
Abstract
Automatic image annotation is a vital and challenging problem in pattern recognition and image understanding areas. The existing models directly extract visual features from segmented image regions. Since segmented image regions may still have multi-objects, the extractive visual features may not effectively describe corresponding regions. In addition, existing models did not consider the visual representations of corresponding keywords, which would lead to appearing plenty of irrelevant annotations in final annotation results, and these annotations did not relate to any part of images considering visual contents. In order to overcome the above problems, an image annotation model based on multi-scale salient region and relevant visual keywords is proposed. In this model, each image is segmented by using multi-scale grid segmentation method and the global contrast based method is used to extract the saliency maps from each image region. Visual features are extracted from each salient region. In addition, each keyword is divided into two categories: abstract words or non-abstract words. Visual seeds of each non-abstract word are established, and then a new method is proposed to extract visual keyword collections by using corresponding seeds. According to the traits of abstract words, an algorithm based on subtraction regions is proposed to extract visual seeds and corresponding visual keyword collections of each abstract word. Adaptive parameter method and a fast solution algorithm are proposed to determine the similarity thresholds of each keyword. Finally, multi-scale visual features and the combinations of the above methods are used to improve the annotation performance. Our model can improve the object descriptions of images and image regions. Experimental results verify the effectiveness of the proposed model.






Similar content being viewed by others


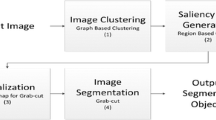
Notes
References
Borji A, Sihite DN, Itti L (2012) Salient object detection: A benchmark. Proceedings of 12th European Conference on Computer Vision, pp 414–429
Carneiro G, Chan AB, Moreno PJ et al (2007) Supervised learning of semantic classes for image annotation and retrieval. IEEE Trans Pattern Anal Mach Intell 29(3):394–410
Cheng MM, Mistra NJ, Huang X et al (2011) Global contrast based salient region detection. Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, pp 409–416
Duygulu P, Barnard K, Freitas J, Forsyth D (2002) Object Recognition as Machine Translation: Learning a Lexicon for a Fixed Image Vocabulary. Proceedings of the 7th European Conference on Computer Vision, pp 97–112
Feng S L, Manmatha R, Lavrenko V (2004) Multiple Bernoulli relevance models for image and video annotation. Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Washington, pp 1002–1009
Feng S, Xu D (2010) Transductive multi-instance multi-label learning algorithm with application to automatic image annotation. Expert Syst Appl 37:661–670
Grubinger M (2007) Analysis and Evaluation of Visual Information Systems Performance. PhD thesis, Victoria University, Melbourne
Guan T, Fan Y, Duan L et al (2014) On-device mobile visual location recognition by using panoramic images and compressed sensing based visual descriptors. PLoS One 9(6):e98806
Guan T, He Y, Duan L et al (2014) Efficient BOF generation and compression for on-device mobile visual location recognition. IEEE Multimed 21(2):32–41
Guan T, He Y, Gao J, Yang J, Yu J (2013) On-device mobile visual location recognition by integrating vision and inertial sensors. IEEE Trans Multimed 15(7):1688–1699
Han Y, Wu F, Tian Q et al (2012) Image annotation by input–output structural grouping sparsity. IEEE Trans Image Process 21(6):3066–3079
Hu J, Lam KM (2013) An efficient two-stage framework for image annotation. Pattern Recogn 46(3):936–947
Jeon J, Lavrenko V, Manmatha R (2003) Automatic image annotation and retrieval using cross-media relevance models. Proceedings of the 26th Annual International ACM SIGIR, Toronto, pp 119–126
Ji R, Duan LY, Chen J et al (2012) Location discriminative vocabulary coding for mobile landmark search. Int J Comput Vis 96(3):290–314
Ji R, Duan LY, Chen J et al (2013) Learning to distribute vocabulary indexing for scalable visual search. IEEE Trans Multimed 15(1):153–166
Ji R, Gao Y, Hong R et al (2014) Spectral-spatial constraint hyperspectral image classification. IEEE Trans Geosci Remote Sens 52(3):1811–1824
Ji R, Yao H, Liu W et al (2012) Task dependent visual codebook compression. IEEE Trans Image Process 21(4):2282–2293
Kang F, Jin R, Sukthankar R (2006) Correlated Label Propagation with application to Multi-label Learning. Proc of the 2006 I.E. Computer Society Conf on Computer Vision and Pattern Recognition. IEEE, Piscataway, pp 1719–1726
Lavrenko V, Manmatha R, Jeon J (2003) A model for learning the semantics of pictures. Proceedings of Advance in Neutral Information Processing, Vancouver
Li Z, Liu J, Xu C et al (2013) MLRank Multi-correlation Learning to Rank for image annotation. Pattern Recogn 46(10):2700–2710
Lindstaedt S, Morzinger R, Sorschag R et al (2009) Automatic image annotation using visual content and folksonomies. Multimed Tools Appl 42:97–113
Liu J, Li MJ, Ma WY et al (2006) An adaptive graph model for automatic image annotation. Proceedings of the ACM SIGMM Workshop on Multimedia Information Retrieval. ACM, New York, pp 61–69
Luis VA, Laura D (2004) Labeling images with a computer game. Proceedings of the SIGCHI conference on Human factors in computing system, pp 319–326
Makadia A, Pavlovic V, Kumar S (2008) A New Baseline for Image Annotation. 10th European Conference on Computer Vision, Marseille, pp 316–329
Matthieu G, Thomas M, Jakob V et al (2009). TagProp: Discriminative metric learning in nearest neighbor models for image auto-annotation. Proceedings of 12th International Conference on Computer Vision, pp 309–316
Pedro F, Daniel P (2004) Efficient graph-based image segmentation [J]. Int J Comput Vis 59(2):167–181
Shi J, Malik J (2000) Normalized cuts and image segmentation. IEEE Trans Pattern Anal Mach Intell 22:888–905
Si Z, Zhu SC (2013) Learning AND-OR templates for object recognition and detection. IEEE Trans Pattern Anal Mach Intell 35(9):2189–2205
Wang Y, Mei T, Gong S, Hua XS (2009) Combining global, regional and contextual features for automatic image annotation. Pattern Recogn 42:259–266
Yang Y, Wu F, Nie F et al (2012) Web and personal image annotation by mining label correlation with relaxed visual graph embedding. IEEE Trans Image Process 21(3):1339–1351
Zhang L, Gao Y, Hong C et al (2014) Feature correlation hypergraph: exploiting high-order potentials for multimodal recognition. IEEE Trans Cybern 44(8):1408–1419
Zhang L, Gao Y, Xia Y et al (2014) A Fine-grained image categorization system by cellet-encoded spatial pyramid modeling. IEEE Trans Ind Electron
Zhang L, Han Y, Yang Y et al (2013) Discovering discriminative graphlets for aerial image categories recognition. IEEE Trans Image Process 22(12):5071–5084
Zhang S, Huang J, Li H et al (2012) Automatic image annotation and retrieval using group sparsity. IEEE Trans Syst Man Cybern 42(3):838–849
Zhang D, Islam MM, Lu G (2012) A review on automatic image annotation techniques [J]. Pattern Recogn 45(1):346–262
Zhang L, Song M, Liu X et al (2013) Fast multi-view segment graph kernel for object classification. Sig Process 93(6):1597–1607
Zhang L, Song M, Liu X et al (2014) Recognizing architecture styles by hierarchical sparse coding of blocklets. Inf Sci 254(1):141–154
Zhu JY, Wu J, Wei Y et al (2012) Unsupervised Object Discovery via Saliency-Guided Multiple Class Learning. Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, pp 3218–3225
Acknowledgments
This work is partially supported by the National Natural Science Foundation of China under Grants No. 61103175, the Natural Science Foundation of Fujian Province under Grant No. 2013 J05088, the Key Project of Chinese Ministry of Education under Grant No.212086, the Fujian Province High School Science Fund for Distinguished Young Scholars under Grand No.JA12016, the Program for New Century Excellent Talents in Fujian Province University under Grant No. JA13021, and the Fujian Natural Science Funds for Distinguished Young Scholar under Grant No. 2014 J06017.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Ke, X., Guo, W. Multi-scale salient region and relevant visual keywords based model for automatic image annotation. Multimed Tools Appl 75, 12477–12498 (2016). https://doi.org/10.1007/s11042-014-2318-2
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11042-014-2318-2