
Abstract
In plant cells, calcium-dependent protein kinases (CDPKs) are important sensors of Ca2+ flux resulting from various environmental stresses like cold, drought or salt stress. Previous genome sequence analysis and comparative studies in Arabidopsis (Arabidopsis thaliana L.) and rice (Oryza sativa L.) defined a multi-gene family of CDPKs. Here, we identified and characterised the CDPK gene complement of the model plant, barley (Hordeum vulgare L.). Comparative analysis encompassed phylogeny reconstruction based on newly available barley genome sequence, as well as established model genomes (e.g. O. sativa, A. thaliana, Brachypodium distachyon). Functional gene copies possessed characteristic CDPK domain architecture, including a serine/threonine kinase domain and four regulatory EF-hand motifs. In silico verification was followed by measurements of transcript abundance via real-time polymerase chain reaction (PCR). The relative expression of CDPK genes was determined in the vegetative growth stage under intensifying drought stress conditions. The majority of barley CDPK genes showed distinct changes in patterns of expression during exposure to stress. Our study constitutes evidence for involvement of the barley CDPK gene complement in signal transduction pathways relating to adaptation to drought. Our bioinformatics and transcriptomic analyses will provide an important foundation for further functional dissection of the barley CDPK gene family.
Similar content being viewed by others


Introduction
One of the major features common to all organisms is the use of signal transduction pathways to control their metabolism and adapt to the changing environment. Frequently, calcium ions serve as a universal second messenger in such signal transduction pathways. The concentration of free, cytosolic Ca2+ in plant cells fluctuates in response to different stimuli, including hormones, pathogens, light and abiotic stresses (Evans et al. 2001; Sanders et al. 2002). These and other signals induce spatial and temporal Ca2+ spikes, as well as changes in the frequency and amplitude of Ca2+ oscillations.
Stimulus-specific increases in free, cytosolic Ca2+ levels are called ‘calcium signatures’ (Evans et al. 2001; Bose et al. 2011). Different Ca2+-interacting proteins recognise diverse calcium signatures and induce cascading downstream effects, such as altered protein phosphorylation and gene expression patterns. One of the largest and most differentiated group of calcium sensors are protein kinases, among them calcium-dependent protein kinases (CDPKs), which have been identified only in plants and protists (Harmon et al. 2000).
All members of this large multi-gene family have a conserved gene structure that consists of four characteristic conserved domains: the N-terminal domain, the serine/threonine kinase domain, the autoinhibitory domain and the calmodulin-like domain (Hrabak et al. 2003). The N-terminal domain is highly variable and often contains myristoylation or palmitoylation sites associated with subcellular targeting (Cheng et al. 2002). The conserved kinase domain is typical of serine/threonine kinases; its activation loop (located between subdomains VII and VIII) contains acidic residues, obviating the need for loop phosphorylation for kinase activity. The autoinhibitory domain contains a pseudosubstrate sequence capable of blocking the enzyme’s active site. The regulatory calmodulin-like domain contains four EF-hand motifs, each able to bind a single calcium cation (Klimecka and Muszyńska 2007). The CDPKs are often called sensor ‘responders’ as they are directly activated by calcium binding to the EF-hand motifs (Sanders et al. 2002). Subsequently, the conformation changes in the calmodulin-like domain lead to an induced conformational change in the kinase domain, which results in the displacement of the pseudosubstrate (autoinhibitory domain) from its active site (Reddy 2001).
The CDPKs are typically involved in the regulation of plant responses to a wide variety of stimuli, including hormones, cold/drought/salt stress, light and elicitor (Romeis et al. 2001; Lecourieux et al. 2006). A transgenic line of rice constitutively expressing OsCDPK7 and OsCDPK13 has enhanced tolerance to cold, salt and drought stress (Saijo et al. 2000; Komatsu et al. 2007), while OsCPK23 (SPK) and OsCPK19 (OsCDPK2) have been reported to be essential for seed development (Breviario et al. 1995; Frattini et al. 1999; Morello et al. 2000). In tobacco, CDPK-silenced plants show a reduced and delayed hypersensitive response to the fungal Avr9 elicitor (Romeis et al. 2001). Heterologous expression of a grape calcium-dependent kinase ACPK1 in Arabidopsis provided evidence that the ACPK1 gene is involved in abscisic acid (ABA) signal transduction as a positive regulator, and, thus, may be of use in improving plant biomass production (Yu et al. 2007). Two Arabidopsis thaliana guard cell-expressed CDPK genes, AtCPK3 and AtCPK6, are involved in transduction of the stomatal ABA signal (Mori et al. 2006). Genetic evidence at the whole-plant level pointed to the AtCPK4 and AtCPK11 genes as positive regulators of the CDPK/calcium-mediated ABA signalling pathways (Zhu et al. 2007). The above evidence clearly indicates the role of the CDPK family in providing the basic building blocks for effective plant responses and increased plant resistance to abiotic and biotic stresses.
The Arabidopsis genome contains 34 genes encoding CDPKs (Cheng et al. 2002; Hrabak et al. 2003), while maize (Zea mays L.) contains 40 (Kong et al. 2013) and rice 29 (Asano et al. 2005) or 31 (Ray et al. 2007) CDPK genes. Such differences in the number of CDPK homologues may suggest different evolutionary processes (duplication, speciation, loss), leading to extant homologues with possibly divergent functional profiles in various species. To date, genome-wide identification of CDPK gene family members and analysis of their functional divergence has been carried out in only a few plants. Thus, our understanding of the evolution of the family of calcium-dependent proteins is still incomplete.
In this study, we identified the barley (Hordeum vulgare) complement of 27 CDPK genes and analysed their expression under water deficiency conditions. We revealed the significant differences in transcript levels of specific CDPK genes which implies their involvement in adaptation to drought stress. Multi-genome comparative analysis of the phylogeny and chromosomal distribution of CDPKs allowed us to propose evolutionary relationships (paralogy vs. orthology scenarios) and provide independent verification of gene correspondence and grouping of CDPKs from multiple reference plant genomes.
Materials and methods
Identification of CDPK genes in barley
The barley CDPK gene complement was annotated by using the BLASTn (Altschul et al. 1990) algorithm to search the Ensembl Plants database (genome assembly: 08214v1), as well as the FLcDNAs of the H. vulgare ‘Haruna Nijo’ cultivar expressed under normal and stressed conditions (Matsumoto et al. 2011) found in NCBI/GenBank (National Center for Biotechnology Information; http://www.ncbi.nlm.nih.gov). The candidate gene sequences were further identified via the IPK Gatersleben BLAST gateway (http://webblast.ipk-gatersleben.de/barley/viroblast.php), which includes a whole-genome assembly of H. vulgare cultivar ‘Morex’ (2,670,738 contigs; Mayer et al. 2011). CDPKs from other model organisms were annotated based on characteristic protein domain signatures, as revealed by searching the Ensembl Plant genomes against the Pfam v13 database (Punta et al. 2012) with HMMER 3.0 software (Finn et al. 2011). The precise exon/intron structures of CDPK genes were determined using Scipio (http://www.webscipio.org/) based on the corresponding protein sequences (Keller et al. 2008). The presence of myristoylation motifs at the N-terminal domain were predicted using the Eukaryotic Linear Motif resource (http://elm.eu.org; Dinkel et al. 2014). The localisations of ancestral duplications shared between barley and rice was determined by mapping previously identified sequences (Thiel et al. 2009) to the recently published genetically anchored physical map (International Barley Genome Sequencing Consortium 2012) (MEGABLAST vs. Ensembl Plants).
Phylogeny reconstruction and reconciliation
Comparative phylogenetic analysis was conducted on a set of six model plant genomes (Chlamydomonas reinhardtii, Physcomitrella patens ssp. patens, Arabidopsis thaliana, Brachypodium distachyon, Oryza sativa ssp. japonica, Hordeum vulgare ssp. vulgare). The multiple alignment of 143 CDPKs was prepared using the parallelised version of MAFFT-LINSI (Katoh and Toh 2010) and inspected in SeaView (Gouy et al. 2010). Conserved regions of the alignment were extracted with TrimAl (Capella-Gutiérrez et al. 2009) using a 70 % threshold for the exclusion of gapped sites (473 sites remained after exclusion). The resulting trimmed alignment is included in Online Resource 5. Maximum likelihood model parameters were assessed with ProtTest v3 (Darriba et al. 2011), according to both Akaike and Bayesian corrected information criteria. The final phylogenetic analysis was conducted in RAxML v.7.3 (Stamatakis 2006; Stamatakis et al. 2008), using the LG model of evolution (Le and Gascuel 2008), with fixed residue frequencies and a gamma-based site rates model. Tree support was computed based on 1000 bootstrap iterations (rapid bootstrap heuristic; Stamatakis et al. 2008). Human calmodulin-dependent kinase 1 was included as the outgroup (UniProt/SwissProt: KCC1A_HUMAN (Q14012)). The resulting gene tree was reconciled and visualised with a custom Python/ete2 script using a strict tree reconciliation algorithm (Page and Charleston 1997), as implemented in the ETE toolkit (Huerta-Cepas et al. 2010). The reference species tree topology was inferred from NCBI Taxonomy (approach analogous to Ensembl Compara; Sayers et al. 2009) and is depicted in Fig 1.

The reference species tree topology inferred from NCBI Taxonomy (approach analogous to Ensembl Compara; Sayers et al. 2009)
Plant material and growth conditions
Experiments were carried out on two spring barley (H. vulgare L.) genotypes differing in response to drought stress: the drought-tolerant variety Sebastian and drought-susceptible variety Georgie (seeds kindly provided by Prof. Andrzej Górny, Institute of Plant Genetics collection). Sebastian, a variety of Danish origin, widely cultivated in the Czech Republic; and Georgie, a British variety released in 1975 (for details concerning varieties, see http://genbank.vurv.cz/barley/pedigree/). The seeds were surface-treated with JOCKEY 201FS for 5 min to protect them from fungal invasion and soaked in water for 24 h at 23 ± 2 °C with continuous shaking at 400 rpm to equalise germination. After treatment, the seeds were sown in 1-dm3 pots (ten plants each) filled with a mixture of sand and soil (2:7 w/w). The plants were grown in a greenhouse at 23/14 °C day/night, 55 % room humidity (RH), with a photoperiod of 10 h. The pots were watered and weighed every day and optimal soil moisture (8–12 %), corresponding to a soil moisture retention (pF) between 2.4 and 3.0, was maintained. The soil moisture retention curve (pF curve) was drawn for soil used in all experiments (kindly provided by Prof. Grzegorz Józefaciuk, The Bohdan Dobrzanski Institute of Agrophysics of Polish Academy of Sciences, Lublin, Poland) (Online Resource 1). It served to distinguish three stages of drought: mild at 3.2 pF, moderate at 3.6 pF and severe (beyond permanent wilting point) at 4.2 pF. Three-week-old plants were exposed to drought stress by withstanding of water to ensure a water content corresponding to 3.2 (first day of drought treatment), 3.6 (second day of drought treatment) or 4.2 pF (fourth day of drought treatment). The drought stress treatment was conducted in triplicate, where the pot was considered as a biological replicate. Each parameter combination (genotype * drought vs. control * stage of drought) was represented by ten plants per pot tested at the same time.
Expression analysis
Samples of barley third leaves from ten plants were ground into fine powder in liquid N2 and total RNA was extracted using TRIZOL reagent according to the manufacturer’s manual (Life Technologies). The isolated RNA was purified with the SV Total RNA Isolation System (Promega). cDNA synthesis was performed in duplicate using a SuperScript cDNA Synthesis Kit (Invitrogen). The primers for the CDPK genes were designed using Primer3Plus software targeting the extreme 5′ end (extreme 5′ ends are not conserved), which produced an amplicon of 89–245 bp (primer length between 20 and 24 bp), with a melting temperature of 54–58 °C. Gene-specific primers used for each CDPK are shown in Online Resource 2. The sequence correctness of particular amplicons was verified by automatic sequencing. Quantitative reverse transcription polymerase chain reaction (RT-PCR) analysis was performed using the Stratagene Mx3000P Cycler system with Brilliant III Ultra-Fast SYBR QPCR MM Supermix (Stratagene) in a total volume of 20 μl. The reactions were performed as technical duplicates using independent cDNA synthesis reactions. Expression values were normalised against the ADP-ribosylation factor gene, which according to geNormPLUS analysis (data not shown), displayed the highest stability of expression level. It was also suggested as the most suitable to study drought-induced changes in gene expression at the seedling stage in barley (Rapacz et al. 2012). Expression values were calculated using the 2−ΔΔCT method (Schmittgen and Livak 2008).
Statistical analysis
For each gene independently, analysis of variance (ANOVA) of expression data was performed using the model of repeated measurements (Winer 1962) with main effects of variety (V), time of observations (T), drought treatment (D), and first- and second-order interactions. Significant effects were declared at P < 0.01. Drought effects (Drought – Control) were computed for all VxT combinations and used for the hierarchical grouping of CDPK genes visualised by a dendrogram (Euclidean distance, UPGMA algorithm). Computations were done in Genstat 15 (VSN International 2012).
Results
Barley CDPK genes: identification and chromosome distribution
We conducted a genome-wide analysis of the barley CDPK gene family using the recently completed H. vulgare genome sequence (Mayer et al. 2011). Structural verification of the candidate CDPK protein sequences revealed a total of 27 genes (Table 1). The majority of them (19 genes with MLOC numbers) were annotated as protein kinases in the Ensembl Plants reference set (also supported by BarleyDB transcripts). However, three sequences were found only as low confidence gene candidates in the IPK Gattersleben dataset (supported by BarleyDB transcripts), while the remaining five candidates were found only among the BarleyDB transcripts available through the NCBI/GenBank database. Ten of the calcium-dependent kinase genes identified in the barley genome were found to contain myristoylation sites at their N-terminus (Table 1). Most of the barley CDPKs consisted of seven or eight exons, a pattern that is common to most plant CDPK genes (Fig. 2). Our proposed nomenclature of the newly annotated genes is based on similarity to corresponding rice kinases.

Genomic structures of barley CDPK genes. The intron/exon structures of CDPK genes was determined using Scipio (http://www.webscipio.org/), based on the protein sequence. Exons are marked with dark grey boxes. The ped lines indicate places where the coding sequence was not identified. The characteristic domains were visualised by PROSITE (http://prosite.expasy.org/; Sigrist et al. 2013). In case of incomplete sequence of HvCPK27, the structures of homologous OsCPK27 were presented additionally
The 18 high confidence genes were distributed among all barley chromosomes, save for chromosome 4 (Fig. 3). As many as 11 CDPK genes were found on just two chromosomes (2 and 5). Three additional genes were localised to chromosome 3, while two candidates were found on chromosome 6. The first and seventh chromosomes carry only one CDPK gene. No adjacent clusters of CDPK genes were observed, suggesting that these genes have not undergone tandem duplications in recent evolution involving genes encoding CDPKs. Notably, 15 out of 18 CDPK genes were localised within ancestrally duplicated genome segments (shared between barley and rice), suggesting that these kinase genes may have arisen via segmental duplication events predating the divergence of barley and rice. Three CDPK genes, namely HvCPK20, HvCPK4 and HvCPK25/26, were not found on any of the ancestral duplicated genome segments, implicating either different scenarios (segmental duplication in rice only for HvCPK25/26, possible rearrangements for HvCPK4 and HvCPK20) or mistakes in the annotation of the barley genome assembly, which is still under construction. Similarly, the close chromosomal positions of HvCPK10 and HvCPK11 (similar placement across all three monocots, divergence predating separation of monocot and dicot lineages; see Fig. 4 and Online Resource 5) suggests either a rearrangement or a segmental duplication predating said separation (in addition to monocot-specific duplications of individual genes).

Chromosomal distribution of CDPK genes in the barley genome. The chromosome numbers are shown at the bottom. The black arrows and numbers indicate the approximate position of particular genes (MEGABLAST vs. Ensembl Plants). Ancestral duplicated genome segments determined on the basis of shared synteny between barley and rice (Thiel et al. 2009) are indicated by coloured boxes

Orthologous relationships between monocot CDPKs. Rice and barley CDPK genes are indicated by numbers in yellow and red boxes, respectively, placed next to a particular accession number. The tree was rescaled for ultrametricity using the ETE toolkit. a Evolutionary relatedness of two orthologous monocot genes and Arabidopsis paralogue. b Evolutionary relatedness of two orthologous monocot genes and four Arabidopsis paralogues, which arose as a result of post-divergence duplications
Phylogenetic analysis
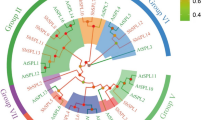
Comparative analysis was conducted on a set of six plant genomes, which enabled study of the evolutionary relationships between the recently annotated barley CDPK complement and the reannotated sets of CDPK genes from well-characterised model species (e.g. O. sativa and A. thaliana) (Online Resources 3–5). The final analysis was based on conserved regions of the corresponding protein sequence (>70 % representation in multiple alignment) (Online Resource 6). The support at most key nodes of the resolved tree was high; in particular, CDPK groups I–VI were all well-supported clades. The first four monophyletic groups have been reported previously (Asano et al. 2005; Li et al. 2008), while groups V (unique to C. reinhardtii) and VI (unique to P. patens) are novel. However, the ancient events corresponding to divergence between ancestral CDPK groups are not satisfactorily resolved by our analysis (support for the respective bipartitions is below 50 %). Since the mapping step of reconciliation (Page 1994) is a top-to-bottom approach where later events are resolved first, low confidence in the order of these early bipartitions does not impact the resolution of individual duplication/speciation events closer to the leaves.
Notably, the analysis points to independent duplications and subsequent diversification of CDPK complements in all major lineages analysed (algae, mosses, dicots, monocots) (Online Resources 3–5). The C. reinhardtii genome has its own monophyletic, extensively duplicated CDPK complement (group V). In the case of P. patens, the extensively duplicated monophyletic group VI, as well as subclades within groups I and III, are unique to this model moss genome. The dicot CDPKs (inferred from the A. thaliana genome) are typically paralogous (with multiple copies retained) relative to monocots. Subgroups that were previously distinguished in groups II and III (Li et al. 2008; Ray et al. 2007) are not validated by this reconstruction.
Phylogenetic analysis based on amino acid sequences distinguished closely related pairs of barley CDPKs: HvCPK4/18, HvCPK1/15, HvCPK2/14, HvCPK3/16, HvCPK21/22, HvCPK8/20, HvCPK24/28, HvCPK11/17, HvCPK10/27 and HvCPK5/13 (Online Resources 3–5). The majority of CDPKs in the monocots examined are orthologous (Fig. 4), but two exceptions were noticed (Fig. 5). First, an orthologue of OsCPK23 was not found in barley. Second, the genes OsCPK25 and OsCPK26 represent an exception in that they are most likely the result of a recent duplication after the separation of the rice and barley lineages. Additionally, the presence of one gene in the barley genome (defined as HvCPK25/26) and two paralogues in B. distachyon indicates a complex gene duplication and gene loss scenario.

Paralogous relationships between monocot CDPKs. Rice and barley CDPK genes are indicated by numbers in the yellow and red boxes, respectively, placed next to a particular accession number. The tree was rescaled for ultrametricity using the ETE toolkit. a Clad containing OsCPK23 and OsCPK7 genes where absence of the orthologue of OsCPK23 in barley genome was identified. b Clad containing genes OsCPK25, OsCPK26 and their paralogues, which arose as a result of complex duplication and gene loss processes
Barley CDPK gene expression
We quantified transcript levels of the majority of the studied genes (25 CDPKs) by quantitative PCR (Q-PCR). However, in most cases, we observed low levels of expression and, indeed, there was no expression of HvCPK6 and HvCPK25/26 at all. In leaf tissues, the 25 CDPK genes responded differently to water deficit: detailed expression profiles over time are presented in Fig. 6. In particular, three genes (HvCPK7, HvCPK8 and HvCPK2) were markedly upregulated. As expected, the shape of the expression profile (e.g. HvCPK24, HvCPK19) or the expression level (e.g. HvCPK17, HvCPK27) of different CDPK genes depended on the variety of barley. However, eight CDPK genes had similar expression patterns in the two varieties under study.

Barley CDPK gene expression profiles in response to intensifying drought stress conditions detected in Sebastian (green line) and Georgie (red line) varieties. Numbers of days (1, 2 and 4) correspond to a field capacity (pF) of 3.2, 3.6, and 4.2, respectively. Relative quantification was determined by Q-PCR analysis (with ADP-ribosylation factor gene as internal controls). Vertical bars correspond to standard errors of the mean values
Analysis of variance (ANOVA) showed 19 significant main drought effects or their modifications by variety (Sebastian and Georgie) or time for 11 genes (Table 2). The ANOVA was carried out for subsets of time points and showed that seven effects (for seven genes) and 18 effects (for ten genes) could be declared significant when considering only days (1, 2) and (2, 4), respectively. This shows that significant changes in gene expression take place mainly during the later stages of drought.
The members of a pair of gene homologues are either expressed differently or similarly to each other, implying that either sub-functionalisation or conservation of expression patterns, respectively, has occurred after the duplication event. In the case of one pair (HvCPK5/13), this similarity of expression patterns was supported by ANOVA, showing that the effects of drought and drought modified by time point are significant for both gene homologues.
Discussion
CDPK activity was first reported in shoot membranes of pea (Pisum sativum; Hetherington and Trewavas 1982) and has since been identified and characterised in many plants and some protozoa (Harmon et al. 2000). To date, the full set of CDPKs has not been described for barley, chiefly due to limited genome sequence information. The recent publication of an ordered, information-rich scaffold of the barley genome (Mayer et al. 2011) provided a valuable framework for the research described in this paper.
All identified sequences share a high degree of protein and nucleotide similarity and possess typical CDPK protein architecture, except an incomplete sequence of HvCPK27 annotated on the basis of high sequence similarity to the rice gene (OsCPK27), which contains only the N-terminal and kinase domain. The majority of barley CDPKs (19) were identified in the Ensembl Plants H. vulgare reference set, while three further sequences were found in the low confidence gene subset (containing potential gene fragments). The five genes were corroborated solely by BarleyDB data (Matsumoto et al. 2011). These sequences could not, however, be directly associated with the genetically anchored physical map (International Barley Genome Sequencing Consortium 2012). In previous studies, such in silico analysis of transcriptome data enabled the identification of four H. vulgare EST contigs representing full-size CDPK family members expressed in the barley leaf epidermis (Freymark et al. 2007).
The CDPK-encoding genes with assigned genome locations (18) are, like in rice (Asano et al. 2005), randomly dispersed throughout the genome. This observation, together with the high sequence similarity of all barley CDPK genes, indicates that they were derived from segmental rather than tandem duplication. Conversely, in the case of A. thaliana, a set of five genes (AtCPK31, AtCPK27, AtCPK22, AtCPK21 and AtCPK23) classified in the same monophyletic group is tandemly arranged in the same transcriptional orientation on chromosome 4, indicating that they may have arisen from a relatively recent gene duplication (Cheng et al. 2002).
The evolutionary relationships outlined in our study are consistent with independent diversification of CDPK complements in all major lineages analysed via extensive duplication(s) and differential loss of resulting copies. A likely origin of the observed copies lies in the ancestral whole-genome duplications inferred at the base of many extant lineages. Such an explanation is in line with the documented tendency for organisms to preferentially retain neofunctionalised duplicates of regulatory toolkit components (such as kinases) arising from whole-genome duplication events (Jiao et al. 2011, 2012; Tang et al. 2010). In particular, the resolution of triplets (close homologues present in all three model monocot genomes) indicates that the respective ancestral duplications most often took place before the divergence of monocot genomes (about 50–70 MYA; Kellogg 2001). Consequently, dicot CDPKs (as typified by A. thaliana) are typically paralogous to those of monocots. This result, together with the aforementioned differences in chromosome distribution, indicates that dicot CDPKs should not be employed as a model in studies based on orthology-derived assumptions. The present evidence also points to the majority of monocot CDPKs being orthologous, although there are some exceptions. For example, the absence of an OsCPK23 orthologue seems to be barley-specific, as a counterpart of this gene is present in B. distachyon. Furthermore, the OsCPK25 and OsCPK26 sequences are very similar to each other at the nucleotide level (99.3 %) (Asano et al. 2005) and are located in the duplicated regions of chromosomes 11 and 12, respectively. Therefore, OsCPK25 and OsCPK26 may have arisen through a recent rice-specific segmental duplication. The two paralogues present in B. distachyon most likely arose before monocot divergence, implicating a complex scenario of duplication and independent loss in the different monocot lineages.
Based on sequence similarity, pairs of CDPK genes can be distinguished: ten in barley and 12 in both rice and B. distachyon. The ubiquity of duplicated CDPK genes in the studied monocot species indicates that these duplications took place before the barley–rice and barley–B. distachyon lineage separations. This also implies that the current complement evolved as a consequence of selection rather than random drift, because gene duplicates should have a short lifespan without selection (Force et al. 1999). The divergence time of rice CDPK gene pairs, estimated on the basis of the individual duplication events, is considered to be ∼50 MYA (Ramakrishna et al. 2002).
The results of our comparative phylogenetic analysis point to the majority of monocot CDPKs being orthologous and placed within ancestrally duplicated regions previously identified between barley and rice (Thiel et al. 2009). Including more species in subsequent studies will probably increase the resolution of duplication events, but it is unlikely to challenge the hypothesis of independent diversification of CDPK complements.
Our expression analysis indicates that almost all of the barley CDPK genes identified are functionally active (25 of 27 genes). The two genes for which transcripts were not detected (HvCPK6 and HvCPK25/26) may be expressed in different plant tissues, or only in response to certain stimuli, or at a specific developmental stage. It has been reported (Ray et al. 2007) that rice homologues of these genes are expressed during panicle development. The evidence for HvCPK25/26 being expressed specifically in flower organs is supported by the observation that full-length cDNA corresponding to this gene deposited in BarleyDB was, indeed, isolated from early stage flowers (Matsumoto et al. 2011). Such data are, unfortunately, not available for HvCPK6.
The number of barley CDPK genes responds differently to water deficiency: ANOVA indicates that, for 11 genes, the drought effect or its modifications by variety or time are significant. This suggests that multiple CDPKs are regulated in a coordinated response to a single stress stimulus. The expressed kinases localise in many different cellular compartments (Harper et al. 2004). Additionally, CDPKs also differ in their affinity for Ca2+ ions (Hrabak et al. 1996). Their sensitivity to calcium can be modulated both by the type of protein substrate and by defects in one or more of their EF hands. The observed differences in affinity might mean that each calcium-dependent protein responds to a specific set of calcium signals, which, in turn, differ in frequency of oscillation, magnitude and duration, depending on the stimulus (McAinsh and Pittman 2009). Thus, different CDPKs even within the same subgroup may have distinct roles at different stages of a plant’s reaction to biotic and abiotic stresses. Calcium-dependent proteins are involved in complex interactions with mitogen-activated protein kinase (MAPK) cascades and other sensors. For example, the different Ca2+ signatures associated with diverse microbe-associated molecular patterns (MAMPs) may be decoded by distinct CDPKs and, thus, partially account for differential MAMP responses (Boudsocq et al. 2010). Additionally, a given signal can induce a different Ca2+ signature in different cell types (Kiegle et al. 2000) and, consequently, affect a different response in downstream signalling pathway components. Moreover, highly modulated plant responses to environmental stimuli are likely the outcome of cross-talk between Ca2+-dependent and Ca2+-independent transduction pathways (Mehlmer et al. 2010). Taking into account the above, our observations confirm that regulatory CDPKs should be regarded as multi-functional genes that partake in complicated signalling networks affecting a specific response through different calcium sensitivities, expression, cellular localisations and substrate regulation.
In water deficiency conditions, the barley CDPK genes HvCPK7, HvCPK8 and HvCPK2 were highly induced, which implies their involvement in drought stress signalling and adaptation. Similar studies on rice (Ray et al. 2007; Wan et al. 2007) showed that the OsCPK13 gene was always highly upregulated by drought stress. Additionally, overexpression of this gene was found to confer significant cold and drought/salt tolerance on rice plants (Saijo et al. 2000). In wheat (Triticum aestivum L.), the orthologue of OsCPK13 (TaCPK2) seems to have lost its ability to respond to biotic stresses, while three other CDPK genes (TaCPK1, TaCPK6 and TaCPK9; homologues of OsCPK7, OsCPK18 and OsCPK11, respectively) were upregulated by drought (Li et al. 2008). Such discrepancies in expression levels between rice, wheat and barley CDPKs indicate that the regulatory competences of particular kinases are likely species-specific. Moreover, our analysis of two varieties of barley suggests that CDPK gene regulation can also be genotype-specific. Previously functional studies in barley have demonstrated that two CDPK paralogues, namely HvCDPK3 and HvCDPK4 (HvCPK19 and HvCPK13, in this study, respectively), play antagonistic roles during the early phase of powdery mildew pathogenesis (Freymark et al. 2007). In addition, HvCDPK1 (HvCPK1) has already been implicated in the gibberellic acid response of the barley aleurone through regulation of vacuolar function (McCubbin et al. 2004). In the context of our results, these findings indicate that the same calcium-dependent proteins can be involved in different signal transduction pathways, as well as being implicated in adaptations to differing stimuli.
In summary, the barley CDPK complement of 27 genes was identified and characterised in this study. The different pattern of response of the CDPK genes under water deficiency conditions constitutes evidence for their involvement in signal transduction pathways relating to adaptation to drought. A precise definition of the role of CDPK genes in transduction pathways requires further studies, including the definition of isoform-specific calcium activation thresholds, substrate specificities and subcellular locations.
References
Altschul SF, Gish W, Miller W, Myers EW, Lipman DJ (1990) Basic local alignment search tool. J Mol Biol 215:403–410
Asano T, Tanaka N, Yang G, Hayashi N, Komatsu S (2005) Genome-wide identification of the rice calcium-dependent protein kinase and its closely related kinase gene families: comprehensive analysis of the CDPKs gene family in rice. Plant Cell Physiol 46:356–366. doi:10.1093/pcp/pci035
Bose J, Pottosin II, Shabala SS, Palmgren MG, Shabala S (2011) Calcium efflux systems in stress signaling and adaptation in plants. Front Plant Sci 2:85. doi:10.3389/fpls.2011.00085
Boudsocq M, Willmann MR, McCormack M, Lee H, Shan L, He P et al (2010) Differential innate immune signalling via Ca2+ sensor protein kinases. Nature 464:418–422. doi:10.1038/nature08794
Breviario D, Morello L, Giani S (1995) Molecular cloning of two novel rice cDNA sequences encoding putative calcium-dependent protein kinases. Plant Mol Biol 27:953–967. doi:10.1007/BF00037023
Capella-Gutiérrez S, Silla-Martínez JM, Gabaldón T (2009) trimAl: a tool for automated alignment trimming in large-scale phylogenetic analyses. Bioinformatics 25:1972–1973. doi:10.1093/bioinformatics/btp348
Cheng SH, Willmann MR, Chen HC, Sheen J (2002) Calcium signaling through protein kinases. The Arabidopsis calcium-dependent protein kinase gene family. Plant Physiol 129:469–485. doi:10.1104/pp.005645
Darriba D, Taboada GL, Doallo R, Posada D (2011) ProtTest 3: fast selection of best-fit models of protein evolution. Bioinformatics 27(8):1164–1165. doi:10.1093/bioinformatics/btr088
Dinkel H, Van Roey K, Michael S, Davey NE, Weatheritt RJ, Born D et al (2014) The eukaryotic linear motif resource ELM: 10 years and counting. Nucleic Acids Res 42(Database issue):D259–D266. doi:10.1093/nar/gkt1047
Evans NH, McAinsh MR, Hetherington AM (2001) Calcium oscillations in higher plants. Curr Opin Plant Biol 4:415–420. doi:10.1016/S1369-5266(00)00194-1
Finn RD, Clements J, Eddy SR (2011) HMMER web server: interactive sequence similarity searching. Nucleic Acids Res 39(Web Server issue):W29–W37. doi:10.1093/nar/gkr367
Force A, Lynch M, Pickett FB, Amores A, Yan YL, Postlethwait J (1999) Preservation of duplicate genes by complementary, degenerative mutations. Genetics 151:1531–1545
Frattini M, Morello L, Breviario D (1999) Rice calcium-dependent protein kinase isoforms OsCDPK2 and OsCDPK11 show different responses to light and different expression patterns during seed development. Plant Mol Biol 41(6):753–764
Freymark G, Diehl T, Miklis M, Romeis T, Panstruga R (2007) Antagonistic control of powdery mildew host cell entry by barley calcium-dependent protein kinases (CDPKs). Mol Plant Microbe Interact 20(10):1213–1221. doi:10.1094/MPMI−20-10-1213
Gouy M, Guindon S, Gascuel O (2010) SeaView version 4: a multiplatform graphical user interface for sequence alignment and phylogenetic tree building. Mol Biol Evol 27(2):221–224. doi:10.1093/molbev/msp259
Harmon AC, Gribskov M, Harper JF (2000) CDPKs—a kinase for every Ca2+ signal? Trends Plant Sci 5:154–159. doi:10.1016/S1360-1385(00)01577-6
Harper JF, Breton G, Harmon A (2004) Decoding Ca2+ signals through plant protein kinases. Annu Rev Plant Biol 55:263–288. doi:10.1146/annurev.arplant.55.031903.141627
Hetherington A, Trewavas A (1982) Calcium-dependent protein kinase in pea shoot membranes. Febs Letters 145(1):67–71
Hrabak EM, Dickmann LJ, Satterlee JS, Sussman MR (1996) Characterization of eight new members of the calmodulin-like domain protein kinase gene family from Arabidopsis thaliana. Plant Mol Biol 31:405–412. doi:10.1007/BF00021802
Hrabak EM, Chan CW, Gribskov M, Harper JF, Choi JH, Halford N et al (2003) The Arabidopsis CDPK-SnRK superfamily of protein kinases. Plant Physiol 132:666–680. doi:10.1104/pp.102.011999
Huerta-Cepas J, Dopazo J, Gabaldón T (2010) ETE: a python Environment for Tree Exploration. BMC Bioinformatics 11:24. doi:10.1186/1471-2105-11-24
International Barley Genome Sequencing Consortium (2012) A physical, genetic and functional sequence assembly of the barley genome. Nature 491:711–716. doi:10.1038/nature11543
Jiao Y, Wickett NJ, Ayyampalayam S, Chanderbali AS, Landherr L, Ralph PE et al (2011) Ancestral polyploidy in seed plants and angiosperms. Nature 473(7345):97–100
Jiao Y, Leebens-Mack J, Ayyampalayam S, Bowers JE, McKain MR, McNeal J et al (2012) A genome triplication associated with early diversification of the core eudicots. Genome Biol 13(1):R3
Katoh K, Toh H (2010) Parallelization of the MAFFT multiple sequence alignment program. Bioinformatics 26(15):1899–1900. doi:10.1093/bioinformatics/btq224
Keller O, Odronitz F, Stanke M, Kollmar M, Waack S (2008) Scipio: using protein sequences to determine the precise exon/intron structures of genes and their orthologs in closely related species. BMC Bioinformatics 9:278. doi:10.1186/1471-2105-9-278
Kellogg EA (2001) Evolutionary history of the grasses. Plant Physiol 125:1198–1205. doi:10.1104/pp.125.3.1198
Kiegle E, Moore CA, Haseloff J, Tester MA, Knight MR (2000) Cell-type-specific calcium responses to drought, salt and cold in the Arabidopsis root. Plant J 23:267–278. doi:10.1046/j.1365-313x.2000.00786.x
Klimecka M, Muszyńska G (2007) Structure and functions of plant calcium-dependent protein kinases. Acta Biochim Pol 54:219–233
Komatsu S, Yang G, Khan M, Onodera H, Toki S, Yamaguchi M (2007) Over-expression of calcium-dependent protein kinase 13 and calreticulin interacting protein 1 confers cold tolerance on rice plants. Mol Genet Genomics 277:713–723. doi:10.1007/s00438-007-0220-6
Kong X, Lv W, Jiang S, Zhang D, Cai G, Pan J, Li D (2013) Genome-wide identification and expression analysis of calcium-dependent protein kinase in maize. BMC Genomics 14:433
Le SQ, Gascuel O (2008) An improved general amino acid replacement matrix. Mol Biol Evol 25(7):1307–1320. doi:10.1093/molbev/msn067
Lecourieux D, Ranjeva R, Pugin A (2006) Calcium in plant defence-signalling pathways. New Phytol 171:249–269. doi:10.1111/j.1469-8137.2006.01777.x
Li AL, Zhu YF, Tan XM, Wang X, Wei B, Guo HZ et al (2008) Evolutionary and functional study of the CDPK gene family in wheat (Triticum aestivum L.). Plant Mol Biol 66(4):429–443. doi:10.1007/s11103-007-9281-5
Matsumoto T, Tanaka T, Sakai H, Amano N, Kanamori H, Kurita K et al (2011) Comprehensive sequence analysis of 24,783 barley full-length cDNAs derived from 12 clone libraries. Plant Physiol 156:20–28. doi:10.1104/pp.110.171579
Mayer KFX, Martis M, Hedley PE, Šimková H, Liu H, Morris JA et al (2011) Unlocking the barley genome by chromosomal and comparative genomics. Plant Cell 23:1249–1263. doi:10.1105/tpc.110.082537
McAinsh MR, Pittman JK (2009) Shaping the calcium signature. New Phytol 181:275–294. doi:10.1111/j.1469-8137.2008.02682.x
McCubbin AG, Ritchie SM, Swanson SJ, Gilroy S (2004) The calcium-dependent protein kinase HvCDPK1 mediates the gibberellic acid response of the barley aleurone through regulation of vacuolar function. Plant J 39(2):206–218. doi:10.1111/j.1365-313x.2004.02121.x
Mehlmer N, Wurzinger B, Stael S, Hofmann-Rodrigues D, Csaszar E, Pfister B et al (2010) The Ca2+-dependent protein kinase CPK3 is required for MAPK-independent salt-stress acclimation in Arabidopsis. Plant J 63:484–498. doi:10.1111/j.1365-313X.2010.04257.x
Morello L, Frattini M, Gianì S, Christou P, Breviario D (2000) Overexpression of the calcium-dependent protein kinase OsCDPK2 in transgenic rice is repressed by light in leaves and disrupts seed development. Transgenic Res 9:453–462
Mori IC, Murata Y, Yang Y, Munemasa S, Wang YF, Andreoli S et al (2006) CDPKs CPK6 and CPK3 function in ABA regulation of guard cell S-type anion- and Ca2+-permeable channels and stomatal closure. PLoS Biol 4(10), e327. doi:10.1371/journal.pbio.0040327
Page RD (1994) Maps between trees and cladistic analysis of historical associations among genes, organisms, and areas. Syst Biol 43:58–77
Page RD, Charleston MA (1997) From gene to organismal phylogeny: reconciled trees and the gene tree/species tree problem. Mol Phylogenet Evol 7(2):231–240
Punta M, Coggill PC, Eberhardt RY, Mistry J, Tate J, Boursnell C et al (2012) The Pfam protein families database. Nucleic Acids Res 40(Database Issue):D290–D301
Ramakrishna W, Dubcovsky J, Park YJ, Busso C, Emberton J, SanMiguel P et al (2002) Different types and rates of genome evolution detected by comparative sequence analysis of orthologous segments from four cereal genomes. Genetics 162:1389–1400
Rapacz M, Stępień A, Skorupa K (2012) Internal standards for quantitative RT-PCR studies of gene expression under drought treatment in barley (Hordeum vulgare L.): the effects of developmental stage and leaf age. Acta Physiol Plant 34(5):1723–1733. doi:10.1007/s11738-012-0967-1
Ray S, Agarwal P, Arora R, Kapoor S, Tyagi AK (2007) Expression analysis of calcium-dependent protein kinase gene family during reproductive development and abiotic stress conditions in rice (Oryza sativa L. ssp. indica). Mol Genet Genomics 278:493–505. doi:10.1007/s00438-007-0267-4
Reddy AS (2001) Calcium: silver bullet in signaling. Plant Sci 160:381–404
Romeis T, Ludwig AA, Martin R, Jones JDG (2001) Calcium-dependent protein kinases play an essential role in a plant defence response. EMBO J 20(20):5556–5567
Saijo Y, Hata S, Kyozuka J, Shimamoto K, Izui K (2000) Over-expression of a single Ca2+-dependent protein kinase confers both cold and salt/drought tolerance on rice plants. Plant J 23:319–327. doi:10.1046/j.1365-313x.2000.00787.x
Sanders D, Pelloux J, Brownlee C, Harper JF (2002) Calcium at the crossroads of signaling. Plant Cell 14(Suppl):S401–S417
Sayers EW, Barrett T, Benson DA, Bryant SH, Canese K, Chetvernin V et al (2009) Database resources of the National Center for Biotechnology Information. Nucleic Acids Res 37(Database issue):D5–D15. doi:10.1093/nar/gkn741
Schmittgen TD, Livak KJ (2008) Analyzing real-time PCR data by the comparative CT method. Nat Protoc 3:1101–1108. doi:10.1038/nprot.2008.73
Sigrist CJA, de Castro E, Cerutti L, Cuche BA, Hulo N, Bridge A et al (2013) New and continuing developments at PROSITE. Nucleic Acids Res 41(Database issue):D344–D347. doi:10.1093/nar/gks1067
Stamatakis A (2006) RAxML-VI-HPC: maximum likelihood-based phylogenetic analyses with thousands of taxa and mixed models. Bioinformatics 22(21):2688–2690
Stamatakis A, Hoover P, Rougemont J (2008) A rapid bootstrap algorithm for the RAxML Web servers. Syst Biol 57(5):758–771
Tang H, Bowers JE, Wang X, Paterson AH (2010) Angiosperm genome comparisons reveal early polyploidy in the monocot lineage. Proc Natl Acad Sci U S A 107(1):472–477
Thiel T, Graner A, Waugh R, Grosse I, Close TJ, Stein N (2009) Evidence and evolutionary analysis of ancient whole-genome duplication in barley predating the divergence from rice. BMC Evol Biol 9:209. doi:10.1186/1471-2148-9-209
VSN International (2012) GenStat for Windows 15th Edition. VSN International, Hemel Hempstead, UK. Web page: GenStat.co.uk
Wan B, Lin Y, Mou T (2007) Expression of rice Ca2+-dependent protein kinases (CDPKs) genes under different environmental stresses. FEBS Lett 581:1179–1189. doi:10.1016/j.febslet.2007.02.030
Winer BJ (1962) Statistical principles in experimental design, 2nd edn. McGraw-Hill, New York
Yu X-C, Zhu S-Y, Gao G-F, Wang X-J, Zhao R, Zou K-Q et al (2007) Expression of a grape calcium-dependent protein kinase ACPK1 in Arabidopsis thaliana promotes plant growth and confers abscisic acid-hypersensitivity in germination, postgermination growth, and stomatal movement. Plant Mol Biol 64:531–538. doi:10.1007/s11103-007-9172-9
Zhu SY, Yu XC, Wang XJ, Zhao R, Li Y, Fan RC et al (2007) Two calcium-dependent protein kinases, CPK4 and CPK11, regulate abscisic acid signal transduction in Arabidopsis. Plant Cell 19:3019–3036. doi:10.1105/tpc.107.050666
Acknowledgments
The authors thank Prof. Alan Tunnacliffe for the critical reading of the manuscript. This work was supported by the European Regional Development Fund through the Innovative Economy Program for Poland 2007–2013, project WND-POIG.01.03.01-00-101/08 POLAPGEN-BD “Biotechnological tools for breeding cereals with increased resistance to drought.” The project is realised by POLAPGEN Consortium coordinated by the Institute of Plant Genetics, Polish Academy of Sciences in Poznan. Further information about the project can be found at http://www.polapgen.pl.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Additional information
Communicated by: Andrzej Górny
Electronic supplementary material
Below are the links to the electronic supplementary material.
ESM 1
The soil water retention curve (pF curve) drawn for soil used in the study (kindly provided by Prof. Grzegorz Józefaciuk, The Bohdan Dobrzanski Institute of Agrophysics of Polish Academy of Sciences, Lublin, Poland). The black ovals designate pF values at which plant material was taken. (JPG 23 kb)
ESM 2
Gene-specific primers used in real-time polymerase chain reaction (PCR) amplification. (PDF 269 kb)
ESM 3
Comparative phylogenetic tree constructed on a set of six model plant genomes (Chlamydomonas reinhardtii, Physcomitrella patens ssp. patens, Arabidopsis thaliana, Brachypodium distachyon, Oryza sativa ssp. japonica, Hordeum vulgare ssp. vulgare): a, b and c, respectively. (PDF 2180 kb)
ESM 4
Comparative phylogenetic tree constructed on a set of six model plant genomes (Chlamydomonas reinhardtii, Physcomitrella patens ssp. patens, Arabidopsis thaliana, Brachypodium distachyon, Oryza sativa ssp. japonica, Hordeum vulgare ssp. vulgare): a, b and c, respectively. (PDF 1904 kb)
ESM 5
Comparative phylogenetic tree constructed on a set of six model plant genomes (Chlamydomonas reinhardtii, Physcomitrella patens ssp. patens, Arabidopsis thaliana, Brachypodium distachyon, Oryza sativa ssp. japonica, Hordeum vulgare ssp. vulgare): a, b and c, respectively. (PDF 2077 kb)
ESM 6
The multiple alignments of analysed sequences. (PDF 112 kb)
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

{kind=link}
Cite this article
Fedorowicz-Strońska, O., Koczyk, G., Kaczmarek, M. et al. Genome-wide identification, characterisation and expression profiles of calcium-dependent protein kinase genes in barley (Hordeum vulgare L.). J Appl Genetics 58, 11–22 (2017). https://doi.org/10.1007/s13353-016-0357-2
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s13353-016-0357-2