
Abstract
Combining and analyzing data from heterogeneous randomized controlled trials of complex multiple-component intervention studies, or discussing them in a systematic review, is not straightforward. The present article describes certain issues to be considered when combining data across studies, based on discussions in an NIH-sponsored workshop on pooling issues across studies in consortia (see Belle et al. in Psychol Aging, 18(3):396–405, 2003). Several statistical methodologies are described and their advantages and limitations are explored. Whether weighting the different studies data differently, or via employing random effects, one must recognize that different pooling methodologies may yield different results. Pooling can be used for comprehensive exploratory analyses of data from RCTs and should not be viewed as replacing the standard analysis plan for each study. Pooling may help to identify intervention components that may be more effective especially for subsets of participants with certain behavioral characteristics. Pooling, when supported by statistical tests, can allow exploratory investigation of potential hypotheses and for the design of future interventions.
Similar content being viewed by others


References
DeMets DL. Methods for combining randomized clinical trials: strengths and limitations. Stat Med. 1987; 6: 341-348.
Belle SH, Czaja SJ, Schulz R, et al. Using a new taxonomy to combine the uncombinable: integrating results across diverse interventions. Psychol Aging. 2003; 18(3): 396-405.
Spinks A, Turner C, Nixon J, McClure RJ (2009) The ‘WHO Safe Communities’ model for the prevention of injury in whole populations. Cochrane Database of Systematic Reviews Issue 3. Art. No.: CD004445. DOI:10.1002/14651858.CD004445.pub3.
Pratt CA, Boyington J, Esposito L, et al. Childhood obesity prevention and treatment research (COPTR): interventions addressing multiple influences in childhood and adolescent obesity. Contemp Clin Trials. 2013; 36(2): 406-413.
Lytle LA, Svetkey LP, Patrick K, et al. The EARLY trials: a consortium of studies targeting weight control in young adults. Translat Behav Med. 2014; 4(3): 304-313.
Czajkowski SM, Powell LH, Adler N, et al. (2015) From ideas to efficacy: The ORBIT model for developing behavioral treatments for chronic diseases. Health Psychology (to appear in print)
Mantel N, Haenszel W. Statistical aspects of the analysis of data from retrospective studies of disease. J Natl Cancer Inst. 1959; 22: 719-748.
Bangdiwala SI, Villaveces A, Garrettson M, et al. Statistical methods for designing and assessing the effectiveness of community-based interventions with small numbers. Int J Inj Control Saf Promot. 2012; 19(3): 242-248.
Morton SC, Adams JL, Suttorp MJ, Shekelle PG (2004) Meta-regression approaches: what, why, when, and how?, Technical Review 8, Agency for Healthcare Research and Quality Publication No. 04–0033. Rockville.
O’Connor DP, Lee RE, Mehta P, et al. Childhood obesity research demonstration project: cross-site evaluation methods. Childhood Obes. 2015; 11: 92-103.
Schulz R, Czaja SJ, McKay JR, et al. Intervention taxonomy (ITAX): describing essential features of interventions. Am J Health Behav. 2010; 34(6): 811-821.
Czaja SJ, Schulz R, Lee CC, et al. A methodology for describing and decomposing complex psychosocial and behavioral interventions. Psychol Aging. 2003; 18(3): 385-395.
Bhargava A. Randomized controlled experiments in health and social sciences: some conceptual issues. Econ Hum Biol. 2008; 6: 293-298.
Bhargava A, Hays J. Behavioral variables and education are predictors of dietary change in the women’s health trial: feasibility study in minority populations. Prev Med. 2004; 38(4): 442-51.
Jöreskog KG. Simultaneous factor analysis in several populations. Psychometrika. 1971; 36: 409-426.
Sörbom D. A general method for studying differences in factor means and factor structure between groups. Br J Math Stat Psychol. 1974; 27: 229-239.
Duncan TE, Duncan SC, Strycker LA. An introduction to latent variable growth curve modeling: concepts, issues, and application. 2nd ed. Mahwah: Lawrence Erlbaum Associates, Inc.; 2006.
Rabe-Hesketh S, Skrondal A, Pickles A. Generalized multilevel structural equation modeling. Psychometrika. 2004; 69: 167-190.
Cox D. Planning of experiments. New York: John Wiley & Sons; 1958.
Fisher RA. The design of experiments. Edinburgh: Oliver and Boyd; 1935.
Bhargava A, Guthrie J. Unhealthy eating habits, physical exercise and macronutrient intakes are predictors of anthropometric indicators in the women’s health trial: feasibility study in minority populations. Br J Nutr. 2002; 88(6): 719-28.
Rao CR. Large sample tests of statistical hypotheses concerning several parameters with applications to problems of estimation. Proc Camb Philos Soc. 1948; 44: 50-57.
Bhargava A. Wald tests and systems of stochastic equations. Int Econ Rev. 1987; 28: 789-808.
Sargan JD. Some tests of dynamic specification for a single equation. Econometrica. 1980; 48: 879-898.
Weiner BJ, Lewis MA, Clauser SB, et al. In search of synergy: strategies for combining interventions at multiple levels. J Natl Cancer Inst Monogr. 2012; 44: 34-41.
Wald A. Sequential analysis. New York: Dover Publications; 1947.
Acknowledgments
This manuscript is one of three presented in this journal and was supported the NIH National Heart, Lung, and Blood Institute, the Eunice Kennedy Shriver National Institute of Child Health and Development, the NIH Office of Behavioral and Social Sciences Research, the NIH Office of Disease Prevention, and the Centers for Disease Control and Prevention. The content is solely the responsibility of the authors and does not necessarily represent the official views of the National Institutes of Health.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflicts of interest
All authors have completed the disclosure form on all relationships or interests that could influence or bias the work, and there are no conflicts of interests from any authors.
Adherence to ethical principles
All authors have adhered to ethical principles and maintain the integrity of the research and its presentation by following the rules of good scientific practice.
Additional information
Implication statements
Policy: Pooling the data across studies, when supported by statistical tests, may facilitate the investigation of hypotheses for improving the design of future interventions and informing policy makers about the interventions that are most likely to be effective.
Practice: Pooling the data from similarly designed randomized controlled trials may be useful for identifying intervention components that may be more effective for diverse participants.
Research: Because combining the data from heterogeneous studies may lead to spurious results, it is important to develop statistical procedures for assessing the validity of models estimated using the pooled data.
APPENDIX
APPENDIX
Modeling overall intervention effects
-
Model 1a: Modeling individual-level outcomes from multiple single-component intervention trials using fixed effects
Let Y ij denote the outcome for the jth person in the ith study, and I ij is a dummy variable denoting the study arm assignment for the same individual (=1 for active arm, =0 for control arm), then
$$ {Y}_{ij}={\beta}_0+{\beta}_1{I}_{ij}+{\beta}_2{X}_{1i}+{\beta}_3\left[{I}_{ij}*{X}_{1i}\right]+{\beta}_4{X}_{2ij}+{e}_{ij}, $$(1a)could be a potential model examining the effect β 1 of the intervention after accounting for the interaction of the intervention with a study-level covariate X 1i and with a subject-level covariate X 2ij . The error terms e ij are assumed to follow an N(0,σ2) distribution. If X 1i is a categorical-level variable, this is essentially stratification (or blocking) analysis. If X i1 is a series of dummy variables identifying the various studies, one is then treating each study as a stratum in a single “stratified large study.”
-
Model 1b: Modeling study-level outcomes from multiple single-component intervention trials using fixed effects
Since we do not have the individual level information, let E i denote the observed effect in the ith study, which could be a difference in means between the intervention and control arms for continuous variables, or the log odds ratio of the probability of an event for binary outcomes, then
$$ {E}_i = \mu +{\beta}_1{X}_{1i}+{\beta}_2{X}_{2i}+{\beta}_3{X}_{3i}+{e}_i, $$(1b)could be a potential model examining the overall effect μ of the intervention after accounting for the effects of three study-level covariates (X 1i , X 2i , X 3i ). The error terms e i are assumed to have an N(0,σ2) distribution for the variation in each study’s estimate of the common effect μ.
-
Model 1c: Modeling study-level outcomes from multiple single-component intervention trials using random effects
Since we do not have the individual level information, let e i denote the observed effect in the ith study, which could be a difference in means between the intervention and control arms for continuous variables, or the log odds ratio of the probability of an event for binary outcomes, then
$$ {E}_i = \mu +{\zeta}_i+{\beta}_1{X}_{1i}+{\beta}_2{X}_{2i}+{\beta}_3{X}_{3i}+{e}_i, $$(1c)could be a potential model examining the overall effect μ of the intervention after accounting for the fixed effects of three study-level covariates (X 1i , X 2i , X 3i ) and the random effects ζi, assumed to be N(0,τ2) and independent of the errors e i . The random effects help decompose the total variance in study effects into a component due to across study variation (τ2) and a within-study variation (σ2).
-
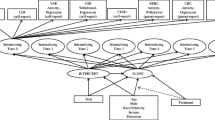
Model 2: Modeling study-level outcomes from multicomponent intervention trials using random effects meta-regression
For illustration purposes, we use the COPTR consortium, where the primary outcome is body mass index change [ΔBMI]. For simplicity of illustration, assume that each of the four studies in the consortium has multicomponent interventions addressing obesity but that three main modalities are common to all—C1 = education modality, C2 = physical activity modality, and C3 = dietary modality. Note that all studies do not necessarily have to offer all modalities as part of their multicomponent intervention and that what they offer may differ within a modality. The Cs above denote indicator variables for whether it is offered or not as part of the intervention in a given study. For example, C1i = 1 if an education component is offered in the ith study, =0 if not. If in addition to the intervention components we have two study-level covariates—say, W1 = proportion of males (assume as a mediator) and W2 = mean age of individuals (assume as a moderator of education component), for example, then, the random-effects meta-regression model with only study-level covariates would be
$$ \left[\varDelta BM{I}_i\right]=\mu +{\zeta}_i+{\beta}_1{C}_{1i}+{\beta}_2{C}_{2i}+{\beta}_3{C}_{3i} + {\beta}_4{W}_{1i}+{\beta}_5{W}_{2i}+{\beta}_6\left[{C}_{1i}*{W}_{2i}\right]\Big)+{e}_i, $$(2)where we are interested in the overall effect μ but also in the fixed coefficients βs. The ζs are the study random effects that help study the variance components.
-
Model 3: Modeling individual-level outcomes from multicomponent intervention trials using random effects multilevel meta-regression
In a consortium, one expects to be able to have individual-level information and can thus model the individual change or effect within a person. Using the COPTR example of Model 2, but for individual-level outcomes, we now have that the jth subject in the ith study may have been randomized to receive or not the kth component Ck. Thus, we can model the within-person effect with individual level covariates sex (S) and age (A):
$$ \Delta BM{I}_{ij}=\mu + {\zeta}_i+{\beta}_1{C}_{1ij}+{\beta}_2{C}_{2ij}+{\beta}_3{C}_{3ij}+{\beta}_4{S}_{ij}+{\beta}_5{A}_{ij}+{\beta}_6\left[{C}_{1ij}*{A}_{ij}\right]\Big)+{e}_i, $$(3)where we are interested in the overall effect μ but also in the fixed coefficients βs. We should point out that any subject-level covariate would ideally be measured using the same instrument or method (i.e., have a set of common metrics) across studies.
About this article

Cite this article
Bangdiwala, S.I., Bhargava, A., O’Connor, D.P. et al. Statistical methodologies to pool across multiple intervention studies. Behav. Med. Pract. Policy Res. 6, 228–235 (2016). https://doi.org/10.1007/s13142-016-0386-8
Published:
Issue Date:
DOI: https://doi.org/10.1007/s13142-016-0386-8