
Abstract
The objective of this study was to develop and validate a time-dependent logistic regression model for prediction of locoregional recurrence (LRR) of breast cancer and a web-based nomogram for clinical decision support. Women first diagnosed with early breast cancer between 2003 and 2006 in all Dutch hospitals were selected from the Netherlands Cancer Registry (n = 37,230). In the first 5 years following primary breast cancer treatment, 950 (2.6 %) patients developed a LRR as first event. Risk factors were determined using logistic regression and the risks were calculated per year, conditional on not being diagnosed with recurrence in the previous year. Discrimination and calibration were assessed. Bootstrapping was used for internal validation. Data on primary tumours diagnosed between 2007 and 2008 in 43 Dutch hospitals were used for external validation of the performance of the nomogram (n = 12,308). The final model included the variables grade, size, multifocality, and nodal involvement of the primary tumour, and whether patients were treated with radio-, chemo- or hormone therapy. The index cohort showed an area under the ROC curve of 0.84, 0.77, 0.70, 0.73 and 0.62, respectively, per subsequent year after primary treatment. Model predictions were well calibrated. Estimates in the validation cohort did not differ significantly from the index cohort. The results were incorporated in a web-based nomogram (http://www.utwente.nl/mira/influence). This validated nomogram can be used as an instrument to identify patients with a low or high risk of LRR who might benefit from a less or more intensive follow-up after breast cancer and to aid clinical decision making for personalised follow-up.
Similar content being viewed by others


Background
A locoregional recurrence (LRR) has a high risk of distant metastasis, and thus confers a poor prognosis [1]. LRRs are defined as the reappearance of breast cancer on the same site as the primary tumour, in the chest wall or ipsilateral, infraclavicular, supraclavicular or parasternal lymph nodes after curative treatment [2]. Factors that influence the risk of recurrence include tumour size, age, vascular invasion, multifocality, histological grade, hormone receptor status and treatment of the primary tumour [3–13]. Regular follow-up is aimed at detecting LRRs in an early stage to improve survival [14]. In the Netherlands, patients are followed clinically for at least 5 years after their treatment. Still, most of the recurrences are detected by the women themselves in between follow-up visits and some are detected after the 5 years of clinical follow-up [15, 16]. In a Dutch multicentre study, Geurts et al. [14] found that only 34 % of the LRRs were detected asymptomatically during routine visits. Due to the increase in survival, the burden of follow-up on health care is rising. Even though the risk factors are known, follow-up is the same for all patients and not dependent on the personal risk of the individual breast cancer patient. Since 2012, the national guideline of the Netherlands recommends an individualised follow-up by shared decision making, but does not provide recommendations on how to effectuate it. To achieve this, good insight into time-dependent individual LRR risk is necessary.
Statistical models that are used for predicting the outcomes of patients are called prognostic models. Many prognostic models appear to be adequate at the population level. However, their use to predict risks on the level of the individual patient is questionable. Patients and clinicians need accurate risks on the individual patient level to reach more informed and uniform decision making. Challenges are incomplete knowledge on causality and the existence of various risk factors with only a small effect [17, 18]. For the prediction of breast cancer, the first model was developed by Gail et al. [19]. This model, as well as other well-known models (e.g. BRCAPRO, BOADICEA [20], [21]) is aimed at predicting the general risk of primary breast cancer. To get towards personalised follow-up, models predicting LRRs are required. In this paper, logistic regression is used to calculate the risks. Not only the single risk estimated for the overall follow-up period of 5 years, but also the annual time-dependent risk. To facilitate uptake in clinical practice, ease of use and accessibility are crucial. This can be achieved by using a nomogram: a graphical representation of the underlying model. Our aim is to develop and validate a time-dependent logistic regression model and nomogram suitable for the annual risk prediction of LRRs in individual breast cancer patients. Knowing this individual risk could facilitate the decision on a personalised follow-up plan.
Patients and methods
Study population
Patients were selected from the Netherlands Cancer Registry (NCR), a nationwide population-based registry, which records all newly diagnosed tumours since 1989. The information on patient, tumour and treatment characteristics, as well as data concerning recurrences within the first 5 years following primary breast cancer were recorded from the patient files by specially trained registration clerks.
Women diagnosed with primary invasive breast cancer between 2003 and 2006 without distant metastasis, previous, or synchronous tumours (diagnosed within 3 months after the first tumour [22]), treated with curative intent and without neo-adjuvant systemic treatment were selected from the registry (n = 37,230). Curative intent was defined as surgical removal of the primary tumour without macroscopic residual disease. Adjuvant treatment should have been received in case of microscopic residue. In the first 5 years following primary breast cancer treatment, 950 (2.6 %) of the selected patients developed a LRR as a first event. For external validation, data were used of a cohort of 12,308 patients from a selection of Dutch hospitals (43 out of 91) that developed their primary breast cancer between the years 2007 and 2008. Of these patients, 275 (2.2 %) were diagnosed with a LRR.
Although second primary breast cancers (any epithelial breast cancer with or without lymph node metastasis in the contralateral breast [2]) are also of interest with regard to follow-up care, they are not included in the model. Second primary tumours are a different entity from the primary tumour, and are hard to predict based on the available clinical variables [23–25]. Patients with a known genetic predisposition (estimates vary between 3 to around 7 % [26–28]) are not part of the regular follow-up. Unless they underwent a double mastectomy, they undergo a separate, more intensive follow-up.
Model development
Variables were selected based on literature and availability of the data. As the effect of age on LRR risk is nonlinear, it was discretized into four groups (<50, 50–59, 60–69, ≥70). The patient, tumour and treatment characteristics shown in Table 1 were assessed for their influence on recurrence risk using multivariable binary logistic regression analysis. By means of backward elimination, we deleted variables from the initial model until only variables with a P value of <0.157 (Akaike information criterion) were maintained in the model. A last check was performed by adding and removing the variables one by one. Firstly, a prediction model for the 5-year LRR risk was developed. Secondly, risks were determined per year conditional on not being diagnosed with recurrence in the previous year(s). Interaction was tested by adding interaction terms to the model. A correlation matrix was composed to assess possible correlation between the variables. Variables with a high correlation coefficient (>0.7 or <−0.7) were excluded. With a ratio of around 100:1, there were enough events for the included variables in the model. Based on simulation studies, it was determined that the ratio should be at least 10:1 [29].
The percentage of missing values of the included variables ranged between 0 and 24 % (PR status). ER and PR status were not registered by the NCR on a regular basis in 2003 and 2004. The variables of the prediction model with missing values were multiple imputed using a chained equation approach [30–32]. Calculations were performed with the MICE package of R. It was assumed that missing values occurred randomly, which validates the use of imputation. A comparison with the complete case analysis was made, as well as an assessment of the convergence. The analyses were repeated on the imputed data and pooled by using Rubin’s rules.
Validation
Prognostic validity or discrimination refers to the capability to discern between high and low-risk patients [33]. It was measured by the Harrell c-statistic from area under the receiver operating characteristic (ROC). A c-statistic of 1.0 indicates perfect predictive ability, whereas 0.5 represents no predictive discrimination. Calibration, whether the predicted probabilities accord with the observed ones, was evaluated by the Hosmer–Lemeshow goodness-of-fit test in deciles. A P value above 0.05 (indicating no significant difference between the model and the data) is generally considered as a satisfactory goodness-of-fit. Plotting the difference between the observed and predicted probabilities was used for graphical assessment of the calibration.
To see if the model can effectively differentiate between women who will develop a LRR and women who will not, the model was validated. For internal validation, bootstrapping (n = 1000) was used because it provides stable estimates [34]. If the shrinkage factor from the validation is over 0.85, it is considered satisfactory [35]. External validation was performed by regression analyses on the validation cohort. Areas under the ROC curves were compared using the jackknife method proposed by DeLong et al. [36]. A P value < 0.05 was considered statistically significant. Analyses were performed using STATA version 13 and R 3.1.1 software (http://www.r-project.org). The nomogram was developed using HTML and jQuery (JavaScript).
Results
After backward elimination, the model included the variables grade, size, multifocality and nodal involvement of the primary tumour, type of surgery, and whether patients were treated with radio-, chemo- or hormone therapy (Table 2). Assessment of the correlations revealed a high correlation between type of surgery and use of radiotherapy (correlation coefficient -0.8). Since radiotherapy showed a higher influence on the risk, type of surgery was omitted from the model. Due to high correlation between the oestrogen (ER) and progesterone (PR) receptor status, they were combined into one variable (ER/PR negative versus other). Inclusion of interaction terms did not improve the model. The patients in the index and validation cohort had small differences in the included variables age, grade, size, lymph node status, hormone status and treatments (all <3 % per category, Table 1). Healthy convergence was achieved with the multiple imputations.
Validation
Table 3 details the discrimination and calibration properties of the prediction model. The probability measure of the predictive ability given as the c-statistic was 0.71 for the 5-year risk of LRR (95 % confidence interval [CI] 0.69–0.73); indicating good discriminating ability. Per subsequent year after primary treatment, the index group showed an area under the ROC curve of 0.84, 0.76, 0.70, 0.73 and 0.65, respectively. The predictions were well calibrated, as can be seen in the Hosmer–Lemeshow goodness-of-fit test (Fig. 1). For the deciles, the average expected to observed ratio was 1.05 and the P value 0.28, indicating a high agreement between the predictions and observations.

Calibration chart
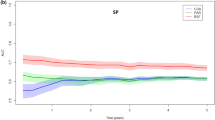
Internal validation in the index group with 1000 times bootstrapping revealed a shrinkage factor of 0.98 for the 5-year risk estimates (Table 3). In the external validation, all effects in the validation group were in the same direction, and the estimates in the validation group did not differ significantly from the index group. Tumour size, chemotherapy and hormone therapy had a slightly higher influence in the validation cohort (Table 2). The comparison between the ROC curves from the index and validation group can be found in Fig. 2.

ROC curves of the index (n = 37,230) and validation (n = 12,308) cohort for 5-year LRR risks
The models based on the imputed data were embedded in the nomogram which is available on http://www.utwente.nl/mira/influence. Figure 3 provides a screenshot of the nomogram which shows the time-dependent risk of a theoretical patient aged between 50 and 59, with a T2M0N1, grade II, hormone status negative primary tumour, who did receive hormone therapy, but no radio- or chemotherapy.

Print screen from the nomogram, providing the time-dependent risk of a fictional patient
Discussion
This study describes the development and validation of the first-ever time-dependent logistic regression model for the prediction of the annual risk of LRR of breast cancer, developed based on data from 37,230 patients. The model takes into account the age of the patient, grade, size, multifocality, and nodal involvement of the primary tumour, and whether patients were treated with radio-, chemo- or hormone therapy. The risk factors used in our model are filtered from the population-based registry and are readily available in (Dutch) clinical practice and for use of the nomogram, without extra efforts or data gathering. Validation displayed only a small overestimation of the risk of developing a LRR (as could be expected with large sample sizes [37]).
In a systematic review on primary breast cancer risk prediction models, it was found that calibration of most models was sufficient [38]. However, discriminatory accuracy was considered poor to fair (c-statistic of 0.52–0.66) after internal validation. Reasons provided were lack of knowledge on risk factors, the different subtypes of breast cancer and discrepancies between risk factors across populations [38]. In this study, both calibration and discrimination (c-statistic of 0.71 after validation) were satisfactory. The individual risk estimates do show uncertainty, particularly in the later years. So risk estimates still need to be interpreted with caution. With nodal involvement being the highest risk factor (odds ratio (OR) 2.9 for >3 nodes compared to negative nodes for the 5 year risk, up to OR 8.5 for the risk in the first year), the effects of the included factors are modest. For instance, Thrift et al. [17] advocate that for prediction of individual risks, the relative risk of factors should exceed ten to be a good predictor of individual risk (even though this does not warrant discriminatory accuracy). Subsequently, individual predictions should be improved by decreasing the unexplained variation. Based on the conventional clinical risk factors, this is not to be expected. Hence more research is needed to discover new characteristics with discriminative ability [18].
This study had a number of strengths including data on many variables associated with risk of LRR and a large sample size. Also, the sample size of the validation cohort was appropriately large, as a minimum of 100 events and hundred non-events was proposed by Vergouwe et al. [39] for an external validation population. A correction for possible subsequent recurrences was unfortunately not feasible, while only first and synchronous recurrences are registered in the NCR. Although information on other known risk factors such as vascular invasion and breast density was unavailable and could not be taken into account, the nomogram can be updated to incorporate more variables when they become available in clinical practice and registries [40]. Of note, our analysis showed that Her2-Neu and primary tumour morphology were not independent predictors of LRR. These findings are in contrast to that of previous studies [10, 41]. This could be due to the fact that all Her2-Neu positive patients are treated with herceptin in the Netherlands. Our nomogram was based on data of almost all diagnosed early primary breast cancers between 2003 and 2006; thus, the results should be generalizable to the Dutch population. Another strength is the presentation of the conditional risk through time instead of only a 5-year risk estimate, which enables the clinician to give a better assessment of the risk over time for patients and adjust the follow-up plan accordingly.
The difference in treatment between the index and validation cohort can be attributed to changing guidelines over time. If the risk is of LRR is high, it could be considered to use adjuvant treatment. However, this is outside the scope of this study, the model is targeted at patients who have completed their treatment. The nomogram can be improved with automatic updating: the new patients will cause adjustments of the estimates, and new patients will weigh more than the less recent ones to better tailor the model to the current clinical practice.
User-friendly access through a nomogram is beneficial for both patients and clinicians. Still, it remains important that the users understand the correct interpretation. Therefore, it is of great importance to present the estimates with the corresponding CI [42]. Much used nomograms like for example Adjuvant! Online (adjuvant treatment decisions) [43], the nomograms from Memorial Sloan Kettering Cancer Center (o.a. likelihood that breast cancer has spread to sentinel lymph nodes) [44] or IBTR! (benefit of adjuvant radiotherapy) [45] do not display these intervals, which makes it hard to appreciate the certainty of the risk estimates.
Current guidelines for follow-up after breast cancer aimed at detecting LRRs at an early, asymptomatic stage prescribe equal follow-up for every patient. This research shows there is a great variability in the risk of LRR, underlining the need for an individualised follow-up. With simulation modelling, thresholds can be found for when to assign the visits, so that using the yearly risk predictions, individual follow-schedules can be developed. This will lower the burden on both patients and care providers, as well as health care resources.
Conclusion
This time-dependent logistic regression model for the prediction of the annual risk of LRR of breast cancer nomogram is simple to use and shows a good predictive ability in the Dutch population. It can be used as an instrument to identify patients with a high risk of LRR who might benefit from a less or more intensive follow-up after breast cancer and to aid clinical decision making.
Abbreviations
- AUC:
-
Area under the curve
- BOADICEA:
-
Breast and ovarian analysis of disease incidence and carrier estimation algorithm
- BRCAPRO:
-
Breast cancer probability
- CI:
-
Confidence interval
- ER:
-
Oestrogen receptor
- Her2-Neu:
-
Human epidermal growth factor receptor 2
- LRR:
-
Locoregional recurrence
- MICE:
-
Multiple imputation by chained equations
- NCR:
-
Netherlands cancer registry
- OR:
-
Odds ratio
- PR:
-
Progesterone receptor
- ROC:
-
Receiver operating characteristic
References
Lu WL, Jansen L, Post WJ et al (2009) Impact on survival of early detection of isolated breast recurrences after the primary treatment for breast cancer: a meta-analysis. Breast Cancer Res Treat 114:403–412. doi:10.1007/s10549-008-0023-4
Moossdorff M, van Roozendaal LM, Strobbe LJ et al (2014) Maastricht delphi consensus on event definitions for classification of recurrence in breast cancer research. J Natl Cancer Inst. doi:10.1093/jnci/dju288
Early Breast Cancer Trialists’ Collaborative Group (EBCTCG) (2005) Effects of chemotherapy and hormonal therapy for early breast cancer on recurrence and 15-year survival: an overview of the randomised trials. Lancet 365:1687–1717. doi:10.1016/S0140-6736(05)66544-0
Begg CB, Haile RW, Borg A et al (2008) Variation of breast cancer risk among BRCA1/2 carriers. JAMA 299:194–201. doi:10.1001/jama.2007.55-a
Dieci MV, Arnedos M, Delaloge S, Andre F (2013) Quantification of residual risk of relapse in breast cancer patients optimally treated. Breast 22(Suppl 2):S92–S95. doi:10.1016/j.breast.2013.07.017
Davies C, Godwin J, Gray R et al (2011) Relevance of breast cancer hormone receptors and other factors to the efficacy of adjuvant tamoxifen: patient-level meta-analysis of randomised trials. Lancet 378:771–784. doi:10.1016/S0140-6736(11)60993-8
Gamucci T, Vaccaro A, Ciancola F et al (2013) Recurrence risk in small, node-negative, early breast cancer: a multicenter retrospective analysis. J Cancer Res Clin Oncol 139:853–860. doi:10.1007/s00432-013-1388-2
Lin P-H, Yeh M-H, Liu L-C et al (2013) Clinical and pathologic risk factors of tumor recurrence in patients with node-negative early breast cancer after mastectomy. J Surg Oncol 108:352–357. doi:10.1002/jso.23403
Komoike Y, Akiyama F, Iino Y et al (2006) Ipsilateral breast tumor recurrence (IBTR) after breast-conserving treatment for early breast cancer: risk factors and impact on distant metastases. Cancer 106:35–41. doi:10.1002/cncr.21551
Cortesi L, Marcheselli L, Guarneri V et al (2013) Tumor size, node status, grading, HER2 and estrogen receptor status still retain a strong value in patients with operable breast cancer diagnosed in recent years. Int J Cancer 132:E58–E65. doi:10.1002/ijc.27795
Clarke M, Collins R, Darby S et al (2005) Effects of radiotherapy and of differences in the extent of surgery for early breast cancer on local recurrence and 15-year survival: an overview of the randomised trials. Lancet 366:2087–2106. doi:10.1016/S0140-6736(05)67887-7
Benson JR, Wishart GC (2013) Predictors of recurrence for ductal carcinoma in situ after breast-conserving surgery. Lancet Oncol 14:e348–e357. doi:10.1016/S1470-2045(13)70135-9
Nagao T, Kinoshita T, Tamura N et al (2013) Locoregional recurrence risk factors in breast cancer patients with positive axillary lymph nodes and the impact of postmastectomy radiotherapy. Int J Clin Oncol 18:54–61. doi:10.1007/s10147-011-0343-y
Geurts SME, de Vegt F, Siesling S et al (2012) Pattern of follow-up care and early relapse detection in breast cancer patients. Breast Cancer Res Treat 136:859–868. doi:10.1007/s10549-012-2297-9
Van der Sangen MJC, Scheepers SWM, Poortmans PMP et al (2012) Detection of local recurrence following breast-conserving treatment in young women with early breast cancer: optimization of long-term follow-up strategies. Breast 22:351–356. doi:10.1016/j.breast.2012.08.006
Khatcheressian J, Swainey C (2008) Breast cancer follow-up in the adjuvant setting. Curr Oncol Rep 10:38–46. doi:10.1007/s11912-008-0007-x
Thrift AP, Whiteman DC (2013) Can we really predict risk of cancer? Cancer Epidemiol 37:349–352. doi:10.1016/j.canep.2013.04.002
Meads C, Ahmed I, Riley RD (2012) A systematic review of breast cancer incidence risk prediction models with meta-analysis of their performance. Breast Cancer Res Treat 132:365–377. doi:10.1007/s10549-011-1818-2
Gail MH, Brinton LA, Byar DP et al (1989) Projecting individualized probabilities of developing breast cancer for white females who are being examined annually. J Natl Cancer Inst 81:1879–1886. doi:10.1093/jnci/81.24.1879
Biswas S, Atienza P, Chipman J et al (2013) Simplifying clinical use of the genetic risk prediction model BRCAPRO. Breast Cancer Res Treat 139:571–579. doi:10.1007/s10549-013-2564-4
Lee AJ, Cunningham AP, Kuchenbaecker KB et al (2013) BOADICEA breast cancer risk prediction model: updates to cancer incidences, tumour pathology and web interface. Br J Cancer 110:535–545. doi:10.1038/bjc.2013.730
Nederlandse Kankerregistratie (2013) Codeerhandleiding Nederlandse Kankerregistratie
Narod SA (2014) Bilateral breast cancers. Nat Rev Clin Oncol 11:157–166. doi:10.1038/nrclinonc.2014.3
Marcu LG, Santos A, Bezak E (2014) Risk of second primary cancer after breast cancer treatment. Eur J Cancer Care (Engl) 23:51–64. doi:10.1111/ecc.12109
Lizarraga IM, Sugg SL, Weigel RJ, Scott-Conner CEH (2013) Review of risk factors for the development of contralateral breast cancer. Am J Surg 206:704–708. doi:10.1016/j.amjsurg.2013.08.002
Kegelaers D, Merckx W, Odeurs P et al (2014) Disclosure pattern and follow-up after the molecular diagnosis of BRCA/CHEK2 mutations. J Genet Couns 23:254–261. doi:10.1007/s10897-013-9656-5
Ford D, Easton DF, Stratton M et al (1998) Genetic heterogeneity and penetrance analysis of the BRCA1 and BRCA2 genes in breast cancer families. Am J Hum Genet 62:676–689. doi:10.1086/301749
Anglian Breast Cancer Study Group (2000) Prevalence and penetrance of BRCA1 and BRCA2 mutations in a population-based series of breast cancer cases. Br J Cancer 83:1301–1308
Peduzzi P, Concato J, Kemper E et al (1996) A simulation study of the number of events per variable in logistic regression analysis. J Clin Epidemiol 49:1373–1379
White IR, Royston P, Wood AM (2011) Multiple imputation using chained equations: issues and guidance for practice. Stat Med 30:377–399. doi:10.1002/sim.4067
Spratt M, Carpenter J, Sterne JAC et al (2010) Strategies for multiple imputation in longitudinal studies. Am J Epidemiol 172:478–487. doi:10.1093/aje/kwq137
Buuren S, Groothuis-Oudshoorn K (2011) MICE: multivariate imputation by chained equations in R. J Stat Softw 45
Steyerberg EW, Vickers AJ, Cook NR et al (2010) Assessing the performance of prediction models: a framework for traditional and novel measures. Epidemiology 21:128–138. doi:10.1097/EDE.0b013e3181c30fb2
Steyerberg EW, Harrell FE, Borsboom GJ et al (2001) Internal validation of predictive models: efficiency of some procedures for logistic regression analysis. J Clin Epidemiol 54:774–781
Harrell FE, Lee KL, Mark DB (1996) Multivariable prognostic models: issues in developing models, evaluating assumptions and adequacy, and measuring and reducing errors. Stat Med 15:361–387. doi:10.1002/(SICI)1097-0258(19960229)15:4<361:AID-SIM168>3.0.CO;2-4
DeLong ER, DeLong DM, Clarke-Pearson DL (1988) Comparing the areas under two or more correlated receiver operating characteristic curves: a nonparametric approach. Biometrics 44:837–845
Steyerberg EW, Eijkemans MJC, Habbema JDF (2001) Application of shrinkage techniques in logistic regression analysis: a case study. Stat Neerl 55:76–88. doi:10.1111/1467-9574.00157
Anothaisintawee T, Teerawattananon Y, Wiratkapun C et al (2012) Risk prediction models of breast cancer: a systematic review of model performances. Breast Cancer Res Treat 133:1–10. doi:10.1007/s10549-011-1853-z
Vergouwe Y, Steyerberg EW, Eijkemans MJC, Habbema JDF (2005) Substantial effective sample sizes were required for external validation studies of predictive logistic regression models. J Clin Epidemiol 58:475–483. doi:10.1016/j.jclinepi.2004.06.017
Boyd NF, Rommens JM, Vogt K et al (2005) Mammographic breast density as an intermediate phenotype for breast cancer. Lancet Oncol 6:798–808. doi:10.1016/S1470-2045(05)70390-9
Wasif N, Maggard MA, Ko CY, Giuliano AE (2010) Invasive lobular vs. ductal breast cancer: a stage-matched comparison of outcomes. Ann Surg Oncol 17:1862–1869. doi:10.1245/s10434-010-0953-z
Iasonos A, Schrag D, Raj GV, Panageas KS (2008) How to build and interpret a nomogram for cancer prognosis. J Clin Oncol 26:1364–1370. doi:10.1200/JCO.2007.12.9791
Adjuvant! Online. https://www.adjuvantonline.com. Accessed 2 Feb 2015
Memorial Sloan Kettering Cancer Center Breast Cancer Nomogram. http://nomograms.mskcc.org/Breast/. Accessed 2 Feb 2015
Tufts Medical Center IBTR! https://www.tuftsmedicalcenter.org/ibtr/. Accessed 2 Feb 2015
Acknowledgments
We would like to thank the registrars of the Netherlands Cancer Registry for their effort in gathering the data essential to this study.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution-NonCommercial 4.0 International License (http://creativecommons.org/licenses/by-nc/4.0/), which permits any noncommercial use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Witteveen, A., Vliegen, I.M.H., Sonke, G.S. et al. Personalisation of breast cancer follow-up: a time-dependent prognostic nomogram for the estimation of annual risk of locoregional recurrence in early breast cancer patients. Breast Cancer Res Treat 152, 627–636 (2015). https://doi.org/10.1007/s10549-015-3490-4
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10549-015-3490-4