
Abstract
We propose a joint hypothesis test for simultaneous confirmatory inference in the overall population and a pre-defined marker-positive subgroup under the assumption that the treatment effect in the marker-positive subgroup is larger than that in the overall population. The proposed confirmatory overall-subgroup simultaneous test (COSST) is based on partitioning the sample space of the test statistics in the marker-positive and marker-negative subgroups. We define two rejection regions in the joint sample space of the two test statistics: (1) efficacy in the marker-positive subgroup only; (2) efficacy in the overall population. COSST achieves higher statistical power to detect the overall and subgroup efficacy than most sequential procedures while controlling the family-wise type I error rate. COSST also takes into account the potentially harmful effect in the subgroups in the decision. The optimal rejection regions depend on the specific alternative hypothesis and the sample size. COSST can be useful for Phase III clinical trials with tailoring objectives.



Similar content being viewed by others


References
Borghaei H et al (2015) Novolumab versus Doxetaxel in Advanced Nonsquamous Non-Small-Cell Lung Cancer. NEJM 373:1627–1639
Dmitrienko A, D’Agostino RB (2013) Tutorial in biostatistics: traditional multiplicity adjustment methods in clinical trials. Stat. Med. 32:5172–5218
Eichhorn EJ et al (2001) A trial of beta-blocker bucindolol in patients with advanced chronic heart failure. New Engl J Med 344(22):1659–1667
European Medicines Agency, Committee for Medicinal Products for Human Use (2010) Concept paper on the need for a guideline on the use of subgroup analyses in randomized controlled trials. http://www.ema.europa.eu/docs/en_GB/document_library/Scientific_guideline/2010/05/WC500090116.pdf. Accessed January 14, 2016
Freidlin B, Korn EL, Gray R (2014) Marker sequential test (MaST) design. Clinical Trials 11(1):19–27. PMID: 24085774
Freidlin B, Korn EL (2014) Biomarker enrichment strategies: matching trial design to biomarker credentials. Nat Rev Clin Oncol 11(2):81–90. PMID: 24281059
Liggett SB, Mialet-Perez J, Thaneemit-Chen S, Weber SA, Greene SM, Hodne D, Nelson B, Morrison J, Domanski MJ, Wagoner LE, Abraham WT, Anderson JL, Carlquist JF, Krause-Steinrauf HJ, Lazzeroni LC, Port JD, Lavori PW, Bristow MR (2006) A polymorphism within a conserved \(\beta _{1}\)-adrenergic receptor motif alters cardiac function and beta-blocker response in human heart failure. Proc Natl Acad Sci 103(30):11288–11293
Millen BA, Dmitrienko A (2011) Chain procedures: a class of flexible closed testing procedures with clinical trial applications. Stat Biopharm Res 3:14–30
Ondra T, Dmitrenko A, Friede T, Graf A, Miller F, Stallard N, Posch M (2016) Methods for identification and confirmation of targeted subgroups in clinical trials: a systematic review. J Biopharm Stat 26(1):99–119
Rosenblum M, Liu H, Yen E-H (2014) Optimal tests of treatment effects for the overall population and two subpopulations in randomized trials, using sparse linear programming. J Am Stat Assoc (Theory and Methods) 109(507):1216–1228. PMID: 25568502
Simon R (2008) The use of genomics in clinical trial design. Clin Cancer Res 14:5984–93
Song Y, Chi GYH (2007) A method for testing a pre-specified subgroup in clinical trials. Stat Med 26:3535–49
Wang SJ, Bretz F, Dmitrienko A, Hsu J, Hung HMJ, Koch G, Maurer W, Offen W, O’Neill R (2015) Multiplicity in confirmatory clinical trials: a case study with discussion from a JSM panel. Stat Med 34(26):3461–80. doi:10.1002/sim.6561
Author information
Authors and Affiliations
Corresponding author
Additional information
The authors Ilana Belitskaya-Lévy and Hui Wang contributed equally to this work.
Electronic supplementary material
Below is the link to the electronic supplementary material.
Appendix
Appendix
Let \(\mu _{T+} ,\mu _{C+} ,\mu _{T-} ,\mu _{C-} \) and \(\sigma _{T+}^2 ,\sigma _{C+}^2 ,\sigma _{T-}^2 ,\sigma _{C-}^2 \)be the means and variances in the populations defined by their subscripts, respectively; \(\bar{X}_{T+} \), \(\bar{X}_{C+} \), \(\bar{X}_{T-} \), and \(\bar{X}_{C-} \) and \(s_{T+}^2 \), \(s_{T-}^2 \),\(s_{C+}^2 \) and \(s_{C-}^2 \)be the corresponding sample means and variances, and \(N_{T+} \),\(N_{T-} \), \(N_{C+} \), \(N_{C-} \) be the corresponding sample sizes. Let \(p_+ \)be the biomarker prevalence rate in the study, such that
and
where \(N_T =N_{T+} +N_{T-} \) and \(N_C =N_{C+} +N_{C-} \) are the sample sizes in the treatment and control arms, respectively, and \(N_+ =N_{T+} +N_{C+} \) and \(N_- =N_{T-} +N_{C-} \) are the numbers of the marker-positive and negative subjects, respectively. Let \(N=N_+ +N_- =N_T +N_C \) be the total sample size (Table 4).
1.1 Randomization ratio
Randomization ensures that the proportion of subjects randomized to treatment are the same in each of the subgroups as well as in the overall sample, i.e., \(p_T =\frac{N_T }{N}=\frac{N_{T+} }{N_+ }=\frac{N_{T-} }{N_- }\) and \(p_C =\frac{N_C }{N}=\frac{N_{C+} }{N_+ }=\frac{N_{C-} }{N_- }=1-p_T \), because the assignment is independent of subgroup status.
Let \(R=\frac{p_T }{p_C }=\frac{N_T }{N_C }=\frac{N_{T+} }{N_{C+} }=\frac{N_{T-} }{N_{C-} }\) be the randomization ratio. Note that
1.2 Relationships between test statistics and population parameters
Let \(S_+^2 =V\left( {\bar{X}_{T+} -\bar{X}_{C+} } \right) =\frac{\sigma _{T+}^2 }{N_{T+} }+\frac{\sigma _{C+}^2 }{N_{C+} }\) and \(S_-^2 =V(\bar{X}_{T-} -\bar{X}_{C-} )=\frac{\sigma _{T-}^2 }{N_{T-} }+\frac{\sigma _{C-}^2 }{N_{C-} }\).
Then \(S^{2}=V\left( {\bar{X}_T -\bar{X}_C } \right) =V\left( {p_+ \bar{X}_+ +p_- \bar{X}_- } \right) =p_+^2 S_+^2 +p_-^2 S_-^2 \) (Lemma 1). Furthermore,
\(Z_+ =\frac{\bar{X}_{T+} -\bar{X}_{C+} }{S_+ }\sim N\left( {E\left( {Z_+ } \right) ,1} \right) \) and \(E\left( {Z_+ } \right) =\frac{\mu _+ }{S_+ }\),
\(Z_- =\frac{\bar{X}_{T-} -\bar{X}_{C-} }{S_- }\sim N\left( {E\left( {Z_- } \right) ,1} \right) \) and \(E\left( {Z_- } \right) =\frac{\mu _- }{S_- }\)
\(Z=\frac{\bar{X}_T -\bar{X}_C }{S}=p_+ \frac{S_+ }{S}Z_+ +p_- \frac{S_- }{S}Z_- =\sqrt{K_+ }Z_+ +\sqrt{K_- }Z_- \) (Lemma 2).
\(\mu =p_+ \mu _+ +p_- \mu _- \) (Lemma 4)
Lemma 1
The following relationship holds:
where \(S^{2}=V\left( {\bar{X}_T -\bar{X}_C } \right) ,S_+^2 =V\left( {\bar{X}_{T+} -\bar{X}_{C+} } \right) \) and \(S_-^2 =V\left( {\bar{X}_{T-} -\bar{X}_{C-} } \right) .\)
Proof
\(\square \)
Lemma 2
The overall study sample test statistic Z can be expressed in terms of the marker-positive and negative test statistics, \(Z_+ \) and \(Z_- \), as follows:
where \(K_+ =p_+^2 S_+^2 /S^{2}\) and \(K_- =p_-^2 S_-^2 /S^{2}\).
Proof
\(\square \)
Lemma 3
When the subgroup variances are equal, i.e., \(\sigma _{T+}^2 =\sigma _{C+}^2 =\sigma _{T-}^2 =\sigma _{C-}^2 \), then \(Z=\sqrt{p_+ }Z_+ +\sqrt{p_- }Z_- \).
Proof
When sample variances are equal among groups, note that
From Lemma 2, we observe that
\(\square \)
Lemma 4
The following relationship holds for population parameters \(\mu \), \(\mu _+ \) and \(\mu _- \):
where \(p_+ =1-p_- \) is the biomarker prevalence rate in the study.
Proof
Note that
Similarly,
Using Lemma 2, we observe that
Therefore, \(\mu =p_+ \mu _+ +p_- \mu _- \). \(\square \)
1.2.1 Safety boundary
We use the standardized safety boundary SB of \(-2\) for the marker-negative group in all numeric studies. That is, if \(Z_- \) falls below \(-2\), we will not reject the overall null hypothesis. The safety boundary, \(SB_\mu \), on the \(\mu \) scale can be easily calculated using the corresponding scaling factor:
1.2.2 Rejection regions
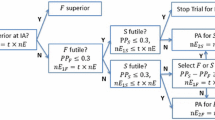
The proposed simultaneous test is based on the partition of the two-dimensional sample space of \(Z_- \) and \(Z_+ \) into two rejection regions and one acceptance region (Fig. 1). Based on the observed \((Z_- ,Z_+ )\), the proposed test will
-
(1)
Reject only \(H_{0+} ,\) if \(\left( {Z_- ,Z_+ } \right) \in R_1 \cup {\Delta }_1 \) (rejection region 1),
-
(2)
Reject both \(H_{0O} \) and \(H_{0+} \), if \(\left( {Z_- ,Z_+ } \right) \in R_2 \) (rejection region 2),
-
(3)
Reject neither \(H_{0O} \) nor \(H_{0+} \), if \(\left( {Z_- ,Z_+ } \right) \notin R_1 \cup {\Delta }_1 \cup R_2 .\)
Note that \(H_{0C} \) is rejected in any of the two rejection regions, that is, \(H_{0C} \) is rejected if \(\left( {Z_- ,Z_+ } \right) \in R_1 \cup {\Delta }_1 \cup R_2 \).
Provided below are calculations for the probability of the rejection regions. To ease the notation, we drop the subscript for standardized safety boundary and denote it SB.
Lemma 5
\(\mathop {\max }\limits _{\mu \le 0<\mu _+ } \alpha _{32} =\alpha _{31} (\mu =\mu _+ =0)\le \alpha _C (\mu =\mu _+ =0)\)
Proof
Let \(y=z_- -\frac{\mu }{p_- S_- }+\frac{p_+ \mu _+ }{p_- S_- }\). Then \(z_- =y+\frac{\mu }{p_- S_- }-\frac{p_+ \mu _+ }{p_- S_- }.\)
Note that \(\frac{\sqrt{K_- }}{\sqrt{K_+ }}z_- =\frac{\sqrt{K_- }}{\sqrt{K_+ }}\left( {y+\frac{\mu }{p_- S_- }-\frac{p_+ \mu _+ }{p_- S_- }} \right) =\frac{\sqrt{K_- }}{\sqrt{K_+ }}y+\frac{\sqrt{K_- }}{\sqrt{K_+ }}\frac{\mu }{p_- S_- }-\frac{\sqrt{K_- }}{\sqrt{K_+ }}\frac{p_+ \mu _+ }{p_- S_- }\)
Therefore,
Therefore, \(\alpha _{32} \) is a decreasing function of \(\mu _+ \) and an increasing function of \(\mu \). Thus, the maximum value for \(\alpha _{32} \) for \(\mu \le 0<\mu _+ \) is achieved at \(\mu _+ =\mu =0\), i.e., \(\,\mathrm{max}\left( {\alpha _{32} ,\mu \le 0<\mu _+ } \right) =\alpha _{31} (\mu =\mu _+ =0)\le \alpha _C (\mu =\mu _+ =0)\). \(\square \)
1.2.3 Effect sizes
We define effect sizes \(\delta \), \(\delta _+ \)and \(\delta _- \) in the overall, \(M_{+}\) and \(M_{-}\) subgroups as follows:
Note that our definition of effect size differs from commonly used definitions. It is common to define effect size as the ratio of treatment effect and the pooled estimate of standard deviation. However, since our test statistics do not rely on pooled estimates of standard deviation, but instead use statistics for two independent samples, our effect sizes are defined based on these statistics. Note that
Similarly,
and
Lemma 6
The following relationship among effect sizes \(\delta ,\delta _+ \)and \(\delta _- \)holds:
Proof
Note that \(\mu =p_+ \mu _+ +p_- \mu _- \) (Lemma 4). Therefore,
\(\square \)
Lemma 7
The following relationship among \(EZ,EZ_+ \)and \(EZ_- \)holds:
Proof
Using Lemma 4, we observe that
\(\square \)
Rights and permissions
About this article

Cite this article
Belitskaya-Lévy, I., Wang, H., Shih, MC. et al. A New Overall-Subgroup Simultaneous Test for Optimal Inference in Biomarker-Targeted Confirmatory Trials. Stat Biosci 10, 297–323 (2018). https://doi.org/10.1007/s12561-016-9174-8
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s12561-016-9174-8