
Abstract
Autism spectrum disorders (ASDs) are a group of neurodevelopmental disorders, characterized by impairment in communication and social interactions, and by repetitive behaviors. ASDs are highly heritable, and estimates of the number of risk loci range from hundreds to >1000. We considered 7 extended families (size 12–47 individuals), each with ≥3 individuals affected by ASD. All individuals were genotyped with dense SNP panels. A small subset of each family was typed with whole exome sequence (WES). We used a 3-step approach for variant identification. First, we used family-specific parametric linkage analysis of the SNP data to identify regions of interest. Second, we filtered variants in these regions based on frequency and function, obtaining exactly 200 candidates. Third, we compared two approaches to narrowing this list further. We used information from the SNP data to impute exome variant dosages into those without WES. We regressed affected status on variant allele dosage, using pedigree-based kinship matrices to account for relationships. The p value for the test of the null hypothesis that variant allele dosage is unrelated to phenotype was used to indicate strength of evidence supporting the variant. A cutoff of p = 0.05 gave 28 variants. As an alternative third filter, we required Mendelian inheritance in those with WES, resulting in 70 variants. The imputation- and association-based approach was effective. We identified four strong candidate genes for ASD (SEZ6L, HISPPD1, FEZF1, SAMD11), all of which have been previously implicated in other studies, or have a strong biological argument for their relevance.

Similar content being viewed by others

Abbreviations
- ASD:
-
Autism spectrum disorder
- WES:
-
Whole exome sequencing
- ADOS:
-
Autism Diagnostic Observational Schedule
- ADI-R:
-
Autism Diagnostic Interview – Revised
- BPASS:
-
Broader Phenotype Autism Symptom Scale
- BAP:
-
Broader autism phenotype
- OE:
-
Illumina HumanOmniExpress
- HCE:
-
Illumina Human Core Exome
- 1KGP-EUR:
-
1,000 genome project Europeans
- IV:
-
Inheritance vectors
- MCMC:
-
Markov chain Monte Carlo
References
Adzhubei IA et al (2010) A method and server for predicting damaging missense mutations. Nat Methods 7:248–249. doi:10.1038/nmeth0410-248
American Psychiatric Association (2013) Diagnostic and statistical manual, 5th edn. American Psychiatric Association, Washington, DC
Anderson GR, Galfin T, Xu W, Aoto J, Malenka RC, Sudhof TC (2012) Candidate autism gene screen identifies critical role for cell-adhesion molecule CASPR2 in dendritic arborization and spine development. Proc Natl Acad Sci USA 109:18120–18125. doi:10.1073/pnas.1216398109
Ashburner M et al (2000) Gene ontology: tool for the unification of biology. Gene Ontol Consort Nat Genet 25:25–29. doi:10.1038/75556
Becker EB, Stoodley CJ (2013) Autism spectrum disorder and the cerebellum. Int Rev Neurobiol 113:1–34. doi:10.1016/B978-0-12-418700-9.00001-0
Berg JM, Geschwind DH (2012) Autism genetics: searching for specificity and convergence. Genome Biol 13:247. doi:10.1186/gb4034
Bishop DVM (1998) Development of the children’s communication checklist (CCC): a method for assessing qualitative aspects of communicative impairment in children. J Child Psychol Psychiatry 39:879–891
Buescher AV, Cidav Z, Knapp M, Mandell DS (2014) Costs of autism spectrum disorders in the United Kingdom and the United States. JAMA Pediatr 168:721–728. doi:10.1001/jamapediatrics.2014.210
CDC (2014) Morbidity and mortality weekly report: prevalence of autism spectrum disorder among children aged 8 years—autism and developmental disabilities monitoring network, 11 Sites, United States, 2010 vol 63 (SS02)
Chahrour MH et al (2012) Whole-exome sequencing and homozygosity analysis implicate depolarization-regulated neuronal genes in autism. PLoS Genet 8:e1002635. doi:10.1371/journal.pgen.1002635
Chapman NH et al (2011) Genome-scan for IQ discrepancy in autism: evidence for loci on chromosomes 10 and 16. Hum Genet 129:59–70
Cheung CYK, Thompson EA, Wijsman EM (2013) GIGI: An approach to effective imputation of dense genotypes on large pedigrees. Am J Hum Genet 92:504–516
Cheung CYK, Blue EM, Wijsman EM (2014) A statistical framework to guide sequencing choices in pedigrees. Am J Hum Genet 94:257–267
Cohen M (1997) Children’s memory scale. Pearson
Constantino JN (2012) Social responsiveness scale, 2nd edn. Western Psychological Services, Los Angeles
Cooper GM, Stone EA, Asimenos G, Program NCS, Green ED, Batzoglou S, Sidow A (2005) Distribution and intensity of constraint in mammalian genomic sequence. Genome Res 15:901–913
Cukier HN et al (2014) Exome sequencing of extended families with autism reveals genes shared across neurodevelopmental and neuropsychiatric disorders Mol. Autism 5:1. doi:10.1186/2040-2392-5-1
Dawson G, Estes A, Munson J, Schellenberg G, Bernier R, Abbott R (2007) Quantitative assessment of autism symptom-related traits in probands and parents: broader Phenotype Autism Symptom Scale. J Autism Dev Disord 37:523–536. doi:10.1007/s10803-006-0182-2
Derkach A et al (2014) Association analysis using next-generation sequence data from publicly available control groups: the robust variance score statistic. Bioinformatics 30:2179–2188. doi:10.1093/bioinformatics/btu196
Dunn W (1999) Sensory profile. Pearson
Fajardo et al (2011) Detecting false positive signals in exome sequencing. Human Mutation 33(4):609–613
Fatemi SH et al (2012) Consensus paper: pathological role of the cerebellum in autism. Cerebellum 11:777–807. doi:10.1007/s12311-012-0355-9
Glessner JT et al (2009) Autism genome-wide copy number variation reveals ubiquitin and neuronal genes. Nature 459:569–573
Gratten J, Visscher PM, Mowry BJ, Wray NR (2013) Interpreting the role of de novo protein-coding mutations in neuropsychiatric disease. Nat Genet 45:234–238. doi:10.1038/ng.2555
Gunnersen JM et al (2007) Sez-6 proteins affect dendritic arborization patterns and excitability of cortical pyramidal neurons. Neuron 56:621–639
Gunnersen JM, Kuek A, Phipps JA, Hammond VE, Puthussery T, Fletcher EL, Tan SS (2009) Seizure-related gene 6 (Sez-6) in amacrine cells of the rodent retina and the consequence of gene deletion. PLoS One 4:e6546. doi:10.1371/journal.pone.0006546
Huang QQ, Shete S, Amos CI (2004) Ignoring linkage disequilibrium among tightly linked markers induces false-positive evidence of linkage for affected sib pair analysis. Am J Hum Genet 75:1106–1112
Hubbard TJ et al (2007) Ensembl 2007. Nucleic Acids Res 35:D610–D617
Human Protein Atlas http://proteinatlas.org (2014)
IBDgraph 2.0: another C-library add-on for MORGAN 3 http://www.stat.washington.edu/thompson/Genepi/pangaea.shtml (2010)
IMGSAC (2001) A genomewide screen for autism: strong evidence for linkage to chromosomes 2q, 7q, and 16p. Am J Hum Genet 69:570–581
Jin G et al (2013) Identification and characterization of novel alternative splice variants of human SAMD11. Gene 530:215–221 doi:10.1016/j.gene.2013.08.033
Kent WJ, Sugnet CW, Furey TS, Roskin KM, Pringle TH, Zahler AM, Haussler D (2002) The human genome browser at UCSC. Genome Res 12:996–1006
Konyukh M et al (2011) Variations of the candidate SEZ6L2 gene on Chromosome 16p11.2 in patients with autism spectrum disorders and in human populations. PLoS One 6:e17289. doi:10.1371/journal.pone.0017289
Kumar P, Henikoff S, Ng PC (2009a) Predicting the effects of coding non-synonymous variants on protein function using the SIFT algorithm. Nat Protoc 4:1073–1081. doi:10.1038/nprot.2009.86
Kumar RA et al (2009b) Association and mutation analyses of 16p11.2 autism candidate genes. PLoS One 4:e4582. doi:10.1371/journal.pone.0004582
Lander ES, Green PJ (1987) Construction of multilocus genetic maps in humans. Proc Natl Acad Sci USA 84:2363–2367
Li H, Durbin R (2010) Fast and accurate long-read alignment with burrows-wheeler transform. Bioinformatics 26:589–595. doi:10.1093/bioinformatics/btp698
Li H et al (2009) The sequence alignment/map format and SAMtools. Bioinformatics 25:2078–2079. doi:10.1093/bioinformatics/btp352
Lord C, Rutter M, DiLavore PC, Risi S, Gotham K, Bishop SL (2012) ADOS-2: autism diagnostic observation schedule, 2nd edn. Western Psychological Services, Torrance
Maestrini E et al (2010) High-density SNP association study and copy number variation analysis of the AUTS1 and AUTS5 loci implicate the IMMP2L-DOCK4 gene region in autism susceptibility. Mol Psychiatry 15:954–968. doi:10.1038/mp.2009.34
Marshall CR et al (2008) Structural variation of chromosomes in autism spectrum disorder. Am J Hum Genet 82:477–488
Matise TC et al (2007) A second-generation combined linkage-physical map of the human genome. Genom Res 17:1783–1786
McKenna A et al (2010) The Genome Analysis Toolkit: a MapReduce framework for analyzing next-generation DNA sequencing data. Genome Res 20:1297–1303. doi:10.1101/gr.107524.110
MORGAN: A package for Markov chain Monte Carlo in genetic analysis (version 3.1.1) http://www.stat.washington.edu/thompson/Genepi/MORGAN/Morgan.shtml (2012)
MORGAN: a package for Markov chain Monte Carlo in genetic analysis (version 3.2) http://www.stat.washington.edu/thompson/Genepi/MORGAN/Morgan.shtml (2013)
Mulley JC, Iona X, Hodgson B, Heron SE, Berkovic SF, Scheffer IE, Dibbens LM (2011) The Role of Seizure-Related SEZ6 as a Susceptibility Gene in Febrile Seizures Neurol Res Int 2011:917565 doi:10.1155/2011/917565
Nair A, Treiber JM, Shukla DK, Shih P, Muller RA (2013) Impaired thalamocortical connectivity in autism spectrum disorder: a study of functional and anatomical connectivity. Brain 136:1942–1955. doi:10.1093/brain/awt079
Nato AQ, Chapman NH, Cheung CYK, Brkanac Z, Wijsman EM (2013) PBAP: A pipeline for family-based quality control of pedigree structures and dense genetic marker data. Paper presented at the ASHG 63rd Annual Meeting, Boston, MA
Neale BM et al (2012) Patterns and rates of exonic de novo mutations in autism spectrum disorders. Nature 485:242–245. doi:10.1038/nature11011
Ng SB et al (2009) Targeted capture and massively parallel sequencing of 12 human exomes. Nature 461:272
O’Connell JR, Weeks DE (1995) The VITESSE algorithm for rapid exact multilocus linkage analysis via genotype set-recoding and fuzzy inheritance. Nat Genet 11:402–408
O’Roak BJ et al (2012) Sporadic autism exomes reveal a highly interconnected protein network of de novo mutations. Nature 485:246–250. doi:10.1038/nature10989
Ozonoff S et al (2011) Recurrence risk for autism spectrum disorders: a Baby Siblings Research Consortium study. Pediatrics 128:e488–e495. doi:10.1542/peds.2010-2825
Picard Tools: a set of Java command line tools for manipulating high-throughput sequencing data and formats. http://broadinstitute.github.io/picard/ (2014)
Rosenbloom KR et al (2013) ENCODE data in the UCSC Genome Browser: year 5 update. Nucleic Acids Res 41:D56–D63. doi:10.1093/nar/gks1172
Rutter M, Folstein S (1995) Modified autism family history interview for developmental disorders of cognition and social functioning. The Johns Hopkins University School of Medicine, Baltimore
Rutter M, LeCouteur A, Lord C (2003) Autism diagnostic interview revised, WPS edn. Manual. Western Psychological Services, Los Angeles
Saad M, Wijsman EM (2014) Power of family-based association designs to detect rare variants in large pedigrees using imputed genotypes. Genet Epidemiol 38:1–9
Sanders SJ et al (2011) Multiple recurrent de novo CNVs, including duplications of the 7q11.23 Williams syndrome region, are strongly associated with autism. Neuron 70:863–885. doi:10.1016/j.neuron.2011.05.002
Sanders SJ et al (2012) De novo mutations revealed by whole-exome sequencing are strongly associated with autism. Nature 485:237–241. doi:10.1038/nature10945
Sarason B, Sarason I, Hacker A, Basham R (1985) Concomitants of social support: social skills, physical attractiveness, and gender. J Pers Soc Psychol 49:469–480
Schellenberg GD et al (2006) Evidence for multiple loci from a genome scan of autism kindreds. Molecular Psychiatry 11:1049–1060
Shi L et al (2013) Whole-genome sequencing in an autism multiplex family Mol. Autism 4:8. doi:10.1186/2040-2392-4-8
Shimizu T, Hibi M (2009) Formation and patterning of the forebrain and olfactory system by zinc-finger genes Fezf1 and Fezf2. Dev Growth Differ 51:221–231. doi:10.1111/j.1440-169X.2009.01088.x
Shimizu-Nishikawa K, Kajiwara K, Kimura M, Katsuki M, Sugaya E (1995) Cloning and expression of SEZ-6, a brain-specific and seizure-related cDNA. Brain Res Mol Brain Res 28:201–210
SIFT http://sift.jcvi.org (2014)
Sparrow S, Cichetti D, Balla D (2005) Vineland adaptive behavior scales, 2nd edn. Pearson, Bloomington
Spence SJ, Schneider MT (2009) The role of epilepsy and epileptiform EEGs in autism spectrum disorders. Pediatr Res 65:599–606. doi:10.1203/PDR.0b013e31819e7168
Stamova BS, Tian Y, Nordahl CW, Shen MD, Rogers S, Amaral DG, Sharp FR (2013) Evidence for differential alternative splicing in blood of young boys with autism spectrum disorders. Mol Autism 4:30. doi:10.1186/2040-2392-4-30
Toma C et al (2014) Exome sequencing in multiplex autism families suggests a major role for heterozygous truncating mutations. Mol Psychiatry 19:784–790. doi:10.1038/mp.2013.106
Uhlen M et al (2010) Towards a knowledge-based Human Protein Atlas. Nat Biotechnol 28:1248–1250. doi:10.1038/nbt1210-1248
Wagner R, Torgesen J, Rashotte C (1999) Comprehensive test of phonological processing (CTOPP). Western Psychological Services, Los Angeles
Wechsler D (1981) Wechsler adult intelligence scale—revised (WAIS-R)
Wechsler D (1989) WPPSI-R manual: Wechsler preschool and primary scale of intelligence, revised
Wechsler D (1992) Wechsler intelligence scale for children, 3rd edn. (WISC-III)
Wechsler D (1997) Wechsler memory scale for adults, 3rd edn. The Psychological Corporation, San Antonio
Wijsman EM (2012) The role of large pedigrees in an era of high-throughput sequencing. Hum Genet 131:1555–1563. doi:10.1007/s00439-012-1190-2
Xu C et al (2013) Polymorphisms in seizure 6-like gene are associated with bipolar disorder I: evidence of gene x gender interaction. J Affect Disord 145:95–99. doi:10.1016/j.jad.2012.07.017
Yu ZL et al (2007) Febrile seizures are associated with mutation of seizure-related (SEZ) 6, a brain-specific gene. J Neurosci Res 85:166–172. doi:10.1002/jnr.21103
Acknowledgments
Research reported in this publication was supported by funding from the National Institute of Mental Health, and the National Institute on Aging, under award numbers R01MH092367, R01MH094293, R01MH094400, and R00AG040184 from the National Institutes of Health. The content is solely the responsibility of the authors and does not necessarily represent the official views of the National Institutes of Health. We would like to thank those with ASD and their families, because without their participation this research would not be possible.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Ethical approval
“All procedures performed in studies involving human participants were in accordance with the ethical standards of the institutional and/or national research committee and with the 1964 Helsinki declaration and its later amendments or comparable ethical standards.”
Electronic supplementary material
Below is the link to the electronic supplementary material.
Appendix
Appendix
Marker selection for linkage analysis
We used the marker subpanels program of the PBAP suite (Nato et al. 2013), with the following parameters: minimum intermarker distance 0.5 cM, marker completion threshold 80 %, minor allele frequency >20 %, maximum linkage disequilibrium (r 2) between markers 0.04. We used allele frequencies and linkage disequilibrium estimates from the 1KGP-EUR population, and maps based on the sex-averaged Rutgers map (Matise et al. 2007). Map locations were converted from those based on the Kosambi map function in the Rutgers map to those based on the Haldane map function. This was necessary because of the implicit assumptions in the multipoint analysis imposed by use of the Lander–Green algorithm (Lander and Green 1987).
Linkage analysis
Our approach to linkage analysis in these families was to use sampled inheritance vectors (IVs) as a basis for analysis. The set of IVs at a particular genomic position represents possible paths of descent of the chromosomes at that position through the pedigree. The sampled IVs are drawn from the posterior distribution of IVs, conditional on marker information, family structure and genetic map, at each marker location along each chromosome. For the smallest pedigree, we sampled IVs from the exact posterior distribution, and for the larger pedigrees we used Markov chain Monte Carlo (MCMC) sampling. Using the sampled IVs as a basis for analysis enabled us to perform chromosome wide multipoint pedigree-based linkage analysis, even in our larger families. The same samples of IVs were also used for genotype imputation from the sequence data.
Linkage analysis from the IVs followed three steps. First, we sampled IVs for each chromosome and family combination using the program gl_auto from the MORGAN (MORGAN: A package for Markov chain Monte Carlo in genetic analysis (version 3.1.1) http://www.stat.washington.edu/thompson/Genepi/MORGAN/Morgan.shtml 2012) package, saving 1,000 IV samples for analysis. For MCMC sampling, 50,000 scans were performed with each run using sequential imputation for setup, and the LMM sampler with 50 % L-sampler. We used allele frequencies based on each dataset, except in the families typed with CE alone, where we used the 1KGP-EUR frequencies. These families are generally well genotyped, and therefore we do not expect the results to be sensitive to the source of allele frequencies (Huang et al. 2004). Second, we identified equivalence classes among the sampled IVs at each marker, using the program IBDgraph (IBDgraph 2.0: another C-library add-on for MORGAN 3 http://www.stat.washington.edu/thompson/Genepi/pangaea.shtml 2010). Identifying equivalence classes allows computations to be performed on one representative of each class, rather than on all 1,000 samples. Finally, we performed linkage analyses using FASTLINK (O’Connell and Weeks 1995) for one representative of each equivalence class, and calculated likelihoods by a weighted average over equivalence classes, where the weights are the sampled probabilities of the classes. Since these analyses were done, the MORGAN program gl_lods has been released (MORGAN: A package for Markov chain Monte Carlo in genetic analysis (version 3.2) http://www.stat.washington.edu/thompson/Genepi/MORGAN/Morgan.shtml 2013), which carries out the analyses directly from the output of gl_auto. In future, it will not be necessary to use FASTLINK for this type of analysis.
Imputation of exome variant dosages
GIGI uses the IVs generated by gl_auto for the entire family based on the SNP genotypes, in addition to exome variant genotypes in available individuals, to calculate the expected dosage of the variant allele in each person in the family. The frequencies of the alternate alleles were taken from the 1KGP-EUR population, unless the allele was absent from that dataset, in which case it was set to 0.01. Sex-averaged map positions were converted to positions based on the Haldane map function, as described above. In cases where variants did not appear in the Rutgers map, map position was interpolated based on physical position.
Example of imputation and association results
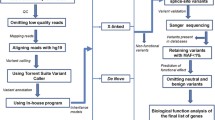
Table 6 shows the results of imputation and subsequent association tests for family AU071, as an example. AU071 is interesting because we imputed variant dosages in multiple unaffected individuals, and there are examples of the imputed dosage being very clear, as well as examples where the dosage was more ambiguous. Variant allele dosages are italicized if they are based on imputation, and not if they are directly observed. The table lists the 18 variants that pass the filters based on linkage analysis, frequency and function, and also have a Mendelian segregation pattern. There is an additional variant where the observed segregation pattern was not obviously Mendelian (pattern = ’no’), due to missing genotypes because of low read depth in affected individuals. For this variant (chr 1 pos 877,523), no copies of the alternate allele are imputed in unaffected individuals, but the status of two affected individuals (A3 and A4) remains ambiguous (imputed dosage = 0.5). Sanger sequencing clarified that both A3 and A4 carry a single copy of the variant, making this variant a very good candidate gene for ASD in this family. Even without taking into account the Sanger results, this is the only variant where the p value is ≤0.05, so the imputation and association-based results represent a substantially reduced set of variants relative to those based on requiring a Mendelian segregation pattern in affected individuals with WES only. Online Resource 3 shows detailed results similar to Table 6 for each of the seven families studied.
Rights and permissions
About this article

Cite this article
Chapman, N.H., Nato, A.Q., Bernier, R. et al. Whole exome sequencing in extended families with autism spectrum disorder implicates four candidate genes. Hum Genet 134, 1055–1068 (2015). https://doi.org/10.1007/s00439-015-1585-y
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00439-015-1585-y