
Abstract
Support vector machine (SVM) is sensitive to outliers or noise in the training dataset. Fuzzy SVM (FSVM) and the bilateral-weighted FSVM (BW-FSVM) can partly overcome this shortcoming by assigning different fuzzy membership degrees to different training samples. However, it is a difficult task to set the fuzzy membership degrees of the training samples. To avoid setting fuzzy membership degrees, from the beginning of the BW-FSVM model, this paper outlines the construction of a bilateral-truncated-loss based robust SVM (BTL-RSVM) model for classification problems with noise. Based on its equivalent model, we theoretically analyze the reason why the robustness of BTL-RSVM is higher than that of SVM and BW-FSVM. To solve the proposed BTL-RSVM model, we propose an iterative algorithm based on the concave–convex procedure and the Newton–Armijo algorithm. A set of experiments is conducted on ten real world benchmark datasets to test the robustness of BTL-RSVM. The statistical tests of the experimental results indicate that compared with SVM, FSVM and BW-FSVM, the proposed BTL-RSVM can significantly reduce the effects of noise and provide superior robustness.

Similar content being viewed by others

References
Armijo L (1966) Minimization of functions having Lipschitz-continuous first partial derivatives. Pac J Math 16(1):1–3
Batuwita R, Palade V (2010) FSVM-CIL: fuzzy support vector machines for class imbalance learning. IEEE Trans Fuzzy Syst 18(3):558–571
Bertsekas DP (1999) Nonlinear programming. Athena Scientific, Belmont
Chapelle O (2007) Training a support vector machine in the primal. Neural Comput 19(5):1155–1178
Collobert R, Sinz F, Weston J, Bottou L (2006) Trading convexity for scalability. In: Proceedings of the 23rd international conference on machine learning. ACM Press, Pittsburgh, pp 201–208
Demsar J (2006) Statistical comparisons of classifiers over multiple data sets. J Mach Learn Res 7:1–30
Dennis JE, Schnabel RB (1983) Numerical methods for unconstrained optimization and nonlinear equations. Prentice-Hall, Englewood Cliffs
Ertekin S, Bottou L, Giles CL (2011) Nonconvex online support vector machines. IEEE Trans Pattern Anal Mach Intell 33(2):368–381
Fung G, Mangasarian OL (2001) Proximal support vector machine classifiers. In: Proceedings of the seventh ACM SIGKDD international conference on knowledge discovery and data mining, San Francisco, California, pp 77–86
Hochberg Y (1988) A sharper Bonferroni procedure for multiple tests of significance. Biometrika 75(4):800–802
Huang W, Lai KK, Yu L, Wang SY (2008) A least squares bilateral- weighted fuzzy SVM method to evaluate credit risk. In: Proceedings of the fourth international conference on natural computation, pp 13–17
Jayadeva Khemchandani R, Chandra S (2004) Fast and robust learning through fuzzy linear proximal support vector machines. Neurocomputing 61:401–411
Jiang XF, Yi Z, Lv JC (2006) Fuzzy SVM with a new fuzzy membership function. Neural Comput Appl 15(3–4):268–276
Jilani TA, Burney SMA (2008) Multiclass bilateral-weighted fuzzy support vector machine to evaluate financial strength credit rating. In: Proceedings of the international conference on computer science and information technology, pp 342–348
Keller JM, Hunt DJ (1985) Incorporating fuzzy membership functions into the perceptron algorithm. IEEE Trans Pattern Anal Mach Intell 7(6):693–699
Lee YJ, Mangasarian OL (2001) SSVM: a smooth support vector machine for classification. Comput Optim Appl 20(1):5–22
Leski JK (2004) An \(\varepsilon -\)margin nonlinear classifier based on fuzzy if-then rules. IEEE Trans Syst Man Cybern Part B Cybern 34(1):68–76
Lin CF, Wang SD (2002) Fuzzy support vector machines. IEEE Trans Neural Netw 13(2):464–471
Lin CF, Wang SD (2004) Training algorithms for fuzzy support vector machines with noisy data. Pattern Recognit Lett 25(14):1647–1656
Lin Y (2002) Support vector machines and the Bayes rule in classification. Data Min Knowl Discov 6(3):259–275
Liu YF, Shen XT, Doss H (2005) Multicategory \(\psi \)-learning and support vector machine: computational tools. J Comput Graph Stat 14(1):219–236
Liu YF, Shen XT (2006) Multicategory \(\psi \)-learning. J Am Stat Assoc 101(474):500–509
Platt JC (1998) Sequential minimal optimization—a fast algorithm for training support vector machines. In: Advances in Kernel methods—support vector learning. MIT Press, Cambridge, pp 185–208
Song Q, Hu W, Xie W (2002) Robust support vector machine with bullet hole image classification. IEEE Trans Syst Man Cybern Part C Appl Rev 32(4):440–448
Tao Q, Wang J (2004) A new fuzzy support vector machine based on the weighted margin. Neural Process Lett 20:139–150
Wang L, Jia HD, Li J (2008) Training robust support vector machine with smooth Ramp loss in the primal space. Neurocomputing 71:3020–3025
Wu XD (1995) Knowledge acquisition from databases. Ablex Publishing Corporation, Norwood
Wu YC, Liu YF (2007) Robust truncated hinge loss support vector machines. J Am Stat Assoc 102(479):974–983
Wu YC, Liu YF (2013) Adaptively weighted large margin classifiers. J Comput Graph Stat 22(2):416–432
Wang YQ, Wang SY, Lai KK (2005) A new fuzzy support vector machine to evaluate credit risk. IEEE Trans Fuzzy Syst 13(6):820–831
Xu LL, Crammer K, Schuurmans D (2006) Robust support vector machine training via convex outlier ablation. In: Proceedings of the 21st national conference on artificial intelligence. AAAI Press, Boston, pp 536–542
Yang XW, Zhang GQ, Lu J, Ma J (2011) A kernel fuzzy c-means clustering based fuzzy support vector machine algorithm for classification problems with outliers or noise\(s\). IEEE Trans Fuzzy Syst 19(1):105–115
Yuille AL, Rangarajia A (2003) The concave–convex procedure. Neural Comput 15(4):915–936
Zhang XG (1999) Using class-center vectors to build support vector machines. In: Proceedings of the 1999 IEEE signal processing society workshop. IEEE Press, New York, pp 3–11
Acknowledgments
The work presented in this paper is supported by the National Science Foundation of China (61273295), the Major Project of the National Social Science Foundation of China (11&ZD156), the Open Project of Key Laboratory of Symbolic Computation and Knowledge Engineering of the Chinese Ministry of Education (93K-17-2009-K04).
Author information
Authors and Affiliations
Corresponding author
Additional information
Communicated by V. Loia.
Appendix
Appendix
Proof of Proposition 1
The loss function \(L({{\mathbf w}},b,m,{{\mathbf x}})\) can be rewritten as follows:
If \(\left| {1-({{\mathbf w}}^T\varphi ({{\mathbf x}})+b)} \right| _+ \ge \left| {1+{{\mathbf w}}^T\varphi ({{\mathbf x}})+b} \right| _+ \), then \(L({{\mathbf w}},b,m,{{\mathbf x}})\ge 1+\left| {1+{{\mathbf w}}^T\varphi ({{\mathbf x}})+b} \right| _+ \). If \(\left| 1-({{\mathbf w}}^T\varphi ({{\mathbf x}})\right. +\left. b) \right| _+ <\left| {1+{{\mathbf w}}^T\varphi ({{\mathbf x}})+b} \right| _+ \), then \(L({{\mathbf w}},b,m,{{\mathbf x}})\ge 1+\left| {1-{{\mathbf w}}^T\varphi ({{\mathbf x}})-b} \right| _+ \). From the definition of the bilateral truncated loss function \(\mathrm{robust}({{\mathbf w}},b,{{\mathbf x}})\), we know that under these two cases, \(L({{\mathbf w}},b,m,{{\mathbf x}})\ge \mathrm{robust}({{\mathbf w}},b,{{\mathbf x}})\) always holds.
Proof of Proposition 2
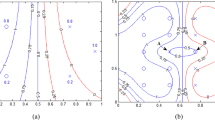
In the following proof, \(z={{\mathbf w}}^T\varphi ({{\mathbf x}})+b\). The graphs of the functions \(f(z)=| {1-z} |_+ \) and \(f(z)=| {1+z} |_+ \) are shown in Fig. 2:

The graphs of the functions \(f(z)=| {1-z} |_+ \) and \(f(z)=| {1+z} |_+ \)
From Fig. 2, we know that
or
If (43) holds, then \(\mathrm{robust}({{\mathbf w}},b,{{\mathbf x}})=1+\left| {1+{{\mathbf w}}^T\varphi ({{\mathbf x}})+b} \right| _+ \). If (44) holds, then \(\mathrm{robust}({{\mathbf w}},b,{{\mathbf x}})=1+\left| {1-{{\mathbf w}}^T\varphi ({{\mathbf x}})-b} \right| _+ \). From the proof procedure of Proposition 1, we know
Let \(\mathrm{ErrorClass}({{\mathbf w}},b,{{\mathbf x}},y)\) be a misclassification error function,
From the definition of \(\mathrm{robust}({{\mathbf w}},b,{{\mathbf x}})\) and (46), we know that the following formulation holds.
which shows that the bilateral truncated loss function \(\mathrm{robust}({{\mathbf w}},b,{{\mathbf x}})\) in the optimization problem (14) is the upper bound of the misclassification error function.
Proof of Theorem 1
Define
From Proposition 2, we know the following two equalities hold:
Considering that \(({{\mathbf w}}_r, b_r )\) and \(({{\mathbf w}}_L ,b_L )\) are the optimal solutions of the optimization problems \(\min \nolimits _{w,b} F_{\mathrm{rob}} ({{\mathbf w}},b)\) and \(\min \nolimits _{w,b} \min \nolimits _{0\le m\le 1} F_L ({{\mathbf w}},b,{{\mathbf m}})\), respectively, we have:
Based on (50), (53), and (56), we can obtain
Based on (51), (52), and (55), we have
Comparing (57) with (58) yields
From the following inequality
we know that the optimal solutions \(({{\mathbf w}}_r, b_r )\) and \(({{\mathbf w}}_L, b_L )\) of the optimization problems (13) and (14) with respect to \(({{\mathbf w}},b)\) are interchangeable.
Proof of Theorem 2
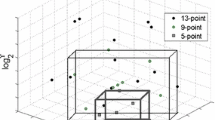
Based on the decision values \(z_i =\sum \nolimits _{j=1}^l {\alpha _j K({{\mathbf x}}_j, {{\mathbf x}}_i )+b} \), we divide the training samples into seven sets \(U_1 =\{ {i\vert \vert z_i -1\vert \le h} \}\), \(U_2 =\{ {i\vert \vert z_i +1\vert \le h} \}\), \(B_1^ =\{ {i\vert h<z_i^ <1-h} \}\), \(B_2^ =\{ {i\vert \vert z_i^ \vert \le h} \}\), \(B_3^ =\!\{ {i\vert \!-\!1\!+\!h<\!z_i^ <\!-\!h} \}\),\(N_1 =\{i\vert z_i >1+h\}\) and \(N_2^ =\{ {i\vert z_i^ <-1-h} \}\), which are illustrated in Fig. 3. Let \(n_{U_1}\), \(n_{U_2 }\), \(n_{B_1}\), \(n_{B_2}\), \(n_{B_3 }\), \(n_{N_1 }\) and \(n_{N_2}\) denote the number of training samples located in the sets \(U_1\), \(U_2\), \(B_1\), \(B_2\), \(B_3\), \(N_1\) and \(N_2 \), respectively. \({{\mathbf I}}_{U_1}\) denotes an \(l\times l\) diagonal matrix with the first \(n_{U_1}\) elements being 1 and the other elements being zeros. \({{\mathbf I}}_{U_2}\) (\({{\mathbf I}}_{B_1}\), \({{\mathbf I}}_{B_2}\), \({{\mathbf I}}_{B_3}\), \({{\mathbf I}}_{N_1}\), and \({{\mathbf I}}_{N_2})\) denote an \(l\times l\) diagonal matrix with the first \(n_{U_1}\) (\(n_{U_1 } +n_{U_2 } \), \(n_{U_1 } +n_{U_2 } +n_{B_1 } \), \(n_{U_1} +n_{U_2}+n_{B_1} +n_{B_2 } \), \(n_{U_1 } +n_{U_2 } +n_{B_1} +n_{B_2}+n_{B_3}\), \(n_{U_1 } +n_{U_2 } +n_{B_1 } +n_{B_2} +n_{B_3}+n_{N_1})\) elements being zeros, followed by \(n_{U_2 }\) (\(n_{B_1}\), \(n_{B_2}\), \(n_{B_3}\), \(n_{N_1 } \) and \(n_{N_2})\) elements being 1, and the other elements being zeros. \({{\mathbf e}}_{U_1}\) denotes an \(l\times 1\) vector with the first \(n_{U_1}\) elements being 1 and the other elements being zeros. \({{\mathbf e}}_{U_2}\) (\({{\mathbf e}}_{B_1 }\), \({{\mathbf e}}_{B_2 }\), \({{\mathbf e}}_{B_3}\), \({{\mathbf e}}_{N_1}\), and \({{\mathbf e}}_{N_2})\) denote an \(l\times 1\) vector with the first \(n_{U_1 }\) (\(n_{U_1 } +n_{U_2 }\), \(n_{U_1 } +n_{U_2} +n_{B_1}\), \(n_{U_1}+n_{U_2}+n_{B_1}+n_{B_2 }\), \(n_{U_1}+n_{U_2} +n_{B_1}+n_{B_2}+n_{B_3}\), \(n_{U_1 } +n_{U_2}+n_{B_1} +n_{B_2}+n_{B_3}+n_{N_1})\) elements being zeros, followed by \(n_{U_2}\) (\(n_{B_1}\), \(n_{B_2}\), \(n_{B_3}\), \(n_{N_1}\) and \(n_{N_2})\) elements being 1, and the other elements being zeros.

The partitioned seven sets
From
and
we can obtain the first-order partial derivatives and the second-order ones of \(J({\varvec{\alpha }},b)\) with respect to \({\varvec{\alpha }}\) and \(b\) as follows:
where \({{\mathbf e}}\) is an \(l\times 1\) vector with elements being 1, the vector \({\varvec{\lambda }}^t\) composes of \(\lambda _i^t \) according to the order of training samples located in the sets \(U_1\), \(U_2 \), \(B_1 \), \(B_2 \), \(B_3 \), \(N_1\), and \(N_2\), and is denoted by \({\varvec{\lambda }}^t=( {{\varvec{\lambda }}_{U_1 }^t, {\varvec{\lambda }}_{U_2 }^t, {\varvec{\lambda }}_{B_1 }^t, {\varvec{\lambda }}_{B_2 }^t, {\varvec{\lambda }}_{B_3 }^t, {\varvec{\lambda }}_{N_1 }^t, {\varvec{\lambda }}_{N_2 }^t })^T\).
From (61)–(65), we can obtain the Hessian matrix and the gradient of the objective function \(J({\varvec{\alpha }},b)\) as follows:
and
For any nonzero vector \((\text{ b }{\varvec{\alpha }}^T)\in R^{l+1}\),
Therefore, the optimization problem (31) is a strictly convex QP problem.
Rights and permissions
About this article

Cite this article
Yang, X., Han, L., Li, Y. et al. A bilateral-truncated-loss based robust support vector machine for classification problems. Soft Comput 19, 2871–2882 (2015). https://doi.org/10.1007/s00500-014-1448-9
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00500-014-1448-9