
Abstract
The cost of data movement over the PCI Express bus is one of the biggest performance bottlenecks for accelerating data-intensive applications on traditional discrete GPU architectures. To address this bottleneck, AMD Fusion introduces a fused architecture that tightly integrates the CPU and GPU onto the same die and connects them with a high-speed, on-chip, memory controller. This novel architecture incorporates shared memory between the CPU and GPU, thus enabling several techniques for inter-device data transfer that are not available on discrete architectures. For instance, a kernel running on the GPU can now directly access a CPU-resident memory buffer and vice versa.
In this paper, we seek to understand the implications of the fused architecture on CPU-GPU heterogeneous computing by systematically characterizing various memory-access techniques instantiated with diverse memory-bound kernels on the latest AMD Fusion system (i.e., Llano A8-3850). Our study reveals that the fused architecture is very promising for accelerating data-intensive applications on heterogeneous platforms in support of supercomputing.







Similar content being viewed by others

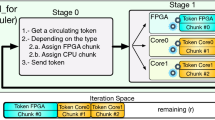

Notes
When using CPU-Resident memory, the Garlic route can be accessed using the CL_MEM_(READ/WRITE)_ONLY flags when using the clCreateBuffer function.
References
Aji A, Daga M, Feng W (2011) Bounding the effect of partition camping in GPU kernels. In: 8th ACM int’l conference on computing frontiers. doi:http://doi.acm.org/10.1145/2016604.2016637
Baghsorkhi S, Delahaye M, Patel S, Gropp W, Hwu W (2010) An adaptive performance modeling tool for GPU architectures. ACM SIGPLAN Not 45:105–114. doi:http://doi.acm.org/10.1145/1837853.1693470
Boudier P, Sellers G (2011) Memory system on fusion APUs: The benefits of zero copy. In: AMD Fusion developer summit, AMD. http://developer.amd.com/afds/assets/presentations/1004_final.pdf
Che S, Boyer M, Meng J, Tarjan D, Sheaffer J, Skadron K (2008) A performance study of general-purpose applications on graphics processors using cuda. J Parallel Distrib Comput. doi:10.1016/j.jpdc.2008.05.014
Che S, Boyer M, Meng J, Tarjan D, Sheaffer JW, Lee S-H, Skadron K (2009) Rodinia: A benchmark suite for heterogeneous computing. In: IEEE int’l symp. on workload characterization. doi:10.1109/IISWC.2009.5306797
Daga M, Scogland T, Feng W (2011) Architecture-aware mapping and optimization on a 1600-core GPU. In: IEEE int’l conf. on parallel and distributed systems
Danalis A, Marin G, McCurdy C, Meredith J, Roth P, Spafford K, Tipparaju V, Vetter J (2010) The scalable heterogeneous computing (shoc) benchmark suite. In: 3rd workshop on general-purpose computation on graphics processing units. doi:10.1145/1735688.1735702
Gutta S, Foley D, Naini A, Wasmuth R, Cherepacha D (2011) In: Int’l solid-state circuits conference digest of technical papers. doi:10.1109/ISSCC.2011.5746314
Hong S, Kim H (2009) An analytical model for a GPU architecture with memory-level and thread-level parallelism awareness. Comput Archit News 37:152–163. doi:10.1145/1555815.1555775
Khronos Group (2008) The khronos group releases opencl 1.0 specification
Ryoo S, Rodrigues C, Stone S, Baghsorkhi S, Ueng S, Hwu W (2007) Program optimization study on a 128-core GPU. In: 1st workshop on general purpose processing on graphics processing units
Ryoo S, Rodrigues C, Baghsorkhi S, Stone S, Kirk D, Hwu W (2008) Optimization principles and application performance evaluation of a multithreaded GPU using cuda. In: 13th ACM SIGPLAN symp. on principles and practice of parallel programming. doi:http://doi.acm.org/10.1145/1345206.1345220
Top500 (2011) http://www.top500.org/
Wong H, Papadopoulou MM, Sadooghi-Alvandi M, Moshovos A (2010) Demystifying GPU microarchitecture through microbenchmarking. In: IEEE Int’l symp. on performance analysis of systems software. doi:10.1109/ISPASS.2010.5452013
Author information
Authors and Affiliations
Corresponding author
Additional information
This work was supported in part by an AMD Research Faculty Fellowship and NSF grant IIP-0804155 for the NSF I/UCRC Center for High-Performance Reconfigurable Computing (CHREC).
Rights and permissions
About this article
Cite this article
Lee, K., Lin, H. & Feng, Wc. Performance characterization of data-intensive kernels on AMD Fusion architectures. Comput Sci Res Dev 28, 175–184 (2013). https://doi.org/10.1007/s00450-012-0209-1
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00450-012-0209-1