
Abstract
The paper revisits the question of how stock return comovement varies with volatility and market returns. I propose an eigenvalue-based measure of comovement implied by the state-dependent correlation matrix estimated using a novel multivariate semi-Markov-switching approach. I show that compared to a basic Markov-switching structure the refined model performs very well in terms of capturing the well-known stylized facts of stock returns such as volatility clustering. With a focus on large-cap stocks, I illustrate the significance of comovement differential across states and document the different comovement patterns in different industries. Although the financial sector tends to conform to the conventional sentiment that comovement is highest when market is down and volatile, the conclusion should be tempered with caution when applied to other industries. In some cases, it is the high return state that registers the highest comovement.



Similar content being viewed by others

Notes
Estimation of the degrees of freedom requires numerically solving a digamma function at each step, which adds another layer of complexity in terms of updating a weighted average for the conditional mean and covariance matrix. Analytical solutions do not exist; see the appendix in Bulla and Bulla (2006).
References
Ang, A., & Chen, J. (2002). Asymmetric correlations of equity portfolios. Journal of Financial Economics, 63(3), 443–494.
Billio, M., & Caporin, M. (2005). Multivariate Markov switching dynamic conditional correlation GARCH representations for contagion analysis. Statistical Methods and Applications, 14(2), 145–161.
Bekaert, G., Hodrick, R.J., & Zhang, X. (2008). Stock return comovements. ECB working paper 931, European Central Bank.
Bulla, J., & Bulla, I. (2006). Stylized facts of financial time series and hidden semi-Markov Models. Computational Statistics & Data Analysis, 51(4), 2192–2209.
Cho, J. S., & White, H. (2007). Testing for regime switching. Econometrica, 75(6), 1671–1720.
Croux, C., Forni, M., & Reichlin, L. (2001). Measure of comovemnet for economic variables: Theory and empirics. The Review of Economics and Statistics, 83(2), 232–241.
Edwards, S., & Susmel, R. (2003). Interest-rate volatility in emerging markets. Review of Economics and Statistics, 85(2), 325–348.
Ferguson, J. D. (1980). Variable duration models for speech. In J. D. Ferguson (Ed.) Proceedings of the symposium on the applications of hidden Markov models to text and speech (pp. 143–179). New York, NJ: Princeton.
Gray, S. (1996). Modeling the conditional distribution of interest rates as a regime-switching process. Journal of Financial Economics, 42(1), 27–62.
Guedon, Y. (2003). Estimating hidden semi-Markov chains from discrete sequences. Journal of Computational and Graphical Statistics, 12(3), 604–639.
Guidolin, M., & Timmermann, A. (2007). Asset allocation under multivariate regime switching. Journal of Economic Dynamics and Control, 31(11), 3503–3544.
Hamilton, J., & Sumsel, R. (1994). Autoregressive conditional heteroskedasticity and change in regime. Journal of Econometrics, 64(1), 307–333.
Hong, Y., Tu, J., & Zhou, G. (2007). Asymmetries in stock returns: Statistical tests and economic evaluation. Review of Financial Studies, 20(5), 1547–1581.
Laloux, L., Cizeau, P., Potters, M., & Bouchaud, J. P. (2000). Random matrix theory and financial correlations. International Journal of Theoretical and Applied Finance, 3(3), 391–397.
MacDonald, I. L., & Zucchini, W. (1997). Hidden Markov and other models for discrete-valued time series. London: Chapman & Hall.
Maheu, J. M., & McCurdy, T. H. (2000). Identifying bull and bear markets in stock returns. Journal of Business & Economic Statistics, 18(1), 100–112.
Peel, D., & McLachlan, G. J. (2000). Robust mixture modelling using the t distribution. Statistics and Computing, 10(4), 339–348.
Pelletier, D. (2006). Regime switching for dynamic correlations. Journal of Econometrics, 131(1), 445–473.
Reigneron, P. A., Allez, R., & Bouchaud, J. P. (2011). Principal regression analysis and the index leverage effect. Physica A, 390(17), 3026–3035.
Rua, A. (2010). Measuring comovement in the time-frequency space. Journal of Macroeconomics, 32(2), 685–691.
Rydén, T., Teräsvirta, T., & Asbrink, S. (1998). Stylized facts of daily return series and the hidden Markov model. Journal of Applied Econometrics, 13(3), 217–244.
Smith, A., Naik, P. A., & Tsai, C. L. (2005). Markov-switching model selection using Kullback–Leibler divergence. Journal of Econometrics, 134(2), 553–577.
Syllignakis, M. N., & Kouretas, G. P. (2011). Dynamic correlation analysis of financial contagion: Evidence from the Central and Eastern European markets. International Review of Economics & Finance, 20(4), 717–732.
Timmermann, A. (2000). Moments of Markov switching models. Journal of Econometrics, 96(1), 75–111.
Acknowledgments
I thank the editors, Hans Amman and Shu-Heng Chen, and two anonymous referees for insightful comments. I also thank Christophe Deissenberg, Gary Anderson and seminar participants at the 21st International Conference on Computing in Economics and Finance for encouraging feedback. All errors are mine.
Author information
Authors and Affiliations
Corresponding author
Appendices
Appendix 1
The goal of this appendix is to show that, in a multivariate context, the semi-Markov-switching framework is numerically stable, identifies states consistent with the market data, captures duration dependence (discussed in Sect. 4), and considerably reproduces the volatility clustering effect. I also consider the effect of prewhitening and outlier reduction. These findings together with the fact that a semi-Markov-switching model has been documented to account for other stock market stylized facts provide economic ground for its use in the full sample study.
1.1 Basic Results
A preliminary study is carried out and the results are given in Table 7. In addition, I compare the EM-sMSw model with the plain EM-MSw model. The three measures of stock return comovement are arranged in a way so that they run from the low state to the high state based on the estimated state-dependent volatilities. Since individual stock returns are often noisy, I also match the ordering of comovement with market data by computing the state-dependent market returns and volatilities over the same sample period. The ordering of state-dependent mean returns for individual stocks (not reported) are mostly in line with that of the market mean returns but exceptions are not rare: When the market is down, not all stock returns are low at the same time.
In an unreported exercise, sMSw appears to be more robust to outliers compared to the basic MSw model. Estimation of EM-sMSw models, is not sensitive to starting values of the conditional mean or the transition probability matrix, but is somewhat influenced by starting values of the variance-covariance matrix and the choice of duration distributions. For the latter, I use the versatile gamma distribution because its scale and shape parameters can vary independently and the result corroborates an earlier finding in the literature on duration dependence of states. Of practical concern is the computational cost, at which direct ML scores very badly, whereas EM-MSw and EM-sMSw are much faster. In the case of two regimes, the latter converges very fast and starting values do not seem to matter. When the order of switching is greater than two, to guarantee proper convergence I use the EM-MSw estimates as starting values.
I also use \(\hbox {VAR}\left( 1 \right) \) prewhitening/recoloring to check the potential influence of residual serial correlation and spurious ARCH effect. In the case of \({\mathrm {m}}=3\) and \({\mathrm {m}}=2\) (not reported), the results are stable across different model specifications and estimation techniques. It is found that \(\hbox {VAR}\left( 1 \right) \)-prewhitening does not appear to yield noticeable differences and that, for a given model, conclusion is the same for all three measures of comovement. In terms of order selection, MSwC and BIC pick either \({\mathrm {m}}=2\) or \({\mathrm {m}}=3\), whereas AIC and AIC\(_{\mathrm{c}}\) always pick the highest order of switching.
1.2 Model Evaluation
Since the four-regime model is not supported by BIC or MSwC, I only focus on two and three regimes in this section. In Table 7, I have conducted a Wald test of parameter equality on the average pairwise correlation measure of comovement (\(Cm_{avg}\)) in the Gaussian specification. The ordering of comovement is statistically insignificant for NYSE Fin Top 4, whereas for DJIA Top 4 and DAX 30 Top 4, significant but opposite conclusions are found.
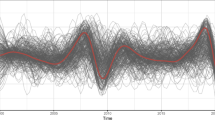
For lack of a simple relationship between the model parameters and the top eigenvalue of the state-dependent correlation matrix, approximate confidence intervals for Cm and \(Cm_{diff} \) cannot be directly imputed using, say, the second-order delta method. So I conduct a bootstrap experiment to see whether eigenvalue-based comovement differentials are statistically significant. I limit the case to two regimes selected by MSwC. Figure 1 shows the distribution of Cm based on 2000 parametric bootstrap samples generated from the two-state Gaussian NYSE Fin Top 4 model. As the paper is primarily concerned with comovement, I briefly report on the correlation parameters and transition probabilities in Table 8. Note that for DAX30 and DJIA the probability of staying in the low-return state is not high by conventional standard.
The small standard errors in Table 8 lead to the conjecture that the implied sampling distribution of Cm and \(Cm_{diff} \) should also have small standard errors, as the latter is fully determined by the correlation matrix. To see this more clearly, two normal distributions centered around the bootstrap means are superimposed onto Fig. 1, both of which have a standard deviation of 0.02. This, together with the bootstrap distribution, suggests that a difference of 0.05–0.1 or more can be viewed as solid evidence for comovement differential across states. For example, in the case of \({\mathrm {m}}=3\), NYSE Financial Top 4 does not deliver a clear message, whereas DAX30 Top 4 yields much more significant result and does not accord with the conventional wisdom of low return-high comovement, at least in the 4-year sample.
To highlight the semi-Markov-switching model’s ability to capture the slow decay of volatility dynamics, Figs. 4 and 5 illustrates the model-implied autocorrelations for squared returns and the sample ACF for squared residuals. In the Gaussian Markov-switching case, exact autocorrelation functions for squared returns can be derived and is plotted in Fig. 5; see Appendix 2 for the expressions. In the semi-Markov case, I approximate the model-implied ACF for squared returns by simulating a sample of 40,000 data points. A polynomial is fitted and superimposed onto each graph. Take DJIA Top 4, Fig. 4 shows that the semi-Markov model can explain a substantial amount of volatility clustering as the filtered squared returns (squared residuals) are very much whitened.
In Fig. 5, it is clear that in a standard Markov-switching model, the model-implied ACF for squared returns decreases too fast due to the geometric declining nature of the duration probability. Bulla and Bulla (2006) find the same result in their univariate analysis.
One remaining question is how well the states are identified since the high and low volatility states may be poorly separated thus confounding the comovement measures across states. Three commonly used methods in this area are filtering, smoothing and Viterbi’s algorithm. I take the filtered (smoothed) state to be the one that has the highest filtered (smoothed) probability; in Viterbi’s algorithm, a single most probable state is produced at each point in time as a byproduct of the global maximum likelihood. In the following simulation study, I compare filtered states, smoothed states and global most probable path inference by computing the percentage of correct matches for the case of \({\mathrm {m}}=3\). Table 9 is based on 1000 simulated samples of size 1000 from the corresponding estimated models. A match is said to occur if the estimated state coincides with the true state.

Model-implied ACF of squared residuals and sample ACF of semi-Markov model residuals, DJIA Top 4, m \(=\) 3

Sample ACF and exact ACF of squared returns of the Markov-switching model, NYSE Fin Top 4, m = 3
It can be seen from Table 9 that the medium volatility state is the hardest to estimate. All three methods are good at estimating the low volatility state, while smoothed inference and Viterbi’s algorithm perform better for the high and medium volatility states. The pattern changes little regardless of the model specification used and using smoothed or Viterbi states does not make any noticeable difference. In the next section, results are based on global most probable states using Viterbi’s algorithm.
1.3 A Note on Student’s t Distribution
At times, a t-distribution appears to be accommodating too much to outliers, whereas outlier reduction fixes this problem but imperfectly by introducing a mild yet unnecessary clustering of high volatility states at the cutoff points. To check this possibility, I simulate data from MSw models estimated with a t-distribution and find that extreme returns occur much too often compared to the frequency seen in real data, the latter of which actually looks much more like a simulation done using Gaussian returns plus just a handful of extreme events. When outlier reduction is combined with t-distributed returns, the tendency to over-accommodate to extreme returns overwhelms the use of outlier reduction because the extra parameter, degree of freedom, changes accordingly and absorbs most of the impact of cutoff points.
Another undesirable side-effect of using Student’s t returns is that the estimated transition matrix is much more concentrated along the diagonal for all states, with the off-diagonal probabilities being very small and thus susceptible to creating spuriously persistent states. By contrast, Gaussian returns are much more robust to one-time big swings and the estimated transition matrix is well-behaved in the sense that the probability of staying in one state is never insanely high especially for the high volatility state. As each row of a transition matrix sums to one and the diagonal element measures the persistence of a certain state, its columns are also meaningful in an important sense. Suppose, there is one highly persistent state with the corresponding diagonal probability close to one and other elements in the same column extremely small. This means that the probability of entering this state is extremely low, then such persistent state might just be the result of influential outliers. In the extreme case if the true data are such that all diagonal elements are extremely high and all off-diagonal probabilities extremely low, the system is then quite “disconnected” and the researcher might as well model the subperiods independently instead of pooling all the data together.
Appendix 2
1.1 Exact Moments of Markov-Switching Models
Let \({\Gamma }\) be the transition matrix, \(p_{ij} \left( k \right) \) the \(\left( {i,j} \right) \) element of \({\Gamma }^{k}\). Denote the stationary distribution and conditional mean vector as \({\varvec{\pi }} =\left( {\pi _1 ,\pi _2 ,\ldots ,\,\pi _m } \right) ^{\prime }\) and \({\varvec{\mu }} =\left( {\mu _1 ,\mu _2 ,\ldots ,\,\mu _m } \right) ^{\prime }\).
The last expression can be computed from the conditional second moment of the state-dependent distribution.
1.2 Estimating the Benchmark Model
Using notation of Sect. 2.1 and treating the unobserved states as missing data one gets,
and by the strong Markov property, a particular realization of states contributes to the likelihood by as much as
A full permutation of the histories of states thus yields
in which \({\Gamma }\) is the \(m\times m\) transition matrix, \(P\left( \cdot \right) \) is the diagonal conditional probability matrix of observation \(x_t \) given each possible state \(s_t \). For a general homogenous and irreducible m-state conditionally serially uncorrelated Markov-switching model, the likelihood function can be written conveniently in matrix form as
Thus a model of n assets has in total \(m\left( {m-1+n\left( {n+3} \right) /2} \right) \) parameters: \(m^{2}-m\) to determine \({\Gamma }\), mn for the state-dependent means, and \(mn\left( {n+1} \right) /2\) for the state-dependent variances and covariances. These parameters are collected in \({\varvec{\theta }} \). The transition probability matrix dictates that \(p_{ii}^{u-1} \left( {1-p_{ii} } \right) \) is the duration probability of staying in state i for u periods, \(u=1,2,\ldots \).
An alternative way to estimate the model is the EM algorithm based on the reknowned Baum-Welch forward-backward procedure. The EM algorithm can be used to check the influence of initial state on subsequent estimates. It does not evaluate the likelihood function directly and is fastest when the E-step can be broken down into a collection of terms involving subsets of parameters of interest, each of which is simple to maximize either numerically, or even better, analytically. This is true when stationarity is not imposed on the initial state but not otherwise. In the latter case, the E-step cannot be neatly seperated and no analytic solution exists. The E step and M step in the basic model are simplified versions of the semi-Markov-switching algorithm and can be found in MacDonald and Zucchini (1997). While it is common to assume that the process starts from its stationary distribution using ML-MSw, I do not impose this restriction on the EM algorithm.
To avoid boundary problems, I transform natural parameters into working ones before each run of estimation. Thus the algorithm returns a Hessian in terms of working parameters. I then recover the variance-covariance matrix with respect to natural parameters using the sandwich estimator:
Let \({\varvec{\phi }} \) and \({\varvec{\theta }} \) denote the vector of working parameters and natural parameters respectively, then
As an example, in the case of bivariate normal MSw model with two states, \(m=2\), the natural parameters are
and the working parameters are
Appendix 3
In this appendix I report the summary statistics for the four-year, the 15-year and the 30-year samples. Data are multiplied by 100.
Rights and permissions
About this article

Cite this article
Deng, K. Another Look at Large-Cap Stock Return Comovement: A Semi-Markov-Switching Approach. Comput Econ 51, 227–262 (2018). https://doi.org/10.1007/s10614-016-9596-x
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10614-016-9596-x