
Abstract
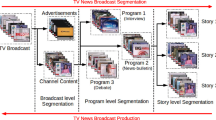
In this paper we proposed two-stage segmentation approach for splitting the TV broadcast news bulletins into sequence of news stories and codebooks derived from vector quantization are used for retrieving the segmented stories. At the first stage of segmentation, speaker (news reader) specific characteristics present in initial headlines of news bulletin are used for gross level segmentation. During second stage, errors in the gross level segmentation (first stage) are corrected by exploiting the speaker specific information captured from the individual news stories other than headlines. During headlines the captured speaker specific information is mixed with background music, and hence the segmentation at the first stage may not be accurate. In this work speaker specific information is represented by using mel frequency cepstral coefficients, and captured by Gaussian mixture models (GMMs). The proposed two-stage segmentation method is evaluated on manual segmented broadcast TV news bulletins. From the evaluation results, it is observed that about 93 % of the news stories are correctly segmented, 7 % are missed and 6 % are spurious. For navigating the bulletins, a quick navigation indexing method is developed based on speaker change points. Performance of the proposed two-stage segmentation and quick navigation methods are evaluated using GMM and neural networks models. For retrieving the target news stories from news corpus, sequence of codebook indices derived from vector quantization is explored. Proposed retrieval approach is evaluated using queries of different sizes. Evaluation results indicating that the retrieval accuracy is proportional to size of the query.



Similar content being viewed by others

References
Antonelli, M., Rizzi, A., & del Vescovo, G. (2010, Dec). A query by humming system for music information retrieval. In: Intelligent Systems Design and Applications (ISDA), 10th International Conference (pp.586–591).
Bengherabi, M., & Sehad, A. (Apr. 2006). Development and evaluation of automatic-speaker based-audio identification and segmentation for broadcast news recordings indexation. Information and Communication Technologies, 1, 1230–1235.
Butko, T., & Nadeu, C. (2011, May). Audio segmentation of broadcast news: A hierarchical system with feature selection for the Albayzin-2010 evaluation. In: Proceedings of IEEE International Conference on Acoustics, Speech and Signal Processing (pp.357–360)
Chen, S., & Gopalakrishnan, P. S. (1998). Speaker, environment and channel change detection and clustering via the bayesian information criterion. In Proceedings of DARPA Broadcast News Transcription and Understanding Workshop.
Delacourt, P., & Wellekens, C. (2000). Distbic: A speaker-based segmentation for audio data indexing. Speech Communication, 32(12), 111–126.
Dhananjaya, N., Prasad, S. G., and Yegnanarayana, B. (2004, Nov). Speaker segmentation based on subsegmental features and neural network models, 11th International Conference on Neural Information Processing (ICONIP-2004), vol. 50, (pp.1210–1215).
Dhananjaya, N., & Yegnanarayana, B. (2008). Speaker change detection in casual conversations using excitation source features. Speech Communication, 50, 153–161.
Foote, J. (2000). Automatic audio segmentation using a measure of audio novelty. In: Proceedings of International Conference on Multimedia and Expo, textit1, (pp.452–455)
Gish, H., Siu, M.-H., & Rohlicek, R. (1991). Segregation of speakers for speech recognition and speaker identification. In Proceedings of IEEE International Conference acoust, speech and signal processing, 2,(pp.873–876).
Hauptmann, A.G., and Witbrock, M. J. (1998, April). Story segmentation and detection of commercials in broadcast news video. In Proceedings of IEEE International Forum Research and Technology Advances in Digital Libraries, Santa Barbara, CA, USA (pp.168–179)
He, Q.-H., Yang, J.-C., Li, Y.-X., He, J., Zhang, X.-Y., & Li, W. (2010). Combining GMM, Jensen’s inequality and BIC for speaker indexing. Electronics Letters, 46(654–655), 29.
Huang, R., & Hansen, J. H. L. (2004, May). Advances in unsupervised audio segmentation for the broadcast news and ngsw corpora. In: Proceedings of IEEE International Conference on Acoustics, Speech and Signal Processing 1, (pp.741–744).
Karydis, A. P.: I Nanopoulos and Y. Manolopoulos. (2005, Jan). Audio indexing for efficient music information retrieval. In: Multimedia Modelling Conference, (pp.22–29)
Kemp, T., Schmidt, M., Westphal, M., & Waibel, A. (2000). Strategies for automatic segmentation of audio data. In Proceedings of IEEE International Conference Acoust Speech Signal Processing, 3, 1423–1426.
Kotti, M., Benetos, E., & Kotropoulos, C. (2008). Computationally efficient and robust bic-based speaker segmentation. IEEE Transactions on Audio, Speech and Language Processing, 16, 920–933.
Lei, W.: Unsupervised techniques for audio content analysis and summarization. PhD thesis, School of Computer Engineering, Nanyang Technological University, Singapore, May 2008.
Li, D., Sethi, I. K., Dimitrova, N., & McGee, T. (Apr. 2001). Classification of general audio data for content-based retrieval. Pattern Recognition Letters, 22, 533–544.
Lu, L, Jiang, H., & Zhang, H. J. (2001, Oct). A robust audio classification and segmentation method. In: Proceedings of the ninth ACM International Conference in Multimedia, Ottawa, Canada (pp.203–211).
Lu, G. (2001). Indexing and retrieval of audio: A survey. Multimedia Tools and Applications, 15, 269–290.
Makhoul, J., Kubala, F., Leek, T., Leu, D., Nguyen, L., Schwartz, R., et al. (2000). Speech and language technologies for audio indexing and retrieval. Processing of the IEEE, 88, 1338–1353.
Meinedo, H., & Neto, J. (2003, April). Audio segmentation, classification and clustering in a broadcast news task. In: Proceedings of IEEE International Conference on Acoustics Speech and Signal Processing, 2, (pp.5–8.)
Nwe, T. L., & Li, H. (2005, Mar). Broadcast news segmentation by audio type analysis. In: Proceedings of IEEE International Conference on Acoustics Speech snd Signal Processing 2, (pp.1065–1068).
Ohtsuki, K., Bessho, K., Matsuo, Y., Matsunaga, S., & Hayashi, Y. (2006). Automatic multimedia indexing: combining audio, speech, and visual information to index broadcast news. Signal Processing Magazine IEEE, 23, 69–78.
Perez-Freire, L., & Garcia-Mateo, C. (2004, May). A multimedia approach for audio segmentation in TV broadcast news. In: Proceedings of IEEE International Conference on Acoustics, Speech and Signal Processing, vol. 1.
Rao, K. S., Pachpande, K., Reddy, V. R., & Maity, S. (2012, Feb). Segmentation of tv broadcast news using speaker specific information. In: National Conference on Communications (NCC-2012), IIT Kharagpur, Kharagpur, India.
Reiss, J., Aucouturier, J. J., & Sandler, M. (2001). Efficient multidimensional searching routines for music information retrieval. International Society of Musical, Information Retrieval, pp.163–171, 2001.
Renals, S., Abberley, D., Kirby, D., & Robinson, T. (2000). Indexing and retrieval of broadcast news. Speech Communication, 32, 5–20.
Vuppala, A. K., Yadav, J., Chakrabarti, S., & Rao, K. S. (2012). Vowel onset point detection for low bit rate coded speech. IEEE Transactions on Audio, Speech and Language Processing, 20(6), 1894–1903.
Vuppala, A. K., Rao, K. S., & Chakrabarti, S. (2013). Vowel onset point detection for noisy speech using spectral energy at formant frequencies. International Journal of Speech Technology (Springer), 16(2), 229–235.
Wu, C.-H., & Hsieh, C.-H. (Mar. 2006). Multiple change-point audio segmentation and classification using an MDL-based Gaussian model. IEEE Transactions on Audio, Speech, and Language Processing, 14, 647–657.
Xue, H., Li, H., Gao, C., & Shi, Z. (2010). Computationally efficient audio segmentation through a multi-stage bic approach. In 3rd International Congress on Image and Signal Processing (CISP), 8, (pp.3774–3777).
Zhang, T., & Kuo, C.-C. (2001). Audio content analysis for online audiovisual data segmentation and classification. IEEE Transactions on Speech and Audio Processing, 9, 441–457.
Zheng, F., Zhang, G., & Song, Z. (2001). Comparison of different implementations of MFCC. Journal of Computer Science and Technology, 16(6), 582–589.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article
Cite this article
Rao, K.S., Pachpande, K. Segmentation, indexing and retrieval of TV broadcast news bulletins using Gaussian mixture models and vector quantization codebooks. Int J Speech Technol 17, 259–269 (2014). https://doi.org/10.1007/s10772-014-9229-5
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10772-014-9229-5