
Abstract
In this paper, a new rectifying action is combined into different proportional-α-order-derivative-type iterative learning control algorithms for a class of fractional order linear time-invariant systems. Unlike the existing fractional order iterative learning control techniques, the proposed algorithms allow the initial state value of a fractional order iterative learning control system at each iteration to shift randomly. By introducing the Lebesgue-p norm and using the method of fractional integration by parts and the generalized Young inequality of convolution integral, the tracking performances with respect to the initial state shift under the proposed algorithms are analyzed. These analyses show that the tracking errors are incurred by such a shift and improved by tuning the rectifying gain. Numerical simulations are performed to demonstrate the effectiveness of the proposed algorithms.
Similar content being viewed by others

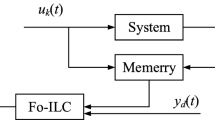
1 Introduction
Iterative learning control (ILC) has become one of the most active fields in intelligent control methodology since the early study for robotic systems trajectory tracking in [1]. The mechanism of the ILC is that, for a control system which repeatedly operates over a finite time interval, in order to enable the system to achieve perfectly tracking as the iteration number increases successively, the ILC unit utilizes the information from the previous operation to modify an unsatisfactory control input signal. One of the important advantages of the ILC is that it requires less prior knowledge to generate iteratively a sequence of control input signals [2–6].
The fractional order iterative learning control (FOILC) is the latest trend in ILC research, it not only retains the advantages of the classical ILC, but also offers potential for better performances in a variety of complex physical processes [7–9]. Even since the above literature suggested this good learning performance, there have been made some efforts to synthesize a better FOILC updating law for various types of fractional order systems, and we have witnessed some progress in the following 16 years [10–16]. However, there still remain some restrictions which hinder further applications of the FOILCs in practice.
The obvious restriction of FOILCs is about the initial state value of the controlled fractional order system. It should be noted that perturbed initial state would degrade the tracking performance [17–19]. In the existing literature, requirements are that the initial state value should be equal to the desired one at each iteration. However, due to the effect of unavoidable noise or unidentified friction in practical engineering, the system cannot guarantee the initial value of state to the desired point. That means the initial state shift exists in the practice system, which motivates us for our study.
Besides, in the existing literature, the tracking error is analyzed in the sense of λ-norm. However, Lee and Bien [20] reported that the so-called λ-norm may not be a satisfactory measure of error in application. This is because of the λ-norm is a time decreasing weighted sup-norm, although the error becomes larger and larger near the terminal time, its λ-norm still decreases. In other words, the λ-norm may conceal the maximum absolute magnitude of the error signal, which would be very detrimental to engineering systems [21]. In order to avoid the above-mentioned phenomenon, for the Lebesgue-p norm it was reported in [22] that it is more suitable for error measure on performance than the λ-norm. Consequently, it is crucial to investigate the error measure with respect to Lebesgue-p norm in FOILCs. Recall that, for a time-varying vector function \(f: [ 0,T ] \to R^{m}\), \(f ( t ) = [ f^{1} ( t ), \ldots,f^{m} ( t ) ]^{\mathrm{T}}\), the λ-norm is defined as [18]
and the Lebesgue-p norm is defined as
Motivated by the limitation of the initial state value of FOILCs and the mentioned drawback of the λ-norm, in this paper, we address the initial state shift problem for a more realistic situation by alleviating the requirement so that the initial state \(x_{k} ( 0 )\) at each iteration k lies in a neighborhood of a random initial point \(x_{0}\). The main contribution of this paper is to consider the initial state shift for a class of fractional order linear systems, and then incorporate a rectifying action into various proportional-α-order-derivative-type ILC algorithms to alleviate the tracking error caused by such a shift. The algorithms include the first- and second-order as well as feedback-based proportional-α-order-derivative-type ILCs. It is also important to note that many new theoretic analysis methods are explored to analyze the tracking performance in the sense of the Lebesgue-p norm.
The remainder of this paper is organized in five parts. In Section 2, the definitions and some properties of fractional order derivatives and some lemmas are revisited. In Section 3, FOILC schemes with rectifying action are presented and the main result on the tracking performance of the proposed schemes are discussed. In Section 4, numerical examples are given to illustrate the performance of the proposed schemes. Finally, a brief conclusion is given in Section 5.
2 Preliminaries
Definition 2.1
([23])
For an arbitrary integrable function \(f ( t ):[ 0,\infty ) \to R\), the left-sided and the right-sided fractional integrals are defined as
where \(\Gamma ( \cdot )\) is the Gamma function and \(\Gamma ( \alpha ) = \int_{0}^{\infty} x^{\alpha - 1} e^{ - x}\,\mathrm{d}x\); \({}_{0}I_{t}^{\alpha}\), \({}_{t}I_{T}^{\alpha} \) are the left-sided and right-sided fractional integral of order α (\(\alpha > 0 \)) on \([ 0,{t} ]\), \([ t,T ]\), respectively.
Property 2.1
([23])
If \(\alpha > 0\), then \({}_{0}I_{t}^{\alpha} t^{\gamma} = \frac{\Gamma ( \gamma + 1 )}{\Gamma ( \gamma + 1 + \alpha )}t^{\gamma + \alpha} \), \(\gamma > - 1\), \(t > 0\).
Definition 2.2
([23])
For a given number \(\alpha > 0\), the left-sided and the right-sided α-order Caputo-type derivatives of the function \(f ( t ): [ 0,\infty ) \to R\) are defined as
where n is an integer and \(f^{ ( n )} ( t ) = \frac{\mathrm{d}^{n}}{\mathrm{d}t^{{n}}}f ( t )\); \({}_{0}^{C}D_{t}^{\alpha}\), \({}_{t}^{C}D_{T}^{\alpha} \) are the left-sided and right-sided Caputo-type derivatives of order α on \([ 0,{t} ]\), \([ t,T ]\), respectively.
For convenience, we denote \({}_{0}D_{t}^{\alpha} = {}_{0}^{C}D_{t}^{\alpha} \) and \({}_{t}D_{T}^{\alpha} = {}_{t}^{C}D_{T}^{\alpha} \) in the following.
Property 2.2
([23])
If \(\alpha > 0\), \(f ( t )\) is continuous on \([ 0,\infty )\), then \({}_{0}D_{t}^{\alpha} ({}_{0}I_{t}^{\alpha} f(t)) = f ( t )\) and \({}_{t}D_{T}^{\alpha} ({}_{t}I_{T}^{\alpha} f(t)) = f ( t )\).
Property 2.3
([16])
If \(0 < \alpha < 1\), \(f ( t )\) is continuous on \([ 0,\infty )\), then \({}_{0}D_{t}^{1 - \alpha} {}_{0}D_{t}^{\alpha} f ( t ) = f^{ ( 1 )} ( t )\), where \(f^{ ( 1 )} ( t ) = \frac{\mathrm{d}}{\mathrm{d}t}f ( t )\).
Definition 2.3
([23])
A single-parameter Mittag-Leffler function is defined by
A two-parameter Mittag-Leffler function is defined by
It is obvious that \(E_{\alpha} ( z ) = E_{\alpha,1} ( z )\) and \(E_{1,1} ( z ) = e^{z}\).
Lemma 2.1
([16])
The series \(E_{\alpha,\beta} (z)\) (\(\alpha > 0\), \(\beta > 0\)) is absolutely convergent on \(\Vert z \Vert < \infty\).
Lemma 2.2
([23], Fractional integration by parts)
For continuous functions \(f ( t )\), \(g ( t )\) on \([ 0,T ]\), the derivatives \({}_{0}D_{t}^{\alpha} f ( t )\) and \({}_{0}D_{t}^{\alpha} g ( t )\) exist at every point \(t \in [ 0,T ]\) and are continuous. Then we have
Lemma 2.3
([24], Generalized Young inequality of convolution integral)
For Lebesgue integrable scalar functions \(g,h: [ 0,T ] \in R\), the generalized Young inequality of their convolution integral is
where \(1 \le p,q,r \le \infty\) satisfy \(\frac{1}{r} = \frac{1}{p} + \frac{1}{q} - 1\). Particularly, when \(r = p\) and thus \(q = 1\), then the inequality of convolution integral is
Lemma 2.4
([25])
Let \(\{ a_{k},k = 1,2, \ldots \}\) be a real sequence defined as
with initial conditions
where \(d_{k}\) is a specified real sequence. If \(\rho_{1},\rho_{2}, \ldots,\rho_{M}\) are nonnegative numbers satisfying
Then:
-
(1)
\(d_{k} \le \bar{d}\), \(k \ge M + 1\) implies that \(a_{k} \le \max \{ \bar{a}_{1},\bar{a}_{2}, \ldots,\bar{a}_{M} \} + \frac{\bar{d}}{1 - \rho}\), \(k \ge M + 1\),
-
(2)
\(\lim_{k \to \infty} \sup d_{k} \le d_{\infty}\) implies that \(\lim_{k \to \infty} \sup a_{k} \le \frac{d_{\infty}}{1 - \rho}\).
3 Rectifying action-based proportional-α- order-derivative-type (\(\mathrm{PD}^{\alpha}\)-type) ILCs
Consider the following α-order (\(0 < \alpha < 1\)) linear time-invariant systems:
where k is the kth repetitive operation symbol, \({}_{0}D_{t}^{\alpha} \) is the Caputo derivative with lower limit zero of order α and \([ 0,T ]\) is an operation time interval, \(x_{k} ( t ) \in R^{n}\), \(u_{k} ( t ) \in R\) and \(y_{k} ( t ) \in R\) are the state vector, control input and output of the system, respectively. A, B and C are matrices with appropriate dimensions and it is assumed that CB is a full-rank matrix.
The solution of the fractional order system (1) can be written in the following form [26]:
where \(\Phi_{\alpha,\beta} ( t ) = t^{\beta - 1}E_{\alpha,\beta} (At^{\alpha} )\) (\(\alpha > 0\), \(\beta > 0\)) stands for the state transition matrix of fractional order system (1).
In this paper, the initial state value satisfies \(x_{k} ( 0 ) \in N ( x_{0} )\), where \(N ( x_{0} )\) is a neighborhood of \(x_{0}\). Specifically, it is assumed that the initial state value satisfies the following condition:
where β denotes a positive constant, and \(\lim_{k \to \infty} o ( \frac{1}{k} ) / \frac{1}{k} = 0\).
It is noted that the proportional-α-order-derivative-type (\(\mathrm{PD}^{\alpha} \)-type) ILC algorithm (3) which has been investigated in [8],
can ensure the system output \(y_{k} ( t )\) to track a desired trajectory \(y_{d} ( t )\) precisely as the operation number k goes to infinity with the initial state being resettable. But it cannot guarantee the precisely tracking with the initial state shift. Here, \(L_{p}\) and \(L_{d}\) are termed the proportional and α-order derivative learning gains, respectively. The expression \(e_{k} ( t ) = y_{d} ( t ) - y_{k} ( t )\) denotes the tracking error of the fractional order system (1).
Then, in order to generate an upgraded control input \(u_{k} ( t )\) to stimulate the system \(y_{k} ( t )\) to track a desired \(y_{d} ( t )\) as precisely as possible, we adopt a rectifying action to compensate for the proportional-α-order-derivative-type (\(\mathrm{PD}^{\alpha} \)-type) ILCs to suppress the tracking error caused by the initial state shift. The adopted rectifying action \(\delta_{k} ( t )\) is an iteration-dependent function sequence as follows:
for engineering applicability, it is assumed that the sequence obeys \(\vert \delta_{k} ( t ) \vert \le 1 / \varepsilon_{k}^{\alpha} \le M\), where M is the tolerance of the system input capability.
To this end, the rectifying first- and second-order as well as the feedback-based proportional-α-order-derivative-type (\(\mathrm{PD}^{\alpha} \)-type) ILC algorithms are considered and we suppose that \(y_{d} ( 0 ) \ne Cx_{0}\).
The rectifying action-based first-order proportional-α-order-derivative-type (\(\mathrm{PD}^{\alpha} \)-type) ILC algorithm is used of the latest historical tracking error and its α-order derivative, which is given as follows:
Here, \(L_{p_{1}}\) and \(L_{d_{1}}\) are termed the first-order proportional and α-order derivative learning gains, respectively. K is the rectifying gain.
The rectifying action-based second-order proportional-α-order-derivative-type (\(\mathrm{PD}^{\alpha} \)-type) ILC algorithm is used of control inputs, tracking errors and their α-order derivatives of the latest two adjacent operations, given by
Here, \(L_{p_{2}}\) and \(L_{d_{2}}\) denote the second-order proportional and α-order derivative learning gains, respectively. The weighing coefficients \(c_{1}\) and \(c_{2}\) satisfy \(0 \le c_{1},c_{2} \le 1\) and \(c_{1} + c_{2} = 1\).
It is observed that, when \(c_{2}\) is null, the rectifying second-order algorithm (5) degenerates to the rectifying first-order algorithm (4). Due to the algorithm (4) being a special case of the algorithm (5), we only analyze the tracking performance of the algorithm (5) in the following.
The rectifying action-based proportional-α-order-derivative-type (\(\mathrm{PD}^{\alpha} \)-type) ILC algorithm with feedback information is used of the latest historical and current tracking errors and their α-order derivatives, given by
Here, \(L_{p_{0}}\) and \(L_{d_{0}}\) denote the feedback learning gains, respectively.
Before showing the effect of the initial state shift, we need the following lemmas.
Lemma 3.1
\({}_{\tau} D_{t}^{1 - \alpha} ( \Phi_{\alpha,1} ( t - \tau ) ) = \Phi_{\alpha,\alpha} ( t - \tau )\), \(0 < \alpha < 1\).
Proof
It is obtained from Lemma 2.1 that the series \(\Phi_{\alpha,1} ( t - \tau )\) is absolutely convergent for all \(0 \le t, \tau < \infty\). Then we can differentiate the series \(\Phi_{\alpha,1} ( t - \tau )\) with respect to the variable τ term by term.
It is easy to see from the definition of the right-sided Caputo derivative that
Let \(\nu = s ( t - \tau ) + \tau\), we can get
where \(B ( \alpha,\beta ) = \int_{0}^{1} t^{\alpha - 1} ( 1 - t )^{\beta - 1}\,\mathrm{d}t\) is the Beta function and \(B ( \alpha,\beta ) = \frac{\Gamma ( \alpha )\Gamma ( \beta )}{\Gamma ( \alpha + \beta )}\) (\(\alpha > 0\), \(\beta > 0\)).
This means that
This completes the proof. □
Lemma 3.2
\(\frac{\mathrm{d}}{\mathrm{d}\tau} \Phi_{\alpha,1} ( t - \tau ) = - \Phi_{\alpha,\alpha} ( t - \tau )A\), \(\alpha > 0\).
Proof
This completes the proof. □
Now, the effect of initial state shift for the rectifying second-order and feedback-based proportional-α-order-derivative-type (\(\mathrm{PD}^{\alpha} \)-type) ILC algorithms will be shown.
3.1 Rectifying action-based second-order\(\mathrm{PD}^{\alpha}\)-type ILC
Theorem 3.1
Suppose that the rectifying action-based second-order \(\mathrm{PD}^{\alpha} \)-type ILC algorithm (5) is applied to the fractional order system (1) and that the initial state at each iteration satisfies the condition (2). If the system matrices A, B, C and the order α together with the learning gains \(L_{p_{1}}\), \(L_{d_{1}}\), \(L_{p_{2}}\) and \(L_{d_{2}}\) satisfy the following conditions \(\rho_{1} < 1\) and \(\rho_{2} < 1\), then we get
where
Proof
From the solution of the fractional order system (1) and algorithm (5), the output error for \(k + 1\) can be written as
Then, from Lemma 3.1, fractional integration by parts, Property 2.3 and Lemma 3.2, the second last term in the right side of (7) is rearranged as
Substituting (8) into (7) yields
Then we consider the last term in the right side of equality (9). By Lemma 3.1 and fractional integration by parts, we have
(1) If \(0 \le t \le \varepsilon_{k}\), then \(\delta_{k} ( t ) = \frac{t^{1 - \alpha}}{\varepsilon_{k}}\). When \(\gamma = 0\), from Property 2.1, we can obtain
hence, by equation (11), Property 2.2 and the mean theory of definite integral, there exists an instant \(\zeta_{k} ( t ) \in [ 0,t ]\) such that
(2) If \(\varepsilon_{k} < t \le T\), then \(\delta_{k} ( t ) = 0\). Analogously, there exists an instant \(\xi_{k} \in [ 0,\varepsilon_{k} ]\) such that
Let
Then, considering the facts of (12) and (13), the above equality (10) is
Notice that
Substituting (14), (15) and (16) into (9) yields
Taking the Lebesgue-p norm on both sides of (17) and adopting the generalized Young inequality of convolution integral, we get
recall that, from the inequality (2), by definition \(\lim_{k \to \infty} o ( \frac{1}{k} ) / \frac{1}{k} = 0\), we have
according to the triangular inequality property of the Lebesgue-p norm, and equality (19) yields
then, from equality (20), we have
Therefore
In this analogy, we can easily get
It is obvious that \(\bar{\rho} = {c}_{1}\rho_{1} + {c}_{2}\rho_{2}\) under the assumption that \(\rho_{1} < 1\), \(\rho_{2} < 1\), then, from (23) and Lemma 2.4, inequality (18) leads to
This completes the proof. □
Remark 3.1
Inequality (24) shows that the FOILC scheme (5) is able to drive the tracking error into a bound. It is worth noting that the upper bound is mainly determined by the parameter ρ̄ and the term \(\Delta_{2} = \Vert C\Phi_{\alpha,1} ( \cdot )B ( c_{1}L_{d_{1}} + c_{2}L_{d_{2}} ) - CH_{k} ( \cdot )BK\Gamma ( 2 - \alpha ) \Vert _{1} \Vert y_{d} ( 0 ) - Cx_{0} \Vert _{p}\). Therefore, the upper bound can be confined to a smaller level by two steps. The first step is to choose the learning gains \(L_{p_{1}}\), \(L_{d_{1}}\), \(L_{p_{2}}\), \(L_{d_{2}}\), so that ρ̄ is sufficiently small. The second step is to select the rectifying gain K so that \(\Vert C\Phi_{\alpha,1} ( \cdot )B ( c_{1}L_{d_{1}} + c_{2}L_{d_{2}} ) - CH_{k} ( \cdot )BK\Gamma ( 2 - \alpha ) \Vert _{1}\) is sufficiently small.
Remark 3.2
Regarding the selection of the rectifying gain K, it is easy to observe that the definition of \(H_{k} ( t )\) is close to the function \(\Phi_{\alpha,1} ( t )\). Thus, we can choose the rectifying gain K so as to approximate \(\frac{c_{1}L_{d_{1}} + c_{2}L_{d_{2}}}{\Gamma ( 2 - \alpha )}\), with the result that \(\Vert C\Phi_{\alpha,1} ( \cdot )B ( c_{1}L_{d_{1}} + c_{2}L_{d_{2}} ) - CH_{k} ( \cdot )BK\Gamma ( 2 - \alpha ) \Vert _{1}\) is sufficiently small.
Remark 3.3
In the case when \(c_{2}\) is null, the proposed rectifying second-order scheme (5) degenerates to the rectifying first-order scheme (4). Thus, the convergent condition becomes \(\rho_{1} < 1\) and the upper bound of output error is \(\frac{\Delta_{1}}{1 - \rho_{1}}\), where \(\Delta_{1} = \Vert C\Phi_{\alpha,1} ( \cdot )BL_{d_{1}} - CH_{k} ( \cdot )BK\Gamma ( 2 - \alpha ) \Vert _{1} \Vert y_{d} ( 0 ) - Cx_{0} \Vert _{p}\). We can find that the second-order scheme (5) has more freedom in choosing the learning gains to make ρ̄ and \(\Delta_{2}\) is smaller than \(\rho_{1}\) and \(\Delta_{1}\), with the result that the upper bound \(\frac{\Delta_{2}}{1 - \bar{\rho}} \) is smaller than \(\frac{\Delta_{1}}{1 - \rho_{1}}\).
Remark 3.4
It is obvious that, for the case when \(y_{d} ( 0 ) = Cx_{0}\), the deduction of Theorem 3.1 guarantees that the output error asymptotically approaches zero, where the initial state shift of the fractional order system exists and satisfies the constraint (2).
3.2 Rectifying action-based \(\mathrm{PD}^{\alpha}\)-type ILC with feedback informantion
Theorem 3.2
Suppose that the algorithm (6) is applied to the system (1) and the initial state value at each iteration satisfies the condition (2). If the system matrices A, B, C and the order α together with the learning gains \(L_{p_{1}}\) and \(L_{d_{1}}\), feedback gains \(L_{p_{0}}\) and \(L_{d_{0}}\) satisfy the condition \(\tilde{\rho} = \rho_{0}\rho_{1} < 1\), then we get
where
Proof
Consider the formulation of rule (6) and the dynamic system (1), we get the \(k + 1\)th output error
Then, from Lemma 3.1, fractional integration by parts, Property 2.3 and Lemma 3.2, the second last term in the right-hand side of (25) can be rearranged as follows:
Similar to the proof of Theorem 3.1, one can easily get
Taking the Lebesgue-p norm on both sides of (27) and adopting the generalized Young inequality of the convolution integral, we get
then inequality (28) can be rewritten as
Similar to the derivation of the (23), it is easy to get
From the assumption that \(\tilde{\rho} < 1\) and Lemma 2.4, we have
This completes the proof. □
Remark 3.5
Inequality (30) shows that the limit superior of the output error is controlled depends on the magnitude ρ̃ and the term \(\Delta_{0} = \Vert C\Phi_{\alpha,1} ( \cdot )B ( L_{d_{1}} + L_{d_{0}} ) - CH_{k} ( \cdot )BK\Gamma ( 2 - \alpha ) \Vert _{1} \Vert y_{d} ( 0 ) - Cx_{0} \Vert _{p}\). Hence, the reduction of the output error should be done based on the suitable choice of learning gains \(L_{p_{1}}\), \(L_{d_{1}}\), \(L_{p_{0}}\), \(L_{d_{0}}\) leading to ρ̃ being sufficiently small.
In addition, it is observed that the \(H_{k} ( t )\) is approximate to the function \(\Phi_{\alpha,1} ( t )\). Therefore, the properly selection of the rectifying gain K leads to K being closer to the value \(\frac{L_{d_{1}} + L_{d_{0}}}{\Gamma ( 2 - \alpha )}\). It leads to \(\Delta_{0} = \Vert C\Phi_{\alpha,1} ( \cdot )B ( L_{d_{1}} + L_{d_{0}} ) - CH_{k} ( \cdot )BK\Gamma ( 2 - \alpha ) \Vert _{1} \Vert y_{d} ( 0 ) - Cx_{0} \Vert _{p}\) being small enough and thus the superior limit of the output errors is also sufficiently small concurrently.
Remark 3.6
In the case when \(L_{p_{0}} = L_{d_{0}} = 0\), the proposed rectifying feedback-based scheme (6) degenerates to the rectifying first-order scheme (4), with the result that the convergent condition becomes \(\rho_{1} < 1\) and the upper bound of the output error is \(\frac{\Delta_{1}}{1 - \rho_{1}}\). It is found that if the learning gains \(L_{p_{0}}\), \(L_{d_{0}}\) are chosen in such a way that \(\rho_{0} < 1\) and \(\Delta_{0} < \Delta_{1}\), then we have an upper bound \(\frac{\rho_{0}\Delta_{0}}{1 - \tilde{\rho}} \) that is smaller than \(\frac{\Delta_{1}}{1 - \rho_{1}}\).
4 Numerical simulations
In this simulation, we consider the fractional order linear system with the Caputo derivative (fractional order \(\alpha = 4 / 5\)),
the desired trajectory is \(y_{d} ( t ) = 12t^{2}(1 - t)\), \(t \in [ 0,1 ]\) and the beginning control input set as \(u_{1} ( t ) = 0\), \(t \in [ 0,1 ]\).
The random initial state are produced as
where ‘rand’ stands for a randomly generated scalar number on the interval \(( 0,1 )\). The rectifying function is set as
To better illustrate the rectifying action of our proposed \(\mathrm{PD}^{4 / 5}\)-type ILC scheme (4) by comparison, first, the \(\mathrm{PD}^{4 / 5}\)-type ILC without a rectifying action (3) is used. We set first-order learning gains \(L_{p_{1}} = 0.1\), \(L_{d_{1}} = 1.2\), respectively. The rectifying gain \(K = 1.1\). We calculate that \(\rho_{1} = 0.7491 < 1\). Figures 1-3 present the tracking performances of the rectifying action-based first-order scheme (4) and the first-order scheme without a rectifying action (3) at the third, fifth and the tenth iterations, respectively, where the dashed curve denotes the desired trajectory, the dash-dotted curve denotes the output produces by the scheme (3) and the solid curve denotes the output produces by the scheme (4), respectively. It is shown that the rectifying action-based first-order scheme (4) is able to stir the system output to track the desired trajectory much better than the \(\mathrm{PD}^{4 / 5}\)-type scheme without a rectifying action (3). Figure 4 shows tracking errors of the above schemes in the sense of the Lebesgue-2 norm. It is shown that the rectifying action can suppress the tracking error incurred by the initial shift effectively.

Tracking perfermance at 3th iterative.

Tracking perfermance at 5th iterative.

Tracking performance at tenth iterative.

Tracking error comparison.
In order to compare the tracking errors of the rectifying first-order scheme (4) with the rectifying second-order scheme (5), the first- and second-order learning gains are chosen as \(L_{p_{1}} = 0.9\), \(L_{d_{1}} = 0.3\), \(L_{p_{2}} = 1.7\) and \(L_{d_{2}} = 0.9\), respectively. The rectifying gain is \(K = 0.9\) and the weighting coefficients are chosen as \(c_{1} = 0.2\), \(c_{2} = 0.8\). It is calculated that \(\rho_{1} = 0.8216 < 1\), \(\rho_{2} = 0.1689 < 1\) and thus \(\bar{\rho} = c_{1}\rho_{1} + c_{2}\rho_{2} = 0.2994 < 1\). The corresponding tracking error comparison between rectifying action-based schemes (4) and (5) in Lebesgue-2 norm is shown in Figure 5. It is shown that asymptotic tracking error of the rectifying second-order scheme (5) is smaller than the rectifying first-order scheme (4).

Tracking error comparison.
In terms of the comparison of the tracking errors of the rectifying first-order scheme (4) and the rectifying feedback-based scheme (6), the first-order learning gains are identically chosen as \(L_{p_{1}} = 0.9\), \(L_{d_{1}} = 0.3\), and the feedback gains are chosen as \(L_{p_{0}} = 1\), \(L_{d_{0}} = 0.3\), respectively. It is computed that \(\rho_{1} = 0.8704 < 1\), \(\rho_{0} = 0.8216 < 1\) and thus \(\tilde{\rho} = \rho_{0}\rho_{1} ={ 0.7151 < 1}\). The corresponding tracking error comparison between rectifying action-based schemes (4) and (6) in Lebesgue-2 norm is shown in Figure 6. It is shown that asymptotic tracking error of the rectifying feedback-based scheme (6) is smaller than the rectifying first-order scheme (4).

Tracking error comparison.
5 Conclusion
In this paper, a new rectifying action was introduced into various \(\mathrm{PD}^{\alpha} \)-type ILC schemes and the tracking performances against the initial state shift were investigated for a class of fractional order linear systems. The proposed \(\mathrm{PD}^{\alpha} \)-type ILC schemes were shown to be an extended form of first- and second-order as well as feedback-based \(\mathrm{PD}^{\alpha} \)-type ILC schemes. The tracking performances were analyzed in the form of the Lebesgue-p norm by the technique of the generalized Young inequality of the convolution integral and fractional integration by parts. These analyses show that effect of the initial state shift can be more effectively controlled in various ways and the tracking performances can be improved according to the proper choice of the learning gains.
References
Arimoto, S, Kawamura, S, Miyazaki, F: Bettering operation of robots by learning. J. Robot. Syst. 1, 123-140 (1984)
Park, KH, Bien, ZA: Generalized iterative learning controller against initial state error. Int. J. Control 73, 871-881 (2000)
Xu, JX, Tan, Y: Robust optimal design and convergence properties analysis of iterative learning control approaches. Automatica 38, 1867-1880 (2002)
Ahn, HS, Chen, YQ, Moore, KL: Iterative learning control: brief survey and categorization. IEEE Trans. Syst. Man Cybern., Part C, Appl. Rev. 37, 1099-1121 (2007)
Longman, RW: Iterative learning control and repetitive control for engineering practice. Int. J. Control 73, 930-954 (2007)
Li, XD, Chow, TWS, Ho, JKL: Iterative learning control with initial rectifying action for nonlinear continuous systems. IET Control Theory Appl. 3, 49-55 (2009)
Chen, YQ, Moore, KL: On \(\mathrm{D}^{\alpha} \)-type iterative learning control. In: Decision and Control, Proc. of the 40th IEEE Conference on. IEEE, Orlando, pp. 4451-4456 (2001)
Lazarevic, MP: \(\mathrm{PD}^{\alpha} \)-type iterative learning control for fractional LTI system. In: Proceedings of International Congress of Chemical and Process Engineering, 0359 (2004)
Li, Y, Chen, YQ, Ahn, HS: Fractional-order iterative learning control for fractional-order linear systems. Asian J. Control 13, 54-63 (2011)
Li, Y, Chen, YQ, Ahn, HS: A generalized fractional-order iterative learning control. In: 2011 50th IEEE Conference on Decision and Control and European Control Conference, pp. 5356-5361 (2011)
Li, Y, Chen, YQ, Ahn, HS: On the \(\mathrm{PD}^{\alpha} \)-type iterative learning control for the fractional-order nonlinear systems. In: Proceedings of the American Control Conference San Francisco, pp. 4320-4325 (2011)
Li, Y, Chen, YQ, Ahn, HS: A survey on fractional-order iterative learning control. J. Optim. Theory Appl. 156, 127-140 (2013)
Lan, YH, Zhou, Y: \(\mathrm{D}^{\alpha} \)-Type iterative learning control for fractional-order linear time-delay systems. Asian J. Control 15, 669-677 (2013)
Lazarević, MP, Tzekis, P: Robust second-order \(\mathrm{PD}^{\alpha} \)-type iterative learning control for a class of uncertain fractional order singular systems. J. Vib. Control 22(8), 2004-2018 (2014)
Liu, S, Wang, JR: Fractional order iterative learning control with randomly varying trial lengths. J. Franklin Inst. 354, 967-992 (2017)
Li, L: Lebesgue-p norm convergence of fractional-order PID-type iterative learning control for linear systems. Asian J. Control (2017). https://doi.org/10.1002/asjc.1561
Sun, M, Wang, D: Brief iterative learning control with initial rectifying action. Automatica 38, 1177-1182 (2002)
Bien, ZZ, Ruan, X: Pulse compensation for PD-type iterative learning control against initial state shift. Int. J. Syst. Sci. 43, 2172-2184 (2012)
Park, KH: An average operator-based PD-type iterative learning control for variable initial state error. IEEE Trans. Autom. Control 50, 865-869 (2005)
Lee, HS, Bien, Z: A note on convergence property of iterative learning controller with respect to sup norm. Automatica 33, 1591-1593 (1997)
Park, KH, Bien, Z: A study on iterative learning control with adjustment of learning interval for monotone convergence in the sense of sup-norm. Asian J. Control 4, 111-118 (2002)
Ruan, X, Bien, ZZ, Wang, Q: Convergence properties of iterative learning control processes in the sense of the Lebesgue-p norm. Asian J. Control 14, 1095-1107 (2012)
Samko, SG, Kilbas, AA, Marichev, O: Fractional Integrals and Derivatives. Gordon & Breach, Yverdon (1993)
Pinsky, MA: Introduction to Fourier Analysis and Wavelets. Brooks/Cole, Pacific Grove (2002)
Park, KH, Bien, Z: Intervalized iterative learning control for monotonic convergence in the sense of sup-norm. Int. J. Control 78, 1218-1227 (2005)
Monje, CA, Chen, Y, Vinagre, BM: Fractional Order Systems and Controls: Fundamentals and Applications. Springer, Berlin (2010)
Author information
Authors and Affiliations
Contributions
The author contributed solely to the writing of this paper. She read and approved the manuscript.
Corresponding author
Ethics declarations
Competing interests
The author declares that she has no competing interests.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Li, L. Rectified fractional order iterative learning control for linear system with initial state shift. Adv Differ Equ 2018, 12 (2018). https://doi.org/10.1186/s13662-018-1467-4
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s13662-018-1467-4