
Abstract
We demonstrate that fixed- and random-effects models for pooled cross-sectional and time series data, and latent growth curve models for panel data are special cases of a more general model. We compare the estimates obtained from each type of model for a data set consisting of homicide rates and a vector of explanatory variables for 400 US counties over a 15-year period. Most, but not all, estimates are similar in the two models. We identify circumstances under which one approach may be advantageous to the other.
Similar content being viewed by others

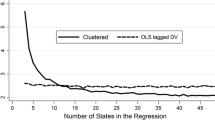

Notes
An alternative approach, the estimation of finite mixture models, also entails the study of trajectories, but is different in spirit from the approach we are considering here. It seeks to classify cases into a finite number of discrete, homogeneous latent classes, each with its own intercept and rate of change over time. All cases in a class are assumed to have the same trajectory (e.g. Nagin and Land 1993; Sampson and Laub 1993; Paternoster and Brame 1997; Laub et al. 1998; Laub and Sampson 2003; Ezell and Cohen 2005). Such models can be estimated parametrically or with a semi-parametric estimation process. To keep the current paper manageable, we do not consider finite mixture models here.
Note that pooled models can accommodate unbalanced data (different time series lengths for cases). The models presented in this paper do not require regular-spaced time intervals. However, models with a lagged endogenous variable or serially-correlated errors do have this requirement.
The estimates obtained from the fixed effects model are consistent in the limit as the number of waves increases without limit. In many applications, there are a small number of waves. In this circumstance, the fixed effects estimates are not necessarily unbiased no matter how many cases the researcher has. Random effects estimates, on the other hand, are consistent as the number of cases increases without limit, regardless of how many observation times there are in the panel. Both types of models require strict exogeneity for consistency. This means that the residuals at a given time cannot be correlated with the independent variables at any times, not just at the same time (Wooldridge 2002: 254–256). This is a stringent requirement, probably violated in many criminological contexts. Where violations occur, the estimation strategy must be modified to take the violations into account (Wooldridge 2002, 219–314).
Some researchers, however, opt for random effects models, arguing that this is the only way to obtain estimates of the effects of time-invariant predictors, which are dropped in the fixed-effect estimation. This strategy runs the risk of omitted variable bias.
Note that the same terminology (fixed and random effects) is used in both the pooled and growth trajectory approaches but refers to different issues.
Some researchers using growth curve models have adopted case-mean centering in the level 1 equation—in other words, examining deviations from each case (e.g. individual) mean calculated across the entire time period—and include the case means over the entire period as an explanatory variable in the level 2 equation (e.g. Horney et al. 1995). This formulation obtains estimates of within-case change, equivalent to the pooled fixed-effects approach (see Allison 2005; Hofman and Gavin 1998; Raudenbush and Bryk 2002: 135–141; Phillips 2006a for further discussion). We do not consider this elaboration of the method here.
We compared models in which curvilinearity was represented by the natural logarithm of population with those in which it was represented by a linear and quadratic term. In the fixed-effects models, the latter had more explanatory power, so we adopted this dependence.
Some decades ago, econometricians analyzing time series became aware that their methods were valid only when stationarity prevailed, that is when the variances and covariances of the variables do not change with time (Box and Jenkins 1976; Mills 1990; Yaffee 2000). Special methods were devised to test for non-stationarity and to deal with it when it is present. Since panel data are merely a collection of time series data sets, non-stationarity can present special issues (such as spurious regressions) that require the researcher’s attention (Baltagi 2001, 233–255; Hsiao 2003). While some researchers using pooled models are aware of these issues and conduct tests for non-stationarity (e.g. Levin and Lin 1993; Banerjee 1999; Im et al. 2003), less attention appears to be directed toward this issue by researchers estimating growth trajectory models. Users of both approaches should be aware of this potential problem and, if present, deal with it. In this analysis, stationarity tests included the Levin-Lin-Chu test with alternate lag-lengths ranging from one to eight for all the series.
The scaling of time has implications for the interpretation of the coefficients in the level-one equation (Stoel and Van den Wittenboer 2000), so authors should specify exactly how they are scaling time in their analyses.
There should be little difference in the ML and REML parameter estimates provided that the number of regressors is small compared to the product of the number of counties and the number of occasions. That is the case in all of our analyses (Diggle et al. 2002).
The turning point is computed by taking the derivative of the level 1 equation, which is a quadratic in time, with respect to time, setting it equal to zero, and solving for time. When our estimates are inserted in the resulting equation, we find that the maximum occurred at t = (−.02/[2(−.003)] = 3.333. When rescaled to original year units, 3.333 corresponds to year 1988. Because some counties have many more homicides than others, this is not necessarily the year in which national homicides were highest.
The HLM program was unable to estimate this model because of extremely high multicollinearity between the interaction terms and the direct term. This difficulty disappeared when we centered the time variables.
The exponent 0.151 in this expression is the value of the level-one equation evaluated at t = 10, i.e. .521−10[−0.050] + 100[0.0013]).
In the years of our study, only one county had a population this large. Consequently, for all practical purposes, the homicide rate is an increasing function of population for almost all counties. With very few counties having high populations, the precise shape of the dependence at high populations is poorly determined. In other words, we do not have enough high-population counties to assess the precise functional dependence of homicide rates on population size for very large counties. Consequently, it is quite possible that the positive dependence of homicide rates on population never reverses. The quadratic term may simply be picking up a slope that is less steep for large populations.
Some programs, such as HLM, do not offer a “built-in” procedure for adding fixed effects to models. Manually including dummies for each county can be onerous and computationally intensive. An alternative way to specify a fixed-effects model is to “condition out” the intercept and county fixed effects. This can be achieved by subtracting from Eq. 3 the same equation with each variable replaced by its mean; when this is done, the intercept a and the county fixed-effects drop out. In other words, to run a fixed effects growth curve model, we can begin by calculating the means over the entire time period for each county and each time-varying variable (dependent and independent variables). These county-specific means are then subtracted from the observed values of each variable, yielding results that would be identical to those obtained from a model with 400 county dummy variables (for more detail on this topic, refer to Allison 2005; Wooldridge 2002). The HLM program does not permit the creation of county-centered variables in its level-two specification menu. If one is interested only in modeling the intercept, one can enter the centered variables in the level-one equation. Alternately, one can do the centering in the program from which HLM is importing data. Then these centered variables can be entered “uncentered” in either the level-one or the level-two equation.
A further difference between the two approaches arises when there is theoretical reason to expect endogeneity among some of the variables in the model. Where reciprocal influences are expected among two or more variables in a panel model, pooled methods permit estimation to proceed free from simultaneous-equation bias through the use of instrumental variables. In principle, reciprocal influences can also be studied using a structural equation modeling approach to study growth curve trajectories, but the procedure requires specialized software, e.g. MPlus (Umberson et al. 2006). It is rarely considered in criminological applications, probably because many of the predictors of criminal behavior studied in this body of research can be considered exogenous (e.g. race and sex). However, this is not always the case, and where it is not, researchers should be aware of the importance of adapting the multilevel modeling approach to take account of this circumstance.
References
Allison P (2005) Fixed effects regression models for longitudinal data using SAS. SAS Institute, Inc, Cary, NC
Baltagi BH (2001) Econometric analysis of panel data. Wiley, New York
Banerjee A (1999) Panel data unit roots and cointegration: an overview. Oxford Bulletin of Economics and Statistics, Special Issue, 607–629
Box GEP, Jenkins GM (1976) Time series analysis: forecasting and control. Revised edition. Holden-Day, San Francisco
Bryk AS, Raudenbush SW (1992) Hierarchical linear models. Sage, Newbury Park, CA
Cooney M (2003) The privatization of violence. Criminology 41(4):1377–1406
Diggle PJ, Heagerty PJ, Wang K-Y, Zeger SL (2002) Analysis of longitudinal data, 2nd ed. New York, Oxford University Press
Ezell M, Cohen LE (2005) Desisting from crime: continuity and change in long-term crime patterns of serious chronic offenders. Oxford University Pressm, New York
Farrington D (1986) Age and crime. In: Tonry M, Morris N (eds) Crime and justice: an annual review of research. University of Chicago Press, Chicago, pp 189–250
Greenberg DF (1977) Delinquency and the age structure of society. Contemporary crises: crime. Law Soc Policy 1:643–51
Greenberg DF (1983) Age and crime. In: Kadish S (eds) Encyclopedia of crime and justice. Macmillan, New York, pp 30–35
Greenberg DF (1985) Age, crime, and social explanation. Am J Sociol 91:1–21
Greenberg DF (2003) Long-term trends in crimes of violence. Criminology 41:601–612
Greenberg DF (2008) Self control and the age, sex and race distribution of crime. In: Goode E (ed), Crime and criminality. Stanford University Press, Stanford
Greene, WH (2000) Econometric analysis, 4th ed. Prentice-Hall, Upper Saddle River, NJ
Hirschi T, Gottfredson MR (1983) Age and the explanation of crime. Am J Sociol 89:552–584
Hofman DA, Gavin MB (1998) Centering decisions in hierarchical linear models: implications for research in organizations. J Manage 24(5):623–641
Hsiao C (1986) Analysis of panel data. Cambridge University Press, New York
Hsiao C (1995) Panel analysis for metric data. In: Arminger G, Clogg CC, Sobel ME (eds) Handbook of statistical modeling for the social and behavioral sciences. Plenum, New York, pp 361–400
Hsiao, C (2003) Analysis of panel data. Cambridge University Press, Cambridge, UK
Horney J, Osgood DW, Marshall IH (1995) Criminal careers in the short-term: intra-individual variability in crime and its relation to local life circumstances. Am Sociol Rev 60(5):655–673
Im KS, Hashem Pesaran M, Shin Y (2003) Testing for unit roots in heterogeneous panels. J Econom 115:53–74
Johnston J, DiNardo J (1997) Econometric methods, 4th ed. McGraw-Hill, New York
Kennedy P (2003) A guide to econometrics. MIT Press, Cambridge, MA
Kreft I, de Leeuw J (1998) Introducing multilevel modeling. Sage, Thousand Oaks, CA
Kubrin CE, Herting JR (2003) Neighborhood correlates of homicide trends: an analysis using growth-curve modeling. Sociol Q 44(3):329–350
Land KC, McCall PL, Cohen LE (1990) Structural covariates of homicide rates: are there any invariances across time and social space? Am J Sociol 95:922–963
Laub JH, Nagin DS, Sampson RJ (1998) Trajectories of change in criminal offending: good marriages and the desistance process. Am Sociol Rev 63:225–238
Laub JH, Sampson RJ (2003) Shared beginnings, divergent lives: delinquent boys to age 70. Harvard University Press, Cambridge, MA
Levin A, Lin C-F (1993) Unit root tests in panel data: new results. University of California at San Diego Discussion Paper, No. 93–56
Longford NT (1993) Random coefficient models. Oxford University Press, New York
McArdle JJ, Hamagami F (1992) Modeling incomplete longitudinal and cross-sectional data using latent growth structural models. Exp Aging Res 18(1996):145–166
Meredith W, Tisak J (1990) Latent growth curve analysis. Psychometrika 55:107–122
Mills TC (1990) Time series techniques for economists. Cambridge University Press, New York
Nagin DS, Land KC (1993) Age, criminal careers, and population heterogeneity: specification and estimation of a nonparametric, mixed poisson model. Criminology 31:327–362
Paternoster R, Brame R (1997) Multiple routes to delinquency? A test of developmental and general theories of crime. Criminology 35:49–84
Phillips JA (2006a) Explaining discrepant findings in cross-sectional and longitudinal analyses: an application to U.S. homicide rates. Soc Sci Res 35(4):948–974
Phillips JA (2006b) The relationship between age structure and homicide rates in the United States, 1970–1999. J Res Crime Delinq 43(3):230–260
Plewis I (1985) Analyzing change: measurement and explanation using longitudinal data. Wiley, New York
Rabe-Hesketh S, Skrondal A (2005) Multilevel and longitudinal modeling using stata. Stata Press, College Station, TX
Raudenbush S, Bryk A (2002) Hierarchical linear models: applications and data analysis methods. Sage, Newbury Park
Rosenfeld R, Fornango R, Baumer E (2005) Did ceasefire, compstat, and exile reduce homicide? Criminol Public Policy 4.3:419–450
Rosenfeld R, Fornango R, Rengifo A (2007) The impact of order-maintenance policing on New York city homicide and robbery rates: 1988–2001. Criminology 45.2:355–384
Sampson RJ, Laub JH (1993) Crime in the making: pathways and turning points through life. Harvard University Press, Cambridge, MA
Searle SR, Cassella G, McCulloch CE (1992) Variance components. Wiley, New York
Singer JD, Willett JB (2003) Applied longitudinal data analysis: modeling change and event occurrence. Oxford University Press, New York
Skrondal A, Rabe-Hesketh S (2004) Generalized latent variable modeling: multilevels, longitudinal, and structural equation models. Chapman & Hall, Boca Raton
Snijders TA, Baker RJ (1999) Multilevel analysis: an introduction to basic and advanced multilevel modeling. Sage, Thousand Oaks, CA
Stoel RD, Van den Wittenboer G (2000) Transforming the time scale in linear multivariate growth curve models. Hist Soc Res 25:57–75
Stucky TD, Heimer K, Lang JB (2005) Partisan politics, electoral competition and imprisonment: an analysis of states over time. Criminology 43:209–245
Taris TW (2000) A primer in longitudinal data analysis. Sage, Thousand Oaks, CA
Uggen C, Thompson M (2003) The socioeconomic determinants of ill-gotten gains: within-person changes in drug use and illegal earnings. Am J Sociol 109:146–185
Umberson D, Williams K, Powers DA, Liu H, Needham B (2006) You make me sick: marital quality and health over the life course. J Health Soc Behav 47:1–16
Unal H, Heimer K (2003) Variation in the gender ratio of criminal punishment: an analysis of States, 1978–1998. Paper presented to the American Society of Criminology, Denver, CO
Wooldridge J (2002) Econometric analysis of cross section and panel data. MIT Press, Cambridge, MA
Yaffee R (2000) Time series analysis and forecasting. Academic Press, New York
Acknowledgments
We are grateful to Robert Sampson and to the anonymous reviewers for helpful suggestions.
Author information
Authors and Affiliations
Corresponding author
Appendices
Appendix I
Appendix II SAS Syntax
Table I
title “Table I, Model 1: Fixed Effects Pooled Model”;
proc mixed data=dataset cl ratio covtest info ic noclprint method=ml;
class caseid year;
model depvar=year caseid
indvar
/ solution ddfm=bw notest;
run;
title “Table I, Model 2: Random Effects Pooled Model”;
proc mixed data=dataset cl ratio covtest info ic noclprint method=ml;
class caseid year;
model depvar=year
indvar
/ solution ddfm=bw notest;
random intercept / subject=caseid type=un;
run;
Table II
title “Table II, Panel A: Growth Trajectory Model”;
proc mixed data=dataset cl ratio covtest info ic noclprint method=ml;
class caseid;
model depvar=time time2
indvar
/ solution ddfm=bw notest;
random intercept / subject=caseid type=un;
run;
title “Table II, Panel B: Growth Trajectory Model”;
proc mixed data=dataset cl ratio covtest info ic noclprint method=ml;
class caseid;
model depvar=time time2
indvar indvar*time indvar*time2
/ solution ddfm=bw notest;
random intercept time time2 / subject=caseid type=un;
run;
Table III
title “Table III, Panel A: Fixed Effects Growth Trajectory Model”;
proc mixed data=dataset cl ratio covtest info ic noclprint method=ml;
class caseid;
model depvar=time time2
indvar
/ solution ddfm=bw notest;
run;
title “Table III, Panel B: Fixed Effects Growth Trajectory Model”;
proc mixed data=dataset cl ratio covtest info ic noclprint method=ml;
class caseid;
model depvar=time time2
indvar indvar*time indvar*time2
caseid
/ solution ddfm=bw notest;
run;
Table IV
title “Table IV: Pooled Model with Selected Interaction Terms with Time”;
proc mixed data=dataset cl ratio covtest info ic noclprint method=ml;
class caseid year;
model depvar=year caseid
indvar indvar*time indvar*time2
/ solution ddfm=bw notest;
run;
Rights and permissions
About this article
Cite this article
Phillips, J.A., Greenberg, D.F. A Comparison of Methods for Analyzing Criminological Panel Data. J Quant Criminol 24, 51–72 (2008). https://doi.org/10.1007/s10940-007-9038-y
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10940-007-9038-y