
Abstract
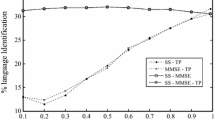
In present work, the robustness of excitation source features has been analyzed for language identification (LID) task. The raw samples of linear prediction (LP) residual signal, its magnitude and phase components are processed at sub-segmental, segmental and supra-segmental levels for capturing the robust language-specific phonotactic information. Present LID study has been carried out on 27 Indian languages from Indian Institute of Technology Kharagpur-Multi Lingual Indian Language Speech Corpus (IITKGP-MLILSC). Gaussian mixture models are used to develop the LID systems using robust language-specific excitation source information. Robustness of excitation source information has been evinced in view of (i) background noise, (ii) varying amount of training data and (iii) varying length of test samples. Finally, the robustness of proposed excitation source features is compared with the well-known spectral features using LID performances obtained from IITKGP-MLILSC database. Segmental level excitation source features obtained from raw samples of LP residual signal and its phase component perform better at low SNR levels, compared with the vocal tract features.






Similar content being viewed by others
References
All India Radio. (AIR). Accessed Feb. 2014 from http://www.newsonair.nic.in/.
Atal, B. S. (1972). Automatic speaker recognition based on pitch contours. Journal of the Acoustical Society of America, 52(6), 1687–1697.
Bajpai, A., & Yegnanarayana, B. (2004). Exploring features for audio clip classification using LP residual and AANN models. In The international conference on intelligent sensing and information processing (ICISIP 2004), Chennai, India (pp. 305–310).
Bapineedu, G., Avinash, B., Gangashetty, S. V., & Yegnanarayana, B. (2009). Analysis of lombard speech using excitation source information. In INTERSPEECH-09, Brighton, UK, September 2009.
Dempster, A. P., Laird, N. M., & Rubin, D. B. (1977). Maximum likelihood from incomplete data via the EM algorithm. Journal of the Royal Statistical Society, Series B (Methodological), 39(1), 1–38.
Foil, J. T. (1986). Language identification using noisy speech. In IEEE international conference on acoustics, speech, and signal processing (ICASSP) (pp. 861–864).
Goodman, F., Martin, A., & Wohlford, R. (1989). Improved automatic language identification in noisy speech. In International conference on acoustics, speech, and signal processing (ICASSP) (Vol. 1, pp. 528–531).
Gupta, C. S., Prasanna, S. R. M., & Yegnanarayana, B. (2002). Autoassociative neural network models for online speaker verification using source features from vowels. In IEEE international joint conference on neural networks (IJCNNS).
Kim, J. H., & Hong, K. S. (2006). Speech and gesture recognition-based robust language processing interface in noise environment. Intelligent Data Engineering and Automated Learning, 4224, 338–345.
Li, M., & Narayanan, S. (2014). Simplified supervised I-vector modeling with application to robust and efficient language identification and speaker verification. Computer, Speech Language, 28, 940–958.
Lawson, A., McLaren, M., Lei, Y., Mitra, V., Scheffer, N., Ferrer, L., et al. (2013). Improving language identification robustness to highly channel degraded speech through multiple system fusion. In INTERSPEECH, Lyon, France, Aug. 2013.
Manchala, S., Prasad, V. K., & Janaki, V. (2014). GMM based language identification system using robust features. International Journal of Speech Technology, 17, 99–105.
Makhoul, J. (1975). Linear prediction: A tutorial review. Proceedings on IEEE, 63, 561–580.
Maity, S., Vuppala, A. K., Rao, K. S., & Nandi, D. (2012). IITKGP-MLILSC speech database for language identification. In National conference on communication (NCC).
Murty, K. S. R., & Yegnanarayana, B. (2006). Combining evidence from residual phase and MFCC features for speaker recognition. IEEE Signal Processing Letters, 13, 52–55.
Prasanna, S. R. M., Gupta, C. S., & Yegnanarayana, B. (2006). Extraction of speaker-specific excitation information from linear prediction residual of speech. Speech Communication, 48, 1243–1261.
Rao, K. S., & Koolagudi, S. G. (2013). Characterization and recognition of emotions from speech using excitation source information. International Journal of Speech Technology, 16, 181–201.
Reddy, V. R., Maity, S., & Rao, K. S. (2013). Identification of indian languages using multi-level spectral and prosodic features. International Journal of Speech Technology, 16(4), 489–511.
Rao, K. S., Maity, S., & Reddy, V. R. (2013). Pitch synchronous and glottal closure based speech analysis for language recognition. International Journal of Speech Technology, 16(4), 413–430.
Reynolds, D. A., & Rose, R. C. (1995). Robust text independent speaker identification using gaussian mixture speaker models. IEEE Transactions on Speech and Audio Process, 3, 4–17.
Shahina, A., & Yegnanarayana, V. (2005). Language identification in noisy environments using throat microphone signals. In International conference on intelligent sensing and information processing.
Sreenivasa Rao, K., & Yegnanarayana, B. (2006). Prosody modification using instants of significant excitation. IEEE Transactions on Speech and Audio Processing, 14, 972–980.
Seshadri, G. P., & Yegnanarayana, B. (2009). Perceived loudness of speech based on the characteristics of glottal excitation source. The Journal of the Acoustical Society of America, 126, 2061–2071.
Sreenivasa Rao, K., Prasanna, S. R. M., & Yegnanarayana, B. (2007). Determination of instants of significant excitation in speech using hilbert envelope and group delay function. IEEE Signal Processing Letters, 14(10), 762–765.
Sreenivasa Rao, K., & Vuppala, A. K. (2013). Non-uniform time scale modification using instants of significant excitation and vowel onset points. Speech Communication, 55(6), 745–756.
Varga, A., & Steeneken, H. J. (1993). Assessment for automatic speech recognition: II. NOISEX-92: A database and an experiment to study the effect of additive noise on speech recognition systems. Speech Communication, 12, 247–251.
Vuppala, A. K., & Sreenivasa Rao, K. (2013). Speaker identification under background noise using features extracted from steady vowel regions. International Journal of Adaptive Control and Signal Processing, 27(9), 781–792.
Vuppala, A. K., & Sreenivasa Rao, K. (2013). Vowel onset point detection for noisy speech using spectral energy at formant frequencies. International Journal of Speech Technology, 16(2), 229–235.
Vuppala, A. K., Sreenivasa Rao, K., & Chakrabarti, S. (2012). Improved vowel onset point detection using epoch intervals. International Journal of Electronics and Communications, 66(8), 697–700.
Yegnanarayana, B., Avendano, C., Hermansky, H., & Murthy, P. S. (1997). Processing linear prediction residual for speech enhancement. In European conference on speech communication and technology (pp. 1399–1402).
Yegnanarayana, B., Prasanna, S., Zachariah, J., & Gupta, C. (2005). Combining evidence from source, suprasegmental and spectral features for a fixed-text speaker verification system. IEEE Transactions on Speech and Audio Processing, 13, 575–582.
Yegnanarayana, B., Prasanna, S. R. M., & Sreenivasa Rao, K. (2002). Speech enhancement using excitation source information. In International conference on acoustics, speech, and signal processing (ICASSP).
Yegnanarayana, B., Swamy, R. K., & Murthy, K. S. R. (2009). Determining mixing parameters from multispeaker data using speech-specific information. IEEE Transactions on Audio, Speech, and Language Processing, 17(6), 1196–1207.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Nandi, D., Pati, D. & Rao, K.S. Implicit excitation source features for robust language identification. Int J Speech Technol 18, 459–477 (2015). https://doi.org/10.1007/s10772-015-9288-2
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10772-015-9288-2