
Abstract
Sea-level rise is a key driver of projected flooding risks. The design of strategies to manage these risks often hinges on projections that inform decision-makers about the surrounding uncertainties. Producing semi-empirical sea-level projections is difficult, for example, due to the complexity of the error structure of the observations, such as time-varying (heteroskedastic) observation errors and autocorrelation of the data-model residuals. This raises the question of how neglecting the error structure impacts hindcasts and projections. Here, we quantify this effect on sea-level projections and parameter distributions by using a simple semi-empirical sea-level model. Specifically, we compare three model-fitting methods: a frequentist bootstrap as well as a Bayesian inversion with and without considering heteroskedastic residuals. All methods produce comparable hindcasts, but the parametric distributions and projections differ considerably based on methodological choices. Our results show that the differences based on the methodological choices are enhanced in the upper tail projections. For example, the Bayesian inversion accounting for heteroskedasticity increases the sea-level anomaly with a 1% probability of being equaled or exceeded in the year 2050 by about 34% and about 40% in the year 2100 compared to a frequentist bootstrap. These results indicate that neglecting known properties of the observation errors and the data-model residuals can lead to low-biased sea-level projections.
Similar content being viewed by others


1 Introduction
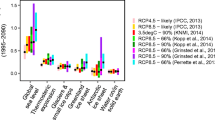
Anthropogenic greenhouse gas emissions are causing sea-level rise (SLR) (Church and White 2006; Jevrejeva et al. 2008). Because of the impacts SLR has on coastal flood risks (McGranahan et al. 2007; Houston 2013; Spanger-Siegfried et al. 2014), many studies focus on resolving future sea-level projections (e.g., Rahmstorf 2007; Grinsted et al. 2010; Church et al. 2013; Moore et al. 2013; Kopp et al. 2014, 2016). However, many of these studies generate ranges in projections that vary from study to study (Fig. SI 11) as they differ in methodology, model approach, and assumptions (Bakker et al. 2016).
Routinely, sea-level projections are constructed using both process-based and semi-empirical model approaches (e.g., Church et al. 2013; Moore et al. 2013). Process-based models of SLR describe the system of interest in the greatest detail available and are thus complex (Church et al. 2013). In contrast, semi-empirical models are typically simple models that trade off completeness (i.e., physical realism) for computational speed and calibration efficiency (e.g., Rahmstorf 2007; Grinsted et al. 2010; Moore et al. 2013). In both cases, projections rely heavily on assumptions, e.g., about the statistical model used for model fitting or lack of representing physical processes.
Key statistical challenges in projecting SLR include (i) the importance of interdependent (autocorrelated) data-model residuals, (ii) the representation of non-constant (heteroskedastic) observation errors, and (iii) tail probabilities far beyond the 90% credible interval (Von Storch 1995; Zellner and Tiao 1964; Ricciuto et al. 2008). Another issue includes spatial aggregation of the data (see, for example, Kopp et al. 2016). In recent years, studies have accounted for the complex error structure of the data including the heteroskedastic nature of the observation errors (Kemp et al. 2011; Kopp et al. 2016) because it is presumed that neglecting these properties of the observations and uncertainties can potentially lead to overconfidence (e.g., Zellner and Tiao 1964; Ricciuto et al. 2008; Donald et al. 2013). This quantitatively raises the question of how large the effect that neglecting or assuming too simple of an error structure is on projections, especially the upper tail projections.
Here, we quantify how explicitly accounting for autocorrelation and heteroskedastic residuals affects SLR projections (especially in the upper tail). We choose to use a semi-empirical sea-level model in our didactic analysis for two reasons: (1) calibration efficiency and (2) their use in informing risk-and-decision analyses (for example, Heberger et al. 2009; Dalton et al. 2010; Neumann et al. 2011; Dibajnia et al. 2012; McInnes et al. 2013). In our analysis, we implement a hierarchical model with a process-level model characterized by the Vermeer and Rahmstorf (2009) sea-level model (Eq. 1) and a data-level model (Eq. 2) where we fit the model in three different ways to the observational data (section 2). Additionally, we run the same analysis on two simpler models to assess the robustness of the conclusions (results in the SI). In section 3, we present the differences among the approaches, and in section 4, we discuss how our results can inform future sea-level projections.
2 Method
2.1 Sea-level model, observational data, and input data for projections
As described above, we adopt a semi-empirical model that predicts SLR on an annual time-step (Vermeer and Rahmstorf 2009):
where α is the sensitivity of the rate of SLR to temperature, T is the global mean surface air temperature, T 0 is the temperature when the sea-level anomaly equals zero, b is a constant corresponding to a rapid response term, H is the global mean sea-level, and t is time. We slightly expand on the model-fitting setup by including the initial value of SLR, H 0 , as an uncertain parameter (prior bounds based on measurement error; Church and White 2006). We use the global mean sea-level estimates, based on tide-gauge observations, of Church and White (2006). The sea-level anomalies are referenced to the average sea level from the 1980 to 2000 period. We use historical temperature anomalies (with respect to the twentieth century; Smith et al. 2008) for the model-fitting process. When the model is used in SLR projection mode, we use global-mean surface air temperature anomalies based on the CNRM-CM5 simulation of the RCP 8.5 scenario (Meinshausen et al. 2011; Riahi et al. 2011) as obtained from the CMIP5 model output archive (http://cmip-pcmdi.llnl.gov/cmip5/). As in Vermeer and Rahmstorf (2009), we apply the same smoothing process to estimate the rate of temperature.
2.2 Analyzed model-fitting methods
We compare parameter estimates and the SLR projections based on three model-fitting methods: a Bootstrap method (Solow 1985), a Bayesian method assuming homoskedastic errors, and a Bayesian method accounting for the time dependent (heteroskedastic) nature of the observation errors (details of the three methods are in the SI) (Zellner and Tiao 1964; Gilks 1997). The methods are described in detail in the SI. Here, we provide a brief overview. The methods approximate the observation dataset as the sum of the model output plus a residual term:
where the f(θ,t) (or H(t)) defines the portion of global mean sea-level related to temperature by the semi-empirical model and y t describe the noisy observations including the variability not explained by the semi-empirical model and the observational error. The model error accounts for effects such as unresolved internal variability or other structural errors. The observational error (often also referred to as measurement error) is the difference between a measured value (i.e., estimated global mean sea-level anomalies) and the true value. The residuals are the sum of the model error ωt and observational error εt:
Therefore, \( \overrightarrow{\omega}=\left({\omega}_1, \dots,\ {\omega}_N\right) \) is a time series from a multivariate normal distribution with variance \( {\upsigma}_{\mathrm{AR}1}^2 \) and the correlation structure given by the first-order autoregressive parameter ρ (this model is also recognized as AR1). The observational errors are given by the global mean sea-level data. In principle, they should be treated as correlated (see, for example, the Church and White (2006) analysis). However, for simplicity, we approximate the observational errors as uncorrelated.
Following the Bootstrap method implemented in Lempert et al. (2012), we fit the model according to the least absolute residual method and approximate the data-model residuals using a first-order autoregressive model assuming homoskedastic observational errors. The resulting residuals are superimposed to the original fit. Parameters are then re-estimated from the Bootstrap realizations. This method estimates parameters without the use of priors. For the two Bayesian methods, we estimate the posterior density using a Markov Chain Monte Carlo method and the Metropolis Hastings algorithm (Metropolis et al. 1953; Zellner and Tiao 1964; Hastings 1970; Gilks 1997; Vihola 2012). Both Bayesian methods approximate the residuals as normally distributed with zero mean. The homoskedastic method and the Bootstrap method assume the variance of the observational errors σε 2 to be constant in time, whereas the heteroskedastic method accounts for the time-varying observational error (Fig. 1). All three methods retain the autocorrelation structure of the residuals (Fig. 1). The Bootstrap method approximates the autoregression coefficient ρ with the most likely value, while the Bayesian methods account for uncertainty in the autocorrelation (as well as in the white noise variance \( {\upsigma}_{\mathrm{AR}1}^2 \)). All three methods use the same annual mean temperature and sea-level data covering the time period of 1880 to 2002.

Stochastic properties of the model residuals and observational errors in the global mean sea-level record. a Displays the residuals (observations—best-fit model simulation derived by differential evolution optimization). b Shows the observational errors are time-dependent. c Displays the autocorrelation coefficient for the residuals. When the vertical lines at the time lags exceed the dashed blue line (95% significance), then the residuals are considered to be statistically autocorrelated
2.3 Method implementation
We implement a hierarchal model with a process-level model characterized by Eq. 1 and a data-level model characterized by Eq. 2. The Bayesian methods use uniform prior distributions for the physical model parameters (θ, including α, T 0 , H 0 , b) and the statistical model parameters (σAR1 and ρ) (Table 1). In the Bayesian (homoskedastic) approach, the observation errors are set to zero (merging the model error and observational error into one term) to represent the homoskedastic assumption. In the heteroskedastic Bayesian approach, the errors are set to the reported values (Zellner and Tiao 1964). We use 2∙104 (Bootstrap), 5∙106 (homoskedastic Bayesian), and 3∙106 (heteroskedastic Bayesian) iterations. For the Bayesian methods, we remove a 2% initial “burn-in” from the Markov chains (Gilks 1997). Additionally, we thin the chains in the Bayesian methods to subsets of 2∙104 for the analysis. To assess convergence, we use (i) visual inspection and (ii) the potential scale reduction factor (Gelman and Rubin 1992; Gilks 1997). Furthermore, we test the sea-level hindcasts from each method for reliability based on the reliability diagram and surprise index (see SI for details). A reliability diagram is a graph of the observed frequency (or the fraction of observations) that is covered by the hindcast credible interval versus the forecast probability. The surprise index is the deviation between the observed frequency and the forecast probability. The hindcasts and projections display the 90% confidence interval (Bootstrap) and the 90% credible interval (Bayesian methods) for comparison to other sea-level studies (comparison shown in Fig. SI. 11; for simplicity, we refer to these intervals as credible intervals in the remainder of this paper). The main conclusions are not sensitive to the random seed applied (tested with five seeds for each method) and not sensitive to the choice of SLR model applied (analysis run with Rahmstorf (2007) and the Grinsted et al. (2010) model; details shown in the SI).
3 Results
3.1 Stochastic structure of sea-level observations
Accounting for the stochastic structure of sea-level observations can be important in hindcasting and projecting sea level (see Fig. 1). Sea-level observation errors vary through time (Fig. 1b). For example, the error estimates of global sea level generally decrease with time due to effects of improved measurement techniques and more frequent observations. By specifying the heteroskedastic observation error, the model-fitting method can account for years when measurements are less or more certain. Moreover, sea-level residuals are autocorrelated because deviations from the main trend often impact sea-level anomalies in the following years (Fig. 1c; the importance of autocorrelation representation is tested by performing a perfect model experiment in the SI, Fig. SI. 1). For example, the climate system is known for its many multi-year oscillations (such as the El Niño-Southern Oscillation (ENSO); Boening et al. 2012; Cazenave et al. 2012) that can cause long-term deviations of the observations from the long-term global sea-level trend (Rietbroek et al. 2016). These multi-year oscillations are often not well represented in the models, leading to structural model errors. Testing the observations and the model residuals for these properties is important, because they can impact the choice of the model-fitting method, parameter estimates, and projections.
3.2 Model evaluation and parameter uncertainty
The considered methods produce similar hindcasts and reliability diagrams, but different parameter distributions (Figs. 2 and 3; (nb: median fits are shown in Fig. SI. 10)). The methods predict well at low to intermediate credible intervals, yet perform relatively poorly at the high credible intervals (i.e., >90% credible level; the SI describes simple tests and results of investigating potential causes for poor performance, Fig. SI. 1–3) (Fig. 2b). Despite the arguably poor performance, each method produces a small average deviation from perfect reliability; this concept is known as the surprise index (Fig. 2b). The average surprise index for the Bootstrap, homoskedastic Bayesian, and heteroskedastic Bayesian methods are 2–7%. Choosing different methods causes differences in the estimated modes and tails of the model parameters (Fig. 3; Table 1). As we account for more known observational properties (i.e., moving from Bootstrap to homoskedastic Bayesian to heteroskedastic Bayesian), the distributions widen, the modes shift, and the tail areas increase for each parameter (Fig. 3; Table 1).

Comparison of sea-level rise hindcasts and projections and the reliability diagram. a, c, d Display the 90% credible interval for each method along with the synthesized observations (points) and their associated measurement error (Church and White 2006). The color ramp from light green to dark blue represents accounting for more known observational properties (Bootstrap to homoskedastic Bayesian to heteroskedastic Bayesian). b The reliability diagram analyzes the hindcast credible intervals produced from each method from 10 to 100% in increments of 10. If the method produces perfectly reliable credible intervals, then the points will plot on a 1:1 line (displayed as a dashed line) representing neither over—nor—underconfidence. b The subplot zooms in on the credible intervals from 90 to 100%

Marginal probability density functions of the estimated model and statistical parameters. Shown are (α) sensitivity of sea-level to changes in temperature (a), (T 0 ) the equilibrium temperature (c), (b) a constant referring to a rapid response term (c), (H 0 ) the initial sea-level anomaly in the year 1880 (d), and (ρ) autoregression coefficient (e). The dashed lines are the prior parameter distribution used in the Bayesian methods. The prior distribution is not shown for parameters α and b because the prior is far larger than the posterior distribution
3.3 Comparison of low probability sea-level estimates
The choice of model-fitting method and associated parameter uncertainty considerably impacts the probability density functions, and especially the upper tail-area estimates, of the SLR projections (Figs. 2 and 4). The projected 90% probability ranges in 2050 differ by up to 0.11 m; Bootstrap (0.23–0.33 m), homoskedastic Bayesian (0.19–0.32 m), to heteroskedastic Bayesian (0.14–0.35 m) (Fig. 2c). Depending on the choice of model-fitting method, the projected sea-level anomaly with a 1% (10−2) probability of being equaled or exceeded in the year 2050 (compared to the 1980–2000 period) varies from 0.35 to 0.46 m (Fig. 4e). The heteroskedastic Bayesian method gives a roughly 34% larger sea-level anomaly (associated with the 1% probability) in the year 2050 compared to the sea-level anomaly produced by the Bootstrap method. In 2100, the sea-level anomaly produced by the heteroskedastic Bayesian method with a 1% probability of being equaled or exceeded (1.49 m) differs from the Bootstrap method sea-level anomaly (1.07 m) by 0.42 m; this difference corresponds to a 40% increase (Fig. 4f).

Projections for global mean sea-level rise in 2050 (a, c, e) and 2100 (b, d, f) determined for the different methods presented as the probability density function (a, b), the cumulative density function (c, d), and the survival function (e, f). The horizontal dashed lines in the survival function represent the 1% (10−2) probability used in example studies to design sea-level rise adaptation strategies (IWR 2011; Houston 2013)
The differences in the SLR projections and parameter distributions can be traced back to assumptions embedded in the model-fitting methods. The Bootstrap method neglects uncertainty in the autocorrelation coefficient, neglects the heteroskedastic nature of the observational errors, and is not informed by priors. The homoskedastic Bayesian method still neglects the heteroskedastic nature of the observational errors, but accounts for uncertainty about the autocorrelation coefficient. Lastly, the heteroskedastic Bayesian method best represents the error structure as it accounts for the heteroskedastic nature of the observation errors and uncertainty about the autocorrelation coefficient.
4 Discussion and conclusion
Semi-empirical SLR models have been used to project sea-level changes (e.g., Rahmstorf 2007; Grinsted et al. 2010; Church et al. 2013; Moore et al. 2013) and inform risk-and-decision analysis (e.g., Heberger et al. 2009; Dalton et al. 2010; Neumann et al. 2011; Dibajnia et al. 2012; McInnes et al. 2013). Here, we present results using a simple sea-level model (i.e., sea level responds only to changes in temperature) to quantify the effects of neglecting known observational properties (i.e., autocorrelated and heteroskedastic residuals). We have chosen a simple (and therefore transparent) framework to demonstrate how neglecting such properties leads to overconfident projections, which can impact how sea-level projections inform risk-and-decision analyses.
The performance of the model-fitting methods could be further analyzed using methods other than reliability diagrams and surprise indices (e.g., Brier 1950; Runge et al. 2016). Given the poor performance at the low probability estimates, extending the temperature and sea-level data with paleo-reconstructions (Hegerl et al. 2006; Kopp et al. 2016) could potentially improve underconfidence in the upper tails (the SI details this effect using a perfect model experiment, Fig. SI. 2). Additionally, this study could be extended to assess the impacts of neglecting error structure has on historical extremes or particular regions and comparing the results to previous studies (e.g., Kopp et al. 2014 and Menendez et al. 2009). Lastly, this study is silent on the impacts of measurement error in temperatures and only considers a single sea-level and temperature reconstruction to isolate the effects of autocorrelated and heteroskedastic residuals. Using different reconstructions and accounting for temperature measurement error would impact estimated parameters and projection probabilities (the SI details the impact different temperature scenarios have on probabilistic projections; Fig. SI. 12 and 13) (Kopp et al. 2016).
Given the caveats, we show that projections are overconfident when the process model neglects autocorrelation and accounts for too simple of an error structure. By considering known observational properties (i.e., heteroskedastic and autocorrelated data-model residuals), the parameter distributions widen and the upper tails increase. Moreover, we show that these effects are enhanced in the upper tail projections. For example, accounting for known observational properties increase the projected sea-level anomaly with a 1% probability of being equaled or exceeded in the year 2050 and the year 2100 (compared to the 1980–2000 period) by roughly 34 and 40%, respectively. This assessment demonstrates how neglecting known properties of the residuals can lead to low-biased sea-level projections and associated flood risk estimates.
References
Bakker AMR, Louchard D, Keller, K (2016) Sources and implications of deep uncertainties surrounding sea-level projections. Clim Change (accepted)
Boening C, Willis JK, Landerer FW, Nerem RS, Fasullo J (2012) The 2011 La Niña: so strong, the oceans fell. Geophys Res Lett 39(19), L19602. doi:10.1029/2012GL053055
Brier (1950) Verification of forecasts expressed in terms of probability. Mon Weather Rev 78:1–3. doi:10.1175/1520-0493(1950)078<0001:VOFEIT>2.0.CO;2
Cazenave A, Henry O, Munier S, Delcroix T, Gordon AL, Meyssignac B, Llovel W, Palanisamy H, Becker M (2012) Estimating ENSO influence on the global mean sea level, 1993–2010. Mar Geod 35:82–97. doi:10.1080/01490419.2012.718209
Church JA, White NJ (2006) A 20th century acceleration in global sea-level rise. Geophys Res Lett 33(1), L01602. doi:10.1029/2005GL024826
Church JA, Clark PU, Cazenave A, Gregory J, Jevrejeva S, Levermann A, Merrifield M, Milne G, Nerem R, Nunn P, Payne A, Pfeffer W, Stammer D, Unnikrishnan A (2013) Sea level change. In: Stocker TF, Qin D, Plattner GK, Tignor M, Allen SK, Boschung J, Nauels A, Xia Y, Bex V, Midgley PM (eds) Climate change 2013: the physical science basis. Contribution of working group I to the fifth assessment report of the Intergovernmental Panel on Climate Change. Cambridge University Press, Cambridge, pp 1137–1216. doi:10.1017/CBO9781107415324.026
Dalton JC, Brown TA, Pietrowsky RA, White KD, Olsen JR, Arnold JR, Giovannettone JP, Brekke LD, Raff DA (2010) US Army Corps of Engineers approach to water resources climate change adaptation. In: Linkov I, Bridges TS (eds) Climate: global change and local adaptation. Springer, Dordrecht, pp 401–417
Dibajnia M, Soltanpour M, Vafai F, Jazayeri Shoushtari SMH, Kebriaee A (2012) A shoreline management plan for Iranian coastlines. Ocean Coast Manag 63:1–15. doi:10.1016/j.ocecoaman.2012.02.012
Donald TR, Irish JL, Westerink JJ, Powell NJ (2013) The effect of uncertainty on estimates of hurricane surge hazards. Nat Hazards 66:1443–1459. doi:10.1007/s11069-012-0315-1
Gelman A, Rubin DB (1992) Inference from iterative simulation using multiple sequences. Stat Sci 7:457–472. doi:10.1214/ss/1177011136
Gilks WR (1997) Markov chain Monte Carlo in practice. Chapman & Hall/CRC, London, UK
Grinsted A, Moore JC, Jevrejeva S (2010) Reconstructing sea level from paleo and projected temperatures 200 to 2100 A.D. Clim Dyn 34(4):461–472. doi:10.1007/s00382-008-0507-2
Hastings WK (1970) Monte Carlo sampling methods using Markov chains and their applications. Biometrika 57(1):97–109. doi:10.1093/biomet/57.1.97
Heberger M, Cooley H, Herrera P, Gleick PH, Moore E (2009) The impacts of sea-level rise on the California coast. California Climate Change Center CEC-500-2009-014-F
Hegerl GC, Crowley TJ, Hyde WT, Frame DJ (2006) Climate sensitivity constrained by temperature reconstructions over the past seven centuries. Nature 440(7087):1029–1032. doi:10.1038/nature04679
Houston J (2013) Methodology for combining coastal design-flood levels and sea-level rise projections. J Waterw Port Coast Ocean Eng 139(5):341–345. doi:10.1061/(ASCE)WW.1943-5460.0000194
IWR (2011) Flood risk management approaches: as being practiced in Japan, Netherlands, United Kingdom, and United States. United States Army Corps of Engineers Institute for Water Resources (IWR) IWR-2011-R-08
Jevrejeva S, Moore JC, Grinsted A, Woodworth PL (2008) Geophys Res Lett 35, L08715. doi:10.1029/2008GL033611
Kemp AC, Horton BP, Donnelly JP, Mann ME, Vermeer M, Rahmstorf S (2011) Climate related sea-level variations over the past two millennia. Proc Natl Acad Sci USA 108(27):11017–11022. doi:10.1073/pnas.1015619108
Kopp RE, Horton RM, Little CM, Mitrovica JX, Oppenheimer M, Rasmussen DJ, Strauss BH, Tebaldi C (2014) Probabilistic 21st and 22nd century sea-level projections at a global network of tide-gauge sites. Earths Future 2(8):383–406. doi:10.1002/2014EF000239
Kopp RE, Kemp AC, Bittermann K et al (2016) Temperature-driven global sea-level variability in the Common Era. Proc Natl Acad Sci USA 113(11):E1434–E1441. doi:10.1073/pnas.1517056113
Lempert R, Sriver R, Keller K (2012) Characterizing uncertain sea level rise projections to support infrastructure investment decisions. California Energy Commission, CEC-500-2012-056
McGranahan G, Balk D, Anderson B (2007) The rising tide: assessing the risks of climate change and human settlements in low elevation coastal zones. Environ Urban 19(1):17–37. doi:10.1177/0956247807076960
McInnes KL, Macadam I, Hubbert G, O’Grady J (2013) An assessment of current and future vulnerability to coastal inundation due to sea-level extremes in Victoria, southeast Australia. Int J Climatol 33(1):33–47. doi:10.1002/joc.3405
Meinshausen M, Smith SJ, Calvin K, Daniel JS, Kainuma M, Lamarque J, Matsumoto K, Montzka S, Raper S, Riahi K, Thomson A, Velders GJM, van Vuuren DPP (2011) The RCP green-house gas concentrations and their extensions from 1765 to 2300. Clim Change 109:213–241. doi:10.1007/s10584-011-0156-z
Menendez M, Mendez FJ, Losada IJ (2009) Forecasting seasonal to interannual variability in extreme sea levels. ICES J Mar Sci 66(7):1490–1496. doi:10.1093/icesjms/fsp095
Metropolis N, Rosenbluth AW, Rosenbluth MN, Teller AH, Teller E (1953) Equation of state calculations by fast computing machines. J Chem Phys 21(6):1087–1092. doi:10.1063/1.1699114
Moore JC, Grinsted A, Zwinger T, Jevrejeva S (2013) Semiempirical and process-based global sea level projections. Rev Geophys 51(3):484–522. doi:10.1002/rog.20015
Neumann J, Hudgens D, Herter J, Martinich J (2011) The economics of adaptation along developed coastlines. Wiley Interdiscip Rev Clim Change 2(1):89–98. doi:10.1002/wcc.90
Rahmstorf S (2007) A Semi-empirical approach to projecting future sea-level rise. Science 315(5810):368–370. doi:10.1126/science.1135456
Riahi K, Rao S, Krey V, Cho C, Chirkov V, Fischer G, Kindermann G, Nakicenovic N, Rafaj P (2011) RCP 8.5—a scenario of comparatively high greenhouse gas emissions. Clim Change 109:33–57. doi:10.1007/s10584-011-0149-y
Ricciuto DM, Davis KJ, Keller K (2008) A Bayesian calibration of a simple carbon cycle model: the role of observations in estimating and reducing uncertainty. Glob Biogeochem Cycles 22:1–15. doi:10.1029/2006GB002908
Rietbroek R, Brunnabend S, Kusche J, Schröter J, Dahle C (2016) Revisiting the contemporary sea-level budget on global and regional scales. Proc Natl Acad Sci USA 113(6):1504–1509. doi:10.1073/pnas.1519132113
Runge MC, Stroeve JC, Barrett AP, Mcdonald-Madden E (2016) Detecting failure of climate predictions. Nat Clim Change. doi:10.1038/nclimate3041
Smith TM, Reynolds RW, Peterson TC, Lawrimore J (2008) Improvements to NOAA’s historical merged land-ocean surface temperature analysis (1880–2006). J Clim 21(10):2283–2296. doi:10.1175/2007JCLI2100.1
Solow AR (1985) Bootstrapping correlated data. J Int Assoc Math Geol 17(7):769–775. doi:10.1007/BF01031616
Spanger-Siegfried E, Fitzpatrick MF, Dahl K (2014) Encroaching tides: how sea level rise and tidal flooding threaten U.S. East and Gulf Coast communities over the next 30 years. Union of Concerned Scientists
Vermeer M, Rahmstorf S (2009) Global sea level linked to global temperature. Proc Natl Acad Sci 106(51):21527–21532. doi:10.1073/pnas/0907765106
Vihola M (2012) Robust adaptive metropolis algorithm with coerced acceptance rate. Stat Comput 22(5):997–1008. doi:10.1007/s11222-011-9269-5
Von Storch H (1995) Inconsistencies at the interface of climate impact studies and global climate research. Meteorological Zeltschrift 4(2):72–80, ISSN:0941-2948
Zellner A, Tiao GC (1964) Bayesian analysis of the regression model with autocorrelated errors. J Am Stat Assoc 59(307):763–778. doi:10.2307/2283097
Acknowledgements
We thank Stefan Rahmstorf for providing his global sea-level model (http://www.sciencemag.org/content/317/5846/1866.4/suppl/DC1). We gratefully acknowledge the comments from P. Applegate, the editor, and the reviewers on draft versions of this paper. This work was partially supported by the US Department of Energy, Office of Science, Biological and Environmental Research Program, Integrated Assessment Program, Grant No. DE-SC0005171 with additional support from the National Science Foundation (NSF) through the Network for Sustainable Climate Risk Management (SCRiM) under NSF cooperative agreement GEO-1240507, and the Penn State Center for Climate Risk Management. We also acknowledge the World Climate Research Programme’s Working Group on Coupled Modelling and thank the climate modeling groups that participated in the Coupled Model Intercomparison Project Phase 5 (CMIP5; http://cmip-pcmdi.llnl.gov/cmip5/), which supplied the climate model output used in this paper (listed in SI Table 3). The US Department of Energy’s Program for Climate Model Diagnosis and Intercomparison, in partnership with the Global Organization for Earth System Science Portals, provides coordinating support for CMIP5. Any opinions, findings, and conclusions or recommendations expressed in this material are those of the author(s). Data and codes are available through the corresponding author and will be available at https://github.com/scrim-network/Ruckertetal_SLR2016 upon publication.
Author contributions
K.R. performed the analysis and drafted the paper. Y.G. provided and wrote the MCMC likelihood codes. A.B. tested the reproducibility of the code. K.K. initiated the study. All authors contributed to the study design, discussed the results, and edited the manuscript.
Author information
Authors and Affiliations
Corresponding author
Electronic supplementary material
Below is the link to the electronic supplementary material.
ESM 1
(PDF 1316 kb)
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Ruckert, K.L., Guan, Y., Bakker, A.M.R. et al. The effects of time-varying observation errors on semi-empirical sea-level projections. Climatic Change 140, 349–360 (2017). https://doi.org/10.1007/s10584-016-1858-z
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10584-016-1858-z