
Abstract
Reservoir fluid properties such as bubble point pressure, oil formation volume factor and viscosity are very important in reservoir and petroleum production engineering computations such as outflow–inflow well performance, material balance calculations, well test analysis, reserve estimates, and numerical reservoir simulations. Ideally, these properties should be obtained from actual measurements. Quite often, however, these measurements are either not available or very costly to obtain. In such cases, empirically derived correlations are used to predict the needed properties using the known properties such as temperature, specific gravity of oil and gas, and gas–oil ratio. Therefore, all computations depend on the accuracy of the correlations used for predicting the fluid properties. Almost all of these previous correlations were developed with linear or nonlinear multiple regression or graphical techniques. Artificial neural networks, once successfully trained, offer an alternative way to obtain reliable and more accurate results for the determination of crude oil PVT properties, because it can capture highly nonlinear behavior and relationship between the input and output data as compared to linear and nonlinear regression techniques. In this study, we present neural network-based models for the prediction of PVT properties of crude oils from Pakistan. The data on which the networks were trained and tested contain 166 data sets from 22 different crude oil samples and used in developing PVT models for Pakistan crude oils. The developed neural network models are able to predict the bubble point pressure, oil formation volume factor and viscosity as a function of the solution gas–oil ratio, gas specific gravity, oil specific gravity, and temperature. A detailed comparison between the results predicted by the neural network models and those predicted by other previously published correlations shows that the developed neural network models outperform most other existing correlations by giving significantly lower values of average absolute relative error for the bubble point, oil formation volume factor at bubble point, and gas-saturated oil viscosity.
Similar content being viewed by others

Introduction
During the last 70 years, engineers developed a significant number of PVT correlations due to the high importance empirical correlations for PVT properties in oil and gas engineering. These correlations are sensitive to the region and number of data points. PVT correlations accuracy varies from one region to another. Therefore, significant numbers of correlations have been developed based on the regional variation, and it is recommended in the previous studies that one should use their own region PVT correlation. A brief overview of the widely used PVT correlation is give below.
Standing (1947, 1977) presented correlations for bubble point pressure and oil formation volume factor. Standing’s correlations were based on laboratory experiments carried out on 105 samples from 22 different crude oils in California. Katz (1942) presented five methods for predicting the reservoir oil shrinkage. Vazquez and Beggs (1980) presented correlations for oil formation volume factor. They divided oil mixtures into two groups, above and below 30 ° API gravity. More than 6000 data points from 600 laboratory measurements were used in developing the correlations. Glaso (1980) developed the correlation for formation volume factor using 45 oil samples from North Sea hydrocarbon mixtures. Al-Marhoun (1988) published correlations for estimating bubble point pressure and oil formation volume factor for the Middle East oils. He used 160 data sets from 69 Middle Eastern reservoirs to develop the correlation. Abdul-Majeed and Salman (1988) published an oil formation volume factor correlation based on 420 data sets. Their model is similar to that of Al-Marhoun (1988) oil formation volume factor correlation with new calculated coefficients.
Labedi (1990) presented correlations for oil formation volume factor for African crude oils. He used 97 data sets from Libya, 28 from Nigeria, and 4 from Angola to develop his correlations. Dokla and Osman (1992) published a set of correlations for estimating bubble point pressure and oil formation volume factor for UAE crudes. They used 51 data sets to calculate new coefficients for Al-Marhoun (1988) Middle East models. Al-Yousef and Al-Marhoun (1993) pointed out that the Dokla and Osman (1992, 1993) bubble point pressure correlation was found to contradict the physical laws. Al-Marhoun (1992) published a second correlation for oil formation volume factor. The correlation was developed with 11,728 experimentally obtained formation volume factors at, above, and below the bubble point pressure. The data set represents samples from more than 700 reservoirs from all over the world, mostly from Middle East and North America.
Macary and El-Batanoney (1992) presented correlations for bubble point pressure and oil formation volume factor. They used 90 data sets from 30 independent reservoirs in the Gulf of Suez to develop the correlations. The new correlations were tested against other Egyptian data of Saleh et al. (1987), and showed improvement over published correlations. Omar and Todd (1993) presented oil formation volume factor correlation, based on Standing’s (1947) model. Their correlation was based on 93 data sets from Malaysian oil reservoirs. Petrosky and Farshad (1993) developed new correlations for the Gulf of Mexico.
Kartoatmodjo and Schmidt (1994) used a global data bank to develop new correlations for all PVT properties. Data from 740 different crude oil samples gathered from all over the world provided 5392 data sets for correlation development. Almehaideb (1997) published a new set of correlations for UAE crudes using 62 data sets from UAE reservoirs. These correlations were developed for bubble point pressure and oil formation volume factor. The bubble point pressure correlation of Omar and Todd (1993) uses the oil formation volume factor as input in addition to oil gravity, gas gravity, solution gas oil ratio, and reservoir temperature. Saleh et al. (1987) evaluated the empirical correlations for Egyptian oils. They reported that Standing’s (1947) correlation was the best for oil formation volume factor. Sutton and Farshad (1990a, b) published an evaluation for Gulf of Mexico crude oils. They used 285 data sets for gas-saturated oil and 134 data sets for undersaturated oil representing 31 different crude oils and natural gas systems. The results show that Glaso (1980) correlation for oil formation volume factor perform the best for most of the data of the study. Later, Petrosky and Farshad (1993) published a new correlation based on the Gulf of Mexico crudes. They reported that the best performing published correlation for oil formation volume is the Al-Marhoun (1988) correlation. McCain (1991) published an evaluation of all reservoir properties correlations based on a large global database. He recommended Standing’s (1947) correlations for formation volume factor at and below the bubble point pressure.
Al-Fattah and Al-Marhoun (1994) published an evaluation of all available oil formation volume factor correlations. They used 674 data sets from published literature. They found that Al-Marhoun (1992) correlation has the least error for global data set. Also, they performed trend tests to evaluate the model’s physical behavior. Finally, Al-Shammasi (1997) evaluated the published correlations and neural network models for bubble point pressure and oil formation volume factor for accuracy and flexibility to represent hydrocarbon mixtures from different geographical locations worldwide. He presented a new correlation for bubble point pressure based on global data of 1661 published and 48 unpublished data sets. Also, he presented neural network models and compared their performance to numerical correlations. He concluded that statistical and trend performance analysis showed that some of the correlations violate the physical behavior of hydrocarbon fluid properties.
De Ghetto et al. (1994) performed a comprehensive study on PVT properties correlation based on 195 global data sets collected from the Mediterranean Basin, Africa, Middle East, and the North Sea reservoirs. They recommended Vazquez and Beggs (1980) correlation for the oil formation volume factor. Elsharkawy et al. (1994) evaluated the PVT correlations for Kuwaiti crude oils using 44 samples. Standing’s (1947) correlation gave the best results for bubble point pressure, while Al-Marhoun (1988) oil formation volume factor correlation performed satisfactorily.
Hanafy et al. (1997) published a study to evaluate the most accurate correlation to apply to Egyptian crude oils. For formation volume factor, Macary and El-Batanoney (1992) correlation showed an average absolute error of 4.9 %, while Dokla and Osman (1992) showed 3.9 %. The study strongly supports the approach of developing a local correlation versus a global correlation.
Mahmood and Al-Marhoun (1996) presented an evaluation of PVT correlations for Pakistani crude oils. They used 166 data sets from 22 different crude samples for the evaluation. Al-Marhoun (1992) oil formation volume factor correlation gave the best results. The bubble point pressure errors reported in this study, for all correlations, are among the highest reported in the literature. It is also possible to increase the accuracy by updating the coefficients of Al-Marhoun correlation, but it is not necessary that the update correlation captures nonlinear behavior completely. Therefore, Mahmood and Al-Marhoun (1996) also recommended new PVT correlations for Pakistani crude oils and this recommendation is the basis for this research.
Artificial neural network
Neural networks are composed of simple elements operating in parallel. These elements are inspired by biological nervous systems. We can train a neural network to perform a particular function by adjusting the values of the connections (weights) between elements. Typically, neural networks are adjusted, or trained, so that a particular input leads to a specific target output (MathWorks, Inc 2008).
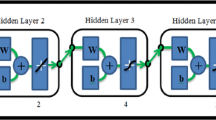
Neural network consists of input and output neurons (elements) and layers, which are connected by further neurons and layers known as hidden layer and hidden layer neurons (Fauset 1996). These neurons are connected in a highly parallel and distributed way, so that they can map any nonlinear complex function as shown in Fig. 1. Each connection in the neural network assigns weights and layers and are connected by transfer functions. The response from each neuron is given by
where x i are the input parameters, i is the index for input parameters, Ni is the total number of input parameters, j is the index for hidden layer neurons, b j is the bias for hidden layer neuron j, y j is the output of hidden layer neuron j, w ji are weights between the input and hidden layer, f is the tan-sigmoid transfer functionand
In this, k is the index for a number of output parameters, b k is the bias for the output layer, w jk are the weights between the hidden and output layer, Nh is the total number of hidden layer neurons, z k are the outputs of the output layer, and f L is the linear transfer function.

Generalized ANN model architecture with input, hidden, and output layer
The work flow for the neural network design process has the following primary steps:
-
Collect data.
-
Create the network.
-
Configure the network.
-
Initialize the weights and biases.
-
Train and validate the network.
-
Test and use the network.
In recent years, neural networks have gained popularity in petroleum applications. Many authors have discussed the applications of neural network in petroleum engineering (Kumoluyi and Daltaban 1994; Ali 1994; Mohaghegh and Ameri 1994; Mohaghegh 1995). Few studies have been carried out to model the PVT properties using neural networks. Gharbi and Elsharkawy (1997) published neural network models for estimating bubble point pressure and oil formation volume factor for Middle East crude oils. Both neural network models were trained using 498 data sets collected from the literature and unpublished sources. The models were tested by other 22 data points from the Middle East. The results showed improvement over the conventional correlation methods with reduction in the average error for the bubble point pressure oil formation volume factor.
Varotsis et al. (1999) presented a novel approach for predicting the complete PVT behavior of reservoir oils and gas condensates using artificial neural network (ANN). The method uses key measurements that can be performed rapidly either in the laboratory or at the well site as input to an ANN. The ANN was trained by a PVT study database of over 650 reservoir fluids originating from all parts of the world. Tests of the trained ANN architecture utilizing a validation set of PVT studies indicate that, for all fluid types, most PVT property estimates can be obtained with a very low mean relative error of 0.5–2.5 %, with no data set having a relative error in excess of 5 %. Osman and Al-Marhoun (2002) developed PVT correlations using ANN for Saudi crude oils. The models were developed using 283 data sets, which were collected from Saudi Reservoirs. Gupta (2010) developed PVT correlations using artificial neural network for Indian crude oils. The models were developed using 372 data sets, which were collected from Indian reservoirs. All of the regional ANN PVT correlations outperform the previously published correlations. Mahmood and Al-Marhoun (1996) presented an evaluation of PVT correlations for Pakistani crude oils. In this study (Mahmood and Al-Marhoun 1996), they concluded that new PVT correlations for Pakistani crude oils are required and therefore this recommendation and conclusion are the basis for this research. Moreover due to the previous success of ANN in regional PVT correlations, ANN is used as an algorithm for PVT correlations of Pakistani crude oil.
Data acquisition and analysis
Data used for this work were collected from Mahmood and Al-Marhoun (1996) publication related to evaluation of PVT correlations for Pakistani crude oil. In general, this data set covers a wide range of bubble point pressure, oil FVF, solution gas/oil ratio, and gas relative density values; whereas the temperature and oil gravity belong to relatively higher values attributed to regional trends prevailing in Pakistani crude oils. Each data set contains reservoir temperature, oil gravity, total solution gas oil ratio, and average gas gravity, bubble point pressure, oil formation volume factor at the bubble point pressure, and viscosity at the bubble point pressure. The data set was randomly divided into two groups of seen data (70 % of total data) and unseen data (30 % of total data). Out of a total of 166 data points, 70 % (seen data by ANN) were used for training, validation, or cross-validation of the ANN models, the remaining 30 % (unseen data by ANN) were used to test the model to evaluate its accuracy. For viscosity at P b data, 128 data points are available in Mahmood and Al-Marhoun’s (1996) publication and these are divided in the same way as bubble point pressure and formation volume factor at P b . A statistical description of training (seen) and test (unseen) data are given in Tables 1 and 2, respectively.
Bubble point pressure artificial neural network model
The bubble point pressure ANN model consists of four input neurons or input parameters, which are related to temperature, specific gravity of gas, API gravity of oil and solution gas–oil ratio, one hidden layer and one output neuron related to bubble point pressure. The hidden layer consists of 12 neurons, which were obtained after sensitivity runs of the number of neurons from 5 to 50. Tan-sigmoid and linear transfer functions were used in the hidden and output layer, respectively. The algorithm of ANN model for bubble point pressure is given below:
The above ANN algorithm for bubble point pressure can also be written in the following way:
Subscript N shows the normalized input and output parameters for ANN model. The bias values are constant and have a similar concept to constants in linear or nonlinear regression. The architecture of the ANN model for bubble point pressure is shown in Fig. 2.

Architecture of ANN model for bubble point pressure
To obtain weights and bias values, training of neural network was performed by Levenberg–Marquardt back-propagation algorithm. To avoid local minimum, 5000 multiple realizations with different weight and bias initialization of training were implemented and the minimum error realization was selected as the best one. After training, the optimal weights and bias values were obtained for bubble point pressure ANN and these are shown in Table 3.
All input parameters should be normalized in the range of [−1, 1] before using in the ANN algorithm for bubble point. The general equation for input normalization is given below:
The x max and x min values (ranges of input parameters) are given in Table 1. Therefore, the input parameters should be normalized by using the following equations:
The proposed ANN model gives normalized bubble point pressure in the range [−1, 1]; therefore for real value of the bubble point pressure, the output value should be de-normalized by the following equation:
where y max and y min values (minimum and maximum bubble point pressures) are given in Table 1. Therefore, the output parameter should be de-normalized by using following equation:
Oil formation volume factor of the P b (B ob) ANN model
The oil formation volume factor of the P b ANN model consists of four input neurons or input parameters, which are related to temperature, specific gravity of gas, API gravity of oil and solution gas–oil ratio, one hidden layer and one output neuron related to B ob. The hidden layer consists of 8 neurons, which were obtained after sensitivity runs of number of neurons from 5 to 50. Tan-sigmoid and linear transfer functions were used in the hidden and output layer, respectively. The algorithm of the ANN model for B ob is given below:
The above ANN algorithm for B ob can also be written in the following way:
Subscript N shows the normalized input and output parameters for ANN model. The bias values are constant values, which have a similar concept to constants in linear or nonlinear regression. The architecture of ANN model for B ob is shown in Fig. 3.

Architecture of ANN model for B ob
To obtain weights and bias values, training of neural network was performed by Levenberg–Marquardt back-propagation algorithm. To avoid local minimum, 5000 multiple realizations with different weight and bias initialization of training were implemented and minimum error realization was selected as the best one. After training, the optimal weights and bias values were obtained for B ob artificial neural network and these are shown in Table 4.
All input parameters should be normalized in the range of [−1, 1] before using in the ANN algorithm for B ob. The procedure for normalization of input parameters is the same as of bubble point ANN algorithm.
The input parameters should be normalized using the following equations for the ANN algorithm of B ob:
The proposed ANN model gives normalized B ob in the range [−1, 1]; therefore for the real value of B ob, the output B ob value should be de-normalized by the following equation:
Viscosity in the P b (µ ob) ANN model
The viscosity in the P b ANN model consists of four input neurons or input parameters, which are related to temperature, specific gravity of gas, API gravity of oil and solution gas–oil ratio, one hidden layer and one output neuron related to µ ob. The hidden layer consists of 26 neurons, which were obtained after sensitivity runs of number of neurons from 5 to 50. Tan-sigmoid and linear transfer functions were used in the hidden and output layer, respectively. It is important to note that the hidden layer neurons in µ ob ANN model is higher than the bubble point and B ob ANN models, because nonlinearity in µ ob is higher than bubble point and B ob. The algorithm of the ANN model for µ ob is given below:
The above ANN algorithm for µ ob can also be written in the following way:
Subscript N shows the normalized input and output parameters for ANN model. The bias values are constant values, which have similar concept to constants in linear or nonlinear regression. The architecture of the ANN model for µ ob is shown in Fig. 4.

Architecture of ANN model for µ ob
To obtain the weights and bias values, the training of neural network was performed by the Levenberg–Marquardt back-propagation algorithm. To avoid local minimum, 5000 multiple realizations with different weight and bias initialization of training were implemented and minimum error realization was selected as the best one. After training, the optimal weights and bias values were obtained for µ ob ANN and these are shown in Table 5.
All input parameters should be normalized in the range of [−1, 1] before using in the ANN algorithm for µ ob. The procedure for normalization of input parameters is the same as of bubble point pressure and B ob ANN algorithms.
The input parameters should be normalized using the following equations for the ANN algorithm of µ ob:
The proposed ANN model gives normalized µ ob in the range [−1, 1]; therefore for real value of µ ob, output µ ob value should be de-normalized by the following equation:
Results and discussion
After training the neural network models for P b , B ob and µ ob, the models become ready for testing and evaluation. To perform this, the first training data set (seen data) and the second testing data set, which were not seen by the neural network during training, were used.
To compare the performance and accuracy of the neural network model of P b to other empirical correlations, five mostly used P b correlations were selected. These are those of Standing (1947), Vazquez and Beggs (1980), Glaso (1980), and Lasater (1958). The statistical results of the comparison are given in Table 6. The ANN model of P b outperforms all these empirical correlations.
To compare the performance and accuracy of the neural network model of B ob to other empirical correlations, five mostly used B ob correlations were selected. These are those of Standing (1947), Vazquez and Beggs (1980), Glaso (1980), and Al-Marhoun (1988, 1992). The statistical results of the comparison are given in Table 7. The ANN model of B ob outperforms all these empirical correlations.
To compare the performance and accuracy of the neural network model of µ ob to other empirical correlations, four mostly used µ ob correlations were selected. These are those of Beggs and Robinson (1975), Chew and Connaly (1959), Khan et al. (1987), and Labedi (1992). The statistical results of the comparison are given in Table 8. The ANN model of µ ob outperforms all these empirical correlations.
The proposed neural network models showed high accuracy in predicting the P b , B ob, and µ ob values, and achieved the lowest relative error, lowest absolute percent relative error, lowest minimum error, lowest maximum error, and lowest standard deviation of relative error.
Conclusion
-
A new ANN model was developed to predict the bubble point pressure, oil formation volume factor at P b , and viscosity at P b . The P b and B ob models were developed using 166 published data sets from the Pakistani crude oil samples. The µ ob model was developed using 128 published data sets from the Pakistani crude oil samples.
-
Out of the 166 data points, 70 % were used to train and cross-validate the ANN models for P b and B ob, and the remaining 30 % used to test the accuracy of P b and B ob models. Similarly, for the µ ob model, out of the 128 data points, 70 % were used to train and cross-validate the ANN model and the remaining 30 % used to test the µ ob accuracy.
-
The results show that the developed models provide better predictions and higher accuracy than the published empirical correlations and have the capability to fulfill the need of more accurate correlations for Pakistani crude oil. The present models provide predictions of P b , B ob, and µ ob with an absolute average percent error of 4.4250, 0.4975, and 2.99 %, respectively, to unseen (testing) data and correlation coefficient of 0.99789, 0.997, and 0.97022, respectively, to unseen (testing) data.
Abbreviations
- API:
-
API gravity of oil
- P b :
-
Bubble point pressure (psi)
- B ob :
-
Oil formation volume factor at the bubble point pressure, RB/STB
- µ ob :
-
Viscosity of oil at bubble point pressure, cp
- Rs:
-
Solution gas–oil ratio, SCF/STB
- T :
-
Reservoir temperature (°F)
- γ o :
-
Specific gravity of oil (water = 1.0)
- γ g :
-
Specific gravity of gas (air = 1.0)
- APE:
-
Average percent relative error
- Er:
-
Percent relative error
- AAPE:
-
Average absolute percent relative error
- E max :
-
Maximum absolute percent relative error = \({ \hbox{max} }\left| {\text{Er}} \right|\)
- E min :
-
Minimum absolute percent relative error = \({ \hbox{min} }\left| {\text{Er}} \right|\)
- R :
-
Correlation coefficient
- St. dev:
-
Standard deviation
- x i :
-
Input parameters
- i :
-
Index for input parameters
- Ni:
-
Total number of input parameters
- j :
-
Index for hidden layer neurons
- b j :
-
Bias for hidden layer neuron j
- w ji :
-
Weights between input and hidden layer
- f :
-
Tan-sigmoid transfer function
- k :
-
Index for number of output parameters
- b k :
-
Bias for output layer
- w jk :
-
Weights between hidden and output layer
- Nh:
-
Total number of hidden layer neurons
- f L :
-
Linear transfer function
- n :
-
Total number of data points
References
Abdul-Majeed GHA, Salman NH (1988) An empirical correlation for FVF prediction. J Can Pet Technol 27(6):118–122
Al-Fattah SM, Al-Marhoun MA (1994) Evaluation of empirical correlation for bubble point oil formation volume factor. J Pet Sci Eng 11:341
Ali JK (1994) Neural networks: a new tool for the petroleum industry. In: Paper SPE 27561 presented at the 1994 European petroleum computer conference, Aberdeen, UK, 15–17 March
Al-Marhoun MA (1988) PVT correlations for Middle East crude oils. JPT 40:650
Al-Marhoun MA (1992) New correlation for formation volume factor of oil and gas mixtures. JCPT 31:22
Almehaideb RA (1997) Improved PVT correlations for UAE crude oils. In: Paper SPE 37691 presented at the 1997 SPE Middle East oil show and conference, Bahrain, 15–18 March
Al-Shammasi AA (1997) Bubble point pressure and oil formation volume factor correlations. In: Paper SPE 53185 presented at the 1997 SPE Middle East oil show and conference, Bahrain, 15–18 March
Al-Yousef HY, Al-Marhoun MA (1993) Discussion of correlation of PVT properties for UAE crudes. SPEFE 8:80
Beggs HD, Robinson JR (1975) Estimating the viscosity of crude oil system. J Pet Technol 9:1140–1149
Chew J, Connally CA Jr (1959) A viscosity correlation for gas-saturated crude oils. Trans AIME (Am Inst Min Metall) 216:23–25
De Ghetto G, Paone F, Villa M (1994) Reliability analysis on PVT correlation. In: paper SPE 28904 presented at the 1994 SPE European petroleum conference, London, UK, 25–27 October
Dokla M, Osman M (1992) Correlation of PVT properties for UAE crudes. SPEFE 7:41
Dokla M, Osman M (1993) Authors’ reply to Discussion of correlation of PVT properties for UAE crudes. SPEFE 8:82
Elsharkawy AM, Elgibaly A, Alikhan AA (1994) Assessment of the PVT correlations for predicting the properties of the Kuwaiti crude oils. In: paper presented at the 6th Abu Dhabi international petroleum exhibition and conference, 16–19 Oct
Fauset L (1996) Fundamentals of neural networks. Prentice Hall, New Jersey
Gharbi RB, Elsharkawy AM (1997) Neural-network model for estimating the PVT properties of Middle East crude oils. In: paper SPE 37695 presented at the 1997 SPE Middle East oil show and conference, Bahrain, 15–18 March
Glaso O (1980) Generalized pressure–volume temperature correlations. JPT 32:785
Gupta JP (2010) PVT correlations for Indian crude oil using artificial neural networks. J Pet Sci Eng 72:93–109
Hanafy HH, Macary SA, Elnady YM, Bayomi AA, El-Batanoney MH (1997) Empirical PVT correlation applied to Egyptian crude oils exemplify significance of using regional correlations. In: paper SPE 37295 presented at the SPE oilfield chemistry international symposium, Houston, 18–21 Feb 1997
Kartoatmodjo T, Schmidt Z (1994) Large data bank improves crude physical property correlations. Oil Gas J 92:51–55
Katz DL (1942) Prediction of shrinkage of crude oils. API, Drill Prod Pract, pp 137–147
Khan SA, Al-Marhoun MA, Duffuaa SO, Abu-Khamsin SA (1987) Viscosity correlations for Saudi Arabian crude oils. In: Presented at the 5th Society of Petroleum Engineers Middle East Oil Show, Bahrain, 7–10 March 1987, Paper SPE 15720
Kumoluyi AO, Daltaban TS (1994) High-order neural-networks in petroleum engineering. In: Paper SPE 27905 presented at the 1994 SPE Western regional meeting, Longbeach, California, USA, 23–25 March
Labedi R (1990) Use of production data to estimate volume factor density and compressibility of reservoir fluids. J Pet Sci Eng 4:357
Labedi R (1992) Improved correlations for predicting the viscosity of light crudes. J Pet Sci Eng 8:221–234
Lasater JA (1958) Bubble point pressure correlation. Trans AIME (Am Inst Min Metall) 213:379–381
MathWorks, Inc (2008) Neural network toolbox 6, user’s guide. MathWorks, Inc
Macary SM, El-Batanoney MH (1992) Derivation of PVT correlations for the Gulf of Suez crude oils. In: Paper presented at the EGPC 11th petroleum exploration and production conference, Cairo, Egypt
Mahmood MM, Al-Marhoun MA (1996) Evaluation of empirically derived PVT properties for Pakistani crude oils. J Pet Sci Eng 16:275
McCain WD (1991) Reservoir fluid property correlations-state of the art. SPERE 6:266
Mohaghegh S (1995) Neural networks: what it can do for petroleum engineers. JPT 47:42
Mohaghegh S, Ameri S (1994) A artificial neural network as a valuable tool for petroleum engineers. In: SPE 29220, unsolicited paper for Society of Petroleum Engineers
Omar MI, Todd AC (1993) Development of new modified black oil correlation for Malaysian crudes. In: Paper SPE 25338 presented at the 1993 SPE Asia Pacific Asia Pacific oil and gas conference and exhibition, Singapore, 8–10 Feb
Osman EA, Al-Marhoun MA (2002) Using artificial neural networks to develop new PVT correlations for Saudi crude oils. Soc Pet Eng. doi:10.2118/78592-MS
Petrosky J, Farshad F (1993) Pressure volume temperature correlation for the Gulf of Mexico. In: Paper SPE 26644 presented at the 1993 SPE annual technical conference and exhibition, Houston, TX, 3–6 Oct
Saleh AM, Maggoub IS, Asaad Y (1987) Evaluation of empirically derived PVT properties for Egyptian oils. In: Paper SPE 15721, presented at the 1987 Middle East oil show and conference, Bahrain, 7–10 March
Standing MB (1947) A pressure–volume–temperature correlation for mixtures of California oils and gases. API, Drill Prod Pract, pp 275–287
Standing MB (1977) Volumetric and phase behavior of oil field hydrocarbon system. Millet Print Inc., Dallas, p 124
Sutton RP, Farshad F (1990a) Evaluation of empirically derived PVT properties for Gulf of Mexico crude oils. SPRE 5:79
Sutton RP, Farshad F (1990) Supplement to SPE 1372, evaluation of empirically derived PVT properties for Gulf of Mexico crude oils. In: SPE 20277, available from SPE book Order Dep., Richardson, TX
Varotsis N, Gaganis V, Nighswander J, Guieze P (1999) A novel non-iterative method for the prediction of the PVT behavior of reservoir fluids. In: Paper SPE 56745 presented at the 1999 SPE annual technical conference and exhibition, Houston, Texas, 3–6 October
Vazquez M, Beggs HD (1980) Correlation for fluid physical property prediction. JPT 32:968
Acknowledgments
The authors wish to thank Dr. Al-Marhoun for his technical support related to this work and acknowledge the support provided by King Abdul-Aziz City for Science and Technology (KACST) through the Science and Technology Unit at King Fahd University of Petroleum and Minerals (KFUPM) for funding this work through Project No. 11-OIL2144-04 as part of the National Science, Technology and Innovation Plan.
Author information
Authors and Affiliations
Corresponding author
Appendices
Appendix 1

Cross plots between ANN-predicted and real data


Comparison plots between ANN-predicted and real data
Appendix 2
Statistical parameters used in the study are average percentage error ‘APE’, average absolute percentage error (AAPE), average percentage error (APE), correlation coefficient (R), and standard deviation.
Relative percentage error is defined mathematically as follows:
Absolute APE is defined mathematically as follows:
Average percentage error is defined mathematically as follows:
Standard deviation is defined mathematically as follows:
Appendix 3
There were two transfer functions used in the proposed ANN models. These are tan-sigmoid and linear transfer functions. Tan-sigmoid function connects input layer neurons to hidden layer neurons. Linear transfer function connects hidden layer neurons to output layer neurons. Mathematically, these transfer functions are defined as follows.
Tan-sigmoid (tansig) transfer function:
Linear (purelin) transfer function:
where, n is any real input argument, f the tan-sigmoid transfer function, and f L the linear transfer function
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Rammay, M.H., Abdulraheem, A. PVT correlations for Pakistani crude oils using artificial neural network. J Petrol Explor Prod Technol 7, 217–233 (2017). https://doi.org/10.1007/s13202-016-0232-z
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s13202-016-0232-z