
Abstract
Consider a politician who has to take two sequential decisions during his term in office. For each decision, the politician faces a trade-off between taking what he believes to be the decision that generates a public benefit, thus increasing his chances of re-election, and taking the decision that increases his private gain but is likely to decrease his chances of re-election. In our results we find that if the politician is a good enough decision maker and he desires to be re-elected enough, he takes the action that generates a public benefit regardless of his private interests. Moreover, we find that the behavior such that the politician delays taking the action that generates a public benefit to the last period of his term in office before he is up for re-election is optimal if and only if he has either very high or very low decision making skills.


Similar content being viewed by others
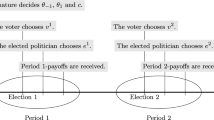

Notes
Most of this empirical literature assumed that politician has a maximum number of terms. Hence, the standard prediction of the political agency model is that the politician shirks when he is in his last term in office. In our model, there is no term limit and shirking occurs because there are multiple decisions per term. Moreover, in our paper the politician chooses not only whether to shirk or not but also when.
For more on the role of commitment and time inconsistencies in a sequential policy making model see Bueno de Mesquita and Landa (2014).
The case where there is only one time period (i.e. the politician takes only one decision per term) is considered in the seminal paper of Ferejohn (1986) and more recently in Weelden (2013). The working paper version of the present paper (Rivas 2014) deals with the cases where there is only one time period (i.e. one decision) per term and when there are more than two.
Note that given that we deal with a binary policy/binary state space model both the quality of information and the politician’s decision making skills are equivalent concepts yet this is not true in general.
The working paper version of the this paper (Rivas 2014) extends this assumption by allowing voters to be strategic players that have the number of times the politician needs to take the public decision in order for him to be re-elected as their choice variable.
Alternatively, it could be assumed that the politician receives some one-off benefit from taking the public decision.
Even though we assume the private decision to be action 1, the private decision could change period by period. This would make no difference to our results but would complicate the exposition.
This does not mean that the politician commits to a certain sequence of plans \(\{d_t\}_{t=1}^{t=2}\). The politician can choose any plan \(d_t\) at time t but, given that \(d_t\) is contingent on all relevant information up to time t, this plan is no different than the one he would have chosen at the beginning of the game. Likewise, this assumption poses no time consistency problems.
The politician would get more if \(\theta = 1\) at either of the two new periods, which happens with probability \(\frac{3}{4}\). In this case, the politician would get a higher payoff this term and, on top of that, he is re-elected again.
Note that \(\beta < \frac{3 - 2q}{q (11-8q) - 2}\) implies \(3 + 2\beta - q(2+11\beta - 8 \beta q) > 0\) and, hence, the continuity in \(\bar{\alpha }\).
References
Acemoglu D, Robinson J (2012) Why nations fail: the origins of power, prosperity and poverty. Profile books. https://profilebooks.com/why-nations-fail.html
Alesina A (1998) Credibility and policy convergence in a two-party system with rational voters. Am Econ Rev 78(4):796–805
Aragonès E, Postlewaite E, Palfrey T (2007) Political reputations and campaign promises. J Eur Econ Assoc 5(4):846–884
Barro R (1973) The control of politicians: an economic model. Public Choice 14(1):19–42
Bernhardt D, Campuzano L, Squintani F, Câmara O (2009) On the benefits of party competition. Games Econ Behav 66:685–707
Bernhardt D, Câmara O, Squintani F (2011) Competence and ideology. Rev Econ Stud 78:487–522
Besley T, Burgess R (2002) The political economoy of goverment responsiveness: theory and evidence from India. Q J Econ 117(4):1415–1451
Bueno de Mesquita E, Landa D (2014) Moral hazard and sequential policy making. Working paper
Downs A (1957) An economic theory of democracy. Harper & Row, New York
Ferejohn J (1986) Incumbent performance and electoral control. Public Choice 50(1–3):5–25
Ferraz C, Finan F (2005) Reelection incentives and political corruption: evidence from Brazilian Audit Reports. Working paper
Pettersson-Lidbom P (2006) Testing political agency models. Working paper
Rivas J (2014) Private agenda and re-election incentives. University of Bath Working Paper 14/13
Sarafidis Y (2007) What have you done for me lately? Relase of information and strategic manipulation of memories. Econ J 117:307–326
Smart M, Sturm D (2007) Do politicians respond to re-election incentives? Evidence from gubernatorial elections. Working paper
Van Weelden R (2013) Candidates, credibility, and re-election incentives. Rev Econ Stud 1:1–32
Author information
Authors and Affiliations
Corresponding author
Additional information
I would like to thank two anonymous referees, the editor, seminar participants at the Universidad Carlos III and the University of Sheffield and members of the Theory Research Group at the University of Bath for very useful comments and suggestions.
Appendix: Proofs
Appendix: Proofs
Proof of lemma 1
Let \(U_E(S)\) be the value of \(U_E\) when a certain plan
is employed. If the politician employs plan HH then it is true that
Which implies
Proceeding in a similar fashion, we have that
If the politician employs plan \(HC_w\) then it is true that
Hence, we have the following:
Thus, proceeding as above
Notice now that \(q \in \left[ \frac{1}{2}, 1 \right] \) implies \(q(2-q) \ge \frac{1+q}{2} \ge \frac{3}{4}\). Therefore, if \(q + \frac{\alpha }{2} \ge \alpha + \frac{1}{2}\) then we have \(U_E(HH) \ge U_E(HD) = U_E(DH)\), \(U_E(HH) \ge U_E(HC_r)\) and \(U_E(HH) \ge U_E(DC_r)\). Similarly, if \(q + \frac{\alpha }{2} \le \alpha + \frac{1}{2}\) then \(U_E(HC_w) \ge U_E(HC_r)\) , \(U_E(DC_w) \ge U_E(HD) = U_E(DH)\), and \(U_E(DD) \ge U_E(DC_r)\). \(\square \)
Proof of Theorem 1
Given the result in lemma 1, it is true that
Recall that
We need to check the conditions on q, \(\beta \) and \(\alpha \) under which each of the four different plans above is optimal. We separate the proof in six parts:
Part 1
Plan HH
Since \(q(2-q) \ge \frac{1+q}{2} \ge \frac{3}{4}\) then \(q + \frac{\alpha }{2} \ge \alpha + \frac{1}{2}\) implies
Thus, if \(q + \frac{\alpha }{2} \ge \alpha + \frac{1}{2}\) then the plan HH is optimal. Moreover, if \(q + \frac{\alpha }{2} \le \alpha + \frac{1}{2}\) then it is easy to see that the plan \(HC_w\) gives more payoff than the plan HH. Thus, the plan HH is optimal if and only if \(q + \frac{\alpha }{2} \ge \alpha + \frac{1}{2}\), which can be rewritten as \(\alpha \le 2q - 1\).
Part 2
Plans \(HC_w\), \(DC_w\) and DD
We proceed by showing first the conditions under which \(U_E(HC_w) \ge U_E(DC_w)\), then we show the conditions under which \(U_E(DD) > U_E(DC_w)\). Finally we prove that if \(U_E(HC_w) \ge U_E(DC_w)\) then \(U_E(HC_w) \ge U_E(DD)\) and that if \(U_E(DD) > U_E(DC_w)\) then \(U_E(DD) > U_E(HC_w)\).
Part 3
Conditions for \(U_E(HC_w) \ge U_E(DC_w)\)
We have that \(U_E(HC_w) \ge U_E(DC_w)\) if and only if
Solving for \(\alpha \), this can be rewritten as
Note now that the expression on the right hand-side is always positive: the minimum of \(q(8 + \beta - q(4+2\beta )) - 3\) is achieved at \(\beta = 0\) and \(q = \frac{1}{2}\) and for those values \(q(8 + \beta - q(4+2\beta )) - 3 = 0\).
Consider now that \(3 + 2\beta - q(2+11\beta - 8 \beta q) \le 0\), then the condition in (1) is satisfied for any \(\alpha \). We have that \(3 + 2\beta - q(2 + 11\beta - 8 \beta q) \le 0\) if and only if \(\beta \ge \frac{3 - 2q}{q (11-8q) - 2}\). Hence, \(U_E(HC_w) \ge U_E(DC_w)\) if \(\beta \le \frac{3 - 2q}{q (11-8q) - 2}\).
Assume now that \(3 + 2\beta - q(2+11\beta - 8 \beta q) > 0\). In this case from Eq. (1) we obtain
Hence, if and only if either the inequality above or \(\beta \ge \frac{3 - 2q}{q (11-8q) - 2}\) is satisfied, we have that \(U_E(HC_w) \ge U_E(DC_w)\).
Part 4
Conditions for \(U_E(DD) > U_E(DC_w)\)
We have that \(U_E(DD) > U_E(DC_w)\) if and only if
Solving for \(\alpha \), this can be rewritten as
Note now that the expression on the right hand-side of (2) is always positive: \(q(8+2\beta ) - \beta - 4 = (4 + \beta ) (2q - 1) \ge 0\). Thus, in order for Eq. (2) to be possible, it must be that its left hand side is positive: \(4 + 5 \beta - 16 \beta q > 0\). This happens if and only if \(\beta < \frac{4}{16q-5}\).
Thus, we have that \(U_E(DD) > U_E(DC_w)\) if and only if \(\beta < \frac{4}{16q-5}\) and, from Eq. (2),
Part 5
\(U_E(HC_w) \ge U_E(DC_w)\) implies \(U_E(HC_w) \ge U_E(DD)\)
Assume first that \(U_E(HC_w) \ge U_E(DC_w)\) and \(\beta \ge \frac{3 - 2q}{q (11-8q) - 2}\). We have that \(\beta \ge \frac{3 - 2q}{q (11-8q) - 2}\) implies \(\beta \ge \frac{4}{16q-5}\). This is because
if and only if \(q \ge \frac{1}{2}\), which is true in our case.
Since \(\beta \ge \frac{4}{16q-5}\) implies that \(U_E(DD) \le U_E(DC_w)\) (see part 4 of the proof), we have that \(U_E(HC_w) \ge U_E(DC_w)\) and \(\beta \ge \frac{3 - 2q}{q (11-8q) - 2}\) implies \(U_E(HC_w) \ge U_E(DD)\).
Assume now that \(U_E(HC_w) \ge U_E(DC_w)\) but \(\beta < \frac{3 - 2q}{q (11-8q) - 2}\). In this case, we must have (see part 3 of the proof)
We now show that the inequality above together with \(\beta < \frac{4}{16q-5}\) (necessary condition for \(U_E(DD) > U_E(DC_w)\)) implies
and, hence, \(U_E(DD) \le U_E(DC_w)\).
We have that
if and only if
Since \(2q-1 \ge 0\), \((2+\beta )q-3 \le 0\) and \(\beta (16q-5)-4 < 0\) given that \(\beta < \frac{4}{16q-5}\), the inequality above is true. Hence, whenever \(U_E(HC_w) \ge U_E(DC_w)\) we have \(U_E(DD) \le U_E(DC_w)\) as required. Therefore, plan \(HC_w\) is optimal if and only if plan HH is not optimal (\(\alpha < 2q - 1\)) and the conditions for \(U_E(HC_w) \ge U_E(DC_w)\) are satisfied.
Part 6
\(U_E(DD) > U_E(DC_w)\) implies \(U_E(DD) > U_E(HC_w)\)
If \(U_E(DD) > U_E(DC_w)\) then it must be that \(\beta < \frac{4}{16q-5}\) and
However, as shown in part 5, this implies that
Which in turn implies that \(U_E(HC_w) < U_E(DC_w)\). Thus, \(U_E(DD) > U_E(DC_w)\) implies \(U_E(HC_w) < U_E(DC_w)\).
Note that the condition
can be rewritten as \(\beta (-8q^2 + 6q - 1) < 0\), which is true for any \(q \ge \frac{1}{2}\). Hence, whenever \(U_E(DD) > U_E(DC_w)\) it is true that \(\alpha > 2q-1\) and, thus, plan HH is not optimal.
Summing up, if \(U_E(DD) > U_E(DC_w)\) then \(U_E(HC_w) < U_E(DC_w)\) and plan HH is not optimal. Therefore, plan DD is optimal if and only if the conditions for \(U_E(DD) > U_E(DC_w)\) are satisfied. \(\square \)
Proof of Result 1
The politician is honest for as long as he has not guaranteed himself re-election if he is honest in period 1 (before period 1 is resolved he has not had the chance to secure re-election yet) and if he is honest in period 2 at least in the situations where he did not take the public decision in period 1. Thus, we have to show that there are values of q and \(\beta \) for which for any value of \(\alpha \) either the plan HH or the plan \(HC_w\) are optimal.
Assume first that \(\alpha \le 2q - 1\). By Theorem 1 the optimal plan is HH, which means that the politician is honest in both periods.
Assume now that \(\alpha > 2q - 1\). If \(\beta \ge \frac{3 - 2q}{q (11-8q) - 2}\) then by Theorem 1 the optimal plan is \(HC_w\) which means that the politician is honest in the first period and honest again in the second period if he did not take the public decision in the first period. Note that \(\beta \ge \frac{3 - 2q}{q (11-8q) - 2}\) is only possible if \(q \ge \frac{5}{8}\) as otherwise \(\frac{3 - 2q}{q (11-8q) - 2} > 1\). This completes the proof. \(\square \)
Proof of Result 2
Assume that \(\beta < \frac{3 - 2q}{q (11-8q) - 2}\). By Theorem 1 we have that in this case \(HC_w\) is the optimal plan if and only if
We now show that the right hand side of this expression is increasing in q at \(q = \frac{1}{2}\) and decreasing in q at \(q = 1\) for \(\beta \ge \frac{1}{4}\). By continuity this means that the value of \(\alpha \) for which \(HC_w\) is the optimal plan is non-monotonic in q.
The sign of the derivative of
with respect to q is equal to the sign of
The expression above evaluated at \(q = 1\) equals \(2 (1-\beta ) (1-4\beta )\) which is negative if \(\beta > \frac{1}{4}\). The expression above evaluated at \(q = \frac{1}{2}\) equals \((4-\beta ) (2 - \frac{3}{2} \beta )\), which is positive. Thus, since the expression \(\bar{\alpha }(q, \beta )\) is continuous in q then the region above its graph is non-convex for \(\beta > \frac{1}{4}\), which proves that the value of \(\alpha \) for which \(HC_w\) is the optimal plan can be non-monotonic in q.Footnote 10
Figure 2 shows that the assumptions imposed on the parameters of the model in this proof are non-empty and, thus, the monotonicity can indeed exist. \(\square \)
Rights and permissions
About this article

Cite this article
Rivas, J. Private agenda and re-election incentives. Soc Choice Welf 46, 899–915 (2016). https://doi.org/10.1007/s00355-015-0941-0
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00355-015-0941-0