
Abstract
Loss circulation is a common problem in drilling industry that causes high expenditure on drilling companies. Nowadays minimizing of loss circulation is a main goal and preference for drilling engineers. Artificial intelligence (Al) is a new method of solving engineering problems that has the ability to consider all effective parameters simultaneously. Moreover, it has generalization and the ability to learn directly from field data. In this paper, two models were designed using Al and data of 38 wells located in Maroun oil field. Both models were developed by modular neural network, to predict loss circulation in quality and quantity. Then, the particle swarm optimization algorithm was used to minimize loss circulation. The accuracy of two models in predicting loss circulation quantitatively and qualitatively is 0.94 and 0.98 %, respectively.
Similar content being viewed by others

Introduction
Lost Circulation Problem (LCP), also known as lost returns, stands for the absence or reduction of drilling mud pumped through the drillstring while drilling the wells, which filtrates into the formation instead of flowing up to the surface. Historic evidence shows that LCP highly contributes to the total cost of the mud and the well. Consequences of lost circulation may go from increasing operation costs to a stuck drill pipe, a blowout, reservoir damage and even loss of well. Although lost circulation can be treated by adding plugging and bridging materials [Lost Circulation Materials (LCMs)], to the drilling fluid, huge volume of mud may invade the formation before it can be detected on surface, especially in fractured and unconsolidated formations while drilling with heavy mud.
The rate of mud loss can vary from steady seepages in high permeability formations to rapid loss to fractures and faults. In either case the total mud loss can amount to several thousand barrels on a single well (Rojas et al. 1998). Dyke et al. (1995); Dupriest (2005) and Majidi et al. (2008a, b) have discussed that over 90 % of lost returns have been experienced in fractured formations.
Pilehvari and Nyshadham (2002) have discussed that circulation losses can be classified into three distinct groups as seepage loss, when the loss rate is 1–10 bbl/h, partial loss, when the loss rate is 10–500 bbl/h, and complete loss, when the loss rate is more than 500 bbl/h. On the other hand, losses can be divided to minor and severe losses. Minor loss occurs when total loss is between 6 and 470 barrels or it takes less than 48 h to be treated by either increasing mud viscosity or increasing small amount of LCMs to the mud. Severe losses are experienced where losses are >470 barrels or it takes >48 h to control or cease the lost circulation by adding some bridging materials to the circulation system (Moazzeni and Nabaei 2010).
Sanfillippo et al. (1997) developed a model for Newtonian mud diffusion in a non-deformable fracture of constant width with impermeable walls and then modified for estimation of fracture aperture from drilling data. But as a matter of fact, most common drilling fluids in use are non-Newtonian fluids and their invasion cannot be investigated using mentioned model. Later, Lietard et al. (1999) have proposed the first model for diffusion of drilling fluid to the single fracture. They have combined Darcy’s law with Bingham plastic model and derived invaded zone radius for different effective parameters versus time. Fracture aperture then could be obtained by some theoretical curve resulted from interpolation between real mud loss data and based on best valid fit. Fracture width is very important for optimizing particle size distribution of LCM for rapid ceasing lost circulation (Moazzeni et al. 2009).
Majidi et al. (2008a, b) developed a theoretical model based on more realistic rheological behavior of drilling fluids like yield-power-law (YPL) fluids which was proposed by Hemphill et al. (1993). These new models explained the essential role of drilling fluid rheology (especially yield stress and shear-thinning effect) on lost circulation in fractured reservoirs. These models cannot consider location of wells along the field.
With the growing interest and enthusiasm in the oil industry toward smart wells, intelligent reservoir characterization, and real-time analysis and interpretation of large amounts of data for process optimization, the need for powerful, robust and intelligent tools has significantly increased. In recent years, hybrid intelligent systems integrating different Artificial Intelligence techniques have made solid steps toward becoming more accepted in the mainstream of the oil and gas industry due to their capabilities in handling real-world complexities involving imprecision, uncertainty, and vagueness (Alvarado et al. 2004; Medsker 1995; Mohaghegh 2005; Nikravesh et al. 2002 and Zhang and Ch 2004).
Several factors like formation pressure (differential pressure), permeability distribution, stress field around the borehole, existence of fractures and caves and some operational parameters such as pump pressure and flow rate, drilling fluid properties (especially viscosity and solid content) and some other time dependent parameters affect severity of lost circulation. This interrelated parameters cause difficulty in obtaining analytical solution for prediction of lost circulation. Besides, spending more costs for removing the consequences of lost circulation forces drilling companies to have an idea about the severity and frequency of mud loss in the drilling area. Since finding reasonable relationship between these factors is not so simple, virtual intelligence can be employed for prediction quality and quantity of loss before drilling.
In this paper, Maroun oilfield in Middle East is selected because of presence of highly fractured oil bearing zone which suffered from severe losses especially as oil production diminishes its pressure. Offset data of 38 wells are used for evaluation of lost circulation. Since lost circulation is governed by very complicated and interrelated parameters, neural network modeling is used for prediction of amount of mud loss quantitatively. Another network also is employed to interpret network-based mud loss results qualitatively. It can classify mud loss results to “seepage”, “partial” and “complete loss”. Predicted mud loss rate fairly matches reality.
In this paper, a new method is presented to obviate loss circulation. This model is developed using modular neural network and particle swarm optimization algorithm. Using this model and improving effective parameters, loss circulation is obviated or mitigated.
Maroun oil field
Maroun is a huge oilfield with fully fractured oil bearing zone located in South West of Iran along with Zagros mountain chains. It is divided to eight different sectors according to production capability and presence of production units. Main oil bearing horizon is called Asmari formation which is divided to different sub layers due to petrophysical property differences.
Modular neural network
The current Multilayer Perceptron (MLP) networks are mostly slow and suffer from massive computational costs which usually lead these networks to be trapped in the local minima and finally preventing prediction of the desired output accurately.
Most of the evolutionary and artificial intelligence algorithms, particularly Artificial Neural Networks (ANNs), are based on biological systems. Therefore, more study of those concepts can help us to improve the limitation of the current methods. According to recent researchers on the brain, it is understood that the brain is composed of three main subsets which introduce the modularity in the brain (Shepherd 1974). Actually, the complex tasks in the brain will be decomposed into simpler ones (Rexrodt 1981). This new finding causes the ANNs to be more flexible and close to the real applications at hand. In other words, the modularity is one of the most important factors in human and animal brains that helps them to manage the very complex tasks efficiently. For example, one can see the brain as a collection of individual functions and modules which can work with each other effectively and decompose the complex problems into several simpler ones (Montcastle 1978; Eccles et al. 1984; Edelman 1987 and Huble 1988). Also, according to several researchers it is shown that the brain is composed of massively parallel and modular parts which relatively work independently (Edelman 1979, 1987; Frackpwiak et al. 1997).
There are some problems in MLP networks which will be mentioned hereafter. For example, in the most of the cases the size of network is very large and there is no efficient learning algorithm and no enough data to find the best associated weights. However, by dividing the network, one can define networks which are independent and have a simpler and smaller size rather than the MLP network.
Since the MLP networks are monolithic, an error and/or change in these networks can propagate in and affect all parts. This problem reduces the stability of network and leads it to be very sensitive to the local variation and error in network while the network should has this ability that can reduce the undesirable fluctuation and decrease its effect.
In most of MLP networks, it is not possible or it is very cumbersome to implement a priori knowledge about the problem at hand. Therefore, the experts’ ideas and an interpretational knowledge cannot be considered in those networks and make them inappropriate for data integration.
In this section, to overcome the mentioned problem, a new concept of modularity is presented, but first let us explain a clear modularity in our visual system. Based on different researches, it is obvious that our visual system needs to do a lot of tasks such as motion detection, color, shape, and intensity evaluation. Also, there is a central system which receives different results of different mentioned parts and combines them resulting in the final realization.
Let us first present a schematic architecture and connection links in a MNN in Fig. 1. Actually, the modularization ability of ANN can overcome the mentioned problems. In other words, MNN has the ability to have different structures in itself and even one can integrate a priori knowledge within it. Also, since the complex task in MNN is decomposed into several smaller and simpler ones, one can expect an overall network with a smaller complexity and CPU demanding. One of the reasons is because of using a smaller part of data for each module.

A schematic view of the MNN architecture
According to the above definitions and explanations, we can define the MNN as a network in which the massive computational burden is divided into some modules which each of them has distinct inputs and are independent to other modules on that network (Happel and Murre 1994; Azam 2000). Finally, the outputs of each module will be integrated to make the final output. Therefore, each part of MNNs does a special computational task of whole system and is independent of other modules and the other one cannot influence the work of rest modules. Also, this network has simpler structures while compared with MLP and, therefore, can response to input much faster.
Let us return to Fig. 1 in which a MNN is presented. In this figure, it is clear that there are a few number of connections and weights; therefore, the network size will be decreased dramatically. Consequently, the complexity of network will be decreased and in this case, finding the global minima in a smaller time would be much easier.
Also, as another result, due to low complexity, we can use a smaller dataset which is one of the main features of petroleum datasets (Feldman and Ballard 1982; Jacobs et al. 1991; Jacobs 1995). We compare modular neural network with multi-layer perceptron and the results show that modular neural networks outperform multi-layer perceptron in examined dataset in terms of accuracy and learning time.
Particle swarm optimization algorithm
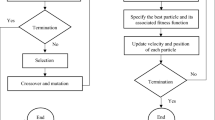
Particle swarm optimization is one of the latest evolutionary optimization techniques developed by Eberhart and Kennedy (1995). PSO concept is based on a metaphor of social interaction such as bird flocking and fish schooling. The particles, which are potential solutions in the PSO algorithm, fly around in the multidimensional search space and the positions of individual particles are adjusted according to its previous best position and the neighborhood best or the global best. Since all particles in PSO are kept as members of the population throughout the course of the searching process, PSO is the only evolutionary algorithm that does not implement survival of the fittest. As simple and economical in concept and computational cost, PSO has been shown to successfully optimize a wide range of continuous optimization problems (Brandstatter and Baumgartner 2002; Yoshida et al. 2000).
Methodology
To have a comprehensive model for predicting loss circulation, it is needed to consider effective parameters. In this modeling, the inputs are geographic coordinates (east and north), the current depth, depth of formation tip, penetration rate, formation type, annulus volume, mud pressure, flow rate of mud pump, mud pump pressure, filter cake viscosity, solid content, plastic viscosity, yield point, initial strength, and final strength after 10 min and the output is loss circulation. Among the 1756 data sets (input and output) after eliminating illogical data that is indication of human and device error, the 1,630 data sets of 38 wells were used in the modeling. After data normalizing, 60 % of data for training, 20 percent for validation, and the remaining 20 % were used for network test. To feed formation types and their sub layers into the neural network, we convert their values from categorical to numerical by assigning numerical codes to them. The range of used parameters in modeling is listed in Table 1.
The first model was developed by modular neural network to predict quantitatively loss circulation. Figure 2 shows the type of modular used for both models. The output of network in this model is the quantity of loss circulation. The structure of modular neural network for the first model is shown in Table 2. The results of training and network test are illustrated in Figs. 3 and 4, respectively. The precision of the first model can almost be acceptable. Using this model the amount of loss circulation can be predicted at any depth with reasonable accuracy.

Modular neural network used for modeling

Correlation coefficient of modular neural network of the first model in the training stage

Correlation coefficient of modular neural network of the first model in the test stage
Provided that the goal merely is the determination of the type of loss circulation and the precise quantity of loss circulation is not needed, the second model that is more accurate than the first model can be used. In this model the output of neural network is the prediction of loss rate qualitatively in the following ranges:
-
The number zero for the loss of <0.07 m3/h (seepage loss).
-
The number 0.5 for the range of 0.07–0.7 m3/h (severe loss).
-
The number 1 for the loss of more than 0.7 m3/h (complete loss).
-
The modular neural network was also used in order to construct the second model. The characteristic of the network is shown in Table 3.
Table 3 Modular neural network construction of the second model
The results of training and test of the second model are illustrated in Figs. 5 and 6, respectively. The learning rule is the means by which the correction term is specified. Once the particular rule is selected, the user must still specify how much correction should be applied to the weights, referred to as the learning rate. If the learning rate is too small, then learning takes a long time. On the other hand, if it is set too high, then the adaptation diverges and the weights are unusable. Because we need nominal values as output (i.e., 0 and 1), we should discretize the continues values of the output of the network to discreet values 0 and 1. To do so, we define a mapping range as Table 4 shows.

Correlation coefficient of modular neural network of the second model in the training stage

Correlation coefficient of modular neural network of the second model in the test stage
Comparison between the MNN and MLP can be between the required epochs for reaching the network to a stable variation of mean square error (MSE). In other words, one can compare the MSE for each epoch in order to find out the performance of different networks to adjust their weights. This comparison can be seen in Fig. 7.

Comparison of MNN and MLP networks in both accuracy and convergence speed for two model (the vertical axis is logarithmic)
According to Figure 7, it is obvious that MNN demand less time to be convergent. This improvement in aspect of CPU time is because of using a less weight vector which it reduces the network’s complexity. Therefore, the applied learning algorithm in the case of a few weights and consequently the variables can find the global minima faster. Table 5 shows the result of comparison of MNN and MPLS in terms of accuracy.
Regarding high volume of data, a concise comparison of predicted lost circulation in testing stage is depicted in Figs. 8 and 9 for both networks with real data. According to figures, there are excellent agreements between the real and estimated lost circulation for the MNN networks.

Comparison of the estimated values of first model and the real permeability

Comparison of the estimated values of second model and the real permeability
Reduction of drilling fluid loss
A part of loss circulation is due to improper selection of drilling parameters during operation. Under these circumstances the effective parameters can be improved to mitigate loss circulation. Loss circulation arisen from high permeable formation, drilling mud filtration, fluid invasion into the matrix, and induced fracture can be alleviated or precluded by proper selection of drilling parameters. To improve and select proper drilling parameters, the optimized algorithms can be used.
In optimizing processes the variation in parameters such as annulus volume, penetration rate, flow rate of mud pump, mud pump pressure, hydrostatic pressure, viscosity of mud filtration, solid content, plastic viscosity, yield point, initial gel strength, and final gel strength after 10 min is allowable, whereas well coordination, depth, characteristic of formation, and the depth of formation tip should be constant. To minimize the function of loss circulation, two optimizing algorithms are examined. The best results are pertinent to particle swarm algorithm.
The optimized parameters are shown in Table 6. To make certain about the obtained results and to investigate the quantity of loss circulation, the optimized and constant parameters of each part of well were inputted into the neural network of the first model and the loss circulation that is network output was calculated. The result of the test is shown in Table 7. As can be seen in almost all the cases, the quantity of loss circulation was reduced to more than half of its present value. Therefore, loss circulation can drastically be alleviated by applying the optimized parameters. Due to limitation, only some of the optimized results are given in table 6.
Table 8 shows result of comparison of PSO and GA to optimize lost circulation. As it can be seen PSO have better performance than GA in terms of optimization values of lost and execution time.
Conclusions
-
1.
A methodology was proposed for prediction of lost circulation in any coordinates of field using operational and geological data.
-
2.
A new method was carried out for loss circulation using particle swarm algorithm and modular neural network.
-
3.
Before utilizing any neural network, data mining and quality control should be performed on available data.
-
4.
Most common drilling problem is lost circulation especially in fractured formations.
-
5.
Lost circulation is governed by numerous factors that make finding analytical solution with acceptable accuracy very difficult or impossible.
-
6.
Neural network helps to have accurate prediction of lost circulation in Asmari formation of Maroun oilfield.
-
7.
Utilizing artificial neural network is recommended while dealing with different interrelated parameters (like lost circulation).
-
8.
Network results are just for the field under study and should not be used for another field even nearby ones.
References
Alvarado M, Sheremetov L, Cantu F (2004) Autonomous agents and computational intelligence: the future of AI applications for petroleum industry. Expert Syst Appl 26:3–8
Azam F (2000) Biologically Inspired Modular Neural Networks, PhD Dissertation, Virginia Tech
Brandstatter B, Baumgartner U (2002) Particle swarm optimisatio-mass-spring system analogon. IEEE Trans Magn 38:997–1000
Dupriest F.E (2005) Fracture Closure Stress (FCS) and Lost Returns Practices, SPE 92192, SPE/IADC Drilling Conference, Amsterdam, Netherlands, 23–25 Feb
Dyke C.G, Wu B, Milton-Tayler D (1995) Advances in Characterizing Natural-Fracture Permeability from Mud-Log Data, SPE 25022, Europe Petroleum Conference, Cannes
Eberhart R.C, Kennedy J (1995) A new optimizer using particle swarm theory, Proceedings of the Sixth International Symposium on Micro Machine and Human Science, Nagoya, Japan, pp, 39–43
Eccles JC, Jones EG, Peters A (1984) The cerebral neocortex: atheory of its operation, cerebral cortex: functional properties of cortical cells, vol 2. Plenum Press, New York
Edelman GM (1979) Group selection and phasic reentrant signaling: a theory ofhigher brain function. In: Schmitt FO, Worden FG (eds) The neurosciences: fourth study program. MIT Press, Cambridge
Edelman G.M (1987) Neural Darwinism: Theory of Neural Group Selection, Basic Books
Feldman JA, Ballard DH (1982) Connectionist models and their properties. Cogn Sci 6(3):205–254
Frackpwiak RSJ, Friston KJ, Frith CD, Dolan RJ, Mazziotta JC (1997) Human brain function. Academic Press, San Diego
Happel B, Murre J (1994) The design and evolution of modular neural network architectures. Neural Netw 7:985–1004
Hemphill T, Campos W, Pilehvari A (1993) Yield-power law model more accurately predicts mud rheology. Oil Gas J 91(34):45–50
Huble DH (1988) Eye, brain, and vision. Scientific American Library, New York
Jacobs RA (1995) Methods of combining experts’ probability assessments. Neural Comput 7:867–888
Jacobs RA, Jordan MI, Nowlan SJ, Hinton GE (1991) Adaptive mixtures of local experts. Neural Comput 3(1):79–87
Lietard O, Unwin T, Guillot D.J, Hodder M.H (1999) Fracture Width Logging While Drilling and Drilling Mud/Loss-Circulation-Material Selection Guidelines in Naturally Fractured Reservoirs, SPE DC, September, 168–177
Majidi R, Miska S.Z, Yu M, Thompson L.G (2008) Quantitative Analysis of Mud Losses in Naturally Fractured Reservoirs: The Effect of Rheology, SPE 114130, SPE Western Regional and Pacific Section AAPG Joint Meeting, Bakersfield, California, USA, 31 March–2 April
Majidi R, Miska S.Z, Yu M, Thompson L.G, Zhang J (2008) Modeling of Drilling Fluid Losses in Naturally Fractured Formations, SPE 114630, SPE Annual Technical Conference and Exhibition, Denver, Colorado, USA, 21–24 September
Medsker LR (1995) Hybrid intelligent systems. Kluwer Academic Publishers, Dordrecht
Moazzeni A, Nabaei M (2010) Drilling engineering. In: Kankash E (ed) Drilling problems, Vol 2, Chap 3. Kankash Publication, pp 321–322
Moazzeni A.R, Nabaei M, Ghadamijegarlooei S (2009) Optimizing size distribution of limestone chips and shellfish as lost circulation materials, 6th International Chemical Engineering Conference (ICheC)
Mohaghegh SD (2005) Recent developments in application of artificial intelligence in petroleum engineering. J Pet Technol 57(4):86–91
Montcastle VB (1978) An organizing principle for cerebral function: the unit module and the distributed system. In: Edelman GM, Mountcatke VB (eds) The mindful brain: cortical organization and the group selective theory of higher brain function. MIT Press, Cambridge, p 7
Nikravesh M, Aminzadeh F, Zadeh L (Eds) (2002) Soft computing and intelligent data analysis in oil exploration. Elsevier, Amsterdam
Pilehvari A, Nyshadham VR (2002) Effect of Material Type and Size Distribution on Performance of Loss/Seepage Control Material, SPE 73791, Texas A and M University-Kingsville, p 13
Rexrodt FW (1981) Gehrin und Psyche. Hippokrates, Stuttgart
Rojas JC, Bern PA, Ftizgerald BL, Modi S, Bezant PN (1998) Minimizing Down Hole Mud Losses, lADC/SPE 39398, Presented at the IADC/SPE Drilling Conference, Dallas, 3–6 March
Sanfillippo F, Brignoli M, Santarelli F.J, Bezzola C (1997) Characterization of Conductive Fractures While Drilling, SPE 38177, SPE European Formation Damage Conference, The Hague, The Netherlands, 2–3 June
Shepherd GM (1974) The Synaptic Organization of the Brain. Oxford University Press, New York
Yoshida H, Kawata K, Fukuyama Y, Takayama S, Nakanishi Y (2000) A particle swarm optimization for reactive power and voltage control considering voltage security assessment. IEEE Trans Power Syst 15:1232–1239
Zhang Z, Zhang Ch (2003) Design and application of hybrid intelligent systems. IOS Press Amsterdam, The Netherlands, p 799–808
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution License which permits any use, distribution, and reproduction in any medium, provided the original author(s) and the source are credited.
About this article
Cite this article
Toreifi, H., Rostami, H. & manshad, A.K. New method for prediction and solving the problem of drilling fluid loss using modular neural network and particle swarm optimization algorithm. J Petrol Explor Prod Technol 4, 371–379 (2014). https://doi.org/10.1007/s13202-014-0102-5
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s13202-014-0102-5