
Abstract
In a world with complete markets, the decision whether to rent or buy a home is not influenced by risks related to human capital. If markets are incomplete and have frictions, however, this may change. Renting should become more likely the more mobile a household has to be and the more income risk can be diversified. Using household panel data from Germany, we test both predictions. We find that mobility requirements have a positive effect on the probability of renting. This effect is robust even after controlling for state dependence, unobserved heterogeneity and other factors known to influence the tenure mode choice. Our data, however, does not support the hypothesis that the potential to diversify net income risk when renting affects the tenure mode choice.



Similar content being viewed by others

Notes
If a down-payment is required, things become more complicated, because the volatility of future direct housing cost will be influenced by the previous tenure mode. We ignore this aspect here and in the empirical application.
In addition to cost for employing the services of real estate agents and surveyors (which in part is also incurred when renting), a purchase implies stamp duty and fees for legal transfer and mortgage underwriting.
The framework assumes stationary random variables. In the empirical analysis, we work correspondingly with growth rates.
The data were made available to us by the German Socio-Economic Panel Study at the German Institute for Economic Research (DIW), Berlin.
The RDM is an association of real estate professionals that publishes annual surveys on house prices in German cities. This information is based on inquiries among members and should indicate prices reasonably. We compute regional prices by aggregating data from cities in the same region, weighted with their population share.
NUTS stands for the geocode standard Nomenclature of Units for Territorial Statistics that has been established by Eurostat to reference the administrative subdivisions of EU member countries.
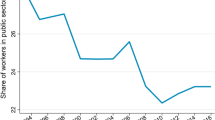
Kirchner (2007, Table 1) uses official statistics to calculate that 47.5 % of all dwellings were in the private rental sector, 10.9 % in the social rental sector (together 58.4 %), and 41.6 % of dwellings were owner-occupied. The sectoral shares for our full panel sample are in line with these numbers and are not reported.
Up to 1996 the subsidy was implemented through the tax code in form of accelerated depreciation rules for owner-occupied housing. From 1996-2004 homeowners received a direct payment that was based on the purchase price (or construction cost) of the house.
In principle, a more finely graded grouping would be desirable to reduce bias when constructing our mobility and income measures. This, however, is precluded by the sample size of the GSOEP, particularly since we subsequently combine the professions with the regions to compute the diversification potential that a member of a profession may exploit when renting its accommodation.
We tried other parametric distributions, such as the exponential, log-logistic, and Weibull. The lognormal provided the best fit to the data.
We suppress the dependence of \(m_{h}\) on \(\tau \) in what follows.
In our panel data application, we use the fixed effects rather than the traditional repeat-sales estimator, because diagnostics of the estimated residuals indicate that the former will be more efficient.
The income movement of a certain profession may also depend on region-specific factors. Therefore, one would ideally like to estimate constant-quality income indices for each of the 420 profession-region groups. Due to sparsity of observations, we do not estimate such indices.
It is not possible to compute the user cost at the household level and hence at the profession group level, because important information on mortgage financing and tax treatment is not recorded in the GSOEP. The regional real user cost \(R_{r}\) is then for the average household; in the empirical applications we control for the tax treatment (by using employment income as a regressor) and for changes in interest and tax rates by using time dummies.
Because the market value of the assets is not reported either, it is not possible to infer income indirectly.
The diversification potential measure \(d_{h,t}\) has a household index, as it can depend on both the household head’s and the spouse’s profession. The measure does not vary across households living in the same region and members working in the same profession.
The simultaneous inclusion of the two credit constraint variables makes it plausible that the income variable controls primarily for the tax advantage of ownership.
Without exclusion restrictions, the coefficients are only weakly identified due to the nonlinearities of the probit model.
Previous tenure mode status may affect current choices for several reasons. For instance, high search cost of selling and buying a home may lock homeowners in. Previous tenure mode may also be an indicator for a household’s financial wealth and thus the ability to afford a home.
An independence assumption is only plausible if all observations for a household start with the beginning of its formation and are independent of the regressors in Eq. 10.
We obtain bootstrap standard errors that take into account clustering of the observations over individual households. For each cluster, we resample from the original set until the new set has as many clusters as the original set. We repeat this procedure 200 times. For each full sample replication, we estimate, both, coefficients and partial effects and use the standard deviations across the replications as bootstrap standard errors.
The estimated correlation between the error terms is negative. A priori one would expect that unobserved factors which increase households’ mobility should also increase their likelihood to rent. However, one must bear in mind that Eqs. 8 and 9 are reduced-form equations which makes any interpretation of the estimated correlation difficult.
For recent movers, \(m_{h,t}\) is almost always evaluated at \(\tau =0\). As some households are not always interviewed in the same months, residence spells for recent movers can be greater than zero.
Each block consist of all observations for an household. For each set of blocks with the same size (measured in years), we resample from the original set until the new set has as many blocks as the original set. We repeat this procedure 200 times. This sampling procedure preserves the total sample size as well as the pattern of unbalancedness found in the full sample. For each full sample replication, we estimate average partial effects and use the standard deviations across the replications as bootstrap standard errors.
Since the variance of the idiosyncratic error in the underlying latent variable model is one, \(\theta \) measures the relative importance of \(\sigma _{a}^{2}\). If \(\theta \) is zero, there is no unobserved effect and the pooled probit and the random effect regressions are identical.
References
Arellano, M. (1987). Computing robust standard errors for within-groups estimators. Oxford Bulletin of Economics and Statistics, 49, 431–434.
Barsky, R.B., Juster, F.T., Kimball, M.S., Shapiro, M.D. (1997). Preference parameters and behavioral heterogeneity: An experimental approach in the health and retirement study. Quarterly Journal of Economics, 112, 537–579.
Boehm, T.P. (1981). Tenure choice and expected mobility: A synthesis. Journal of Urban Economics, 10, 375–389.
Boehm, T.P., Herzog, H.W., Schlottmann, A.M. (1991). Intra-urban mobility, migration, and tenure choice. The Review of Economics and Statistics, 73, 59–68.
Bunke, O., Droge, B., Polzehl, J. (1999). Model selection, transformations and variance estimation in nonlinear regression. Statistics, 33, 197–240.
Chamberlain, G. (1980). Analysis of covariance with qualitative data. The Review of Economic Studies, 47, 225–238.
Davidoff, T. (2006). Labor income, housing prices, and homeownership. Journal of Urban Economics, 59, 209–235.
Dohmen, T., Falk, D., Huffmann, U., Sunde, U., Schupp, J., Wagner, W. (2005). Individual risk attiudes. new evidence from a large, representative, experimentally-validated survey. DIW Discussion Paper 511. Berlin: German Institute for Economic Research.
Efron, B., & Tibshirani, R.J. (1993). An Introduction to the Bootstrap. New York: Chapman and Hall.
Haurin, D.L., & Gill, H.D. (2002). The impact of transaction costs and the expected length of stay on home ownership. Journal of Urban Economics, 51, 563–584.
Heckman, J.J. (1981). The incidental parameters problem and the problem of initial conditions in estimating a discrete- time-discrete data stochastic process. In C. Manski, & D. McFadden (Eds.), Structural Analysis of Discrete Data with Econometric Applications. Cambridge: MIT Press.
Henderson, J.V., & Ioannides, Y.M. (1989). Dynamic aspects of consumer decisions in housing markets. Journal of Urban Economics, 26, 212–230.
Hubert, F. (1998). Private rented housing in Germany. Netherlands Journal of Housing and the Built Environment, 13, 205–232.
Ihlanfeldt, K.R. (1981). An empirical investigation of alternative approaches to estimating the equilibrium demand for housing. Journal of Urban Economics, 9, 97–105.
Kambourov, G., & Manovskii, I. (2009). Occupational specificity of human capital. International Economic Review, 50, 63–115.
Kan, K. (2000). Dynamic modeling of housing tenure choice. Journal of Urban Economics, 48, 46–69.
King, M.A. (1980). An econometric model of tenure choice and demand for housing as a joint decision. Journal of Public Economics, 14, 137–159.
Kirchner, J. (2007). The declining social rental sector in Germany. European Journal of Housing Policy, 7, 85–101.
Lai, C.D., & Xie, M. (2006). Stochastic ageing and dependence for reliability. New York: Springer.
Malpezzi, S. (1998). Private rented housing markets in the United States. Netherlands Journal of Housing and the Built Environment, 13, 353–386.
Martin, J.P. (1996). Measure of replacement rates for the purpose of international comparison: A note. OECD Economic Studies, 26, 99–115.
Mundlak, Y. (1978). On the pooling of time series and cross section data. Econometrica, 46, 69–85.
Neal, D. (1995). Industry-specific human capital: Evidence from displaced workers. Journal of Labor Economics, 13, 653–677.
Ortalo-Magné, F., & Rady, S. (2002). Tenure choice and the riskiness of non-housing consumption. Journal of Housing Economics, 11, 266–279.
Painter, G., Gabriel, S., Myers, D. (2001). Race, immigrant status, and housing tenure choice. Journal of Urban Economics, 49, 150–167.
Poletaev, M., & Robinson, C. (2008). Human capital specificity: Evidence from the dictionary of occupational titles and displaced worker surveys. Journal of Labor Economics, 26, 387–420.
Rosen, H.S. (1979). Housing decisions and the U.S. income tax. Journal of Public Economics, 11, 1–23.
Rosen, H.S., & Rosen, K.T. (1980). Federal taxes and homeownership: Evidence from time series. Journal of Political Economy, 88, 59–75.
Rosen, H.S., Rosen, K.T., Holtz-Eakin, D. (1984). Housing tenure, uncertainty, and taxation. Review of Economics and Statistics, 66, 405–416.
Shiller, R.J. (1993). Macro Markets. Creating institutions for managing society’s largest economic risks. Oxford: Clarendon Press.
Shiller, R.J., & Schneider, R. (1998). Labor income indices designed for use in contracts promoting income risk management. Review of Income and Wealth, 44, 163–82.
Sinai, T., & Souleles, N.S. (2005). Owner-occupied housing as a hedge against rent risk. The Quarterly Journal of Economics, 120, 763–789.
Tomann, H. (1990). The housing market, housing finance and housing policy in West Germany: Prospects for the 1990s. Urban Studies, 27, 919–930.
Van de Ven, W.P.M.M., & Van Praag, B.M.S. (1981). The demand for deductibles in private health insurance: A probit model with sample selection. Journal of Econometrics, 17, 229–252.
Voigtländer, M. (2009). Why is the German homeownership rate so low? Housing Studies, 24, 355–372.
Wooldridge, J.M. (2005). Simple solutions to the initial conditions problem in dynamic, nonlinear panel data models with unobserved heterogeneity. Journal of Applied Econometrics, 20, 39–54.
Acknowledgments
We have benefited from comments on earlier versions of this paper by five anonymous referees, Bernd Fitzenberger, James Follain, Christian Hilber, Franz Hubert, Verity Watson and participants at presentations at the AREUEA Annual Conference 2009, ERES Annual Conference 2008, Regensburg Conference on Real Estate Economics and Finance 2007, University of Aberdeen, DIW Berlin, Heriot Watt University Edinburgh, Humboldt-Universität zu Berlin, Universität Hannover, and Universität Tübingen. The usual disclaimer applies.
Author information
Authors and Affiliations
Corresponding author
Additional information
Financial support from the Deutsche Forschungsgemeinschaft, SFB 649 Economic Risk, is gratefully acknowledged.
Appendix
Appendix
Cluster Analysis
Our cluster analysis uses the observed transitions between occupation-industry groups to delineate professions. Let i denote a occupation-industry group and \(p_{ij}\) the probability of an individual belonging to this group conditional on being a member of group j in the previous period. The transition probability is
where \(N_{i,t|j,t-1}\) is the number of individuals in group i in period t conditional on being in group j in period \(t-1\). \(N_{i,t}\) denotes the total number of individuals in group i in period t.
To estimate transition probabilities between occupation-industry groups, we use information on individuals in the full sample that are in employment and have been in the GSOEP for at least two years. Each individual falls into one of 9 ISCO-88 1-digit occupations and one of 14 NACE Rev.1 1-digit industries. This leads to 126 occupation-industry groups, of which two have no observations in our sample. The estimated transition probabilities provide the data with which we select professions. We use a K-Medians cluster algorithm that starts from a given partition of the groups and proceeds by exchanging groups between clusters so that all groups within a cluster are closest to the cluster’s centroid. The algorithm converges when occupation-industry groups are no longer exchanged between profession groups. We run the cluster analysis with different initial profession groupings found by a first step agglomerative cluster algorithm. In most cases, the cluster analysis leads to 14 profession groups.
Table 7 presents the estimated transition matrix for the 14 professions. The professions are fairly stable. The diagonal elements of the matrix shows the transition probabilities within professions. The lowest within transition probability is 79 percent, the highest 94 percent. The off-diagonal elements, which are the transition probabilities between professions, are almost always lower than 3 percent. The lowest between transition probability is 0 percent and the highest about 10 percent.
Survival Analysis
We estimate the coefficients in Eq. 4 using a linear regression for censored data
where \(\tau _{h}\) is the time since household h moved into the current dwelling. A spell is completed if the household moves to a new residence or disbands. Disbandment is the result of emigration or death. Incomplete spells are defined to be right-censored. The vector \(\mathbf {x}(\tau _{h})\) collects, possibly time-varying, household characteristics at time \(\tau _{h}\), as well as a full set of profession, region, and time dummies. The latter take the value one if household's residence spell begins in the respective year. The idiosyncratic error term is distributed with \(\varepsilon _{h} \sim N\left (0,\sigma ^{2}\right )\).
Equation 15 is estimated with ML, using a flow sample of residence spells from the GSOEP. In particular, a household enters the sample if it moves to a new residence or is newly formed between 1985–2003. We allow for multiple spells of the same household and adjust standard errors in the estimation accordingly. In total, we have 6,842 residence spells, of which 3,407 are completed. The remaining spells are right-censored.
Table 8 reports summary statistics of household characteristics in the spell sample. With respect to most of their socioeconomic characteristics households in this sample are quite similar to recent movers as summarized in column (2) of Table 1. This is attributable to the fact that the GSOEP, on average, follows newly moved households for only 5 years.
Income Series
We derive the profession-specific constant-quality income series from the hedonic repeat-measures regression
where \(y_{i,t}\) is the log of the employment income of individual i in period t \((t=1984, \ldots , 2004)\). The vector \(\mathbf {x}_{i,t}\) contains time-varying individual characteristics, as well as a full set of region dummies. The binary indicator \(D_{p,i,0}\) is set to one if individual i is employed in profession p in the base period \(t=1995\). The binary indicator \(D_{p,i,t}\) is set to one if individual i is employed in profession p in period \(t \neq 1995\). The profession dummies for the base period, \(D_{p,i,0}\), control for the income change of individuals who switch professions between periods. Observed and unobserved time-constant characteristics are captured by the individual specific effect \(c_{i}\). \(\varepsilon _{i,t}\) is an idiosyncratic error term.
Estimating Eq. 16 directly would lead to a biased estimator, because unobserved characteristics captured in \(c_{i}\) are omitted. We therefore use a fixed effects estimator, which subtracts the individual-specific average from each observed variable. This removes the observed and unobserved time-constant characteristics, \(c_{i}\), from the regression equation. Estimating this modified regression with OLS leads to an unbiased estimator for the coefficients in Eq. 16.
We use an unbalanced panel sample of the relevant 15,701 employed individuals in the GSOEP to estimate the coefficients. Following the literature on Mincer wage equations, we include education in years, labor force experience in years, and labor force experience squared in \(\mathbf {x}_{i,t}\). Further controls comprise age, work hours, and duration of current employment. These variables are suggested by Shiller and Schneider (1998) to ensure that the income index captures only the income trend of fully employed individuals in a given profession. As economic theory does not suggest a particular functional form for the age and work hours variable, we use the Box-Cox type transformation suggested in Bunke et al. (1999). These functions capture non-linearities, such as the common hump-shaped age profile of income. Table 9 presents these fixed effects estimates. The fit of the regression is reasonably good as measured by the \(R^{2}\). Moreover, the estimated coefficients of the control variables have reasonable signs and are statistically significant.
We obtain profession-specific income series in two steps. First, we compute constant-quality index series \(I_{p,t} = \exp \{\widehat {\gamma }_{p,t}-0.5\widehat {\sigma }^{2}_{\gamma _{p,t}}\}\). \(\widehat {\gamma }_{p,t}\) is the estimated time dummy coefficient from Eq. 16 for profession p in period t. \(\widehat {\sigma }^{2}_{\gamma _{p,t}}\) is the estimated variance of the coefficient estimator, which corrects for small-sample bias. The index series are normalized to one in the base period 1995. Second, we convert the series into series in levels, thereby taking account for unemployment
The median employment income \(\bar {Y}_{pr}\) is for profession-region cell \((pr)\) in year 1995. The unemployment rate \(u_{p,t}\) is estimated from the GSOEP. \(B_{t}\) is the OECD summary measure of unemployment benefits, which is the ratio of gross benefit entitlements and gross earnings (Martin 1996). \(B_{t}\) is published only on a biannual basis and we interpolate values for non-covered years linearly. The full-employment income \(I_{p,t} Y_{pr,1995}\) and the unemployment benefit \(I_{p,t}B_{t}Y_{pr,1995}\) are weighted by the profession-specific unemployment rate in the respective period. After deflating with the consumer price index, we obtain the final constant-quality real income series.
Rent Series
We derive the region-specific rent series from the hedonic repeat-measures regression
where \(y_{i,t}\) is the log rent of dwelling i in period t \((t=1984, \ldots , 2004)\). The vector \(\mathbf {x}_{i,t}\) collects time-varying characteristics of the dwelling. These include variables related to modernization (indicators if a bathroom and central heating are present), as well as variables related to the landlord-tenant relationship (indicators for subsidized rental housing and different lengths of tenancy). The binary indicator \(D_{r,i,t}\) is set to one if the dwelling is observed in region r and period t. Unobserved and observed time-constant characteristics, such as size of the dwelling, type of building, and type of urban area are captured by the dwelling-specific effect \(c_{i}\). \(\varepsilon _{i,t}\) is an idiosyncratic error term.
We estimate the coefficients in Eq. 18 using an unbalanced panel sample of 9,852 rental dwellings in the GSOEP. As before, we use a fixed effects estimator, which removes the time-constant observed and unobserved characteristics, \(c_{i}\), from the regression. Table 10 reports the coefficient estimates. The fit of the regression measured with the \(R^{2}\) is reasonably good. Moreover, the estimated coefficients for the included time-varying variables have reasonable signs and are statistically significant at the usual significance levels.
We compute region-specific constant-quality rent series in two steps. First, we compute constant-quality index series from the estimated time dummy coefficients in Eq. 18 with \(I_{r,t} = \exp \{\widehat {\gamma }_{r,t}-0.5\widehat {\sigma }^{2}_{\gamma _{r,t}}\}\), where \(\widehat {\gamma }_{r,t}\) is the estimated time dummy coefficient for region r in period t. \(\widehat {\sigma }_{\gamma _{r,t}}\) is the corresponding estimated standard error of the coefficient estimator. This second term corrects for small sample bias. The index series are normalized to one for our base period 1995. We then, second, convert the index series into level series \(R_{r,t} = \widehat {I}_{r,t} \bar {R}_{r,1995}\), where \(\bar {R}_{r,1995}\) represents the median rent level in region r for the year 1995. After deflating with the consumer price index, we obtain the final constant-quality real rent series.
Rights and permissions
About this article
Cite this article
Schulz, R., Wersing, M. & Werwatz, A. Renting versus Owning and the Role of Human Capital: Evidence from Germany. J Real Estate Finan Econ 48, 754–788 (2014). https://doi.org/10.1007/s11146-013-9412-5
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11146-013-9412-5