
Abstract
Additive manufacturing (AM), or popular scientific 3D printing, disseminates in more and more production processes. This changes not only production processes themselves, e.g. by replacing subtractive production technologies, but AM will in all likelihood also impact the configuration of supply networks. Due to a more efficient use of raw materials, transportation relations may change and production sites may be relocated. How this change will look like is part of an ongoing discussion in industry and academia. However, quantitative studies on this question are scarce. In order to quantify the potential impact of AM on a two-stage supply network, we use a facility location model. The impact of AM on the production process is integrated into the model by varying resource efficiency ratios. We create a test data set of 700 instances. Features of this data set are, among others, different geographical clusters of source nodes, production nodes, and customer nodes. By means of a computational study, the impact of AM on the supply network structure is measured by four indicators. In the context of our experimental set-up, AM reduces the overall transportation costs of a supply network compared to subtractive production. However, the share of the transportation costs on the second stage of a supply network in the total costs increases significantly. Therefore, supply networks in which production sites and customer sites are closely spaced improve their cost-effectiveness stronger than other regional configurations of supply networks.
Similar content being viewed by others


1 Introduction
Due to the technological enhancement of additive manufacturing (AM) over the past years, AM starts to replace subtractive production technologies. In some fields of use, AM is competitive, because it reduces production costs and at the same time improves the range of features of components. But if one production technology is replaced by another, this can change production and logistics processes as well. Still it appears that the focus in research is on improving the actual AM production technology, although industry and academia are aware of possible broader implications of AM, e.g. on supply networks. Potential implications of AM on supply networks are discussed. Tuck et al. [17], Fawcett and Waller [8], Cottrill [6], Christopher and Ryals [5] and Waller and Fawcett [18] study and evaluate implications of AM, but they are of a qualitative nature. We are not aware of study that measures impacts of AM on supply networks and quantifies these effects. Only a few quantitative assessments like a case study of Khajavi et al. [13] on a spare parts supply chain in the aeronautics industry are available, which, however, focuses on accounting issues. Quantifying the impact of AM on supply networks appears to be important in order to support managerial decisions on the structure of the future supply network.
The contribution of this study is as follows: We quantify the effects of AM on a two-stage supply network. Raw material is transported from sources (e.g. a port) to production sites and then to customer locations. We model this problem as a well-known multi-stage facility location problem. A data set of 700 instances is generated that covers a broad range of geographical distributions of the nodes in the network. The effect of AM is integrated by using different buy-to-fly ratios, which represent the efficiency of material usage in a production process. By comparing less efficient buy-to-fly ratios (i.e. traditional production) with more efficient ratios (i.e. AM), we can compare different optimal network configurations. This is done for each of the 700 instances. Four indicators measure the performance of the generated networks. In contrast to our previous study [3], the evaluation is significantly extended: instead of six instances, a set of 700 instances is generated and used for testing. We included several more structures in these instances, in particular with respect to the geographical distribution of nodes as well as a different clustering of nodes. In our previous study, the geographical distribution of the nodes was roughly based on the network structures in Germany and USA. In this contribution, the geographical distribution of the different nodes is created more abstractly (i.e. not based on any country’s supply structure) and more systematically. Therefore, broader and validated statements are possible.
This article is structured in five sections. After this introduction, Sect. 2 will give a brief overview of AM and describe technological aspects which probably will have implications on the structure of supply networks. Section 3 introduces our two-stage supply network together with a facility location-allocation model. In particular, the generation of the used data set is described. In Sect. 4, we present and analyse the results of a computational study. Section 5 concludes the paper.
2 Implications of additive manufacturing
The concept of AM is introduced. Section 2.1 explains the term AM. Among the advantages of AM discussed in the literature, two will be explained in detail, that is, functional integration of parts in Sect. 2.2 and a higher resource efficiency for production in Sect. 2.3.
2.1 Definition of additive manufacturing
Within the scientific community, there is a set of several synonyms for AM and the technology, respectively. Nevertheless, AM is the most often used term. It is an umbrella term for many different technologies. AM usually is divided into subcategories dependent for what the AM technology is used for. These subcategories are rapid manufacturing for producing serial parts, rapid prototyping for producing prototypes and models, and rapid tooling for production tools for production like moulds. However, in the non-scientific community AM is a rather unknown term. The most common mainstream term is 3D printing [21]. Therefore, 3D printing is the more often used term overall. According to the mainstream term parts are printed using ink (being equivalent to AM production using raw material).
Regardless of the many different synonyms in the scientific and non-scientific community, there is no overall-agreed definition on AM, respectively, on 3D printing until now. In this contribution, we follow Gebhardts definition, wherein AM is “...a layer-based automated fabrication process for making scaled 3-dimensional physical objects directly from 3D-CAD data without using part-depending tools” [9].
The industrial development and research on AM started mid of the twentieth century [4]. But AM is not a new technology in general or was invented at that time. A first patent which could be considered AM at least partly reaches back to 1903 [16]. In the past, the technology was especially used for producing models or prototypes. In this case, it is referred to as rapid prototyping. With the ongoing development of AM, the technology is capable of printing final products today. Therefore, classical production technologies could be replaced by AM [6].
Currently, companies as well as research institutions work hard on the further development of the technology itself and set up new business models using AM for production. The most popular branches for using AM are the aerospace industry and the medical engineering. For example, there is research going on to replace parts like brackets or engine sensors of an air plane, and dental implants [1, 9, 10].
2.2 Functional integration
When using classical production technologies, usually several production steps have to be performed and several precursors have to be assembled to get the final product. Because of that the production planning becomes more complex. But with AM this is going to change. AM enables the functional integration in one production step. That means, apart of a post-processing of the final product it may be produced in a single production step [11]. An assembly of precursors is not necessary. Therefore, the number of production steps decreases and production planning will be simplified.
This functional integration has not to be limited to a single company. Imagine original equipment manufacturers (OEMs) printing the final product in one production step. Precursors that were originally produced by a supplier are directly integrated in the AM process. Therefore, actors could drop out of the supply network and its structure will change.
2.3 Higher resource efficiency
For AM processes, only the material that is actually needed for the final part is used. Regardless of the dedicated technical process, the unused raw material can be (re-)used for the later production of other parts. Therefore, less material is required [19], and AM may increase the resource efficiency during production. Classical production on the other hand has a rather low resource efficiency. There, over 80 % of material is removed from the work piece [11].
Especially in the aerospace industry, this effect is referred to as buy-to-fly ratio. The term refers to the weight ratio of “...wrought material that is purchased as a block that is required to form a complex part” [11]. Our computational experiments do not address aerospace production in particular but AM production in general. Nevertheless, we will use the term in this paper for addressing resource efficiency.
3 An optimization model for a two-stage supply network
For quantifying the effects of AM on supply networks, a facility location-allocation model was used. The main characteristics of the considered supply network are discussed in Sect. 3.1. In Sect. 3.2, the corresponding facility location-allocation model is introduced. Section 3.3 explains how the test data for our 700 test instances has been created.
3.1 Definition of supply network
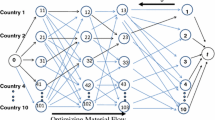
We assume a stylized two-stage supply network. According to Sect. 2.2, manufacturing of products requires one production step only. This should apply for both, AM and classical production technologies. In our model, the different technologies are represented by different buy-to-fly ratios (see Sect. 3.3.2). A buy-to-fly ratio \(\alpha\) of 5 means that five units of material are bought and thereof only one unit goes into the final product. Therefore, the focus is on a two-stage supply network that consists of three types of nodes: source nodes, production sites, and customers (see Fig. 1). On the first stage of such a network, the raw materials are transported from the source nodes (e.g. a harbour) to the production sites. There, the raw material is transformed into a final product. Afterwards, the final products are transported from the production sites to the customers on the second stage of the network.

Basic structure of supply network
The raw material to manufacture a final product is assumed to be homogenous. Precursors are also not considered. The amount of the transported goods (raw material and final products) is measured in tonnes. The costs for transporting the materials and final products are calculated as tonne-kilometres (tkm) using the distance in kilometres weighted by the weight of goods to be transported.
A source node can supply multiple production sites. A production site can supply multiple customers. However, the demand of a customer has to be fulfilled by only one production site. Furthermore, a storage of raw materials or final products at the production sites is forbidden. The production sites have a capacity restriction on the number of products to be manufactured. In contrast, transport relations between the nodes have no capacities. This is reasonable, because network design is a rather long-term problem and transport capacities, in particular road transport, are usually easily adaptable.
3.2 Two-stage capacitated facility location problem
According to Sect. 2.3, the use of AM might reduce the required raw materials in order to produce final products. Therefore, quantity of goods to be transported will change. But this change is not the only implication for the supply network. Beyond that the questions arises whether the locations of our facilities are still adequate in order to supply our customers if AM is applied within the network? In the operations research literature, this question is a well studied. There, the problem is classified as a facility location problem. Many models for this problem are discussed, and a comprehensive survey is presented by Klose and Drexl [14].
In order to model the two-stage supply network at hand, we decided to use the two-stage capacitated facility location problem (TSCFLP) in the formulation presented by Klose and Drexl [14] with a slight adjustment. In the TSCFLP, we are given a set N of nodes. N is divided into a set I of source nodes, a set J of potential production sites, and a set K of customer locations.
The capacity of source i and production site j are given by \(p_i\) (\(i \in I\)) and \(s_j\) (\(j\in J)\), respectively. For each customer location \(k\in K\) the demand \(d_{k}\) is given. The fixed cost for opening a production site j is given by \(f_j\) (\(j \in J\)). The transport costs on the first stage of a network are given by \(t_{ij}\) with \(i \in I\) and \(j \in J\). On the second stage of a network, the transport costs per unit from a production site \(j \in J\) to a customer location \(k \in K\) are given by \(c_{kj}\).
The decision variables are \(x_{ij}\), \(y_j\), and \(z_{kj}\) (\(i \in I, j\in J, k \in K\)). \(x_{ij}\) indicates the transport volume in tonnes from source node i to production site j. The binary variable \(y_j\) indicates if a production site is in use \(y_j=1\) (referred to as open) or not \(y_j=0\). The binary variable \(z_{jk}\) indicates if production site j supplies customer location k. The TSCFLP is given by (1) to (11).
The objective function (1) minimizes the total costs that are made up from the transport costs on the first and the second stage of the network plus the costs for opening a production site. Constraint (2) ensures that each customer is supplied by exactly one production site. Constraint (3) ensures that the open production sites on the whole are able to satisfy the demand of all customers. Constraint (4) guarantees that the capacity of a production site suffices to satisfy the demand of the customers supplied by this production site. The capacity of a source has to be larger than the transport volume of the assigned production sites (5). Restriction (6) defines the flow balance, and the inflow of each production site has to be equal to the outflow. Storage is not possible. Constraint (7) ensures that a source does not supply more raw materials than required by an open production site. Restriction (8) guarantees that a production site is open if it supplies goods to a customer location. Constraints (9) to (11) define the decision variables.
In contrast to the model of Klose and Drexl [14], we include the parameter \(\alpha\) in restriction (6). This parameter is denoted as buy-to-fly ratio. It indicates the efficiency of the production process, and lower values of \(\alpha\) stand for a higher efficiency. This parameter is changed during the computational experiments in order to introduce the higher resource efficiency of AM into the model.
3.3 Generation of test data
The parameters of the TSCFLP represent the required input data for our experiments. The following parameters were considered:
-
The nodes of a supply network, in particular
-
The number of source nodes, production nodes, and customer nodes as well as
-
The geographical distribution of these nodes,
-
-
The buy-to-fly ratio \(\alpha\), and
-
Some other parameters, whose values were fixed for all instances.
We studied seven node allocations, twenty-five different geographical distributions, and four buy-to-fly ratios. As a consequence, 700 instances of the TSCFLP have been created. This allows a much more in-depth analysis of AM effects on supply networks as a previous study of ours [3] which uses only six instances.
3.3.1 Locating nodes of supply networks
A supply network consists of three types of nodes: source nodes, production nodes, and customer nodes. Just as [3], the total number of nodes in a network was set to 90. Most instances of the TSCFLP with 90 or less nodes are solved via state-of-the-art mixed-integer programming (MIP) solvers within a few minutes. Table 1 shows the seven used allocations of source nodes, production nodes, and customer nodes.
The configuration of a supply network is not only impacted by the mere number of network nodes, but by the geographical distribution of these network nodes. The geographical distribution of nodes affects significantly supply relationships between nodes and therefore transport costs. An equal distribution of nodes over the grid lacks practical relevance in many cases. We assumed there are clusters of nodes. For example, production sites may be clustered in industrial parks which may be close to source nodes (i.e. seaports) or far away in the hinterland. A clustering of source nodes could be supported by geographical characteristics, e.g. access to the sea. Clusters could also form because of urbanization which might imply fallow lands in other areas of a country. Different clusters of the three node types were considered in order to take some of these characteristics into account.
To generate a node set which is geographical distributed, we assumed a \(100 \times 100\) grid. Given an allocation \(A_i\) (\(i=1,\ldots ,7\)) the nodes were placed randomly and independently of each other on the grid. As Fig. 2 shows, the x-axis and the y-axis were divided into segments with a width of 10 units, respectively. 100 squares emerged. For each node, first a square was selected. The selection probability of this square followed a normal distribution. Mean and standard deviation of the normal distribution depended on the desired positions of the clusters. However, for each type of node the same normal distribution was applied. Second, after the square was chosen, the exact location within the \(10 \times 10\)-square was equally likely.
Figure 2 shows an example, where a cluster of nodes was generated in the north-east region. On both axes, the mean of the normal distribution was set to 75 and the standard deviation was set to 20. Sixty nodes are placed randomly. As intended by the used normal distribution, a cluster of nodes in the north-east area emerged.

Example distribution of 60 nodes using normal distributions on the x-axis and y-axis, respectively
A node distribution in a network is identified by quadruple (nw, ne, sw, se). Each element of the quadruple represents the desired position of a node cluster. nw, ne, sw, and se denote the north-west, north-east, south-west, and south-east region of the grid. Possible values of nw, ne, sw, se are \(S, P, C, \emptyset\) indicating a source node, a production node, a customer node, or no clustering. Combinations of S, P and C were possible. Graphically, this can be illustrated like one of the squares in Fig. 4.
For all instances, source nodes and customer nodes were placed in one cluster, respectively. However, for production nodes we created a set of instances with one cluster and another set with two clusters. This allowed us to study more realistic network structures. Note, using more than two clusters with the given allocations (see Table 1) leads to little additional insights, because the node locations become similar to the equal distribution case.
Grids with one cluster of production nodes. From all possible combinations of single production clusters on the grid, only eleven are considered. The main reason to exclude cluster combinations from the study is rotational symmetry among the quadruples. An example for rotational symmetry of clusters is given in Fig. 3. Symmetric quadruples do not have to be considered because they represent no unique arrangement of clusters.

Comparison of rotationally symmetric distributions of clusters
Figure 4 shows all network structures consisting of only one cluster per type of node which were used for the computational experiments (C 1–C 11). In addition, the structure \(C_{11}\) was created where all nodes are evenly distributed.

Studied grids with one (\(C_1\)–\(C_{11}\)) and two (\(C_{12}\)–\(C_{25}\)) clusters of production nodes
Grids with two clusters of production nodes. Other things being equal, the probability distribution used to place the production nodes differs in this setting. Two production clusters were generated using two individual probability distributions from the single cluster case. However, for each segment of the axis the higher probability of both probabilities was determined. It was squared and standardized to 100 % for all segments of the axis. Figure 5 shows an example of the corresponding probabilities on the axes and two clusters of production nodes in the north-east and the south-east regions.
When two production clusters are diagonal to each other, a slightly different treatment was required. Diagonal means either production clusters in the nw and se regions or production clusters in the ne and sw regions. If an unwanted region is selected for placing a production site (i.e. after drawing random numbers for the x-axis and the y-axis), we dismissed this decision in 85 % of all accounts. By this, an almost uniform spread of production sites over the grid in both diagonal cases was avoided.

Example distribution of 60 nodes with two production clusters
We created instances for 14 different cluster combinations (see Fig. 4, C 12–C 25). All of them contain two production clusters. Other cluster combinations were excluded from the test due to rotational symmetry considerations.
3.3.2 Buy-to-fly ratio \(\alpha\)
The buy-to-fly ratio expresses the resource efficiency of a production process. According to Heck et al. [12], Lindemann et al. [15], and Arcam-AB [2], the buy-to-fly ratio for AM varies between almost \(\alpha =1\) and \(\alpha =3\). For subtractive production, the buy-to-fly ratio varies between \(\alpha =10\) and \(\alpha =40\) as reported by Dutta and Froes [7] and Whittaker and Froes [20] for real-world scenarios. Four different buy-to-fly ratios were considered to allow for a broad spectrum, i.e. \(\alpha\) was set to 2, 5, 10 and 20.
3.3.3 Other parameters
The TSCFLP allows to set different capacities for sources \(p_{i}\) and production sites \(s_{j}\), cost for opening production sites \(f_{j}\) as well as demand of customers \(d_{k}\). All of these were set once and are constant for all instances. The values are:
-
Capacities \(p_i\) of each source node \(i \in I\) were unlimited, i.e. \(p_i := 99{,}999{,}999\) and have therefore no impact.
-
Capacities \(s_j\) of each production site \(j\in J\) were uniform randomly drawn between 100 and 500.
-
Cost \(f_{j}\) for opening a production site \(j \in J\) were set to \(f_j := 5000\). This value equals the average tkm for a transport in the supply network from a source node to customer node. The average distance between all source nodes and all production sites as well as all production sites and all customers is 50 km each. The customers demand is uniform randomly drawn between 1 and 100; therefore, the average demand per customer is 50. We assumed the best possible buy-to-fly ratio \(\alpha =1\), i.e. the average transported material is 50 tones on both stages of transport. Therefore, the average tone kilometres are 2500 on each stage of transport, in sum 5000.
-
The demand \(d_k\) of each customer \(k \in K\) was drawn uniform randomly between 1 and 100.
4 A computational study
The 700 instances of the TSCFLP (cf. Sects. 3.2, 3.3) are solved by the mixed-integer programming solver CPLEX 12.5.1 from IBM. To measure the performance of a supply network, the indicators presented in Sect. 4.1 are used. The results of the computational experiments are discussed in Sect. 4.2.
4.1 Performance indicators
The structural effects of AM on supply networks are measured and discussed by means of the indicators \(z_1\) to \(z_4\):
-
1.
\(z_1\), the total costs of the network as defined by the TSCFLP’s objective function (1).
-
2.
\(z_2 := \frac{1}{|K|} (\sum _{j\in J, k \in K} d_k c_{kj} z_{kj})\), the average transport costs per customer on the second stage of the supply network. The second stage considers transports between production sites and customer locations only. The first-stage transportation costs between source nodes and production sites are not considered because a lower buy-to-fly ratio requires less raw materials which obviously reduces the first-stage transportation cost. However, the demand of the customers is independent of the buy-to-fly ratio which is why the transport volume on the second stage is constant. Therefore, \(z_2\) might provide useful information about to what extent transport costs are affected by different locations of production sites.
-
3.
\(z_3 := z_3^{1{\mathrm{st}}}:z_3^{2{\mathrm{nd}}}\) the proportion of total costs \(z_3^{1{\mathrm{st}}}\) arising on the first stage versus costs \(z_3^{2{\mathrm{nd}}}\) arising on the second stage of the supply network.
$$\begin{aligned} z_3^{1{\mathrm{st}}}&:= \frac{\sum _{i \in I, j\in J}^{}t_{ij} x_{ij}}{\sum _{i \in I,j\in J}^{}t_{ij}x_{ij}+\sum _{j\in J, k \in K}^{}d_{k}c_{kj}z_{kj}} \\ z_3^{2{\mathrm{nd}}}&:= \frac{\sum _{j\in J, k \in K} d_{k} c_{kj} z_{kj}}{ \sum _{i \in I,j\in J}^{}t_{ij} x_{ij}+\sum _{j\in J, k \in K} d_{k} c_{kj} z_{kj}} \end{aligned}$$ -
4.
\(z_4 := \sum _{j\in J}y_{j}\), the number of open production sites.
When discussing the results of our computational study in the next section, we focus on these four indicators.
4.2 Discussion of results
All 700 instances have been solved by the mixed-integer programming solver CPLEX 12.5.1 from IBM. First, the results for 308 instances with one production cluster are discussed in Sect. 4.2.1. Next, we analyse the results of 392 instances with two production clusters in Sect. 4.2.2.
It goes without saying that the discussion of the effects of AM on the structure of supply networks is only valid for the instances at hand used for our stylized model. Nevertheless, this provides a new method of analysing effects of AM on network structures.
4.2.1 Analysis of networks with one production cluster
Recall, an improved buy-to-fly ratio means a higher resource efficiency of the production process and corresponds to a lower value of \(\alpha\). Table 2 shows the rounded median indicator values for the 308 single production cluster instances of the TSCFLP. The instances are divided into four groups with different buy-to-fly ratios of \(\alpha =2, 5, 10, 20\). So, each group comprises 77 different networks. In addition, Fig. 6 shows the median and the 10 and 90 % quantile of the indicators \(z_1\) to \(z_4\) for different buy-to-fly ratios. For the sake of an easy comparison, the results are normalized with the results for \(\alpha =20\) defined as 100 percent.
Looking at the median \(z_1\), the total costs decrease in all cases with an improved (i.e. lower) buy-to-fly ratio. In addition, even the quantiles are always below the median value for \(\alpha =20\) (see Fig. 6). We conclude that in 80 % of all compared instances an improved buy-to-fly ratio—that is, a switch to AM production—will reduce total costs of the network.
Concerning \(z_2\), an improvement of \(\alpha\) will lead to lower transportation costs between production sites and customer locations on average per customer. However, with the given data the quantiles always reach the median of the \(\alpha =20\)-case (see Fig. 6). But different from the effects observed by means of \(z_1\), a lower \(\alpha\) will not always reduce \(z_2\).
With respect to \(z_3\), the proportion of transportation costs on the first stage and on the second stage shifts to the second stage. However, using AM changes the proportion of tkm required on the first stage versus those required on the second stage of the supply network in the same way. This might be counter-intuitive, because \(z_2\) indicated a total reduction in transport costs on the second stage. The reason for this is that the buy-to-fly ratio \(\alpha\) leads to significantly stronger reduction in the required tkm on the first stage. Especially for \(\alpha =2\), the quantile range is very broad (see Fig. 6). Compared to \(\alpha =20\), the share of tkm for \(\alpha =2\) on the second stage is over three times higher.
The number of open production sites \(z_4\) is slightly reduced using a better \(\alpha\). Because the values of the other performance indicators change a lot more depending on \(\alpha\), we conclude that the number of production sites used does not affect the costs of the supply network much. However, when applying a better buy-to-fly ratio in the network, other possible production sites are opened and therefore the structure changes.

Median and quantile of performance indicators for different \(\alpha\) relatively to \(\alpha =20\)
Apart from an overall analysis, a more detailed view on the cluster structures as well as on the allocation of nodes shows that the results are especially dependent on the number of the customers and clusters of at least two types of nodes. Table 3 shows the median values of the performance indicators classified for the allocation of numbers and clusters of nodes.
In case of an allocation \(A_1\) and \(A_3\) (see Table 3), there are 60 customers to be supplied. On the other hand, the number of production sites is rather low with 10 or 20, respectively. To fulfil the demand of the customers, 9 production sites have to be opened. Only little cost reductions are possible for lower values of \(\alpha\). We conclude that if there are only few possible production sites to choose from, using AM improves the supply network only marginal. There are different allocations from production sites to customers, but overall the benefit through the use of AM is low, because either way almost every production site has to be opened to fulfil the customer’s demand.
If production sites and customers are located in the same region of the grid, AM, respectively a lower \(\alpha\), results in high cost reductions. This is the case for clusters \(C_8\) and \(C_9\) (see Table 3). There, production sites and customers are located in the same region. By applying a lower \(\alpha\) especially, the average transport costs per customer on the second stage of the supply network drop at least 17 up to 30 percent. We conclude that even though the production sites and customers are already clustered in the same region the production sites move closer to the customers with a lower \(\alpha\).
Summarizing the computational experiments of the 308 single cluster instances, we conclude that the general results of Barz et al. [3] on the effects of AM on supply networks are reflected in our experiments, too. The total costs decrease, the proportion of transports costs shifts towards the second stage of transport, the costs of transport between production sites and the customer locations on average per customer drop and the number of production sites used is relatively steady. Additional conclusions are drawn from the different geographical distributions of the nodes and varying numbers of each node type. The biggest improvements by using AM production arise if the number of possible production sites to chose from is high. However, the number of production sites changes rarely. Furthermore, the effect of AM is large, if the clusters of two types of nodes are located nearby at the same geographical area. This is especially true for production sites and customer locations, which are close together. Vice versa the change to AM production in networks with only few production sites to chose, and/or clusters located at different spots, results in minor benefits. With respect to supply network effects, AM production has the highest impact if the supply network is flexible, i.e. if it is possible to change locations of the production sites.
4.2.2 Analysis of networks with two production clusters
The aggregated results for the two production cluster case are given in Table 5. It indicates the median of the indicator values for 392 test instances.
A better buy-to-fly ratio, i.e. using AM, improves the performance indicators. That is, total costs \(z_1\) reduce, the average tkm per customer on the second stage of transport \(z_2\) reduce, and a shift of transport share towards the second stage \(z_3\) occurs. The number of required production sites \(z_4\) remains unchanged. Compared to grids with one production cluster the total cost \(z_1\) is significantly lower. The other performance indicators \(z_2\), \(z_3\), and \(z_4\) are approximately on the same level.
If subtractive production technologies are used, we conclude that supply networks consisting of two production clusters are superior compared to single production cluster networks. Analogous to one production cluster grids, the use of AM reduces the total costs of the supply network. Since the number of opened production sites remains unchanged and the average tkm per customer on the second stage of transport drop, we conclude that production sites are opened closer to the customer, too.
Table 6 compares the performance indicators of one and two production cluster networks; the values for \(\alpha =20\) are fixed to 100 % and the remaining values are scaled accordingly. Roughly speaking, the effects are similar to those shown in Fig. 6. From a more pairwise comparison of corresponding indicator values, one can conclude that networks with two production clusters profit stronger from the introduction of AM than one production cluster grids. Again, the number of open productions sites \(z_4\) remains unchanged independently of the chosen \(\alpha\)-value.
Table 4 shows the performance indicators for allocations \(A_1\) to \(A_7\) and clusters \(C_{12}\) to \(C_{25}\) for two production cluster networks. The effect of AM appears to superpose the different geographical layouts, because the performance values behave in a similar way like those in Table 3 for the one production cluster case.
Looking at the two production clusters grids \(C_{23}\), \(C_{25}\) and the one production cluster grids \(C_{10}\), the performance indicators have the lowest, i.e. the best values. In these cases, the clusters are highly concentrated in one region of the grid, i.e. number of nodes located in this region is very high and very low in the other regions. Therefore, the transport distances are low and also the total costs in this supply networks are low as well. Nevertheless, introducing AM might still lead to significant benefits, see e.g. the reduction in total costs \(z_1\) of \(C_{23}\). So, if a supply network is already highly competitive due to favourably geographical node distribution, it can and will still highly benefit from AM.
4.2.3 Other cost effects
Our computational experiments focus on the structure and transport costs of a supply network and how it changes if AM as a production technology is introduced within this network. Other costs and cost effects, which are directly linked to the production of the part, are not considered within the computational experiments. For example, these cost (effects) could be raw material costs, economies of scale, etc. Although we did not consider these costs and cost effects, respectively, a few general statements concerning these are possible.
Direct production costs are independently of the production site used. Imagine raw material costs. If AM is used less raw material and therefore less transports from sources to production sites are needed. The transport costs will drop. On the other hand, the costs for raw material for AM may be higher because of higher technical requirements. Both aspects influence production costs. However, these effects will always arise regardless of the production site used.
Concerning economies of scale, we assumed a constant demand of the customers in our simulation experiments. Therefore, the production volume is constant as well. Because of that economies of scale do not arise regardless of the production technology used. But if the production volume at a production site is increased to generate economies of scale, this will ceteris paribus lead to increased transports from/to this dedicated production site and therefore to higher transport costs. Therefore, the consideration of economies of scale is only reasonable, if the savings in production costs itself exceed the increased transport costs.
5 Conclusion and outlook
Additive manufacturing (AM) disseminates more and more and replaces or complements classic subtractive manufacturing processes. This will also affect the organization of today’s supply networks. To the knowledge of the authors, there are little approaches that try to quantify potential effects of AM on the structure of a supply network. Our study provides a novel framework on how to measure these potential effects. We used a well-known facility location-allocation problem to model a two-stage supply network. An extensive test data set of 700 instances has been created which provides the basis for our experiments. These instances represent a wide variety of geographical constellations of a supply network. In particular, different types of clusters of source nodes, production sites, and customer locations are included. A main assumption for our experiments was that AM increases the resource efficiency of a production process: the same amount of output is generated with less input material. This is implemented by the buy-to-fly ratio \(\alpha\). Given equal customer demand, the buy-to-fly ratio is the main factor that influences the amount of goods to be transported in a supply network. To measure important effects, we introduced four performance indicators.
Our computational experiments provide insights into the effects of AM on supply networks. Increasing the resource efficiency through AM can have a significant impact on the structure of supply networks. Our experiments confirm in general that production sites will be located closer to the customers. Therefore, the total tonne-kilometres as well as the required tonne-kilometres per customer decrease, which decreases the overall transportation costs. This study supports the findings suggested by Barz et al. [3]. However, Barz et al. [3] used a tiny test data set only, i.e. six handmade test instances. The experiments presented provide a broader foundation which improves the validity and the insights of the results significantly. For this reason, however, we also observed that not all supply networks change in the same way; the intensity of the effects can vary strongly. In order that a supply network benefits from AM it is important that switching production sites is easy, that is, there has to be a high number of possible production sites selectable and the switching costs have to be low enough. The observed effects result from a comparison of production processes with a high resource efficiency versus processes with a low resource efficiency. The next stage would be to also model transition effects which arise from switching from subtractive to additive manufacturing, e.g. higher costs for machinery or slower time of production or maybe even changes in the production programme or the customer demand. Of course, supply networks with a more generalized network structure than our used two-stage network should also be investigated in the future.
References
Airbus SAS (2014) Printing the future: airbus expands its applications of the revolutionary additive layer manufacturing process. http://www.airbus.com/presscentre/pressreleases/press-release-detail/detail/printing-the-future-airbus-expands-its-applications-of-the-revolutionary-additive-layer-manufacturi/
Arcam-AB (s. a.) Ebm in aerospace—additive manufacturing taken to unseen heights. http://www.arcam.com/solutions/aerospace-ebm/
Barz A, Buer T, Haasis HD (2016) A study on the effects of additive manufacturing on the structure of supply networks. IFAC-PapersOnLine 49(2):72–77. In: 7th IFAC conference on management and control of production and logistics MCPL 2016 Bremen, Germany, 22–24 Feb 2016
Breuninger J, Becker R, Wolf A, Rommel S, Verl A (2013) Generative Fertigung mit Kunststoffen: Konzeption und Konstruktion für selektives Lasersintern. Springer Vieweg, Berlin et al
Christopher M, Ryals LJ (2014) The supply chain becomes the demand chain. J Bus Logist 35(1):29–35
Cottrill K (2011) Transforming the future of supply chains through disruptive innovation— additive manufacturing. http://ctltest1.mit.edu/sites/default/files/library/public/Disruptive_Innovations4_1.pdf
Dutta B, Froes FH (2015) The additive manufacturing (AM) of titanium alloys. Titanium powder metallurgy. Butterworth-Heinemann, Boston, pp 447–468
Fawcett SE, Waller MA (2014) Supply chain game changers—mega, nano, and virtual trends- and forces that impede supply chain design. J Bus Logist 35(3):157–164
Gebhardt A (2012) Understanding additive manufacturing: rapid prototyping, rapid tooling, rapid manufacturing. Hanser, Munich
General Electric (2015) GE Aviations first additive manufactured part takes off on a GE90 engine. http://www.geaviation.com/press/ge90/ge90_20150414.html
Gibson I, Rosen D, Stucker B (2015) Additive manufacturing technologies: rapid prototyping to direct digital manufacturing, 2nd edn. Springer, New York
Heck S, Rogers M, Carroll P (2014) Resource revolution how to capture the biggest business opportunity in a century. Houghton Mifflin Harcourt, Boston
Khajavi SH, Partanen J, Holmstrm J (2014) Additive manufacturing in the spare parts supply chain. Comput Ind 65(1):50–63
Klose A, Drexl A (2005) Facility location models for distribution system design. Eur J Oper Res 162(1):4–29
Lindemann C, Jahnke U, Klemp E, Koch R (2013) Additive manufacturing als serienreifes Produktionsverfahren. Ind Manag 29(2):25–28
Peacock G (1903) Method of making composition horseshoes. US Patent 746,143
Tuck C, Hague R, Burns N (2007) Rapid manufacturing: impact on supply chain methodologies and practice. Int J Serv Oper Manag 3(1):1–22
Waller MA, Fawcett SE (2013) Click here for a data scientist: big data, predictive analytics, and theory development in the era of a maker movement supply chain. J Bus Logist 34(4):249–252
Waller MA, Fawcett SE (2014) Click here to print a maker movement supply chain: how invention and entrepreneurship will disrupt supply chain design. J Bus Logist 35(2):99–102
Whittaker D, Froes FHS (2015) Future prospects for titanium powder metallurgy markets. Titanium powder metallurgy. Butterworth-Heinemann, Boston, pp 579–600
Wohlers T (2014) The future of 3d printing. Presentation, inside 3D-printing Berlin, 10 Mar 2014
Acknowledgments
The cooperative junior research group on Computational Logistics is funded by the University of Bremen in line with the Excellence Initiative of German federal and state governments. The authors declare that they have no conflict of interest.
Author information
Authors and Affiliations
Corresponding authors
Additional information
This article is part of a focus collection on “Dynamics in Logistics: Digital Technologies and Related Management Methods”.
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Barz, A., Buer, T. & Haasis, HD. Quantifying the effects of additive manufacturing on supply networks by means of a facility location-allocation model. Logist. Res. 9, 13 (2016). https://doi.org/10.1007/s12159-016-0140-0
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s12159-016-0140-0