
Abstract
Osteoporotic fractures, including hip fractures, are a global health concern associated with significant morbidity and mortality as well as a major economic burden. Identifying individuals who are at an increased risk of osteoporotic fracture is an important challenge to be resolved. Recently, multivariable prediction tools have been developed to assist clinicians in the management of their patients by calculating their 10-year risk of fracture (FRAX, QFracture, Garvan) using a combination of known risk factors. These prediction models have revolutionized the way clinicians assess the risk of fracture. Studies evaluating the performance of prediction models in this and other areas of medicine have, however, been characterized by poor design, methodological conduct, and reporting. We examine recently developed fracture prediction models and critically discuss issues in their design, validation, and transparency.
Similar content being viewed by others

Introduction
Osteoporotic fractures are a global health burden with 9 million incident cases identified in 2000 [1]. It is also estimated that approximately 1.6 million hip fractures occur each year with marked variations in incidence around the world [2]. The costs of osteoporosis are considerable, with Europe spending over €36 billion and the United States spending $27 billion annually on treating and managing osteoporosis [3, 4]. The number of fractures in the elderly and associated economic burden will only continue grow due to the world’s aging population imposing greater emphasis on health care planning. Targeting individuals who are at an increased risk of developing hip and other osteoporotic fractures that might benefit from therapeutic or preventive intervention is therefore an important challenge to be resolved.
Risk Prediction Models
Multivariable risk prediction models hold enormous potential to augment and support the physician in the clinical decision reasoning with objective probability estimates [5]. The key term is multivariable, which explicitly implies the simultaneous contribution of multiple risk factors on the outcome (ie, fracture) captured by a mathematical function.
There is an abundance of prediction models, even for the same condition, and each year an ever-increasing number of models are developed yet disappointingly very few are routinely used in clinical practice. Reasons why certain prediction models get used while others do not are largely unknown. Existing reviews of clinical prediction models in cancer [6–8], diabetes [9•], and traumatic brain injury [10] have all consistently highlighted design problems, methodological weaknesses, and deficiencies in reporting, which could contribute to the lack of uptake.
A recent systematic review critically evaluated 35 prediction models for fracture risk assessment [11]. Consistent with existing reviews of prediction models of other clinical outcomes, the authors highlighted problems with poor reporting including key details on the development and performance of the model frequently omitted. Worthy of particular note, the well-known FRAX model [12] was excluded from the review due to the insufficient information in the FRAX manuscript to provide a minimum of information needed to objectively review the model (to be discussed later).
Regardless of how a clinical prediction model has been developed, the crucial and arguably the only important attribute of a prediction model is to assess its performance (validation), particularly when tested in new individuals (external validation).
Overview of the Steps in Validating a Clinical Prediction Model
The general framework for developing and evaluating a prediction model has been well described [13••, 14•, 15–19, 20•, 21, 22]. Once a model has been developed, the sequence of steps with increasing evidence to support the usefulness and transportability of a prediction models is apparent validation [18], internal validation [23], temporal validation [24], external validation [13••, 24–26], and ultimately an impact study [14•, 21, 27]. Apparent validation provides the least amount of useful information and is defined as the performance of the model using the same dataset used to develop the model. Such performance will be optimistic and have limited information to support the prediction model.
Internal validation comprises split-sample, cross-validation, and bootstrapping (in increasing levels of usefulness). When performing a split-sample internal validation, the dataset is randomly split into a development and validation dataset. However, this archaic approach is suboptimal as the random split merely creates two non-dissimilar datasets and does not provide a real test of the prediction model [13••, 24]. Furthermore, the model is built on a smaller subset of the original data leading to unstable models and the validation data is also usually small leading to unreliable and potentially biased performance data. Bootstrapping is a stronger method that uses all the data to develop the model. Bootstrapping involves taking repeated samples (with replacement) from the original dataset, reflecting drawing samples from an underlying population. The main advantage of bootstrapping is the ability to calculate optimism-corrected performance estimates.
External validation is a key aspect to evaluate the transportability of the prediction model. External validation may comprise temporal, geographical, or spectrum transportability (ie, primary vs secondary care) or their combination. Ideally, external validation should be conducted by independent investigators not involved in the development of a prediction model [24]. An important aspect of external validation is to evaluate a prediction model using cohorts of patients with different case mix.
Impact studies attempt to comparatively quantify the effect of a prediction model on clinician behavior (ie, changing therapeutic decisions, acceptability), cost-effectiveness, or patient outcomes against a system without the prediction model [14•, 21, 22, 27]. While impact studies are the ultimate test and evaluation of a prediction model, very few impact analyses have been carried out [14•, 17].
Quantifying Performance
Irrespective of how a prediction model has been developed, the fundamental aspect is to quantify and evaluate the performance of the model. There are two important characteristics of a prediction model: discrimination and calibration [28••]. Discrimination is the ability of the prediction model to differentiate between individuals who do or do not experience the event (ie, fracture). The crucial aspect here is that individuals who experience the event have higher predicted risks than those who do not. Discrimination is typically assessed by the area under the receiver operating characteristic curve (equivalent to the c-index), ranging from 0 to 1 (the higher the better), where a value of 0.5 reflects the model is no better than flipping a coin. It is also worth noting that the c-index estimated from time-to-event data is influenced heavily on the length of follow-up [29]. Calibration is the agreement between observed outcomes and predictions and can be assessed visually by a calibration plot, plotting observed outcomes versus predicted risk, or by key prognostic predictors (eg, age) [30]. Calibration is also assessed numerically by the calibration slope or calibration-in-the-large [28••]. Discrimination and calibration are joint properties of a prediction model and both aspects should be evaluated; yet existing systematic reviews all conclude that calibration is frequently not assessed [9•, 31]. In the absence of calibration assessment, it is unknown how accurate are the model predictions.
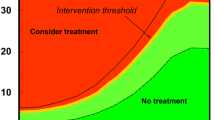
Both discrimination and calibration are statistical properties of a prediction model; neither component captures clinical usefulness. Decision analytic methods have recently been suggested to address clinical usefulness [32]. The approach uses the whole range of clinically useful thresholds to designate an individual at high risk who could benefit from treatment accounting for relative harms of false-positive and false-negative results. Competing (multiple) prediction models can be easily compared, and also compared against a strategy of do nothing (ie, is the model doing any harm?) and treat all (ie, assume everyone is at high risk).
The specific impact of each variable included in the multivariable model can be misinterpreted since risk estimates of dichotomous variables cannot readily be compared with estimates derived from continuous variables, often expressed as a relative risk per 1 standard deviation increase of the values. The relevant comparison should be a risk change by a 2 standard deviation increase of the exposure [33]. In addition, threshold effects or non-linear associations are rarely considered when developing multivariable risk prediction models.
Study Design
One of the most important aspects in developing and, more importantly, in validation studies is study design and data quality. While study design in terms of minimizing potential for overfitting is understood in model development [34–37], less is known on the design requirements for validation studies. Although no firm guidance exists on sample size requirements for validation studies, empirical simulations have found that a minimum 100 events (ie, fractures) are required to validate a prediction model based on a logistic regression [38]. There is no evidence to the contrary to suggest sample size requirements for external validation models based for survival outcomes would be any different. It is worth stressing that the effective sample size in studies involving prediction model for development and validation are driven not by the number of patients in the cohort, but the number of events (ie, fractures).
Missing data are omnipresent in medical research and systematic reviews of prediction models have frequently identified the handling and treatment of missing data as being a major concern [9•, 39]. Omitting patients with missing values, thereby conducting a so-called complete-case analysis can lead to inaccurate and biased estimates of performance [40–47]. Multiple imputation is regarded and advocated as a viable and methodologically superior approach to handle missing data, which makes less strong assumptions on the missing data mechanism than a complete-case analysis [42, 46, 48].
FRAX
Developed under the umbrella of the World Health Organization, the risk assessment tool known as FRAX (http://www.shef.ac.uk/FRAX ) has revolutionized the way in which clinicians identify individuals who are at an increased risk of major osteoporotic or hip fracture over the next 10 years [12, 49••]. As of November 2011, 45 FRAX calculators were available for use in 40 countries [2]. The popularity and uptake of FRAX has been astonishing, with over 300 publications listed on PubMed (accessed March 27, 2012) since its introduction in 2007. Furthermore, FRAX is now embedded in numerous clinical guidelines of the National Osteoporosis Foundation [50], National Osteoporosis Guideline Group [51], Osteoporosis Canada guidelines [52], and is currently (as of March 2012) under consideration in the United Kingdom by the National Institute for Health and Clinical Excellence (http://guidance.nice.org.uk/CG/Wave25/2). See Table 1 for a list of risk factors included in FRAX.
However, in an era of reproducible research [53•, 54] and transparent reporting [55–57], it is disappointing that FRAX has to date failed to deliver on either [58••]. Furthermore, methodological weaknesses and complexities in both the original derivation and validation of FRAX have largely been ignored and its scientific validity has not come under rigorous methodological and statistical scrutiny. Many subsequent studies evaluating FRAX suffer similar shortcomings, primarily due to poor design or replicating the methodology in the original development and validation of FRAX. Many of these studies often included the FRAX developers and thus, in addition, very few independent and methodologically robust evaluations of the predictive performance of FRAX exist. It is also disappointing that the FRAX developers have often received any criticisms of FRAX negatively, often with flawed arguments [59].
FRAX may have great potential to assist the clinical decision making and ultimately in improving patient outcomes; however, it is debatable as to whether the scientific community has been provided with sufficient evidence to support the widespread use of FRAX. This is compounded by the problem that FRAX is largely a black box, as the underlying equations behind them have never been published or placed in the public domain and it seems unlikely they will be published in the near future. It is unclear whether commercial and licensing issues are behind not placing the equations in the public domain, but such secrecy makes it impossible for independent investigators to appropriately evaluate and critique the prediction model [60]. In addition, the methodology behind FRAX has been reported disjointedly and opaquely, making it difficult for researchers to objectively evaluate and critique. As previously mentioned, a recent systematic review of prediction models for fracture risk were also forced to omit FRAX from their review as insufficient information has been reported to enable an objective evaluation of FRAX [58••].
FRAX is frequently cited to have been validated in 11 independent cohorts [12, 49••]; however, there are non-ignorable design and methodological issues that are worth elucidating to refute or dampen such claims. Of the 11 cohorts only one included men (Miyama cohort, 180 men); the other 10 cohorts, all substantially larger (ranging from 1173-135,695) than the Miyama cohort, included only women. As discussed earlier, unreliable and misleading performance data are frequently observed in cohorts with less than 100 events; 7 of the 11 cohorts for hip fracture had less than 100 events. Inflated, and optimistic performance data are frequently observed in cohorts comprising small numbers of events [61]. However, equally disconcerting is the handling of missing data. Missing data were present in the cohorts used to derive the FRAX, with many cohorts not having collected specific risk factors, and how this was handled is unclear. In the validation of FRAX, six cohorts did not record one or more risk factors required to calculate FRAX, while it is unclear on how many had missing body mass index in any of the 11 cohorts. In particular, one cohort (the PERF cohort) did not record information on five of the risk factors needed to calculate FRAX: family history (either parent has a history of hip fracture), currently using oral glucocorticoids, smoking status, alcohol consumption, and diagnosis of rheumatoid arthritis. Only six cohorts collected information on alcohol consumption. How this was handled was to set the beta-coefficient in the FRAX model to zero (ie, omit the predictor from the FRAX model) and calculate the score based on the available risk factors. Such practice is not only highly flawed and misleading but results from such analyses do not constitute valid performance data of FRAX, and certainly should not be used to claim validation of FRAX.
Despite these methodological shortcomings the discrimination in each of the 11 validation cohorts was disappointingly low. For example, in the FRAX model (without bone mineral density [BMD]) for predicting for major osteoporotic fractures, area under the receiver operator characteristic curve (AUROC) ranged from 0.54 to 0.81 (0.81 clearly an outlier from the small Miyama cohort), with AUROC ≤ 0.6 in 9 of the 11 cohorts. Similarly, for the FRAX model with BMD, AUROC ranged from 0.55 to 0.77 (0.77 again from the small Miyama cohort) with AUROC ≤ 0.6 in 5 of the 9 cohorts that had BMD data. Such unimpressive performance data are highly debatable to support the validation of FRAX. For the FRAX models that predict hip fractures, the performance data was marginally higher, notably for the model that includes BMD, but for the model without BMD, the data supporting FRAX is hardly stunning to support such rapid and unequivocal acceptance. Reasons for the poor performance are unclear, but contributing factors, acknowledged by the FRAX developers, will undoubtedly include the omission of previous falls (number, severity, or type) frailty, and history of cardiac disease or stroke as predictors in the model [62–64]. Failure to take into account dose–response relationships (ie, dose and duration of glucocorticoids), alcohol consumption, and smoking status will also likely weaken the predictive accuracy of FRAX [62, 63].
As described earlier, characteristics of a model’s predictive accuracy include both discrimination and calibration. While the discrimination of FRAX on the 11 cohorts was evaluated by calculating the AUROC, calibration of FRAX was not evaluated, yet calibration describing the agreement between observed and predicted risks is a crucial component. In the absence of an assessment of calibration, it is unclear on the accuracy of the predictions from FRAX. We also note that very few subsequent publications of FRAX have evaluated calibration [65].
QFracture
QFracture is a prediction tool for the 10-year risk of osteoporotic fracture and 10-year risk of hip fracture [66•]. It was developed and validated in the United Kingdom on a large cohort of general practice patients (3.6 million) contributing 50,755 osteoporotic fractures (hip, vertebral, and distal radius fracture) and 19,531 hip fractures from 25 million person years of observation. See Table 1 for a list of risk factors included in the model. Subsequent external validation by independent investigators on a separate but large (2.2 million patients) cohort of patients contributing 25,208 osteoporotic fractures and 12,188 hip fractures demonstrated very good performance of QFracture [60], despite the fact that the model did not include BMD. AUROC curves were 0.89 (women) and 0.86 (men) for the model predicting the risk of hip fracture and 0.82 (women) and 0.74 (men) for the model predicting the risk of osteoporotic fracture. Independent evaluation of QFracture also showed it was well calibrated, and taken with the high discrimination values would suggest good predictive accuracy.
However, unlike FRAX, there are very few other studies that have examined the usefulness of QFracture [67]. Nevertheless, the development, internal validation [66•] and external validation [60] have to date used 5.9 million patients, contributing 38 million person years of observation and 75,963 new cases of osteoporotic fracture and 31,719 new hip fractures with good predictive accuracy demonstrated. While the actual prediction models have not been published, open source software has been made freely available by the developers (http://www.qfracture.org). Since writing this paper, QFracture has been updated to include a number of additional predictors including ethnicity, previous fracture, use of antidepressants, chronic obstructive pulmonary disease, epilepsy, use of anticonvulsants, dementia, Parkinson's disease, cancer, systemic lupus erythematosus, chronic renal disease, type 1 diabetes and care or nursing home residence [68].
Garvan Calculator
The Garvan fracture risk prediction model has been developed in Australia by use of the Dubbo cohort constituting 1208 women and 740 men aged 60 years of age or older [69•, 70]. The risk algorithm includes only five variables: age, sex, number of previous fractures after 50 years of age, number of falls during the last year, and BMD. External validation of the Garvan calculator has displayed moderate to good discrimination ability [71] and there are indications of equal or better performance with the Garvan calculator compared to FRAX [71–74]. Unlike FRAX, the equations of the Garvan model are freely available [71].
Conclusions
In an era of evidence-based medicine, reproducibility, and transparency, it is disappointing that FRAX had penetrated the medical community to the levels it has in the absence of methodological and transparent evidence. Arguably, the results from the flawed validation, which were branded as an international validation FRAX that accompanied the development of FRAX, have potentially misled potential users of FRAX by falsely claiming the model was well validated. Subsequent studies using FRAX have mis-cited [62] this validation as providing satisfactory or good evidence to support FRAX to elevate the model to be viewed as a gold standard risk prediction fracture assessment [75]. Results from the SCOOP (Screening of Older Women for Prevention of Fracture) randomized controlled trial (http://www.scoopstudy.ac.uk/) will provide excellent data on the impact of FRAX on the effectiveness and cost-effectiveness in screening 11,580 older women in the United Kingdom [76]. Such impact studies for prediction models are rare yet a vital component in determining clinical usefulness. Interestingly, bisphosphonates [77–79] and denosumab [80] are only proven efficacious for clinical fracture prevention in those with osteoporosis, and not in those with higher BMD values. Thus, off-label use presently recommended by current guidelines partially based on FRAX [81–83] might not benefit the patient and might also theoretically even cause net harm [84–86]. Importantly, in large US cohort studies, more than 80 % of women who suffer a fracture after the age of 65 years do not have osteoporosis [87, 88].
Studies evaluating prediction models as a minimum must assess and report both discrimination and calibration; merely stating FRAX has been calibrated to a particular countries incidence and mortality rates does not imply the model is calibrated. The process of adjusting FRAX to a countries incidence is unclear as it has to date not been adequately reported, but regardless of the method, the approach can be viewed as a form of model updating or recalibration [18, 27, 89–92]. Such updating is unfortunately rarely done for prediction models in other medical areas and models. Models that are not calibrated in certain populations often get discarded and needless new prediction models are derived when an updating or recalibration would suffice. However, it is prudent and recommended that for any model that undergoes recalibration to another setting or country, that the model undergo extensive, and preferably an independent, validation to assess the predictive accuracy of the model. In addition, official country-, sex-, and age-specific fracture incidence rates based on register data are used to provide 10-year risk fracture probabilities for each country. The validity of the underlying fracture register incidences are uncertain—in Sweden, a country well known for complete national registers [93], incidence fracture rates are overestimated by use of normal official data [94] (ie, prevalent and incident cases are admixed).
A number of guidelines in the medical literature exist for the reporting of randomized controlled trials [95], diagnostic accuracy [96], systematic reviews and meta-analyses [97] cohort and case–control studies [98], and tumor marker prognostic studies [99]. Yet, there are currently no consensus-based guidelines for developing and evaluating multivariable risk prediction models in terms of conduct or reporting, though a recent collaborative initiative has started to develop such reporting guidelines [100]. It is envisaged such reporting guidelines will improve the quality and clarity of studies developing or validating prediction models. In the meantime, the developers of FRAX are urged to provide a single concise document describing the full steps of the derivation of FRAX and to place the underlying equations of FRAX in the public domain to enable independent investigators to critically evaluate the tool using prospectively collected data and appropriate statistical methods.
References
Papers of particular interest, published recently, have been highlighted as: • Of importance •• Of major importance
Johnell O, Kanis JA. An estimate of the worldwide prevalence and disability associated with osteoporotic fractures. Osteoporos Int. 2006;17(12):1726–33.
Kanis JA, Oden A, McCloskey EV, Johansson H, Wahl DA, Cooper C. A systematic review of hip fracture incidence and probability of fracture worldwide. Osteoporos Int. 2012;in press.
Cummings SR, Melton LJ. Epidemiology and outcomes of osteoporotic fractures. Lancet. 2002;359:1761–67.
Kanis JA, Johnell O. Requirements for DXA for the management of osteoporosis in Europe. Osteoporos Int. 2005;16:229–38.
Feinstein AR. Clinical judgment revisited: the distraction of quantitative models. Ann Intern Med. 1994;120:799–805.
Meads C, Ahmed I, Riley RD. A systematic review of breast cancer incidence risk prediction models with meta-analysis of their performance. Breast Canc Res Treat. 2012;132(2):365–77.
Altman DG, Lyman GH. Methodological challenges in the evaluation of prognostic factors in breast cancer. Breast Cancer Res Treat. 1998;52(1–3):289–303.
Mallett S, Royston P, Dutton S, Waters R, Altman DG. Reporting methods in studies developing prognostic models in cancer: a review. BMC Med. 2010;8:20.
• Collins GS, Mallett S, Omar O, Yu LM. Developing risk prediction models for type 2 diabetes: a systematic review of methodology and reporting. BMC Med. 2011;9:103. Highlights the general poor level of methodological conduct and reporting in studies developing clinical prediction models.
Perel P, Edwards P, Wentz R, Roberts I. Systematic review of prognostic models in traumatic brain injury. BMC Med Inform Decis Mak. 2006;6:38.
Steurer J, Haller C, Hauselmann H, Brunner F, Bachmann LM. Clinical value of prognostic instruments to identify patients with an increased risk for osteoporotic fractures: systematic review. PLoS One. 2011;6(5):e19994.
Kanis JA, Johnell O, Oden A, Johansson H, McCloskey E. FRAX and the assessment of fracture probability in men and women from the UK. Osteoporos Int. 2008;19(4):385–97.
•• Altman DG, Vergouwe Y, Royston P, Moons KGM. Prognosis and prognostic research: Validating a prognostic model. BMJ. 2009;338:b605. Provides an excellent overview of the general issues in evaluating the performance of clinical prediction models.
• Moons KGM, Altman DG, Vergouwe Y, Royston P. Prognosis and prognostic research: application and impact of prognostic models in clinical practice. BMJ 2009;338:b606. Describes the issues in evaluating impact of clinical prediciton models on clinician behavior and patient outcomes.
Moons KGM, Royston P, Vergouwe Y, Grobbee DE, Altman DG. Prognosis and prognostic research: what, why, and how? BMJ. 2009;338(feb23 1):b375-b75.
Royston P, Moons KGM, Altman DG, Vergouwe Y. Prognosis and prognostic research: Developing a prognostic model. BMJ 2009;338(mar31 1):b604-b04.
Reilly BM, Evans AT. Translating clinical research into clinical practice: impact of using prediction rules to make decisions. Ann Intern Med. 2006;144(3):201–9.
Steyerberg EW. Clinical prediction models: a practical approach to development, validation, and updating. New York: Springer; 2008.
Vickers AJ. Prediction models in cancer care. CA: a cancer journal for clinicians. 2011;61(5):315–26.
• Vickers AJ, Cronin AM. Traditional statistical methods for evaluating prediction models are uninformative as to clinical value: towards a decision analytic framework. Semin Oncol. 2010;37(1):31-8. Describes a new method to evalaute the clinical usefulness of a clinical prediction model without imposing one single treatment threshold.
Wallace E, Smith SM, Perera-Salazar R, Vaucher P, McCowan C, Collins G, et al. Framework for the impact analysis and implementation of Clinical Prediction Rules (CPRs). BMC Med Inform Decis Mak. 2011;11:62.
Toll DB, Janssen KJM, Vergouwe Y, Moons KGM. Validation, updating and impact of clinical prediction rules: a review. J Clin Epidemiol. 2008;61(11):1085–94.
Moons KG, Kengne AP, Woodward M, Royston P, Vergouwe Y, Altman DG, et al. Risk prediction models: I. Development, internal validation, and assessing the incremental value of a new (bio)marker. Heart. 2012;Mar 7([Epub ahead of print]).
Altman DG, Royston P. What do we mean by validating a prognostic model? Stat Med. 2000;19(4):453–73.
Bleeker SE, Moll HA, Steyerberg EW, Donders ART, Derksen-Lubsen G, Grobbee DE, et al. External validation is necessary in prediction research: a clinical example. J Clin Epidemiol. 2003;56(9):826–32.
Peek N, Arts DG, Bosman RJ, van der Voort PH, de Keizer NF. External validation of prognostic models for critically ill patients required substantial sample sizes. J Clin Epidemiol. 2007;60(5):491–501.
Moons KG, Kengne AP, Grobbee DE, Royston P, Vergouwe Y, Altman DG, et al. Risk prediction models: II. External validation, model updating, and impact assessment. Heart. 2012.
•• Steyerberg EW, Vickers AJ, Cook NR, Gerds T, Gonen M, Obuchowski N, et al. Assessing the performance of prediction models: a framework for traditional and novel measures. Epidemiology. 2010;21(1):128-38. Methodological experts in clinical prediction give an overview of traditional and new methods to evaluate clinical prediction models.
Vickers AJ, Cronin AM. Everything you always wanted to know about evaluating prediction models (but were too afraid to ask). Urology. 2010;76(6):1298–301.
Collins GS, Altman DG. An independent and external validation of QRISK2 cardiovascular disease risk score: a prospective open cohort study. BMJ. 2010;340:c2442.
Mallett S, Royston P, Waters R, Dutton S, Altman DG. Reporting performance of prognostic models in cancer: a review. BMC Med. 2010;8:21.
Vickers AJ, Elkin EB. Decision curve analysis: a novel method for evaluating prediction models. Med Decis Making. 2006;26(6):565–74.
Gelman A. Scaling regression inputs by dividing by two standard deviations. Stat Med. 2008;27(15):2865–73.
Courvoisier DS, Combescure C, Agoritsas T, Gayet-Ageron A, Perneger TV. Performance of logistic regression modeling: beyond the number of events per variable, the role of data structure. J Clin Epidemiol. 2011;64(12):1463–64.
Peduzzi P, Concato J, Feinsten AR, Holford TR. Importance of events per independent variable in proportional hazards regression analysis.2. Accuracy and precision of regression estimates. J Clin Epidemiol. 1995;48(12):1503–12.
Peduzzi P, Concato J, Kemper E, Holford TR, Feinstein AR. A simulation study of the number of events per variable in logistic regression analysis. J Clin Epidemiol. 1996;49(12):1373–79.
Vittinghoff E, McCulloch CE. Relaxing the rule of ten events per variable in logistic and Cox regression. Am J Epidemiol. 2007;165(6):710–8.
Vergouwe Y, Steyerberg EW, Eijkemans MJC, Habbema JDF. Substantial effective sample sizes were required for external validation studies of predictive logistic regression models. J Clin Epidemiol. 2005;58(5):475–83.
Ettema RG, Peelen LM, Schuurmans MJ, Nierich AP, Kalkman CJ, Moons KG. Prediction models for prolonged intensive care unit stay after cardiac surgery: systematic review and validation study. Circulation. 2010;122(7):682–89.
Burton A, Altman DG. Missing covariate data within cancer prognostic studies: a review of current reporting and proposed guidelines. Br J Cancer. 2004;91(1):4–8.
Janssen KJ, Donders AR, Harrell Jr FE, Vergouwe Y, Chen Q, Grobbee DE, et al. Missing covariate data in medical research: to impute is better than to ignore. J Clin Epidemiol. 2010;63(7):721–7.
Janssen KJM, Vergouwe Y, Donders ART, Harrell Jr FE, Chen Q, Grobbee DE, et al. Dealing with missing predictor values when applying clinical prediction models. Clin Chem. 2009;55(5):994–1001.
Marshall A, Altman DG, Holder RL, Royston P. Combining estimates of interest in prognostic modelling studies after multiple imputation: current practice and guidelines. BMC Med Res Meth. 2009;9:57.
Marshall A, Altman DG, Royston P, Holder RL. Comparison of techniques for handling missing covariate data withing prognostic modelling studies: a simulation study. BMC Med Res Meth. 2010;10:7.
Moons KG, Donders RA, Stijnen T, Harrell Jr FE. Using the outcome for imputation of missing predictor values was preferred. J Clin Epidemiol. 2006;59(10):1092–101.
Vergouwe Y, Royston P, Moons KGM, Altman DG. Development and validation of a prediction model with missing predictor data: a practical approach. J Clin Epidemiol. 2010;63(2):205–14.
White IR, Royston P, Wood AM. Multiple imputation using chained equations: Issues and guidance for practice. Stat Med. 2011;30(4):377–99.
Sterne JAC, White IR, Carlin JB, Spratt M, Royston P, Kenward MG, et al. Multiple imputation for missing data in epidemiological and clinical research: potential and pitfalls. BMJ. 2009;338(jun29 1):b2393-b93.
•• Kanis JA, Oden A, Johnell O, Johansson H, De Laet C, Brown J, et al. The use of clinical risk factors enhances the performance of BMD in the prediction of hip and osteoporotic fractures in men and women. Osteoporos Int. 2007;18(8):1033-46. This article describes the development of FRAX and the indivdual studies used in the development and validation of FRAX.
National Osteoporosis Foundation. Clinician's guide to prevention and treatment of osteoporosis (available at http://www.nof.org/sites/default/files/pdfs/NOF_ClinicianGuide2009_v7.pdf). 2010.
National Osteoporosis Guideline Group (NOGG). Osteoporosis: clinical guidelines for prevention and treatment. Executive Summary. 2010.
Papaioannou A, Morin S, Cheung AM, Atkinson S, Brown JP, Feldman S, et al. 2010 clinical practice guidelines for the diagnosis and management of osteoporosis in Canada: summary. CMAJ. 2010;182(17):1864–73.
• Laine C, Goodman SN, Griswold ME, Sox HC. Reproducible research: moving toward research the public can really trust. Ann Intern Med. 2007;146(6):450-53. A discussion on the importance of reproducible research.
Peng RD. Reproducible research and biostatistics. Biostatistics. 2009;10(3):405–08.
Mayor S. Ethics code for professional medical writers emphasises transparency and completeness of research reporting. BMJ. 2010;341:c7025.
Simera I, Moher D, Hirst A, Hoey J, Schulz KF, Altman DG. Transparent and accurate reporting increases reliability, utility, and impact of your research: reporting guidelines and the EQUATOR Network. BMC Med. 2010;8:24.
Simera I, Altman DG. Writing a research article that is “fit for purpose”: EQUATOR Network and reporting guidelines. Evid Based Med. 2009;14(5):132–34.
•• Steurer J, Haller C, Häuselmann H, Brunner F, Bachmann LM. Clinical value of prognostic instruments to identify patients with an increased risk for osteoporotic fractures: systematic review. PLoS One 2011;6(5):e19994. Systematic review of clinical prediction model for osteoporotic fracture, highlighting weaknesses in the development and validation of prediction models.
Kanis JA, Oden A, Johansson H, McCloskey E. Pitfalls in the external validation of FRAX. Osteoporos Int. 2012;23(2):423–31.
Collins GS, Mallett S, Altman DG. Predicting risk of osteoporotic and hip fracture in the United Kingdom: prospective independent and external validation of QFractureScores. BMJ. 2011;342:d3651.
Siontis GC, Tzoulaki I, Ioannidis JP. Predicting death: an empirical evaluation of predictive tools for mortality. Arch Intern Med. 2011;171(19):1721–6.
Silverman SL, Calderon AD. The utility and limitations of FRAX: a US perspective. Curr Osteoporos Rep. 2010;8(4):192–7.
van Geel TA, van den Bergh JP, Dinant GJ, Geusens PP. Individualizing fracture risk prediction. Maturitas. 2010;65(2):143–8.
Sennerby U, Melhus H, Gedeborg R, Byberg L, Garmo H, Ahlbom A, et al. Cardiovascular diseases and risk of hip fracture. JAMA. 2009;302(15):1666–73.
Leslie WD, Lix LM, Johansson H, Oden A, McCloskey E, Kanis JA. Independent clinical validation of a Canadian FRAX tool: fracture prediction and model calibration. J Bone Miner Res. 2010;25(11):2350–8.
• Hippisley-Cox J, Coupland C. Predicting risk of osteoporotic fracture in men and women in England and Wales: prospective derivation and validation of QFractureScores. BMJ. 2009;339:b4229. Describes the development and internal validation of QFracture in a very large cohort of general practice patients in the United Kingdom.
Cummins NM, Poku EK, Towler MR, O'Driscoll OM, Ralston SH. clinical risk factors for osteoporosis in Ireland and the UK: a comparison of FRAX and QFractureScores. Calcif Tissue Int. 2011;89(2):172–77.
Hippisley-Cox J, Coupland C. Derivation and validation of updated QFracture algorithm to predict risk of osteoporotic fracture in primary care in the United Kingdom: prospective cohort study. BMJ. 2012;344:e3427.
• Nguyen ND, Frost SA, Center JR, Eisman JA, Nguyen TV. Development of a nomogram for individualizing hip fracture risk in men and women. Osteoporos Int. 2007;18(8):1109-17. Describes the development of the Garvan prediction model.
Nguyen ND, Frost SA, Center JR, Eisman JA, Nguyen TV. Development of prognostic nomograms for individualizing 5-year and 10-year fracture risks. Osteoporos Int. 2008;19(10):1431–44.
Langsetmo L, Nguyen TV, Nguyen ND, Kovacs CS, Prior JC, Center JR, et al. Independent external validation of nomograms for predicting risk of low-trauma fracture and hip fracture. CMAJ. 2011;183(2):E107–E14.
Pluskiewicz W, Adamczyk P, Franek E, Leszczynski P, Sewerynek E, Wichrowska H, et al. Ten-year probability of osteoporotic fracture in 2012 Polish women assessed by FRAX and nomogram by Nguyen et al.-Conformity between methods and their clinical utility. Bone. 2010;46(6):1661–67.
Sandhu SK, Nguyen ND, Center JR, Pocock NA, Eisman JA, Nguyen TV. Prognosis of fracture: evaluation of predictive accuracy of the FRAX algorithm and Garvan nomogram. Osteoporos Int. 2010;21(5):863–71.
van Geel TA, Nguyen ND, Geusens PP, Center JR, Nguyen TV, Dinant GJ, et al. Development of a simple prognostic nomogram for individualising 5-year and 10-year absolute risks of fracture: a population-based prospective study among postmenopausal women. Ann Rheum Dis. 2011;70(1):97–7.
Watts NB. The Fracture Risk Assessment Tool (FRAX(R)): applications in clinical practice. J Womens Health (Larchmt). 2011;20(4):525–31.
Shepstone L, Fordham R, Lenaghan E, Harvey I, Cooper C, Gittoes N, et al. A pragmatic randomised controlled trial of the effectiveness and cost-effectiveness of screening older women for the prevention of fractures: rationale, design and methods for the SCOOP study. Osteoporos Int. 2012.
Wells G, Cranney A, Peterson J, Boucher M, Shea B, Robinson V, et al. Risedronate for the primary and secondary prevention of osteoporotic fractures in postmenopausal women. Cochrane Database Syst Rev. 2008;23(1):CD004523.
Wells GA, Cranney A, Peterson J, Boucher M, Shea B, Robinson V, et al. Alendronate for the primary and secondary prevention of osteoporotic fractures in postmenopausal women. Cochrane Database Syst Rev. 2008;23(1):CD001155.
Wells GA, Cranney A, Peterson J, Boucher M, Shea B, Robinson V, et al. Etidronate for the primary and secondary prevention of osteoporotic fractures in postmenopausal women. Cochrane Database Syst Rev. 2008;23(1):CD003376.
McClung M, Boonen S, Törring O, Roux C, Rizzoli R, Bone H, et al. Effect of denosumab treatment on the risk of fractures in subgroups of women with postmenopausal osteoporosis. J Bone Miner Res. 2011;Epub ahead of print.
Bolland MJ, Grey A. Disparate outcomes from applying U.K. and U.S. osteoporosis treatment guidelines. J Clin Endocrinol Metab. 2010;95(4):1856–60.
Compston J, Cooper A, Cooper C, Francis R, Kanis JA, Marsh D, et al. Guidelines for the diagnosis and management of osteoporosis in postmenopausal women and men from the age of 50 years in the UK. Maturitas. 2009;62(2):105–08.
Dawson-Hughes B. National Osteoporosis Foundation Guide C. A revised clinician's guide to the prevention and treatment of osteoporosis. J Clin Endocrinol Metab. 2008;93(7):2463–65.
Compston J. Pathophysiology of atypical femoral fractures and osteonecrosis of the jaw. Osteoporos Int. 2011;22(12):2951–61.
Michaëlsson K, Schilcher J, Aspenberg P. Comment on Compston: Pathophysiology of atypical femoral fractures and osteonecrosis of the jaw. Osteoporos Int 2011;Jan 31. [Epub ahead of print].
Schilcher J, Michaelsson K, Aspenberg P. Bisphosphonate use and atypical fractures of the femoral shaft. N Engl J Med. 2011;364(18):1728–37.
Siris ES, Chen YT, Abbott TA, Barrett-Connor E, Miller PD, Wehren LE, et al. Bone mineral density thresholds for pharmacological intervention to prevent fractures. Arch Intern Med. 2004;164(10):1108–12.
Stone KL, Seeley DG, Lui LY, Cauley JA, Ensrud K, Browner WS, et al. BMD at multiple sites and risk of fracture of multiple types: long-term results from the Study of Osteoporotic Fractures. J Bone Miner Res. 2003;18(11):1947–54.
Ankerst DP, Koniarski T, Liang Y, Leach RJ, Feng Z, Sanda MG, et al. Updating risk prediction tools: a case study in prostate cancer. Biom J. 2012;54(1):127–42.
Janssen KJM, Moons KGM, Kalkman CJ, Grobbee DE, Vergouwe Y. Updating methods improved the performance of a clinical prediction model in new patients. J Clin Epidemiol. 2008;61(1):76–86.
Steyerberg EW, Borsboom GJ, van Houwelingen HC, Eijkemans MJ, Habbema JD. Validation and updating of predictive logistic regression models: a study on sample size and shrinkage. Stat Med. 2004;23(16):2567–86.
van Houwelingen HC, Thorogood J. Construction, validation and updating of a prognostic model for kidney graft-survival. Stat Med. 1995;14(18):1999–2008.
Calltorp J, Adami HO, Aström H, Fryklund L, Rossner S, Trolle Y, et al. Country profile: Sweden. Lancet. 1996;347(9001):587–94.
Gedeborg R, Engquist H, Berglund L, Michaelsson K. Identification of incident injuries in hospital discharge registers. Epidemiology. 2008;19(6):860–67.
Schulz KF, Altman DG, Moher D, CONSORT Group. CONSORT 2010 statement: updated guidelines for reporting parallel group randomised trials. BMJ. 2010;340:c332.
Bossuyt PM, Reitsma JB, Bruns DE, Gatsonis CA, Glasziou PP, Irwig LM, et al. Towards complete and accurate reporting of studies of diagnostic accuracy: the STARD initiative. BMJ. 2003;326:41–4.
Moher D, Liberati A, Tetzlaff J, Altman DG. Preferred reporting items for systematic reviews and meta-analyses: the PRISMA statement. BMJ. 2009;339:b2535.
von Elm E, Altman DG, Egger M, Pocock SJ, Gotzsche PC, Vandenbroucke JP. The Strengthening the Reporting of Observational Studies in Epidemiology (STROBE) statement: guidelines for reporting observational studies. Lancet. 2007;370(9596):1453–57.
McShane LM, Altman DG, Sauerbrei W, Taube SE, Gion M, Clark GM. REporting recommendations for tumour MARKer prognostic studies (REMARK). Br J Cancer. 2005;93(4):387–91.
Collins GS. Opening up multivariable prediction models: Consensus-based guidelines for transparent reporting: BMJ Blogs. 2011.
Disclosure
No potential conflicts of interest relevant to this article were reported.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article
Cite this article
Collins, G.S., Michaëlsson, K. Fracture Risk Assessment: State of the Art, Methodologically Unsound, or Poorly Reported?. Curr Osteoporos Rep 10, 199–207 (2012). https://doi.org/10.1007/s11914-012-0108-1
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11914-012-0108-1