
Abstract
Multi-hazard risk assessment is a major concern in risk analysis, but most approaches do not consider all hazard interactions when calculating possible losses. We address this problem by developing an improved quantitative model—Model for multi-hazard Risk assessment with a consideration of Hazard Interaction (MmhRisk-HI). This model calculates the possible loss caused by multiple hazards, with an explicit consideration of interaction between those hazards. There are two main components to the model. In the first, based on the hazard-forming environment, relationships among hazards are classified into four types for calculation of the exceedance probability of multiple hazards occurrence. In the second, a Bayesian network is used to calculate possible loss caused by multiple hazards with different exceedance probabilities. A multi-hazard risk map can then be drawn addressing the probability of multi-hazard occurrence and corresponding loss. This model was applied in northeast Zhejiang, China and validated by comparison against an observed multi-hazard sequence. The validation results show that the model can more effectively represent the real world, and that the modelled outputs, possible loss caused by multiple hazards, are reliable. The outputs can additionally help to identify areas at greatest risk, and allows a determination of the factors that contribute to that risk, and hence the model can provide useful further information for planners and decision-makers concerned with risk mitigation.
Similar content being viewed by others
1 Introduction
Multi-hazard risk assessment (MHRA) is a major concern in risk analysis and management (Carpignano et al. 2009; Frigerio et al. 2012; Marulanda et al. 2013; Ming et al. 2015). MHRA is a relatively new field, with little MHRA research conducted before 2000, although three recognizable phases in MHRA development can be identified. Initially, research focused on multiple hazards affecting a given area through the development of a synthetic indicator. Examples included the Australian Geological Survey Organisation Cities project (Granger and Trevor 2000), the Natural Hazard Index for Mega-cities (Munich Re 2003), the World Bank’s global Natural Disaster Hotspot analysis (Dilley et al. 2005), European Spatial Planning and Observation Network (ESPON’s) multi-hazard approach for the enlarged European Union (Schmidt-Thomé 2006), and the Calculation of the Total Place Vulnerability Index for the State of South Carolina, USA (SCEMDOAG 2009). These synthetic indicators are effective in comparing the relative danger experienced by different areas, but give no representation of the real risk situation in those areas—that is, the approach is useful in assessing relative but not absolute losses. To address this problem, research moved from synthetic indicators to assessing integrated losses caused by multiple natural hazards in a given region and time period. This included HAZUS-MH software for Risk Assessment in the USA (FEMA 2004), the Regional RiskScape project for New Zealand (Schmidt et al. 2011), and the Central American Probabilistic Risk Assessment Program for Latin America and the Caribbean Region (Linares-Rivas 2012). However, this research still neglected hazard interaction, hence recently, more comprehensive MHRA research was proposed to assess possible loss due to multiple hazards with a consideration of domino effects (Marzocchi et al. 2012, Eshrati et al. 2015). Nevertheless, these studies, which typify a rather small body of MHRA work, are incomplete. The interaction between different natural hazards is complex and dynamic, and only addressing domino effect hazard interaction is not enough to cover all situations. For example, hazards can occur independently without evident common cause, yet in close proximity, spatially, temporally, or both, and thus interact to elevate risk. Thus the incomplete consideration of possible hazard interactions represents a significant gap in MHRA. This paper therefore aims to develop an improved MHRA model, Model for multi-hazard Risk assessment with a consideration of Hazard Interaction (MmhRisk-HI). The model calculates the possible loss caused by multiple hazards, with an explicit consideration of interaction between different hazards.
2 Multi-hazard risk assessment
The MHRA process is based on that for single-hazard risk assessment, with its main advance being that it puts different hazard types into a single system for joint evaluation (Armonia 2006; Di Mauro et al. 2006; Marzocchi et al. 2009; Carpignano et al. 2009). MHRA is a relatively new field, with no clear definition, but in principle, it takes into account the characteristics (frequency, magnitude) of each hazardous event, and their mutual interactions and interrelations (e.g. a hazard may occur repeatedly in time; different hazards may occur independently in the same place; different hazards may occur dependently in the same place) (Kappes et al. 2012; Marzocchi et al. 2012). The aim of MHRA is to have a holistic view of the total effects or impacts by assessing and mapping the expected social, economic and/or environmental loss due to the occurrence of all natural hazards in a given area (Dilley et al. 2005; Armonia 2006; Kappes et al. 2012; Komendantova et al. 2014).
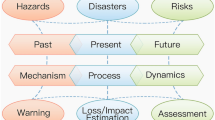
A conceptual model for multi-hazard risk assessment is as shown in Fig. 1, based on the disaster formation process (Burton et al. 1993; Shi 1996; Wisner et al. 2004). Natural hazards are natural events that arise from a specific geophysical environment, accompanied by concentrations of energy released to produce major threats to human life or economic assets (McGuire et al. 2002; ISDR 2004). Space, time, magnitude and frequency are the basic characteristics of natural hazards (Alexander 1993; Smith 2000). The hazard forming environment is the specific geophysical environment that natural hazards arise from, including environmental factors in the atmosphere, hydrosphere, biosphere and lithosphere. These factors are the basic conditions for the occurrence of hazards (Park 1994; Shi 1996; McGuire et al. 2002). Natural hazards are then caused by the substantial departure of one or more environmental factor from their mean values, either in a positive or negative direction. Thus flood can be induced when precipitation is above the normal level, and drought when it is below. Hence, the time, space, magnitude and frequency of hazards are determined by the hazard-forming environment. Some hazards can occur in close proximity, spatially, temporally, or both, in a specific hazard-forming environment. Exposure is defined as the number, type and/or monetary value of elements that are under threat from natural hazards (Alexander 2000; Blanchard 2005; Tong et al. 2009). Vulnerability is broadly defined as the conditions, determined by physical, social, economic, and environmental factors, which determine the potential damage following exposure to hazard (Pelling 2003; Brooks 2003; Ge et al. 2013). The hazards’ interaction with vulnerability and exposures can result in losses and impacts of a human, material, economic and/or environmental nature, losses that can be increased if one hazardous event interacts with another (Gill and Malamud 2014). The induced consequence also influences the stability of the hazard-forming environment and the distribution of exposures, whilst the influenced hazard-forming environment has a chance of producing new hazards. This conceptual model provides a theoretical basis for the improved MHRA model (MmhRisk-HI) construction.

Conceptual model for multi-hazard risk
3 Model construction
3.1 Framework
The structure of the MmhRisk-HI model, with its’ explicit consideration of interaction between different hazards, is shown in Fig. 2. There are two main components. In the first, the hazard-forming environment is used in hazard identification and hazard interaction analysis to analyse the relationship between hazards and to calculate the exceedance probability of multiple hazards occurrence. The second component focuses on the calculation of the possible loss from multiple hazards with different exceedance probabilities. The methods used for the exposure analysis depends on the scale of the region addressed and the assessment units. A Bayesian network (BN) is used to measure the possible loss ratio (the ratio of total losses to the total value of the exposure) caused by multiples hazards with different exceedance probabilities, considering the relevant vulnerability indicators in the loss ratio assessment. Finally, a multi-hazard risk map can be drawn addressing the probability of multi-hazard occurrence and corresponding loss.

Framework of model for multi-hazard Risk assessment with a consideration of Hazard Interaction (MmhRisk-HI)
3.2 Calculation of the exceedance probability of multiple hazards
Natural hazards arise from specific hazard-forming environments, with environmental factors in each environment determining the preconditions for hazard occurrence. The hazard-forming environment can therefore be used to identify which natural hazards influence a given area. For example, proximity to a crustal plate boundary is a precondition for an earthquake. Substantial change in one or more environmental factor in a hazard-forming environment is the main reason that hazards are induced, thus these factors can be taken as triggers for natural hazards and used to analyse hazard interaction. Hazards are thus classified, into four types, according to their trigger factors (Liu et al. 2016), as follows.
3.2.1 Independent relationship
The Independent relationship is where there is no evident common cause between two different hazards. This means that changes in trigger factors which induce hazard A are independent of those which induce hazard B. The relationship between these trigger factors and hazards can be expressed by Eqs. (1) and (2), whereby changes in trigger factors t 1, t 2 … t i … t n are independent of changes in trigger factors t n + 1, t n + 2 …t s …t t . Therefore, the probability of these two hazards occurring together can be calculated as Eq. (3).
where f is the function used to calculate the probability of the change in trigger factors within the brackets occurring together, t i is the trigger factor i, i = 1, 2,…n, t s is the trigger factor s, s = n + 1, n + 2,…t, h j is the hazard j, j = A, B, \({p_{t_{i}}}\) is the probability of the change in trigger factor i, \({p_{t_{s}}}\) is the probability of the change in trigger factor s, and p(h j ) is the probability of hazard j occurrence.
3.2.2 Mutex relationship
A Mutex relationship is where the changes in trigger factors which induce hazards A and B are mutually exclusive, and so these hazards cannot occur together. The relationship between the trigger factors and hazards can be expressed as:
where f is the function, which is used to calculate the probability of the change in trigger factors within the brackets occurring together, t i is the trigger factor i, i = 1, 2,…n, t i+ represents the trigger factor i departure in positive direction from its mean values, t i− represents the trigger factor i departure in the negative direction from its mean values, h j is the hazard j, j = A, B, \({p_{t_{i}}}\) is the probability of the change in trigger factor i, and p(h j ) is the probability of hazard j occurrence.
One trigger factor cannot move in two directions simultaneously, hence, the probability of these two hazards occurring together can be expressed as:
3.2.3 Parallel relationship
Changes in one or more trigger factor may induce more than one hazard A1, A2…A m at the same time, that is, the relationship of hazard A1, A2…A m is parallel. This relationship between trigger factors and hazards can be expressed by Eq. (7), where hazards A1, A2…A m constitute a hazard group, with all hazards induced by the same trigger factor(s). Hence, the frequency and magnitude of this hazard group are determined by changes in the trigger factors, with the probability of the hazard group (hazard A1, A2……A m ) occurring expressed by Eq. (8).
where f is the function, which is used to calculate the probability of the change in trigger factors within the brackets occurring together, t i is the trigger factor i, i = 1, 2,…n, h j is the hazard j, j = A 1, A 2,…A m , \({p_{t_{i}}}\) is the probability of the change in trigger factor i, and p(h j ) is the probability of hazard j occurrence.
3.2.4 Series relationship
In the series relationship, hazard A induces changes in trigger factors, then the changes in these trigger factors induce hazard B. Hazards A and B are in a series relationship, which can be expressed by Eq. (9). Changes in trigger factors t 1 , t 2 …t i …t n induce hazard A, then hazard A changes the trigger factors t n + 1, t n + 2 …t s …t t , which then induce hazard B. The probability of hazards A and B occurring together can thus be expressed by Eq. (10).
where f is the function, which is used to calculate the probability of the change in trigger factors within the brackets occurring together, t i is the trigger factor i, i = 1, 2,…n, t s is the trigger factor s, s = n + 1, n + 2,…t, h j is the hazard j, j = A, B, \({p_{t_{i}}}\) is the probability of the change in trigger factor i, \({p_{t_{s}}}\) is the probability of the change in trigger factor s, and p(h j ) is the probability of hazard j occurrence.
This classification of trigger factors is useful as it helps ensure all possible relationships among hazards are considered. It fills a gap in current multi-hazard methods which to date only consider domino effects, just one type of possible hazard interaction. Based on the four part hazard interaction classification above, the probability of multiple hazards of different magnitudes occurring together can be calculated based on changes in trigger factors, with the degree of change representing the magnitude of hazards, and the probability of change representing the probability of hazards. This can be achieved using a mathematical statistics approach to define a function that determines event magnitude and frequency. For example, Grünthal et al. (2006) calculated exceedance probability-mean wind speed curves for windstorm magnitude assessment using Schmidt and Gumbel distributions (Gumbel 1958).
3.3 Calculation of the possible loss caused by multiple hazards
The second main component of the MmhRisk-HI model focuses on the calculation of possible loss caused by multiple hazards with different exceedance probabilities. This requires exposure analysis, and loss ratio assessment.
3.3.1 Exposure analysis
Exposure analysis is used to determine the spatial distribution of elements at risk (e.g. people, infrastructure). This is usually achieved using analysis of data contained in official statistical reports, or that obtained via on-site survey or remote sensing image. These data sources vary considerably in their characteristics: on-site survey data may be very detailed, but generally only exist on a very local scale, as it is time and resource intensive to collect. Conversely remotely sensed images provide wide area coverage, but the raster format means that the information conveyed is more limited in scope. Official statistics data, based on government administrative units, represent a common intermediate point, in terms of functional resolution. The exposure analysis module selects from these sources following a consideration of the study area size, and the data available for that area.
3.3.2 Loss ratio assessment
The loss ratio assessment module is used to measure the possible loss ratio for a given exposure, under conditions caused by multiple hazards with different exceedance probabilities, and then to determine how vulnerability-related indicators (physical, social, economic and/or environmental factors) influence the possible loss ratio. A BN, a probabilistic graphical model that encodes probabilistic interdependencies among a set of random variables (Jensen and Nielsen 2007), is used in this process. A BN is a good method for modelling uncertainties and interactions between related factors (Maldonado et al. 2015), and has previously been applied in risk assessment of earthquake (Bayraktarli et al. 2006), landslide (Straub 2005) and flooding (Li et al. 2010). The two key steps in the BN, discussed further below, are the construction of the BN structure and estimating the conditional probabilities of relationships within the network.
-
(1)
Bayesian network structure
A BN is a complete model of the system of interest, comprising component variables and the probabilistic relationships between them. In this module, the BN modelling framework is constructed according to domain knowledge (e.g. Alexander 2000; Cutter et al. 2003; Villagran 2006; Schmidt-Thomé 2006). Figure 3 shows that the loss ratio, which is assumed to be a parent node of vulnerability and hazard related indicators, is the root node. Trigger factors are then used to construct the set of hazard-related indicators which represent the magnitude of multiple hazards. Indicators in economic, social, physical and environmental domains represent the sets of vulnerability-related indicators (Table 1).

Generic Bayesian network framework for loss ratio assessment
Table 1 identifies some possible vulnerability-related indicators, with further details given below:
-
GDP/capita: high GDP/capita indicates more economic activity is under threat of hazard events (Blaikie et al. 1994; Schmidt-Thomé 2006).
-
Income of residents: high income indicates residents have more personal resources to absorb losses and speed up recovery after a disaster (Hewitt 1997; Cutter et al. 2003; SCEMDOAG 2009).
-
Population density: high population density indicates more population is under threat of hazard events (Puente 1999; Pelling 2003).
-
Gender ratio: females are often more vulnerable than males as they tend to have more limited education, lower income and family care responsibilities (Cutter et al. 2003; SCEMDOAG 2009).
-
Age structure: children and the elderly are more vulnerable to hazard than young adults due to their limited physical strength (Cutter et al. 2000; Ngo 2001).
-
Telecommunication: high telecommunication capacity supports fast and precise hazard information transmission, thus targeted measures can be adopted quickly (Blaikie et al. 1994; Puente 1999).
-
Transport route: good transport infrastructure makes it easier to evacuate people and to distribute emergency rescue and relief materials (Platt 1991; Villagran 2006).
-
Medical condition: good medical services ensure wounded people get fast and effective treatment after a disaster, thus the recovery period can be shortened (Morrow 1999; Cutter et al. 2003).
-
Social dependency: people who are wholly dependent on social services have very limited personal resources to absorb losses, and require more support in the post-disaster period, thus they are more vulnerable than the employed (Cutter et al. 2003; SCEMDOAG 2009).
-
Risk perception: this measures an individuals’ ability to discern and understand the characteristics and severity of risk from hazard events (Slovic 2000). Understanding risk promotes taking effective measures to cope with disaster, thus people with low risk perception are inherently more vulnerable (Armas 2006; Smith 2013).
-
Warning system: a disaster warning system gives early warning to those at risk and promotes preparedness, mitigating against disaster (Zschau and Küppers 2003).
-
Institutional preparedness: this comprises regulations or procedures (e.g. emergency response plan) developed to mitigate against potential disasters (Haque 2000; Schmidt-Thomé 2006).
-
Educational achievement: higher education levels indicate people can better understand information about hazard events and take more effective measures to cope with disaster (Cutter et al. 2003; SCEMDOAG 2009).
-
Technical infrastructure: this indicates presence of facilities needed to respond to hazard events (e.g. fire trucks, steamboats, helicopters). Good technical infrastructure makes it possible to evacuate people and exert more control during a disaster (Schmidt-Thomé 2006).
-
Significant natural areas: these areas (e.g. national parks) are considered more vulnerable as they are unique and hard to recover (Schmidt-Thomé 2006).
-
Fragmented natural areas: these are vulnerable because nature in larger undisturbed areas recovers faster than that in smaller areas (Schmidt-Thomé 2006).
In this framework, the indicators used to construct vulnerability-related indicators should be independent. To check for this, factor analysis, a classical statistical method to detect structure in the relationships between variables or indicators, is applied (Russell 2002). Using SPSS statistics software, principal component analysis (PCA) (Jolliffe 2002) is adopted to first make distinct the principal component, and then the varimax rotation strategy (Osborne 2008) is used to calculate the factor loading in each principal component. The factors (vulnerability-related indicators) having the highest loading in each principal component are then selected to construct the BN.
Next, trigger factors are chosen to construct the set of hazard-related indicators which represent the magnitude of multiple hazards. Hazard-related indicators for multiple hazards with different relationships are shown in Fig. 4.


Bayesian network frameworks for loss ratio assessment of multiple hazards with different relationships a Independent relationship, b Parallel relationship, c Series relationship
In Fig. 4a, hazards A and B have an independent relationship. The changes in trigger factors t 1, t 2 …t i …t n which induce hazard A are independent of the changes in trigger factors t n + 1, t n + 2 …t s …t t which induce hazard B. The two trigger factor groups (t 1, t 2 …t i …t n ) and (t n + 1 , t n + 2 …t s …t t ) can be used to measure the frequency and magnitude of hazard A and B respectively. Hence, the trigger factor group (t 1, t 2 …t i …t n ) is chosen as the hazard-related indicator to represent the magnitude of hazard A, and the trigger factor group (t n + 1, t n + 2 …t s …t t ) is chosen as the hazard-related indicator to represent the magnitude of hazard B.
In Fig. 4b, hazards A1, A2…A m represent a parallel relationship. Hazards A1, A2…A m are all induced by the changes in the same trigger factors t 1, t 2 …t i . The frequency and magnitude of this hazard group (A1, A2…A m ) are determined by the changes in these trigger factors. Hence, the trigger factor group (t 1, t 2 …t i …t n ) is chosen as the hazard-related indicator to represent the magnitude of group (A1, A2…A m ).
In Fig. 4c, hazards A and B are in a series relationship. The changes in trigger t 1 , t 2 … t i …t n induce the hazard A, then hazard A cause the changes in trigger factors t n + 1, t n + 2 …t s …t t . The changes in trigger factors t n + 1, t n + 2 …t s …t t induce hazard B. Hence, the trigger factor group (t 1, t 2 …t i …t n ) is chosen as the hazard-related indicator to represent the magnitude of hazard A, and the trigger factor group (t n + 1, t n + 2 …t s …t t ) is chosen as the hazard-related indicator to represent the magnitude of hazard B. The probability and degree of the changes in the trigger factor group (t n + 1, t n + 2 …t s …t t ) are decided by the magnitude of hazard A, that is, the changes in the trigger factor group (t 1 , t 2 …t i …t n ).
Hazards in a mutex relationship cannot occur together, so the mutex relationship is not mentioned further.
-
(2)
Determining the conditional probability
A conditional probability measures the probability of an event given that another event has occurred. Once a BN framework is constructed, the conditional probability of a node given their parent nodes should be determined. The conditional probability of a vulnerability-related indicator or hazard-related indicator given a loss ratio is determined in this module as:
where l i represent the i state of loss ratio l, i = 1, 2,…m, and v kj represents the j state of a vulnerability-related indicator or hazard-related indicator k, k = 1,2,…s, j = 1, 2,…n.
There are three commonly used methods for estimation of the conditional probability. When applied to a complete observed data set, maximum-likelihood estimation (MLE), a well-known statistics method is used to provide estimates for the model’s parameters (the conditional probabilities) (Redner and Walker 1984; Grossman and Domingos 2004; Liu et al. 2015). If the model relies on incomplete observed data, an expectation–maximization (EM) algorithm, an iterative method for finding maximum likelihood estimates of parameters (conditional probabilities) in statistical models, can be used (Lauritzen 1995). When there is no observed data for the model, the model’s parameters (conditional probabilities) can be estimated according to domain knowledge (Heckerman et al. 1995; Liao and Ji 2009). Hence, in this module, the methods used for estimation of conditional probabilities are determined according to the availability of observed data.
-
(3)
Loss ratio calculation
In this step, given the above conditional probability, the joint probability (Eq. 12) is used to estimate the posteriori probability of the target loss ratio:
where l i represents the i state of loss ratio l, and v k is the vulnerability-related indicator or hazard-related indicator k, k = 1,2,…s.
When the states of all vulnerability-related indicator and hazard-related indicators are given as j, the probability of loss ratio l i occurring can be calculated based on the posteriori probability of the target loss ratio:
where l i represent the i state of loss ratio l, i = 1,2,…m, and v kj represents the j state of vulnerability-related indicator or hazard-related indicator k, k = 1,2, …s, j = 1, 2,…n.
The final loss ratio L, with given all vulnerability-related indicator and hazard-related indicator states j, can then be calculated as:
where l i is the i state loss ratio with given all vulnerability-related indicator and hazard-related indicator states j, i = 1,2,…m, and P(l i ) is the corresponding probability of the target loss ratio l i occurred.
The loss ratio with other states of vulnerability-related and hazard-related indicator can be calculated in the same way. This module can thus calculate the loss ratio induced by multi-hazards of different degree (different states in hazard-related indicators), whilst also addressing vulnerability using vulnerability-related indicators from physical, social, economic and environmental domains.
3.4 Multi-hazard risk assessment
At this point, and based on the hazard identification and hazard interaction analysis modules, the exceedance probability of multiple hazards can be determined. For any given exceedance probability of multiple hazards, the corresponding loss can be calculated by the value of exposure (identified in the exposure module), and the corresponding loss ratio induced by these hazards (measured in the loss ratio assessment module). With the help of ArcGIS software, the possible loss caused by multi-hazard with different exceedance probabilities in each spatial assessment unit can then be mapped. These maps can be used to identify high risk (large potential loss) areas. Furthermore, this model can help to identify what underlies these large losses. This is significant, as such information supports, guides and targets the development of appropriate loss prevention and risk mitigation measures.
4 Model application: a case study in northeast Zhejiang
4.1 Study area and data
Northeast Zhejiang (Fig. 5), as part of the Yangtze River Delta, is one of China’s main economic regions. This region comprises seven prefecture-level cities in Zhejiang provinces (hereafter “city”), and comprises 55 county level cities and counties (hereafter “county”). With both population density and economic activity growing, this already vulnerable region is increasingly at risk from natural disasters (Liu et al. 2013). Northeast Zhejiang, facing the Pacific to the east, is a typical floodplain with numerous rivers, lakes and canals, and is highly prone to natural hazards. This region is downstream of the Yangtze and Qiantang Rivers and their many tributaries, with channel density >0.5 km of river per km2, factors that make it liable to frequent flooding (Li et al. 2013). The region is coastal and an oceanic landform between Eurasia and the Pacific, so is susceptible to typhoons and storm surges. In addition, some hilly areas are likely to be influenced by landslides. Hence, due to its geographical location and topography, multiple hazards, particularly typhoons, floods, landslides and storm surges are evident in Northeast Zhejiang.

Northeast Zhejiang, China
In addition, according to historical observations, being struck by two consecutive typhoons (within 60 days) is the most common multi-hazard scenario in Northeast Zhejiang. The first and second typhoons have an independent relationship, and these two typhoons could induce floods, landslides and storm surges respectively. Typhoons, floods, landslides and storm surges have a strong relationship with each other in this multi-hazard scenario. Hence, Northeast Zhejiang being struck by typhoons twice consecutively (within 60 days) is a suitable case to show the application of the proposed model.
Three types of data are needed to implement the proposed model: environmental data, disaster data and socioeconomic data. Environmental data mainly comprises meteorological data, downloaded for 15 recording stations (Fig. 5) in the region, with daily data from 1980 to 2013, a suitably lengthy period for hazard-forming environment analysis. Disaster data for this period, collected from the Meteorological Department and the Civil Administration Department in China, includes the disaster type, time, place, and direct economic loss for each disaster in Northeast Zhejiang. Socioeconomic data, derived from statistics yearbooks (1980–2013) in each city includes GDP, income (of rural and urban residents), population density, gender ratio, age structure, telecommunication infrastructure (number of mobile phone users, fixed line phone users, and internet users), transport route (road length), medical service provision (number of medical institutions, beds and medical personnel), and social dependency (number of residents covered by subsistence allowances, number of employed) in each county.
4.2 Exceedance probability for multiple hazards from two consecutive typhoons in northeast Zhejiang
Typhoons, floods, landslides and storm surges are the main hazards in the region. In contrast to other hazards, typhoons can move thousands of kilometres accompanied by strong winds and heavy rain, and a series of hazards (strong winds, floods, landslides and storm surges) induced by changes in wind and rainfall are the reasons for losses in the typhoon track (Lee et al. 2012; Smith 2013). Thus typhoon is viewed as changes of wind speed and rainfall, with these changes used as trigger factors to measure the magnitude of the series of hazards in the track. Hence, the relationships among multiple hazards of two consecutive typhoons in northeast Zhejiang is shown by Fig. 6.

Relationships among multiple hazards of two consecutive typhoons in northeast Zhejiang
Both typhoons are viewed as the trigger factors, with changes of wind speed and rainfall, which induce strong winds, floods, landslides and storm surges. During each typhoon, these four hazard types are in a parallel relationship and constitute a hazard group with each hazard induced by common trigger factors (wind speed and rainfall). Hence, the frequency and magnitude of this hazard group are determined by changes in wind speed and rainfall. The exceedance probability of this hazard group (strong winds, floods, landslides and storm surges) occurring with different magnitudes can be expressed as:
where H w is strong wind, H f is flood, H l is landslide, H s is storm surge, and EP(wind speed, rainfall) is the exceedance probability of the corresponding maximum daily rainfall and maximum daily wind speed sets during the typhoon, calculated using the mathematical statistics approach with maximum daily rainfall and maximum wind speed during each historical typhoon.
According to the trigger factors for hazard occurrence, two typhoons are in an independent relationship, so the hazard groups A and B are also in an independent relationship. Hence, the exceedance probability for multiple hazards of two consecutive typhoons can be calculated as:
where EP(MH) is the exceedance probability for multiple hazards of two consecutive typhoons, EP f (wind speed, rainfall) is the exceedance probability of the corresponding maximum daily rainfall and maximum daily wind speed sets during the first typhoon, and EP s (wind speed, rainfall) is the exceedance probability of the corresponding maximum daily rainfall and maximum daily wind speed sets during the second typhoon.
In our analysis, we adopted the two dimension information diffusion method (Huang 1997) to calculate the exceedance probability of the corresponding maximum daily rainfall and maximum daily wind speed sets. Within this method, maximum daily wind speed and maximum daily rainfall are viewed as two associated factors in one set, and the coefficient of correlation between them is considered during the diffusion. The results in 3 meteorological sites are used as cases to be shown in Fig. 7. Then, a spatial interpolation technique is used to estimate the rainfall and wind distribution in the whole region. The results, as distribution of maximum daily rainfall and maximum wind speed with different exceedance probabilities, are shown in Fig. 8.

Exceedance probability distribution of rainfall and wind speed sets a Hangzhou, b Shengshan, c Yuhuan

Distribution of maximum daily rainfall and maximum wind speed with different exceedance probabilities a Maximum daily rainfall distribution with exceedance probability of 5 %, b Maximum wind speed distribution with exceedance probability of 5 %, c Maximum daily rainfall distribution with exceedance probability of 10 %, d Maximum wind speed distribution with exceedance probability of 10 %
4.3 Possible loss caused by multiple hazards from two consecutive typhoons in northeast Zhejiang
4.3.1 Exposure distribution in northeast Zhejiang
With respect to losses, our case study takes economic loss as an example, with GDP selected as the exposure indicator. The assessment unit in northeast Zhejiang is the county level (government administrative division), so the official statistics data analysis method is used. From these statistics, GDP in each county was obtained, and mapped using ArcGIS. Figure 9 shows that countries with higher GDP in 2013 are mainly located in the north eastern part of the region.

GDP distribution in northeast Zhejiang in 2013
4.3.2 Loss ratio assessment in northeast Zhejiang
For northeast Zhejiang, the relevant vulnerability-related indicators are selected as shown in Table 2. Among these indicators, GDP per km2, population density and percentage of residents covered by subsistence allowances show the same trend direction with vulnerability, that is, as the value of these indicators increases, the value of vulnerability increases. The other indicators show the opposite directional trend with vulnerability. In order to unify the directional trend of these indicators with vulnerability, the reciprocal of the GDP per km2, population density, and 1-percentage of residents covered by subsistence allowances are used in Factor analysis. PCA is adopted to make distinct the principal component. Table 3 shows eight principal components selected based on the cumulative variance, then a varimax rotation strategy is used to calculate the factor loading in each principal component. Variables with the highest loading in each principal component (bold figures in Table 3), are selected as the vulnerability-related indicators to construct the BN. These were: the number of mobile phone users per 10,000 persons (a proxy for income of residents, and telecommunication condition), doctors per 10,000 persons (a proxy for hospital beds and access to medical services), reciprocal of the population density (a proxy for population density and road length per 10,000 persons), reciprocal of the GDP per km2, number of medical institutions per km2, percentage of population age >15 and <65, and percentage of male residents and percentage of employed.
Maximum daily rainfall and maximum daily wind speed in each typhoon are selected as trigger factors to construct the set of hazard-related indicators which represent the magnitudes of multiple hazards. The first and second typhoons have an independent relationship, hence based on the hazard interaction analysis (Sect. 4.2), the BN framework in northeast Zhejiang can be constructed as shown in Fig. 10.

The basic structure of Bayesian Networks for loss ratio assessment in northeast Zhejiang
In our case study, the loss ratio is divided into six states, the eight vulnerability-related indicators are each divided into five states, and the hazard-related indicators (maximum daily rainfall and maximum daily wind speed sets) are divided into eight states (Table 4). From the 1980–2012 historic disaster records, aggregate loss data from two consecutive typhoons were collected, along with corresponding data for vulnerability-related indicators (from the relevant statistics yearbook) to construct a complete observed data set. Then maximum-likelihood estimation (MLE) was then used to provide estimates of the conditional probabilities (Grossman and Domingos 2004). With these conditional probabilities, the loss ratio with different states of vulnerability-related and hazard-related indicator was calculated based on Eqs. 12–14. Taking the maximum daily rainfall distribution and maximum wind speed distribution of the first typhoon with exceedance probability of 10 %, and the second with exceedance probability of 5 % as example, the results are shown in Fig. 11.

Loss ratio distribution influenced by two typhoons with exceedance probability of 10 % and exceedance probability of 5 %
4.4 Multi-hazard risk map in northeast Zhejiang
Taking northeast Zhejiang in 2013, influenced by consecutive typhoons (maximum daily rainfall distribution and maximum wind speed distribution of the first typhoon with exceedance probability of 10 %, and the second with exceedance probability of 5 %) as an example, and according to the hazard identification and interaction analysis described above, the magnitudes of multiple hazards can be expressed by the maximum daily rainfall distribution and maximum wind speed distribution (Fig. 8). With these rainfall and wind speed distributions, the corresponding loss can be calculated by the exposure distribution (Fig. 9) and corresponding loss ratio distribution (Fig. 11). The final risk map is shown in Fig. 12.

Multi-hazard risk map for two consecutive typhoons with exceedance probability of 10 % and exceedance probability of 5 %
This analysis shows that higher loss counties are mainly in the south eastern part of the region, with Linhai, Tiantai, Xianju, Sanmen and Jinzhou counties in the highest risk area. Risk is determined by the magnitudes of multiple hazards, vulnerability and value of exposure. Jinzhou is in the highest risk area due to its highest exposure value. The high risk at Linai, Tiantai, Xianju and Sanmen is due to the interaction of the highest magnitudes of multiple hazards and the highest vulnerability. Thus the relative importance of factors that underlies observed high risk varies geographically. The model can be used to estimate the loss distribution influenced by typhoon with other exceedance probabilities, and also through other hazard combinations.
5 Model validation
Model validation is used to check how well the model represents reality. In our example application, MmhRisk-HI is applied to estimate potential loss caused by multiple hazards in northeast Zhejiang. To test the effectiveness of the model, the hazards that occurred in 2013 were simulated, and calculated losses compared to observed losses. In 2013, northeast Zhejiang was influenced by typhoon Trami (21st August) then typhoon Fitow (7th October). According to the hazard identification and hazard interaction analysis, the magnitudes of multiple hazards induced by typhoons in northeast Zhejiang can be expressed by the maximum daily rainfall and maximum wind speed. Data for these variables was collected from 15 meteorological stations in northeast Zhejiang. With these hazard-related indicators (maximum daily rainfall and maximum wind speed) and vulnerability-related indicators described, using data for 2013, the loss ratio assessment module (based on historical data from 1980 to 2012) was used to estimate the probability of loss ratio in each county induced by these typhoons Trami and Fitow. The modelled and observed loss ratio in 55 counties in northeast Zhejiang are shown in Table 5.
As shown in Table 5, among these 55 counties, the real loss ratio in 42 counties (76.36 %) falls into the loss ratio state (l i ) which has the highest estimated probability (bold figures in Table 5). Taking Shangcheng as an example, the real loss ratio in this county is 0.01 %, which falls into the loss ratio state 2 (0 % < l 2 < 0.5 %). In the corresponding estimated results, the estimated probability of l 2 occurring in Shangcheng is 98 %, which is the highest among all six loss ratio states. In addition, the total estimated loss in these 55 counties is 51,893.39 million yuan compared to the actual loss of 50,485.43 million yuan; a deviation of estimated from actual value of less than 2.79 %. Hence the MmhRisk-HI model is shown to effectively represent the real system, with estimated results reflecting the real loss situation.
6 Conclusion and discussion
MmhRisk-HI fills a key research gap in existing MHRA methods as it goes beyond the simple consideration of multi-hazard interaction as domino effect, to calculate possible loss with an explicit consideration of all possible hazard relationships. In our case study example, whilst the typhoons are independent, the short time period between them means the area is more vulnerable as it has not recovered immediately from the first typhoon. Previous MHRA methods assume there is no change in vulnerability, and so would calculate the loss in each typhoon individually assuming the same vulnerability, then the aggregates the losses. Thus such results cannot reflect the real loss situation. In MmhRisk-HI, the loss ratio assessment module addresses this issue by considering the magnitudes of these two typhoons together in hazard-related indicators. These two typhoons are treated as a multiple hazards group, and the relevant vulnerability-related indicators correspond to this group rather than a single typhoon. Hence, the results obtained in the model are more reliable.
Model validation is a highly desirable step in model development, but a process that has previously proved intractable in MHRA due to the nature of the existing models. MmhRisk-HI can be validated through comparison of modelled and observed data, with the model used to simulate different multiple natural hazards scenarios and estimate the corresponding loss. In the case study, MmhRisk-HI was used to simulate consecutive events, typhoons Trami and Fitow which struck northeast Zhejiang within a few months in 2013. The simulated results were then compared to the observed data, with good agreement. The validation, although based on a necessarily limited set of actual multi-hazard interaction, does indicate that MmhRisk-HI can represent the real world risk situation with greater confidence.
In conclusion, MmhRisk-HI provides more reliable results (possible loss caused by multiple hazards) with an explicit consideration of interaction between different hazards, and can also be used to explore and better explain what underpins large potential losses (high risk). Hence, the model is a useful tool which can provide better information in risk mitigation planning.
Further improvements to MmhRisk-HI are possible. First, a change in one (or several) trigger factors may induce more than one hazard at the same time. In MmhRisk-HI, these hazards are treated as a multiple hazards group, with all hazards in the group induced by the same trigger factor(s). These trigger factors can be used as hazard-related indicators to represent the intensity of this hazard group in loss ratio assessment. In this way, the results obtained in this model are more reliable. However, these results cannot show how much loss is induced by each single hazard in the hazard group. In reality, it is also hard to distinguish how much loss is induced by each single hazard. For example, during a typhoon, it is hard to distinguish how much loss can be attributed to strong winds and how much to floods. Indeed, in the historical disaster record, only records of loss induced by the whole typhoon are made, rather than for the constituent hazards. Understanding the loss induced by each single hazard could help decision-makers take more targeted mitigation measures. Addressing this issue, without historical loss data, will be challenging. Equally challenging will be the inclusion of uncertainty quantifiers in the MmhRisk-HI model. Uncertainty is inherent in natural disaster risk, and needs to be better addressed for effective risk management, yet uncertainty analysis in MHRA remains rare.
References
Alexander D (1993) Natural disasters. UCL Press, London
Alexander D (2000) Confronting catastrophe, new perspectives on natural disaster. Terra, Harpenden
Armas I (2006) Earthquake risk perception in Bucharest Romania. Risk Anal 26(5):1223–1234
Armonia (Applied Multi-Risk Mapping of Natural Hazards for Impact Assessment) (2006) Applied multi-risk mapping of natural hazards for impact assessment. Report on new methodology for multi-risk assessment and the harmonisation of different natural risk maps. Armonia, European Community, Genova
Bayraktarli YY et al (2006) Capabilities of the Bayesian probabilistic networks approach for earthquake risk management. First European Conference on Earthquake Engineering and Seismology. Geneva
Blaikie P, Cannon T, Davis I, Wisner B (1994) At risk: natural hazards, people’s vulnerability, and disasters. Routledge, New York
Blanchard W (2005) Select emergency management-related terms and definitions, vulnerability assessment techniques and applications (VATA). NOAA Coastal Services Center. http://www.csc.noaa.gov/vata/glossary.html. Accessed 12 May 2015
Brooks N (2003) Vulnerability, risk and adaptation: a conceptual framework. Tyndall Centre for Climate Change Research Working Paper 38:1–16
Burton I, Kates RW, White GF (1993) The environment as hazard, 2nd edn. The Guildford Press, New York
Carpignano A, Golia E, Di Mauro C, Bouchon S, Nordvik JP (2009) A methodological approach for the definition of multi-risk maps at regional level: first application. J Risk Res 12(3–4):513–534
Cutter SL, Mitchell JT, Scott MS (2000) Revealling vulnerability of people and place: a case study of Geogretown county, South Carolina. Annal Assoc Am Geogr 90(4):713–737
Cutter SL, Boruff BJ, Shirley WL (2003) Social vulnerability to environmental hazards. Soc Sci Quart 84(2):242–261
Di Mauro C, Bouchon S, Carpignana A, Golia E, Peressin S (2006) Definition of multi-risk maps at regional level as management tool: experience gained by civil protection authorities of Piemonte region. 5th conference on risk assessment and management in the civil and industrial settlements. University of Pisa
Dilley M et al (2005) Natural disaster hotspots, a global risk analysis. World Bank, Washington, DC
Eshrati L, Mahmoudzadeh A, Taghvaei M (2015) Multi hazards risk assessment, a new methodology. Int J Health Syst Disaster Manag 3(2):79–88
FEMA (2004) Using HAZUS-MH for risk assessment. http://www.fema.gov. Accessed 11 March 2012
Frigerio S, Kappes MS, Glade T, Malet J-P (2012) MultiRISK: a platform for Multi-Hazard Risk Modelling and Visualisation. http://www.mae-srl.it/allegati/3_22_692.pdf Accessed 18 March 2014
Ge Y, Dou W, Gu Z, Qian X, Wang J, Xu W, Shi P, Ming X, Zhou X, Chen Y (2013) Assessment of social vulnerability to natural hazards in the Yangtze River Delta, China. Stoch Environ Res Risk Assess 27(8):1899–1908
Gill JC, Malamud BD (2014) Reviewing and visualizing the interactions of natural hazards. Rev Geophys 52(4):680–722
Granger K, Trevor J (2000) A multi-hazard risk assessment. In: Middelmann M, Granger K (eds) Community risk in MacKay, a multi-hazard risk assessment. Australian geological survey organization, Canberra
Grossman D, Domingos P (2004) Learning Bayesian network classifiers by maximizing conditional likelihood. Proceedings of the twenty-first international conference on Machine learning. ACM, New York
Grünthal G et al (2006) Comparative risk assessment for the city of Cologne-storms, floods, earthquake. Nat Hazards 38:21–44
Gumbel EJ (1958) Statistics of extremes. Columbia University Press, New York
Haque CE (2000) Risk assessment, emergency preparedness and response to hazards: the case of the 1997 Red River Valley flood, Canada. In: Natural Hazards. Springer, Dordrech
Heckerman D, Geiger D, Chickering DM (1995) Learning Bayesian networks: the combination of knowledge and statistical data. Mach Learn 20(3):197–243
Hewitt K (1997) Regions of risk: a geographical introduction to disasters. Longman, Essex
Huang CF (1997) Principle of information diffusion. Fuzzy Sets Syst 91(1):69–90
ISDR (Intentional Strategy for Disaster Reduction) (2004) Living with risk. A global review of disaster reduction initiatives. United Nations publication, Geneva
Jensen FV, Nielsen TD (2007) Bayesian networks and decision graphs, 2nd edn. Springer, New York
Jolliffe I (2002) Principal component analysis. John Wiley & Sons Ltd, New York
Kappes MS, Keiler M, von Elverfeldt K, Glade T (2012) Challenges of analyzing multi-hazard risk: a review. Nat Hazards 64(2):1925–1958
Komendantova N et al (2014) Multi-hazard and multi-risk decision-support tools as a part of participatory risk governance: feedback from civil protection stakeholders. Int J Disaster Risk Reduct 8:50–67
Lauritzen SL (1995) The EM algorithm for graphical association models with missing data. Comput Stat Data Anal 19(2):191–201
Lee YH, Yang HD, Chen CS (2012) Spatial risk assessment of typhoon cumulated rainfall: a case study in Taipei area. Stoch Environ Res Risk Assess 26(4):509–517
Li LF et al (2010) Assessment of catastrophic risk using Bayesian network constructed from domain knowledge and spatial data. Risk Anal 30(7):1157–1175
Li GF, Xiang XY, Tong YY, Wang HM (2013) Impact assessment of urbanization on flood risk in the Yangtze River Delta. Stoch Environ Res Risk Assess 27(7):1683–1693
Liao W, Ji Q (2009) Learning Bayesian network parameters under incomplete data with domain knowledge. Pattern Recogn 42(11):3046–3056
Linares-Rivas A (2012) CAPRA initiative: integrating disaster risk into development policies in Latin America and the Caribbean. http://www.ecapra.org/capra-initiative-integrating-disaster-risk-development-policies-latam. Accessed Oct 2013
Liu B, Siu YL, Mitchell G, Xu W (2013) Exceedance probability of multiple natural hazards: risk assessment in China’s Yangtze River Delta. Nat Hazards 69(3):2039–2055
Liu R, Chen Y, Wu J, Gao L, Barrett D, Xu T, Li L, Huang C, Yu J (2015) Assessing spatial likelihood of flooding hazard using naïve Bayes and GIS: a case study in Bowen Basin, Australia. Stoch Environ Res Risk Assess: 1–16. doi:10.1007/s00477-015-1198-y
Liu B, Siu YL, Mitchell G (2016) Hazard interaction analysis for multi-hazard risk assessment: a systematic classification based on hazard-forming environment. Nat Hazards Earth Syst Sci 16(2):629–642
Maldonado AD, Aguilera PA, Salmerón A (2015) Continuous Bayesian networks for probabilistic environmental risk mapping. Stoch Environ Res Risk Assess: 1–15. doi:10.1007/s00477-015-1133-2
Marulanda MC et al (2013) Probabilistic earthquake risk assessment using CAPRA: application to the city of Barcelona, Spain. Nat Hazards 69(1):59–84
Marzocchi W et al (2009) Principles of multi-risk assessment. Interaction amongst natural and man-induced risks. European Communities, Brussels
Marzocchi W et al (2012) Basic principles of multi-risk assessment: a case study in Italy. Nat Hazards 62(2):551–573
McGuire B, Mason I, Kilburn C (2002) Natural hazards and environmental change. Arnold, London
Ming X, Xu W, Li Y, Du J, Liu B, Shi P (2015) Quantitative multi-hazard risk assessment with vulnerability surface and hazard joint return period. Stoch Environ Res Risk Assess 29(1):35–44
Morrow BH (1999) Identifying and mapping community vulnerability. Disasters 23(1):11–18
Munich Re (Munich Reinsurance Company) (2003) Topics—annual review: natural catastrophes 2002. Munich Re Group, Munich
Ngo EB (2001) When disasters and age collide: reviewing vulnerability of the elderly. Nat Hazards Rev 2(2):80–89
Osborne JW (2008) Best practices in quantitative methods. Sage, London
Park C (1994) Environment issues. Prog Phys Geogr 18(3):411–424
Pelling M (2003) The vulnerability of cities. Natural disasters and social resilience. Earthscan Publications, London
Platt RH (1991) Lifelines: an emergency management priority for the United States in the 1990s. Disasters 15(2):172–176
Puente S (1999) Social vulnerability to disaster in Mexico City. In: Mitchell JK (ed) Crucibles of Hazard: Mega-cities and disasters in transition. United Nations University Press, Tokyo, pp 295–334
Redner RA, Walker HF (1984) Mixture densities, maximum likelihood and the EM algorithm. SIAM Rev 26(2):195–239
Russell DW (2002) In search of underlying dimensions: the use (and abuse) of factor analysis in Personality and Social Psychology Bulletin. Pers Soc Psychol Bull 28(12):1629–1646
SCEMDOAG (South Carolina Emergency Management Division Office of the Adjutant General) (2009) State of South Carolina hazards assessment 2008. University of South Carolina, South Carolina Emergency Management Division Office of the Adjutant General, Hazards Research Lab, Department of Geography, South Carolina
Schmidt J et al (2011) Quantitative multi-risk analysis for natural hazards: a framework for multi-risk modelling. Nat Hazards 58(3):1169–1192
Schmidt-Thomé P (2006) The spatial effects and management of natural and technological hazards in Europe. European Spatial Planning and Observation Network (ESPON) project 1.3.1. Geological Survey of Finland, Luxembourg
Shi PJ (1996) Theory and practice of disaster study. J Nat Disaster 5(4):6–17
Slovic PE (2000) The perception of risk. Earthscan Publications, London
Smith K (2000) Environmental hazards: assessing risk and reducing disaster, 3rd edn. Routledge, New York
Smith K (2013) Environmental hazards: assessing risk and reducing disaster, 6th edn. Routledge, New York
Straub D (2005) Natural hazards risk assessment using bayesian networks. The 9th international conference on structural safety and reliability. Rome
Tong ZJ, Zhang JQ, Liu XP (2009) GIS-based risk assessment of grassland fire disaster in western Jilin province, China. Stoch Environ Res Risk Assess 23(4):463–471
Villagrán de León JC (2006) Vulnerability: a Conceptual and methodological review. UNU-EHS (The United Nations University, Institute for Environment and Human Security), Bonn
Wisner B, Blaikie P, Cannon T, Davis I (2004) At risk: natural hazards, people’s vulnerability and disasters, 2nd edn. Routledge, London
Zschau J, Küppers AN (eds) (2003) Early warning systems for natural disaster reduction. Springer Science & Business Media, New York
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Liu, B., Siu, Y.L. & Mitchell, G. A quantitative model for estimating risk from multiple interacting natural hazards: an application to northeast Zhejiang, China. Stoch Environ Res Risk Assess 31, 1319–1340 (2017). https://doi.org/10.1007/s00477-016-1250-6
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00477-016-1250-6