
Abstract
In personalized learning, each student gets a customized learning plan according to their pace of learning, instructional preferences, learning objects, etc. Hence the content recommender system in Personalized Learning Environment (PLE) should adapt to learner attributes and suggest appropriate learning resources to aid the learning process and improve the learning outcomes. This systematic literature review aims to analyze and summarize the studies on learning content recommenders in adaptive and personalized learning environments from 2015 to 2020. The publications were searched using proper keywords and filtered using the inclusion and exclusion criteria, which resulted in 52 publications. This paper summarizes the recent trends in research on different aspects of the recommender systems, such as learner attributes, recommendation methods, evaluation metrics, and the usability tests used by the researchers. It is observed that cognitive aspects of learners like learning style, preferences, knowledge level, etc., are used by most studies than non-cognitive aspects as social tags or trust. In most cases, recommendation engines are a hybrid of collaborative filtering, content-based filtering, ontological approaches, etc. All models were evaluated for the correctness of the prediction done, and a few studies have also done evaluations based on learner satisfaction or usability.
Similar content being viewed by others


Introduction
Technology's rapid progression has affected many facets of our lives, especially those related to education. The impact of the COVID-19 pandemic resulted in the drastic shift of learning from traditional classrooms to e-learning environments (Basilaia & Kvavadze, 2020; Sun et al., 2020). Electronic gadgets, especially mobile devices, applications, learning environments, and internet usage, have made learning simpler and quicker and improve learning. The virtual learning environments find more popularity in higher education and distance learning, providing free access and immersive participation to learners worldwide through the internet and other technologies (Bylieva, 2020).
As Chrysafiadi and Virvou (2013) have shown, the target learners are no longer just undergraduate students; these courses are open to anyone who desires to learn. So, the learner community is a large number of heterogenous enrolees. But when learning resources are delivered to learners systematically, the "one-size-fits-all" approach may not be beneficial. In addition, the vast number of learning resources available on the internet could contribute to knowledge overload (Raj & Renumol, 2018). The learning environment should be tailored to improve learners' learning performance and satisfaction (Hwang et al., 2020b). Personalized learning shows how each learner's pace of learning, instructional preferences, and learning objects are tailored to their specific needs. Adaptivity is the ability of the system to adapt to the changing needs of the learners as they progress in their studies (Dorca et al., 2017). Adaptive/Personalized learning maximizes learning and assists learners in effectively completing course objectives in less time and at a lower cost. The use of adaptivity in assessment, focusing on remediation, is linked to a significant increase in learning gains while having no significant impact on drop-out rates (Rosen et al., 2018). Xie et al. (2019) reviewed the literature on PL from 2007 to 2017, where they have analyzed the major research issues such as the parameters of adaptive/personalized learning, learning supports, learning outcomes, subjects, participants, hardware, etc. From the study, the authors concluded that the spectrum of personalized learning is getting more comprehensive with the advancements in Artificial Intelligence, Cloud Computing, Wearable Computing, and Virtual Reality. Thus, for developing personalized learning environments, various aspects of individual learners need to be analyzed. The data acts as a guide for the instructors to design pedagogy and learning materials (Moreno-León et al., 2017; Essalmi et al., 2010). Machine learning and data mining techniques need to be applied to generate helpful information (Piety et al., 2014).
The learning environments logs data regarding the various learning aspects of the students, which can be used for gauging the student's performance, grouping them based on their similarities, detecting undesirable behaviors, and also recommending courses and course materials to them (Romero & Ventura, 2010; Baker et al., 2014). Content authoring and content recommendation are two essential features of a learning environment. In e-learning, a recommender system's job is to suggest suitable learning materials to learners and assist them in making decisions. Recommender systems are a type of information retrieval in which learning resources are filtered and presented to students (Aguliar et al., 2017). The available data are mined to provide suitable recommendations to the learners. Several indications demonstrate the efficacy of adaptation and personalization in e-learning environments. The authors recommend indicators such as making course content available at the student's choice and allowing the learner to study at their own space and pace (Lerís et al., 2017; Raj & Renumol, 2019).
This paper provides a critical review of research works that have applied data analytics in e-learning, especially in adaptive and personalized content recommendation. The article also tries to identify the popular techniques associated with these recommendation models. The primary objectives of this review are:
-
1.
To analyze and summarize the research happenings in personalized learning environments from 2015 to 2020.
-
2.
Identify the different recommendation techniques, personalization parameters, models, algorithms, evaluation metrics for e-learning content recommendation systems.
The organization of this paper is as follows. The “Related works” secion deals with the similar literature reviews conducted in e-learning content recommender systems by other researchers. The “Adaptive content recommender system—a general framework” section presents the system framework of e-learning content recommender systems. The “Methodology” section discusses the methodology used in this paper. The “Analysis of literature on content recommender systems” section compares and summarizes different content recommendation models reviewed as part of this study, and the “Analysis of results” section projects the inferences from the review. The “Discussion” section discusses the results concerning the study’s objective, section and the limitations of the study, and the “Conclusion” section concludes the entire process.
Related works
In the last few years, e-learning researchers have written several review articles on e-learning recommender systems. This segment describes some of the current reviews. The appropriate suggestions made by the recommender systems help learners in decision-making toward self-regulated learning (Fatahi et al., 2016; Aguilar & Riofrio, 2017). Klašnja-Mili'cevi'c et al. (2015) conducted an inclusive review of recommender systems in e-learning environments. The study focused on essential requirements and challenges in designing recommender systems in e-learning environments. The paper summarized tag-based recommender systems as a future scope and expected more research in possible extensions with prototypes for tagging activities. But from later studies, it is evident that tag-based systems showed declination in popularity among researchers. Tarus et al., (2018a, 2018b) conducted a literature review on ontology-based recommender systems for e-learning from 2005 to 2014. The paper discusses different hybridization of techniques. The authors detail the various aspects of a knowledge-based recommender system. They also identify that the hybrid scenarios will help to overcome issues like data sparsity and cold start. The authors found that ontology working with other knowledge structures like knowledge vectors, case-based reasoning, social knowledge, and constraint-based reasoning will be future research trends.
George and Lal (2019) conducted a systematic literature study based on the papers from 2010 to 2018, which compared the non-ontology and ontology-based techniques for providing the content recommendation. The non-ontology methods discussed in the article are matrix factorization-based, machine learning-based, tag-based, group-based, and user-based recommendation systems. The paper concludes that among the other techniques used for recommendations in the learning domain, the research works that have used ontology showed better results. But the review is not discussing the reason behind the better acceptance of ontology-based systems. Both learner and learning object characteristics are factored in using ontologies on the papers under their discussion. By hybridizing the techniques, researchers are trying to overcome the margins of one process. Traditional systems try to combine different styles either to feed data in the system or to develop algorithms. The authors also observed that using ontology with other techniques produces better results.
The review also discusses several techniques to calculate learner similarity based on their interests. Zhong and Xie (2019) summarized five assessment aspects of e-learning recommender systems. They are the metrics for the e-learning system, the evaluation metrics for the recommendation algorithms, the recommendation filtering technology, the phases of the recommendation process, and the system's learning outcomes. They concluded that most e-learning systems would adopt the adaptive mechanism as the central aspect and accuracy as a vital performance index for the algorithms. Mangaroska and Giannakos (2019) analyzed 43 articles from the literature from 2010 to 2017. This article highlights the knowledge of relating learning analytics with learning design to develop tools, methods, and models to benefit instructors and learners. The authors insist on using LA to design personalized learning and feedback and lessen the conventional mode of lecturing, reading, or watching videos.
Drachsler et al. (2015) reviewed 82 recommender systems from 35 countries and classified them using a specific classification process. According to their characteristics, the examined systems were divided into seven clusters and analyzed. The clusters are (a) Cluster 1: Recommending resources for learning based on CF (b) Cluster 2: Improving CF algorithms with TEL domain particularities (c) Cluster 3: Educational constraints as a source of information (d) Cluster 4: Exploring non-CF techniques to find successful educational recommendations (e) Cluster 5: Considering contextual information (f) Cluster 6: Assessing the educational impact of recommendations (g) Cluster 7: Recommending courses. The paper summarized the frameworks used in recommender systems and the possible challenges in designing and developing the frameworks.
The literature reviews on e-learning recommender systems show that the studies are done and published on recommendation techniques like collaborative filtering, content-based and hybrid recommendation techniques. These reviews include investigating different recommendation models that use conventional recommendation techniques, ontology-based strategies, machine learning algorithms, and comparisons between different recommendation strategies. But these reviews included recommender systems where data from systems other than PLE is also analyzed. The authors were unable to locate any study that focuses only on e-learning content recommendation. This study is intended to bridge this gap by consolidating the recent research works, focusing on adaptive and personalized content recommender studies conducted from 2015 to 2020.
Adaptive content recommender system—a general framework
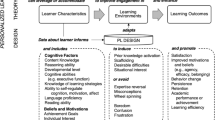
The primary goal of a content recommender system is to provide suggestions to both the learners and the instructors who interact with the system. The learners can get adaptive content recommendations, and instructors can use the inferences for course design and content authoring. The basic framework of a content recommendation system is given in Fig. 1 (Raj & Renumol, 2018).

A general framework of an adaptive personalized content recommender
When the learner is active for the first time, the basic preferences are collected using a questionnaire, and Learner Modeling Unit develops an initial Learner Model (LM). The input attributes are specific learner parameters such as their learning style, media preference, and level of knowledge. Later, as the learner becomes more active, the Learner Modeling Unit should alter the learner model accordingly by adapting to the changing preferences of the learner. The Learner Monitoring Unit assesses the learner's performance, logs the interactions, and analyzes the changes in the preferences. The instructor provides the learning objects. The Content Managing Unit contains the learning object model and the recommender engine. The recommender engine is supported with recommendation algorithms. Various measures are used to find the similarity between the learner attributes, to cluster them, or to cluster the learning patterns to recommend appropriate learning objects (Joy & Renumol, 2020). Based on this similarity measure, learner and learning object mapping is done in the content managing unit, and the recommender engine will recommend relevant learning objects to the learners. The monitoring unit gets feedback from the learners so that the system can adapt to changing needs of the learner.
Thus, the steps involved in developing an adaptive, personalized content recommender are:
-
1.
Collect data and develop the learner and learning object (LO) model.
-
2.
Group the learners in terms of their similarities. Identify the rules by which the learners and LOs can be mapped.
-
3.
Generate top 'N' learning object recommendations.
-
4.
Get feedback from the learners. Identify the learning paths from the learner activity log.
-
5.
Revisit the mapping between learner and LO based on feedback.
Methodology
This survey paper aims to analyze and summarize the research happenings in personalized learning environments from 2015 to 2020. The systematic review (Fig. 1) is done in three phases (Xiao & Watson, 2019).
-
1.
Search the repositories with selected keywords.
-
2.
Apply inclusion and exclusion criteria.
-
3.
Detailed analysis and summarization of the content.
The authors analyzed the literature in the databases Scopus (https://www.scopus.com) and the Web of Science Core Collection (www.webofknowledge.com), libraries of the Institute of Electrical and Electronics Engineers (IEEE, https://ieeexplore.ieee.org), and the Association for Computing Machinery (ACM, https://dl.acm.org/). Google Scholar is used as the seed search engine with the keywords, and later the literature is imported from the above-said repositories. The filter search is done using the keywords like "recommender system", "e-learning", "hybrid recommender system", "ontology", "ontology-based recommender system", "intelligent tutoring system", "knowledge-based systems", "machine learning for recommender". Always the filter search is done with the keywords mentioned above combined with strings as "personalized" and "adaptive learning." The papers were selected based on their relevance to the domain under review. Few records are removed from this set of records as the full-text version of those articles was inaccessible.
After retrieving the publications, the authors analyzed the abstract, conclusion, methodology, and keywords to select the most relevant papers.
The articles were chosen based on the following inclusion criteria:
-
Proposing recommendation techniques for personalized content recommendation.
-
Research is an empirical study.
-
Offering detailed discussion on methodology, design, development, and evaluation of the recommendation models.
-
Converging on adaptive/personalized e-learning environments
-
Published in the journals from 2015 to 2020, considering the indexing and impact factors of the journal. Articles from leading conference proceedings are also included as they show high relevance in the domain under study.
Again, a filtering step is carried out to exclude few articles based on the exclusion criteria:
Authors excluded those articles with all or any one of the following criteria:
-
The recommended items are neither learning resources nor learning activities.
-
The methodology, design, and evaluation of recommendation models are vague.
-
The article is not written in English.
-
The article is from the proceedings of Seminars/Workshops.
Further, the content of the selected papers was thoroughly read, analyzed, and summarized. The following section discusses the publications based on the models, recommendation techniques, evaluation criteria, and usability studies. Figure 2 represents the stages in the literature review methodology adopted.

Stages of literature review
Analysis of literature on content recommender systems
An adaptive or personalized e-learning system tries to understand learners' individual needs and preferences for supporting teaching–learning activities. Literature shows that there are many techniques by which researchers attempted to achieve this goal. A content recommender system should fundamentally decide two strategies, (i) Learner/Learning Object Model and (ii) the recommendation technique, including algorithm and evaluation methods used. This section exposes these aspects of the recommender systems concerning the recent publications. Table 1 discusses the recommendation methods, input attributes, and summary of the publications selected for the current study.
Analysis of results
This study examined research works on the adaptive content recommendation in e-learning environments, published from 2015 to 2020. The literature repository contains 52 papers which are analyzed and summarized in the previous section. This review process focuses on finding the different attributes/techniques that the research works adopted in learner/learning object modeling, recommendation process, and evaluation. On summarizing the results, the researchers are curious to know the systems' adaptivity and dynamicity. Like any other system, the recommender systems also need to be checked based on the system's usability. Here, the authors try to mine the works to know if they do a usability check or not?
-
1.
Personalization Parameters and Models
-
2.
Recommendation Techniques
-
3.
Usability of the system
Personalization parameters and models
This subsection discusses the primary models used in the e-learning content recommendations. The learner modeling attributes are learning style, learner preferences, knowledge level, learning paths and patterns, learner skills, pre-defined tags, context, etc.
Table 2 represents the set of prevalent parameters used for learner modeling in the content recommender systems under review.
Felder-Silverman Learning Style Model (FSLSM) is the most popular modeling technique used among the works analyzed. Felder and Silverman (Felder, 1988) presented a theoretical model in which each student can be classified according to four dimensions: perception, input, processing, and organization. (1) Perception classifies learners based on how they perceive the contents, and the dimension has two classes Sensitive (Sen) and Intuitive (Int). (2) Input, where the classification is done based on the format of the content presented to study, and the classes are Visual (Vis) and Verbal (Ver). (3) Processing, which indicates the measure of the active involvement of the student toward the content presented, and the classes are Active (Act) and Reflective (Ref). (4) Organization: Classifies students as sequential, if they prefer content exhibited progressively and more restricted view; are Sequential (Seq) and Global (Glo). To find each learner's dominant learning style, a survey with 44 questions, the Felder -Soloman Index of Learning Style questionnaire, is used (Graf et al., 2007, Joy et al., 2019). The questions are analyzed, and a probabilistic learner model is constructed and fed as an input to the system. Even though the FSLSM is not an adaptive model, it can alleviate the model's cold-start issue. Many recommender systems use the FSLSM as an initial fuel and later switch to learning path or learning pattern analysis for being adaptive.
Aeiad and Meziane (2019) focused on another learning style, VARK (Visual, Auditory, Reading/Writing, Kinaesthetic). VARK Learning Styles Theory is introduced by Fleming, N.D. and Mills, C. (Othman & Amiruddin, 2010). The VARK proposes four learning attributes. (1) Visual (V): learning by viewing a picture, diagram, and graphs (2) Auditory (A): learning by listening to explanations or group discussion. (3) Read/Write (R): learning by reading or writing. (4) Kinaesthetic (K): learning by experience or simulation. VARK has lesser acceptance compared with FSLSM as the latter is a probabilistic model.
Few recommender systems took a survey on learner preferences about learning objects explicitly, on the system's initiation. For example, questions like "Do you prefer visual or verbal learning content?" are asked. The knowledge level is historical data that the learner gives at the system's entry point. The learners are classified as, Novice, Intermediate, Advanced based on their subject knowledge. This parameter is assessed by explicitly surveying the learner by conducting a pre-test. The learning path is identified after the initiation of the recommender system. This method cannot be used under cold-start conditions. A path is a sequence of learning objects visited by the learner in time (Zhu et al., 2018). The paths are recommended for similar users who specify the initial or/and final learning objects to be studied.
Few studies have evaluated the learners' performance at regular intervals, and recommendations are made based on the score (Table 2). Learner's ratings, both positive and negative, are taken as a learner modeling parameter in few studies. Similar learners behave similarly in rating the learning objects. Motivated by the business domain, few studies adopted social tags/trust for classifying learners and recommend learning materials to them. Recently, research shows interest in using cognitive states of learners by analyzing how they interact with the system, how engaged they are, and their emotional state and relationship between these states and learning patterns.
The content recommender always tries to find the relation between learners and learning objects. So, it is equally important to model the learning objects appropriately for the system. The IEEE LOM is observed to be of high popularity among the researchers who believe in modeling the LOs (Araújo et al., 2017, Dorca et al. 2016; Dorca et al., 2017; Tarus et al., 2017). Some studies used specific content features and media attributes (Wan and Niu 2016; Deng et al., 2018; Venkatesh and Satyalakshmi 2020). The Learning Object Metadata Schema, created by IEEE Working Group P1484.12, is one of the most promising metadata schemas (Shen et al., 2002). It was primarily inspired by IMS and ARIADNE's work (Alliance of Remote Instructional Authoring and Distribution Networks for Europe). IEEE LOM has a wide range of data field categories. The Educational Category was crucial for the recommendation systems because it would enable the system to focus on defining learning materials' pedagogical features. Learning management system data or the recommender system data are used by most researchers in their studies.
Recommendation techniques
The use of efficient and effective recommendation techniques is crucial to solving the problem of retrieving relevant learning objects for learners. The different aspects of recommendation techniques discussed here are
-
a.
Recommendation Method
-
b.
Algorithms Used
-
c.
Similarity Measures Used
-
d.
Evaluation techniques checking the correctness of the algorithm
The past years viewed many recommendation techniques and algorithms as collaborative filtering, content-based filtering, fuzzy-based systems, context-aware systems, tag-based systems, group-based systems, ontology-based systems, rule-based, trust-aware systems, and social networking-based systems.
The collaborative filtering strategy leverages the learner's feedback (rating history) to cluster comparable learners and provide relevant recommendations for the future, which is the most prevalent RS design technique (Bourkoukou et al., 2016). The basic idea is that if users' tastes were similar in the past, they would have similar tastes in the future. The rating history is the essential factor in determining how similar two users are. The principle of content-based recommendation is based on the similarity computation of the item features associated with the compared objects (Dwivedi et al., 2018). Both collaborative filtering and content-based models heavily depend on the similarity measures used in the implementation.
Ontology is used to represent knowledge in ontology-based systems (Tarus et al., 2018a, b). Semantic relations are established between learners and learning objects. They are the best solution for cold start and sparsity problems. But the disadvantage is it's challenging, expensive, and time-consuming to build the ontologies. Group-based models analyze the behavior of a group of learners and make recommendations. They use different learner characteristics for grouping the learners. In contrast, the skill-based models observe the similarity in skills among the learners and cluster them based on their abilities. Both group-based and skill-based systems use collaborative or content-based methods to recommend the learning objects after initial clustering (Jagadeesan and Subbiah, 2020; Rahman and Abdullah, 2018).
In this period, 2015–2020, the models based on ontologies emphasize the inclusion of fuzzy techniques and hybrid methods that include algorithms genetics to enhance adaptive learning. Hybrid approaches are observed to have mostly collaborative or content-based models combined with an ontological framework. The following table, Table 3, shows that researchers show affinity toward hybrid models compared to others. The publications are grouped based on different recommendation methods.
Recommendation techniques give better results when it is combined with suitable machine learning algorithms (Table 4). The algorithms cluster the learners, recognize learning patterns, and map learners with learning objects.
It is observed that the majority of the research works use K-Nearest Neighbor (KNN) and K-Means algorithms to cluster the items. Both of them are simple and powerful grouping algorithms. KNN is used in supervised learning and K-Means in unsupervised learning. Tarus et al., in their publications in 2017 and 2018, tried sequence and pattern mining algorithms, respectively. They were working with non-real-time data and attempted to explore patterns of learning objects ranked by the learners. Studies also use genetic algorithms for grouping learners/learning objects. Learning path explorers also tried to find the shortest path between sequences of learning things to fulfill the learning needs/goals of the learners. Figure 3 shows the distribution of the algorithms used in the e-learning recommender system.

Distribution of machine learning algorithms
The similarity measures used in the works are Euclidean distance similarity, Jaccard Coefficient, Cosine Similarity, Ontological Similarity, Pearson Correlation Coefficient, learner parameters-based similarity. Algorithmic calculations are also used for assuming similarities between different entities in the system. However, few studies have used multiple similarities for clustering either the learners or the learning objects or both. When the data are represented using an ontological framework, an ontological similarity measure is used. The research works with input data as learning style/learner preferences used Pearson Coefficient, Cosine Similarity, Euclidean Distance, or Jaccard Coefficient as the similarity measure.
The similarity measures, along with the publications, are given in Table 5.
The most popular similarity measure is cosine similarity. It is used mainly with both hybrid and non-hybrid models. The data used in these cases are from learning management systems which are recorded or real-time learner logs. The preprocessed data are removed of null values. For comparison, studies have used Jaccard Coefficient and Pearson Correlation coefficient with many hybrid models to measure learner similarity. Euclidean distance similarity measures serve to cluster learners based on their preferences in collaborative filtering models. The study takes content and learner features as input data uses learner parameter-based similarity (Dwivedi et al., 2018). The models analyzing learning path or patterns also uses the correlation coefficient.
The evaluation methods in content recommenders aim to check the recommendation technique's correctness (Fazeli et al., 2017). The following table, Table 3, categorizes the references based on their recommender evaluation method.
The analysis shows that MAE, MSE, RMSE, accuracy, recall, and f-measure are the most commonly used standardized measurement measures in e-learning content recommender systems. Aside from that, the run-time complexity of some of the established procedures is assessed. In addition, many researchers used pre-and post-tests to evaluate student academic progress. The popularity assessment of different evaluation methods is shown in Fig. 4.

Prevalent evaluation methods
Usability
A recommendation's usefulness to the system or the user is referred to as utility (Fazeli et al., 2017). The learner could decide the utility of a recommendation explicitly (e.g., in learner-defined ratings), or the system can compute it by observing learner attributes (e.g., click-stream data). The utility of a recommendation can be determined by examining the learners' subsequent behavior, such as interacting with the recommendation or using prescribed learning objects. However, the studies are not focusing on increasing the system's usability; few studies use learner rating (Albatayneh et al., 2018; Deng et al., 2018; Tarus et al., 2017; Xiao et al., 2018). The user rating is primarily used as a learner/learning object attribute to train the systems.
Some studies use the learner's score and satisfaction level (Table 6) as an evaluation criterion of the model. Learner rating and satisfaction level are direct feedback, and scores are indirect feedback given by the learner (Shi et al., 2020). So, the input from the users in these cases is reflecting on the usability of the systems.
Discussion
The journal papers reviewed, rated, and categorized in this survey were excellent, particularly considering that most of them were downloaded from the Science Citation Index (SCI) and Scopus indexed journals (Table 1). The selected papers have more comprehensive content and are subject to a more stringent peer-review process. From the analysis, it is evident that the research work in the field is active throughout the review period. The development of research in the broader area of recommender systems and the acceptance of e-learning as a teaching and learning method by more institutions of higher learning can be attributed to this substantial growth and increase in research interest.
From Table 2, it is observed that both cognitive and non-cognitive aspects of the learners contribute toward learner modeling in the content recommendation. Learning style, pattern, knowledge level are examples of cognitive factors, while ratings, social tags, the polarity of hit, social trust are non-cognitive aspects. Learning styles are fundamental in achieving adaptivity in the system (Shemshack et al., 2021). The probability-based learning style, FSLSM, has received the most popularity among others. Most of the works do the initial questionnaire-based learning style or knowledge level survey to handle the cold-start issue. At an advanced stage of recommendation, learners' paths or patterns or ratings adapt to the learner's changing needs. Ratings are a strong indicator of the usability of the system also. Fuzzy learners use cognitive attributes to train the model (Hwang et al., 2020a). The adaptivity and dynamicity of the designs are ensured by exploring learning the paths and patterns within the system.
Table 3 displays that the hybrid systems are the most popular among other recommendation techniques. That includes the hybrid of ontology and knowledge-based systems. Most of the studies which followed hybridization have used collaborative filtering as one knowledge-based method. This trend shows that researchers are trying to unveil the hidden patterns and the diversity in learner behavior. Collaborative filtering clusters the learners based on their similarity or dissimilarity, thereby exposes common likeliness. Collaborative filtering is combined with trust-based, content-based, rule-based, pattern-based, and item-based filtering methods for recommending LOs. KNN and K-means are the popular learner grouping algorithms used across the publications under review. KNN, as it is a non-parametric and lazy learner, goes well with learner data, where data points are separated into clusters to interpret new samples. KNN relies only on feature similarity; it will calculate the distance of the learner attribute of one learner with all others and returns top N similar learners. So, in a feature similarity study, KNN performs well. General appreciation of the K-Means algorithm as an unsupervised classifier makes it a good performer in the e-learning recommendation.
On analyzing the similarity measures used in the recommender engine, if there are no null references in the input dataset, the cosine similarity measure performs well. Similarly, when data is usually distributed, Pearson Correlation Coefficient produces the best output. The popularity of Jaccard Coefficient and Euclidean distance similarity stems from their ease of use. The most common associates are K nearest neighbors and cosine similarity "fit for the Collaborative filtering method." Content-based strategies are commonly associated with space vector models. Analyzing the hybrid methods is based on integrating at least two techniques, using weighted algorithms; from commutation, cascade, and magnification functions. Based on semantic recommendation techniques used, it is observed that the hybridization is inclined to respond to the main limitations of the methods previously associated with cold-start (George & Lal, 2019). The recommendations carried out in the adaptive environment do not depend on the students' evaluations but are based on knowledge of the domain; this integrates relevance and inference feedback methods. The recommendation correctness is mainly calculated in Mean Absolute Error, Precision, or Recall (Table 6).
Instead of recommending top-N or top-1 LO, there are studies which recommend a sequence or pattern of LOs for a lesson using a knowledge graph (Shi et al., 2020; Zhu et al., 2018). These sequences are called a learning path. Here, the learners should specify the target topic (knowledge unit, KU) or the lesson they need to study. Then the model recommends a learning path, which starts from the initial KU, through the intermediate KUs till the final KU. For each KU, an LO is recommended based on the learner's performance or learner goals. These models are highly interactive and experimented with live data, whereas the methods which study the frequent patterns or rule-based patterns work with recorded data (Tarus et al., 2018a, 2018b). Interactive environments analyze students' performance or satisfaction and non-interactive environments analyze the learner ratings to evaluate the system's usability.
Unlike the earlier reviews, this study is confined to the content recommender system from the e-learning domain alone. The observations made in the current study, the classification of recommender model support systems, are in line with earlier studies (Zhong & Xie, 2019; Mangaroska & Giannakos, 2019). This means there is a continuity and correlation in the trends that the researchers follow. Zhong and Xie (2019) concluded that recommender systems would adopt the adaptive mechanism. The current study observed that the recent recommender models show adaptivity with the changing user needs. Mangaroska and Giannakos (2019) observed the growing demand for learning analytics in designing personalized learning environments. The current study observed that the selected publications apply machine learning algorithms to analyze the learner logs/feedback and predict suitable learning objects. Tarus et al., (2018a, 2018b) conducted exclusive studies with ontology-based systems, but the current research includes different recommendation strategies. Both studies converge on the observation that hybrid models are most popular in recommender systems.
There are few limitations to this review study as listed below:
-
Due to potential subjectivity and a lack of relevant knowledge, bias in collecting databases, papers, and publications.
-
Since keywords are discipline and language-specific, there is a bias in the search string.
-
The bias from rejecting non-English papers; the works in other languages are not considered for the study, even though they seemed appropriate from the abstracts.
-
The emphasis was on observational analysis, so; it was difficult to draw broader conclusions.
-
The bias and vagueness in data extraction because only the two authors conducted it
-
The bias from the interpretation of specific results, processes, or approaches since some parts of the research from the selected studies was not adequately represented.
On the other hand, the authors attempted to ensure an impartial review procedure by planning a study protocol with a pre-determined research objective. The search keywords are created based on the research objectives and consider the lack of standardization in keywords, varying by discipline and language. The authors performed a detailed search in the journals, repositories, and previous related reviews. Applying the literature review method described in Section “Methodology” the authors have done an in-depth study in the narrower area of content recommendation in e-learning.
Conclusion
An adaptive and personalized e-learning system aims to support the learners' individual needs and interests to facilitate the learning process. The researchers in this area have tried a variety of techniques to achieve this goal. This paper presents a systematic analysis of 52 publications on e-learning recommender systems published between 2015 and 2020. This review investigated the methods used, attribute selection, and model evaluation metrics used across the publications.
A hybrid of two or more recommendation methods like ontology-based, collaborative filtering-based is observed as the most commonly used technique. In contrast, the usage of non-hybrid ontology systems has been decreased in these years. Also, the designs are relying on explicit learner attributes. Some recommender system studies analyze the cognitive features of the learners as an implicit attribute. In many studies, the input attribute selection is based on learning style, knowledge level, and learning preferences. The learning pattern and learning path are computed in these works for recommending the content. Apart from MAE, MSE, RMSE, accuracy, recall, and f-measure, the models also use run-time, learner satisfaction, and learner performance to evaluate the models.
According to Shi et al. (2020) there is an increase in the usage of mobile devices in learning and the need for generating context-aware recommendations is relatively higher. The new research studies in this domain would be ubiquitous and autonomous systems using the knowledge in recommender systems.
References
Aeiad, E., & Meziane, F. (2019). An adaptable and personalized E-learning system applied to computer science Programmes design. Education and Information Technologies, 24(2), 1485–1509.
Aguilar, J., Valdiviezo-Díaz, P., & Riofrio, G. (2017). A general framework for intelligent recommender systems. Applied Computing and Informatics, 13(2), 147–160.
Al Abri, A., Jamoussi, Y., AlKhanjari, Z., & Kraiem, N. (2020). PerLCol: A framework for personalized e-learning with social collaboration support. International Journal of Computing and Digital Systems, 9(03).
Albatayneh, N. A., Ghauth, K. I., & Chua, F. F. (2018). Utilizing learners’ negative ratings in semantic content-based recommender system for e-learning forum. Journal of Educational Technology & Society, 21(1), 112–125.
Anuradha, M., Ganesan, V., Oliver, S., Jayasankar, T., & Gopi, R. (2020). Hybrid firefly with differential evolution algorithm for multi agent system using clustering based personalization. Journal of Ambient Intelligence and Humanized Computing, 1–10.
Araújo, R. D., Cattelan, R. G., & Dorça, F. A. (2017). Towards an adaptive and ubiquitous learning architecture. In 2017 IEEE 17th international conference on advanced learning technologies (ICALT) (pp. 539–541)
Baker, R. S., & Inventado, P. S. (2014). Educational data mining and learning analytics. In Learning analytics (pp. 61–75). New York, NY: Springer. https://doi.org/10.1007/978-1-4614-3305-7_4
Basilaia, G., & Kvavadze, D. (2020). Transition to online education in schools during a SARS-CoV-2 coronavirus (COVID-19) pandemic in Georgia. Pedagogical Research. https://doi.org/10.29333/pr/7937
Benhamdi, S., Babouri, A., & Chiky, R. (2017). Personalized recommender system for e-Learning environment. Education and Information Technologies, 22(4), 1455–1477.
Bhaskaran, S., & Santhi, B. (2019). An efficient personalized trust-based hybrid recommendation (tbhr) strategy for e-learning system in cloud computing. Cluster Computing, 22(1), 1137–1149.
Bouihi, B., & Bahaj, M. (2019). Ontology and rule-based recommender system for e-learning applications. International Journal of Emerging Technologies in Learning (iJET), 14(15), 4–13.
Bourkoukou, O., & El Bachari, E. (2016). E-learning personalization based on collaborative filtering and learner’s preference. Journal of Engineering Science and Technology, 11(11), 1565–1581.
Bourkoukou, O., El Bachari, E., & El Adnani, M. (2016). A personalized e-learning based on recommender system. International Journal of Learning and Teaching, 2(2), 99–103.
Bourkoukou, O., El Bachari, E., & El Adnani, M. (2017). A recommender model in e-learning environment. Arabian Journal for Science and Engineering, 42(2), 607–617.
Bylieva, D., Bekirogullari, Z., Kuznetsov, D., Almazova, N., Lobatyuk, V., & Rubtsova, A. (2020). Online group student peer-communication as an element of open education. Future Internet, 12(9), 143.
Chrysafiadi, K., & Virvou, M. (2013). Student modeling approaches: A literature review for the last decade. Expert Systems with Applications, 40(11), 4715–4729.
Christudas, B. C. L., Kirubakaran, E., & Thangaiah, P. R. J. (2018). An evolutionary approach for personalization of content delivery in e-learning systems based on learner behavior forcing compatibility of learning materials. Telematics and Informatics, 35(3), 520–533.
Deng, X., Li, H., & Huangfu, F. (2018). A trust-aware neural collaborative filtering for elearning recommendation. Educational Sciences: Theory & Practice, 18(5).
Dorça, F. A., Araújo, R. D., De Carvalho, V. C., Resende, D. T., & Cattelan, R. G. (2016). An automatic and dynamic approach for personalized recommendation of learning objects considering students learning styles: An experimental analysis. Informatics in Education, 15(1), 45.
Dorca, F. A., Carvalho, V. C., Mendes, M. M., Araujo, R. D., Ferreira, H. N., & Cattelan, R. G. (2017). An approach for automatic and dynamic analysis of learning objects repositories through ontologies and data mining techniques for supporting personalized recommendation of content in adaptive and intelligent educational systems. In: Proceedings - IEEE 17th international conference on advanced learning technologies, ICALT 2017 (pp. 514–516). https://doi.org/10.1109/ICALT.2017.121
Drachsler, H., Verbert, K., Santos, O. C., & Manouselis, N. (2015). Panorama of recommender systems to support learning. In Recommender systems handbook (pp. 421–451).Boston, MA: Springer.
Dwivedi, P., & Bharadwaj, K. K. (2015). e-Learning recommender system for a group of learners based on the unified learner profile approach. Expert Systems, 32(2), 264–276.
Dwivedi, P., Kant, V., & Bharadwaj, K. K. (2018). Learning path recommendation based on modified variable length genetic algorithm. Education and Information Technologies, 23(2), 819–836.
Essalmi, F., Ayed, L. J. B., Jemni, M., & Graf, S. (2010). A fully personalization strategy of E-learning scenarios. Computers in Human Behavior, 26(4), 581–591.
Fatahi, S., Moradi, H., & Kashani-Vahid, L. (2016). A survey of personality and learning styles models applied in virtual environments with emphasis on e-learning environments. Artificial Intelligence Review, 46(3), 413–429.
Fazeli, S., Drachsler, H., Bitter-Rijpkema, M., Brouns, F., Van der Vegt, W., & Sloep, P. B. (2017). User-centric evaluation of recommender systems in social learning platforms: Accuracy is just the tip of the iceberg. IEEE Transactions on Learning Technologies, 11(3), 294–306.
Felder, R. M., & Silverman, L. K. (1988). Learning and teaching styles in engineering education. Engineering Education, 78(7), 674–681.
Fraihat, S., & Shambour, Q. (2015). A framework of semantic recommender system for e-learning. Journal of Software, 10(3), 317–330.
George, G., & Lal, A. M. (2019). Review of ontology-based recommender systems in e-learning. Computers & Education, 142, 103642.
Graf, S., Viola, S. R., Leo, T., & Kinshuk. (2007). In-depth analysis of the Felder-Silverman learning style dimensions. Journal of Research on Technology in Education, 40(1), 79–93. https://doi.org/10.1080/15391523.2007.10782498
Hwang, G. J., Sung, H. Y., Chang, S. C., & Huang, X. C. (2020a). A fuzzy expert system-based adaptive learning approach to improving students’ learning performances by considering affective and cognitive factors. Computers and Education: Artificial Intelligence, 1, 100003.
Hwang, G. J., Xie, H., Wah, B. W., & Gašević, D. (2020b). Vision, challenges, roles and research issues of artificial intelligence in education. Computers & Education: Artificial Intelligence, 1, 100001.
Ibrahim, T. S., Saleh, A. I., Elgaml, N., & Abdelsalam, M. M. (2020). A fog based recommendation system for promoting the performance of E-Learning environments. Computers & Electrical Engineering, 87, 106791.
IEEE-LTSC, IEEE P1484.12.1-2002/Cor 1/D14. Draft standard for learning object metadata — corrigendum 1: corrigenda for 1484.12.1 LOM (learning object metadata), IEEE Learning Technology Standards Committee, 2010.
Imran, H., Belghis-Zadeh, M., Chang, T. W., & Graf, S. (2016). PLORS: A personalized learning object recommender system. Vietnam Journal of Computer Science, 3(1), 3–13.
Jagadeesan, S., & Subbiah, J. (2020). Real-time personalization and recommendation in Adaptive Learning Management System. Journal of Ambient Intelligence and Humanized Computing, 11, 1–11.
Joy, J.,Raj, N. S. & Renumol V. G. (2019). An ontology model for content recommendation in personalized learning environment. In Proceedings of the second international conference on data science, e-learning and information systems (pp. 1–6).
Joy, J., & Renumol, V. G. (2020, December). Comparison of generic similarity measures in e-learning content recommender system in cold-start condition. In 2020 IEEE Bombay section signature conference (IBSSC) (pp. 175–179). IEEE.
Klašnja-Milićević, A., Ivanović, M., & Nanopoulos, A. (2015). Recommender systems in e-learning environments: A survey of the state-of-the-art and possible extensions. Artificial Intelligence Review, 44(4), 571–604.
Klašnja-Milićević, A., Ivanović, M., Vesin, B., & Budimac, Z. (2018a). Enhancing e-learning systems with personalized recommendation based on collaborative tagging techniques. Applied Intelligence, 48(6), 1519–1535.
Klašnja-Milićević, A., Vesin, B., & Ivanović, M. (2018b). Social tagging strategy for enhancing e-learning experience. Computers & Education, 118, 166–181.
Kolekar, S. V., Pai, R. M., & Manohara Pai, M. M. (2019). Rule based adaptive user interface for adaptive E-learning system. Education and Information Technologies, 24(1), 613–641.
Kouis, D., Kyprianos, K., Ermidou, P., Kaimakis, P., & Koulouris, A. (2020). A framework for assessing LMSs e-courses content type compatibility with learning styles dimensions. Journal of e-Learning and Knowledge Society, 16(2), 73–86.
Labib, A. E., Canós, J. H., & Penadés, M. C. (2017). On the way to learning style models integration: A Learner’s Characteristics Ontology. Computers in Human Behavior, 73, 433–445.
Lerís, D., Sein-Echaluce, M. L., Hernández, M., & Bueno, C. (2017). Validation of indicators for implementing an adaptive platform for MOOCs. Computers in Human Behavior, 72, 783–795.
Mangaroska, K., & Giannakos, M. (2019). Learning analytics for learning design: A systematic literature review of analytics-driven design to enhance learning. IEEE Transactions on Learning Technologies, 12(4), 516–534.
Moreno-León, J., Robles, G., & Román-González, M. (2017). Towards data-driven learning paths to develop computational thinking with scratch. IEEE Transactions on Emerging Topics in Computing, 8(1), 193–205.
Murad, D. F., Heryadi, Y., Isa, S. M., & Budiharto, W. (2020). Personalization of study material based on predicted final grades using multi-criteria user-collaborative filtering recommender system. Education and Information Technologies, 25, 5655–5668.
Nabizadeh, A. H., Gonçalves, D., Gama, S., Jorge, J., & Rafsanjani, H. N. (2020). Adaptive learning path recommender approach using auxiliary learning objects. Computers & Education, 147, 103777.
Nafea, S., Siewe, F., & He, Y. (2018). ULEARN: Personalized course learning objects based on hybrid recommendation approach. IJIET, 8, 842.
Nafea, S. M., Siewe, F., & He, Y. (2019). On recommendation of learning objects using felder-Silverman learning style model. IEEE Access, 7, 163034–163048.
Nihad, E. G., Mohamed, K., & El Mokhtar, E. N. (2020). Designing and modeling of a multiagent adaptive learning system (MAALS) using incremental hybrid case-based reasoning (IHCBR). International Journal of Electrical & Computer Engineering (2088–8708), 10(3).
Othman, N., & Amiruddin, M. H. (2010). Different perspectives of learning styles from VARK model. Procedia-Social and Behavioral Sciences, 7, 652–660.
Ouf, S., Abd Ellatif, M., Salama, S. E., & Helmy, Y. (2017). A proposed paradigm for smart learning environment based on semantic web. Computers in Human Behavior, 72, 796–818.
Perumal, S. P., Sannasi, G., & Arputharaj, K. (2019). An intelligent fuzzy rule-based e-learning recommendation system for dynamic user interests. The Journal of Supercomputing, 75(8), 5145–5160.
Piety, P. J., Hickey, D. T., & Bishop, M. J. (2014, March). Educational data sciences: Framing emergent practices for analytics of learning, organizations, and systems. In Proceedings of the fourth international conference on learning analytics and knowledge (pp. 193–202).
Rahman, M. M., & Abdullah, N. A. (2018). A personalized group-based recommendation approach for Web search in E-learning. IEEE Access, 6, 34166–34178.
Raj, N. S., & Renumol, V. G. (2018). Architecture of an adaptive personalized learning environment (APLE) for content recommendation. In Proceedings of the 2nd international conference on digital technology in education (pp. 17–22).
Raj, N. S., & Renumol, V. G. (2019). A rule-based approach for adaptive content recommendation in a personalized learning environment: An experimental analysis. In 2019 IEEE tenth international conference on technology for education (T4E) (pp. 138–141). IEEE.
Riyahi, M., & Sohrabi, M. K. (2020). Providing effective recommendations in discussion groups using a new hybrid recommender system based on implicit ratings and semantic similarity. Electronic Commerce Research and Applications, 40, 100938.
Romero, C., & Ventura, S. (2010). Educational data mining: A review of the state of the art. IEEE Transactions on Systems, Man, and Cybernetics, Part C Applications and Reviews, 40(6), 601–618.
Rosen, Y., Rushkin, I., Rubin, R., Munson, L., Ang, A., Weber, G., Lopez, G., & Tingley, D. (2018, June). The effects of adaptive learning in a massive open online course on learners' skill development. In Proceedings of the fifth annual acm conference on learning at scale (pp. 1–8).
Saleena, B., & Srivatsa, S. K. (2015). Using concept similarity in cross ontology for adaptive e-Learning systems. Journal of King Saud University-Computer and Information Sciences, 27(1), 1–12.
Sarwar, S., Qayyum, Z. U., García-Castro, R., Safyan, M., & Munir, R. F. (2019). Ontology based E-learning framework: A personalized, adaptive and context aware model. Multimedia Tools and Applications, 78(24), 34745–34771.
Segal, A., Gal, K., Shani, G., & Shapira, B. (2019). A difficulty ranking approach to personalization in E-learning. International Journal of Human-Computer Studies, 130, 261–272.
Senthilnayaki, B., Venkatalakshmi, K., & Kannan, A. (2015). An ontology based framework for intelligent web based e-learning. International Journal of Intelligent Information Technologies (IJIIT), 11(2), 23–39.
Shen, Z., Shi, Y., & Xu, G. (2002). A learning resource metadata management system based on LOM specification. Proceedings of the International Conference on Computer Supported Cooperative Work in Design, 7, 452–457. https://doi.org/10.1109/cscwd.2002.1047730
Shemshack, A., Kinshuk, & Spector, J. M. (2021). A comprehensive analysis of personalized learning components. Journal of Computers in Education. https://doi.org/10.1007/s40692-021-00188-7
Shi, D., Wang, T., Xing, H., & Xu, H. (2020). A learning path recommendation model based on a multidimensional knowledge graph framework for e-learning. Knowledge-Based Systems, 195, 105618.
Soloman, B. A., & Felder, R. M. 2005. Index of learning styles questionnaire. NC State University. Retrieved April 4, 2018, from https://www.webtools.ncsu.edu/learningstyles/
Sun, L., Tang, Y., & Zuo, W. (2020). Coronavirus pushes education online. Nature Materials, 19(6), 687–687.
Tarus, J. K., Niu, Z., & Yousif, A. (2017). A hybrid knowledge-based recommender system for e-learning based on ontology and sequential pattern mining. Future Generation Computer Systems, 72, 37–48.
Tarus, J. K., Niu, Z., & Kalui, D. (2018a). A hybrid recommender system for e-learning based on context awareness and sequential pattern mining. Soft Computing, 22(8), 2449–2461.
Tarus, J. K., Niu, Z., & Mustafa, G. (2018b). Knowledge-based recommendation: A review of ontology-based recommender systems for e-learning. Artificial Intelligence Review, 50(1), 21–48. https://doi.org/10.1007/s10462-017-9539-5
Vanitha, V., & Krishnan, P. (2019). A modified ant colony algorithm for personalized learning path construction. Journal of Intelligent & Fuzzy Systems, 37(5), 6785–6800.
Venkatesh, M., & Sathyalakshmi, S. (2020). Smart learning using personalised recommendations in web-based learning systems using artificial bee colony algorithm to improve learning performance. Electronic Government, an International Journal, 16(1–2), 101–117.
Wan, S., & Niu, Z. (2016). A learner-oriented learning recommendation approach based on mixed concept mapping and immune algorithm. Knowledge-Based Systems, 103, 28–40.
Wan, S., & Niu, Z. (2018). An e-learning recommendation approach based on the self-organization of learning resource. Knowledge-Based Systems, 160, 71–87.
Wan, S., & Niu, Z. (2019). A hybrid e-learning recommendation approach based on learners’ influence propagation. IEEE Transactions on Knowledge and Data Engineering, 32(5), 827–840.
Xiao, Y., & Watson, M. (2019). Guidance on conducting a systematic literature review. Journal of Planning Education and Research, 39(1), 93–112.
Xiao, J., Wang, M., Jiang, B., & Li, J. (2018). A personalized recommendation system with combinational algorithm for online learning. Journal of Ambient Intelligence and Humanized Computing, 9(3), 667–677.
Xie, H., Chu, H. C., Hwang, G. J., & Wang, C. C. (2019). Trends and development in technology-enhanced adaptive/personalized learning: A systematic review of journal publications from 2007 to 2017. Computers & Education, 140,
Zhang, H., Huang, T., Lv, Z., Liu, S., & Yang, H. (2019). MOOCRC: A highly accurate resource recommendation model for use in MOOC environments. Mobile Networks and Applications, 24(1), 34–46.
Zhong, J., Xie, H., & Wang, F. L. (2019). The research trends in recommender systems for e-learning. Asian Association of Open Universities Journal., 14, 12.
Zhu, H., Tian, F., Wu, K., Shah, N., Chen, Y., Ni, Y., Zhang, X., Chao, K.-M., & Zheng, Q. (2018). A multi-constraint learning path recommendation algorithm based on knowledge map. Knowledge-Based Systems, 143, 102–114.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Raj, N.S., Renumol, V.G. A systematic literature review on adaptive content recommenders in personalized learning environments from 2015 to 2020. J. Comput. Educ. 9, 113–148 (2022). https://doi.org/10.1007/s40692-021-00199-4
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40692-021-00199-4