
Abstract
We consider nonregular fractions of factorial experiments for a class of linear models. These models have a common general mean and main effects; however, they may have different 2-factor interactions. Here we assume for simplicity that 3-factor and higher-order interactions are negligible. In the absence of a priori knowledge about which interactions are important, it is reasonable to prefer a design that results in equal variance for the estimates of all interaction effects to aid in model discrimination. Such designs are called common variance designs and can be quite challenging to identify without performing an exhaustive search of possible designs. In this work, we introduce an extension of common variance designs called approximate common variance or A-ComVar designs. We develop a numerical approach to finding A-ComVar designs that is much more efficient than an exhaustive search. We present the types of A-ComVar designs that can be found for different number of factors, runs, and interactions. We further demonstrate the competitive performance of both common variance and A-ComVar designs using several comparisons to other popular designs in the literature.






Similar content being viewed by others

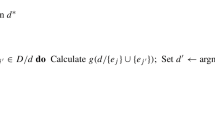

References
Bingham DR, Chipman HA (2007) Incorporating prior information in optimal design for model selection. Technometrics 49(2):155–163
Breiman L (1995) Better subset regression using the nonnegative garrote. Technometrics 37(4):373–384
Calvin JA (1986) A new class of variance balanced designs. J Stat Plan Inference 14(2–3):251–254
Candes E, Tao T (2007) The Dantzig selector: statistical estimation when p is much larger than n. Ann Stat 35(6):2313–2351
Cheng C-S (1986) A method for constructing balanced incomplete-block designs with nested rows and columns. Biometrika 73(3):695–700
Chowdhury S (2016) Common variance fractional factorial designs for model comparisons. PhD thesis, University of California Riverside
Ghosh S, Chowdhury S (2017) CV, ECV, and robust CV designs for replications under a class of linear models in factorial experiments. J Stat Plan Inference 188:1–7
Ghosh S, Flores A (2013) Common variance fractional factorial designs and their optimality to identify a class of models. J Stat Plan Inference 143(10):1807–1815
Ghosh S, Tian Y (2006) Optimum two level fractional factorial plans for model identification and discrimination. J Multivar Anal 97(6):1437–1450
Gupta S, Jones B (1983) Equireplicate balanced block designs with unequal block sizes. Biometrika 70(2):433–440
Hedayat A, Stufken J (1989) A relation between pairwise balanced and variance balanced block designs. J Am Stat Assoc 84(407):753–755
Kane A, Mandal A (2019) A new analysis strategy for designs with complex aliasing. Am Stat. https://doi.org/10.1080/00031305.2019.1585287
Khatri C (1982) A note on variance balanced designs. J Stat Plan Inference 6(2):173–177
Li W, Nachtsheim CJ (2000) Model-robust factorial designs. Technometrics 42(4):345–352
Lin CD, Anderson-Cook CM, Hamada MS, Moore LM, Sitter RR (2015) Using genetic algorithms to design experiments: a review. Qual Reliab Eng Int 31(2):155–167
Mandal A, Wong WK, Yu Y (2015) Algorithmic searches for optimal designs. In: Dean A, Morris M, Stufken J, Bingham D (eds) Handbook of design and analysis of experiments. Chapman & Hall/CRC, Boca Raton, FL, pp 755–783
Mukerjee R, Kageyama S (1985) On resolvable and affine resolvable variance-balanced designs. Biometrika 72(1):165–172
Srivastava J (1976) Some further theory of search linear models. In: Contribution to applied statistics. Swiss-Australian Region of Biometry Society, pp 249–256
Srivastava J, Ghosh S (1976) A series of balanced factorial designs of resolution v which allow search and estimation of one extra unknown effect. Sankhyā Indian J Stat Ser B 38:280–289
Srivastava J, Gupta B (1979) Main effect plan for 2m factorials which allow search and estimation of one unknown effect. J Stat Plan Inference 3(3):259–265
Yuan M, Joseph VR, Lin Y (2007) An efficient variable selection approach for analyzing designed experiments. Technometrics 49(4):430–439
Yuan M, Joseph VR, Zou H (2009) Structured variable selection and estimation. Ann Appl Stat 3(4):1738–1757
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendices
Appendix 1: Genetic Algorithm
In this work we used a genetic algorithm to find designs that maximize the A-ComVar objective function. This appendix provides specific details on the algorithm. Keeping with the standard genetic algorithm terminology, we use the word chromosome to describe a single candidate design. Each chromosome is comprised of the factor settings for each factor at each design point. Each of these individual factor settings is known as a gene. The population is the set of all chromosomes, i.e., all designs that we are currently considering.
We illustrate a simple version of the genetic algorithm below. In this example we search for a 6-run A-ComVar design for an experiment with three two-level factors and one interaction. We label the factors as A, B, and C. For simplicity, we assume that the population size is 3, although in real applications it will generally be larger.
Since this experiment has three two-level factors, there are 8 possible design points to pick the 6 points for our design from. The 8 points are shown in Table 7. There are \({3}\atopwithdelims (){2}\) \(= 3\) possible models with all main effects and one interaction. For notational simplicity we label these models by the corresponding interaction: (AB), (AC), and (BC). Our goal is to obtain a design under which the variance of the interaction term is identical, or close to identical, under all three of these models.
0. Initialization
First, each of the three chromosomes is initialized to a random start. To obtain the random start for a specific chromosome, we simply sample six of the rows in Table 7 without replacement. Our initialization procedure results in the following three chromosomes:

After initializing, we need to calculate the fitness for each of these chromosomes using the objective function in expression (2). In order to evaluate the objective function, we need to calculate \(\sigma _{2i}^2\) for \(i = 1, 2, 3\), which correspond to models (AB), (AC), and (BC), respectively. Then, we take the average of these three values to be \(\sigma _{2}^2\) and can evaluate the objective function. These steps are illustrated below for the first chromosome.

The above procedure is repeated for each of the three chromosomes. In this case, all three designs end up having the same fitness value. We now summarize each chromosome below:

Now that we have completed the initialization process, we can begin the main loop over the algorithm.
1. Identify worst chromosome(s)
The first step is to identify the worst chromosomes. These are the chromosomes that will be replaced by new offspring. Since we only have three chromosomes in the population, we will only identify and replace the single worst chromosome. In the case of a tie (as we have here), the chromosome to be replaced is randomly chosen. In this case we have chosen chromosome 3 to be replaced.
2. Generate replacement using crossover
We next generate a replacement for the worst chromosome (3) using crossover from 2 randomly selecting remaining chromosomes. Since our example only has three chromosomes, we simply use the remaining chromosomes (1 and 2). In the crossover, a random cut point is selected, and the two chromosomes are combined using the values from the first chromosome for the factors to the left of the cut point and the values from the second chromosome for the factors to the right of the cut point. This process is illustrated below:

Note that it is possible to consider other ways of producing offspring via crossover. For example, the cut point could be different for each support point, or they could be “horizontal” instead of “vertical,” choosing certain rows from the first chromosome and the remaining rows from the second.
3. Mutation
In addition to crossover, more novelty can be introduced to the solution by randomly changing, or mutating, some of factor settings. For our purpose, the probability of each factor setting (gene) mutating is identical.
4. Replacement and Fitness Evaluation
Following Steps 3 and 4, we are now ready to replace the old chromosome with the offspring. In this step, the worst chromosome(s) is replaced by the offspring created in Steps 2–3. The fitness of this new chromosome is evaluated and stored.
Appendix 2: Tables for Example 3
Tables 8, 9, 10, 11, 12, 13, and 14 present detailed results for each of the comparisons in Example 3.
Rights and permissions
About this article

Cite this article
Chowdhury, S., Lukemire, J. & Mandal, A. A-ComVar: A Flexible Extension of Common Variance Designs. J Stat Theory Pract 14, 16 (2020). https://doi.org/10.1007/s42519-019-0079-y
Published:
DOI: https://doi.org/10.1007/s42519-019-0079-y