
Abstract
Through a Privacy Calculus (i.e. risk–benefit trade-off) lens, this study identifies factors that contribute to consumers’ adoption of personalised nutrition services. We argue that consumers’ intention to adopt personalised nutrition services is determined by perceptions of Privacy Risk, Personalisation Benefit, Information Control, Information Intrusiveness, Service Effectiveness, and the Benevolence, Integrity, and Ability of a service provider. Data were collected in eight European countries using an online survey. Results confirmed a robust and Europe-wide applicable cognitive model, showing that consumers’ intention to adopt personalised nutrition services depends more on Perceived Personalisation Benefit than on Perceived Privacy Risk. Perceived Privacy Risk was mainly determined by perceptions of Information Control, whereas Perceived Personalisation Benefit primarily depended on Perceived Service Effectiveness. Services that required increasingly intimate personal information, and in particular DNA, raised consumers’ Privacy Risk perceptions, but failed to increase perceptions of Personalisation Benefit. Accordingly, to successfully exploit personalised nutrition, service providers should convey a clear message regarding the benefits and effectiveness of personalised nutrition services. Furthermore, service providers may reduce Privacy Risk by increasing consumer perceptions of Information Control. To enhance perceptions of both Information Control and Service Effectiveness, service providers should make sure that consumers perceive them as competent and reliable.
Similar content being viewed by others


Introduction
Research within the field of nutrigenomics has raised high expectations, as increased understanding of the genes–nutrition relationship holds the potential to revolutionise disease prevention and health promotion (Arkadianos et al. 2007; Williams et al. 2008). Once it has reached its maturity, nutrigenomics offers the opportunity to prevent disease and promote health through dietary advice tailored to the individual, also referred to as personalised nutrition, rather than homogenous groups within the population (Ghosh 2010). The urge for personalised nutrition is not surprising, as it may not only lead to the most relevant dietary advice, but also stimulate advice adherence (Hurlimann et al. 2014) through increased involvement (Lustria et al. 2009). Consumer reluctance to adopt personalised nutrition may, however, compromise the potential benefits resulting from personalised nutrition.
For consumers, enjoying the benefits of personalised nutrition is practically impossible without getting exposed to some degree of privacy risk, as personalised nutrition advice requires information regarding an individual’s: (1) lifestyle (i.e. questionnaires concerning dietary intake and physical activity), (2) phenotype (i.e. current health status based on, for instance, a blood test), and/or (3) genetic make-up (i.e. DNA profiling based on a buccal swab) (Gibney and Walsh 2013; Rimbach and Minihane 2009). Disclosing these types of personal information to a service provider that generates personalised nutrition advice implies potential negative consequences caused by privacy loss (Mothersbaugh et al. 2012). For instance, consumers may have trouble getting health insurance when their genetic information would be made known to their insurance company. Hence, consumers’ willingness to disclose personal information in return for the benefits of personalised nutrition advice, while putting at risk their privacy, is considered decisive in the adoption of personalised nutrition.
Although highly relevant for the domain of nutrition and health, consumers’ intention to engage in personalisation is most often studied in business-related contexts such as advertising and e-commerce (e.g. Li and Unger 2012; Taylor et al. 2009; van Doorn and Hoekstra 2013). Due to a difference in the intimacy level of the required personal information (e.g. demographics and purchase history vs. health information), it cannot be assumed that the findings from the business context are fully applicable to personalised nutrition. Hence, to successfully exploit personalised nutrition, knowledge on factors that contribute to consumers’ adoption of personalised nutrition is required. The current study, therefore, aims to provide insight into determinants of consumers’ intention to adopt personalised nutrition.
Theoretical framework
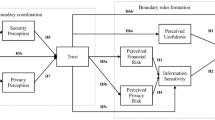
The theoretical framework (Fig. 1) of this study proposes consumers’ intention to adopt personalised nutrition to be determined by the shared impact of risk and benefit perceptions (Berezowska et al. 2014). The balance between desired benefits and undesired risks is assessed by combining risk and benefit perceptions into an overall information disclosure valuation (Li 2012), captured by the Privacy Calculus (Culnan and Armstrong 1999). The Privacy Calculus builds on the principles of behavioural decision-making theories (e.g. Blau 1964; Kahneman and Tversky 1979; Vroom 1964) in assuming that consumers behave in ways that maximise positive outcomes (i.e. benefits) and minimise negative outcomes (i.e. risks) resulting from information disclosure (Keith et al. 2013). Hence, consumers will only be willing to adopt personalised nutrition, rather than general dietary advice, if the perceived benefits of information disclosure offset the perceived risks of information disclosure (Dinev and Hart 2006). When the outcome of the Privacy Calculus is positive (i.e. perceived benefits are greater than perceived risks), consumers are more inclined to disclose personal information for the purpose of personalisation. In contrast, a negative Privacy Calculus outcome (i.e. perceived benefits are lower than perceived risks) is likely to result in the rejection of personalised nutrition (Xu et al. 2011). Therefore, we hypothesise that:

Theoretical framework
Hypothesis 1
The more positive the outcome of the Privacy Calculus, the more likely consumers are to adopt personalised nutrition services.
As risks and benefits of information disclosure for the purpose of personalisation generally revolve around privacy risks and personalisation benefits, we presume that the key drivers of the Privacy Calculus outcome will be consumer perceptions of Personalisation Benefit and Privacy Risk:
Hypothesis 2
The Privacy Calculus outcome is determined by perceptions of both Privacy Risk and Personalisation Benefit.
Personalisation Benefit can be viewed in terms of the personal value that consumers perceive to receive in return for information disclosure (Chellappa and Sin 2005). The value of personalised nutrition is, amongst others, based on the extent to which an individual expects that using personalised nutrition will help him/her to attain a particular goal (e.g. improve health) (Sweeney and Soutar 2001). Consumer perceptions of value, therefore, depend on the effectiveness of personalised nutrition, which is rooted in concepts such as usefulness (Davis 1989) and expected performance (Venkatesh et al. 2003). The extent to which consumers perceive engaging in personalised nutrition as effective is affected by a service provider’s Ability to transform the acquired personal information into a tailored and useful advice. That is to say, believing that a service provider is able to transform personal information into effective personalised nutrition advice assures consumers that engaging in personalised nutrition will enable them to achieve their goal (Earle 2010; Siegrist et al. 2005). Therefore, service providers who prompt higher levels of Perceived Ability will be seen as suppliers of more effective services, which in turn will increase consumers’ perception of Personalisation Benefit. Thus, we suggest that:
Hypothesis 3
Perceived Personalisation Benefit increases with increasing perceptions of Service Effectiveness.
Hypothesis 4
Perceived Service Effectiveness increases with increasing perceptions of a service provider’s Ability.
Privacy Risk perceptions are determined by the extent to which consumers believe that privacy loss is likely to occur (Smith et al. 2011). Perceptions of likely privacy loss are reduced if consumers feel in control of which personal information is disclosed and how the disclosed information is being used (Phelps et al. 2000). Hence, Information Control mitigates Perceived Privacy Risk by making consumers feel in control of the privacy risk they are exposed to (Margulis 2003). Consumer perceptions of Information Control result from the belief that a service provider is trustworthy and consequently will not misuse the disclosed personal information. If consumers perceive a service provider to be a person of Benevolence (i.e. wants to do good) and Integrity (i.e. adheres to sound moral and ethical principles), high perceptions of trustworthiness are in place (Colquitt et al. 2007). Therefore, service providers who induce high perceptions of Benevolence and Integrity are likely to increase consumer perceptions of Information Control and with that reduce consumer perceptions of Privacy Risk:
Hypothesis 5
Perceived Privacy Risk decreases with increasing perceptions of Information Control.
Hypothesis 6
Perceived Information Control increases with increasing perceptions of a service provider’s Benevolence.
Hypothesis 7
Perceived Information Control increases with increasing perceptions of a service provider’s Integrity.
Both Privacy Risk and Personalisation Benefit perceptions are likely to depend on the personal information that is required for personalisation to take place. Personal information allowing for personalisation varies in breadth and depth (Taddei and Contena 2013). Information breadth denotes the quantity of the required information, whereas information depth refers to the intimacy level of the information (Lee et al. 2013). Based on the extent to which the information is perceived to approach an individual’s core identity, personal information can be classified into four categories (Marx 2005) that increase in intimacy level: (1) individual information (e.g. demographics), (2) private information (e.g. lifestyle), (3) sensitive information (e.g. health status), and (4) unique information (e.g. DNA). The more information is required and the higher the intimacy level of this information, the greater the intrusiveness of the personal information. Consumers’ concern regarding information disclosure increases as personal information becomes more intrusive (Goldsmith et al. 2012; Li et al. 2011; Sheehan and Hoy 2000). At the same time, an increase in Information Intrusiveness leads to more effective personalised nutrition advice. Hence, the more intrusive the required personal information, the more likely it becomes that personalisation will result in valuable benefits, but also the more severe the consequences of possible privacy loss (Wendel et al. 2013). Consequently, we hypothesise that:
Hypothesis 8
Both Perceived Personalisation Benefit and Perceived Privacy Risk increase with increasing perceptions of Information Intrusiveness.
Once the cognitive process behind consumers’ intention to adopt personalised nutrition has been mapped, it is important to identify factors that drive this cognitive process. Looking at personalised nutrition as an information exchange process (van Trijp and Ronteltap 2007), it becomes clear that the cognitive process behind consumers’ intention to adopt personalised nutrition is fuelled by attributes that shape the way in which personalised nutrition advice is generated and provided. The information exchange process consists of three consecutive stages: (1) the consumer discloses personal information to a service provider; (2) the service provider uses the personal information to generate personalised nutrition advice; and (3) the service provider provides the personalised nutrition advice to the consumer (Ronteltap et al. 2013). Although personal information remains at the heart of personalised nutrition, the information exchange process suggests that service attributes such as communication mode, service scope, and service frequency also contribute to consumers’ intention to adopt personalised nutrition. Consumers may, for instance, be reluctant to disclose DNA to a service provider that limits himself to email communication (Metzger 2004) or perceive information disclosure as more valuable when nutrition advice is provided more than once (Seiders et al. 2014). Since consumers’ preference for and reaction to service attributes may differ from country to country (Pullman et al. 2001), to consolidate widespread adoption of personalised nutrition, it is important to identify which service attributes amplify or mitigate adoption intention across different countries.
Methods
Sample and procedure
To test the theoretical model, a total of 8136 participants from eight European countries (Greece, Spain, the Netherlands, Ireland, the UK, Germany, Poland, and Norway) participated in the study. To ensure nationally representative samples, participants were quota-sampled based on gender, age, region of residence, and highest level of education completed according to the International Standard Classification of Education (UNESCO Institute for Statistics 2012). Participants’ age was 41 years on average and ranged from 18 to 65. The sample included 49.9 % men. Of all participants, 29.9 % enjoyed tertiary education, 40.5 % obtained an upper-secondary or post-secondary education degree, and 30.5 % completed lower-secondary education or less.
Participants were sampled from the panels of a market research agency (GfK) and invited to participate in the survey by email. Completion of the online survey took about 18 min. The overall response rate was 51 %. To compensate for time and effort, participants were rewarded credits that accumulate to a gift voucher. Data were collected in November/December 2013.
Stimuli
Fictitious personalised nutrition services were used as stimulus material. A total of 144 services were generated using a full-factorial design combining five service attributes (personal information with four levels, service provider with three levels, communication mode with two levels, advice scope with three levels, and advice frequency with two levels) based on Berezowska et al. (2014) (Table 1). Each participant was shown two personalised nutrition services. To ensure intra-individual variance in the Information Intrusiveness construct, the two personalised nutrition services contained different levels of personal information. Taking account of this condition, the first personalised nutrition service was assigned completely at random, while the second personalised nutrition service was assigned partially at random. For instance, if the first service required DNA through the collection of a buccal swab, the second service had to require lifestyle information, phenotypic information through the collection of a blood sample, or the combination of phenotypic information and DNA. The service attribute levels of both personalised nutrition services were presented to the participants using pictograms supported by textual descriptions (Fig. 2). To control for assumptions regarding terms and conditions, participants were told that all services met the guidelines of the European Association of Dietitians (a non-existent organisation). Furthermore, to ensure that all services were evaluated from the same perspective, participants were instructed to imagine being in need of a service that could help them develop a healthier lifestyle.

Representation of personalised nutrition service descriptions
Measures
Measures were derived from existing scales adapted from prior studies (Table 2). As no relevant Information Intrusiveness scale was available, Information Intrusiveness items were developed based on Zwick and Dholakia (2004). All items were answered on seven-point scales ranging from strongly disagree to strongly agree or, in case of the Privacy Calculus, greater risks to greater benefits. The survey was pretested in the Netherlands using cognitive walkthrough interviews (N = 12). Based on the pretest minor amendments related to the questionnaire’s layout and comprehensiveness of the personalised nutrition service descriptions were made. To test the adequacy of the revised questionnaire, an online pilot study was conducted in the UK (N = 50) and the Netherlands (N = 50). The pilot study did not result in further amendments. Finally, the English questionnaire was translated and back-translated (Brislin 1970) into the national languages of the participating countries.
Data analysis
The proposed model was tested using confirmatory factor analysis and structural equation modelling with maximum likelihood estimation in the R package lavaan (Rosseel 2012).
First, to rule out the possibility of language causing differences between countries, the relationship between a latent construct and its items (i.e. measurement model) was assessed through a multi-group confirmatory factor analysis. Using one-factor models, cross-national equivalence of the employed measures was established on the basis of three consecutive tests (Steenkamp and Baumgartner 1998) for each latent construct individually. Test 1 checked whether the items of a particular measure loaded on the same latent construct in all countries, meaning that the conceptual definition of a latent construct was similar across countries (i.e. configural invariance). Test 1 was conducted for Perceived Benevolence of Service Provider only, given that, in the light of model identification, assessing configural invariance for one-factor models is solely meaningful when construct scales consist of at least four items (Brown 2006). Test 2 assessed whether the factor loadings of a particular item were equal across countries, indicating that a latent construct has the same meaning in all countries (i.e. metric invariance). Test 3 established whether the average item scores were equivalent across countries, showing that response patterns were equal across countries (i.e. scalar invariance). When cross-national equivalence was not reached, parameters related to configural, metric, and/or scalar invariance were relaxed based on the modification indices.
Second, to determine whether scalar invariance could be assigned to the overall measurement model, Test 3 was repeated using a multi-factor model consisting of all latent constructs and their items, while accounting for the relaxations suggested by the one-factor models.
Third, internal consistency of the latent constructs was evaluated on the basis of two reliability checks: (1) ω2, adequate when >0.7 (Nunnally 1978); and (2) average variance extracted (AVE), adequate when >0.5 (Fornell and Larcker 1981). Discriminant validity (i.e. the extent to which the measured constructs are distinct) was confirmed when the shared variation between a construct and its items (i.e. AVE) exceeded the shared variance between that particular construct and each of the other constructs (Fornell and Larcker 1981).
Fourth, the causal relations between the latent constructs (i.e. structural model) were assessed. To identify differences and similarities between countries, a multi-group structural equation model was performed. The structural model was tested in six steps that consecutively added equality constraints across countries: Step 1) strength of causal relation (i.e. path coefficient or β) between latent constructs is allowed to vary across countries; Step 2) strength of causal relation between latent constructs is not allowed to vary across countries; Step 3) variances and covariances amongst exogenous latent constructs Ability, Benevolence, Integrity, and Information Intrusiveness are not allowed to vary across countries; Step 4) regression intercepts for Information Control, Service Effectiveness, Privacy Risk, Personalisation Benefit, Privacy Calculus, and Adoption Intention are not allowed to vary across countries; Step 5) means for Ability, Benevolence, Integrity, and Information Intrusiveness are not allowed to vary across countries; and Step 6) the extent to which an explanatory variable explains an outcome variable is not allowed to vary across countries (i.e. R 2).
To determine whether both the measurement model and structural model were equal across countries, model fit was assessed based on four goodness of fit indices: (1) root mean square error of approximation (RMSEA), good if <.07; (2) standardised root mean square residual (SRMR), good if <0.08; (3) Comparative Fit Index (CFI), good if >0.95; and (4) Tucker-Lewis index (TLI), good if >0.95. The adopted cut-off values were derived from Hair et al. (2010).
To evaluate the main effects of the service attributes corrected for population variance, the individual cases (N = 16,272) were aggregated into 144 new cases representing each of the 144 personalised nutrition services. The aggregated data were analysed using multivariate analysis of variance with the service attributes as explanatory variables and Privacy Risk, Personalisation Benefit, Privacy Calculus, and Adoption Intention as outcome variables.
Results
Measurement model
To rule out the possibility of language causing differences between countries, the relationships between the different latent construct and their items were subjected to several tests.
Partial configural invariance was confirmed for Perceived Benevolence of Service Provider, implying that its conceptual definition was similar across countries (Table 3). Partial configural invariance for Perceived Benevolence of Service Provider was reached by introducing error covariance between item 1 (concerned about welfare) and item 4 (goes out of its way to help).
Metric invariance was achieved for all multi-item constructs, except Perceived Benevolence of Service Provider, indicating that the latent constructs have the same meaning in all countries. Partial metric invariance for Perceived Benevolence of Service Provider was reached after relaxing the equality constrain for the error covariance between item 1 and item 4 in the case of Norway.
Demonstrating equal response patterns across countries, scalar invariance was achieved for Perceived Integrity of Service Provider, Perceived Ability of Service Provider, Perceived Information Control, Perceived Information Intrusiveness, Perceived Service Effectiveness, Perceived Privacy Risk, and Perceived Personalisation Benefit. After relaxing some equality constraints (see Table 3), partial scalar invariance was obtained for Perceived Benevolence of Service Provider and Adoption Intention. After relaxing the relevant parameters, CFI, TLI, and SRMR showed good fit for all constructs. The RMSEA indicated good fit for all constructs except Perceived Benevolence of Service Provider (RMSEA = 0.079) and Adoption Intention (RMSEA = 0.076). These RMSEA values could, however, be considered sufficiently close to good fit at this stage (Baumgartner and Homburg 1996).
Given that the Privacy Calculus was a single-item construct, establishing configural, metric, and scalar invariance was irrelevant. Furthermore, measuring the Privacy Calculus with only one item made estimating the item’s error variance impossible. To distribute variance between the latent construct and the item, the error variance of the single-item construct Privacy Calculus was set to 20 % (Fuchs and Diamantopoulos 2009).
Since the CFI, TLI, RMSEA, and SRMR values for the overall measurement model indicated good fit (Table 3), it can be assumed that despite the difference in language, the measurement model is equal across all participating countries.
All constructs fulfilled the requirements for internal consistency. The ω2 values ranged from 0.888 to 0.969. The AVE values ranged from 0.712 to 0.913. Discriminant validity was adequate across all constructs except Benevolence of Service Provider. Benevolence of Service Provider was not distinct from Integrity of Service Provider in the case of Norway, Germany, Greece, Poland, and the Netherlands. Nevertheless, considering the (1) evidence for discriminant validity of the two constructs in the other countries, (2) AVE for Integrity of Service Provider (0.816–0.876) being considerably larger than the between-construct variance (0.757–0.799), and (3) almost identical values of the AVE for Benevolence of Service Provider (0.712–0.772) and the between-construct variance (0.757–0.799), it was decided that Benevolence of Service Provider and Integrity of Service Provider would not be merged.
Structural model
Table 4 shows the fit measures for the six consecutive steps based on which differences and similarities between the causal relations across countries were assessed. Although most fit measures met the proposed cut-off values, the SRMR values were slightly higher than the recommended cut-off criterion. As adding relations would diminish the parsimony of our model and introduce empirically determined rather than theoretical relations, it was decided to not adjust the model.
Correlations between Ability of Service Provider, Benevolence of Service Provider, Integrity of Service Provider, and Information Intrusiveness were high and ranged from 0.64 to 0.87 (p < 0.001).
Hypothesis testing
The first important finding is the fact that all hypothesised relations were significant and equal across countries (Fig. 3). In addition, the extent to which the model explained Information Control, Service Effectiveness, Personalisation Benefit, Privacy Calculus, and Adoption Intention was substantial, as the proportions of explained variance ranged from 36 to 70 %. With 8 %, the explained variance of Perceived Privacy Risk was modest (R 2 = 0.08).

Final structural model
As expected based on Hypothesis 1, Adoption Intention was determined by the outcome of the Privacy Calculus. The more positive the outcome of the Privacy Calculus, the higher the participants’ intention to adopt personalised nutrition services (β = .60; p < .001). Confirming Hypothesis 2, the outcome of the Privacy Calculus depended on both Privacy Risk and Personalisation Benefit perceptions. Perceived Privacy Risk had a negative effect on the outcome of the Privacy Calculus (β = −.25; p < .001), while Perceived Personalisation Benefit had a positive effect on the outcome of the Privacy Calculus (β = .65; p < .001). Compared to the path coefficient of Privacy Risk, the path coefficient of Personalisation Benefit was almost three times as high.
Confirming Hypothesis 3 and Hypothesis 8b, Perceived Personalisation Benefit depended on participants’ perceptions of Service Effectiveness and Information Intrusiveness. Perceived Service Effectiveness and Perceived Information Intrusiveness were positively related to Perceived Personalisation Benefit, meaning that an increase in both Service Effectiveness (β = .69; p < .001) and Information Intrusiveness (β = .23; p < .001) results in higher perceptions of Personalisation Benefit. Comparing the path coefficients of Perceived Service Effectiveness and Perceived Information Intrusiveness, the effect of Perceived Service Effectiveness on Perceived Personalisation Benefit was three times as high. In line with Hypothesis 4, Perceived Service Effectiveness depended on the Perceived Ability of the Service Provider. As the Perceived Ability of the Service Provider rose, so did participants’ perceptions of Service Effectiveness (β = .81; p < .001).
In line with Hypothesis 5 and Hypothesis 8a, Perceived Privacy Risk was affected by both Perceived Information Intrusiveness and Perceived Information Control. The relation between Information Intrusiveness and Perceived Privacy Risk was positive (β = .07; p < .001), indicating that an increase in Information Intrusiveness caused an increase in the perception of Privacy Risk. The influence of Perceived Information Intrusiveness on Perceived Privacy Risk was, however, minor. In the case of Perceived Information Control, participants’ perception of Privacy Risk decreased as perception of Information Control increased (β = −.32; p < .001). Consistent with Hypothesis 6 and Hypothesis 7, Perceived Information Control was determined by both Perceived Benevolence of the Service Provider and Perceived Integrity of the Service Provider. An increase in both Benevolence (β = .43; p < .001) and Integrity (β = .29; p < .001) enhanced participants’ perceptions of Information Control.
The impact of the service attributes on the cognitive process behind consumers’ intention to adopt personalised nutrition was minor. Although most of the service attributes had a significant effect on the Perceived Ability of the Service Provider, Benevolence of the Service Provider, Integrity of the Service Provider, and Information Intrusiveness, the extent to which the service attributes explained each of these latent constructs was approximately 1 % (Table 5). Aggregated data showed that Adoption Intention was affected by Personal Information, Service Provider, and Communication Mode. The outcome of the Privacy Calculus was influenced by all service attributes except Advice Scope. Perceptions of Privacy Risk were induced by Personal Information and the Service Provider. Disclosing unique information (i.e. DNA) and services offered by an employer was perceived as most risky, whereas private information (i.e. lifestyle) and services offered by a fitness clubs was perceived as least risky. Perceived Personalisation Benefit resulted from the service attributes Advice Scope, Advice Frequency, and Service Provider. Nutrition and exercise advice that was offered on a monthly basis by a fitness club was perceived as most beneficial. Communicating by means of personal contact had a positive effect on the Privacy Calculus and Adoption Intention as it reduced Privacy Risk perceptions and increased Personalisation Benefit perceptions (Table 6).
Discussion
This study developed and tested a comprehensive model explaining consumers’ intention to adopt personalised nutrition services. Confirming all hypothesised relations, we find strong support for the proposed model. Moreover, we show that the basic model structure is generalisable to eight European countries. Together, these findings point towards a robust and Europe-wide applicable cognitive model that predicts differences in consumers’ intention to adopt personalised nutrition.
The proposed cognitive model postulates a central role for the Privacy Calculus in consumers’ intention to adopt personalised nutrition services. Most studies that assume the Privacy Calculus to mediate the relationship between risk and benefit perceptions on the one hand and intention on the other, do not explicitly measure the outcome of such calculus (e.g. Dinev et al. 2013; Keith et al. 2013; Xu et al. 2013). Reasons for omitting an explicit Privacy Calculus measure may stem from the belief that the Privacy Calculus does not contribute beyond perceptions of Privacy Risk and Personalisation Benefit. The current study, however, suggests that including an explicit Privacy Calculus measure supports the understanding of Adoption Intention without affecting the explanatory power of risk and benefit perceptions. Including an explicit Privacy Calculus measure in addition to Privacy Risk and Personalisation Benefit measures is, therefore, recommended.
The Privacy Calculus depends more on consumer perceptions of Personalisation Benefit than on perceptions of Privacy Risk. The dominant role of Perceived Personalisation Benefit is in line with the “privacy paradox” (e.g. Bélanger and Crossler 2011; Pavlou 2011; Smith et al. 2011), which implies that consumers tend to put their privacy concerns aside if they expect information disclosure to result in attractive benefits. As most consumers perceive products and services that are tailored to their specific needs to be beneficial (e.g. Franke et al. 2009; Kalyanaraman and Sundar 2006), it is likely that the effect of Privacy Risk perceptions on the Privacy Calculus may have been offset by perceptions of Personalisation Benefit.
Our findings show that disclosing increasingly intimate personal information did not result in higher perception of Personalisation Benefit, but did increase perceptions of Privacy Risk. This suggests that consumers are aware of the Privacy Risk that is induced by the disclosure of highly intimate personal information (i.e. DNA), but not of the Personalisation Benefit. In the light of the Privacy Calculus, this would mean that the benefits resulting from disclosing highly intimate personal information may not suffice to offset the risk associated with the disclosure of highly intimate information. Such risk–benefit balance is likely to lead consumers towards “intermediate” levels of personalised nutrition that are less intrusive but also less effective. Hence, although studies into DNA-based personalised nutrition advice report consumers to favour personalised over general nutrition advice (e.g. Nielsen and El-Sohemy 2012; Nielsen et al. 2014), we should not lose sight of the role that Privacy Risk plays in consumers’ intention to adopt personalised nutrition. To offset Privacy Risk perceptions, service providers may even need to educate consumers about the benefits of DNA-based personalised nutrition, over and above those of lifestyle- and phenotype-based personalised nutrition.
Compared to the other latent constructs included in our theoretical model, the explained variance of Perceived Privacy Risk was modest. Reasons for this low percentage of explained variance in the Privacy Risk construct may be twofold. First, the applied methodology may have induced a non-committal way of consumers expressing their Adoption Intention, which may have inhibited participants from taking a closer look at Privacy Risk determinants such as Information Control and Information Intrusiveness. Hence, in situations where the decision to engage with a personalised nutrition service is no longer hypothetical (Hofstetter et al. 2013), the effect of Perceived Information Control and Perceived Information Intrusiveness on Privacy Risk perceptions may be larger than would be expected on the basis of the current findings (Trope and Liberman 2010). Second, the specific operationalisation of privacy risk may have steered respondents towards privacy risk determinants related to information exchange, rather than those related to information management (Hong and Thong 2013). Information management-related privacy concerns such as unauthorised access due to inadequate information storage security (Anton et al. 2010) may provide additional insight into consumers’ Privacy Risk perception (Cortese and Lustria 2012; Smith et al. 1996; Zhou 2011). Future research is recommended to include both information exchange and information management-related determinants of Privacy Risk.
With regard to the trust dimensions (Mayer and Davis 1999), Perceived Ability of the Service Provider (i.e. competence) had a large effect on Perceived Service Effectiveness and through that on consumer perceptions of Personalisation Benefit. Furthermore, Perceived Benevolence and Integrity of the Service Provider (i.e. reliability) influenced Perceived Information Control and through that Perceived Privacy Risk. In the current analysis, we followed the idea that each of the trust dimensions has a distinct contribution to the decision process (Colquitt et al. 2007; Terwel et al. 2009). That is, competence-related trust dimensions may be associated with consumers’ confidence in service effectiveness (Earle 2010; Siegrist et al. 2005), while reliability-related trust dimensions may be linked to social trust that comprises the belief whether service providers can be relied on when it comes to having control over personal information (Earle and Cvetkovich 1995). Although the current findings support the idea of the different trust dimensions playing a distinct role in the decision-making process, we cannot be conclusive about how the different trust dimensions are best positioned in the hypothesised model. Future research should, therefore, systematically test the relevance of each trust dimension on the different latent constructs.
Considering the extent to which the proposed constructs explained consumers’ intention to adopt personalised nutrition, the overall performance of the theoretical model was good. Compared to the latent constructs, the effect of the service attributes on Adoption Intention was, however, small. The difference in the extent to which the latent constructs and service attributes were able to explain Adoption Intention may be caused by the design of this study and participants’ lack of knowledge about or relevance of personalised nutrition service attributes. Evaluating two of the 144 personalised nutrition services without being familiar with the full range of possible service attributes may have caused the within-participant measured effects of the latent constructs to dominate over the between-participant measured effects of the services attributes.
In relation to overall health, the present study examined consumers’ intention to adopt personalised nutrition services based on the perceived benefits of personalised nutrition advice compared to general nutrition advice. It is important to recognise that the benefits of improved overall health, in most instances, will only materialise if consumers adhere to the provided nutrition advice. Future research is needed to better understand the drivers and barriers of adherence to personalised nutrition advice. Important in this respect is also that some health benefits may be experienced shortly after engaging with a personalised nutrition service (e.g. increase in physical fitness), while other health benefits only materialise over a longer period of time (e.g. prevention of chronic diseases). Lack of direct feedback on long-term health improvement may, however, reduce motivation to adhere to the advice. Future research should identify whether and how direct feedback may contribute to advice adherence, either through directly perceivable improvements related to, for instance, physical performance, and/or the use of more dynamic assessments enabled by wearable devices capable of monitoring relevant biomarkers.
Conclusion
This study confirmed a robust and Europe-wide applicable cognitive model showing how the Privacy Calculus and its antecedents determine consumers’ intention to adopt personalised nutrition services. For theory, the model implies that consumers’ intention to adopt personalised nutrition services depends more on perceptions of Personalisation Benefit than on perceptions of Privacy Risk. At the practical level, this implication suggests that to consolidate adoption, providers of services that require highly intrusive personal information such as DNA should pay attention to possible privacy risks that may keep consumers from engaging with their service. Service providers may reduce consumers’ Privacy Risk perceptions by, where possible, using less intrusive types of personal information such as lifestyle information and phenotypic information, or alternatively, and offer the option of using pseudonyms to anonymise data. Furthermore, it is important to more strongly emphasise and communicate the benefits of engaging with personalised rather than with non-personalised nutrition services, particularly how and why DNA profiling contributes to superior nutrition advice. Finally, to increase consumers’ perception of Personalisation Benefit, service providers should optimise the effectiveness of their service. Promising tools that may help increase service effectiveness are face-to-face communication and regular meetings.
References
Anton AI, Earp JB, Young JD (2010) How internet users’ privacy concerns have evolved since 2002. IEEE Secur Priv 8:21–22
Arkadianos I, Valdes AM, Marinos E, Florou A, Gill RD, Grimaldi KA (2007) Improved weight management using genetic information to personalize a calorie controlled diet. Nutr J 6:29. doi:10.1186/1475-2891-6-29
Baumgartner H, Homburg C (1996) Applications of structural equation modeling in marketing and consumer research: a review. Int J Res Mark 13:139–161
Bélanger F, Crossler RE (2011) Privacy in the digital age: a review of information privacy research in information systems. MIS Q 35:1017–1041
Berezowska A, Fischer ARH, Ronteltap A, Kuznesof S, Macready A, Fallaize R, van Trijp HCM (2014) Understanding consumer evaluations of personalised nutrition services in terms of the privacy calculus: a qualitative study. Public Health Genomics 17:127–140. doi:10.1159/000358851
Blau PM (1964) Exchange and power in social life. Wiley, New York
Brislin RW (1970) Back-translation for cross-cultural research. J Cross-Cult Psychol 1:185–216. doi:10.1177/135910457000100301
Brown TA (2006) Confirmatory factor analysis for applied research. Guilford Press, New York
Chellappa RK, Sin RG (2005) Personalization versus privacy: an empirical examination of the online consumer’s dilemma. Inf Technol Manag 6:181–202
Colquitt JA, Scott BA, LePine JA (2007) Trust, trustworthiness, and trust propensity: a meta-analytic test of their unique relationships with risk taking and job performance. J Appl Psychol 92:909–927. doi:10.1037/0021-9010.92.4.909
Cortese J, Lustria MLA (2012) Can tailoring increase elaboration of health messages delivered via an adaptive educational site on adolescent sexual health and decision making? J Am Soc Inform Sci Technol 63:1567–1580. doi:10.1002/asi.22700
Culnan MJ, Armstrong PK (1999) Information privacy concerns, procedural fairness, and impersonal trust: an empirical investigation. Organ Sci 10:104–115. doi:10.1287/orsc.10.1.104
Davis F (1989) Perceived usefulness, perceived use, and user acceptance of information technology. MIS Q 13:319–340
Dinev T, Hart P (2006) An extended privacy calculus model for e-commerce transactions. Inf Syst Res 17:61–80. doi:10.1287/isre.1060.0080
Dinev T, Xu H, Smith JH, Hart P (2013) Information privacy and correlates: an empirical attempt to bridge and distinguish privacy-related concepts. Eur J Inf Syst 22:295–316. doi:10.1057/ejis.2012.23
Earle TC (2010) Trust in risk management: a model-based review of empirical research. Risk Anal 30:541–574. doi:10.1111/j.1539-6924.2010.01398.x
Earle TC, Cvetkovich G (1995) Social trust: toward a cosmopolitan society. Praeger, Westport
Fornell C, Larcker DF (1981) Evaluating structural equation models with unobservable variables and measurement error. J Mark Res 18:39–50. doi:10.2307/3151312
Franke N, Keinz P, Steger CJ (2009) Testing the value of customization: When do customers really prefer products tailored to their preferences? J Mark 73:103–121. doi:10.1509/jmkg.73.5.103
Fuchs C, Diamantopoulos A (2009) Using single-item measures for construct measurement in management research. Die Betriebswirtschaft 69:195–210
Ghosh D (2010) Personalised food: How personal is it? Genes Nutr 5:51–53. doi:10.1007/s12263-009-0139-0
Gibney MJ, Walsh MC (2013) The future direction of personalised nutrition: my diet, my phenotype, my genes. Proc Nutr Soc 72:219–225. doi:10.1017/s0029665112003436
Goldsmith L, Jackson L, O’Connor A, Skirton H (2012) Direct-to-consumer genomic testing: systematic review of the literature on user perspectives. Eur J Hum Genet 20:811–816. doi:10.1038/ejhg.2012.18
Hair JF, Black WC, Babin BJ (2010) Multivariate data analysis: a global perspective. Pearson Education, Upper Saddle River
Hofstetter R, Miller KM, Krohmer H, Zhang ZJ (2013) How do consumer characteristics affect the bias in measuring willingness to pay for innovative products? J Prod Innov Manag 30:1042–1053. doi:10.1111/jpim.12040
Hong WY, Thong JYL (2013) Internet privacy concerns: an integrated conceptualization and four empirical studies. MIS Q 37:275–298
Hurlimann T, Menuz V, Graham J, Robitaille J, Vohl MC, Godard B (2014) Risks of nutrigenomics and nutrigenetics? What the scientists say. Genes Nutr. doi:10.1007/s12263-013-0370-6
Kahneman D, Tversky A (1979) Prospect theory: an analysis of decision under risk. Econometrica 47:263–291
Kalyanaraman S, Sundar SS (2006) The psychological appeal of personalized content in web portals: does customization affect attitudes and behavior? J Commun 56:110–132. doi:10.1111/j.1460-2466.2006.00006.x
Keith MJ, Thompson SC, Hale J, Lowry PB, Greer C (2013) Information disclosure on mobile devices: re-examining privacy calculus with actual user behavior International. J Hum Comput Stud 71:1163–1173. doi:10.1016/j.ijhcs.2013.08.016
Kim S, Park H (2013) Effects of various characteristics of social commerce (s-commerce) on consumers’ trust and trust performance. Int J Inf Manage 33:318–332. doi:10.1016/j.ijinfomgt.2012.11.006
Lee H, Park H, Kim J (2013) Why do people share their context information on Social Network Services? A qualitative study and an experimental study on users’ behavior of balancing perceived benefit and risk. Int J Hum Comput Stud 71:862–877. doi:10.1016/j.ijhcs.2013.01.005
Li Y (2012) Theories in online information privacy research: a critical review and an integrated framework. Decis Support Syst 54:471–481. doi:10.1016/j.dss.2012.06.010
Li T, Unger T (2012) Willing to pay for quality personalization? Trade-off between quality and privacy. Eur J Inf Syst 21:621–642. doi:10.1057/ejis.2012.13
Li H, Sarathy R, Xu H (2011) The role of affect and cognition on online consumers’ decision to disclose personal information to unfamiliar online vendors. Decis Support Syst 51:434–445. doi:10.1016/j.dss.2011.01.017
Lustria MLA, Cortese J, Noar SM, Glueckauf RL (2009) Computer-tailored health interventions delivered over the web: review and analysis of key components. Patient Educ Couns 74:156–173. doi:10.1016/j.pec.2008.08.023
Margulis ST (2003) Privacy as a social issue and behavioral concept. J Soc Issues 59:243–261. doi:10.1111/1540-4560.00063
Marx GT (2005) Varieties of personal information as influences on attitudes towards surveillance. In: Haggerty KD, Ericson RV (eds) The new politics of surveillance and visibility. University of Toronto Press, Toronto, pp 79–110
Mayer RC, Davis JH (1999) The effect of the performance appraisal system on trust for management: a field quasi-experiment. J Appl Psychol 84:123–136. doi:10.1037/0021-9010.84.1.123
Metzger MJ (2004) Privacy, trust, and disclosure: exploring barriers to electronic commerce. J Comput Mediat Commun. doi:10.1111/j.1083-6101.2004.tb00292.x
Mothersbaugh DL, Foxx WK, Beatty SE, Wang SJ (2012) Disclosure antecedents in an online service context: the role of sensitivity of information. J Serv Res 15:76–98. doi:10.1177/1094670511424924
Nielsen DE, El-Sohemy A (2012) A randomized trial of genetic information for personalized nutrition. Genes Nutr 7:559–566. doi:10.1007/s12263-012-0290-x
Nielsen DE, Shih S, El-Sohemy A (2014) Perceptions of genetic testing for personalized nutrition: a randomized trial of dna-based dietary advice. J Nutrigenet Nutrigenomics 7:94–104. doi:10.1159/000365508
Nunnally JC (1978) Psychometric theory. McGraw-Hill, New York
Pavlou PA (2011) State of the information privacy literature: Where are we now and where should we go? MIS Q 35:977–988
Phelps J, Nowak G, Ferrell E (2000) Privacy concerns and consumer willingness to provide personal information. J Public Policy Mark 19:27–41. doi:10.1509/jppm.19.1.27.16941
Pullman ME, Verma R, Goodale JC (2001) Service design and operations strategy formulation in multicultural markets. J Oper Manag 19:239–254. doi:10.1016/S0272-6963(00)00059-0
Rimbach G, Minihane AM (2009) Nutrigenetics and personalised nutrition: How far have we progressed and are we likely to get there? Proc Nutr Soc 68:162–172. doi:10.1017/S0029665109001116
Ronteltap A, van Trijp HCM, Berezowska A, Goossens J (2013) Nutrigenomics-based personalised nutritional advice. In search of a business model? Genes Nutr 8:153–163. doi:10.1007/s12263-012-0308-4
Rosseel Y (2012) Lavaan: an R package for structural equation modeling. J Stat Softw 48:1–36
Seiders K, Flynn AG, Berry LL, Haws KL (2014) Motivating customers to adhere to expert advice in professional services a medical service context. J Serv Res 18:39–58. doi:10.1177/1094670514539567
Sheehan KB, Hoy MG (2000) Dimensions of privacy concern among online consumers. J Public Policy Mark 19:62–73. doi:10.1509/jppm.19.1.62.16949
Siegrist M, Gutscher H, Earle TC (2005) Perception of risk: the influence of general trust, and general confidence. J Risk Res 8:145–156. doi:10.1080/1366987032000105315
Smith HJ, Milberg SJ, Burke SJ (1996) Information privacy: measuring individuals’ concerns about organizational practices. MIS Q 20:167–196. doi:10.2307/249477
Smith HJ, Dinev T, Xu H (2011) Information privacy research: an interdisciplinary review. MIS Q 35:989–1015
Steenkamp J-BEM, Baumgartner H (1998) Assessing measurement invariance in cross-national consumer research. J Consum Res 25:78–107. doi:10.1086/209528
Sweeney JC, Soutar GN (2001) Consumer perceived value: the development of a multiple item scale. J Retail 77:203–220. doi:10.1016/S0022-4359(01)00041-0
Taddei S, Contena B (2013) Privacy, trust and control: Which relationships with online self-disclosure? Comput Hum Behav 29:821–826. doi:10.1016/j.chb.2012.11.022
Taylor DG, Davis DF, Jillapalli R (2009) Privacy concern and online personalization: the moderating effects of information control and compensation. Electron Commer Res 9:203–223. doi:10.1007/s10660-009-9036-2
Terwel BW, Harinck F, Ellemers N, Daamen DDL (2009) Competence-based and integrity-based trust as predictors of acceptance of carbon dioxide capture and storage (CCS). Risk Anal 29:1129–1140. doi:10.1111/j.1539-6924.2009.01256.x
Trope Y, Liberman N (2010) Construal-level theory of psychological distance. Psychol Rev 117:440–463. doi:10.1037/a0018963
UNESCO Institute for Statistics (2012) International Standard Classification of Education ISCED 2011. Montreal
van Doorn J, Hoekstra JC (2013) Customization of online advertising: the role of intrusiveness. Mark Lett 24:339–351. doi:10.1007/s11002-012-9222-1
van Trijp JCM, Ronteltap A (2007) A marketing and consumer behaviour perspective on personalised nutrition. In: Kok F, Bouwman L, Desiere F (eds) Personalized nutrition: principles and applications. CRC Press, Boca Raton, pp 185–204
Venkatesh V, Morris MG, Davis GB, Davis FD (2003) User acceptance of information technology: toward a unified view. MIS Q 27:425–478
Vroom VH (1964) Work and motivation. Wiley, New York
Wendel S, Dellaert BGC, Ronteltap A, van Trijp HCM (2013) Consumers’ intention to use health recommendation systems to receive personalized nutrition advice. BMC Health Serv Res 13:126. doi:10.1186/1472-6963-13-126
Williams C, Ordovas J, Lairon D, Hesketh J, Lietz G, Gibney M, van Ommen B (2008) The challenges for molecular nutrition research 1: linking genotype to healthy nutrition. Genes Nutr 3:41–49. doi:10.1007/s12263-008-0086-1
Xu H, Teo HH, Tan BCY, Agarwal R (2009) The role of push–pull technology in privacy calculus: the case of location-based services. J Manage Inf Syst 26:135–173. doi:10.2753/mis0742-1222260305
Xu H, Luo X, Carroll JM, Rosson MB (2011) The personalization privacy paradox: an exploratory study of decision making process for location-aware marketing. Decis Support Syst 51:42–52. doi:10.1016/j.dss.2010.11.017
Xu F, Michael K, Chen X (2013) Factors affecting privacy disclosure on social network sites: an integrated model. Electron Commer Res 13:151–168. doi:10.1007/s10660-013-9111-6
Zarmpou T, Saprikis V, Markos A, Vlachopoulou M (2012) Modeling users’ acceptance of mobile services. Electron Commer Res 12:225–248. doi:10.1007/s10660-012-9092-x
Zhou T (2011) The impact of privacy concern on user adoption of location-based services. Ind Manage Data Syst 111:212–226. doi:10.1108/02635571111115146
Zwick D, Dholakia N (2004) Whose identity is it anyway? Consumer representation in the age of database marketing. J Macromarketing 24:31–43. doi:10.1177/0276146704263920
Acknowledgments
This research was carried out within the context of Food4Me, which is the acronym of the EU FP7 project “Personalised nutrition: an integrated analysis of opportunities and challenges” (Contract No. KBBE.2010.2.3-02, Project No. 265494), http://www.food4me.org/. The authors would like to thank Hans Marvin, the Polish Food and Nutrition Institute, University College Dublin, Harokopio University, Technical University of Munich, University of Navarra, and University of Reading for their contribution to this study.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
Authors declare that they have no conflict of interest.
Informed consent and animal rights statements
All procedures performed in studies involving human participants were in accordance with the ethical standards of the institutional and/or national research committee and with the 1964 Helsinki Declaration and its later amendments or comparable ethical standards). Informed consent was obtained from all individual participants for being included in the study.
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Berezowska, A., Fischer, A.R.H., Ronteltap, A. et al. Consumer adoption of personalised nutrition services from the perspective of a risk–benefit trade-off. Genes Nutr 10, 42 (2015). https://doi.org/10.1007/s12263-015-0478-y
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s12263-015-0478-y