined as
where p is the two-dimensional position vector and pe(y - h(x)) the likelihood given the error distribution. For the SNLS model 8, J(x) is 2 × 2. Again, the gradient derivations are tedious but symbolic exercises not reproduced here.
Plausible approximative scalar information measures are the trace of the FIM and the smallest eigenvalue of FIM
The former information measure is additive as FIM itself, while the latter is an under-estimation of the information useful when reasoning about whether the available information is sufficient or not. Note that in the Gaussian case with a diagonal measurement error co-variance matrix, the trace of FIM is the squared gradient magnitude.
The Cramér-Rao lower bound is given by
where xodenotes the true position. (22) holds for any unbiased estimate of , although the right hand side is not necessarily attainable. Asymptotically in the number of sensor nodes, the ML estimate is [24] and thus reaches this bound, but this may not hold for finite amount of data.
The right hand side of (22) gives, however, an idea of how suitable a given sensor configuration is for positioning. It can also be used for sensor network design. It should always be kept in mind though that this lower bound is quite conservative and relies on many assumptions.
In practice, the root mean square error (RMSE) is perhaps of more importance. This can be interpreted as the achieved position error in meters. The CRLB implies the following bound:
If RMSE requirements are specified, it is possible to include more and more measurements in the design until (23) indicates that the amount of information is enough.
Figure 11 illustrates how the RMSE lower bound varies for different target positions x. One observation is that the bound is approximately equally good within the area where the sensor nodes are placed. This observation is in line with Figure 10, where the performance within this area is about the same. Such findings illustrate the the use of CRLB analysis of sensor configurations as a means for sensor configuration design

RMSE bound implied by the CRLB and the sensor locations.
7 Conclusions
Conventional received signal strength (RSS)-based algorithms as found in the literature of wireless or acoustic networks assume either that the emitted power is known or that the distance power law exponent is known from calibration. We have considered a network of microphone sensors that is rapidly deployed in an unknown environment where the distance power law exponent is unknown or may vary with time. Also, the emitted power is inherently unknown in the localization and tracking applications under consideration. For localization, both the emitted acoustic energy and the power law exponent are nuisance parameters unique for each target and sensor type, but constant over the sensor nodes.
The nonlinear least squares (NLS) algorithm offers a suitable framework for positioning in this kind of sensor networks, where the RSS measurements suffer from unknown emitted power and where also the environmental path loss constant is unknown. Marginalization of the nuisance parameters using the separable least squares principle leads to a NLS cost function of only two unknowns (horizontal position), where global grid-based methods can be used for minimization. Results from field trials confirm the usability of the proposed method. Hopefully, the provided framework can form a basis for subsequent target tracking and thorough performance evaluations.
References
Patwari N, Hero A III, Perkins M, Correal N, O'Dea R: Relative location estimation in wireless sensor networks. IEEE Trans Signal Process 2003, 51(8):2137-2148. 10.1109/TSP.2003.814469
Gezici S, Tian Z, Giannakis B, Kobayashi H, Molisch A: Localization via ultra-wideband radios. IEEE Signal Process Mag 2005, 22(4):70-84.
Gustafsson F, Gunnarsson F: Possibilities and fundamental limitations of positioning using wireless communication networks measurements. IEEE Signal Process Mag 2005, 22: 41-53.
Li D, Hu Y: Energy-based collaborative source localization using acoustic microsensor array. J Appl Signal Process 2003, 321-337.
Huang Y, Benesty J, Elko B: Passive acoustic source localization for video camera steering. IEEE Conference on Acoustics, Speech and Signal Processing 2000.
Chen L-WHPCM, Liu Z, Zhang Z: Energy-based position estimation of microphones and speakers for ad hoc microphone arrays. Proceedings of of IEEE Workshop on Applications of Signal Processing to Audio and Acoustics, New Paltz, NY 2007.
Sheng X, Hu Y-H: Maximum likelihood multiple-source localization using acoustic energy measurements with wireless sensor networks. IEEE Trans Signal Process 2005, 53(1):44-53.
Meesookho UMC, Narayanan S: On energy-based acoustic source localization for sensor networks. IEEE Trans Signal Process 2008, 56(1):365-377.
Shi Q, He C: A new incremental optimization algorithm for ML-based source localization in sensor networks. IEEE Signal Process Lett 2008, 15: 45-48.
Gustafsson F, Gunnarsson F: Localization in sensor networks based on log range observations. In Fusion 2007. Quebec, Canada; 2007.
Gustafsson F, Gunnarsson F: Localization based on observations linear in log range. In International Federation of Automatic Control (IFAC) World Congress. IFAC, Seoul; 2008.
Koorapaty H: Barankin bound for position estimation using received signal strength measurements. Proceedings of IEEE Vehicular Technology Conference, Milan, Italy 2004.
Qi Y, Kobayashi H: On relation among time delay and signal strength based geolocation methods. Proceedings of IEEE Global Telecommunications Conference, San Francisco, CA 2003.
Qi Y, Kobayashi H: On geolocation accuracy with prior information in non-line-of-sight environment. Proceedings of IEEE Vehicular Technology Conference, Vancouver, Canada 2002.
Qi Y, Kobayashi H: Cramer-Rao lower bound for geolocation in non-line-of-sight environment. Proceedings of IEEE Conference on Acoustics, Speech and Signal Processing, Orlando, FL 2002.
Gustafsson F: Statistical Sensor Fusion. Stu-dentlitteratur, Lund; 2010.
Qi Y, Kobayashi H: Adaptive Filtering and Change Detection. Wiley, Ltd; 2001.
Parsons J: The Mobile Radio Transmission Channel. 2nd edition. Wiley, Ltd., Chichester, England; 2000.
Bjork A: Numerical Methods for Least Squares Problems. SIAM, Philadelphia, USA; 1996.
Ljung L: System Identification, Theory for the User. 2nd edition. Englewood Cliffs, NJ; 1999.
Dennis J Jr, Schnabel B: Numerical Methods for Unconstrained Optimization and non-linear Equations. Prentice-Hall, Englewood Cliffs, NJ; 1983. ser. Prentice-Hall series in computational mathematics
Carson Y, Maria A: Simulation optimization: methods and applications. Proceedings of the Winter Simulation Conference, Atlanta, Georgia 1997.
Kay S: Fundamentals of signal processing-estimation theory. Prentice Hall; 1993.
Lehmann E: Theory of Point Estimation. Wadsworth & Brooks/Cole; 1991. ser. Statistical/Probability series
Acknowledgements
This work is funded by the VINNOVA supported Centre for Advanced Sensors, Multisensors and Sensor Networks, FOCUS, at the Swedish Defence Research Agency, FOI. The authors also want to thank two anonymous reviewers for very detailed comments and suggestions on improvements.
Author information
Authors and Affiliations
Corresponding author
Additional information
Competing interests
The authors declare that they have no competing interests.
Authors’ original submitted files for images
Below are the links to the authors’ original submitted files for images.
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 2.0 International License (https://creativecommons.org/licenses/by/2.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
About this article
Cite this article
Gustafsson, F., Gunnarsson, F. & Lindgren, D. Sensor models and localization algorithms for sensor networks based on received signal strength. J Wireless Com Network 2012, 16 (2012). https://doi.org/10.1186/1687-1499-2012-16
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/1687-1499-2012-16