
Abstract
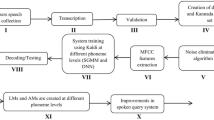
In this work, we present the recent improvements incorporated in the earlier developed Assamese spoken query (SQ) system for accessing the price of agricultural commodities. The SQ system consists of interactive voice response (IVR) and automatic speech recognition (ASR) modules developed using open source resources. The speech data used for training the ASR system has a high level of background noise since it is collected in field conditions. In the earlier version of the SQ system, this background noise had an adverse effect on the recognition performance. In the improved version, a background noise suppression module based on zero frequency filtering is added before feature extraction. In addition to this, we have also explored the recently reported subspace Gaussian mixture (SGMM) and deep neural network (DNN) based acoustic modeling approaches. These techniques have been reported to be more powerful than the GMM-HMM approach which was employed in the previous version. Further, the foreground separated speech data is used while learning the acoustic models for all systems. The amalgamation of noise removal and SGMM/DNN-based acoustic modeling is found to result in a relative improvement of 39 % in word error rate in comparison to the earlier reported GMM-HMM-based ASR system. The on-line testing of the developed SQ system (done with the help of real farmers) is also presented in this work. Some efforts are made to quantify the usability of the developed SQ system and the explored enhancements are noted to be helpful on that front too.








Similar content being viewed by others

References
Kaldi Toolkit: http://kaldi.sourceforge.net.
Dahl, G., Yu, D., Deng, L., & Acero, A. (2012). Context-dependent pre-trained deep neural networks for large vocabulary speech recognition. IEEE Transactions on Audio Speech, and Language Processing (receiving 2013 IEEE SPS Best Paper Award), 20(1), 30–42.
Deepak, K.T., Sarma, B.D., & Prasanna, S.R.M. (2012). Foreground speech segmentation using zero frequency filtered signal. In Proc. Interspeech.
Glass, J.R. (1999). Challanges for spoken dialogue systems. In Proc. IEEE ASRU workshop.
Hinton, G.E., Deng, L., Yu, D., Dahl, G., Mohamed, A.R., Jaitly, N., Senior, A., Vanhoucke, V., Nguyen, P., Sainath, T., & Kingsbury, B. (2012). Deep neural networks for acoustic modeling in speech recognition. Signal Processing Magazine.
Hinton, G.E., Osindero, S., & Teh, Y.W. (2006). A fast learning algorithm for deep belief nets. Neural Computer, 18(7), 1527–1554.
Murthy, K.S.R., & Yegnanarayana, B. (2008). Epoch extraction from speech signals. IEEE Transaction Audio, Speech and Language Processing, 16, 1602–1613.
Murthy, K.S.R., & Yegnanarayana, B. (2009). Characterization of glottal activity from speech signals. IEEE Signal Processing Letters, 16, 469–472 .
Povey, D., Burget, L., Agarwal, M., Akyazi, P., Kai, F., Ghoshal, A., Glembek, O., Goel, N., Karafiát, M., Rastrow, A., Rose, R.C., Schwarz, P., & Thomas, S. (2011). The subspace gaussian mixture model-a structured model for speech recognition. Computer Speech and Language, 25(2), 404–439.
Povey, D., Ghoshal, A., Boulianne, G., Burget, L., Glembek, O., Goel, N., Hannemann, M., Motlicek, P., Qian, Y., Schwarz, P., Silovsky, J., Stemmer, G., & Vesely, K. (2011). The kaldi speech recognition toolkit. In Proc. ASRU.
Rabiner, L.R. (1994). Applications of voice processing to telecommunications. In Proc. IEEE (Vol. 82, pp. 199–228).
Rabiner, L.R., & Sambur, M.R. (1975). An algorithm for determining the endpoints of isolated utterances. Bell System Technical Journal, 54, 297–315.
Rose, R.C., Yin, S.C., & Tang, Y. (2011). An investigation of subspace modeling for phonetic and speaker variability in automatic speech recognition. In Proc. ICASSP (pp. 4508–4511).
Shahnawazuddin, S., Deepak, K.T., Sarma, B.D., Deka, A., Prasanna, S.R.M., & Sinha, R. (2014). Low complexity on-line adaptation techniques in context of assamese spoken query system. Journal of Signal Processing Systems, 1–15.
Trihandoyo, A., Belloum, A., & Hou, K.M. (1995). A real-time speech recognition architecture for a multi-channel interactive voice response system. In Proc. ICASSP (Vol. 4, pp. 2687–2690).
Xu, H., Povey, D., Mangu, L., & Zhu, J. (2011). Minimum bayes risk decoding and system combination based on a recursion for edit distance. Computer Speech and Language, 25(4), 802–828.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
The authors comply with the ethical standards of the journal. The authors also declare that they have no conflict of interest. This work is part of the ongoing consortium project on Speech-based Access of Agricultural Commodity Prices and Weather Information in 11 Indian Languages / Dialects, funded by the Technology Development for Indian Languages (TDIL) programme initiated by the Department of Electronics & Information Technology (DeitY), Ministry of Communication & Information Technology (MC&IT), Govt. of India (Grant number: 11(18)/2012-HCC(TDIL)). The authors would like to thank the consortium leader Prof. S. Umesh and other consortium members for their valuable inputs and suggestions.
Rights and permissions
About this article

Cite this article
Shahnawazuddin, S., Thotappa, D., Dey, A. et al. Improvements in IITG Assamese Spoken Query System: Background Noise Suppression and Alternate Acoustic Modeling. J Sign Process Syst 88, 91–102 (2017). https://doi.org/10.1007/s11265-016-1133-6
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11265-016-1133-6