
Abstract
Background
Leukocoria is defined as a white reflection and its manifestation is symptomatic of several ocular pathologies, including retinoblastoma (Rb). Early detection of recurrent leukocoria is critical for improved patient outcomes and can be accomplished via the examination of recreational photography. To date, there exists a paucity of methods to automate leukocoria detection within such a dataset.
Methods
This research explores a novel classification scheme that uses fuzzy logic theory to combine a number of classifiers that are experts in performing multichannel detection of leukocoria from recreational photography. The proposed scheme extracts features aided by the discrete cosine transform and the Karhunen-Loeve transformation.
Results
The soft fusion of classifiers is significantly better than other methods of combining classifiers with p = 1.12 × 10-5. The proposed methodology performs at a 92% accuracy rate, with an 89% true positive rate, and an 11% false positive rate. Furthermore, the results produced by our methodology exhibit the lowest average variance.
Conclusions
The proposed methodology overcomes non-ideal conditions of image acquisition, presenting a competent approach for the detection of leukocoria. Results suggest that recreational photography can be used in combination with the fusion of individual experts in multichannel classification and preprocessing tools such as the discrete cosine transform and the Karhunen-Loeve transformation.
Similar content being viewed by others

Background
Leukocoria is an abnormal pupillary light reflex that is characterized by a persistent ‘white-eye’ phenomenon during visible light photography. It is often the primary observable diagnostic symptom for a range of catastrophic ocular disorders. In addition, leukocoria is a prevailing symptom of congenital cataracts, vitreoretinal disorders and malformations, retinopathy of prematurity, trauma-associated diseases, Coats’ disease, ocular toxocariasis, Norrie disease, ciliary melanoma, retrolental fibroplasia, and retinal hamartomas [1, 2], see [3] for a review. In children under the age of 5, however, the predominant cause of leukocoria is Rb [4, 5].
In the case of Rb, tumors in the eye can act as diffuse reflectors of visible light [6–9]. Consequently, leukocoria associated with Rb is a progressive symptom that occurs more frequently, during recreational photography, as the size and number of tumors increase [10]. The fact that it occurs in recreational photography opens the door to investigate a way to perform an automatic assessment of visual dysfunction [11]. Leukocoria is optically distinct from specular reflections of the cornea and can be detected with a low resolution digital camera, a camera phone equipped with or without a flash, or with a digital video recorder. In clinical settings, the "red reflex" test is adequate for the identification of tumor reflections when administered by trained clinicians, but may suffer from a high degree of false negatives when conducted under a wide range of conditions [12, 13]. This ineffectiveness of the "red-reflex" test is especially problematic in developing nations where there is a limited supply of properly trained specialists in ophthalmology or pediatrics. Even in developed nations, recent studies suggest that clinicians are either improperly trained for leukocoric screening, or do not perform the test [14]. Indeed, parents or relatives are generally the first individuals to detect leukocoria in a child, and their observation often initiates diagnosis [1, 4, 15–17]. For example, in a study of 1632 patients with Rb, the eventual diagnosis in ∼80% of cases was initiated by a relative who observed leukocoria in a photograph [4].
The consequences of a false negative finding can be profound, as the case of Rb illustrates. While it only comprises 3-4% of pediatric cancer, the incidence of Rb is high enough (i.e., ∼ 1-2:30,000 live births) to mandate universal screening [4, 13]. The median age of diagnosis is 24 months for unilateral disease and 9–12 months for bilateral disease [18, 19]. When detected early, Rb is curable, either by enucleation of the eye, or the use of ocular salvage treatments with chemotherapy and focal treatments or radiation therapy [20, 21]. Delays in diagnosis lead to increased rates of vision loss, need for therapy intensification (with its associated life-time toxicity) and death, particularly for children who live in resource-poor settings [7]. Compressing diagnostic time frames rely, in part, on improved methods for detecting intraocular tumors or their leukocoric presentation.
The autonomous and semi-autonomous analysis of diagnostic medical images, such as those mediated by computational biology and machine learning, are routinely used for the unsupervised and supervised prediction and prognosis of numerous pathologies and pathology outcomes, but have had limited application in areas of detection and diagnosis [22, 23]. In applications where machine learning has been applied to the discernment of disease based on image data (analogous to the observable detection of leukocoria in digital photographs), there has been significant success. These previous studies have employed a variety of soft computing techniques: support vector machines (SVMs), Bayesian statistical approaches and neural networks have been used to assist in the detection of breast cancer in mammograms [24], prostate cancer [25], lung cancer [26] and cervical cancers [27]. Of particular importance has been the successful use of neural networks for the detection of skin cancers, such as melanoma, where non-histological photographic digital images serve as the medium [28–31]. In each of these scenarios, however, studies have been applied to controlled environments where skilled technicians intentionally seek to classify disease states.
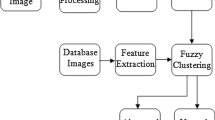
In spite of the apparent symptomology and recent successes in categorization [10], the automated or semi-automated detection of leukocoria remains a naive process. Therefore, this paper proposes a classification algorithm that detects a leukocoric eye using images (see Figure 1) processed to automatically detect faces and the position of the eyes [32], regions of interest, i.e., both eyes, and, finally, an individual class for each eye using a soft fusion of multiple classifiers to produce optimal results. The essential property of soft fusion of classifiers is the use of fuzzy integrals as a similarity measure [33, 34]. While still a very active area of research [35, 36], the fusion of multiple classifiers based on support vector machines, neural networks, and discriminant analysis has had success, such as the classification of bacteria [37], handwriting images [38], credit scores [39], and remote sensing [40]. Here, we demonstrate that this approach is a significant improvement over alternative methods of machine learning-enabled leukocoria detection.

Process of classification of two input images.
Methods
Ethics statement
This study was determined to be exempt from review by an Institutional Review Board at Baylor University. The parents of the study participants have given written informed consent to use and publish unaltered images of faces.
Database and feature extraction
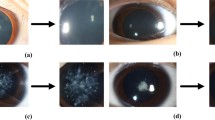
This research uses a database of digital images corresponding to the eyes of 72 faces, for a total of 144 eye images. This database is strictly an internal collection of images produced by the authors of this paper, consequently, no external permission is required. To the best of our knowledge, there are no other databases for this task.Out of the 144 eye images, 54 eyes are labeled as "leukocoric" while the remaining 90 are labeled as "healthy". This implies that the database is unbalanced with 37.5% being the positive class and 62.5% the negative. The size of each image varies being 19 × 19 the smallest size and 138 × 138 the largest. Orientation, angle, and rotation of each eye varies from image to image. The database includes faces with different skin and iris color. Illumination is not controlled and varies depending of the distance between the face and the flash of the camera. Also, different cameras were used to build the database. Figure 2 depicts several example images from the database.Figure 2 shows samples for the two classes and illustrates the challenges mentioned above. These challenges demand a pre-processing strategy that reduces the effect of random factors in the acquisition process. We use the strategy explained herein and presented in Figure 3.

Sample images from the experimental database.

Proposed image pre-processing strategy and feature extraction for the detection of leukocoria.
First, the input image is cropped to contain only the M × N image of the circumference delimited by the iris. This process can be done either manually or automatically.
Secondly, the cropped M × N three-channel (RGB) image, denoted as I(n 1,n 2,n 3), where n 1 ∈ {0,…,M - 1}, n 2 ∈ {0,…,N - 1}, and n 3 ∈ {0,1,2}, is separated into three different gray-scale images, I R (n 1,n 2), I G (n 1,n 2), and I B (n 1,n 2).
The next step leverages 2D-DCT to alleviate the problem of variant illumination in all three channels. For an image I(n 1,n 2) of size M × N, we can determine a matrix F I (k 1,k 2) also of size M × N that contains all the spatial frequency components of the image, for k 1 ∈ {0,…,M - 1} and k 2 ∈ {0,…,N - 1}. The matrix F I can be computed with the 2D-DCT in the following manner:
where and
According to [41], discarding the first three coefficients of F I (k 1,k 2) will counter the variation of illumination within the image. That is, an altered frequency domain matrix is created by discarding the elements in the coordinates (k 1 = 0,k 2 = 0), (k 1 = 0,k 2 = 1), and (k 1 = 1,k 2 = 0) of F I . After discarding the first three DCT coefficients, is inversely transformed from the frequency domain to the spatial domain as follows:
where and α(·) is also computed with (2).
Fourth, each image is then down-sampled or up-sampled to a fixed size of 32 × 32. The selection of this particular size was determined experimentally, training several classifiers using different image sizes and choosing the size that produced the smallest classification error in the average case, which was 32 × 32. Note that this is a very small resolution compared to the natural resolution of recreational photographs.
Fifth, we z-score (subtract the mean and divide by the standard deviation) for each channel. The purpose is to have a dataset approximating a distribution at each channel. That is, having a dataset that follows a normal distribution with zero mean and unit variance at each channel. In order to determine the mean and standard deviation for z-scoring we only make use of all images available for training, i.e., the training dataset. Images in the testing dataset will require the estimated mean and standard deviation estimated for the training dataset. We define as the image that has been processed by up-sampling or down-sampling, subtraction of a mean image, and division by a standard deviation.
Finally, the Karhunen-Loeve Transform (KLT) is applied to the data using only the two eigenvectors whose corresponding eigenvalues are the largest of all [42, 43]. This procedure is analog to dimensionality reduction using Principal Component Analysis (PCA). Experimental research determined that the minimum number of eigenvectors that can be used without loss of generalization is two. We define x
i
as a two-row vector defining the i-th eye image transformed using the KLT; that is, , where denotes the KLT. Therefore, the transformed training set per each individual channel is defined as , where , d
i
∈ {-1,1} is the desired target class corresponding to the i-th vector (indicating normal or leukocoric), and N indicates the total number of training samples. Then, the training set  is used in the design of classifiers, which is explained in the next section.
is used in the design of classifiers, which is explained in the next section.
Classification architecture
The proposed classification scheme involves the fusion of different classifiers that are known to perform well individually. The purpose of the fusion is to achieve better performance than with individual classifiers [44]. The fusion of classifiers is also known as "combination of multiple classifiers" [45], "mixture of experts" [46], or "consensus aggregation" [47]. This paper uses fuzzy logic to combine different classifiers using the method proposed in [33, 34]. A fuzzy integral conceptualizes the idea of the method along with Sugeno’s g λ -fuzzy measure [48]. The different classifier performances define the importance that the fusion method will give to each classifier. We propose having nine different classifiers per channel, as shown in Figure 3. The total number of classifiers is 27. We perform the analysis of each channel aiming to observe which channel performs better and to determine its contribution to correct classification in further studies. A final class is given considering each classifier’s output at each channel. The following paragraphs explain the fusion methodology.
Soft fusion of classifiers
Revisiting [33] and [48] we have that a set function is called a fuzzy measure if 1) g(0) = 0, , 2) if , and 3) if is an increasing sequence of measurable sets, then . This can be used to define the following equality:
which is known as the g λ -fuzzy measure, for some λ > -1, all , and .
If we consider  as a finite set and as a fuzzy subset of
as a finite set and as a fuzzy subset of  , then, the fuzzy integral over
, then, the fuzzy integral over  of the function h w.r.t. a fuzzy measure g can be defined as follows:
of the function h w.r.t. a fuzzy measure g can be defined as follows:
where . The equality in Equation 5 defines the agreement between the expectation and the evidence.
Particularly, let  define a finite set containing the outputs of n classifiers, that is, . Let be a function that tells the certainty of a classifier’s output to belong to a given class (i.e. provides the "evidence"). Then, order the classifiers according to their current classification certainty, such that h(y
1) ≥ h(y
2) ≥ ⋯ ≥ h(y
n
). Then it follows to define the fuzzy integral e w.r.t. a fuzzy measure g over
define a finite set containing the outputs of n classifiers, that is, . Let be a function that tells the certainty of a classifier’s output to belong to a given class (i.e. provides the "evidence"). Then, order the classifiers according to their current classification certainty, such that h(y
1) ≥ h(y
2) ≥ ⋯ ≥ h(y
n
). Then it follows to define the fuzzy integral e w.r.t. a fuzzy measure g over  as follows:
as follows:
where . Furthermore, since g is a g λ -fuzzy measure, each value for can be computed using the following recursive equation:
where λ is the unique root greater than -1 that can be obtained solving the following polynomial:
where λ ∈ (-1,+∞) and λ ≠ 0. However, in order to solve the polynomial, we need to estimate the densities g i (i.e., "the expectation"). The i-th density g i defines the degree of importance the i-th classifier y i has in the final classification. This densities can be estimated by an expert, or defined using a training dataset. In this research we defined the densities using the performance obtained from the data, and the process of experimentation will be explained later. In the following subsection we discuss briefly the classifiers used in this research.
Selection of classifiers
We are using three different kinds of classifiers: artificial neural network (ANN)-based, support vector machines (SVM)-based, and discriminant analysis (DA)-based. The three ANN-based classifiers we use for each channel have the same Feed-Forward (FF) architecture [49]; the difference lies in the number of neurons in each hidden layer. The two outputs of each neural network have softmax activation functions; the goal is to train the neural networks to approximate probability density functions of the problem and output the posterior probabilities at the output layer. Thus the output layer’s activation functions, softmax, act as the function h that maps the output of the classifier to values in the range [0,1] indicating classification certainty for either class. We used a partial subset of data and started training with three different groups: networks that randomly have between a) 2–5 neurons, b) 6–25 neurons, and c) 26–125 neurons. After a large number of experiments we concluded that the three best architectures were those shown in Table 1. The selection was performed based on those networks whose balanced error rate (BER) was the lowest in the average case.
E.g., consider the third row of Table 1; for the blue channel, the best three architectures were those with two, three, and five neurons in the hidden layer; in contrast, the red channel exhibited the lowest errors using two, 20, and 50 neurons in the hidden layer. Intuitively, one can conclude that the training data for both green and blue channels is much simpler to classify than the data for the red channel.
Next, the SVM-based classifiers in this research are, by necessity, of the soft margin kind since the dataset has two non-linearly separable classes [50]. This research uses four SVMs; each has a different type of kernel function. The four SVM kernel functions are: 1) linear, 2) quadratic, 3) polynomial, and 4) radial basis function (RBF).
An SVM with linear kernel is the simplest form of a soft margin SVM; in practice it only performs a dot product, leaving the data in the input space. SVMs with a quadratic kernel are a particular case of a polynomial kernel of second degree. An RBF kernel is a preferred choice in research that offers little or no information about the dataset properties. SVMs can be very powerful, but its effectiveness, however, is tied up to an appropriate selection of its model parameters, a.k.a. hyper-parameters [51]. The traditional soft-margin SVM requires a hyper-parameter usually known as "regularization" parameter, C, that penalizes data-points incorrectly classified. Then, depending on the kernel choice, SVMs may have additional hyper-parameters; e.g., the polynomial kernel requires a parameter p that defines the degree of the polynomial while the RBF kernel requires the parameter τ which controls the wideness in an exponential Gaussian-like function.
The typical method to find a "good" set of hyper-parameters is called "grid search", which some times can be computationally costly, especially if the data set is large. Thus, in order to accelerate the process of finding the hyper-parameters this research uses a quasi-optimal method to find the hyper-parameters based on optimization techniques [52]. The list of hyper-parameters used in our SVM-based classifiers appears in Table 2. The table shows the final values of C, p, and τ for each channel and the particular kernel choice. In the case of SVMs based on a polynomial kernel with a variable degree, it was found that a third degree polynomial produced better results; this is shown in the fourth column of Table 2.
The last choice of classifiers are based on discriminant analysis. Both Linear Discriminant Analysis (LDA) [53] and Quadratic Discriminant Analysis (QDA) [54] are closely related and are well known in the community for their simplicity and the robustness provided by statistical properties of the data. QDA and LDA achieve optimal results, in terms of probability theory, when the data in each class follows a Gaussian distribution independent and identically distributed (IID). Since this research uses the KLT, the data is close to being IID; however, the data is not actually IID, as in most real-life applications such as this research. LDA and QDA require no parameters except for the mean and covariance matrix estimates for each channel; these are computed from the training set  . The experiments performed while training the classifiers and the soft fusion are discussed next.
. The experiments performed while training the classifiers and the soft fusion are discussed next.
Experimental design
The soft fusion of i classifiers for detecting leukocoria requires an estimation of each classifier’s importance, i.e., the i-th density g i. This research defined each classifier’s importance based on their individual performances using several different performance metrics and averaging the ranking in each individual metric. This section describes the experimental process of evaluating each classifier and the final value for g i density corresponding to the i-th classifier.
Cross-validation
The whole database of eye images contains 144 examples. We divided the database into 10 groups of approximately equal size in order to use the well-known K-fold cross validation (CV) technique. Cross validation helps the researcher get an estimate of true classification performances [55]. This research uses 10-fold CV (K = 10) in order to determine the true importance of each classifier.
The database is divided in 10 groups of 14.4 data points in the average case. The methodology selects which points belong to each group randomly. Nine out of the 10 groups follow the pre-processing and feature extraction procedure explained earlier. Then the set of nine groups with its corresponding target classes d i is defined as the training dataset , where , d i ∈ {-1,1}. Then, the 10th group (the one not used for training) is used as the testing set , where N + M = 144. The process is repeated 10 times selecting a different combination of nine groups each time leaving the 10th out for testing. Finally, the performances obtained with each testing set are averaged. We ran 10-fold CV 100 times in order to have more meaningful results, averaging each instance of 100 CVs. This process reduces the uncertainty that the CV method will choose nearly the same sets of data for the 10 groups. The following paragraph explains the performance metrics used to rank the classifiers.
Performance metrics
Let us define the i-th difference y i - d i as the i-th "residual error", where y i is the actual output of the classifier when the testing set input vector x i is presented at its input, for all . Commonly, machine learning researchers use the following statistical metrics to quantify performance based on the residual error: Root Mean Squared Error (RMSE) and Normalized Root Mean Squared Error (NRMSE). Such metrics are defined as follows:
where σ is the standard deviation of y i .
From estimation theory it is known that if one has the residual error’s expected value equal to zero, and a unit variance, one may have achieved the least-squares solution to the problem, either linear or non-linear. Furthermore, it is understood that as the variance of the residual error approaches zero, the problem is better solved. Therefore, we want to measure both the expected value and the variance. Let us denote the expected value of the residual error μ ε and the variance of the residual error and their sample-based estimators as follows:
from where it is desired that both |μ ε |,σ ε → 0 as M → ∞.
On the other hand, some standard performance metrics for binary classification employ the well known confusion matrix. For binary classification, four possible prediction outcomes exist. A correct prediction is either a True Positive (TP) or a True Negative (TN), while an incorrect prediction is either a False Positive (FP) or a False Negative (FN). Here ‘Positive’ and ‘Negative’ correspond to the predicted label of the example.
From hereafter we denote TP as the total number of true positives, TN as the total number of true negatives, FP as the total number of false positives, and FN as the total number of false negatives in a classification event using a complete dataset, which in our case is the cross validation set  . Such definitions allow us to use following performance metrics based on a confusion matrix:
. Such definitions allow us to use following performance metrics based on a confusion matrix:
Note that in the literature, one might also find the above measures with different names; e.g., TPR is also known as Sensitivity, SPC is also known as TN rate, PPV is also known as Precision, and the F 1-Score is also known as the F-Measure.
In the literature, one can find other typical performance metric based on the area under Receiver Operating Characteristics (ROC) curve [56]. The area under the ROC curve, abbreviated AUC, provides a basis for judging whether a classifier performs realistically better than others in terms of the relationship between its TPR and FPR.
The last performance metric we use is the Cohen’s kappa measure κ. The κ measure scores the number of correct classifications independently for each class and aggregates them [57]. This way of scoring is less sensitive to randomness caused by a different number of examples in each class, therefore, it is less sensitive to class bias in training data.
All the performance measures described in Equations 9a through 9n need to be interpreted according to a desired outcome. Table 3 shows all the performance metrics discussed and their corresponding desired outcome; this will help interpret the results and rank the classifiers fairly well.
Results
Tables 4, 5 and 6 show the average performance of each classifier over 100 experiments using different metrics. Each table ranks the classifiers on different color channel data: red, green, and blue, respectively. The number in parenthesis defines the rank of a classifier for that particular metric (in each row). A classifier ranked as "(1)" is the best among all the others, consequently, one ranked as "(9)" is the worst. The average rank of each classifier is shown in the last row of each table and this is used to determine the actual importance of each classifier. The i-th density, g i, is computed using the following expression:
where r i is the average rank of each classifier and Σ r is the sum of all classifier ranks. In this manner, the sum of all densities is equal to one, which is desired [33].
From Table 4 we observe that for the red channel, the first three best ranked classifiers are LDA (DA 1), and SVM with RBF kernel (SVM 4), and SVM linear (SVM 1). Table 5 shows that for the green channel, SVM with RBF kernel, SVM with polynomial kernel of third degree (SVM 3), and LDA as the best ranked classifiers respectively. Similarly, Table 6 shows that for the blue channel, the SVM with polynomial kernel of third degree, SVM with RBF kernel, and SVM linear are the top three classifiers respectively.
Soft fusion classification and comparison
Finally, we can perform the soft fusion of classifiers using the densities found after performance analysis of the classifiers. Since the densities, g i, are now known, we can use Equation 8 to determine the appropriate value for λ and then compute the g λ -fuzzy measure using Equation 7 that allows us to compute the fuzzy integral (Equation 6).
For comparison purposes we also use three of the most common combination methods: 1) Average, 2) Weighted Average, and 3) Majority. The Average method consists of averaging the classification of all classifiers and choosing the class closest to the average. However, the Weighted Average method takes into account the importance of each classifier as determined by the densities g i and multiplies each classifier’s output by its corresponding importance; the products are added all together and the method decides for the class closest to the sum. In contrast, the majority method considers all classifiers equally relevant and takes a vote, deciding for class that agrees with the majority. Note that the Average and Majority methods produce the value for metrics based on classification error (such as Accuracy and TPR), but differ in metrics producing real values (such as RMSE). This is because the Average method uses real values output from the individual models, while the Majority method uses voting.
Table 7 shows the results of classification with the different methods of combining classifiers. Note that these methods consider the information of all classifiers in all three channels and, thus, only one table is necessary. The next section introduces the analysis of these results. Note, however, that in the next section, the variables p and α are redefined and have the traditional meaning of statistical analysis and they shall not be confused with the variables p and α that, in the rest of the paper, represent a kernel parameter and a DCT scaling function, respectively.
Discussion
Table 7 shows that the proposed classification scheme performs better than the other three methodologies in most cases. The soft fusion of classifiers produces results that have less variability in the average case, as shown in the second-to-last row.
The results in Tables 4, 5 and 6 clearly indicate that classifiers that use the green channel information perform better than those using blue or red channel information. Also, we can observe that the classifiers using red channel information perform the worst of all. Therefore, we can argue that the most discriminant information is carried over the green channel and the information in the red channel may be introducing noise to the soft fusion of classifiers. Considering this possibility we compare the results of the best classifiers that use the information of the green channel against the proposed scheme, i.e., SVM with RBF kernel from Table 5 against the soft fusion method in Table 7. In comparison we can notice that the proposed soft fusion of classifiers performs better only in terms of the RMSE, NRMSE, σ ε , and AUC. This means that the proposed scheme has better statistical stability, and that its relationship in terms of TPR and FPR demonstrates better performance. In all the remaining instances the SVM classifier with RBF kernel performs better than the soft fusion; arguably, because of the introduction of noise via red channel information.
We continued by performing the well known Friedman’s test and if the null-hypothesis were rejected we also performed the post-hoc Nemenyi’s test [58]. First, Friedman’s test determined that the results were statistically significant with p = 1.12 × 10-5 rejecting the null-hypothesis. The null-hypothesis being tested here is that the different approaches presented in the comparison of Table 7 perform the same, and that their performance differences are random. Then, since the null hypothesis was rejected it followed to perform the post hoc Nemenyi’s test. We determined the critical difference (CD) for comparing four methods of combining classifiers using 17 different performance metrics with a level of significance α = 0.05. The result is the following: . Therefore, since the difference between the two best methods, i.e., Weighted Average and Soft Fusion, is greater than the CD, then we conclude that the Soft Fusion of classifiers performs significantly better than the other three methods in a statistical sense. That is, 2.6471 - 1.3529 = 1.2942 > 1.1376. Note that even when both the Soft Fusion and Weighted Average methods take the importance of each classifier into account, still the proposed classification scheme is significantly better.
Figure 4 depicts an analysis of the classification certainty and uncertainty. This analysis is possible since the fuzzy integral (Equation 6) gives us the certainty that a classifier’s ouptut y i belongs to one class or the other. From the upper part of Figure 4 we can observe how images in the threshold of being misclassified as leukocoric or misclassified as healthy are extremely similar and, thus, difficult to classify. The lower part of Figure 4 illustrates the problem when images are in the threshold of being correctly classified as healthy or leukocoric; here the problem seems to be related to the resolution of the original image. The lower the resolution the higher the risk of the image to be misclassified. Also the angle towards where the eye is gazing affects the classification to some degree. This is expected since the white reflection of the leukocoric eye is better observed when the eye is looking directly towards the camera and its source of light; the converse is also true and affects classification. Skin color and uneven illumination problems were reduced because of the image preprocessing explained earlier; however, experimental proof of this remains pending for further publications.

Analysis of classification certainty and uncertainty as the eye images are classified as healthy or leukocoric.
Conclusions
The proposed classification scheme presented in this research uses a soft fusion of multichannel classifiers that are experts in detecting leukocoria in human eyes. These experts are trained with features extracted from RGB images preprocessed to overcome poor illumination and skin color variation using the DCT, statistical normalization of the images, and the KLT.
This research uses nine different classifiers per channel for a total of 27 experts. These include neural networks, linear discriminant classifiers, and support vector machines. The estimation of the fuzzy densities, a.k.a. importance of classifiers, was determined experimentally using cross-validation. The null-hypothesis was rejected and we demonstrated that the proposed classification scheme performs significantly better than the other approaches. Furthermore, it was shown that the green channel provides with more discriminant information than the other two.
While a soft fusion of classifiers is a good alternative in the detection of leukocoria in eyes of infants, it is just one part of a larger program to identify leukocoria in natural images. Other areas of research include eye localization (to improve detection), age discrimination (to reduce false positives on adult subjects), and alternative learning-based methods for leukocoria detection [59, 60].
Consent
Written informed consent was obtained from the patient’s parents for the publication of this report and any accompanying images.
References
Balmer A, Munier F: Leukocoria in the child: urgency and challenge. Klinische Monatsblatter Fur Augenheilkunde. 1999, 214 (5): 332-335. 10.1055/s-2008-1034807.
Meire FM, Lafaut BA, Speleman F, Hanssens M: Isolated norrie disease in a female caused by a balanced translocation t(x,6). Ophthalmic Genet. 1998, 19 (4): 203-207. 10.1076/opge.19.4.203.2306.
Meier P, Sterker I, Tegetmeyer H: Leucocoria in childhood. Klinische Monatsblatter Fur Augenheilkunde. 2006, 223 (6): 521-527. 10.1055/s-2005-859005.
Abramson DH, Beaverson K, Sangani P, Vora RA, Lee TC, Hochberg HM, Kirszrot J, Ranjithan M: Screening for retinoblastoma: presenting signs as prognosticators of patient and ocular survival. Pediatrics. 2003, 112 (6 Pt 1): 1248-1255.
Phan I. T, Stout T: Retinoblastoma presenting as strabismus and leukocoria. J Patient Saf. 2010, 157 (5): 858-
Poulaki V, Mukai S: Retinoblastoma: genetics and pathology. Int Ophthalmol Clin. 2009, 49 (1): 155-164. 10.1097/IIO.0b013e3181924bc2.
Rodriguez-Galindo C, Wilson MW, Chantada G, Fu L, Qaddoumi I, Antoneli C, Leal-Leal C, Sharma T, Barnoya M, Epelman S, Pizzarello L, Kane JR, Barfield R, Merchant TE, Robison LL, Murphree AL, Chevez-Barrios P, Dyer MA, O’Brien J, Ribeiro RC, Hungerford J, Helveston EM, Haik BG, Wilimas J: Retinoblastoma: one world, one vision. Pediatrics. 2008, 122 (3): 763-770. 10.1542/peds.2008-0518.
Melamud A, Palekar R, Singh A: Retinoblastoma. Am Fam Physician. 2006, 73 (6): 1039-1044.
Houston SK, Murray TG, Wolfe SQ, Fernandes CE: Current update on retinoblastoma. Int Ophthalmol Clin. 2011, 51 (1): 77-91. 10.1097/IIO.0b013e3182010f29.
Abdolvahabi A, Taylor BW, Holden RL, Shaw EV, Kentsis A, Rodriguez-Galindo C, Mukai S, Shaw BF: Colorimetric and longitudinal analysis of leukocoria in recreational photographs of children with retinoblastoma. PloS one. 2013, 8 (10): 76677-10.1371/journal.pone.0076677. doi:10.1371/journal.pone.0076677
Singman EL: Automating the assessment of visual dysfunction after traumatic brain injury. Med Instrum. 2013, 1 (1): 3-10.7243/2052-6962-1-3.
Khan AO, Al-Mesfer S: Lack of efficacy of dilated screening for retinoblastoma. J Pediatr Ophthalmol Strabismus. 2005, 42 (4): 205-102334.
Li J, Coats DK, Fung D, Smith EO, Paysse E: The detection of simulated retinoblastoma by using red-reflex testing. Pediatrics. 2010, 126 (1): 202-207. 10.1542/peds.2009-0882.
Marcou V, Vacherot B, El-Ayoubi M, Lescure S, Moriette G: [abnormal ocular findings in the nursery and in the first few weeks of life: a mandatory, yet difficult and neglected screening]. Arch Pediatr. 2009, 16 (Suppl 1): 38-41.
Balmer A, Munier F: Differential diagnosis of leukocoria and strabismus, first presenting signs of retinoblastoma. Clin Ophthalmol. 2007, 1 (4): 431-439.
Wallach M, Balmer A, Munier F, Houghton S, Pampallona S, von der Weid N, Beck-Popovic M: Shorter time to diagnosis and improved stage at presentation in swiss patients with retinoblastoma treated from 1963 to 2004. Pediatrics. 2006, 118 (5): 1493-1498. 10.1542/peds.2006-0784.
Imhof SM, Moll AC, Schouten-van Meeteren AY: Stage of presentation and visual outcome of patients screened for familial retinoblastoma: nationwide registration in the netherlands. Br J Ophthalmol. 2006, 90 (7): 875-878. 10.1136/bjo.2005.089375.
Goddard AG, Kingston JE, Hungerford JL: Delay in diagnosis of retinoblastoma: risk factors and treatment outcome. Br J Ophthalmol. 1999, 83 (12): 1320-1323. 10.1136/bjo.83.12.1320.
Butros LJ, Abramson DH, Dunkel IJ: Delayed diagnosis of retinoblastoma: analysis of degree, cause, and potential consequences. Pediatrics. 2002, 109 (3): 45-10.1542/peds.109.3.e45.
Shields CL, Shields JA: Retinoblastoma management: advances in enucleation, intravenous chemoreduction, and intra-arterial chemotherapy. Curr Opin Ophthalmol. 2010, 21 (3): 203-212. 10.1097/ICU.0b013e328338676a.
Friedrich MJ: Retinoblastoma therapy delivers power of chemotherapy with surgical precision. JAMA : Jo Am Med Assoc. 2011, 305 (22): 2276-2278. 10.1001/jama.2011.778.
Cruz JA, Wishart DS: Applications of machine learning in cancer prediction and prognosis. Cancer Inform. 2006, 2: 59-77.
Drier Y, Domany E: Do two machine-learning based prognostic signatures for breast cancer capture the same biological processes?. PloS one. 2011, 6 (3): 1-7.
Kim S, Yoon S: Adaboost-based multiple svm-rfe for classification of mammograms in ddsm. BMC Med Inform Decis Making. 2009, 9: 1-10. 10.1186/1472-6947-9-1.
Doyle S, Feldman M, Tomaszewski J, Madabhushi A: A boosted bayesian multi-resolution classifier for prostate cancer detection from digitized needle biopsies. IEEE Trans Biomed Eng. 2010, 59 (5): 1205-1218. doi:10.1109/TBME.2010.2053540
Zhou ZH, Jiang Y, Yang YB, Chen SF: Lung cancer cell identification based on artificial neural network ensembles. Artif Intell Med. 2002, 24 (1): 25-36. 10.1016/S0933-3657(01)00094-X.
Mango LJ: Computer-assisted cervical cancer screening using neural networks. Cancer Lett. 1994, 77 (2–3): 155-162.
Ercal F, Chawla A, Stoecker WV, Lee HC, Moss RH: Neural network diagnosis of malignant melanoma from color images. IEEE Trans Biomed Eng. 1994, 41 (9): 837-845. 10.1109/10.312091. doi:10.1109/10.312091
Blum A, Luedtke H, Ellwanger U, Schwabe R, Rassner G, Garbe C: Digital image analysis for diagnosis of cutaneous melanoma. development of a highly effective computer algorithm based on analysis of 837 melanocytic lesions. Br J Dermatol. 2004, 151 (5): 1029-1038. 10.1111/j.1365-2133.2004.06210.x. doi:10.1111/j.1365-2133.2004.06210.x
Ganster H, Pinz A, Röhrer R, Wildling E, Binder M, Kittler H: Automated melanoma recognition. IEEE Trans Med Imaging. 2001, 20 (3): 233-239. 10.1109/42.918473. doi:10.1109/42.918473
Garcia-Uribe A, Kehtarnavaz N, Marquez G, Prieto V, Duvic M, Wang LV: Skin cancer detection by spectroscopic oblique-incidence reflectometry: classification and physiological origins. Appl Opt. 2004, 43 (13): 2643-2650. 10.1364/AO.43.002643.
Viola P, Jones M: Rapid object detection using a boosted cascade of simple features. Computer Vision and Pattern Recognition, 2001. CVPR 2001 Proceedings of the 2001 IEEE Computer Society Conference On Volume 1. 2001, Piscataway: IEEE, 511-5181.
Cho S-B, Kim JH: Multiple network fusion using fuzzy logic. Neural Netw IEEE Trans. 1995, 6 (2): 497-501. 10.1109/72.363487.
Cho S-B, Kim JH: Combining multiple neural networks by fuzzy integral for robust classification. Syst Man Cybernet IEEE Trans. 1995, 25 (2): 380-384. 10.1109/21.364825.
Abdallah ACB, Frigui H, Gader P: Adaptive local fusion with fuzzy integrals. Fuzzy Syst IEEE Trans. 2012, 20 (5): 849-864.
Linda O, Manic M: Interval type-2 fuzzy voter design for fault tolerant systems. Inf Sci. 2011, 181 (14): 2933-2950. 10.1016/j.ins.2011.03.008.
Wang D, Keller JM, Carson CA, McAdo-Edwards KK, Bailey CW: Use of fuzzy-logic-inspired features to improve bacterial recognition through classifier fusion. Syst Man Cybernet Part B: Cybernet IEEE Trans. 1998, 28 (4): 583-591. 10.1109/3477.704297.
Gader PD, Mohamed MA, Keller JM: Fusion of handwritten word classifiers. Pattern Recognit Lett. 1996, 17 (6): 577-584. 10.1016/0167-8655(96)00021-9.
Wang Y, Wu J: Fuzzy integrating multiple svm classifiers and its application in credit scoring. Machine Learning and Cybernetics, 2006 International Conference On. 2006, Piscataway: IEEE, 3621-3626.
Benediktsson JA, Sveinsson JR, Ingimundarson JI, Sigurdsson HS, Ersoy OK: Multistage classifiers optimized by neural networks and genetic algorithms. Nonlinear Anal: Theory Methods Appl. 1997, 30 (3): 1323-1334. 10.1016/S0362-546X(97)00222-8.
Du S, Shehata M, Badawy W: A novel algorithm for illumination invariant dct-based face recognition. Electrical Computer Engineering (CCECE), 2012 25th IEEE Canadian Conference On. 2012, Piscataway: IEEE, 1-4.
Najim M: Modeling, Estimation and Optimal Filtering in Signal Processing. Chap. Karhunen Loeve Transform. 2010, London: Wiley – ISTE, :335–340
Hua Y, Liu W: Generalized karhunen-loeve transform. Signal Process Lett IEEE. 1998, 5 (6): 141-142.
Kuncheva LI, Bezdek JC, Duin RPW: Decision templates for multiple classifier fusion: an experimental comparison. Pattern Recognit. 2001, 34 (2): 299-314. 10.1016/S0031-3203(99)00223-X.
Kittler J, Hatef M, Duin RPW, Matas J: On combining classifiers. Pattern Anal Mach Intell IEEE Trans. 1998, 20 (3): 226-239. 10.1109/34.667881.
Jordan MI, Xu L: Convergence results for the em approach to mixtures of experts architectures. Neural Netw. 1995, 8 (9): 1409-1431. 10.1016/0893-6080(95)00014-3.
Swain PH, Benediktsson JA: Consensus theoretic classification methods. Syst Man Cybernet IEEE Trans. 1992, 22 (4): 688-704. 10.1109/21.156582.
Sugeno M: Fuzzy measures and fuzzy integrals: a survey. Fuzzy Automata Decis Process. 1977, 78 (33): 89-102.
Chacon MI, Rivas-Perea P: Performance analysis of the feedforward and som neural networks in the face recognition problem. IEEE Symposium on Computational Intelligence in Image and Signal Processing, 2007. CIISP 2007 Hawaii, USA. 2007, Piscataway: IEEE, 313-318.
Cristianini N, Scholkopf B: Support vector machines and kernel methods: the new generation of learning machines. Ai Magazine. 2002, 23 (3): 31-
Haykin SS: Neural Networks and Learning Machines. 2009, Upper Saddle River: Pearson Education
Rivas-Perea P, Cota-Ruiz J, Rosiles J-G: A nonlinear least squares quasi-newton strategy for lp-svr hyper-parameters selection. Int J Mach Learn Cybernet. 2013, 5 (4): 579-597.
Yang J, Frangi AF, Yang J-Y, Zhang D, Jin Z: Kpca plus lda: a complete kernel fisher discriminant framework for feature extraction and recognition. Pattern Anal Mach Intell IEEE Trans. 2005, 27 (2): 230-244.
Frigyik BA, Gupta MR: Bounds on the bayes error given moments. Inf Theory IEEE Trans. 2012, 58 (6): 3606-3612.
Cawley GC: Leave-one-out cross-validation based model selection criteria for weighted ls-svms. Neural Networks, 2006. IJCNN’06. International Joint Conference On. 2006, Piscataway: IEEE, 1661-1668.
Fawcett T: Roc graphs: notes and practical considerations for researchers. Mach Learn. 2004, 31: 1-38.
Carletta J: Assessing agreement on classification tasks: the kappa statistic. Comput Linguist. 1996, 22 (2): 249-254.
Demšar J: Statistical comparisons of classifiers over multiple data sets. J Mach Learn Res. 2006, 7: 1-30.
Henning R, Rivas-Perea P, Shaw B, Hamerly G: A convolutional neural network approach for classifying leukocoria. Image Analysis and Interpretation (SSIAI) 2014 IEEE Southwest Symposium On. 2014, Piscataway: IEEE, 9-12. doi:10.1109/SSIAI.2014.6806016
Rivas-Perea P, Henning R, Shaw B, Hamerly G: Finding the smallest circle containing the iris in the denoised wavelet domain. Image Analysis and Interpretation (SSIAI) 2014 IEEE Southwest Symposium On. 2014, Piscataway: IEEE, doi:10.1109/SSIAI.2014.6806017
Pre-publication history
The pre-publication history for this paper can be accessed here:http://www.biomedcentral.com/1471-2415/14/110/prepub
Acknowledgements
This work was supported in part by the National Council for Science and Technology (CONACyT), Mexico, under grant 193324/303732 provided to PRP, and a start-up fund provided to BFS by Baylor University.
Author information
Authors and Affiliations
Corresponding author
Additional information
Competing interests
The authors declare that they have no competing interests.
Authors’ contributions
PRP designed and performed the soft classification study. All authors were actively involved in the project. BFS provided the data. PRP, EB, and GH conducted the analysis. GH and EB revised early drafts of the manuscript. All authors commented on and approved the final version of the manuscript.
Authors’ original submitted files for images
Below are the links to the authors’ original submitted files for images.
Rights and permissions
This article is published under an open access license. Please check the 'Copyright Information' section either on this page or in the PDF for details of this license and what re-use is permitted. If your intended use exceeds what is permitted by the license or if you are unable to locate the licence and re-use information, please contact the Rights and Permissions team.
About this article

Cite this article
Rivas-Perea, P., Baker, E., Hamerly, G. et al. Detection of leukocoria using a soft fusion of expert classifiers under non-clinical settings. BMC Ophthalmol 14, 110 (2014). https://doi.org/10.1186/1471-2415-14-110
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/1471-2415-14-110