
Abstract
One of John Loehlin’s many contributions to the field of behavioral genetics involves gene-environment (GE) correlation. The empirical base for GE correlation was research showing that environmental measures are nearly as heritable as behavioral measures and that genetic factors mediate correlations between environment and behavior. Attempts to identify genes responsible for these phenomena will come up against the ‘missing heritability’ problem that plagues DNA research on complex traits throughout the life sciences. However, DNA can also be used for quantitative genetic analyses of unrelated individuals (Genome-wide Complex Trait Analysis, GCTA) to investigate genetic influence on environmental measures and their behavioral correlates. A novel feature of GCTA is that it enables genetic analysis of family-level environments (e.g., parental socioeconomic status) and school-level environments (e.g., teaching quality) that cannot be investigated using within-family designs such as the twin method. An important implication of GE correlation is its shift from a passive model of the environment imposed on individuals to an active model in which individuals actively create their own experiences in part on the basis of their genetic propensities.
Similar content being viewed by others

Introduction
John Loehlin’s influence on my career involves gene-environment (GE) correlations of a personal as well as scientific kind. At the personal level, he introduced me to behavioral genetics in 1971 when I was a second-year graduate student in psychology at the University of Texas at Austin. He contributed to a ‘core course’ on behavioral genetics, which included the first Annual Review of Psychology chapter on behavioral genetics (Lindzey et al. 1971) and was compulsory for all psychology graduate students. For GE correlation reasons that involve appetite more than aptitude, this course, and especially John Loehlin’s contribution, made me realize that behavioral genetics was the field for me, even though none of the other 40 students in the core course were similarly enticed to behavioral genetics.
The beauty and clarity of John Loehlin’s writing also attracted me to behavioral genetics. It cannot be a coincidence that his undergraduate degree was English and that he is passionate about poetry. In part because of his writing and the clear thinking that underlies it, his books form part of the bedrock of behavioral genetics, bringing lucidity to difficult topics such as race differences (Loehlin et al. 1975), personality (Loehlin 1992; Loehlin and Nichols 1976), and latent variable models (Loehlin 1987). My favorite is his 1976 book on personality, Heredity, environment, and personality: A study of 850 sets of twins. Three quotes from this book illustrate the clarity and lack of pomposity in his writing—as well as the importance of his findings:
The first clear statement about the importance of non-shared environment:“As far as personality and interests are concerned, then, it would appear that the relevant environments of a pair of twins are no more alike than those of two members of the population paired at random. Can this possibly be true? (p. 91)… Thus, a consistent – though perplexing – pattern is emerging from the data (and it is not purely idiosyncratic to our study). Environment carries substantial weight in determining personality – it appears to account for at least half the variance – but that environment is one for which twin pairs are correlated close to zero… In short, in the personality domain we seem to see environmental effects that operate almost randomly with respect to the sorts of variables that psychologists (and other people) have traditionally deemed important in personality development. What can be going on?” (p. 92).
Nearly all psychological traits show moderate genetic influence (lack of differential heritability): “Its message might roughly be translated: ‘Identical twins correlate about .20 higher than fraternal twins, give or take some sampling fluctuation, and it doesn’t much matter what you measure – whether the difference is between .75 and .55 on ability measures, between .50 and .30 on a personality scale, or between .35 and .15 on a self-concept composite” (p. 35).
One of the earliest multivariate genetic analyses using twin data: “The motivation underlying such analyses is the hope that they may provide a powerful tool for studying how genetic and environmental influences affect phenotypic traits. The basic reasoning runs something like this: It is unlikely that our convenient phenotypic trait measures are aligned in a simple one-to-one fashion with either the genetic or the environmental sources of influence upon them. If they are not, the effects of such influences should often show up more clearly on the associations among traits than on the measures of the individual traits themselves. Thus, two genetically independent traits might be correlated because they are subject to common environmental influences, or two traits that share no important environmental inputs might both be affected by a particular gene or genes (‘pleiotropy’)” (p. 75).
More than 30 years later, his work continues to advance these topics of nonshared environment (Loehlin 2007; Loehlin and Martin 2011b); differential heritability for personality traits (Loehlin 2012); and multivariate genetic issues especially in relation to a general factor of personality (Loehlin 2011; Loehlin and Horn 2012; Loehlin and Martin 2011a, 2013). He has also written about GE correlation and other aspects of the interplay between genes and environment (Loehlin 2010a, b). The beauty of his writing continues to shine through his most recent papers (e.g., Loehlin 2013).
John Loehlin was also responsible for launching my career in a very practical way by recommending me for an Assistant Professor position that suddenly materialized at the Institute for Behavioral Genetics as I was finishing my dissertation. His influence on my career did not decrease with the 1,000 miles between Austin and Boulder. I was so impressed with the Texas Adoption Study that John Loehlin and Joseph Horn had established while I was a graduate student at Texas (Horn et al. 1979; Horn and Loehlin 2010; Loehlin et al. 1981) that I decided, with John DeFries, to conduct a study of newborn adoptees in Colorado, which became the Colorado Adoption Project (Plomin and DeFries 1985).
Another example of John Loehlin’s impact on my scientific career is my interest in GE correlation, which was sparked by John Loehlin while I was at Texas. This interest led to a paper with John Loehlin and John DeFries on GE correlation and interaction, which continues to be my most highly cited paper (Plomin et al. 1977). In that paper, the best writing was John Loehlin’s, including the concluding paragraph, which I quote here because it is about the interpretation of GE correlation. Roberts (1967) had argued that GE correlation is ‘really’ genetic and that “it matters not one whit whether the effects of the genes are mediated through the external environment or directly through, say, the ribosomes” (p. 218). We argued that GE correlation is ‘really’ a correlation between genes and environment, and John Loehlin wrote:
“Although formally it may not matter one whit in which way the effects of the genes are mediated, in practice it often matters quite a few whits, especially if one should happen to be interested in intervening in the process. Changing behavior by changing parental attitudes is a decidedly different proposition from tinkering with the ribosomes, even though a similar behavioral change might conceivably be brought about by either means” (p. 321).
The wit of ‘whits’ and ‘tinkering with the ribosomes’ are good examples of the freshness and vividness of his writing—in addition to making a critical point. He also wrote the last sentence of the paper: “And one day, perhaps, we may yet get to the ribosomes” (p. 321).
GE correlation
In our 1977 paper, we considered the effects of GE correlation and interaction on quantitative genetic estimates, proposed three types of GE correlation (passive, reactive and active), and suggested ways to assess GE correlation and interaction. In the present paper, I will briefly summarize research on GE correlation, highlighting new developments using DNA.
GE correlation can be viewed as genetic influence on exposure to environments—literally, a correlation between genetic propensities and experiences. In contrast, GE interaction denotes genetic influence on response to environments, that is, a conditional relationship in which the effect of the environment on a phenotype depends on genotype (Kendler and Eaves 1986). In other words, GE correlation refers to genetic mediation of associations between environments and traits, whereas GE interaction involves genetic moderation of these associations. For example, much research in the past decade investigates moderation of environment-trait correlations by candidate genes, following one of the most highly cited papers in the behavioral sciences reporting that the influence of life stress on depression depends on DNA variation in a serotonin transporter (Caspi et al. 2003). GE interaction and GE correlation assume different models of the environment. The GE interaction model assumes an environment ‘out there’ that is imposed on the individual to which the individual reacts in part on the basis of genetic propensities. The essence of active GE correlation is choice: Individuals select, modify and create experiences that are correlated with their genetic propensities. Although there is much to learn about GE interaction (Petrill et al. 2013), I suggest that active GE correlation will ultimately be more enlightening about the developmental interplay in which genotypes use the environment—from cells to society—to develop into phenotypes.
GE correlation is responsible for one of the most extraordinary findings in behavioral genetics: environmental measures used widely in the behavioral sciences show nearly as much genetic influence as behavioral measures (Plomin and Bergeman 1991). By 1991, this was shown in 18 studies. In 1992, John Loehlin wrote that “the complexities of GE correlation represent a research area which has barely been touched empirically” (Loehlin 1992, p. 126). Now there are more than 100 empirical reports that explore a wide range of environmental measures such as life events, social support, parenting and even children’s television viewing. One review of 55 independent studies analyzing environmental measures as dependent variables in genetically sensitive designs found an average heritability of 27 % across 35 different environmental measures (Kendler and Baker 2007). A recent review of 32 studies on parenting in child-centered designs (i.e., where twins are children) reported an average heritability of 23 % (Avinun and Knafo 2013).
If there is genetic influence on environmental measures as well as behavioral measures, it is possible that associations between environmental measures and behavioral measures are mediated genetically. Most GE correlation research in the past decade has moved beyond merely demonstrating genetic influence on environmental measures, to using multivariate genetic analysis to assess genetic mediation on associations between environment and behavior (Plomin 1994).
Scores of studies show that genetic factors often significantly mediate associations between environmental and behavioral measures, such as correlations between family environment and the development of children’s psychopathology (Knafo and Jaffee 2013). These findings indicate that such correlations cannot safely be interpreted causally as the effect of environment on behavior. They also indicate the extent to which such correlations are truly environmental in origin. For example, a recent study showed that, despite some genetic influence on household chaos, its effect on subsequent disruptive behavior was environmentally mediated (Jaffee et al. 2012). In the search for such true environmental effects, it is important to disentangle passive, reactive and active types of GE correlation, and John Loehlin has contributed models that can do this (e.g., Loehlin and DeFries 1987; Loehlin 2010b; Plomin et al. 1985). A powerful design to disentangle types of GE correlation and to identify true environmental effects is the children of twins design (D’Onofrio et al. 2003) and the extended children of twins design (Narusyte et al. 2008).
Within-family versus between-family environmental factors
Most GE correlation research uses the twin design that compares resemblance within pairs of monozygotic and dizygotic twins. For GE correlation, this limits the twin design to investigating experiences that differ for a pair of twins growing up in the same family, living in the same neighborhood, and attending the same school. This is an important limitation because many crucial environmental variables are the same for two children in a family (e.g., parental SES, chaos in the home), in a neighborhood (e.g., crime and safety, green space), and in a school (e.g., school infrastructure such as resources and teaching quality, school composition such as demographic characteristics). Because these environmental variables are the same for members of a twin pair, they would be read as shared environmental influences in a twin design. However, the correlation between family-level environmental factors such as parental SES and children’s developmental outcomes could be mediated genetically but the twin design would not ‘see’ it. This is a problem primarily for research on children, but also for research that attempts to study the childhood origins of adult behavior. It is much less of a problem for twin studies investigating the effects of contemporaneous environments of adults to the extent that members of adult twin pairs live separate lives.
One way to circumvent this within-family limitation of the twin design is to recast between-family factors, such as family chaos, as individual differences in children’s perceptions of their family chaos. For example, we have studied GE correlation using children’s perceptions of their experiences at home (e.g., Hanscombe et al. 2010, 2011) and school (e.g., Asbury et al. 2008; Haworth et al. 2013). Young people (twins) in the same family and same school report differences in their perceptions, and these self-reported perceptions show genetic influence, but they only correlate modestly with educational outcomes. In retrospect, this research evokes the allegory of losing one’s wallet (GE correlation) in the dark alley (family-level, neighborhood-level, and school-level environments) but looking for it under the streetlamp (individual-level perceptions) because the light is better.
The parent-offspring adoption design can address family-level environmental factors, for example, by comparing the correlation between family environment and children’s development in non-adoptive and adoptive homes (Loehlin and DeFries 1987). However, because it is increasingly difficult to conduct adoption studies, twin studies will continue to be most widely used and will miss most of the environmental action, which is between families, and thus shortchange research on GE correlation.
Research on GE correlation in general—and family-level, neighborhood-level, and school-level environments in particular—will be revolutionized by a new quantitative genetic technique that uses DNA alone in samples of unrelated individuals rather than twins or adoptees.
Genome-wide complex trait analysis (GCTA)
If heritable factors contribute to individual differences as assessed by environmental measures, this means that DNA differences are responsible for these effects. Nothing would advance GE correlation research more than identifying some of these DNA differences. Candidate gene association studies of environmental measures began to be reported as early as 2006 (Lucht et al. 2006) and the first genome-wide association study of an environmental measure was reported in 2008 (Butcher and Plomin 2008). However, this research has run up against the problem that plagues research on complex traits throughout the life sciences: missing heritability, which refers to the wide gap between heritability and the variance explained by identified DNA associations (Plomin and Simpson 2013). Genome-wide association studies throughout the life sciences have shown that there are no DNA associations of large effect size. The largest effect sizes are less than 1 % and the smallest effect sizes are likely to be infinitesimal. Very large samples will be needed to detect such small effects.
An unforeseen benefit of genome-wide association studies is that the data required for them—large samples of unrelated individuals, each genotyped for hundreds of thousands of single-nucleotide polymorphisms (SNPs)—can be used for quantitative genetic analyses of genetic influence. This technique, often called Genome-wide Complex Trait Analysis (GCTA), is the first new human quantitative genetic technique in a century (Yang et al. 2010, 2011b, 2013a). The significance of GCTA is that it can estimate the net effect of genetic influence using DNA of unrelated individuals rather than using familial resemblance in groups of special family members who differ in genetic relatedness such as twins and adoptees (Zaitlen and Kraft 2012).
Unlike genome-wide association, GCTA does not identify specific SNPs associated with a trait. Like other quantitative genetic designs such as the twin design, GCTA uses genetic similarity to predict phenotypic similarity. However, instead of using genetic similarity from groups differing by a known degree of genetic similarity, such as MZ and DZ twins, GCTA uses genetic similarity (Genetic Relatedness Matrix) for each pair of unrelated individuals based on that pair’s overall similarity across hundreds of thousands of SNPs; each pair’s genetic similarity is then used to predict their phenotypic similarity. Even remotely related pairs of individuals are excluded so that chance genetic similarity is used as a random effect in a mixed linear maximum likelihood model to decompose phenotypic variance into genetic variance as captured by the additive effects of causal variants in linkage disequilibrium with SNPs genotyped on DNA arrays (Yang et al. 2011b). The power of the method comes from comparing, not just two groups like MZ and DZ twins, but millions of pairs of individuals. For example, a sample of 6,000 individuals provides eight million pair-by-pair comparisons. In contrast to the twin design, which only requires a few hundred pairs of twins to estimate moderate heritability and does not need DNA, GCTA requires samples of thousands of individuals because the method attempts to extract a small signal of genetic similarity from the massive noise of hundreds of thousands of SNPs. A handy GCTA power calculator is available (http://spark.rstudio.com/ctgg/gctaPower/). For example, a sample of 6,000 has 80 % power to detect a GCTA heritability estimate of 15 %. However, power declines sharply with smaller sample sizes: Samples of 4,000 and 2,000 have 80 % power to detect GCTA heritability estimates of 22 and 45 %, respectively. As discussed later, GCTA heritability estimates are limited to detecting additive effects of the common SNPs on current GWA microarrays, which results in GCTA heritability estimates often being about half of twin study estimates. GCTA can also be used to estimate genetic influence within pairs of siblings (Visscher et al. 2006; Hemani et al. 2013). Because siblings vary in genetic relatedness around their average genetic relatedness of 50 %, GCTA-estimated differences within pairs of siblings can be used in an analogous way to explain phenotypic differences within the sibling pairs. A benefit of this within-family design is that it controls for between-family stratification; a disadvantage in the present context, which is discussed later, is that it is limited to measures that vary within families. More generally, because much larger samples are needed to apply GCTA within sibling pairs, GCTA will primarily be applied to unrelated individuals.
GCTA has been used in scores of studies to estimate genetic influence for physical traits such as height and weight (Yang et al. 2010, 2011a), physiological traits (Yang et al. 2013b), medical disorders (Keller et al. 2012; Lee et al. 2013), psychiatric disorders (Cross-Disorder Group of the Psychiatric Genomics Consortium 2013; Lee et al. 2011, 2012a; Lubke et al. 2012), alcohol dependence (Kos et al. 2013), pharmacogenetics (Tansey et al. 2013; Verweij et al. 2013; Vrieze et al. 2013), personality (McGue et al. 2013; Rietveld et al. 2013a; Vinkhuyzen et al. 2012), behavioral economics (Benjamin et al. 2012; van der Loos et al. 2013), and cognitive abilities (Benyamin et al. 2013; Davies et al. 2011; Deary et al. 2012; Plomin et al. 2013). GCTA has recently been extended to bivariate analyses (Lee et al. 2012b), which enables more sophisticated quantitative genetic analyses such as analyses of age-to-age change and continuity (Deary et al. 2012; Trzaskowski et al. 2013d) and multivariate analyses (Trzaskowski et al. 2013b, c). An important feature of bivariate GCTA analysis is that its estimates of genetic correlations are similar to twin study estimates even though GCTA estimates of genetic variance and covariance are about half the estimates from twin analyses (Trzaskowski et al. 2013d).
There are three benefits of GCTA analysis. First, GCTA makes it possible to conduct quantitative genetic analyses in any large sample with genome-wide genotypes. In this way, GCTA will make behavioral genetics available to a much larger community. Second, GCTA can be used to confirm the results of twin studies. Comparisons between GCTA and twin study estimates of heritability generally show that GCTA accounts for about half the heritability estimates in twin studies (Plomin et al. 2013), perhaps less for behavior problems and personality (Trzaskowski et al. 2013a).
A third benefit is that GCTA provides insight into genetic architecture and the missing heritability problem. GCTA only detects genetic effects tagged by the common SNPs (allele frequencies greater than 1 %) that have until recently been incorporated in commercially available DNA microarrays used in genome-wide association studies. In addition, GCTA is limited to detecting the additive effects of SNPs; it cannot detect gene–gene (or gene-environment) interaction. Thus, if GCTA heritability estimates are half the twin study heritability estimates, the additive effects of common SNPs can in theory account for about half of the heritability estimated from twin studies. The ‘missing GCTA heritability’, the gap between GCTA and twin study heritability estimates, could be due to nonadditive effects or the effects of rare DNA variants. In other words, GCTA estimates the lower limit of heritability from twin studies and the upper limit for genome-wide association studies. These generalizations may not apply equally to all behavioral domains. For example, childhood behavior problems and personality seem to show a greater gap between GCTA estimates and twin estimates than do other domains such as cognitive abilities; this may be due to greater assortative mating for cognitive abilities which increases additive genetic variance or to greater nonadditive effects for behavior problems and personality (Trzaskowski et al. 2013a).
GCTA and GE correlation: group-level environments
GCTA can also be used to study GE correlation. In addition to investigating genetic influence on environmental measures (Power et al. 2013) and genetic mediation of associations between environment and behavior (Harlaar et al. 2014), GCTA can remedy the problem raised above concerning group-level environmental factors. That is, twin studies are limited to investigating within-family (twin-specific) experiences, whereas many important environmental factors are the same for two children in a family. Because GCTA is based on comparisons between unrelated individuals, the method focuses entirely on differences between families, in contrast to the twin method, which is a within-family analysis, comparing differences within pairs of twins in a family to differences between families. For this reason, we can use GCTA to investigate whether genetic factors contribute to family-level, neighborhood-level, and school-level environmental variables and their association with child outcomes.
It may seen counter-intuitive to look for genetic influence on such group-level environments, but children are not randomly assigned to families, neighborhoods, or schools—they are grouped genetically. Nuclear families are genetically defined groups, so average differences between families such as family SES can obviously be affected by genetic differences between families. But what about neighborhood-level and school-level environmental variables—how can ‘environmental’ differences between neighborhoods and between schools be genetic in origin? The answer is that genetic influence can emerge from all three types of GE correlation mentioned earlier. A group-level ‘passive’ GE correlation is possible because schools reflect families who live in those districts. Group-level ‘reactive’ GE correlation can be created by school intake policies such as selecting children on the basis of their performance on school entrance exams and interviews or on the basis of religious affiliation. Group-level ‘active’ GE correlation can occur, especially in secondary schools, when parents and pupils select schools that are correlated with the children’s abilities and interests.
As an empirical example of group-level genetics, we applied GCTA to genome-wide genotypes from 3,000 unrelated children to investigate family socio-economic status (SES), a composite of parental education and occupational status, and its association with children’s intelligence (Trzaskowski et al. 2014). Univariate GCTA indicated that phenotypic variance between families for SES is significantly due to genetic differences. The univariate GCTA heritability estimates for family SES were 0.18 when the children were age 2 and 0.19 when the children were age 7. It should be noted that genome-wide genotypes of one child per family were used to estimate genetic influence on family SES. Because the children’s genotypes only weakly reflect causal genetic factors responsible for their parents’ education and occupation, one might expect that parents’ DNA, not available in this study, would yield a higher GCTA heritability estimate of family SES because the family SES composite is constructed from the parents’ education and occupation. However, a similar GCTA heritability estimate of 0.22 (0.04 standard error, SE) has been reported for adult educational attainment based on the adults’ own DNA (Rietveld et al. 2013b). Another study also reported a similar GCTA heritability estimate of 0.19 (0.05 SE) for adult educational attainment as well as for an index of deprivation (0.21, 0.05 SE; Marioni et al. 2014). Bivariate GCTA yielded a genetic correlation of 0.83 (0.16 SE) between the adults’ own intelligence and their educational attainment, but the genetic correlation was much lower between their intelligence and the index of deprivation (0.16, 0.16 SE).
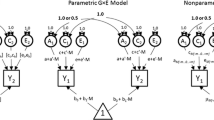
A strength of the child-based design using children’s genotypes in GCTA analyses rather than genotypes of their parents is that it captures the genetic influence of family SES on the children themselves. This feature of the design facilitates a bivariate GCTA that assesses the extent to which the well-known correlation between family SES and cognitive development—about 0.30 in meta-analyses (Sirin 2005)—is mediated genetically. In the study described above (Trzaskowski et al. 2014), a GCTA genetic correlation near 1.0 emerged between family-level SES and children’s intelligence, as shown in Fig. 1. Moreover, genes almost entirely accounted for the phenotypic correlation of 0.30 between family SES and children’s intelligence. However, the large standard errors (shown in parentheses in Fig. 1), especially for the genetic correlation, indicate that samples larger than 3,000 are needed for definitive GCTA estimates.

Bivariate GCTA showing genetic influence on family-level SES and on children’s IQ at age 7, and a genetic correlation of 1.0 between them. Although this path model looks like the result of a twin study, the within-family twin design cannot be used to analyze between-family environmental variables such as family-level SES; this path model describes GCTA results based on DNA from unrelated children. (Used with permission from Trzaskowski et al. 2014.)
GE correlation and an active model of experience
GE correlation challenges current conceptions of the environment as something ‘out there’ that happens passively to children. Finding genetic influence on measures of the environment and on their association with outcomes will make us rethink how the environment works, leading to an active model of experience in which children select, modify and create environments correlated with their genetic propensities. This active model of experience supports an educational trend in the direction of personalized learning, making the educational environment fit the pupil’s profile of strengths and weaknesses—and appetites as well as aptitudes—rather than using a one-size-fits-all curriculum (Asbury and Plomin 2013).
John Loehlin has written about this active model of GE correlation in relation to the development of social attitudes, which highlights the importance of choice. It is fitting for this festschrift in honor of John Loehlin to let him have the last word, especially because the environment he provided was a crucial component in the GE correlations of my life:
“We may view this as a kind of cafeteria model of the acquisition of social attitudes. The individual does not inherit his ideas about fluoridation, royalty, women judges and nudist camps; he learns them from his culture. But his genes may influence which ones he elects to put on his tray. Different cultural institutions – family, church, school, books, television – like different cafeterias, serve up somewhat different menus, and the choices a person makes will reflect those offered him as well as his own biases. As he gets older, choice of cafeterias will become important, in addition to his choice of dishes within them” (Loehlin 1997, p.48).
References
Asbury K, Plomin R (2013) G is for genes: what genetics can teach us about how we teach our children. Wiley, Oxford
Asbury K, Almeida D, Hibel J, Harlaar N, Plomin R (2008) Clones in the classroom: a daily diary study of the nonshared environmental relationship between monozygotic twin differences in school experience and achievement. Twin Res Hum Genet 11(6):586–595. doi:10.1375/twin.11.6.586
Avinun R, Knafo A (2013) Parenting as a reaction evoked by children’s genotype: a meta-analysis of children-as-twins studies. Pers Soc Psychol Rev 18(1):87–102. doi:10.1177/1088868313498308
Benjamin DJ, Cesarini D, van der Loos MJHM, Dawes CT, Koellinger PD, Magnusson PKE, Chabris CF, Conley D, Laibson D, Johannesson M, Visscher PM (2012) The genetic architecture of economic and political preferences. Proc Natl Acad Sci USA 109(21):8026–8031. doi:10.1073/pnas.1120666109
Benyamin B, Pourcain B, Davis OS, Davies G, Hansell NK, Brion MJ, Kirkpatrick RM, Cents RA, Franic S, Miller MB, Haworth CM, Meaburn E, Price TS, Evans DM, Timpson N, Kemp J, Ring S, McArdle W, Medland SE, Yang J, Harris SE, Liewald DC, Scheet P, Xiao X, Hudziak JJ, de Geus EJ, Jaddoe VW, Starr JM, Verhulst FC, Pennell C, Tiemeier H, Iacono WG, Palmer LJ, Montgomery GW, Martin NG, Boomsma DI, Posthuma D, McGue M, Wright MJ, Davey Smith G, Deary IJ, Plomin R, Visscher PM (2013) Childhood intelligence is heritable, highly polygenic and associated with FNBP1L. Mol Psychiatry 19(2):253–258. doi:10.1038/mp.2012.184
Butcher LM, Plomin R (2008) The nature of nurture: a genomewide association scan for family chaos. Behav Genet 38(4):361–371. doi:10.1007/s10519-008-9198-z
Caspi A, Sugden K, Moffitt TE, Taylor A, Craig IW, Harrington H, McClay J, Mill J, Martin J, Braithwaite A, Poulton R (2003) Influence of life stress on depression: moderation by a polymorphism in the 5-HTT gene. Science 301(5631):386–389. doi:10.1126/science.1083968
Cross-Disorder Group of the Psychiatric Genomics Consortium (2013) Genetic relationship between five psychiatric disorders estimated from genome-wide SNPs. Nat Genet 45(9):984–994. doi:10.1038/ng.2711
D’Onofrio BM, Turkheimer EN, Eaves LJ, Corey LA, Berg K, Solaas MH, Emery RE (2003) The role of the children of twins design in elucidating causal relations between parent characteristics and child outcomes. J Child Psychol Psychiatry 44(8):1130–1144. doi:10.1111/1469-7610.00196
Davies G, Tenesa A, Payton A, Yang J, Harris SE, Liewald D, Ke X, Le Hellard S, Christoforou A, Luciano M, McGhee K, Lopez L, Gow AJ, Corley J, Redmond P, Fox HC, Haggarty P, Whalley LJ, McNeill G, Goddard ME, Espeseth T, Lundervold AJ, Reinvang I, Pickles A, Steen VM, Ollier W, Porteous DJ, Horan M, Starr JM, Pendleton N, Visscher PM, Deary IJ (2011) Genome-wide association studies establish that human intelligence is highly heritable and polygenic. Mol Psychiatry 16(10):996–1005. doi:10.1038/mp.2011.85
Deary IJ, Yang J, Davies G, Harris SE, Tenesa A, Liewald D, Luciano M, Lopez LM, Gow AJ, Corley J, Redmond P, Fox HC, Rowe SJ, Haggarty P, McNeill G, Goddard ME, Porteous DJ, Whalley LJ, Starr JM, Visscher PM (2012) Genetic contributions to stability and change in intelligence from childhood to old age. Nature 482(7384):212–215. doi:10.1038/nature10781
Hanscombe KB, Haworth CMA, Davis OSP, Jaffee SR, Plomin R (2010) The nature (and nurture) of children’s perceptions of family chaos. Learn Individ Differ 20(5):549–553. doi:10.1016/j.lindif.2010.06.005
Hanscombe KB, Haworth CMA, Davis OSP, Jaffee SR, Plomin R (2011) Chaotic homes and school achievement: a twin study. J Child Psychol Psychiatry 52(11):1212–1220. doi:10.1111/j.1469-7610.2011.02421.x
Harlaar N, Trzaskowski M, Dale PS, Plomin R (2014) Word reading fluency: role of genome-wide SNPs in developmental stability and correlations with print exposure. Child Dev 85(3):1190–1205. doi:10.1111/cdev.12207
Haworth CMA, Davis OSP, Hanscombe KB, Kovas Y, Dale PS, Plomin R (2013) Understanding the science-learning environment: a genetically sensitive approach. Learn Individ Differ 23:145–150. doi:10.1016/j.lindif.2012.07.018
Hemani G, Yang J, Vinkhuyzen A, Powell JE, Willemsen G, Hottenga J-J, Abdellaoui A, Mangino M, Valdes AM, Medland SE, Madden PA, Heath AC, Henders AK, Nyholt DR, de Geus EJC, Magnusson PKE, Ingelsson E, Montgomery GW, Spector TD, Boomsma DI, Pedersen NL, Martin NG, Visscher PM (2013) Inference of the genetic architecture underlying BMI and height with the use of 20,240 sibling pairs. Am J Hum Genet 93(5):865–875. doi:10.1016/j.ajhg.2013.10.005
Horn JM, Loehlin JCA (2010) Heredity and environment in 300 adoptive families: The Texas Adoption Project. AldineTransaction, New Brunswick
Horn J, Loehlin J, Willerman L (1979) Intellectual resemblance among adoptive and biological relatives: The Texas Adoption Project. Behav Genet 9(3):177–207. doi:10.1007/BF01071300
Jaffee SR, Hanscombe KB, Haworth CM, Davis OS, Plomin R (2012) Chaotic homes and children’s disruptive behavior: a longitudinal cross-lagged twin study. Psychol Sci 23(6):643–650. doi:10.1177/0956797611431693
Keller MF, Saad M, Bras J, Bettella F, Nicolaou N, Simon-Sanchez J, Mittag F, Buchel F, Sharma M, Gibbs JR, Schulte C, Moskvina V, Durr A, Holmans P, Kilarski LL, Guerreiro R, Hernandez DG, Brice A, Ylikotila P, Stefansson H, Majamaa K, Morris HR, Williams N, Gasser T, Heutink P, Wood NW, Hardy J, Martinez M, Singleton AB, Nalls MA, International Parkinson’s Disease Genomics Consortium, Wellcome Trust Case Control Consortium 2 (2012) Using genome-wide complex trait analysis to quantify ‘missing heritability’ in Parkinson’s disease. Hum Mol Genet 21(22):4996–5009. doi:10.1093/hmg/dds335
Kendler KS, Baker JH (2007) Genetic influences on measures of the environment: a systematic review. Psychol Med 37(5):615–626. doi:10.1017/S0033291706009524
Kendler KS, Eaves LJ (1986) Models for the joint effects of genotype and environment on liability to psychiatric illness. Am J Psychiatry 143(3):279–289
Knafo A, Jaffee SR (2013) Gene-environment correlation in developmental psychopathology. Dev Psychopathol 25(1):1–6. doi:10.1017/S0954579412000855
Kos MZ, Yan J, Dick DM, Agrawal A, Bucholz KK, Rice JP, Johnson EO, Schuckit M, Kuperman S, Kramer J, Goate AM, Tischfield JA, Foroud T, Nurnberger J, Hesselbrock V, Porjesz B, Bierut LJ, Edenberg HJ, Almasy L (2013) Common biological networks underlie genetic risk for alcoholism in African- and European-American populations. Genes Brain Behav 12(5):532–542. doi:10.1111/gbb.12043
Lee SH, Wray NR, Goddard ME, Visscher PM (2011) Estimating missing heritability for disease from genome-wide association studies. Am J Hum Genet 88(3):294–305. doi:10.1016/j.ajhg.2011.02.002
Lee SH, DeCandia TR, Ripke S, Yang J, Schizophrenia Psychiatric Genome-Wide Association Study Consortium (PGC-SCZ), International Schizophrenia Consortium (ISC), Molecular Genetics of Schizophrenia Collaboration (MGS), Sullivan PF, Goddard ME, Keller MC, Visscher PM, Wray NR (2012a) Estimating the proportion of variation in susceptibility to schizophrenia captured by common SNPs. Nat Genet 44(3):247–250. doi:10.1038/ng.1108
Lee SH, Yang J, Goddard ME, Visscher PM, Wray NR (2012b) Estimation of pleiotropy between complex diseases using single-nucleotide polymorphism-derived genomic relationships and restricted maximum likelihood. Bioinformatics 28(19):2540–2542. doi:10.1093/bioinformatics/bts474
Lee SH, Harold D, Nyholt DR, ANZGene Consortium, International Endogene Consortium, The Genetic and Environmental Risk for Alzheimer’s disease (GERAD1) Consortium, Goddard ME, Zondervan KT, Williams J, Montgomery GW, Wray NR, Visscher PM (2013) Estimation and partitioning of polygenic variation captured by common SNPs for Alzheimer’s disease, multiple sclerosis and endometriosis. Hum Mol Genet 22(4):832–841. doi:10.1093/hmg/dds491
Lindzey G, Loehlin J, Manosevitz M, Thiessen D (1971) Behavioral genetics. Annu Rev Psychol 22(1):39–94. doi:10.1146/annurev.ps.22.020171.000351
Loehlin JC (1987) Latent variable models: An introduction to factor, path, and structural analysis. Erlbaum, Hillsdale
Loehlin JC (1992) Genes and environment in personality development. Sage Publications Inc., Newbury Park
Loehlin JC (1997) Genes and environment. In: Magnusson D (ed) The lifespan development of individuals: Behavioral, neurobiological, and psychosocial perspectives: a synthesis. Cambridge University Press, New York, pp 38–51
Loehlin JC (2007) The strange case of c2 = 0: what does it imply for views of human development? Res Hum Dev 4(3–4):151–162. doi:10.1080/15427600701662959
Loehlin JC (2010a) Environment and the behavior genetics of personality: let me count the ways. Pers IndividDiff 49(4):302–305. doi:10.1016/j.paid.2009.10.035
Loehlin JC (2010b) Is there an active gene-environment correlation in adolescent drinking behavior? Behav Genet 40(4):447–451. doi:10.1007/s10519-010-9347-z
Loehlin JC (2011) Genetic and environmental structures of personality: a cluster-analysis approach. Pers Individ Diff 51(5):662–666. doi:10.1016/j.paid.2011.06.005
Loehlin J (2012) The differential heritability of personality item clusters. Behav Genet 42(3):500–507. doi:10.1007/s10519-011-9515-9
Loehlin JC (2013) Arthur R. Jensen, 1923–2012. Twin Res Hum Genet 16(1):499–500. doi:10.1017/thg.2012.143
Loehlin J, DeFries J (1987) Genotype-environment correlation and IQ. Behav Genet 17(3):263–277. doi:10.1007/BF01065506
Loehlin JC, Horn JM (2012) How general is the “General Factor of Personality”? Evidence from the Texas Adoption Project. J Res Pers 46(6):655–663. doi:10.1016/j.jrp.2012.07.004
Loehlin JC, Martin NG (2011a) The general factor of personality: questions and elaborations. J Res Pers 45(1):44–49. doi:10.1016/j.jrp.2010.11.008
Loehlin JC, Martin NG (2011b) What does a general factor of personality look like in unshared environmental variance? Pers Individ Diff 51(7):862–865. doi:10.1016/j.paid.2011.07.021
Loehlin JC, Martin NG (2013) General and supplementary factors of personality in genetic and environmental correlation matrices. Pers Individ Diff 54(6):761–766. doi:10.1016/j.paid.2012.12.014
Loehlin JC, Nichols J (1976) Heredity, environment and personality: A study of 850 sets of twins. University of Texas, Austin
Loehlin JC, Lindzey G, Spuhler JN (1975) Race differences in intelligence. Freeman, San Francisco
Loehlin JC, Horn JM, Willerman L (1981) Personality resemblance in adoptive familes. Behav Genet 11(4):309–330. doi:10.1007/BF01070814
Lubke GH, Hottenga JJ, Walters R, Laurin C, de Geus EJ, Willemsen G, Smit JH, Middeldorp CM, Penninx BW, Vink JM, Boomsma DI (2012) Estimating the genetic variance of major depressive disorder due to all single nucleotide polymorphisms. Biol Psychiatry 72(8):707–709. doi:10.1016/j.biopsych.2012.03.011
Lucht M, Barnow S, Schroeder W, Grabe HJ, Finckh U, John U, Freyberger HJ, Herrmann FH (2006) Negative perceived paternal parenting is associated with dopamine D2 receptor exon 8 and GABA(A) alpha 6 receptor variants: an explorative study. Am J Med Genet B 141(2):167–172. doi:10.1002/ajmg.b.30255
Marioni RE, Davies G, Hayward C, Liewald D, Kerr SM, Campbell A, Luciano M, Smith BH, Padmanabhan S, Hocking LJ, Hastie ND, Wright AF, Porteous DJ, Visscher PM, Deary IJ (2014) Molecular genetic contributions to socioeconomic status and intelligence. Intelligence 44:26–32. doi:10.1016/j.intell.2014.02.006
McGue M, Zhang Y, Miller MB, Basu S, Vrieze S, Hicks B, Malone S, Oetting WS, Iacono WG (2013) A genome-wide association study of behavioral disinhibition. Behav Genet 43(5):363–373. doi:10.1007/s10519-013-9606-x
Narusyte J, Neiderhiser JM, D’Onofrio BM, Reiss D, Spotts EL, Ganiban J, Lichtenstein P (2008) Testing different types of genotype-environment correlation: an extended children-of-twins model. Dev Psychol 44(6):1591–1603. doi:10.1037/a0013911
Petrill SA, Bartlett CW, Blair C (2013) Editorial: gene–environment interplay in child psychology and psychiatry-challenges and ways forward. J Child Psychol Psychiatry 54(10):1029. doi:10.1111/jcpp.12133
Plomin R (1994) Genetics and experience: The interplay between nature and nurture. Sage Publications Inc., Thousand Oaks
Plomin R, Bergeman CS (1991) The nature of nurture: genetic influence on “environmental” measures. (With open peer commentary). Behav Brain Sci 14(3):373–414. doi:10.1017/S0140525X00070278
Plomin R, DeFries JC (1985) Origins of individual differences in infancy: The Colorado Adoption Project. Academic Press Inc, Orlando
Plomin R, Simpson MA (2013) The future of genomics for developmentalists. Dev Psychopathol 25(4):1263–1278. doi:10.1017/S0954579413000606
Plomin R, DeFries JC, Loehlin JC (1977) Genotype-environment interaction and correlation in the analysis of human behavior. Psychol Bull 84(2):309–322. doi:10.1037/0033-2909.84.2.309
Plomin R, Loehlin JC, DeFries JC (1985) Genetic and environmental components of “environmental” influences. Dev Psychol 21(3):391–402. doi:10.1037/0012-1649.21.3.391
Plomin R, Haworth CMA, Meaburn EL, Price T, Wellcome Trust Case Control Consortium 2, Davis OSP (2013) Common DNA markers can account for more than half of the genetic influence on cognitive abilities. Psychol Sci 24(4):562–568. doi:10.1177/0956797612457952
Power RA, Wingenbach T, Cohen-Woods S, Uher R, Ng MY, Butler AW, Ising M, Craddock N, Owen MJ, Korszun A, Jones L, Jones I, Gill M, Rice JP, Maier W, Zobel A, Mors O, Placentino A, Rietschel M, Lucae S, Holsboer F, Binder EB, Keers R, Tozzi F, Muglia P, Breen G, Craig IW, Müller-Myhsok B, Kennedy JL, Strauss J, Vincent JB, Lewis CM, Farmer AE, McGuffin P (2013) Estimating the heritability of reporting stressful life events captured by common genetic variants. Psychol Med 43(9):1965–1971. doi:10.1017/S0033291712002589
Rietveld CA, Cesarini D, Benjamin DJ, Koellinger PD, De Neve JE, Tiemeier H, Johannesson M, Magnusson PK, Pedersen NL, Krueger RF, Bartels M (2013a) Molecular genetics and subjective well-being. Proc Natl Acad Sci USA 110(24):9692–9697. doi:10.1073/pnas.1222171110
Rietveld CA, Medland SE, Derringer J, Yang J, Esko T, Martin NW, Westra H-J, Shakhbazov K, Abdellaoui A, Agrawal A, Albrecht E, Alizadeh BZ, Amin N, Barnard J, Baumeister SE, Benke KS, Bielak LF, Boatman JA, Boyle PA, Davies G, de Leeuw C, Eklund N, Evans DS, Ferhmann R, Fischer K, Gieger C, Gjessing HK, Hägg S, Harris JR, Hayward C, Holzapfel C, Ibrahim-Verbaas CA, Ingelsson E, Jacobsson B, Joshi PK, Jugessur A, Kaakinen M, Kanoni S, Karjalainen J, Kolcic I, Kristiansson K, Kutalik Z, Lahti J, Lee SH, Lin P, Lind PA, Liu Y, Lohman K, Loitfelder M, McMahon G, Vidal PM, Meirelles O, Milani L, Myhre R, Nuotio M-L, Oldmeadow CJ, Petrovic KE, Peyrot WJ, Polašek O, Quaye L, Reinmaa E, Rice JP, Rizzi TS, Schmidt H, Schmidt R, Smith AV, Smith JA, Tanaka T, Terracciano A, van der Loos MJHM, Vitart V, Völzke H, Wellmann J, Yu L, Zhao W, Allik J, Attia JR, Bandinelli S, Bastardot F, Beauchamp J, Bennett DA, Berger K, Bierut LJ, Boomsma DI, Bültmann U, Campbell H, Chabris CF, Cherkas L, Chung MK, Cucca F, de Andrade M, De Jager PL, De Neve J-E, Deary IJ, Dedoussis GV, Deloukas P, Dimitriou M, Eiríksdóttir G, Elderson MF, Eriksson JG, Evans DM, Faul JD, Ferrucci L, Garcia ME, Grönberg H, Guðnason V, Hall P, Harris JM, Harris TB, Hastie ND, Heath AC, Hernandez DG, Hoffmann W, Hofman A, Holle R, Holliday EG, Hottenga J–J, Iacono WG, Illig T, Järvelin M-R, Kähönen M, Kaprio J, Kirkpatrick RM, Kowgier M, Latvala A, Launer LJ, Lawlor DA, Lehtimäki T, Li J, Lichtenstein P, Lichtner P, Liewald DC, Madden PA, Magnusson PKE, Mäkinen TE, Masala M, McGue M, Metspalu A, Mielck A, Miller MB, Montgomery GW, Mukherjee S, Nyholt DR, Oostra BA, Palmer LJ, Palotie A, Penninx BWJH, Perola M, Peyser PA, Preisig M, Räikkönen K, Raitakari OT, Realo A, Ring SM, Ripatti S, Rivadeneira F, Rudan I, Rustichini A, Salomaa V, Sarin A-P, Schlessinger D, Scott RJ, Snieder H, St Pourcain B, Starr JM, Sul JH, Surakka I, Svento R, Teumer A, Study TLC, Tiemeier H, van Rooij FJA, Van Wagoner DR, Vartiainen E, Viikari J, Vollenweider P, Vonk JM, Waeber G, Weir DR, Wichmann H-E, Widen E, Willemsen G, Wilson JF, Wright AF, Conley D, Davey-Smith G, Franke L, Groenen PJF, Hofman A, Johannesson M, Kardia SLR, Krueger RF, Laibson D, Martin NG, Meyer MN, Posthuma D, Thurik AR, Timpson NJ, Uitterlinden AG, van Duijn CM, Visscher PM, Benjamin DJ, Cesarini D, Koellinger PD (2013b) GWAS of 126,559 individuals identifies genetic variants associated with educational attainment. Science 340(6139):1467–1471. doi:10.1126/science.1235488
Roberts RC (1967) Some concepts and methods in quantitative genetics. In: Hirsch J (ed) Behavior-genetic analysis. McGraw-Hill, New York, pp 214–257
Sirin SR (2005) Socioeconomic status and academic achievement: a meta-analytic review of research. Rev Educ Res 75(3):417–453. doi:10.3102/00346543075003417
Tansey KE, Guipponi M, Hu X, Domenici E, Lewis G, Malafosse A, Wendland JR, Lewis CM, McGuffin P, Uher R (2013) Contribution of common genetic variants to antidepressant response. Biol Psychiatry 73(7):679–682. doi:10.1016/j.biopsych.2012.10.030
Trzaskowski M, Dale PS, Plomin R (2013a) No genetic influence for childhood behavior problems from DNA analysis. J Am Acad Child Adolesc Psychiatry 52(10):1048–1056. doi:10.1016/j.jaac.2013.07.016
Trzaskowski M, Davis OS, Defries JC, Yang J, Visscher PM, Plomin R (2013b) DNA evidence for strong genome-wide pleiotropy of cognitive and learning abilities. Behav Genet 43(4):267–273. doi:10.1007/s10519-013-9594-x
Trzaskowski M, Shakeshaft NG, Plomin R (2013c) Intelligence indexes generalist genes for cognitive abilities. Intelligence 41(5):560–565. doi:10.1016/j.intell.2013.07.011
Trzaskowski M, Yang J, Visscher PM, Plomin R (2013d) DNA evidence for strong genetic stability and increasing heritability of intelligence from age 7 to 12. Mol Psychiatry 19(3):380–384. doi:10.1038/mp.2012.191
Trzaskowski M, Harlaar N, Arden R, Krapohl E, Rimfeld K, McMillan A, Dale PS, Plomin R (2014) Genetic influence on family socioeconomic status and children’s intelligence. Intelligence 42:83–88. doi:10.1016/j.intell.2013.11.002
van der Loos MJ, Rietveld CA, Eklund N, Koellinger PD, Rivadeneira F, Abecasis GR, Ankra-Badu GA, Baumeister SE, Benjamin DJ, Biffar R, Blankenberg S, Boomsma DI, Cesarini D, Cucca F, de Geus EJ, Dedoussis G, Deloukas P, Dimitriou M, Eiriksdottir G, Eriksson J, Gieger C, Gudnason V, Hohne B, Holle R, Hottenga JJ, Isaacs A, Jarvelin MR, Johannesson M, Kaakinen M, Kahonen M, Kanoni S, Laaksonen MA, Lahti J, Launer LJ, Lehtimaki T, Loitfelder M, Magnusson PK, Naitza S, Oostra BA, Perola M, Petrovic K, Quaye L, Raitakari O, Ripatti S, Scheet P, Schlessinger D, Schmidt CO, Schmidt H, Schmidt R, Senft A, Smith AV, Spector TD, Surakka I, Svento R, Terracciano A, Tikkanen E, van Duijn CM, Viikari J, Volzke H, Wichmann HE, Wild PS, Willems SM, Willemsen G, van Rooij FJ, Groenen PJ, Uitterlinden AG, Hofman A, Thurik AR (2013) The molecular genetic architecture of self-employment. PLoS ONE 8(4):e60542. doi:10.1371/journal.pone.0060542
Verweij KJ, Vinkhuyzen AA, Benyamin B, Lynskey MT, Quaye L, Agrawal A, Gordon SD, Montgomery GW, Madden PA, Heath AC, Spector TD, Martin NG, Medland SE (2013) The genetic aetiology of cannabis use initiation: a meta-analysis of genome-wide association studies and a SNP-based heritability estimation. Addict Biol 18(5):846–850. doi:10.1111/j.1369-1600.2012.00478.x
Vinkhuyzen AAE, Pedersen NL, Yang J, Lee SH, Magnusson PKE, Iacono WG, McGue M, Madden PAF, Heath AC, Luciano M, Payton A, Horan M, Ollier W, Pendleton N, Deary IJ, Montgomery GW, Martin NG, Visscher PM, Wray NR (2012) Common SNPs explain some of the variation in the personality dimensions of neuroticism and extraversion. Transl Psychiatry 2:e102. doi:10.1038/tp.2012.27
Visscher PM, Medland SE, Ferreira MA, Morley KI, Zhu G, Cornes BK, Montgomery GW, Martin NG (2006) Assumption-free estimation of heritability from genome-wide identity-by-descent sharing between full siblings. PLoS Genet 2(3):e41. doi:10.1371/journal.pgen.0020041
Vrieze SI, McGue M, Miller MB, Hicks BM, Iacono WG (2013) Three mutually informative ways to understand the genetic relationships among behavioral disinhibition, alcohol use, drug use, nicotine use/dependence, and their co-occurrence: twin biometry, GCTA, and genome-wide scoring. Behav Genet 43(2):97–107. doi:10.1007/s10519-013-9584-z
Yang J, Benyamin B, McEvoy BP, Gordon S, Henders AK, Nyholt DR, Madden PA, Heath AC, Martin NG, Montgomery GW, Goddard ME, Visscher PM (2010) Common SNPs explain a large proportion of the heritability for human height. Nat Genet 42(7):565–569. doi:10.1038/ng.608
Yang J, Manolio TA, Pasquale LR, Boerwinkle E, Caporaso N, Cunningham JM, de Andrade M, Feenstra B, Feingold E, Hayes MG, Hill WG, Landi MT, Alonso A, Lettre G, Lin P, Ling H, Lowe W, Mathias RA, Melbye M, Pugh E, Cornelis MC, Weir BS, Goddard ME, Visscher PM (2011a) Genome partitioning of genetic variation for complex traits using common SNPs. Nat Genet 43(6):519–525. doi:10.1038/ng.823
Yang JA, Lee SH, Goddard ME, Visscher PM (2011b) GCTA: a tool for genome-wide complex trait analysis. Am J Hum Genet 88(1):76–82. doi:10.1016/j.ajhg.2010.11.011
Yang J, Lee SH, Goddard ME, Visscher PM (2013a) Genome-wide Complex Trait Analysis (GCTA): Methods, data analyses, and interpretations. In: Gondro C, van der Werf J, Hayes B (eds) Genome-wide association studies and genomic prediction. Methods Mol Biol 1019:215–236. doi:10.1007/978-1-62703-447-0_9
Yang J, Lee T, Kim J, Cho M-C, Han B-G, Lee J-Y, Lee H-J, Cho S, Kim H (2013b) Ubiquitous polygenicity of human complex traits: genome-wide analysis of 49 traits in Koreans. PLoS Genet 9(3):e1003355. doi:10.1371/journal.pgen.1003355
Zaitlen N, Kraft P (2012) Heritability in the genome-wide association era. Hum Genet 131(10):1655–1664. doi:10.1007/s00439-012-1199-6
Acknowledgments
TEDS is supported by a program Grant to RP from the UK Medical Research Council [G0901245; and previously G0500079], with additional support from the US National Institutes of Health [HD044454; HD059215]. Genome-wide genotyping was made possible by a Grant from the Wellcome Trust to the Wellcome Trust Case Control Consortium 2 Project [085475/B/08/Z; 085475/Z/08/Z]. RP is supported by a Medical Research Council Research Professorship Award [G19/2] and a European Research Council Advanced Investigator Award [295366].
Conflict of Interest
The author declares that he has no conflict of interest.
Human and Animal Rights and Informed Consent
All procedures followed were in accordance with the ethical standards of the responsible committee on human experimentation (institutional and national) and with the Helsinki Declaration of 1975, as revised in 2000 (5). Informed consent was obtained from all participants for being included in the study.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution License which permits any use, distribution, and reproduction in any medium, provided the original author(s) and the source are credited.
About this article

Cite this article
Plomin, R. Genotype-Environment Correlation in the Era of DNA. Behav Genet 44, 629–638 (2014). https://doi.org/10.1007/s10519-014-9673-7
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10519-014-9673-7