
Abstract
This paper presents a simple and robust feature descriptor method, namely local dominant orientation feature histogram (LDOFH). In this method, the discriminant histogram contains dominant orientation, and the corresponding relative energy value is obtained by calculating the direction and the amplitude of the gradient of each pixel over a local patch. The LM-NNDA (Yang et al. in Pattern Recognit 44:1387–1402, 2011) method based on the principal component analysis (PCA) method is finally employed to reduce the redundancy information and get the low-dimensional and discriminative features. We apply this descriptor on AR, IMM face image databases. Experimental results demonstrate the effectiveness of the proposed LDOFH method.
Similar content being viewed by others


Introduction
With the development of pattern recognition, many researchers focus on the topic of face recognition. Feature extraction is an important factor influencing the final classification results. The identity-preserving features are extracted through hierarchical nonlinear mappings. Good image representation features are expected to have high discriminative ability and robustness. During the recent decades, there have been a large amount of literature on developing traditional image feature-extraction methods, such as local binary patterns (LBPs) (Huang et al. 2011), LTP (Tan and Triggs 2010), scale-invariant feature transform (SIFT) (Lowe 2004), speeded-up robust features (SURF) (Bay et al. 2006), and histogram of oriented gradient (HOG) (Dalal and Triggs 2005). Recently deep learning-based methods have shown great success in face recognition (Zhu et al. 2013; Wen et al. 2016), but the complexity of deep learning-based methods is very high. Here, we mainly focus on hand-crafted feature descriptors, since these kinds of methods are very effective and efficient.
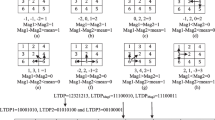
As can be seen, the gradient orientation of each pixel in a face image plays a more important role in the image feature extraction, such as Weber Local Descriptor (WLD) (Chen et al. 2010), SIFT (Lowe 2004), HOG (Bay et al. 2006), and histograms of the second-order gradients (HSOG) (Huang et al. 2014). In the above methods, the gradient orientation is calculated directly through the corresponding pixel points, but when there are changes in lighting conditions, noise, and other external factors, the information expressed by the gradient orientations is unstable. In view of this, Qian et al. (2013) proposed discriminative histograms of local dominant orientation (D-HLDO) method. First, D-HLDO adopts a PCA-based (Hotelling 1932; Belhumeur et al. 1997) method to obtain the dominant orientation and the corresponding energy value of each pixel in the face image. These two kinds of information contain a wealth of structural information, such as textures, edges, spots, and so on. Then, an image is divided into series of overlapping regions, and the 1D statistical histograms can be acquired by accumulating the relative energies of different dominant orientations on a local region. The histograms of all the regions are combined together to produce a high-dimensional feature with spatial information and local structural information. Finally, the local mean-based, nearest-neighbor discriminant analysis (LM-NNDA) method is used to get the low-dimensional and discriminative D-HLDO feature vector. However, the process of SVD in PCA is very time consuming, so in this paper, the dominant orientation and the corresponding energy value of each pixel were obtained by calculating the direction and the amplitude on the gradient map directly. Furthermore, we apply the LM-NNDA method to reduce dimension to get the low-dimensional and discriminative LDOFH feature. The steps of our image feature-extraction method are illustrated in Fig. 1. To show the effectiveness of the proposed LDOFH method in face recognition, we evaluate this method on two face databases: the AR and IMM face databases. Our method is nearly three times faster than Qian’s method while we obtain the approximate equal recognition rate.

An overview of our image feature-extraction method
The remainder of this paper is organized as follows. “Related work” briefly introduces the image feature-extraction method, D-HLDO, proposed by Qian; “LDOFH for feature extraction” develops our proposed image feature-extraction method, LDOFH and describes its merits. “Experiments” shows the experimental methodology and the results. “Conclusions and future work” offers the conclusions drawn and scope for future work.
Related work
The related work from Qian is introduced in this part. In D-HLDO method, the dominant orientation and the corresponding energy values are acquired by PCA.
Principal component analysis for local orientation and energy
In this section, we mainly introduce the PCA-based method to estimate the local gradient orientation. PCA is a special case of KL transform (Deprettere 1988). It minimizes the mean-square approximation error to get a set of optimal basis vectors. This can represent the given data with lower dimension. PCA can be achieved by eigenvalue decomposition of the data covariance matrix or singular value decomposition (SVD) of the data matrix. Here, we introduce the method SVD.
Specifically, the gradient matrix over a P × P window (w i ) around the interesting point (x, y) of an image is defined as
where g x (k) and g y (k) represent the gradients of the image at point (x, y) in x and y directions, respectively. We can get useful local information from the gradient matrix G of the local patch in this image. The local dominant orientation can be obtained by SVD on the gradient matrix G:
where U is a p × 2 matrix, V is a 2 × 2 matrix, S is a 2 × 2 diagonal matrix, and diagonal elements are singular values. The S matrix also expresses the energy values of the corresponding pixels in the dominant orientation and its perpendicular direction. First column of V gives the dominant orientation of the local gradient.
The dominant orientation of the local patch (overlapped) can be obtained through two steps. The first step is to use a gradient operator to estimate the gradient map of the entire image. The second step is to use the Eq. (3) to perform the SVD of matrix G i (G i is the gradient vectors matrix in the ith local patch), which can be obtained from the following formula:
Since v 1 = [v 1,1, v 1,2] contains the dominant orientation information in the local region, the angle θ i of the dominant orientation is defined as follows:
The singular values s 1, s 2 express the energy information, and the relative energy value of the dominant orientation in a local patch is defined as
where \(\lambda \;(\lambda \ge 0)\) is a regular parameter to avoid the denominator being zero and restrict the effect of noise.
The resulting matrix \(O = \left[ {\left( {\theta_{1} ,e_{1} } \right), \ldots \left( {\theta_{i} ,e_{i} } \right), \ldots \left( {\theta_{N} ,e_{N} } \right)} \right]^{\text{T}}\) contains dominant orientation and energy information of an image, and there are N pixels in the image.
Constructing histogram of local dominant orientation
The dominant orientation map and the corresponding energy map over the whole image can be achieved through the PCA method. Considering the local structural and spatial information, the dense spatial histogram represents a better representation. The dominant orientation map is divided into a series of overlapping rectangular regions \(R_{1} \ldots R_{L}\), where L is the number of divided regions. We build a 1D dominant orientation histogram on each region:
Each histogram contains b bins; for the unsigned gradient direction, each bin covers (180/b)°; and for the signed gradient direction, each bin covers (360/b)°. In the ith region, the energy value in the corresponding energy map is added to the histogram bin to which the dominant orientation of the point belongs. Finally, the histograms of all overlapping regions are connected as a high-dimensional feature vector, that is, HLDO features
LDOFH for feature extraction
Feature extraction plays an important role in exploring data by mapping the input data onto a space which reflects the inherent structure of the original data. In the mapped space, distinctive features are extracted from source data to represent the source data. In general, feature extraction is always considered as the preprocessing step which offers distinctive features for the following learning. An efficient feature-extracted method is proposed as followes.
The dominant orientation map and the energy map
The original image I(x, y) is smooth filtered with a Gaussian kernel function G(x, y, σ) to eliminate the noise. The processed image is defined as L(x, y, σ)—σ is the width parameter of Gaussian function. The gradient amplitude m(x, y) and the gradient direction θ(x, y) of each point are calculated from Eqs. (8) and (9), respectively:
We define the angle θ(x, y) (gradient direction) as the dominant orientation of the pixel, and the amplitude m(x, y) of the gradient is defined as the corresponding energy value of the point. Thus, one can get the orientation map and the corresponding energy map through this operation covering the whole image.
Constructing dense histogram as the extracted feature
In this part, the dense histogram is constructed to describe the spatial information and the local structure of the image in the same way adopted in D-HLDO. After getting the dominant orientation map and the corresponding energy map, we partition the dominant orientation map into a series of overlapping rectangular regions \(R_{1} \ldots R_{L}\), where L is the number of divided regions. We build a 1D dominant orientation histogram on each region:
The height of the histogram in the ith bin is obtained by accumulating the weights, that is, the corresponding energy values dominant orientation of which belongs to the same bin. Finally, the histograms of all overlapping regions are connected as a high-dimensional feature vector, that is, LDOFH features:
Obtaining the low-dimensional feature
The dimension of the histogram features extracted from the above method is very high because some redundant information is introduced, while rich structural features are obtained. This section introduces a LM-NNDA method to obtain a more efficient low-dimensional feature with more discriminative ability.
First, the PCA method (Wen et al. 2016) is used to reduce the data dimension. We can obtain the transformation matrix U of the data, and the reduced data are defined as follows:
After getting the low-dimensional data through PCA, LM-NNDA is adopted to make the data more distinguished. It seeks to find a projection axis such that the Fisher criterion (i.e., the ratio of the between-class scatter to the within-class scatter) is maximized after the projection of samples. The local within-class scatter and the local between-class scatter matrices \(S_{W}^{L}\) and \(S_{b}^{L}\) are defined by
respectively, where X i,j is the jth training sample in class i, c is the number of classes, M is the number of total samples, and \(m_{i,j}^{t} = \sum\nolimits_{r}^{R} {X_{t,r} }\) is the local mean vector of X i,j in class t. There are R-nearest neighbors of X i,j in class t. We calculate the generalized eigenvectors \(\varphi_{1} \ldots \varphi_{d}\) which have d largest eigenvalues of \(S_{b}^{L} X = \lambda S_{w}^{L} X\), and \(P=(\varphi_{1} \ldots \varphi_{d})\) is the transform axes. We can use the linear transformation y = P T x to obtain the reduced d-dimensional feature vectors.
At last, we choose the nearest-neighbor classifier to achieve the face recognition, and LDOFH uses the cosine distance.
The algorithm of LDOFH
The feature extraction using the algorithm of LDOFH could be achieved as follows:
- Step 1.:
-
Calculate the gradient amplitude m(x, y) and the gradient direction θ(x, y) of each pixel using Eqs. (8) and (9);
- Step 2.:
-
Divide the dominant orientation map and the corresponding relative energy map into a series of overlapping local regions;
- Step 3.:
-
Construct the histogram on each local region;
- Step 4.:
-
Concatenate the histograms of all overlapping local regions to obtain the total histogram; and
- Step 5.:
-
Reduce the dimension of the total histogram by LM-NNDA to get the final features.
Merits of LDOFH
First, LDOFH calculates the local dominant orientation of each pixel over local patches to obtain the structure information of the image. The information can describe the local shape feature of the image well. Second, the change in light has little effect on the LDOFH recognition performance, because the change in light causes weak change in the dominant orientation over a local region. Third, the LDOFH is much faster than D-HLDO, because D-HLDO uses SVD to obtain the dominant orientation and energy value of each pixel, but this operation consumes more time. The following experiments show that our proposed LDOFH method is nearly three times faster than D-HLDO method. Given that the image resolution is w × h, the time complexities of Step 1, Step 2, Step 3, Step 4, Step 5 are O(w × h), O(1), O(w × h), O(1), O((b × L) 3 ), respectively. Therefore, the total time complexity of our LDOFH is O((b × L) 3 ).
Experiments
In this section, we will evaluate the effectiveness of LDOFH and compare it with the D-HLDO algorithm on two large available face image databases (AR, IMM). There are three parameters in our method: the number of orientation bins (here we set bin = 9) over 0–180°, Gaussian smoothing parameter σ (σ = 0.3), block size bsize (we construct histogram on a bsize block). Here, we compare the results including face recognition rate and cost time in different bsize values and the number of training samples. The experiment is done on DELL computer (CPU i5-3470, 3.20 GHZ, 8G, win 64) with matlab 2016a.
Experiment on AR database
The AR face database (Martinez and Benavente 1998) contains over 4000 color face images of 126 persons (70 men and 56 women), including frontal views of faces with different facial expressions, lighting conditions, and occlusions. The pictures of 120 individuals (65 men and 55 women) were taken in two sessions (separated by 2 weeks), and each session contains 13 color images. Fourteen face images (each session contains seven) of these 120 individuals are selected and used in our experiment. The size of each image is normalized to a 50 * 40. The sample is as shown in Fig. 2.

Sample images for one person of AR database
In order to obtain a better recognition rate, we set σ 0.3 and assume that the number of training samples in each class is 8, and then change the block size from 2 * 2 to 10 * 10; the experimental results are shown in Fig. 3. We can see that when the bsize is set to 8, the result is the best.

The influence of parameter bsize on the recognition rate
Next we compare LDOFH method with the related method D-HLDO. First, we compare the LDOFH method and the D-HLDO method in respect of the recognition rates and the cost times when changing the number of training samples in each class from 2 to 12, and the experimental results are, respectively, shown in Figs. 4 and 5.

The recognition rates in D-HLDO and LDOFH methods

The cost times in LDOFH and D-HLDO method
To further demonstrate advantages of our method, we compare the performances of LDOFH, D-HLDO, LBP, LTP, PCA, and FLDA. We can see that our method LDOFH outperforms LBP and D-HLDO methods. Compared with LBP, it significantly captures the dominant orientation in the local patch and reveals the local statistical information. Meanwhile, it consumes less time than D_HLDO and LBP. They both illustrate the effectiveness of the LDOFH method. The recognition rates of each method are listed in Table 1. Table 1 shows that our proposed LDOFH obtains the top recognition rate. The time cost results are shown in Table 2. Table 2 shows that our proposed LDOFH is much faster than D-HLDO method.
Experiment on IMM database
IMM is a database consisting of 240 annotated monocular images of 40 different human faces. Points of correspondence are placed on each image so the dataset can be readily used for building statistical models of shape.
The parameter is the same as the parameter set on the AR database. The results of recognition rate and cost time on IMM database are shown, respectively, in Figs. 6 and 7.

The recognition rates in D-HLDO and LDOFH methods

The cost time results in LDOFH and D-HLDO methods
It can be seen from the above experimental results that on the IMM database, LDOFH has lower recognition rate than D-HLDO under the same conditions. However, the cost time of the D-HLDO method is nearly three times greater than the cost time found from the LDOFH method.
Integrating the results from the two databases, the LDOFH method is shown to be more effective than the D-HLDO method.
Conclusions and future works
In our work, a novel image feature-extraction method—local dominant orientation feature histograms (LDOFH)—is proposed. LDOFH obtains the dominant orientation and the relative energy value of each pixel by calculating the gradient direction and the gradient amplitude in a local patch around the pixel. The feature histogram is constructed by accumulating the relative energies of the dominant orientations in the rectangular region. All the histograms are concatenated into a high-dimensional feature vector. LM-NNDA is finally adopted to reduce the dimension of the feature to obtain the more discriminative feature. LDOFH is compared with the D-HLDO method on two different image databases, AR and IMM. The results demonstrate the effectiveness of the presented method.
In the future, we will find an algorithm to achieve feature fusion to improve the recognition rate of the proposed method.
References
Bay H, Tuytelaars T, Van Gool L (2006) SURF: speeded up robust features. ECCV 2006:404–417
Belhumeur V, Hespanha J, Kriegman D (1997) Eigenfaces vs Fisherfaces: recognition using class specific linear projection. IEEE Trans Pattern Anal Mach Intell 19(7):711–720
Chen J, Shan S, He C et al (2010) WLD: a robust local image descriptor. IEEE Trans Pattern Anal Mach Intell 32(9):1705–1720
Dalal N, Triggs B (2005) Histograms of oriented gradients for human detection. In: CVPR 2005, pp 886–893
Deprettere F (1988) SVD and signal processing: algorithms, applications and architectures. Elsevier Science Pub.Co, Amsterdam
Hotelling H (1932) Analysis of a complex of statistical variables into principal components. Br J Educ Psychol 24(6):417–520
Huang D, Shan C, Ardabilian M, Wang Y, Chen L (2011) Local binary patterns and its application to facial image analysis: a survey. IEEE Trans Syst Man Cybern Part C Appl Rev 41(6):765–781
Huang D, Zhu C, Wang Y, Chen L (2014) HSOG: a novel local image descriptor based on histograms of the second order gradients. IEEE Trans Image Process 23(11):4680–4695
Lowe D (2004) Distinctive image features from scale-invariant keypoints. Int J Comput Vis 60(2):91–110
Martinez AM, Benavente R (1998) The AR Face Database. CVC Technical Report ♯24
Qian J, Yang J, Gao G (2013) Discriminative histograms of local dominant orientation (D-HLDO) for biometric image feature extraction. Pattern Recognit 46(10):2724–2739
Tan X, Triggs B (2010) Enhanced local texture feature sets for face recognition under difficult lighting conditions. IEEE Trans Image Process 19(6):1635–1650
Wen Y, Zhang K, Li Z, Qiao Y (2016) A discriminative feature learning approach for deep face recognition. In: ECCV
Yang J, Zhang L, Yang J-y, Zhang D (2011) From classifiers to discriminators: a nearest neighbor rule induced discriminant analysis. Pattern Recognit 44:1387–1402
Zhu Z, Luo P, Wang X, Tang X (2013) Deep learning identity preserving face space. In: ICCV
Authors’ contributions
The authors discussed the problem and the solutions proposed all together. All the authors participated in drafting and revising the final manuscript. All authors read and approved the final manuscript.
Acknowledgements
This project is partly supported by the NSF of China (61473086), partly supported by the Fundamental Research Funds for the Central Universities (2242017K40124).
Competing interests
The authors declare that they have no competing interests.
Availability of data and materials
Not applicable.
Consent for publication
We agree.
Ethics approval and consent to participate
Not applicable.
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Cui, X., Zhou, P. & Yang, W. Local dominant orientation feature histograms (LDOFH) for face recognition. Appl Inform 4, 14 (2017). https://doi.org/10.1186/s40535-017-0043-4
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s40535-017-0043-4