
Abstract
We propose an SQP algorithm for mathematical programs with vanishing constraints which solves at each iteration a quadratic program with linear vanishing constraints. The algorithm is based on the newly developed concept of \({\mathcal {Q}}\)-stationarity (Benko and Gfrerer in Optimization 66(1):61–92, 2017). We demonstrate how \({\mathcal {Q}}_M\)-stationary solutions of the quadratic program can be obtained. We show that all limit points of the sequence of iterates generated by the basic SQP method are at least M-stationary and by some extension of the method we also guarantee the stronger property of \({\mathcal {Q}}_M\)-stationarity of the limit points.
Similar content being viewed by others


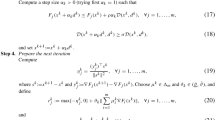
1 Introduction
Consider the following mathematical program with vanishing constraints (MPVC)
with continuously differentiable functions \(f, h_i, i \in E, g_i, i \in I, G_i, H_i, i \in V\) and finite index sets E, I and V.
Theoretically, MPVCs can be viewed as standard nonlinear optimization problems, but due to the vanishing constraints, many of the standard constraint qualifications of nonlinear programming are violated at any feasible point \({\bar{x}}\) with \(H_i({\bar{x}}) = G_i({\bar{x}}) = 0\) for some \(i \in V\). On the other hand, by introducing slack variables, MPVCs may be reformulated as so-called mathematical programs with complementarity constraints (MPCCs), see [7]. However, this approach is also not satisfactory as it has turned out that MPCCs are in fact even more difficult to handle than MPVCs. This makes it necessary, both from a theoretical and numerical point of view, to consider special tailored algorithms for solving MPVCs. Recent numerical methods follow different directions. A smoothing-continuation method and a regularization approach for MPCCs are considered in [6, 10] and a combination of these techniques, a smoothing-regularization approach for MPVCs is investigated in [2]. In [3, 8] the relaxation method has been suggested in order to deal with the inherent difficulties of MPVCs.
In this paper, we carry over a well known SQP method from nonlinear programming to MPVCs. We proceed in a similar manner as in [4], where an SQP method for MPCCs was introduced by Benko and Gfrerer. The main task of our method is to solve in each iteration step a quadratic program with linear vanishing constraints, a so-called auxiliary problem. Then we compute the next iterate by reducing a certain merit function along some polygonal line which is given by the solution procedure for the auxiliary problem. To solve the auxiliary problem we exploit the new concept of \({\mathcal {Q}}_M\)-stationarity introduced in the recent paper by Benko and Gfrerer [5]. \({\mathcal {Q}}_M\)-stationarity is in general stronger than M-stationarity and it turns out to be very suitable for a numerical approach as it allows to handle the program with vanishing constraints without relying on enumeration techniques. Surprisingly, we compute at least a \({\mathcal {Q}}_M\)-stationary solution of the auxiliary problem just by means of quadratic programming by solving appropriate convex subproblems.
Next we study the convergence of the SQP method. We show that every limit point of the generated sequence is at least M-stationary. Moreover, we consider the extended version of our SQP method, where at each iterate a correction of the iterate is made to prevent the method from converging to undesired points. Consequently we show that under some additional assumptions all limit points are at least \({\mathcal {Q}}_M\)-stationary. Numerical tests indicate that our method behaves very reliably.
A short outline of this paper is as follows. In Sect. 2 we recall the basic stationarity concepts for MPVCs as well as the recently developed concepts of \({\mathcal {Q}}\)- and \({\mathcal {Q}}_M\)-stationarity. In Sect. 3 we describe an algorithm based on quadratic programming for solving the auxiliary problem occurring in every iteration of our SQP method. We prove the finiteness and summarize some other properties of this algorithm. In Sect. 4 we propose the basic SQP method. We describe how the next iterate is computed by means of the solution of the auxiliary problem and we consider the convergence of the overall algorithm. In Sect. 5 we consider the extended version of the overall algorithm and we discuss its convergence. Section 6 is a summary of numerical results we obtained by implementing our basic algorithm in MATLAB and by testing it on a subset of test problems considered in the thesis of Hoheisel [7].
In what follows we use the following notation. Given a set M we denote by \(\mathcal {P}(M):=\{ (M_1,M_2) \,\vert \,M_1 \cup M_2 = M, \, M_1 \cap M_2 = \emptyset \}\) the collection of all partitions of M. Further, for a real number a we use the notation \((a)^+:=\max (0,a), (a)^-:=\min (0,a)\). For a vector \(u= (u_1, u_2, \ldots , u_m)^T \in \mathbb {R}^m\) we define \(\vert u \vert , (u)^+, (u)^-\) componentwise, i.e. \(\vert u \vert := (\vert u_1 \vert , \vert u_2 \vert , \ldots , \vert u_m \vert )^T\), etc. Moreover, for \(u \in \mathbb {R}^m\) and \(1 \le p \le \infty \) we denote the \(\ell _p\) norm of u by \(\Vert u \Vert _p\) and we use the notation \(\Vert u \Vert := \Vert u \Vert _2\) for the standard \(\ell _2\) norm. Finally, given a sequence \(y_k \in \mathbb {R}^m\), a point \(y \in \mathbb {R}^m\) and an infinite set \(K \subset \mathbb {N}\) we write \(y_k \mathop \rightarrow \limits ^{K} y\) instead of \(\lim _{k \rightarrow \infty , k \in K} y_k = y\).
2 Stationary points for MPVCs
Given a point \({\bar{x}}\) feasible for (1) we define the following index sets
In contrast to nonlinear programming there exist a lot of stationarity concepts for MPVCs.
Definition 2.1
Let \({\bar{x}}\) be feasible for (1). Then \({\bar{x}}\) is called
-
1.
Weakly stationary, if there are multipliers \(\lambda _i^g, i \in I, \lambda _i^h, i \in E, \lambda _i^G, \lambda _i^H, i \in V\) such that
$$\begin{aligned}&\nabla f({\bar{x}})^T + \sum _{i \in E} \lambda _i^h \nabla h_i({\bar{x}})^T + \sum _{i \in I} \lambda _i^g \nabla g_i({\bar{x}})^T \nonumber \\&\quad + \sum _{i \in V} \left( - \lambda _i^H \nabla H_i({\bar{x}})^T+ \lambda _i^G \nabla G_i({\bar{x}})^T \right) = 0 \end{aligned}$$(3)and
$$\begin{aligned} \begin{array}{rcl} \lambda _i^g g_i({\bar{x}}) = 0, i \in I, &{} \lambda _i^H H_i({\bar{x}}) = 0, i \in V, &{} \lambda _i^G G_i({\bar{x}}) = 0, i \in V, \\ \lambda _i^g \ge 0, i \in I, &{} \lambda _i^H \ge 0, i \in I^{0-}({\bar{x}}), &{} \lambda _i^G \ge 0, i \in I^{00}({\bar{x}}) \cup I^{+0}({\bar{x}}). \end{array} \end{aligned}$$(4) -
2.
M-stationary, if it is weakly stationary and
$$\begin{aligned} \lambda _i^H \lambda _i^G = 0, i \in I^{00}({\bar{x}}). \end{aligned}$$(5) -
3.
\(\mathcal {Q}\)-stationary with respect to \((\beta ^1,\beta ^2)\), where \((\beta ^1,\beta ^2)\) is a given partition of \(I^{00}({\bar{x}})\), if there exist two multipliers \({\overline{\lambda }}=({\overline{\lambda }}^h,{\overline{\lambda }}^g,{\overline{\lambda }}^H,{\overline{\lambda }}^G)\) and \({\underline{\lambda }}=({\underline{\lambda }}^h,{\underline{\lambda }}^g,{\underline{\lambda }}^H,{\underline{\lambda }}^G)\), both fulfilling (3) and (4), such that
$$\begin{aligned} {\overline{\lambda }}_i^G = 0, \ {\underline{\lambda }}_i^H, {\underline{\lambda }}_i^G \ge 0, \ i \in \beta ^1; \quad {\overline{\lambda }}_i^H, {\overline{\lambda }}_i^G \ge 0, \ {\underline{\lambda }}_i^G = 0, \ i \in \beta ^2. \end{aligned}$$(6) -
4.
\(\mathcal {Q}\)-stationary, if there is some partition \((\beta ^1,\beta ^2) \in {\mathcal {P}}(I^{00}({\bar{x}}))\) such that \({\bar{x}}\) is \(\mathcal {Q}\)-stationary with respect to \((\beta ^1,\beta ^2)\).
-
5.
\(\mathcal {Q}_M\)-stationary, if it is \(\mathcal {Q}\)-stationary and at least one of the multipliers \({\overline{\lambda }}\) and \({\underline{\lambda }}\) fulfills M-stationarity condition (5).
-
6.
S-stationary, if it is weakly stationary and
$$\begin{aligned} \lambda _i^H \ge 0, \lambda _i^G = 0, i \in I^{00}({\bar{x}}). \end{aligned}$$
The concepts of \(\mathcal {Q}\)-stationarity and \(\mathcal {Q}_M\)-stationarity were introduced in the recent paper by Benko and Gfrerer [5], whereas the other stationarity concepts are very common in the literature, see e.g. [1, 7, 8]. The following implications hold:
The first implication follows from the fact that the multiplier corresponding to S-stationarity fulfills the requirements for both \({\overline{\lambda }}\) and \({\underline{\lambda }}\). The third implication holds because for \((\beta ^1,\beta ^2) = (\emptyset ,I^{00}({\bar{x}}))\) the multiplier \({\underline{\lambda }}\) fulfills (5) since \({\underline{\lambda }}_i^G = 0\) for \(i \in I^{00}({\bar{x}})\).
Note that the S-stationarity conditions are nothing else than the Karush-Kuhn-Tucker conditions for the problem (1). As we will demonstrate in the next theorems, a local minimizer is S-stationary only under some comparatively stronger constraint qualification, while it is \(\mathcal {Q}_M\)-stationary under very weak constraint qualifications. Before stating the theorems we recall some common definitions.
Denoting
we see that problem (1) can be rewritten as
Recall that the contingent (also tangent) cone to a closed set \(\Omega \subset \mathbb {R}^m\) at \(u \in \Omega \) is defined by
The linearized cone to \(\Omega _V\) at \({\bar{x}} \in \Omega _V\) is then defined as \(T_{\Omega _V}^{\mathrm {lin}}({\bar{x}}) := \{d \in \mathbb {R}^n \,\vert \,\nabla \mathcal {F}({\bar{x}}) d \in T_{D}(\mathcal {F}({\bar{x}}))\}\).
Further recall that \({\bar{x}} \in \Omega _V\) is called B-stationary if
Every local minimizer is known to be B-stationary.
Definition 2.2
Let \({\bar{x}}\) be feasible for (1), i.e \({\bar{x}} \in \Omega _V\). We say that the generalized Guignard constraint qualification (GGCQ) holds at \({\bar{x}}\), if the polar cone of \(T_{\Omega _V}({\bar{x}})\) equals the polar cone of \(T_{\Omega _V}^{\mathrm {lin}}({\bar{x}})\).
Theorem 2.1
(c.f. [5, Theorem 8]) Assume that GGCQ is fulfilled at the point \({\bar{x}} \in \Omega _V\). If \({\bar{x}}\) is B-stationary, then \({\bar{x}}\) is \(\mathcal {Q}\)-stationary for (1) with respect to every partition \((\beta ^1,\beta ^2) \in \mathcal {P}(I^{00}({\bar{x}}))\) and it is also \(\mathcal {Q}_M\)-stationary.
Theorem 2.2
(c.f. [5, Theorem 8]) If \({\bar{x}}\) is Q-stationary with respect to a partition \((\beta ^1,\beta ^2) \in \mathcal {P}(I^{00}({\bar{x}}))\), such that for every \(j \in \beta ^1\) there exists some \(z^j\) fulfilling
and there is some \({\bar{z}}\) such that
then \({\bar{x}}\) is S-stationary and consequently also B-stationary.
Note that these two theorems together also imply that a local minimizer \({\bar{x}} \in \Omega _V\) is S-stationary provided GGCQ is fulfilled at \({\bar{x}}\) and there exists a partition \((\beta ^1,\beta ^2) \in \mathcal {P}(I^{00}({\bar{x}}))\), such that for every \(j \in \beta ^1\) there exists \(z^j\) fulfilling (9) and \({\bar{z}}\) fulfilling (10).
Moreover, note that (9) and (10) are fulfilled for every partition \((\beta ^1,\beta ^2) \in \mathcal {P}(I^{00}({\bar{x}}))\) e.g. if the gradients of active constraints are linearly independent. On the other hand, in the special case of partition \((\emptyset ,I^{00}({\bar{x}})) \in \mathcal {P}(I^{00}({\bar{x}}))\), this conditions read as the requirement that the system
has a solution, which resembles the well-known Mangasarian-Fromovitz constraint qualification (MFCQ) of nonlinear programming and it seems to be a rather weak and possibly often fulfilled assumption.
Finally, we recall the definitions of normal cones. The regular normal cone to a closed set \(\Omega \subset \mathbb {R}^m\) at \(u \in \Omega \) can be defined as the polar cone to the tangent cone by
The limiting normal cone to a closed set \(\Omega \subset \mathbb {R}^m\) at \(u \in \Omega \) is given by
In case when \(\Omega \) is a convex set, regular and limiting normal cone coincide with the classical normal cone of convex analysis, i.e.
Well-known is also the following description of the limiting normal cone
We conclude this section by the following characterization of M- and \({\mathcal {Q}}\)-stationarity via limiting normal cone. Straightforward calculations yield that
and hence the M-stationarity conditions (4) and (5) can be replaced by
and the \({\mathcal {Q}}\)-stationarity conditions (4) and (6) can be replaced by
where for \((\beta ^1,\beta ^2) \in \mathcal {P}(I^{00}({\bar{x}}))\) we define
Note also that for every \(i \in V\) we have
3 Solving the auxiliary problem
In this section, we describe an algorithm for solving quadratic problems with vanishing constraints of the type
here the vector \(\theta = (\theta ^g,\theta ^G,\theta ^H) \in \{ 0, 1 \}^{\vert I \vert + 2 \vert V \vert } =: \mathcal {B}\) is chosen at the beginning of the algorithm such that some feasible point is known in advance, e.g. \((s,\delta )=(0,1)\). The parameter \(\rho \) has to be chosen sufficiently large and acts like a penalty parameter forcing \(\delta \) to be near zero at the solution. B is a symmetric positive definite \(n \times n\) matrix, \(\nabla f, \nabla h_i, \nabla g_i, \nabla G_i, \nabla H_i\) denote row vectors in \(\mathbb {R}^n\) and \(h_i,g_i,G_i,H_i\) are real numbers. Note that this problem is a special case of problem (1) and consequently the definition of \(\mathcal {Q}-\) and \(\mathcal {Q}_M-\) stationarity as well as the definition of index sets (2) remain valid.
It turns out to be much more convenient to operate with a more general notation. Let us denote by \(F_i:=(-H_i,G_i)^T\) a vector in \(\mathbb {R}^2\), by \(\nabla F_i := (-\nabla H_i^T,\nabla G_i^T)^T\) a \(2 \times n\) matrix and by \(P^1 := \{0\} \times \mathbb {R}\) and \(P^2:= \mathbb {R}^2_-\) two subsets of \(\mathbb {R}^2\). Note that for P given by (7) it holds that \(P = P^1 \cup P^2\). The problem (18) can now be equivalently rewritten in a form
For a given feasible point \((s,\delta )\) for the problem \(QPVC(\rho )\) we define the following index sets
where the index sets \(I^{0+}(s,\delta ), I^{+0}(s,\delta ), I^{+-}(s,\delta ), I^{0-}(s,\delta ), I^{00}(s,\delta )\) are given by (2).
Further, consider the distance function d defined by
for \(x \in \mathbb {R}^2\) and \(A \subset \mathbb {R}^2\). The following proposition summarizes some well-known properties of d.
Proposition 3.1
Let \(x \in \mathbb {R}^2\) and \(A \subset \mathbb {R}^2\).
-
1.
Let \(B \subset \mathbb {R}^2\), then
$$\begin{aligned} d(x, A \cup B) = \min \{ d(x, A), d(x, B) \}. \end{aligned}$$(20)In particular,
$$\begin{aligned} d(x,P^1)= & {} (x_1)^+ + (-x_1)^+, \,\, d(x,P^2) = (x_1)^+ + (x_2)^+,\nonumber \\ d(x,P)= & {} (x_1)^+ + (\min \{-x_1,x_2\})^+. \end{aligned}$$(21) -
2.
\(d(\cdot ,A) : \mathbb {R}^2 \rightarrow \mathbb {R}^+\) is Lipschitz continuous with Lipschitz modulus \(L = 1\) and consequently
$$\begin{aligned} d(x,A) \le d(x+y,A) + \Vert y \Vert _1. \end{aligned}$$(22) -
3.
\(d(\cdot ,A) : \mathbb {R}^2 \rightarrow \mathbb {R}^+\) is convex, provided A is convex.
Due to the disjunctive structure of the auxiliary problem we can subdivide it into several QP-pieces. For every partition \((V_1,V_2) \in \mathcal {P}(V)\) we define the convex quadratic problem
Since \((V_1,V_2)\) form a partition of V it is sufficient to define \(V_1\) since \(V_2\) is given by \(V_2 = V \setminus V_1\).
At the solution \((s,\delta )\) of \(QP(\rho , V_1)\) there is a corresponding multiplier \(\lambda (\rho , V_1) = (\lambda ^h,\lambda ^g,\lambda ^H,\lambda ^G)\) and a number \(\lambda ^{\delta } \ge 0\) with \(\lambda ^{\delta } \delta = 0\) fulfilling the KKT conditions:
where \(\lambda _i^F := (\lambda _i^H,\lambda _i^G)^T\) for \(i \in V\). Since \(P^1\) and \(P^2\) are convex sets, the above normal cones are given by (12).
The definition of the problem \(QP(\rho , V_1)\) allows the following interpretation of \(\mathcal {Q}\)-stationarity, which is a direct consequence of (15) and (16).
Lemma 3.1
A point \((s,\delta )\) is \(\mathcal {Q}\)-stationary with respect to \((\beta ^1,\beta ^2) \in \mathcal {P}(I^{00}(s,\delta ))\) for (19) if and only if it is the solution of the convex problems \(QP(\rho , I^{1}(s,\delta ) \cup \beta ^1)\) and \(QP(\rho , I^{1}(s,\delta ) \cup \beta ^2)\).
Moreover, since for \(V_1 = I^{1}(s,\delta ) \cup I^{00}(s,\delta )\) the conditions (27),(28) read as \(\lambda _i^F \in \nu _i^{I^{00}(s,\delta ),\emptyset }(s,\delta )\), it follows from (17) that if a point \((s,\delta )\) is the solution of \(QP(\rho , I^{1}(s,\delta ) \cup I^{00}(s,\delta ))\) then it is M-stationary for (19).
Finally, let us denote by \({\bar{\delta }}(V_1)\) the objective value at a solution of the problem
An outline of the algorithm for solving \(QPVC(\rho )\) is as follows.
Algorithm 3.1
(Solving the QPVC) Let \(\zeta \in (0,1), \bar{\rho } > 1\) and \(\rho > 0\) be given.
-
1:
Initialize:
-
Set the starting point \((s^0, \delta ^0) := (0,1)\), define the vector \(\theta \) by
$$\begin{aligned} \theta _i^{g} := \left\{ \begin{array}{ll} 1 &{} \quad \text {if } g_i > 0, \\ 0 &{} \quad \text {if } g_i \le 0, \end{array} \right. \qquad (\theta _i^{H}, \theta _i^{G}) := \left\{ \begin{array}{ll} (0,0) &{} \quad \text {if } d(F_i,P) = 0, \\ (1,0) &{} \quad \text {if } 0< d(F_i,P^1) \le d(F_i,P^2), \\ (0,1) &{} \quad \text {if } 0< d(F_i,P^2) < d(F_i,P^1) \end{array} \right. \end{aligned}$$(30)and set the partition \(V_1^1 := I^{1}(s^0,\delta ^0)\) and the counter of pieces \(t:=0\).
-
Compute \((s^{1}, \delta ^{1})\) as the solution and \(\lambda ^{1}\) as the corresponding multiplier of the convex problem \(QP(\rho , V_1^{1})\) and set \(t:=1\).
-
If \(\delta ^1 > \delta ^0\), perform a restart: set \(\rho := \rho \bar{\rho }\) and go to step 1.
-
-
2:
Improvement step:
-
while \((s^t,\delta ^t)\) is not a solution of the following four convex problems:
$$\begin{aligned}&QP(\rho , I^{1}(s^t,\delta ^t) \cup (I^{00}(s^t,\delta ^t) \cap V_1^t)), \nonumber \\&\quad QP(\rho , I^{1}(s^t,\delta ^t) \cup (I^{00}(s^t,\delta ^t) \setminus V_1^t)), \end{aligned}$$(31)$$\begin{aligned}&QP(\rho , I^{1}(s^t,\delta ^t)), QP(\rho , I^{1}(s^t,\delta ^t) \cup I^{00}(s^t,\delta ^t)). \end{aligned}$$(32) -
Compute \((s^{t+1}, \delta ^{t+1})\) as the solution and \(\lambda ^{t+1}\) as the corresponding multiplier of the first problem with \((s^{t+1}, \delta ^{t+1}) \ne (s^{t}, \delta ^{t})\), set \(V_1^{t+1}\) to the corresponding index set and increase the counter t of pieces by 1.
-
If \(\delta ^t > \delta ^{t-1}\), perform a restart: set \(\rho := \rho \bar{\rho }\) and go to step 1.
-
-
3:
Check for successful termination:
-
If \(\delta ^t < \zeta \) set \(N:=t\), stop the algorithm and return.
-
-
4:
Check the degeneracy:
-
If the non-degeneracy condition
$$\begin{aligned} \min \{ \bar{\delta }(I^{1}(s^t,\delta ^t)), \bar{\delta }(I^{1}(s^t,\delta ^t) \cup I^{00}(s^t,\delta ^t)) \} < \zeta \end{aligned}$$(33)is fulfilled, perform a restart: set \(\rho := \rho \bar{\rho }\) and go to step 1.
-
Else stop the algorithm because of degeneracy.
-
The selection of the index sets in step 2 is motivated by Lemma 3.1, since if \((s,\delta )\) is the solution of convex problems (31), then it is \(\mathcal {Q}\)-stationary and if \((s,\delta )\) is also the solution of convex problems (32), then it is even \(\mathcal {Q}_M\)-stationary for problem (19).
We first summarize some consequences of the Initialization step.
Proposition 3.2
-
1.
Vector \(\theta \) is chosen in a way that for all \(i \in V\) it holds that
$$\begin{aligned} \Vert (\theta _i^H H_i, - \theta _i^G G_i)^T \Vert _1 = d(F_i, P). \end{aligned}$$(34) -
2.
Partition \((V_1^1,V_2^1)\) is chosen in a way that for \(j=1,2\) it holds that
$$\begin{aligned} i \in V_j^1 \, \text { implies } \, d(F_i, P) = d(F_i, P^j). \end{aligned}$$(35)
Proof
1. If \(d(F_i, P) = 0\) we have \((\theta _i^H, \theta _i^G) = (0,0)\) and (34) obviously holds. If \(0 < d(F_i,P^1) \le d(F_i,P^2)\) we have \((\theta _i^H, \theta _i^G) = (1,0)\) and we obtain
by (21) and (20). Finally, if \(0< d(F_i,P^2) < d(F_i,P^1)\) we have \(H_i< 0 < G_i, (\theta _i^H, \theta _i^G) = (0,1)\) and thus
follows again by (21) and (20).
2. If \((\theta _i^H H_i, - \theta _i^G G_i)^T + F_i \in P^j\) for some \(i \in V\) and \(j = 1,2\), by (22) and (34) we obtain
and consequently \(d(F_i,P^j) = d(F_i,P)\), because of (20). Hence we conclude that \(i \in (I^{j}(s^0,\delta ^0) \cup I^{0}(s^0,\delta ^0))\) implies \(d(F_i,P^j) = d(F_i,P)\) for \(j = 1,2\) and the statement now follows from the fact that \(V_1^1 = I^{1}(s^0,\delta ^0)\) and \(V_2^1 = I^{2}(s^0,\delta ^0) \cup I^{0}(s^0,\delta ^0)\). \(\square \)
The following lemma plays a crucial part in proving the finiteness of the Algorithm 3.1.
Lemma 3.2
For each partition \((V_1,V_2) \in \mathcal {P}(V)\) there exists a positive constant \(C_{\rho }(V_1)\) such that for every \(\rho \ge C_{\rho }(V_1)\) the solution \((s,\delta )\) of \(QP(\rho ,V_1)\) fulfills \(\delta = {\bar{\delta }}(V_1)\).
Proof
Let \((s(V_1),\delta (V_1))\) denote a solution of (29). Since \(\delta (V_1)={\bar{\delta }}(V_1)\), it follows that the problem
is feasible and by \({\bar{s}}(V_1)\) we denote the solution of this problem and by \({\bar{\lambda }}(V_1)\) the corresponding multiplier. Further, \(({\bar{s}}(V_1),{\bar{\delta }}(V_1))\) is a solution of (29) and by \(\lambda (V_1)\) we denote the corresponding multiplier.
Then, triple \(({\bar{s}}(V_1),{\bar{\delta }}(V_1))\) and \({\bar{\lambda }}(V_1)\) fulfills (24) and (26)–(28). Moreover, triple \(({\bar{s}}(V_1),{\bar{\delta }}(V_1))\) and \(\lambda (V_1)\) fulfills (26)-(28) and
for some \(\lambda ^{\delta } \ge 0\) with \(\lambda ^{\delta } {\bar{\delta }}(V_1) = 0\).
Let \(C_{\rho }(V_1)\) be a positive constant such that for all \(\rho \ge C_{\rho }(V_1)\) we have
and set \({\tilde{\lambda }}^{\delta } := \alpha \lambda ^{\delta } \ge 0\) and \({\tilde{\lambda }} := {\bar{\lambda }}(V_1) + \alpha \lambda (V_1)\). We will now show that for such \(\rho \) it holds that \(({\bar{s}}(V_1),{\bar{\delta }}(V_1))\) is the solution of \(QP(\rho ,V_1)\).
Clearly, \({\tilde{\lambda }}^{\delta } {\bar{\delta }}(V_1) = \alpha \lambda ^{\delta } {\bar{\delta }}(V_1) = 0\) and the triple \(({\bar{s}}(V_1),{\bar{\delta }}(V_1))\) and \({\tilde{\lambda }}\) also fulfills (24) due to (37) and it fulfills (26)-(28) due to the convexity of the normal cones. Moreover, taking into account the definitions of \(\alpha , {\tilde{\lambda }}^{\delta }\) and \({\tilde{\lambda }}\) together with (38), we obtain
showing also (25). Hence \(({\bar{s}}(V_1),{\bar{\delta }}(V_1))\) is the solution of \(QP(\rho ,V_1)\) and the proof is complete. \(\square \)
We now formulate the main theorem of this section.
Theorem 3.1
-
1.
Algorithm 3.1 is finite.
-
2.
If the Algorithm 3.1 is not terminated because of degeneracy, then \((s^N,\delta ^N)\) is \(\mathcal {Q}_M\)-stationary for the problem (19) and \(\delta ^N < \zeta \).
Proof
1. The algorithm is obviously finite unless we perform a restart and hence increase \(\rho \). Thus we can assume that \(\rho \) is sufficiently large, say
with \(C_{\rho }(V_1)\) given by the previous lemma. However this means, taking into account also Proposition 3.3 (1.), that \((s^{t-1},\delta ^{t-1})\) is feasible for the problem \(QP(\rho ,V_1^t)\) for all t, hence \(\delta ^{t-1} \ge {\bar{\delta }}(V_1^t)\) and \((s^t,\delta ^t)\) is the solution of \(QP(\rho ,V_1^t)\), implying \(\delta ^{t} = {\bar{\delta }}(V_1^t)\) and consequently \(\delta ^{t} \le \delta ^{t-1}\). Therefore we do not perform a restart in step 1 or step 2. On the other hand, since we enter steps 3 and 4 with \(\delta ^t = {\bar{\delta }}(I^{1}(s^t,\delta ^t)) = {\bar{\delta }}(I^{1}(s^t,\delta ^t) \cup I^{00}(s^t,\delta ^t))\), we either terminate the algorithm in step 3 with \(\delta ^t < \zeta \) if the non-degeneracy condition (33) is fulfilled or we terminate the algorithm because of degeneracy in step 4. This finishes the proof.
2. The statement regarding stationarity follows easily from the fact that we enter step 3 of the algorithm only when \((s,\delta )\) is a solution of problems (32) and this means that it is also \(\mathcal {Q}\)-stationary with respect to \((\emptyset ,I^{00}(s^N,\delta ^N))\) by Lemma 3.1. Thus, \((s,\delta )\) is also \(\mathcal {Q}_M\)-stationary for problem (19). The claim about \(\delta \) follows from the assumption that the Algorithm 3.1 is not terminated because of degeneracy. \(\square \)
We conclude this section with the following proposition that brings together the basic properties of the Algorithm 3.1.
Proposition 3.3
If the Algorithm 3.1 is not terminated because of degeneracy, then the following properties hold:
-
1.
For all \(t = 1, \ldots , N\) the points \((s^{t-1},\delta ^{t-1})\) and \((s^{t},\delta ^{t})\) are feasible for the problem \(QP(\rho ,V_1^t)\) and the point \((s^t,\delta ^t)\) is also the solution of the convex problem \(QP(\rho ,V_1^t)\).
-
2.
For all \(t = 1, \ldots , N\) it holds that
$$\begin{aligned} 0 \le \delta ^{t} \le \delta ^{t-1} \le 1. \end{aligned}$$(39) -
3.
There exists a constant \(C_t\), dependent only on the number of constraints, such that
$$\begin{aligned} N \le C_t. \end{aligned}$$(40)
Proof
1. By definitions of the problems \(QPVC(\rho )\) and \(QP(\rho ,V_1)\) it follows that a point \((s,\delta )\), feasible for \(QPVC(\rho )\), is feasible for \(QP(\rho ,V_1)\) if and only if
The point \((s^0,\delta ^0)\) is clearly feasible for \(QP(\rho ,V_1^1)\) and similarly the point \((s^{t},\delta ^{t})\) is feasible for \(QP(\rho ,V_1^{t+1})\) for all \(t = 1, \ldots , N-1\), since the partition \(V_1^{t+1}\) is defined by one of the index sets of (31)-(32) and thus fulfills (41). However, feasibility of \((s^{t+1},\delta ^{t+1})\) for \(QP(\rho ,V_1^{t+1})\), together with \((s^{t+1},\delta ^{t+1})\) being the solution of \(QP(\rho ,V_1^{t+1})\), then follows from its definition.
2. Statement follows from \(\delta ^0 = 1\), from the fact that we perform a restart whenever \(\delta ^t > \delta ^{t-1}\) occurs and from the constraint \(-\delta \le 0\).
3. Since whenever the parameter \(\rho \) is increased the algorithm goes to the step 1 and thus the counter t of the pieces is reset to 0, it follows that after the last time the algorithm enters step 1 we keep \(\rho \) constant. It is obvious that all the index sets \(V_1^t\) are pairwise different implying that the maximum of switches to a new piece is \(2^{\vert V \vert }\). \(\square \)
4 The basic SQP algorithm for MPVC
An outline of the basic algorithm is as follows.
Algorithm 4.1
(Solving the MPVC)
-
1:
Initialization:
-
Select a starting point \(x_0 \in \mathbb {R}^n\) together with a positive definite \(n \times n\) matrix \(B_0\), a parameter \(\rho _0 > 0\) and constants \(\zeta \in (0,1)\) and \({\bar{\rho }} > 1\).
-
Select positive penalty parameters \(\sigma _{-1} = (\sigma ^h_{-1}, \sigma ^g_{-1}, \sigma ^F_{-1})\).
-
Set the iteration counter \(k := 0\).
-
-
2:
Solve the Auxiliary problem:
-
Run Algorithm 3.1 with data \(\zeta , {\bar{\rho }}, \rho := \rho _k, B:=B_k, \nabla f := \nabla f (x_k),\) \(h_i := h_i(x_k), \nabla h_i := \nabla h_i (x_k), i \in E,\) etc.
-
If the Algorithm 3.1 stops because of degeneracy, stop the Algorithm 4.1 with an error message.
-
If the final iterate \(s^N\) is zero, stop the Algorithm 4.1 and return \(x_k\) as a solution.
-
-
3:
Next iterate:
-
Compute new penalty parameters \(\sigma _{k}\).
-
Set \(x_{k+1} := x_k + s_k\) where \(s_k\) is a point on the polygonal line connecting the points \(s^0,s^1, \ldots , s^N\) such that an appropriate merit function depending on \(\sigma _{k}\) is decreased.
-
Set \(\rho _{k+1} := \rho \), the final value of \(\rho \) in Algorithm 3.1.
-
Update \(B_{k}\) to get positive definite matrix \(B_{k+1}\).
-
Set \(k := k+1\) and go to step 2.
-
Remark 4.1
We terminate the Algorithm 4.1 only in the following two cases. In the first case no sufficient reduction of the violation of the constraints can be achieved. The second case will be satisfied only by chance when the current iterate is a \(\mathcal {Q}_M\)-stationary solution. Normally, this algorithm produces an infinite sequence of iterates and we must include a stopping criterion for convergence. Such a criterion could be that the violation of the constraints at some iterate is sufficiently small,
where \(F_i\) is given by (7) and the expected decrease in our merit function is sufficiently small,
see Proposition 4.1 below.
4.1 The next iterate
Denote the outcome of Algorithm 3.1 at the \(k-\)th iterate by
The new penalty parameters are computed by
where
with maximum being taken over \(t \in \{ 1, \ldots , N_k \}\) and \(1< \xi _1 < \xi _2\). Note that this choice of \(\sigma _{k}\) ensures
4.1.1 The merit function
We are looking for the next iterate at the polygonal line connecting the points \(s_k^0,s_k^1, \ldots , s_k^{N_k}\). For each line segment \([s_k^{t-1},s_k^t] := \{(1-\alpha ) s_k^{t-1} + \alpha s_k^t \,\vert \,\alpha \in [0,1] \}, t = 1, \ldots , N_k\) we consider the functions
where \(s = (1 - \alpha ) s_k^{t-1} + \alpha s_k^t\) and \(f = f(x_k), \nabla f = \nabla f (x_k), h_i = h_i(x_k), \nabla h_i = \nabla h_i (x_k), i \in E,\) etc. and we further denote
Lemma 4.1
-
1.
For every \(t \in \{ 1, \ldots , N_k \}\) the function \(\hat{\phi }_k^t\) is convex.
-
2.
For every \(t \in \{ 1, \ldots , N_k \}\) the function \(\hat{\phi }_k^t\) is a first order approximation of \(\phi _k^t\), that is
$$\begin{aligned} \vert \phi _k^t(\alpha ) - \hat{\phi }_k^t(\alpha ) \vert = o(\Vert s \Vert ), \end{aligned}$$where \(s = (1 - \alpha ) s_k^{t-1} + \alpha s_k^t\).
Proof
1. By convexity of \(P^1\) and \(P^2, \hat{\phi }_k^t\) is convex because it is sum of convex functions.
2. By Lipschitz continuity of distance function with Lipschitz modulus \(L = 1\) we conclude
and hence the assertion follows. \(\square \)
We state now the main result of this subsection. For the sake of simplicity we omit the iteration index k in this part.
Proposition 4.1
For every \(t \in \{ 1, \ldots , N_k \}\)
Proof
Fix \(t \in \{ 1, \ldots , N_k \}\) and note that
because of \(s^0 = 0\). For \(j=0,1\) consider \(r^{t+j}_{1-j}\) defined by (45). We obtain
Using that \((s^{\tau },\delta ^{\tau })\) is the solution of \(QP(\rho ,V_1^{\tau })\) and multiplying the first order optimality condition (24) by \((s^{\tau } - s^{\tau -1})^T\) yields
Summing up the expression on the left hand side from \(\tau =1\) to t, subtracting it from the right hand side of (48) and taking into account the identity
we obtain for \(j=0,1\)
First, we claim that
Consider \(i \in V\) and \(\tau \in \{1, \ldots , t\}\) with \(i \in V_1^{\tau }\). By the feasibility of \((s^{\tau },\delta ^{\tau })\) and \((s^{\tau -1},\delta ^{\tau -1})\) for \(QP(\rho , V_1^{\tau })\) it follows that
and hence from (27) and (12) we conclude
and consequently
follows by the Hölder inequality and (34).
Analogous argumentation yields (52) also for \(i, \tau \) with \(i \in V_2^{\tau }\) and since \(V_1^{\tau },V_2^{\tau }\) form a partition of V, the claimed inequality (51) follows.
Further, we claim that for \(j=0,1\) it holds that
From feasibility of \((s^t,\delta ^t)\) for either \(QP(\rho ,V_1^{t})\) or \(QP(\rho ,V_1^{t+1})\) for \(i \in V_1^t \cup V_1^{t+1}\) it follows that
and hence, using (34) and (22),
Again, for \(i \in V_2^{t}\) or \(i \in V_2^{t+1}\) it holds that \(\sigma _i^F d(F_i + \nabla F_i s^{t}, P^2) \le \sigma _i^F \delta ^{t} d(F_i,P)\) by analogous argumentation and since \(V_1^{t},V_2^{t}\) and \(V_1^{t+1},V_2^{t+1}\) form a partition of V, the claimed inequality (53) follows.
Finally, we have
due to the fact that \(V_1^{1},V_2^{1}\) form a partition of V and (35).
Similar arguments as above show
Taking this into account and putting together (50), (51), (53) and (55) we obtain for \(j=0,1\)
and hence (46) and (47) follow by monotonicity of \(\delta \) and (44). This completes the proof. \(\square \)
4.1.2 Searching for the next iterate
We choose the next iterate as a point from the polygonal line connecting the points \(s_k^0, \ldots , s_k^{N_k}\). Each line segment \([s_k^{t-1},s_k^t]\) corresponds to the convex subproblem solved by Algorithm 3.1 and hence each line search function \({\hat{\phi }}_k^t\) corresponds to the usual \(\ell _1\) merit function from nonlinear programming. This makes it technically more difficult to prove the convergence behavior stated in Proposition 4.2 which is also the motivation for the following procedure.
First we parametrize the polygonal line connecting the points \(s_k^0, \ldots , s_k^{N_k}\) by its length as a curve \({\hat{s}}_k: [0,1] \rightarrow \mathbb {R}^n\) in the following way. We define \(t_k(1) := N_k\), for every \(\gamma \in [0,1)\) we denote by \(t_k(\gamma )\) the smallest number t such that \(S_k^t > \gamma S_k^{N_k}\) and we set \(\alpha _k(1) := 1\),
where \(S_k^0 := 0, S_k^t := \sum _{\tau =1}^{t} \Vert s_k^{\tau } - s_k^{\tau -1} \Vert \) for \(t=1, \ldots , N_k\). Then we define
Note that \(\Vert {\hat{s}}_k (\gamma ) \Vert \le \gamma S_k^{N_k}\).
In order to simplify the proof of Proposition 4.2, for \(\gamma \in [0,1]\) we further consider the following line search functions
Now consider some sequence of positive numbers \(\gamma ^k_1 = 1, \gamma ^k_2, \gamma ^k_3, \ldots \) with \(1> {\bar{\gamma }} \ge \gamma ^k_{j+1} / \gamma ^k_j \ge {\underline{\gamma }} > 0\) for all \(j \in \mathbb {N}\). Consider the smallest j, denoted by j(k) such that for some given constant \(\xi \in (0,1)\) one has
Then the new iterate is given by
As can be seen from the proof of Lemma 4.5, this choice ensures a decrease in merit function \(\Phi \) defined in the next subsection.
The following relations are direct consequences of the properties of \(\phi _k^t\) and \({\hat{\phi }}_k^t\)
The last property holds due to Proposition 4.1 and
which follows from \(\alpha _k(0) = 0, S_k^{t_k(0)-1} = 0\) and hence \({\hat{\phi }}_k^{t_k(0)}(0) = {\hat{\phi }}_k^{1}(0)\). We recall that \(r^t_{k,0}\) and \(r^{t}_{k,1}\) are defined by (45).
Lemma 4.2
The new iterate \(x_{k+1}\) is well defined.
Proof
In order to show that the new iterate is well defined, we have to prove the existence of some j such that (57) is fulfilled. Note that \(S_k^{t_k(0) - 1} = 0\) and \(S_k^{t_k(0)} > 0\). There is some \(\delta _k > 0\) such that \(\vert Y_k(\gamma ) - \hat{Y}_k(\gamma ) \vert \le \frac{-(1 - \xi )r^{t_k(0)}_{k,1} \gamma S_k^{N_k}}{S_k^{t_k(0)}}\), whenever \(\gamma S_k^{N_k} \le \delta _k\). Since \(\lim _{j \rightarrow \infty } \gamma _j^k = 0\), we can choose j sufficiently large to fulfill \(\gamma _j^k S_k^{N_k} < \min \{ \delta _k, S_k^{t_k(0)} \}\) and then \(t_k(\gamma _j^k) = t_k(0)\) and \(\alpha _k(\gamma _j^k) = \gamma _j^k S_k^{N_k} / S_k^{t_k(0)}\), since \(S_k^{t_k(0) - 1} = 0\). This yields
Then by second property of (58), (59), taking into account \(r^{t_k(\gamma _j^k)}_{k,0} \le 0\) by Proposition 4.1 and \(Y_k(0) = Z_k(0)\) we obtain
Thus (57) is fulfilled for this j and the lemma is proved. \(\square \)
4.2 Convergence of the basic algorithm
We consider the behavior of the Algorithm 4.1 when it does not prematurely stop and it generates an infinite sequence of iterates
Note that \(\delta _k^{N_k} < \zeta \). We discuss the convergence behavior under the following assumption.
Assumption 1
-
1.
There exist constants \(C_x, C_s, C_{\lambda }\) such that
$$\begin{aligned} \Vert x_k \Vert \le C_x, \quad S_k^{N_k} \le C_s, \quad {\hat{\lambda }}_k^h, {\hat{\lambda }}_k^g, {\hat{\lambda }}_k^F \le C_{\lambda } \end{aligned}$$for all k, where \({\hat{\lambda }}_k^h := \max _{i \in E} \{ {\tilde{\lambda }}_{i,k}^h \}, {\hat{\lambda }}_k^g := \max _{i \in I} \{ {\tilde{\lambda }}_{i,k}^g \}, {\hat{\lambda }}_k^F := \max _{i \in V} \{ {\tilde{\lambda }}_{i,k}^F \}\).
-
2.
There exist constants \({\bar{C}}_{B}, {\underline{C}}_{B}\) such that \({\underline{C}}_B \le \lambda (B_k), \Vert B_k \Vert \le {\bar{C}}_B\) for all k, where \(\lambda (B_k)\) denotes the smallest eigenvalue of \(B_k\).
For our convergence analysis we need one more merit function
Lemma 4.3
For each k and for any \(\gamma \in [0,1]\) it holds that
Proof
The first claim follows from the definitions of \(\Phi _k\) and \(Y_k\) and the estimate
which holds by (20). The second claim follows from (35). \(\square \)
A simple consequence of the way that we define the penalty parameters in (42) is the following lemma.
Lemma 4.4
Under Assumption 1 there exists some \({\bar{k}}\) such that for all \(k \ge {\bar{k}}\) the penalty parameters remain constant, \({\bar{\sigma }} := \sigma _{k}\) and consequently \(\Phi _k(x) = \Phi _{{\bar{k}}}(x)\).
Remark 4.2
Note that we do not use \(\Phi _k\) for calculating the new iterate because its first order approximation is in general not convex on the line segments connecting \(s_k^{t-1}\) and \(s_k^{t}\) due to the involved min operation.
Lemma 4.5
Assume that Assumption 1 is fulfilled. Then
Proof
Take an existed \({\bar{k}}\) from Lemma 4.4. Then we have for \(k \ge {\bar{k}}\)
and therefore \(\Phi _{k+1}(x_{k+1}) - \Phi _k(x_k) \le Y_k(\gamma _{j(k)}^{k}) - Y_k(0) < 0\). Hence the sequence \(\Phi _k(x_k)\) is monotonically decreasing and therefore convergent, because it is bounded below by Assumption 1. Hence
and the assertion follows. \(\square \)
Proposition 4.2
Assume that Assumption 1 is fulfilled. Then
and consequently
Proof
We prove (63) by contraposition. Assuming on the contrary that (63) does not hold, by taking into account \({\hat{Y}}_k(1) - {\hat{Y}}_k(0) \le 0\) by Proposition 4.1, there exists a subsequence \(K = \{ k_1, k_2, \ldots \}\) such that \({\hat{Y}}_k(1) - {\hat{Y}}_k(0) \le {\bar{r}} < 0\). By passing to a subsequence we can assume that for all \(k \in K\) we have \(k \ge {\bar{k}} \) with \({\bar{k}}\) given by Lemma 4.4 and \(N_k = {\bar{N}}\), where we have taken into account (40). By passing to a subsequence once more we can also assume that
where \(r_{k,1}^t\) and \(r_{k,0}^t\) are defined by (45). Note that \({\bar{r}}_1^{{\bar{N}}} \le {\bar{r}} < 0\).
Let us first consider the case \(\bar{S}^{{\bar{N}}} = 0\). There exists \(\delta > 0\) such that \(\vert Y_k(\gamma ) - \hat{Y}_k(\gamma ) \vert \le (\xi - 1) \bar{r}_1^{{\bar{N}}} \gamma S_k^{{\bar{N}}} \, \forall k \in K,\) whenever \(\gamma S_k^{{\bar{N}}} \le \delta \). Since \(\bar{S}^{{\bar{N}}} = 0\) we can assume that \(S_k^{{\bar{N}}} \le \min \{ \delta , 1/2 \} \, \forall k \in K\). Then
and this implies that for the next iterate we have \(j(k) = 1\) and hence \(\gamma _{j(k)}^k = 1\), contradicting (62).
Now consider the case \(\bar{S}^{N} \ne 0\) and let us define the number \({\bar{\tau }} := \max \{ t \,\vert \,\bar{S}^{t} = 0 \} + 1\). Note that Proposition 4.1 yields
and therefore \({\tilde{r}} := \max _{t > {\bar{\tau }}} {\bar{r}}^t < 0\), where \({\bar{r}}^t := \max \{ {\bar{r}}_0^t, {\bar{r}}_1^t \}\). By passing to a subsequence we can assume that for every \(t > {\bar{\tau }}\) and every \(k \in K\) we have \(r_{k,0}^t,r_{k,1}^{t} \le \frac{{\bar{r}}^t}{2}\).
Now assume that for infinitely many \(k \in K\) we have \(\gamma _{j(k)}^k S_k^{{\bar{N}}} \ge S_k^{{\bar{\tau }}}\), i.e. \(t_k(\gamma _{j(k)}^{k}) > {\bar{\tau }}\). Then we conclude
contradicting (62). Hence for all but finitely many \(k \in K\), without loss of generality for all \(k \in K\), we have \(\gamma _{j(k)}^k S_k^{{\bar{N}}} < S_k^{{\bar{\tau }}}\).
There exists \(\delta > 0\) such that
whenever \(\gamma S_k^{{\bar{N}}} \le \delta \). By eventually choosing \(\delta \) smaller we can assume \(\delta \le S^{{\bar{\tau }}} / 2\) and by passing to a subsequence if necessary we can also assume that for all \(k \in K\) we have
Now let for each k the index \({\tilde{j}}(k)\) denote the smallest j with \(\gamma _j S_k^{{\bar{N}}} \le \delta \). It obviously holds that \(\gamma _{{\tilde{j}}(k)-1}^{k} S_k^{{\bar{N}}} > \delta \) and by (67) we obtain
implying \(t_k(\gamma _{{\tilde{j}}(k)}^{k}) = {\bar{\tau }}\) and
by (67).
Taking this into account together with (66) and \(\gamma _{{\tilde{j}}(k)}^{k} S_k^{{\bar{N}}} \le \delta \) we conclude
Now we can proceed as in the proof of Lemma 4.2 to show that \({\tilde{j}}(k)\) fulfills (57).
However, this yields \({\tilde{j}}(k) \ge j(k)\) by definition of j(k) and hence \(\gamma _{j(k)}^{k} S_k^{{\bar{N}}} \ge \gamma _{{\tilde{j}}(k)}^{k} S_k^{{\bar{N}}} \ge S_k^{{\bar{\tau }}-1}\) showing \(t_k(\gamma _{j(k)}^{k}) = t_k(\gamma _{{\tilde{j}}(k)}^{k}) ={\bar{\tau }}\). But then we also have \(\alpha _k(\gamma _{j(k)}^{k}) \ge \alpha _k(\gamma _{{\tilde{j}}(k)}^{k}) \ge \frac{\underline{\gamma } \delta }{4 {\bar{S}}^{{\bar{\tau }}}}\) and from (57) we obtain
contradicting (62) and so (63) is proved. Condition (64) now follows from (63) because we conclude from (65) that \({\hat{Y}}_k(1) - {\hat{Y}}_k(0) \le - \frac{{\underline{C}}_{B}}{2} \frac{1}{N_k} (S_k^{N_k})^2 \le - \frac{{\underline{C}}_{B}}{2} \frac{1}{N_k} \Vert s_k^{N_k} \Vert ^2\). \(\square \)
Now we are ready to state the main result of this section.
Theorem 4.1
Let Assumption 1 be fulfilled. Then every limit point of the sequence of iterates \(x_k\) is at least M-stationary for problem (1).
Proof
Let \(\bar{x}\) denote a limit point of the sequence \(x_k\) and let K denote a subsequence such that \(\lim _{k \mathop \rightarrow \limits ^{K} \infty } x_k = {\bar{x}}\). Further let \({\underline{\lambda }}\) be a limit point of the bounded sequence \({\underline{\lambda }}_k^{N_k}\) and assume without loss of generality that \(\lim _{k \mathop \rightarrow \limits ^{K} \infty } {\underline{\lambda }}_k^{N_k} = {\underline{\lambda }}\). First we show feasibility of \(\bar{x}\) for the problem (1) together with
Consider \(i \in I\). For all k it holds that
Since \(0 \le \delta _k^{N_k} \le \zeta , \theta _{i,k}^{g} \in \{0,1\}\) we have \(1 \ge (1 - \theta _{i,k}^{g} \delta _k^{N_k}) \ge 1 - \zeta \) and together with \(s_k^{N_k} \rightarrow 0\) by Proposition 4.2 we conclude
\({\underline{\lambda }}_i^g \ge 0\) and
Hence \({\underline{\lambda }}_i^g \ge 0 = {\underline{\lambda }}_i^g g_i({\bar{x}})\). Similar arguments show that for every \(i \in E\) we have
Finally consider \(i \in V\). Taking into account (22), (34) and \(\delta _k^{N_k} \le \zeta \) we obtain
Hence, \(\nabla F_i(x_k) s_k^{N_k} \rightarrow 0\) by Proposition 4.2 implies
showing the feasibility of \({\bar{x}}\). Moreover, the previous arguments also imply
Taking into account (14), the fact that \({\underline{\lambda }}_k^{N_k}\) fulfills M-stationarity conditions at \((s_k^{N_k},\delta _k^{N_k})\) for (19) yields
However, this together with \(({\underline{\lambda }}_{k}^{H,N_k}, {\underline{\lambda }}_{k}^{G,N_k}) \mathop \rightarrow \limits ^{K} ({\underline{\lambda }}^{H}, {\underline{\lambda }}^{G})\), (69), and (13) yield \(({\underline{\lambda }}^{H}, {\underline{\lambda }}^{G}) \in N_{P^{\vert V \vert }}(F({\bar{x}}))\) and consequently (68) follows.
Moreover, by first order optimality condition we have
for each k and by passing to a limit and by taking into account that \(B_ks_k^{N_k} \rightarrow 0\) by Proposition 4.2 we obtain
Hence, invoking (14) again, this together with the feasibility of \({\bar{x}}\) and (68) implies M-stationarity of \({\bar{x}}\) and the proof is complete. \(\square \)
5 The extended SQP algorithm for MPVC
In this section we investigate what can be done in order to secure \(\mathcal {Q}_M\)-stationarity of the limit points. First, note that to prove M-stationarity of the limit points in Theorem 4.1 we only used that \(({\underline{\lambda }}_{k}^{H,N_k}, {\underline{\lambda }}_{k}^{G,N_k}) \in N_{P^{\vert V \vert }}({\tilde{F}}(x_k,s_k^{N_k},\delta _k^{N_k}))\), i.e. it is sufficient to exploit only the M-stationarity of the solutions of auxiliary problems. Further, recalling the comments after Lemma 3.1, the solution \((s,\delta )\) of \(QP(\rho , I^{1}(s,\delta ) \cup I^{00}(s,\delta ))\) is M-stationary for the auxiliary problem. Thus, in Algorithm 3.1 for solving the auxiliary problem, it is sufficient to consider only the last problem of the four problems (31),(32). Moreover, definition of limiting normal cone (11) reveals that, in general, the limiting process abolishes any stationarity stronger that M-stationarity, even S-stationarity.
Nevertheless, in practical situations it is likely that some assumption, securing that a stronger stationarity will be preserved in the limiting process, may be fulfilled. E.g., let \({\bar{x}}\) be a limit point of \(x_k\). If we assume that for all k sufficiently large it holds that \(I^{00}({\bar{x}}) = I^{00}(s_k^{N_k},\delta _k^{N_k})\), then \({\bar{x}}\) is at least \(\mathcal {Q}_M\)-stationary for (1). This follows easily, since now for all \(i \in I^{00}({\bar{x}})\) it holds that \({\underline{\lambda }}_{i,k}^{G,N_k} = 0, {\overline{\lambda }}_{i,k}^{H,N_k}, {\overline{\lambda }}_{i,k}^{G,N_k} \ge 0\) and consequently
This observation suggests that to obtain a stronger stationarity of a limit point, the key is to correctly identify the bi-active index set at the limit point and it serves as a motivation for the extended version of our SQP method. Before we can discuss the extended version, we summarize some preliminary results.
5.1 Preliminary results
Let \(a: \mathbb {R}^n \rightarrow \mathbb {R}^p\) and \(b: \mathbb {R}^n \rightarrow \mathbb {R}^q\) be continuously differentiable. Given a vector \(x \in \mathbb {R}^n\) we define the linear problem
Note that \(d=0\) is always feasible for this problem. Next we define a set A by
Let \({\bar{x}} \in A\) and recall that the Mangasarian-Fromovitz constraint qualification (MFCQ) holds at \({\bar{x}}\) if the matrix \(\nabla a({\bar{x}})\) has full row rank and there exists a vector \(d \in \mathbb {R}^n\) such that
Moreover, for a matrix M we denote by \(\Vert M \Vert _p\) the norm given by
and we also omit the index p in case \(p = 2\).
Lemma 5.1
Let \({\bar{x}} \in A\), let assume that MFCQ holds at \({\bar{x}}\) and let \({\bar{d}}\) denote the solution of \(LP({\bar{x}})\). Then for every \(\epsilon > 0\) there exists \(\delta > 0\) such that if \(\Vert x - {\bar{x}} \Vert \le \delta \) then
where d denotes the solution of LP(x).
Proof
The classical Robinson’s result (c.f. [9, Corollary 1, Theorem 3]), together with MFCQ at \({\bar{x}}\), yield the existence of \(\kappa > 0\) and \({\tilde{\delta }} > 0\) such that for every x with \(\Vert x - {\bar{x}} \Vert \le {\tilde{\delta }}\) there exists \({\hat{d}}\) with \(\nabla a(x) {\hat{d}} = 0, (b(x))^- + \nabla b(x) {\hat{d}} \le 0\) and
Since \(\Vert {\hat{d}} \Vert _\infty \le \Vert {\hat{d}} - {\bar{d}} + {\bar{d}} \Vert _\infty \le 1 + \nu \), by setting \({\tilde{d}} := {\hat{d}} /(1 + \nu )\) we obtain that \({\tilde{d}}\) is feasible for LP(x) and
Thus, taking into account \(\nabla a({\bar{x}}) {\bar{d}} = 0, (b({\bar{x}}))^- + \nabla b({\bar{x}}) {\bar{d}} \le 0\) and \(\Vert {\bar{d}} \Vert _{\infty } \le 1\), we obtain
Hence, given \(\epsilon > 0\), by continuity of objective and constraint functions as well as their derivatives at \({\bar{x}}\) we can define \(\delta \le {\tilde{\delta }}\) such that for all x with \(\Vert x - {\bar{x}} \Vert \le \delta \) it holds that
Consequently, we obtain
and since \(\nabla f (x) d \le \nabla f (x) {\tilde{d}}\) by feasibility of \({\tilde{d}}\) for LP(x), the claim is proved. \(\square \)
Lemma 5.2
Let \(\nu \in (0,1)\) be a given constant and for a vector of positive parameters \(\omega = (\omega ^{{\mathcal {E}}},\omega ^{{\mathcal {I}}})\) let us define the following function
Further assume that there exist \(\epsilon > 0\) and a compact set C such that for all \(x \in C\) it holds that \(\nabla f(x) d \le - \epsilon \), where d denotes the solution of LP(x). Then there exists \({\tilde{\alpha }} > 0\) such that
holds for all \(x \in C\) and every \(\alpha \in [0,{\tilde{\alpha }}]\).
Proof
Definition of \(\varphi \), together with \(u^+-v^+ \le (u - v^+)^+\) for \(u,v \in \mathbb {R}\), yield
By uniform continuity of the derivatives of constraint functions and objective function on compact sets, it follows that there exists \({\tilde{\alpha }} > 0\) such that for all \(x \in C\) and every h with \(\Vert h \Vert _{\infty } \le {\tilde{\alpha }}\) we have
Hence, for all \(x \in C\) and every \(\alpha \in [0,{\tilde{\alpha }}]\) we obtain
On the other hand, taking into account \(\nabla a(x) d = 0, \Vert d \Vert _{\infty } \le 1\), (77) and
we similarly obtain for all \(x \in C\) and every \(\alpha \in [0,{\tilde{\alpha }}]\)
Consequently, (75) follows from (76) and the proof is complete. \(\square \)
5.2 The extended version of Algorithm 4.1
For every vector \(x \in \mathbb {R}^n\) and every partition \((W_1 , W_2) \in \mathcal {P}(V)\) we define the linear problem
Note that \(d=0\) is always feasible for this problem and that the problem \(LP(x,W_1)\) coincides with the problem LP(x) with a, b given by
The following proposition provides the motivation for introducing the problem \(LP(x,W_1)\).
Proposition 5.1
Let \({\bar{x}}\) be feasible for (1). Then \({\bar{x}}\) is \(\mathcal {Q}\)-stationary with respect to \((\beta ^1,\beta ^2) \in \mathcal {P}(I^{00}({\bar{x}}))\) if and only if the solutions \({\bar{d}}^1\) and \({\bar{d}}^2\) of the problems \(LP({\bar{x}},I^{0+}({\bar{x}}) \cup \beta ^1)\) and \(LP({\bar{x}}, I^{0+}({\bar{x}}) \cup \beta ^2)\) fulfill
Proof
Feasibility of \(d=0\) for \(LP({\bar{x}},I^{0+}({\bar{x}}) \cup \beta ^1)\) and \(LP({\bar{x}},I^{0+}({\bar{x}}) \cup \beta ^2)\) implies
Denote by \({\tilde{d}}^1\) and \({\tilde{d}}^2\) the solutions of \(LP({\bar{x}},I^{0+}({\bar{x}}) \cup \beta ^1)\) and \(LP({\bar{x}},I^{0+}({\bar{x}}) \cup \beta ^2)\) without the constraint \(-1 \le d \le 1\), and denote these problems by \(\tilde{LP}^1\) and \(\tilde{LP}^2\). Clearly, we have
The dual problem of \(\tilde{LP}^j\) for \(j=1,2\) is given by
where \(\lambda = (\lambda ^h,\lambda ^g,\lambda ^H,\lambda ^G), m = \vert E \vert + \vert I \vert + 2 \vert V \vert , W_1^j := I^{0+}({\bar{x}}) \cup \beta ^j, W_2^j := V \setminus W_1^j\).
Assume first that \({\bar{x}}\) is \(\mathcal {Q}\)-stationary with respect to \((\beta ^1,\beta ^2) \in \mathcal {P}(I^{00}({\bar{x}}))\). Then the multipliers \({\overline{\lambda }}, {\underline{\lambda }}\) from definition of \(\mathcal {Q}\)-stationarity are feasible for dual problems of \(\tilde{LP}^1\) and \(\tilde{LP}^2\), respectively, both with the objective value equal to zero. Hence, duality theory of linear programming yields that \(\min \{ \nabla f ({\bar{x}}) {\tilde{d}}^1 , \nabla f ({\bar{x}}) {\tilde{d}}^2 \} \ge 0\) and consequently (80) follows.
On the other hand, if (80) is fulfilled, is follows that \(\min \{ \nabla f ({\bar{x}}) {\tilde{d}}^1 , \nabla f ({\bar{x}}) {\tilde{d}}^2 \} = 0\) as well. Thus, \(d=0\) is an optimal solution for \(\tilde{LP}^1\) and \(\tilde{LP}^2\) and duality theory of linear programming yields that the solutions \(\lambda ^1\) and \(\lambda ^2\) of the dual problems exist and their objective values are both zero. However, this implies that for \(j=1,2\) we have
and consequently \(\lambda ^1\) fulfills the conditions of \({\overline{\lambda }}\) and \(\lambda ^2\) fulfills the conditions of \({\underline{\lambda }}\), showing that \({\bar{x}}\) is indeed \(\mathcal {Q}\)-stationary with respect to \((\beta ^1,\beta ^2)\). \(\square \)
Now for each k consider two partitions \((W_{1,k}^1,W_{2,k}^1), (W_{1,k}^2,W_{2,k}^2) \in {\mathcal {P}}(V)\) and let \(d_k^1\) and \(d_k^2\) denote the solutions of \(LP(x_k, W_{1,k}^1)\) and \(LP(x_k, W_{1,k}^2)\). Choose \(d_k \in \{d_k^1, d_k^2\}\) such that
and let \((W_{1,k},W_{2,k}) \in \{(W_{1,k}^1,W_{2,k}^1), (W_{1,k}^2,W_{2,k}^2)\}\) denote the corresponding partition. Next, we define the function \(\varphi _k\) in the following way
Note that the function \(\varphi _k\) coincides with \(\varphi \) for a, b given by (79) with \((W_1,W_2) := (W_{1,k},W_{2,k})\) and \(\omega = (\omega ^{{\mathcal {E}}}, \omega ^{{\mathcal {I}}})\) given by
Proposition 5.2
For all \(x \in \mathbb {R}^n\) it holds that
Proof
Non-negativity of the distance function, together with (20) yield for every \(i \in V, j = 1,2\)
Hence (84) now follows from
\(\square \)
An outline of the extended algorithm is as follows.
Algorithm 5.1
(Solving the MPVC*)
-
1:
Initialization:
-
Select a starting point \(x_0 \in \mathbb {R}^n\) together with a positive definite \(n \times n\) matrix \(B_0\), a parameter \(\rho _0 > 0\) and constants \(\zeta \in (0,1), {\bar{\rho }} > 1\) and \(\mu \in (0,1)\).
-
Select positive penalty parameters \(\sigma _{-1} = (\sigma ^h_{-1}, \sigma ^g_{-1}, \sigma ^F_{-1})\).
-
Set the iteration counter \(k := 0\).
-
-
2:
Correction of the iterate:
-
Set the corrected iterate by \({\tilde{x}}_{k} := x_k\).
-
Take some \((W_{1,k}^1,W_{2,k}^1), (W_{1,k}^2,W_{2,k}^2) \in {\mathcal {P}}(V)\), compute \(d_k^1\) and \(d_k^2\) as solutions of \(LP(x_k, W_{1,k}^1)\) and \(LP(x_k, W_{1,k}^2)\) and let \(d_k\) be given by (82).
-
Consider a sequence of numbers \(\alpha _k^{(1)} = 1, \alpha _k^{(2)}, \alpha _k^{(3)}, \ldots \) with \(1> {\bar{\alpha }} \ge \alpha _k^{(j+1)} / \alpha _k^{(j)} \ge {\underline{\alpha }} > 0\).
-
If \(\nabla f (x_k) d_k < 0\), denote by j(k) the smallest j fulfilling either
$$\begin{aligned} \Phi _k(x_k + \alpha _k^{(j)} d_k) - \Phi _k(x_k)\le & {} \mu \alpha _k^{(j)} \nabla f (x_k) d_k, \end{aligned}$$(85)$$\begin{aligned} \text {or } \qquad \alpha _k^{(j)}\le & {} \frac{\Phi _k(x_k) - \varphi _k(x_k)}{\mu \nabla f (x_k) d_k}. \end{aligned}$$(86)-
If j(k) fulfills (85), set \({\tilde{x}}_{k} := x_k + \alpha _k^{j(k)} d_k\).
-
-
-
3:
Solve the Auxiliary problem:
-
Run Algorithm 3.1 with data \(\zeta , {\bar{\rho }}, \rho := \rho _k, B:=B_k, \nabla f := \nabla f ({\tilde{x}}_k),\) \(h_i := h_i({\tilde{x}}_k), \nabla h_i := \nabla h_i ({\tilde{x}}_k), i \in E,\) etc.
-
If the Algorithm 3.1 stops because of degeneracy, stop the Algorithm 5.1 with an error message.
-
If the final iterate \(s^N\) is zero, stop the Algorithm 5.1 and return \({\tilde{x}}_k\) as a solution.
-
-
4:
Next iterate:
-
Compute new penalty parameters \(\sigma _{k}\).
-
Set \(x_{k+1} := {\tilde{x}}_k + s_k\) where \(s_k\) is a point on the polygonal line connecting the points \(s^0,s^1, \ldots , s^N\) such that an appropriate merit function depending on \(\sigma _{k}\) is decreased.
-
Set \(\rho _{k+1} := \rho \), the final value of \(\rho \) in Algorithm 3.1.
-
Update \(B_{k}\) to get positive definite matrix \(B_{k+1}\).
-
Set \(k := k+1\) and go to step 2.
-
Naturally, Remark 4.1 regarding the stopping criteria for Algorithm 4.1 aplies to this algorithm as well.
Lemma 5.3
Index j(k) is well defined.
Proof
In order to show that j(k) is well defined, we have to prove the existence of some j such that either (85) or (86) is fulfilled. By (84) we know that \(\Phi _k(x_k) - \varphi _k(x_k) \le 0\). In case \(\Phi _k(x_k) - \varphi _k(x_k) < 0\) every j sufficiently large clearly fulfills (86). On the other hand, if \(\Phi _k(x_k) - \varphi _k(x_k) = 0\), taking into account (84) we obtain
However, Lemma 5.2 for \(\nu := \mu \) and \(C:= \{x_k\}\) yields that if \(\nabla f (x_k) d_k < 0\) then there exists some \({\tilde{\alpha }}\) such that
holds for all \(\alpha \in [0,{\tilde{\alpha }}]\) and thus (85) is fulfilled for every j sufficiently large. This finishes the proof. \(\square \)
5.3 Convergence of the extended algorithm
We consider the behavior of the Algorithm 5.1 when it does not prematurely stop and it generates an infinite sequence of iterates
We discuss the convergence behavior under the following additional assumption.
Assumption 2
Let \({\bar{x}}\) be a limit point of the sequence of iterates \(x_k\).
-
1.
Mangasarian-Fromovitz constraint qualification (MFCQ) holds at \({\bar{x}}\) for constraints \(x \in A\), where A is given by (71) and a, b are given by (79) with \((W_1,W_2) := (I^{0+}({\bar{x}}),V \setminus I^{0+}({\bar{x}}))\) or \((W_1,W_2) := (I^{0+}({\bar{x}}) \cup I^{00}({\bar{x}}),V \setminus (I^{0+}({\bar{x}}) \cup I^{00}({\bar{x}})))\).
-
2.
There exists a subsequence \(K({\bar{x}})\) such that \(\lim _{k \mathop \rightarrow \limits ^{K({\bar{x}})} \infty } x_k = {\bar{x}}\) and
$$\begin{aligned} W_{1,k}^1 = I^{0+}({\bar{x}}), \,\, W_{1,k}^2 = I^{0+}({\bar{x}}) \cup I^{00}({\bar{x}}) \text { for all } k \in K({\bar{x}}). \end{aligned}$$
Note that the Next iterate step from Algorithm 5.1 remains almost unchanged compared to the Next iterate step from Algorithm 4.1, we just consider the point \({\tilde{x}}_k\) instead of \(x_k\). Consequently, most of the results from subsections 4.1 and 4.2 remain valid, possibly after replacing \(x_k\) by \({\tilde{x}}_k\) where needed, e.g. in Lemma 4.3. The only exception is the proof of Lemma 4.5, where we have to show that the sequence \(\Phi _k(x_k)\) is monotonically decreasing. This follows now from (85) and hence Lemma 4.5 remains valid as well.
We state now the main result of this section.
Theorem 5.1
Let Assumptions 1 and 2 be fulfilled. Then every limit point of the sequence of iterates \(x_k\) is at least \({\mathcal {Q}}_M\)-stationary for problem (1).
Proof
Let \(\bar{x}\) denote a limit point of the sequence \(x_k\) and let \(K({\bar{x}})\) denote a subsequence from Assumption 2 (2.). Since
we conclude that \(\lim _{k \mathop \rightarrow \limits ^{K({\bar{x}})} \infty } {\tilde{x}}_{k-1} = {\bar{x}}\) and by applying Theorem 4.1 to sequence \({\tilde{x}}_{k-1}\) we obtain the feasibility of \({\bar{x}}\) for problem (1).
Next we consider \({\bar{d}}^1,{\bar{d}}^2\) as in Proposition 5.1 with \(\beta ^1 := \emptyset \) and without loss of generality we only consider \(k \in K({\bar{x}}), k \ge {\bar{k}}\), where \({\bar{k}}\) is given by Lemma 4.4. We show by contraposition that the case \(\min \{ \nabla f ({\bar{x}}) {\bar{d}}^1 , \nabla f ({\bar{x}}) {\bar{d}}^2 \} < 0\) can not occur. Let us assume on the contrary that, say \(\nabla f ({\bar{x}}) {\bar{d}}^1 < 0\). Assumption 2 (2.) yields that \(W_{1,k}^1 = I^{0+}({\bar{x}})\) and feasibility of \({\bar{x}}\) for (1) together with \(I^{0+}({\bar{x}}) \subset W_{1,k}^1 \subset I^{0}({\bar{x}})\) imply \({\bar{x}} \in A\) for A given by (71) and a, b given by (79) with \((W_1,W_2) := (W_{1,k}^1,W_{2,k}^1)\). Taking into account Assumption 2 (1.), Lemma 5.1 then yields that for \(\epsilon := - \nabla f({\bar{x}}) {\bar{d}}^1 /2 > 0\) there exists \(\delta \) such that for all \(\Vert x_k - {\bar{x}} \Vert \le \delta \) we have \(\nabla f(x_k) d_k \le \nabla f(x_k) d_k^1 \le \nabla f({\bar{x}}) {\bar{d}}^1 /2 = - \epsilon \), with \(d_k\) given by (82).
Next, we choose \({\hat{k}}\) to be such that for \(k \ge {\hat{k}}\) it holds that \(\Vert x_k - {\bar{x}} \Vert \le \delta \) and we set \(\nu := (1 + \mu )/2, C:= \{x \,\vert \,\Vert x - {\bar{x}} \Vert \le \delta \}\). From Lemma 5.2 we obtain that
holds for all \(\alpha \in [0,{\tilde{\alpha }}]\). Moreover, by choosing \({\hat{k}}\) larger if necessary we can assume that for all \(i \in V\) we have
For the partition \((W_{1,k},W_{2,k}) \in \{(W_{1,k}^1,W_{2,k}^1), (W_{1,k}^2,W_{2,k}^2)\}\) corresponding to \(d_k\) it holds that \(I^{0+}({\bar{x}}) \subset W_{1,k} \subset I^{0}({\bar{x}})\) and this, together with the feasibility of \({\bar{x}}\) for (1), imply \(F_i({\bar{x}}) \in P^j, i \in W_{j,k}\) for \(j=1,2\). Therefore, taking into account (22), we obtain
Consequently, (84) and (88) yield for all \(\alpha > {\underline{\alpha }} {\tilde{\alpha }}\)
Thus, from (87) and (84) we obtain for all \(\alpha \in ({\underline{\alpha }} {\tilde{\alpha }},{\tilde{\alpha }}]\)
Now consider j with \(\alpha _k^{(j-1)} > {\tilde{\alpha }} \ge \alpha _k^{(j)}\). We see that \(\alpha _k^{(j)} \in ({\underline{\alpha }} {\tilde{\alpha }},{\tilde{\alpha }}]\), since \(\alpha _k^{(j)} \ge {\underline{\alpha }} \alpha _k^{(j-1)} > {\underline{\alpha }} {\tilde{\alpha }}\) and consequently j fulfills (85) and violates (86). However, then we obtain for all \(k \ge {\hat{k}}\)
a contradiction.
Hence it follows that the solutions \({\bar{d}}^1,{\bar{d}}^2\) fulfill \(\min \{ \nabla f ({\bar{x}}) {\bar{d}}^1 , \nabla f ({\bar{x}}) {\bar{d}}^2 \} = 0\) and by Proposition 5.1 we conclude that \({\bar{x}}\) is \({\mathcal {Q}}\)-stationary with respect to \((\emptyset ,I^{00}({\bar{x}}))\) and consequently also \({\mathcal {Q}}_M\)-stationary for problem (1). \(\square \)
Finally, we discuss how to choose the partitions \((W_{1,k}^1,W_{2,k}^1)\) and \((W_{1,k}^2,W_{2,k}^2)\) such that Assumption 2 (2.) will be fulfilled. Let us consider a sequence of nonnegative numbers \(\epsilon _k\) such that for every limit point \({\bar{x}}\) with \(\lim _{k \mathop \rightarrow \limits ^{K} \infty } x_k = {\bar{x}}\) it holds that
and let us define
Proposition 5.3
For \(W_{1,k}^1\) and \(W_{1,k}^2\) defined by \(W_{1,k}^1 := {\tilde{I}}^{0+}_k\) and \(W_{1,k}^1 := {\tilde{I}}^{0+}_k \cup {\tilde{I}}^{00}_k\) the Assumption 2 (2.) is fulfilled.
Proof
Let \({\bar{x}}\) be a limit point of the sequence \(x_k\) such that \(\lim _{k \mathop \rightarrow \limits ^{K} \infty } x_k = {\bar{x}}\). Recall that \(\mathcal {F}\) is given by (8) and let us set \(L := \max _{\Vert x - {\bar{x}} \Vert _{\infty } \le 1} \Vert \nabla \mathcal {F}(x) \Vert _{\infty }\), where \(\Vert \nabla \mathcal {F}(x) \Vert _{\infty }\) is given by (72). Further, taking into account (89), consider \({\hat{k}}\) such that for all \(k \ge {\hat{k}}\) it holds that \(\Vert x_k - {\bar{x}} \Vert _{\infty } \le \min \left\{ \epsilon _k / L,1 \right\} \). Hence, for all \(k \in K\) with \(k \ge {\hat{k}}\) we conclude
Now consider \(i \in I^{0+}({\bar{x}})\), i.e. \(H_i({\bar{x}}) = 0 < G_i({\bar{x}})\). By choosing \({\hat{k}}\) larger if necessary we can assume that for all \(k \ge {\hat{k}}\) it holds that \(\epsilon _k < G_i({\bar{x}})/2\) and consequently, taking into account (90), for all \(k \in \{k \in K \,\vert \,k \ge {\hat{k}}\}\) we have
showing \(i \in {\tilde{I}}^{0+}_k\). By similar argumentation and by increasing \({\hat{k}}\) if necessary we obtain that for all \(k \in \{k \in K \,\vert \,k \ge {\hat{k}}\} =: K({\bar{x}})\) it holds that
However, feasibility of \({\bar{x}}\) for (1) yields
and the index sets \({\tilde{I}}^{0+}_k, {\tilde{I}}^{00}_k, {\tilde{I}}^{0-}_k, {\tilde{I}}^{+0}_k, {\tilde{I}}^{+-}_k\) are pairwise disjoint subsets of V by definition. Hence we claim that (91) must in fact hold with equalities. Indeed, e.g.
This finishes the proof. \(\square \)
Note that if we assume that there exist a constant \(L > 0\), a number \(N \in \mathbb {N}\) and a limit point \({\bar{x}}\) such that for all \(k \ge N\) it holds that
by setting \(\epsilon _k := \sqrt{\Vert x_{k} - x_{k-1} \Vert _{\infty }}\) we obtain (89), since
6 Numerical results
Algorithm 4.1 was implemented in MATLAB. To perform numerical tests we used a subset of test problems considered in the thesis of Hoheisel [7].
First we considered the so-called academic example
As in [7], we tested 289 different starting points \(x^0\) with \(x^0_1,x^0_2 \in \{-5,-4,\ldots ,10,20 \}\). For 84 starting points our algorithm found a global minimizer (0, 0) with objective value 0, while for the remaining 205 starting points a local minimizer (0, 5) with objective value 10 was found. Hence, convergence to the perfidious candidate \((0,5 \sqrt{2})\), which is not a local minimizer, did not occur (see [7]).
Expectantly, after adding constraint \(3 - x_1 - x_2 \le 0\) to the model (92), to artificially exclude the point (0, 0), unsuitable for the practical application, we reached the point (0, 5), now a global minimizer. For more detailed information about the problem we refer the reader to [7] and [2].
Next we solved 2 examples in truss topology optimization, the so called Ten-bar Truss and Cantilever Arm. The underlying model for both of them is as follows:
Here the matrix K(a) denotes the global stiffness matrix of the structure a and the vector \(f \in \mathbb {R}^d\) contains the external forces applying at the nodal points. Further, for each i the function \(\sigma _i(a,u)\) denotes the stress of the \(i-\)th potential bar and \(c, {\bar{a}}_i, {\bar{\sigma }}\) are positive constants. Again, for more background of the model and the following truss topology optimization problems we refer to [7].

Ten-bar Truss example
In the Ten-bar Truss example we consider the ground structure depicted in Fig. 1a consisting of \(N = 10\) potential bars and 6 nodal points. We consider a load which applies at the bottom right hand node pulling vertically to the ground with force \(\Vert f \Vert = 1\). The two left hand nodes are fixed, and hence the structure has \(d = 8\) degrees of freedom for displacements.
We set \(c := 10, {\bar{a}} := 100\) and \({\bar{\sigma }} := 1\) as in [7] and the resulting structure consisting of 5 bars is shown in Fig. 1b and is the same as the one in [7]. For comparison, in the following table we show the full data containing also the stress values.
i | \(a_i^*\) | \(\sigma _i(a^*,u^*)\) | \(u_i^*\) |
|---|---|---|---|
1 | 0 | 1.029700000000000 | −1.000000000000000 |
2 | 1.000000000000000 | 1.000000000000000 | 1.000000000000000 |
3 | 0 | 1.119550000000000 | −2.000000000000000 |
4 | 1.000000000000000 | 1.000000000000000 | 1.302400000000000 |
5 | 0 | 0.485150000000000 | −1.970300000000000 |
6 | 1.414213562373095 | 1.000000000000000 | −3.000000000000000 |
7 | 0 | 0.302400000000000 | −8.000000000000000 |
8 | 1.414213562373095 | 1.000000000000000 | −6.511800000000000 |
9 | 2.000000000000000 | 1.000000000000000 | \(f^T u^* = 8\) |
10 | 0 | 1.488200000000000 | \(V^*= 8.000000000000002\) |
We can see that although our final structure and optimal volume are the same as the final structure and the optimal volume in [7], the solution \((a^*,u^*)\) is different. For instance, since \(f^T u^* = 8 < 10 = c\), our solution does not reach the maximal compliance. Similarly as in [7], we observe the effect of vanishing constraints since the stress values from the table show that

Cantilever Arm example
In the Cantilever Arm example we consider the ground structure depicted in Fig. 2a consisting of \(N = 224\) potential bars and 27 nodal points. Again, we consider a load acting at the bottom right hand node pulling vertically to the ground with force \(\Vert f \Vert = 1\). Now the three left hand nodes are fixed, and hence \(d = 48\).
We proceed as in [7] and we first set \(c := 100, {\bar{a}} := 1\) and \({\bar{\sigma }} := 100\). The resulting structure consisting of only 24 bars (compared to 38 bars in [7]) is shown in Fig. 2b. Similarly as in [7], we have \(\max _{1 \le i \le N} a_i^{*1} = {\bar{a}}\) and \(f u^{*1} = c\). On the other hand, our optimal volume \(V^{*1} = 23.4407\) is a bit larger than the optimal volume 23.1399 in [7]. Also, analysis of our stress values shows that

and hence, although it holds true that both absolute stresses as well as absolute ”fictitious stresses” (i.e., for zero bars) are small compared to \({\bar{\sigma }}\) as in [7], the difference is that in our case they are not the same.
The situation becomes more interesting when we change the stress bound to \({\bar{\sigma }}= 2.2\). The obtained structure consisting again of only 25 bars (compared to 37 or 31 bars in [7]) is shown in Fig. 2c. As before we have \(\max _{1 \le i \le N} a_i^{*2} = {\bar{a}}\) and \(f u^{*2} = c\). Our optimal volume \(V^{*2} = 23.6982\) is now much closer to the optimal volumes 23.6608 and 23.6633 in [7]. Similarly as in [7], we clearly observe the effect of vanishing constraints since our stress values show
Finally, we obtained 32 bars (in contrast to 24 bars in [7]) satisfying both
To better demonstrate the performance of our algorithm we conclude this section by a table with more detailed information about solving Ten-bar Truss problem and 2 Cantilever Arm problems (CA1 with \({\bar{\sigma }} := 100\) and CA2 with \({\bar{\sigma }} := 2.2\)). We use the following notation.
Problem | Name of the test problem |
|---|---|
(n, q) | Number of variables, number of all constraints |
\(k^*\) | Total number of outer iterations of the SQP method |
\((N_0, \ldots , N_{k^*-1})\) | Total numbers of inner iterations corresponding to each outer iteration |
\(\sum _{k=0}^{k^*-1}j(k)\) | Overall sum of steps made during line search |
\(\sharp f_{eval}\) | Total number of function evaluations, \(\sharp f_{eval} = k^* + \sum _{k=0}^{k^*-1}j(k)\) |
\(\sharp \nabla f_{eval}\) | Total number of gradient evaluations, \(\sharp \nabla f_{eval} = k^*+1\) |
Problem | (n, q) | \(k^*\) | \((N_0, \ldots , N_{k^*-1})\) | \(\sum _{k=0}^{k^*-1}j(k)\) | \(\sharp f_{eval}\) | \(\sharp \nabla f_{eval}\) |
|---|---|---|---|---|---|---|
Ten-bar Truss | (18, 39) | 14 | \((1, \ldots , 1, 2, 2, 2, 2, 1, 1)\) | 67 | 81 | 15 |
CA1 | (272, 721) | 401 | \((1, \ldots , 1)\) | 401 | 802 | 402 |
CA2 | (272, 721) | 1850 | \((1, \ldots , 1)\) | 1850 | 3700 | 1851 |
References
Achtizger, W., Kanzow, C.: Mathematical programs with vanishing constraints: optimality conditions and constraint qualifications. Math. Program. 114, 69–99 (2008)
Achtizger, W., Hoheisel, T., Kanzow, C.: A smoothing-regularization approach to mathematical programs with vanishing constraints. Comput. Optim. Appl. 55, 733–767 (2013)
Achtizger, W., Kanzow, C., Hoheisel, T.: On a relaxation method for mathematical programs with vanishing constraints. GAMM-Mitt. 35, 110–130 (2012)
Benko, M., Gfrerer, H.: An SQP method for mathematical programs with complementarity constraints with strong convergence properties. Kybernetika 52, 169–208 (2016)
Benko, M., Gfrerer, H.: On estimating the regular normal cone to constraint systems and stationary conditions. Optimization 66(1), 61–92 (2017)
Fukushima, M., Pang, J .S.: Convergence of a smoothing continuation method for mathematical programs with complementarity constraints. In: Théra, M., Tichatschke, R. (eds.) Ill-Posed Variational Problems and Regularization Techniques. Lecture Notes in Economics and Mathematical Systems. Springer, Berlin (1999)
Hoheisel, T.: Mathematical programs with vanishing constraints. Dissertation, Department of Mathematics, University of Würzburg (2009)
Izmailov, A.F., Solodov, M.V.: Mathematical programs with vanishing constraints: optimality conditions, sensitivity, and a relaxation method. J. Optim. Theory Appl. 142, 501–532 (2009)
Robinson, S.M.: Stability theory for systems of inequalities, part II: differentiable nonlinear systems. SIAM J. Numer. Anal. 13, 497–513 (1976)
Scholtes, S.: Convergence properties of a regularization scheme for mathematical programs with complementarity constraints. SIAM J. Optim. 11, 918–936 (2001)
Acknowledgements
Open access funding provided by Austrian Science Fund (FWF). This work was supported by the Austrian Science Fund (FWF) under Grant P 26132-N25.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Benko, M., Gfrerer, H. An SQP method for mathematical programs with vanishing constraints with strong convergence properties. Comput Optim Appl 67, 361–399 (2017). https://doi.org/10.1007/s10589-017-9894-9
Received:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10589-017-9894-9
Keywords
- SQP method
- Mathematical programs with vanishing constraints
- \({\mathcal {Q}}\)-stationarity
- \({\mathcal {Q}}_M\)-stationarity