
Abstract
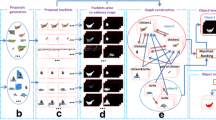
Automatic discovery of topical objects in video clips is a typical cognitive-related task and is essential for understanding and summarizing the video contents. In this paper, we propose a novel framework based on structured dictionary learning for such a task. Different from existing work which utilizes multiple segmentations to coarsely obtain the object regions, we adopt the most recently developed objectness operator to extract candidate objects. Such a method exhibits a great advantage that the interested object can be more reliably segmented. A structured dictionary learning method is proposed to discover the topical objects of the video clips. Such an optimization model exploits the temporal relation between video frames and therefore leads to better performance. Further, a globally convergent algorithm is developed to solve the structured dictionary learning problem, and extensive experiments on 10 Web video clips show that the proposed method outperforms the state-of-the-art methods.






Similar content being viewed by others


Notes
For the experiments, we used the code of [19] available online without any modifications or tuning. It takes only about 0.01 s to compute candidate windows for one image.
References
Zhao G, Yuan J, Xu J, Wu Y. Discovering the thematic object in commercial videos. IEEE Multimed. 2011;18(3):56–65.
Liu H, Liu Y, Yu Y, Sun F. Diversified key-frame selection using structured L 2,1 optimization. IEEE Trans Ind Inform. 2014;10(3):1736–45.
Liu H, Liu Y, Sun F. Video key-frame extraction for smart phones, Multimed Tools Appl., In press.
Navarretta C. The automatic identification of the producers of co-occurring communicative behaviours. Cogn Comput. 2014;6(4):689–98.
Chen Y, Zhou Q, Luo W, Du J, Classification of Chinese texts based on recognition of semantic topics, Cogn Comput., In press.
Yuan Y, Sun F. Data fusion-based resilient control system under DoS attacks: a game theoretic approach. Int J Control Autom Syst. 2015;13(3):513–20.
Sivic J, Russell B, Efros A, Zisserman A, Freeman W. Discovering objects and their location in images. In: Proceedings of international conference on computer vision (ICCV), 2005, pp. 370–377.
Russell B, Freeman W, Efros A, Sivic J, Zisserman A. Using multiple segmentations to discover objects and their extent in image collections. In: Proceedings of IEEE conference on computer vision and pattern recognition (CVPR), 2006, pp. 1605–1614.
Tunnermann J, Mertsching B. Region-based artificial visual attention in space and time. Cogn Comput. 2014;6(1):125–43.
Zhao G, Yuan J, Hua G. Topical video object discovery from key frames by modeling word co-occurrence prior. In: Proceedings of IEEE conference on computer vision and pattern recognition (CVPR), 2013; pp. 1602–1609.
Tang J, Lewis P. Non-negative matrix factorization for object class discovery and image auto-annotation. In: Proceedings of international conference on content-based image and video retrieval, 2008; pp. 105–112.
Liu T, Yuan Z, Sun J, Wang J, Zheng N, Tang X, Shum HY. Learning to detect a salient object. IEEE Trans Pattern Anal Mach Intell. 2011;33(2):353–67.
Zhu J, Wu J, Wei Y, Chang E, Tu Z. Unsupervised object class discovery via saliency-guided multiple class learning, In: Proceedings of IEEE conference on computer vision and pattern recognition (CVPR), 2012; pp. 3218–3225.
Liu D, Chen T. A topic-motion model for unsupervised video object discovery. In: Proceedings of IEEE conference on computer vision and pattern recognition (CVPR), 2014, pp. 1–8.
Zhao G, Yuan J. Discovering thematic patterns in videos via cohesive sub-graph mining. In: Proceedings of International conference on data mining (ICDM), pp. 1260–1265.
Zhao J, Sun S, Liu X, Sun J, Yang A. A novel biologically inspired visual saliency model. Cogn Comput. 2014;6(4):841–8.
Tu Z, Zheng A, Yang E, Luo B, Hussain A. A biologically inspired vision-based approach for detecting multiple moving objects in complex outdoor scenes. Cogn Comput. 2015;7(2):539–51.
Alexe B, Deselaers T, Ferrari V. What is an object?. In: Proceedings of IEEE conference on computer vision and pattern recognition (CVPR), 2010, pp. 73–80.
Cheng M, Zhang Z, Lin W, Torr P. BING: Binarized normed gradients for objectness estimation at 300fps. In: Proceedings of IEEE conference on computer vision and pattern recognition (CVPR), 2014, pp. 1–8.
Cheng H, Liu Z, Hou L, Yang J. Sparsity induced similarity measure and its applications. IEEE Trans Circuits Syst Video Technol., In press, doi:10.1109/TCSVT.2012.2225911.
Wang J, Su G, Xiong Y, Chen J, Shang Y, Liu J, Ren X. Sparse representation for face recognition based on constraint sampling and face alignment. Tsinghua Sci Technol. 2013;1:62–7.
Zheng Y, Sheng H, Zhang B, Zhang J, Xiong Z. Weight-based sparse coding for multi-shot person re-identification. Sci China Inform. Sci. 2015;58:100104(15).
Bolte J, Sabach S, Teboulle M. Proximal alternating linearized minimization for nonconvex and nonsmooth problems. Math Program. 2013;146:1–36.
Bao C, Ji H, Quan Y, Shen Z. \(l_0\) Norm based dictionary learning by proximal methods with global convergence. In: Proceedings of IEEE conference on computer vision and pattern recognition (CVPR), 2014, pp. 1–8.
Yuan J, Zhao G, Fu Y, Li Z, Katsaggelos A, Wu Y. Discovering thematic objects in image collections and videos. IEEE Trans Image Process. 2012;21(4):2207–19.
Acknowledgments
This study was jointly supported by National Key Project for Basic Research of China under Grant 2013CB329403, National Natural Science Foundation of China under Grant 61327809, and National High-tech Research and Development Plan under Grant 2015AA042306.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of Interest
Huaping Liu and Fuchun Sun declare that they have no conflict of interest.
Informed Consent
All procedures followed were in accordance with the ethical standards of the responsible committee on human experimentation (institutional and national) and with the Helsinki Declaration of 1975, as revised in 2008 (5). Additional informed consent was obtained from all patients for which identifying information is included in this article.
Human and Animal Rights
This article does not contain any studies with human or animal subjects performed by the any of the authors.
Rights and permissions
About this article

Cite this article
Liu, H., Sun, F. Discovery of Topical Objects from Video: A Structured Dictionary Learning Approach. Cogn Comput 8, 519–528 (2016). https://doi.org/10.1007/s12559-015-9381-5
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s12559-015-9381-5