
Abstract
The Estrada index of a graph/network is defined as the trace of the adjacency matrix exponential. It has been extended to other graph-theoretic matrices, such as the Laplacian, distance, Seidel adjacency, Harary, etc. Here, we describe many of these extensions, including new ones, such as Gaussian, Mittag–Leffler and Onsager ones. More importantly, we contextualize all of these indices in physico-mathematical frameworks which allow their interpretations and facilitate their extensions and further studies. We also describe several of the bounds and estimations of these indices reported in the literature and analyze many of them computationally for small graphs as well as large complex networks. This article is intended to formalize many of the Estrada indices proposed and studied in the mathematical literature serving as a guide for their further studies.
Similar content being viewed by others

1 Introduction
At the dawn of the XXI century the current author proposed an index to quantify the “degree of folding” of a linear chain in a three-dimensional space [70]. The motivation of this work came from the fact that many scientific articles make claims like that the structure A “is more folded than” the structure B (see examples at: [44, 67, 128, 237]), or that certain structure is “highly folded” (see for instance: [42, 129, 142, 246]), etc. These expressions could be referring to protein or polymer structures, but also to brain regions or even geological structures (see previous refs.). However, in neither of these works there was an index that quantifies how folded a linear chain is. Thus, the author proposed the index \(I_{3}=\sum _{j=1}^{n}\exp \left( \lambda _{j}\left( W\right) \right) \), where \(\lambda _{j}\left( W\right) \) are the eigenvalues of certain tridiagonal matrix W whose diagonal entries are related to the cosines of the dihedral angles between adjacent planes and \(W_{i,i+1}\) and \(W_{i+1,i}\) are equal to one. This index characterizes very well the degree of folding of a geometric chain and it has been mainly applied to the study of the degree of folding of proteins (see for instance [71, 73, 211]), although it can be applied to the folding of any linear chain.
Five years after the publication of the “folding degree” paper, the authors of [88] proposed the “subgraph centrality” as a way to characterize the importance of the nodes in a complex network. “Complex networks” are large graphs representing the skeleton of complex systems in social, ecological, cellular, molecular, infrastructural, semantic and other scenarios [78]. The subgraph centrality of a node v in a network is defined as \(SC_{v}=\sum _{j=1}^{n}\psi _{jv}^{2}\exp \left( \lambda _{j}\left( A\right) \right) \), where \(\lambda _{j}=\lambda _{j}\left( A\right) \) are the eigenvalues of the adjacency matrix of the graph and \(\psi _{jv}\) is the vth entry of its jth normalized eigenvector. Then, the so-called subgraph centralization of the network is \(\sum _{v}SC_{v}=\sum _{j=1}^{n}\exp \left( \lambda _{j}\left( A\right) \right) \) [88], which is similar to the folding degree \(I_{3}\).
In June 2005 the current author presented the lecture “Topological characterization of complex networks” at the International Academy of Mathematical Chemistry in Dubrovnik, Croatia. As a consequence Ivan Gutman proposed to organize a small seminar at a park near the port of Dubrovnik to discuss some of the mathematical aspects of the index \(\sum _{v}SC_{v}=\sum _{j=1}^{n}\exp \left( \lambda _{j}\right) \) for general graphs. As a result, a paper was published in 2006 in Croatica Chemica Acta introducing \(\sum _{v}SC_{v}\) as a molecular structure descriptor [113]. A year later the paper “Estimating the Estrada index” was published, where the authors proposed to call \(EE\left( G\right) =\sum _{j=1}^{n}\exp \left( \lambda _{j}\right) \) the Estrada index [54]. The same year a statistical mechanics interpretation of \(EE\left( G\right) \) as the partition function of a graph [83] appeared. A year later, in 2008, there were more than 30 papers published in the mathematical literature containing “Estrada index” in the title.
It seems a priori that \(EE\left( G\right) \) has emerged in different, apparently unrelated, scenarios: folding of linear chains, subgraphs in networks, and partition function in statistical mechanics. This reminds us the story told by Eugene Wigner in the first paragraph of his paper “The unreasonable effectiveness of mathematics in the natural sciences” [233] where a fellow asked a former classmate, now a statistician, about a symbol in a paper dealing with population trends. The statistician replied that the symbol was “\(\pi \)” and to clarify the skepticism of the other he added that it is “the ratio of the circumference of the circle to its diameter.” The fellow then replied more skeptical: “Well, now you are pushing your joke too far, surely the population has nothing to do with the circumference of the circle.” The situation of the Estrada index seems murkier than the one in that story, particularly after the ad hoc definition of several other variations of the index based not on the eigenvalues of the adjacency matrix, but of the graph Laplacian, distance matrix, resolvent of the adjacency matrix, Hadamard pseudo-inverse of the distance matrix (a.k.a. Harary matrix), Mittag–Leffler matrix functions of A, etc.
The goal of this paper is to make an account of the different facets of the Estrada indices. In doing so we will provide contextualization of several of these indices, many of which have been proposed in an ad hoc way. Therefore, we will provide a physical and/or mathematical context and interpretation of these indices. They include a combinatorial interpretation based on counting subgraphs, a statistical mechanics approach, a probabilistic interpretation in the context of walk-regular graphs, an interpretation on the basis of oscillations in (quantum and classical) systems of ball-and-springs, a contextualization on the basis of epidemiological models (normal and fractional) on graphs, diffusive processes with negative diffusiveness, nonlocal processes on graphs, quantification of graph radius of gyration. Although this paper does not intend to describe all the results published in the literature on this topic we make an account of many of the different bounds and estimations of the Estrada, Seidel Estrada, Harary Estrada, Laplacian Estrada, resolvent Estrada, Mittag–Leffler Estrada, and distance Estrada indices. For this purpose we include some numerical analysis of these bounds in the set of 11,117 connected graphs with 8 nodes and in five real-world networks representing a variety of complex system scenarios. The paper is written in a way that intend to be self-contained and make the necessary definitions for understanding the concepts used in it. The paper is then intended as a guide for further studies and developments in this area of spectral graph theory.
2 General definitions
Here we present some definitions which are used across the paper and settle down the notation. We consider here simple, connected graphs \(G=(V,E)\) with n nodes (vertices) and m edges.
Definition 1
A walk of length k in G is a set of nodes and edges \(v_{1},e_{1,2},v_{2}\cdots v_{k-1},e_{k-1,k},v_{k}\) such that for all \(1\le l\le k\), \((v_{l},v_{l+1})\in E\). A closed walk is a walk for which \(v_{1}=v_{k+1}\).
Definition 2
A path of length k in G is a walk in which neither vertices nor edges are repeated. A cycle is a closed path. The length of the shortest path connecting two vertices v and w is the (topological) shortest path distance \(d_{vw}\) between the two nodes. The diameter of G is the longest distance between two vertices of G.
Definition 3
A subgraph \(G'=(V',E')\) of G is a graph such that \(V'\subseteq V\) and \(E'\subseteq E\cap \left( V'\times V'\right) \). An induced subgraph is a subgraph formed by a subset of the vertices of the graph and all of the edges connecting pairs of vertices in that subset.
Definition 4
A graph \(G=\left( V,E\right) \) is connected if there is a path between every pair of nodes \(v,w\in V\). If the graph is directed we said that it is strongly connected if there is a directed path between every pair of nodes \(v,w\in V\). A (strongly) connected component in a (directed) graph is a subgraph in which any two vertices are connected to each other by (directed) paths, and which is connected to no additional vertices in the rest of the graph.
Definition 5
The degree of a node v is the number \(k_{v}\) of edges incident with that node. A graph is regular if the degree of all its nodes is the same.
The following matrices will be considered (Table 1):
Other matrices such as the Seidel adjacency matrix and Harary matrix, are defined in situ in the corresponding sections of the paper. The following types of graphs are used in this work.
-
Complete graph of n vertices \(K_{n}\): the graph having an edge between every pair of vertices.
-
Empty graph of n vertices \({\bar{K}}_{n}\): the graph having n vertices and no edges.
-
Complete bipartite graph \(K_{n_{1},n_{2}}\): the graph with \(n=n_{1}+n_{2}\) vertices in which the vertex set is partitioned into two disjoint subsets of cardinalities \(n_{1}\) and \(n_{2},\) respectively, such that every vertex in one set is connected to every vertex in the other set.
-
Star graph \(S_{n}\): the particular case of \(K_{n_{1},n_{2}}\) in which \(n_{1}=1\) and \(n_{2}=n-1.\)
-
Path graph of n vertices \(P_{n}\): the connected graph in which every vertex has degree 2, except two vertices which have degree one.
-
Cycle \(C_{n}\): a connected graph in which every vertex has degree 2.
Finally we consider two kinds of random graphs.
-
Erdős–Rényi (ER) \(G\left( n,p\right) \) [68] graph with n nodes: constructed by connecting nodes randomly in such a way that each edge is included in \(G\left( n,p\right) \) with probability p independent from every other edge.
-
Barabási and Albert (BA) one [21]: created on the basis of a preferential attachment process. The graph is constructed from an initial seed of \(m_{0}\) vertices connected randomly like in an Erdős–Rényi \(G\left( n,p\right) \). Then, new nodes are added to the network in such a way that each new node is connected to \(c\le m_{0}\) of the existing ones with a probability that is proportional to the degree of these existing nodes.
3 Estrada index and subgraph centralization
The main goal in proposing the Estrada index was for the structural characterization of networks. This index corresponds to the “centralization”, a global structural index, derived from the node centrality known as “subgraph centrality. In network theory a centrality measure (see [78] Chapter 7 and refs. therein) is any graph-theoretic quantity that captures the relative “importance” of a node in the network. Here “importance” means a relevant–mainly from applications point of view–structural feature such as connectivity, closeness to the rest of the nodes, position of a node in relation to the shortest paths connecting other others, etc. The simplest of these centrality measures is the degree of a node, which counts the number of connections that a node has. Let us first introduce the following result.
Theorem 1
Let \(G=\left( V,E\right) \) be a simple graph with adjacency matrix A. Let \(v,w\in V\), then the number of walks of length k between the nodes v and w is given by \(\left( A^{k}\right) _{vw}.\)
Remark 1
The roots of Theorem 1 can be traced back to the paper “The analysis of sociograms by matrix algebra” by Leo Festinger in 1949 [93], although Festinger mentioned it only for the case of walks of length three. Then, Leo Katz in his seminal paper “A new status index derived from sociometric analysis” extended it to longer walks in 1953 [141]. The result appeared formally in the book of Claude Berge in 1962 in the form of Corollary 1 on page 131 [29].
Then, from a walks perspective, the degree is defined as the number of closed walks of length two starting at the given node. That is, let \(v\in V\), then the degree of v is given by:
The degree of a node can be seen as a first order approximation of centrality measures that accounts for the walks of all length in the graph. That is, in a graph without self-loops the following measures can be defined
where \(c_{k}\) are coefficients which give more weight to the shorter than to the longer walks. Then, if \(c_{k}=\left( k!\right) ^{-1}\):
where \(EE_{v}\) is known as the “subgraph centrality” of the node v [88]. The term “subgraph” in the name of this centrality is due to the following.
Lemma 1
Let G be a (directed) graph. Then, every closed walk of length k starting at the node \(v\in V\) encloses one (strongly) connected subgraph having at most k (directed) edges and at most k vertices including v.
Proof
A (directed) graph G is (strongly) connected if there is a (directed) path connecting every pair of vertices G. By the definition of walk it is clear that a walk of length k between two nodes v and w cannot visit more than \(k+1\) vertices. Therefore, a closed walk, where the initial and final nodes coincide, can visit no more than k nodes. In a closed walk of length k without backtracking the number of edges visited is k, i.e., in a cycle. For a given length k, backtracking reduces the number of edges that can be visited. Therefore, a closed walk of length k cannot visit more than k edges. Obviously, the nodes and edges visited by the closed walk form the sets \(V'\subseteq V\) and \(E'\subseteq E\cap \left( V'\times V'\right) ,\) which implies that \(G'=\left( V',E'\right) \) is a subgraph of \(G=\left( V,E\right) \). Finally, because the walk of length k is a sequence \(v_{v},e_{v,v+1},v_{v+1}\cdots v_{v-1},e_{v-1,i},v_{v}\) there is a (directed) path connecting every pair of nodes in the subgraph, which means that \(G'\) is (strongly) connected. \(\square \)
The previous result implies that we can express \(EE_{v}\) as a weighted sum of subgraphs, which gives the index its name. However, as we are focused here on the Estrada index let us move to the fact that the Estrada index is the sum of the subgraph centralities of all nodes in the graph:
The sum of node centralities in a graph is known as the corresponding centralization of the graph, or simply as a graph-theoretic invariant. Therefore, the Estrada index of the graph can be seen as its subgraph centralization.
Theorem 2
Let G be a (directed) graph and let \({{\mathscr {F}}}\) be the set of all (strongly) connected subgraphs of G, and let us designate the cardinality of the set \({{\mathscr {F}}}\) by \(\eta \). Then,
where \(F_{l}\in {\mathscr {F}}\) and \(c_{l}\in {\mathbb {Q}}\).
Proof
Using Lemma 1 we can show that that \(M_{k}=\text {tr}\left( A^{k}\right) \) can be expressed as a weighted sum of (strongly) connected subgraphs. The weight of each subgraph is given by the number of closed walks of length k in the given subgraph. Then, grouping together all identical subgraphs and summing their weights we obtain the final result. \(\square \)
For instance, let us consider the first seven powers of the adjacency matrix. Then,
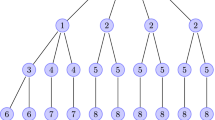
where the subgraphs are illustrated in Fig. 1.

Illustration of the small subgraphs appearing in the first seven spectral moments of the adjacency matrix of simple graphs
Then, we have the following result.
Lemma 2
Let G be a simple graph. Then, the Estrada index of G is bounded as
Proof
Based on the relations shown before for \(\text {tr}\left( A^{k}\right) \) for \(k\le 7\) and calling \(F_{1}=n\) we have that the right-hand-side part of Eq. (3.12) is \(\sum _{k=0}^{7}\tfrac{\text {tr}\left( A^{k}\right) }{k!}\) from which the inequality follows. \(\square \)
The expressions for calculating these subgraphs are given in the Appendix as adapted from [9]. The formula for \(F_{20}\) is given here by the first time.
3.1 Some elementary properties of the Estrada index
Before proceeding to more complex properties of the Estrada index let us state a few elementary ones that could be helpful in understanding the structural nature of this index. The reader is referred to the following references [54, 57, 112, 116] for details and references.
Lemma 3
Let G be a simple graph and let \(G-e\) the same graph from which edge e has been removed. Then
Corollary 1
Let G be a simple graph and let T be a tree with the same number of nodes as G. Then
Theorem 3
[53, 56] Let G be a simple connected graph with n nodes. Then
Theorem 4
Let G be a simple graph with n nodes. Then
The Estrada indices of some elementary graphs are given below.
-
\(EE\left( K_{n}\right) =e^{n-1}+\left( n-1\right) e^{-1};\)
-
\(EE\left( K_{n_{1},n_{2}}\right) =n_{1}+n_{2}-2+2\cosh \left( \sqrt{n_{1}n_{2}}\right) ;\)
-
\(EE\left( S_{n}\right) =n-2+2\cosh \left( \sqrt{n-1}\right) ;\)
-
\(\lim _{n\rightarrow \infty }EE\left( C_{n}\right) =nI_{0}\), where \(I_{0}=\dfrac{1}{\pi }\int _{0}^{\pi }e^{2\cos x}dx\);
-
\(\lim _{n\rightarrow \infty }EE\left( P_{n}\right) =\left( n-1\right) -2\cosh \left( 2\right) \).
3.2 Numerical analysis
We consider here two datasets which will be used in the rest of the paper for the numerical evaluation of the different indices and bounds. The first one consists of the 11,117 connected graphs with 8 nodes. The second one is formed by five real-world networks, which correspond to a food web at Stony stream, a network of the neurons in the worm C. elegans, the protein–protein interaction network of yeast, a representation of the Internet at the autonomous system (AS) level, and a network of the USA western power grid system. The number of nodes n, of edges m, the maximum degree of the nodes \(k_{max}\), and the diameter \(d_{max}\) of each network are given in Table 2.
The main goal of these numerical experiments is to show how close the bounds reported in the literature are to the actual values of the Estrada index. This is done because in most of the papers where these bounds are proposed there are no numerical experiments to illustrate this relation. When possible we will find some connection between structural characteristics of the networks studied and the corresponding bounds analyzed to understand why are they close or far away the actual values of the Estrada index.
First, we consider the deviation of the bound from the actual value as \(\left| EE_{\text {exact}}-EE_{\text {bound}}\right| /EE_{\text {exact}}\) expressed as percentage. We do this calculation considering the bound given in Lemma 2 for all the connected graphs with 8 nodes. The histogram illustrating the number of graphs having a given relative deviation (frequency) among the 11,117 connected graphs with 8 nodes is illustrated in Fig. 2. We should remark that we use here the terms “good bound” or refer to a bound as “better than” another just on the basis of the deviation of this bound relative to the actual value of the index. This is used only as a guide as for many cases there is large room for improvement as some of the bounds reported are orders of magnitude further from the real values of the indices.
The mean deviation is \(5.768\pm 4.169\), which indicates that this bound is a good estimation of the Estrada index for these small graphs. The largest deviation is 40.352 obtained for the complete graph \(K_{8}\). In general, the most densely connected graphs are richer in small subgraphs than the poorly dense ones, which increases the relative deviation of this bound for these graphs.

Histogram of the relative deviation of the bound given in Lemma 2 for all 11,117 connected graphs with 8 nodes
In Table 3 we illustrate the results for the five real-world networks. The largest deviation occurs for the Internet at AS indicating that in this network there are many larger subgraphs with important contribution to the Estrada index. On the other hand, the bound is very close to the actual value for the power grid of western USA, which points out that the Estrada index of this network is well approximated by counting the number of the 21 subgraphs described by Lemma 2. These differences point out clearly to the differences in the subgraph richness contained in different networks, which is what the Estrada index characterizes at the structural level.
4 Estrada index and matrix functions
Soon after the definition of the Estrada index and the subgraph centrality several authors started to be interested in these indices due to their clear relation to functions of the adjacency matrix. The study of matrix functions is an active area of research in (numerical) linear algebra [25, 97, 127, 222]. The topic of matrix functions in network theory has been recently reviewed by the authors of [28]. Therefore, we will not give too many details here and the interested reader is directed to the excellent review [28]. The goal of this section is then to establish the connection between the Estrada indices and functions of the corresponding matrices which pave the way for further sections of the article. Here we will follow the book [127].
Let M be any graph-theoretic matrix, e.g., adjacency, Laplacian, distance, etc. Then, its Jordan canonical form is given by
where
where Z is nonsingular and \(m_{1}+m_{2}+\cdot \cdot \cdot +m_{p}=n\).
Definition 6
Let \(\lambda _{1},\ldots ,\lambda _{s}\) be the distinct eigenvalues of M and let and let \(n_{i}\) be the order of the largest Jordan block in which \(\lambda _{i}\) appears, which is called the index of \(\lambda _{i}\). The function f is defined on the spectrum of M if the values
exist, which are called the values of the function f on the spectrum of M. Here \(f^{\left( j\right) }\) represents the jth derivative of f.
Then we have a definition of matrix function via the Jordan canonical form.
Definition 7
Let f be defined on the spectrum of M and let M have the Jordan canonical form given before. Then, the matrix function \(f\left( M\right) \) is given by
where
Another, equivalent, definition is given via the Cauchy integral.
Definition 8
Let \(M\in {\mathbb {C}}^{n\times n}\), then
here f is analytic on and inside a closed contour \(\varGamma \) that encloses the spectrum of M.
5 Estrada index and spectral graph theory
An obvious connection exists between the Estrada index and the area of algebraic graph theory. Algebraic graph theory [24, 30, 105] deals with the use of algebraic methods to solve problems about graphs. Of particular interest is the use of the spectra of graph theoretic matrices to understand the structure of graphs, which is known as spectral graph theory [46, 50,51,52, 213, 214]. This area of research started in an applied context when Collatz and Sinogowitz published their paper entitled: “Spektren endlicher grafen” motivated by application problems such as the vibrations of a membrane [223]. Let us consider a simple example of the connections between structural properties of graphs and their spectra: counting triangles in a graph. The number of triangles, which is a combinatorial property of the graph, can be obtained from the spectrum of the adjacency matrix as: \(\dfrac{1}{6}\sum _{j=1}^{n}\lambda _{j}^{3}\), where \(\lambda _{j}\) are the eigenvalues of the adjacency matrix. The field of spectral graph theory had a tremendous impulse in the 1970s due to its connection with electronic properties of conjugated molecules [59, 95, 124, 215, 216, 219].
The relation between the trace of a matrix and its eigenvalues immediately implies that the Estrada index of a graph can be expressed in terms of the eigenvalues of A as follows:
In general, the exponentiation of A enlarges the spectral gap \(\lambda _{1}-\lambda _{2}\) and contracts the negative part of the spectrum. On the contrary, \(\exp \left( -A\right) \) largely contracts the positive part of the spectrum and enlarges its negative part. These simple dilation/contraction effects of the main parts of the spectrum of A have important consequences on the Estrada index of a graph as we will see in the next parts of this review.
The analysis of the relation between the spectrum of a graph, i.e., the eigenvalues of its adjacency matrix, and the structure of the graph is the main goal of spectral graph theory. One of the first results on spectral graph theory related to the Estrada index was the following bounds obtained by the authors of [54].
Theorem 5
Let G be a simple graph with n nodes and m edges. Then, the Estrada index of G is bounded as
with equality attained if and only if \(G\cong {\bar{K}}_{n}\).
These bounds were further improved in [166] where the following was proved.
Theorem 6
Let G be a simple graph with n nodes and \(m\ge 1\) edges. Then, the Estrada index of G is bounded as
Based on Gauss–Radau quadrature rule the authors of [27] obtained the following bounds.
Theorem 7
Let G be a simple graph and let \(a,b\in {\mathbb {R}}\) be such that the spectrum of A is contained in \(\left[ a,b\right] \). Then, the Estrada index of G is bounded as
where \(k_{i}\) is the degree of the node i.
Remark 2
Two examples of the use of this bound are (i) considering \(a=-\lambda _{1}\) and \(b=-\lambda _{n}\); (b) considering \(a=-k_{max}\) and \(b=k_{max}\).
Another set of bounds was obtained in 2016 [156] by using the number of triangles t and \(\text {tr}\left( A^{4}\right) \) in addition to the number of nodes and edges of the graph.
Theorem 8
Let G be a simple graph with n nodes, m edges, t triangles and let \(Q=\text {tr} \left( A^{4}\right) \). Then, the Estrada index of G is bounded as
with equality attained if and only if \(G\cong {\bar{K}}_{n}\).
Other bounds have been proposed, specially lower bounds, for the Estrada index. Some examples are given below.
Theorem 9
[247] Let G be a simple graph with n nodes and let \(Z=\sum _{i=1}^{n}k_{i}^{2}\). Then, the Estrada index of G is bounded as
with equality attained if and only if \(G\cong K_{n}\) or \(G\cong {\bar{K}}_{n}\).
Theorem 10
[110] Let G be a simple graph with n nodes and m edges either without isolated vertices or having the property \(2m/n>1\), then, the Estrada index of G is bounded as
with equality if and only if G is a regular graph of degree 1.
Theorem 11
[110] Let G be a simple graph with n nodes and m edges, such that \(2m/n<1\). Then, the Estrada index of G is bounded as
where equality holds if and only if G consists of \(n-2m\) isolated vertices and m copies of \(K_{2}\).
Theorem 12
[110, 119] Let G be a simple graph with n nodes, m edges and graph nullity \(\eta _{0}\). Then, the Estrada index of G is bounded as
where equality is attained if and only if \(n-\eta _{0}\) is even, and if G consists of copies of complete bipartite graphs \(K_{r_{i},s_{i}},i=1,\ldots ,\left( n-\eta _{0}\right) /2\), such that all products \(r_{i}\cdot s_{i}\) are mutually equal.
Theorem 13
[190] Let G be a simple graph with n nodes, m edges and minimum degree \(k_{min}\). Then, the Estrada index of G is bounded as
with equality if and only if \(G\cong K_{p,p}\cup K_{1}\) with \(n=2p+1.\)
Theorem 14
[190] Let G be a simple graph with n nodes, m edges and minimum degree \(k_{min}\). Then, the Estrada index of G is bounded as
with equality if and only if \(G\cong P_{2}\) or \(G\cong P_{4}.\)
Theorem 15
[19] Let G be a simple graph with n nodes, m edges and t triangles. Then, the Estrada index of G is bounded as
with equality if and only if \(G\cong {\bar{K}}_{n}\).
Other bounds reported in the literature are based on different graph-theoretic indices and properties or for specific classes of graphs. A non-exhaustive resume is provided in Table 4.
5.1 Numerical analysis
We now do some calculations to show how close to the actual values of the Estrada index are some of the bounds studied in the previous sections. In particular, we consider the following five bounds: Bound 1 (Theorem 5); Bound 2 (Theorem 6; Bound 3 (Theorem 7 using \(a=-\lambda _{1}\) and \(b=-\lambda _{n}\)); Bound 4 (Theorem 7 using \(a=-k_{max}\) and \(b=k_{max}\)); Bound 5 (Theorem 8). First, we study these bounds for the 11,117 connected graphs with 8 nodes. The histograms of the relative deviations of these bounds are illustrated in Fig. 3, where the lower bound is always drawn in blue and the upper one in red. The means and standard deviations of the lower, upper bounds are as follow: Bound 1 (\(79.672\pm 9.485\), \(259.948\pm 44.555\)); Bound 2 (\(82.588\pm 8.499\), \(19.205\pm 14.198\)); Bound 3 (\(57.915\pm 13.701\), \(30.466\pm 5.860\)); Bound 4 (\(73.741\pm 12.359\), \(239.249\pm 156.52\)); Bound 5 (\(54.629\pm 14.214\), \(18.276\pm 8.812\)). Therefore, the best lower and upper bounds are Bound 5 (Theorem 8) for these small graphs.

Histograms of the relative deviations in percentage for: a Bound 1 (Theorem 5), b Bound 2 (Theorem 6, c Bound 3 (Theorem 7 using \(a=-\lambda _{1}\) and \(b=-\lambda _{n}\)), d Bound 4 (Theorem 7 using \(a=-k_{max}\) and \(b=k_{max}\)), e Bound 5 (Theorem 8). In blue we illustrate the histogram for the lower and in red for the upper bounds. As usual for histograms, frequency stands for the number of graphs in each bin
In Fig. 4 we illustrate the results for the five real-world networks considered in this work. In general, with the exception of Bound 3, which is based on eigenvalues, and Bound 5, which uses \(\text {tr}\left( A^{4}\right) \), the rest of the bounds are very far from the actual values for these four networks. With these two exceptions, the upper bounds exaggerate dramatically the estimation, in particular the Bound 1. Bound 4, performs very badly when the maximum degree of the network is very high and not close to the spectral radius, which is the case for instance of Internet, but also of many real-world networks. All in all, these results point out to the necessity of improving the bounds for the Estrada index of large graphs.

Plot of the estimates of the lower (blue circles) and upper (red squares) for the bounds: (1) (Theorem 5), (2) (Theorem 6, (3) (Theorem 7 using \(a=-\lambda _{1}\) and \(b=-\lambda _{n}\)), (4) (Theorem 7 using \(a=-k_{max}\) and \(b=k_{max}\)), (5) (Theorem 8). The results are for (a) Stony, (b) neurons, (c) yeast, (d) internet and (e) powergrid. The dashed lines represents the “exact” value of the Estrada index for the networks. Very large values are obtained by using variable-precision floating-point arithmetic (vpa) in Matlab
We then consider simple bounds based on the spectral radius of the adjacency matrix \(\lambda _{1}\). That is,
The results are given in Table 5. As can be seen the bounds are very close to the actual values of the Estrada index. This is a consequence of the relatively large values of the spectral radius and of the spectral gap observed in most of the real-world networks, which when exponentiated are significantly enlarged. Notice that the largest deviation is obtained for powergrid, where the spectral radius is significantly smaller than in the rest of the networks and the spectral gap is very small.
5.2 Random graphs
In the study of real-world networks it is desired to investigate how unique are their structural and dynamical properties in relation to some null model. For instance, suppose that we have found that certain network displays relatively large Estrada index in relation to other networks of the same size. Is this a characteristic feature of the topological organization of this network or just an artifact emerging from a random interconnection of their nodes? A way to investigate this is by comparing the Estrada index of these networks with those of random realizations of such networks with the same number of nodes and edges. Then, the use of random graphs is frequent in the analysis of real-world networks [220]. Two classical models, although not the only ones, to do such studies are the Erdős–Rényi random graphs [68] and the Barabási–Albert preferential attachment model [21]. For instance, the Estrada index of the network “neurons” studied here is \(EE\left( G_{\text {real}}\right) \approx 1.3062\times 10^{10}\) and that of an Erdős–Rényi random graph with the same number of nodes and edges is \(EE\left( G_{\text {ER}}\right) \approx 3.4688\times 10^{6}\), which indicates that the large Estrada index of this network is not due to a random interconnection of the neurons of C. elegans. However, the consideration of a Barabási–Albert network with the same number of nodes and edges than those in the network “neurons” gives \(EE\left( G_{\text {BA}}\right) \approx 1.2131\times 10^{10}\), which clearly points out that the relatively large Estrada index of this network may be explained by its skewed degree distribution.
For the Estrada index of random graphs, only the Erdős–Rényi model has been considered so far, indicating the necessity of extending these studied to other classes of random graphs such as the Barabási–Albert one. The following estimates were found for Erdős–Rényi random graphs based on the number of nodes and the probability of connection.
Lemma 4
[196] Let \(G_{n,p}\) be an Erdős–Rényi random graph with n nodes and probability
Then, the Estrada index is
almost surely as \(n\rightarrow \infty .\)
Theorem 16
[43] Let \(G_{n,p}\) be e an Erdős–Rényi random graph with n nodes and probability p. Then, the Estrada index is
almost surely (a.s.) if and only if \(\lim _{n\rightarrow \infty }n_{2}/n_{1}=1\).
In the case of Erdős–Rényi random bipartite graphs the author of [206] proved the following bounds for the Estrada index.
Theorem 17
Let \(G_{n_{1},n_{2},p}\) be an Erdős–Rényi random bipartite graph with \(n=n_{1}+n_{2}\) nodes, such that \(\lim _{n\rightarrow \infty }n_{2}/n_{1}\,{:}{=}\,y\in \left( 0,1\right] \), and probability p. Then, the Estrada index is bounded as
provided that \(y=1\).
6 Estrada index and statistical mechanics
The analogy of the Estrada index \(EE\left( G\right) =tr\left( e^{A}\right) \) with the partition function of a quantum system \(Z=tr\left( e^{-\hat{\tau \mathcal {H}}}\right) \) (see further for definitions) is remarkable, and was noticed soon after the definition of this index [83]. The importance of establishing this connection is twofold. On the one hand, the index can be interpreted in a physical context which at the same time facilitates its interpretation in other contexts where it is applied. On the other hand, new tools and techniques from statistical mechanics can be used to enrich the theory behind this index. Here, we will describe the statistical mechanics interpretation of the Estrada index.
Let us consider a physical system \({\mathcal {S}}\) that can be represented by a graph G, such that the total energy E of \({\mathcal {S}}\) can be obtained by the time-independent Schrödinger equation: \(\hat{{\mathcal {H}}}\varPsi =E\varPsi \), where \(\varPsi \) is the wavefunction and \(\hat{{\mathcal {H}}}\) is the Hamiltonian describing the interactions between the elements of \({\mathcal {S}}\). In certain approaches in physics and chemistry, it is customary to use an effective Hamiltonian which describes the interaction between nearest-neighbors (NN) in the system
where \(\alpha \) is a self-energy parameter for the elements of \({\mathcal {S}}\) and \(t_{NN}\) is the energy of the interaction between pairs of adjacent elements. In Chemistry this model is known as the Hückel Molecular Orbital (HMO) method [154, 239], while in Physics it is better known as the tight-binding approach [184]. The parameter \(t_{NN}\) is negative as it is supposed to be an attractive interaction. Therefore, it is common to set \(\alpha =0\) and \(t_{NN}=-1,\) such that \({\hat{\mathcal {H}}}=-A.\) Therefore, the energy levels of the system are \(E_{j}=-\lambda _{j}\) and the wavefunctions correspond to the eigenvectors associated to the eigenvalues of A.
In the statistical mechanics framework [23, 69], the Boltzmann probability \(p_{j}\left( \tau \right) \) of finding the system in a state with energy \(E_{j}\) when the inverse temperature of the system is \(\tau =\left( k_{B}T\right) ^{-1}>0\) with \(k_{B}\) being a constant and T being the temperatureFootnote 1 is
where \(Z=\text {tr}\left( e^{-\tau {\hat{\mathcal {H}}}_{NN}}\right) \). Therefore, the Boltzmann probability of the system is given by
where the Estrada index plays the role of the partition function of the graph.
We now can define the entropy of the graph as [83]
which in general is bounded as follows.
Lemma 5
Let G be a simple graph. Then, the free energy of G is bounded as
where the upper bound is attained for the null graph \({\overline{K}}_{n}\) and the lower bound is reached for the complete graph \(K_{n}\).
From the general expression of the entropy one can obtain the graph “enthalpy” \(H\left( G,\tau \right) =-\sum _{j}p_{j}\lambda _{j}\) and the graph free energy, which is sometimes named the natural connectivity of the network [83]:
We can write the logarithm of the Estrada index as follows,
which implies that
where \(\triangle =\lambda _{1}-\lambda _{2}\) is the spectral gap. Therefore, we have proved the following.
Lemma 6
Let G be a simple graph. Then, the free energy of G is bounded as
More generally, the free energy of a graph can be bounded by using the many bounds obtained for the Estrada index which have been previously reported in the literature. One important example is the following [83].
Lemma 7
Let G be a simple graph. Then, the free energy of G is bounded as
where the lower bound is obtained for the complete graph \(K_{n}\) and the upper bound for the null graph \({\overline{K}}_{n}\).
6.1 Numerical analysis
We consider here numerical experiments to illustrate some general characteristics of the indices described in the previous section. We report the change of the entropy, enthalpy and free energy of all connected graphs with the increase of the number of edges in the connected graphs with 8 nodes, i.e., its edge density. It can be seen in Fig. 5, as expected, that the three parameters decay with the increase in the edge density. However, it should be noticed that for graphs with exactly the same number of edges there is a wide variability in these parameters, particularly for the entropy. The readers interested in more details about the implications of these parameters on the structure of graphs are referred to [83].

Plots of the entropy (a), enthalpy (b) and free energy (c) versus the number of edges in all connected graphs with 8 nodes
We then computed the three statistical mechanics parameters for the five networks studied here. The results are in Table 6 where we also give the values of the edge density of these graphs: \(\delta \left( G\right) =2m/\left( n\left( n-1\right) \right) \) where n and m are the number of nodes and edges of the graph. The most densely connected network, Stony, displays the lowest entropy and the least dense, powergrid, displays the largest one. However, as can be seen for the intermediate values of \(\delta \left( G\right) \) this trend is not always followed as there are other structural factors influencing these statistical mechanics parameters. For instance, the network of Internet at AS displays the second smaller entropy of all the networks and the lowest free energy of all, although it is not very dense.
7 Marginal probability, walk entropy and walk regularity
Having in mind the importance that the probability \(p_{j}\left( \tau \right) \) has in the definition of statistical mechanics properties of networks we propose to explore it further in this section. That is, we consider here the role of the Estrada index in defining some probability-based measures for graphs. Let us start with two definitions from basic statistics (see for instance [49, Ch. 2]).
Definition 9
The conditional probability \(P\left( A\left| B\right. \right) \) is the probability that the event A occurs given that the event B occurs.
Definition 10
The marginal probability is the unconditional probability of one event A. That is, the probability that A occurs regardless of whether B occurs or not.
To obtain the marginal probability of an event A one should sum all possible configurations of the other event to obtain a weighted average probability
Let us then return to the time-independent Schrödinger equation:
where \(E_{j}\) are the energy levels of the system and \(\psi _{j}\) are the corresponding eigenfunctions. As usual, \(\left| \psi _{j,v}\right| ^{2}\) represents the probability of finding a quantum particle at a given vertex v and time conditional to the system to be at the energy level described by the wave function \(\psi _{j}\). That is, \(\left| \psi _{j,v}\right| ^{2}=P\left( v\left| j\right. \right) \) using the notation defined before.
On the other hand, \(p_{j}\left( \tau \right) \) which was defined in the previous section accounts for the probability that the system is at the jth energy level for a given \(\tau \). Then, fixing \(\tau \), \(p_{j}\left( \tau \right) =P\left( j\right) .\) Therefore, the marginal probability that the node v is occupied by the quantum particle independently of the energy level in which the system is, is given by:
which can be expressed as [86]:
The corresponding entropy, known as the walk-entropy of the graph [86], is defined using Shannon formula:
We now consider a graph property known as walk-regularity and the role that the walk entropy play in its characterization. Let us introduce the concept of walk regularity first (see for instance [106]).
Definition 11
A graph is walk-regular if \(\forall i,j\in V\) and for every nonnegative integer r, \([A^{r}]_{ii}=[A^{r}]_{jj}\).
The following conjecture was formulated in [86] as an extension of the conjecture related to the subgraph centrality which had been previously stated in [88].
Conjecture 1
A graph is walk-regular if and only if \(S^{w}\left( \tau \right) =\ln n\) for all \(\tau >0.\)
Let us then introduce some necessary concepts for the further developments in the proof of this conjecture.
Definition 12
Two vertices i, j of G are \(\tau \)-subgraph equivalent if \([e^{\tau A}]_{ii}=[e^{\tau A}]_{jj}\).
Definition 13
A graph is \(\tau \)-subgraph regular if all pairs of vertices are \(\tau \)-subgraph equivalent.
The following result was a step forwards the proof of Conjecture 1.
Theorem 18
[26] A graph G is walk-regular if and only if G is \(\tau \)-subgraph regular for all \(\tau \in \mathscr {{\mathcal {I}}}\subseteq {\mathbb {R}}\), where \({\mathcal {I}}\) is any set of real numbers containing an accumulation point.
In the saga, in [151] the authors found some counterexamples to a new conjecture proposed in [26] and stated a new conjecture. The final proof of Conjecture 1 came from an elegant Theorem in 2021 [18] where the authors used results from the Lindemann–Weierstrass Theorem.
Theorem 19
[18] Let \(\tau >0\) be an algebraic number and let G be a connected undirected graph with adjacency matrix A.
-
1.
G is \(\tau \)-subgraph regular if and only if G is walk-regular.
-
2.
If two vertices i, j are \(\tau \)-subgraph equivalent, then the degree and eigenvector centralities of i and j are equal.
-
3.
If G is \(\tau \)-subgraph regular, then the degree and eigenvector centralities are also identical for all nodes.
Walk regular graphs can be constructed by using Kronecker product of the adjacency matrices of two walk-regular graphs [106]. That is, if \(G_{1}\) and \(G_{2}\) are walk regular graphs, then \(G_{1}\otimes G_{2}\) is also walk regular. Therefore, we have the following result.
Proposition 1
[86] Let \(G_{1}\) and \(G_{2}\) be two simple graphs with \(n_{1}\) and \(n_{2}\) vertices, respectively. Then,
for all \(\tau >0\) if \(G_{1}\) and \(G_{2}\) are walk-regular.
8 Bipartivity, signed graphs and Seidel Estrada index
A graph \(G=\left( V,E\right) \) is bipartite if its set of nodes V can be split into two subsets \(V_{1}\) and \(V_{2}\) such that there are edges only between the two sets but no edge connects vertices in neither \(V_{1}\) nor \(V_{2}\) . Therefore, a graph is or is not bipartite. However, in certain real-world situations a graph can be “close to bipartite”, meaning that by removing very few edges the graph become bipartite. This is the case, for instance, of human sexual contact networks and human romance or partnership networks as remarked in [130]. In 2003 the authors of [130] proposed to quantify the “bipartivity” of a graph. The first of their measures is defined by
where \(m_{f}\) is the number of edges that if removed the network becomes bipartite.Footnote 2 The calculation of this index is computationally intractable as it is NP complete. The authors [130] then proposed another index in which \(m_{f}\) is assessed computationally. Here we will show how the use of the Estrada index of graphs allows the calculation of an index of bipartivity which depends only on the eigenvalues of the graph. The first of these approaches was published in [87] and will not be discussed here. Instead we will consider the index studied in [82]. Another measure of bipartivity was also proposed in [180]. We will start with some basic definitions for the sake of completeness of this section.
A bipartite graph is characterized by the following result proved by Konig in 1916 [153] (see also [15]).
Theorem 20
A graph is bipartite if and only if G has no cycles of odd length.
Corollary 2
A graph G is bipartite if and only if it contains no closed walks of odd length.
The Estrada index of a graph can be expressed in terms of the hyperbolic matrix functions as
The \(\text {tr}\left( \sinh \left( A\right) \right) \) counts the odd-length closed walks in the graph:
Similarly, \(\text {tr}\left( \cosh \left( A\right) \right) \) counts the even-length closed walks. An odd closed walk of any length in the graph exists if and only if the graph contains at least one odd-length cycle. Therefore, we can reformulate the previous Corollary as.
Corollary 3
A graph G is bipartite if and only if \(\text {tr} \left( \sinh \left( A\right) \right) =0\).
Based on this result the authors of [82] proposed the following.
Definition 14
The bipartivity of a graph is defined as the relative difference between the number of closed walks of even and odd length,
where \(G^{-}\) is the graph in which all the edges are weighted by \(-1\).
It is easy to see that \(\text {tr}\left( \exp \left( -A\right) \right) \) reaches its minimum for the complete graph, which is also the graph for which \(EE\left( G\right) \) is maximum (see an example in Fig. 6). In this figure the reader can also visualize how the bipartivity index changes monotonically with the increase of the number of edges “frustrating” the bipartition.

Illustration of the change in the bipartivity index with the increase in the number of edges in a complete bipartite graph
Then, we have the following result.
Lemma 8
Let G be a simple graph. Then, its bipartivity is bounded as
where the upper bound is attained for any bipartite graph and the lower bound is reached for \(G\cong K_{n}.\)
Therefore, we have that
8.1 Signed graphs
In order to understand why the index \(b\left( G\right) \) quantifies the bipartivity of a graph we should start by recognizing that the numerator of \(b\left( G\right) \) is the trace of the adjacency matrix of a fully-negative signed graph. For an exhaustive compilation of mathematical results about signed graphs the reader is referred to [241]. Let us introduce here the necessary concepts for understanding the connections between bipartivity and signed graphs. We will start with the following.
Definition 15
A signed graph is the 4-tuple \(G^{+-}=\left( V,E,\varSigma ,\varphi \right) \), where \(V=\left\{ v_{1},\ldots ,v_{n}\right\} \) is the set of nodes or vertices representing individual social entities, \(E\subseteq V\times V\) is the set of edges formed by (ordered or unordered) pairs of nodes, \(\varSigma =\left\{ +,-\right\} \) is a set of signs, positive and negative relations,Footnote 3 and \(\varphi :E\rightarrow \varSigma \) is a mapping assigning one sign to each edge.
Therefore, the numerator of \(b\left( G\right) \) counts the number of negative cycles in G, where a negative cycle is any cycle in which the product of the sign of its edges is negative. In a fully-negative graph, the negative cycles are the odd-length cycles, which are indeed those that break the bipartivity of the graph. In the theory of signed graphs we have the following important concept (for a list of references and some critical account see [79]).
Definition 16
A signed graph \(G^{+-}\) is balanced if all its cycles are positive.
Then, it is obvious that a fully-negative graph is balanced if and only if it is bipartite. In the general case of any signed graph the following result is well-known.
Theorem 21
A signed graph \(G^{+-}\) is balanced if and only if its nodes can be separated into two mutually disjoint sets, such that positive edges joint nodes only inside the subsets and negative edges joint nodes from different subsets.
The adjacency matrix of a signed graph can be expressed as: \(A=A^{+}-A^{-},\) where \(A^{+}\) represents the adjacency between pairs of nodes connected by positive edges, and \(A^{-}\) represents the adjacency between pairs of nodes connected by negative edges.
Definition 17
[79, 81] The balance of a signed network with adjacency matrix \(A=A^{+}-A^{-}\) can be quantified by
where \(\left| \cdot \right| \) represents the entrywise absolute of the corresponding matrix.
The following result was proved in 1980 [2].
Theorem 22
For any signed graph, the matrices \(A^{+}-A^{-}\) and \(\left| A^{+}-A^{-}\right| \) are isospectral (cospectral) if and only if the signed graph is balanced.
Then, we have the following.
Theorem 23
Let \(G^{+-}\) be a signed graph with adjacency matrix \(A^{+}-A^{-}\). Then,
where the upper bound is attained for any balanced graph and the lower bound is reached for a fully-negative complete graph.
Then, we also have that
which is a maximally unbalanced graph.
8.2 Seidel Estrada index
Let us focus now on a particular kind of signed graph. Let J and I be the all-ones and identity matrices, respectively. The following matrix was introduced in [221] and it is nowadays known as the Seidel matrix.
Definition 18
The Seidel matrix of a simple graph G with adjacency matrix A is defined as
Obviously, \(S\left( G\right) =A^{+}-A^{-}\) is the adjacency matrix of a signed graph \(G^{+-}\), where \(A^{+}\text {=}J-I-A\) and \(A^{-}\text {=}-A\). Therefore, we have the following result.
Theorem 24
Let \(G^{+-}\) be a signed graph with adjacency matrix \(S\left( G\right) \). Then, G is balanced if and only if \(S\left( G\right) \) is isospectral to \(A\left( K_{n}\right) \).
Proof
The balance index of a signed graph with adjacency matrix \(S\left( G\right) \) is
which immediately implies the result. \(\square \)
Remark 3
The term \(\text {tr}\left( \exp \left( S\left( G\right) \right) \right) \,{=:}\,SEE\left( G\right) \) was denoted in [122] as the Seidel Estrada index of the graph. The name Seidel honors mathematician Johan Jacob Seidel (1919–2001).Footnote 4
We can prove here the following result.
Theorem 25
Let \(K_{n_{1},n_{2}}\) be a complete bipartite graph. Let \(S\left( K_{n_{1},n_{2}}\right) \) be the Seidel matrix of \(K_{n_{1},n_{2}}\). Then, \(S\left( K_{n_{1},n_{2}}\right) \) and \(A\left( K_{n_{1}+n_{2}}\right) \) are cospectral.
Proof Using the structural balance theorem we can show that the signed graph whose adjacency matrix is \(S\left( K_{n_{1},n_{2}}\right) \) is balanced. That is, we can split the set of nodes into two disjoint sets containing \(n_{1}\) and \(n_{2}\) nodes, respectively, in which the inter-set edges are negative and all intra-set edges are positive. Then, using Theorem 24 we prove the result. \(\square \)
Remark 4
The previous result implies that any signed graph with adjacency matrix
is balanced. Also that \(SEE\left( K_{n_{1},n_{2}}\right) =EE\left( K_{n_{1}+n_{2}}\right) =\exp \left( n\right) +\left( n-1\right) e^{-1}.\)
In [122] it was proved the following results for the Seidel Estrada index.
Theorem 26
Let G be a simple graph with \(n\ge 2\) nodes, m edges, t triangles and \(Z=\sum _{i}k_{i}^{2}\). Then,
Theorem 27
Let G be a simple k-regular graph. Then,
Theorem 28
Let G be a simple k-regular bipartite graph. Then,
In this subsection we have shown that although the so-called Seidel Estrada index was proposed and studied in a completely ad hoc way, it can be connected with the theory of signed graphs. This may facilitate further studies of this index, its extension to consider statistical mechanics parameters and its applications to the study of real-world signed graphs.
8.3 Negative absolute temperatures and the Onsager Estrada index
In the definition of the bipartivity index we have considered in the numerator of Eq. (8.4) the term \(EE\left( G^{-}\right) =\text {tr}\left( \exp \left( -A\right) \right) .\) In the context of statistical mechanics which we have analyzed in Sect. 6 this corresponds to consider the inverse temperature \(\tau =-1\). So far, we have considered the inverse temperature \(\tau \) to be positive. So, what a negative inverse temperature could mean? Let us first analyze what is the physical definition of \(\tau \). Let S be the statistical entropy, which is a function of the possible microstates of the system, and let E be the system’s energy. Then, the absolute temperature is defined as:
Graphically, it corresponds to the slope of the curve of entropy versus energy at a given point. Therefore, as can be seen in Fig. 7 the inverse temperature can be negative. In a system at negative temperature the high-energy states are more occupied than low-energy states. Such systems have been created by physicists in the real-world [35].

Sketch of the plot of entropy versus energy used to illustrate the definition of the inverse temperature which is given by the slope of the curve in a given point. The scale of inverse temperature is given on top of this plot
From a graph-theory perspective what it means that “the high-energy states are more occupied than low-energy states”? In the Sect. 6 we have considered that the Hamiltonian describing the graph as a quantum system is given by the negative of the adjacency matrix \({\hat{\mathcal {H}}}_{NN}=-A\), such that the energy levels of the system are \(E_{j}=-\lambda _{j}\) and the wavefunctions are the eigenvectors associated to the eigenvalues of A. In this case the partition function of the graph is given by \(Z=\sum _{j=1}^{n}\left( e^{\tau \lambda _{j}}\right) \) with \(\tau >0\). Therefore, for \(\tau \rightarrow \infty \), we have that \(Z=e^{\tau \lambda _{1}}.\) In the current case, where \(\tau <0\), we have that when \(\tau \rightarrow -\infty \), the partition function is: \(Z=e^{\tau \lambda _{n}}.\) This means that we have changed the “importance” given to the different eigenvalues in the Estrada index, giving now more weight to the contributions of the smallest ones. Because Lars Onsager (1903-1976) was the scientist who first study the negative absolute temperatures in [178] we propose to name the following index in his honor.Footnote 5
Definition 19
The Onsager Estrada index of G is defined as
First let us consider some elementary results, which are presented here by the first time. First, because \(\text {tr}\left[ \exp \left( -A\right) \right] =\text {tr}\left[ \cosh \left( A\right) \right] -\text {tr}\left[ \sinh \left( A\right) \right] ,\) and due to the fact that a graph is bipartite if and only if it has no odd cycles, we have the following result.
Lemma 9
Let G be a simple graph. Then, \(OEE\left( G\right) =\text {tr} \left[ \cosh \left( A\right) \right] \) if and only if G is bipartite. In this case \(OEE\left( G\right) =EE\left( G\right) \).
Remark 5
Some graphs for which \(OEE\left( G\right) =EE\left( G\right) \) for which we can write explicitly the indices are
-
\(OEE\left( K_{n_{1},n_{2}}\right) =EE\left( K_{n_{1},n_{2}}\right) =n_{1}+n_{2}-2+2\cosh \left( \sqrt{n_{1}n_{2}}\right) \);
-
\(OEE\left( S_{n}\right) =EE\left( S_{n}\right) =n-2+2\cosh \left( \sqrt{n-1}\right) \);
-
\(\lim _{n\rightarrow \infty }EE\left( C_{n}\right) =nI_{0}\), n even, where \(I_{0}=\dfrac{1}{\pi }\int _{0}^{\pi }e^{2\cos x}dx\);
-
\(\lim _{n\rightarrow \infty }EE\left( P_{n}\right) =\left( n-1\right) -2\cosh \left( 2\right) \).
Lemma 10
Let G be a simple graph and let \(\lambda _{n}\) be the least eigenvalue of A. Then,
The following result allows us to compare \(OEE\left( G\right) \) with \(EE\left( G\right) \) using Eq. (3.12).
Lemma 11
Let G be a simple graph. Then, the Onsager Estrada index of G is bounded as
As we can see only bipartite subgraphs make a positive contribution to the Onsager Estrada index.
8.4 Numerical analysis
Here we compute the bipartivity index for all connected graphs with 8 nodes. We select two other network parameters to compare with the bipartivity. The first is the edge density \(\delta \left( G\right) =2m/\left( n\left( n-1\right) \right) \) where m is the number of edges. The reason for selecting this parameter is that as the density of the graph increases the number of cycles of any length will also increase. For instance, in Erdős–Rényi random graphs we can find that the number of triangles \(F_{4}\) (see Fig. 1) is bounded as
The second parameter is the clustering coefficient \(C\left( G\right) \), which is defined as \(C\left( G\right) =3F_{4}/F_{3}\), where \(F_{3}\) is the number of paths of length 2 in the graph (see [78]). Here again we would expect that the bipartivity and the clustering coefficient are negatively correlated due to the fact that the increase in clustering means the relative increase in the number of triangles. However, bipartivity is also related to other odd-cycles in the graphs and we want to investigate their influence of this network parameter.
In Fig. 8 we plot the results of the bipartivity vs. the clustering coefficient where the points are colored according to the number of edges that the graph has. As can be seen the most dense graphs also have the highest clustering and lowest bipartivity, as expected. Although there is a decaying trend between the bipartivity and the clustering coefficient, it is clear that even for these small graphs, the contribution of longer cycles to the bipartivity is very important.

Scatter plot of the bipartivity and the clustering coefficient of all connected graphs with 8 nodes. The points in the plot are colored by the number of edges that the corresponding graph has
In Table 7 we give the values of the bipartivity for the five networks studied in this work. The networks of Stony and powergrid have significant bipartivity, while neurons and yeast are highly non-bipartite. As can be seen in the Table there is not a clear trend between bipartivity and edge density nor to the clustering coefficient of these graphs.
In the case of Stony we have obtained a bipartition of the network using a technique also based on matrix exponentials. The result is illustrated in Fig. 9 where the edges colored in red or in blue are those that frustrate the bipartition of the network, i.e., those that, if removed, make the graph bipartite.

Illustration of a bipartition of the network of Stony stream using the method developed by [82]. The dotted lines joints the two partitions and continuous lines connect vertices inside the same partition, i.e., they frustrate the bipartition of the network
9 Gaussian Estrada indices
As we have seen in the previous analysis there are situations in which the Estrada index of a graph is mainly determined by the spectral radius of the adjacency matrix. That is, when \(\lambda _{1}\gg \lambda _{2}\gg 1\) the sum \(\sum _{j}\exp \left( \lambda _{j}\right) \) is approximated very well by \(\exp \left( \lambda _{1}\right) .\) From the structural point of view, this means that most of the information contained in the eigenvalues \(\lambda _{j}\) for \(j>1\) is making almost no contribution to the Estrada index. It is well-known that structural information encoded by some other eigenvalues other than \(\lambda _{1}\) is very important for several kinds of problems [46, 50,51,52, 213, 214]. For instance, the nullity of the graph (see [111] for a review), i.e., the multiplicity of the zero eigenvalue of the adjacency matrix, plays a fundamental role in explaining magnetic properties of materials [230]. In general, many real-world networks have large multiplicity of \(\lambda _{j}=0\) (nullity) and of \(\lambda _{j}=-1\) which points to the fact that some important structural information on these networks is encoded in eigenvalues different from \(\lambda _{1}\) .
In this section we investigate Estrada indices that give higher weights to the contribution of eigenvalues other than the spectral radius. In particular we use here a technique known as spectral folding [36, 229] to produce Gaussian Estrada indices [5, 80]. In the following let \({\tilde{\lambda }}\) be a given reference eigenvalue, \(I\left( z\right) \) be the modified Bessel function of the first kinds, \(\text {erf}\left( z\right) \) be the error function and \(\text {erfc}\left( z\right) =1-\text {erf}\left( z\right) \) be the complimentary error function [5, 80].
Definition 20
The Gaussian Estrada index of G is defined as
The idea behind this Gaussian Estrada index is explained graphically in Fig. 10. The name Gaussian honors Carl Friedrich Gauss (1777–1855).Footnote 6

Illustration of the gaussianized spectrum method. The eigenvalues of the adjacency matrix of the network are folded at \({\tilde{\lambda }}\) into the spectrum of \(\left( {\tilde{\lambda }}I-A\right) ^{2}\). Then they are exponentiated to give more weight to \(\lambda _{\text {ref}}\)
First we give a few general results for the Gaussian Estrada index (see [5, 80]).
Lemma 12
Let G be any graph. Then,
Theorem 29
Let G be a graph with n nodes and m edges. Then,
where \(k_{i}\) is the degree of the node i in the graph G .
Lemma 13
Let \(K_{n}\) be the complete graph of n nodes. Then
Lemma 14
Let \(P_{n}\) be a path having n nodes. Then, asymptotically as \(n\rightarrow \infty \) and for some \(c\in (0,\pi )\)
Lemma 15
Let \(C_{n}\) be a cycle having n nodes. Then, asymptotically as \(n\rightarrow \infty \) and for some \(c\in (0,\pi )\)
Lemma 16
Let \(K_{n_{1},n_{2}}\) be the complete bipartite graph of \(n_{1}+n_{2}\) nodes. Then
Corollary 4
Let \(K_{1,n-1}\) be the star graph of n nodes. Then
In [210] the authors studied several bounds for the Gaussian Estrada index when \({\tilde{\lambda }}=0\) which are resumed below.
Theorem 30
Let G be a simple graph with n nodes and \(m\le \dfrac{n}{2}\) edges and let \({\tilde{\lambda }}=0\). Then,
with equality if and only if \(G\cong {\bar{K}}_{n}\).
Theorem 31
Let G be a simple graph with n nodes and \(m\le \dfrac{n}{4}+\dfrac{n\left( n-1\right) }{4}\exp \left( -4m/n\right) \) edges and let \({\tilde{\lambda }}=0\). Then,
with equality if and only if \(G\cong {\bar{K}}_{n}\).
Remark 6
The previous bound can only be applied for very sparse networks where the density \(\delta \left( G\right) =2m/\left( n\left( n-1\right) \right) \) is bounded as
Theorem 32
Let G be a simple graph with \(n\ge 2\) nodes and \(m\le \dfrac{n}{2}\) edges. Let \(M=\sum _{i}k_{i}^{2}\), then,
with equality attained if and only if G admits \(\lambda _{1}=\sqrt{M/n}\) , \(\lambda _{2}=\cdots =\lambda _{k}=\left( n-2k+1\right) ^{-1}\sqrt{M/n}\) and \(\lambda _{k+1}=\cdots =\lambda _{n}=-\left( n-2k+1\right) ^{-1}\sqrt{M/n}\) for some \(1\le k\le \left\lfloor \dfrac{n}{2}\right\rfloor \).
9.1 Random graphs
In this subsection we consider the estimation of the Gaussian Estrada indices of random graphs. The reasons for studying random graphs have been explained in Sect. 5.2. Here we will consider both Erdős–Rényi and Barabási–Albert random graphs.
Theorem 33
[5, 80] For an Erdős–Rényi random graph \(G_{n,p}\) with \(\frac{\ln n}{n}\ll p\) for significantly large \(r=2\sqrt{np\left( 1-p\right) }\), we have
if \({\tilde{\lambda }}=0,\) and
if \({\tilde{\lambda }}=-1,\) as \(n\rightarrow \infty \).
Theorem 34
[5, 80] Let \(G_{BA}\) be a Barabási–Albert random graph and let \(r=2\sqrt{np\left( 1-p\right) }\). Then, when \(n\rightarrow \infty \),
if \({\tilde{\lambda }}=0,\) and
if \({\tilde{\lambda }}=-1\).
9.2 Double Gaussian Estrada index
Another important situation appearing in many molecular systems is the existence of two reference eigenvalues, typically located around the mid part of the spectrum, which are of great relevance for understanding the behavior of these systems. In 1952, Fukui et al. [99] calculated the chemical reactivity of molecules by using molecular orbital theory, but their method neglects all molecular orbitals except two, the occupied one of higher energy (HOMO) and the vacant one of lowest energy (LUMO). According to Fukui the HOMO gives a molecule a character of electron donor, whereas the LUMO acts as an electron acceptor. The theory was further applied by Woodward and Hoffmann [234] in the interpretation of the stereochemistry of electrocyclic organic reactions. Both, the Frontiers Molecular Orbital (FMO) theory of Fukui and the Woodward-Hoffmann rules are paradigmatic examples of success of theoretical approaches in Chemistry. Both Fukui and Hoffmann won the Nobel Prize in Chemistry for such works. Since then [98], FMO is widely applied for studying chemical reactivity [176].
Let us consider here, for instance, molecular systems \({\mathcal {S}}\) where the energy E is obtained by the time-independent Schrödinger equation: \(\left( \alpha I+t_{NN}A\right) \varPsi =E\varPsi \), as described before. Then, when \(\alpha =0\) and \(t_{NN}=-1,\) the energy levels of the system are \(E_{j}=-\lambda _{j}\). Typically, the states with energy levels \(E_{j}<0\) are occupied by electrons, while those with energy \(E_{j}\ge 0\) are empty. Then, the energy level just below \(E_{j}=0\) is known as the highest occupied molecular orbital (HOMO) and the one just over \(E_{j}=0\) is the lowest unoccuppied molecular orbital (LUMO). These two molecular orbitals are fundamental in understanding the chemical reactivity of these molecular systems [182]. They can be described in the current approach by the negative of two references eigenvalues \({\tilde{\lambda }}_{1}\) and \({\tilde{\lambda }}_{2}\) of the adjacency matrix. Then, we have the following [6] (Fig. 11).
Definition 21
The double-Gaussianized Estrada index of G is defined as

Schematic illustration of the double Gaussianization of the graph spectra. The eigenvalues of the adjacency matrix are folded at two different reference eigenvalues and then exponentiated as illustrated in the right part of the figure
Lemma 17
Let G be any graph. Then,
Lemma 18
Let \({\tilde{\lambda }}_{1}=-1\) and \({\tilde{\lambda }}_{2}=1\), such that \(EE\left( G,-1,1\right) =\text {tr} \left( \exp \left[ -\left( A^{2}-I\right) ^{2}\right] \right) .\) Let \(K_{n}\), \(K_{n_{1},n_{2}}\) and \(K_{1,n-1}\) be the complete, bicomplete and star graphs of n nodes, respectively. Then
Lemma 19
Let \(G_{b}\) be connected bipartite graph of n nodes, then
Conjecture 2
Let G be any connected graph of n nodes, then
Claim 1
The double-Gaussianized Estrada index of a simple graph has the following Taylor series expansion:
where \(a_{k}={\sum }_{4a+2b=2k}(-1)^{a}\frac{2^{b}}{a!b!}\), and a, b are non negative integers.
9.3 Numerical analysis
We consider here the bounds given in Theorem 30 and in Theorem 32 for all connected graphs with 8 nodes. The bound given in Theorem 31 is not applicable in all the cases and we do not considered it for this general case. We show in Fig. 12 the histogram of the relative deviations for these two bounds in these small graphs. The mean relative deviations (in %) of the two bounds are, respectively \(89.84\pm 2.51\) and \(66.51\pm 6.55\), which points to the fact that the second bound is a better approximation than the first one to the Gaussian Estrada index.

In Table 8 we give the values of the three bounds for the five networks studied here as well as the values of the actual Gaussian Estrada index for \({\tilde{\lambda }}=0\). The bound given in Theorem 30 is extremely far away from the actual values and practically says the same as the trivial bound \(GEE_{0}\left( G\right) >0.\) The same happens for Theorem 32 in the cases of Stony and neurons, but it gives more decent estimations for the cases of the bigger networks of Internet and powergrid.
10 Mittag–Leffler Estrada indices
As we have seen in previous sections of this paper, the Estrada indices of a graph may arise as the solution of the linear dynamical system
where M is a given graph matrix, with initial condition \(u\left( 0\right) =u_{0}\). The solution of this system is given by \(u\left( t\right) =\exp \left( tM\right) u_{0}\). The case in which \(M=A\) is the adjacency matrix of the graph has been analyzed in the paper [172].
Let us consider that, instead of using the first derivative of \(u\left( t\right) \) respect to time, we use a fractional derivative. Then we have a system of the form:
for \(0<\alpha <1\), where the Caputo fractional derivative [37] is given by
where \(f^{\left( k\right) }\) represents the kth derivative of f and \(\varGamma \left( z\right) \) is the Euler gamma function:
The solution of this system is given by
where
which are the Mittag–Leffler matrix functions (for properties of Mittag–Leffler matrix function the reader is referred to [102, 183]).
To catch the analogy with the standard Estrada index of a graph we can write is as
due to the fact that \(\varGamma \left( k+1\right) =k!\),
Therefore we can generalize the Estrada index to account for a wider class of penalization functions, such that we write
At the same time we keep in mind that \(EE_{\alpha ,\beta }\left( G\right) \) is the solution of a system of equations of the form \(D_{t}^{\alpha }u\left( t\right) =Au\left( t\right) \) as we will explore later. We propose the name Mittag–Leffler Estrada index for \(EE_{\alpha ,\beta }\left( G\right) \) in honor to the mathematician Gösta Mittag–Leffler (1846–1927).Footnote 7 Some examples of closed formulas are illustrated in Table 9.
One important aspect of these functions in general is that by controlling the parameters \(\alpha \) and \(\beta \) we can penalize the walks of k length in different ways. For instance, if \(\left( \left( \alpha -1\right) k+\beta \right) <0\) for all k, then the walks of any length are penalized less than in \(EE_{1,1}\left( G\right) \). This is for instance, the case of \(EE_{1/2,1}\left( G\right) \) (see Table 9). In those cases where \(\left( \left( \alpha -1\right) k+\beta \right) >0\) for all k, the penalization of all walks is heavier than in the exponential, which are for instance the cases of \(EE_{\alpha >1,\beta }\left( G\right) \). There is a third case which occurs when \(\left( \alpha -1\right) k+\beta \) is negative for \(0\le k\le k_{c}\) and positive for \(k>k_{c}\), where \(k_{c}\) is a given integer. This is the case, for instance, of the matrix functions where \(k_{c}<-\left( \dfrac{\beta }{\alpha -1}\right) \).
Let us first consider the Estrada index \(EE_{1/2,1}\left( G\right) =\text {tr}\left( \exp \left( A^{2}\right) {{\left( I+\text {erf}\left( A\right) \right) }}\right) \). A similar index was defined and studied in the paper [89] in the following form:
where k!! is the double factorial of k. The goal of defining such index was to account for less penalization of longer walks, which may play an important role in several applications (for some examples see [1, 89]) . For instance, if we compare the subgraph expansion of \(EE_{1/2,1}\left( G\right) \) with that of \(EE_{1,1}\left( G\right) \) (see Eq. (3.12)) we can clearly observe the differences in the penalization of bigger subgraphs made by both indices. In the case of \(EE_{1/2,1}\left( G\right) \) we have:
which points out that triangles are more than 20 times less penalized by this function that by the exponential, squares are penalized 30 times less, pentagons, hexagons and heptagons are penalized 93, 120 and 433 times less by \(EE_{1/2,1}\left( G\right) \) than by \(EE_{1,1}\left( G\right) \). Let us show a practical example on how these different penalizations influence the Estrada indices of cycle graphs. In Fig. 13 we illustrate three graphs with 8 nodes but having different length of their main cycles. In \(G_{I}\) there is a triangle and an heptagon, in \(G_{II}\) a square and a hexagon, and in \(G_{III}\) two pentagons. The index \(EE_{1,1}\left( G\right) \) of the three graphs are: 21.68, 20.64 and 20.38, respectively. That is, there is a difference of 4.8% between \(G_{I}\) and \(G_{II}\) and of 1.25% between \(G_{II}\) and \(G_{III}\). On the other hand, the index \(EE_{1/2,1}\left( G\right) \) is 672.24, 540.58 and 507.13 for \(G_{I}\), \(G_{II}\) and \(G_{III}\), respectively, which represent 19.6% of difference between the first pair and 6.2% between the second one.

Examples of three graphs with 8 nodes and chordless cycles of different lengths: \(G_{I}\) has a triangle and an heptagon; \(G_{II}\) has a square and a hexagon; \(G_{III}\) has two pentagons
Finally, we consider the Mittag–Leffler Estrada indices defined as follow:
These indices were developed and studied in 2010 in the paper [75], as a way to penalize more heavily the longer walks than in the matrix exponential. The indices \(EE_{1,\beta +1}\left( G\right) \) are also the trace of the so-called matrix \(\varPsi \) functions:
where
which obey the following recurrence formula:
When the adjacency matrix is not singular we can represent these Estrada indices as follow
and so forth. Other Mittag–Leffler matrix functions in the context of network theory have been recently studied in [13].
10.1 Resolvent Estrada index
The context of Mittag–Leffler Estrada indices also allow the consideration of other indices that were previously proposed in the literature. This is the case of an index proposed in 2010 in [85]. The goal of introducing this index was to change the penalization of the different powers of the adjacency matrix from k! to \(\left( n-1\right) ^{k}\) to increase the contribution of walks of longer lengths. The index proposed in [85] corresponds to the trace of the resolvent of the adjacency matrix:
which eventually was proposed in [27] to be named as the resolvent Estrada index of the graph. It can be seen that the resolvent Estrada index is a particular case of Mittag–Leffler Estrada index:
Remark 7
The use of the normalization \(c_{k}=1/\left( n-1\right) \) in \(\left( c_{k}A\right) ^{k}\) is just one of the many possibilities that exist. In reality this normalization is not a good one, because the corresponding Estrada index is very close to the number of nodes of the graph, as can be inferred from the bounds presented before. Then, other general choices of the type \(\left( \varrho A\right) ^{k}\) where \(\varrho <\left( \lambda _{1}\right) ^{-1}\) are more appropriate here.
A nice result relating the resolvent Estrada index and the characteristic polynomial of the adjacency matrix was proved by in [41] and is given below.
Theorem 35
Let G any graph with n nodes and let \(P\left( G,x\right) \) be the characteristic polynomial of the adjacency matrix of G, aka its characteristic polynomial. Then,
where \(P'\left( G,n\right) \) is the first derivative of \(P\left( G,x\right) \) evaluated at \(x=n\).
To illustrate the previous result let us consider the three graphs in Fig. 13. Their characteristic polynomials are, respectively:
which give \(EE_{0,1}\left( G_{I}\right) =4023/484,\) \(EE_{0,1}\left( G_{II}\right) =2980/359,\) and \(EE_{0,1}\left( G_{III}\right) =2191/264.\) That is, the difference between the first pair of graphs is only 0.13% and between the second pair is only 0.02%. This is a direct consequence of penalizing more heavily the longer walks than in the exponential matrix function.
Some other inequalities have been reported for the resolvent Estrada index in terms of the number of nodes, edges, maximum degree, etc.
Lemma 20
[41] Let G be a simple graph with n nodes and m edges. Then,
with equality if and only if \(G\cong {\bar{K}}_{n}.\)
Lemma 21
[114] Let G be a simple noncomplete graph with \(n>3\) nodes and m edges. Then,
with equality if and only if \(G\cong {\bar{K}}_{n}.\)
Lemma 22
[175] Let G be a simple graph with n nodes, m edges and maximum degree \(k_{max}\ne n-1\). Then,
11 Estrada indices and network of oscillators
The study of vibrations on regular graphs, known as lattices, is standard in solid-state physics (see for instance Chapter 4 in [144]). The techniques of classical as well as of quantum mechanics are used in the analysis of such vibrational problems. In 2003 this analysis was extended to consider non-regular networks [146] where the vibrations where analyzed in the context of a quantum system. Here we investigate the connections existing between some of the Estrada indices and the network vibrations, used in a metaphorical sense. That is, although some physical systems represented by non-regular graphs can be analyzed using the techniques developed here we consider the current approach as an appropriate tool for giving a physical meaning to the indices involved.
Let us consider a system \({\mathcal {S}}\) consisting of ball of mass M which are connected by springs with the spring constant \(M\omega ^{2}\). Let us consider that the ball-spring system is submerged into a thermal bath at the temperature \(\tau \). Then the balls in the complex network oscillate under thermal disturbances. We will consider that every ball is tied to the ground by a spring which has spring constant satisfying \(K\gg \max _{v}k_{v}\) (see Fig. 14). This guarantees that the system can oscillates but do not translate from a fixed position. In this way we can analyze how a given ball can transmit small oscillations to the rest of the balls of the system.

Illustration of a system formed by three balls of mass M tied to the ground with springs of constant K connected by springs of constant \(M\omega ^{2}\)
The general Hamiltonian of this system is written as
where the first term represents the kinetic energy of the corresponding balls and the second term represents the potential energy of the system, with \(p_{v}\) being the momentum and \(x_{v}\) the coordinate of the ball v.
11.1 Quantum oscillators
In this setup we consider that the system obeys the laws of quantum mechanics. Then, the momenta \(p_{w}\) and the coordinates \(x_{v}\) are not independent variables but they are operators that satisfy the commutation relation: \(\left[ x_{v},p_{w}\right] =i\hbar \delta _{vw},\)where \(i=\sqrt{-1}\), \(\hbar \) is the Dirac constant and \(\delta _{vw}\) is Dirac delta. Additionally we will use second quantization to express the creation and annihilation of oscillations at the given balls of the system. That is, we use the boson creation and annihilation operators defined by [184]
With the use of these operators, the Hamiltonian of a network of quantum harmonic oscillators is given by [84]
where \(\varOmega =\sqrt{K/M\omega }\) and K is a constant such that \(K\gg \max _{v}k_{v}\).
Since A is symmetric, we can diagonalize it by means of an orthogonal matrix O as in
where \(\varLambda \) is the diagonal matrix with the eigenvalues \(\lambda _{\mu }\) of \(\left( KI-A\right) \) on the diagonal. This generates a new set of boson creation and annihilation operators as
We can then decouple the Hamiltonian as
with
We now introduce an approximation in which each mode of oscillation does not get excited beyond the first excited state. In other words, we restrict ourselves to the space spanned by the ground state (the vacuum) \(\left| \mathrm{vac}\right\rangle \) and the first excited states \(b_{\mu }^{\dagger }\left| \mathrm{vac}\right\rangle \). Then the second term in the last line of the Hamiltonian (11.9) equals zero and we have
Remark 8
This approximation is justified when the energy level spacing \(\hbar \varOmega \) is much greater than the energy scale of external disturbances, (specifically the temperature fluctuation \(k_{B}T=1/\tau \)), as well as than the energy of the network springs \(\hbar \omega \), i.e. \(\tau \hbar \varOmega>>1\) and \(\varOmega>>\omega \). This happens when the mass of each oscillator is small, when the springs to the ground, \(M\varOmega ^{2}\), are strong, and when the network springs \(M\omega ^{2}\) are weak. Then an oscillation of tiny amplitude propagates over the network.
We are going to work in this limit hereafter. The thermal bath represents here an ’external situation’ which affects all the links in the network at the same time, e.g., economic crisis, social agitation, extreme physiological conditions, etc. After equilibration, all links in the network are weighted by the parameter \(\tau =\left( k_{B}T\right) ^{-1}\).
Let us now compute how much an excitation at the node p propagates throughout the network before coming back to the same node and being annihilated. This information is obtained through the diagonal thermal Green’s function, which is given in the framework of quantum mechanics by
where the partition function is given by
The diagonal thermal Green’s function can then be obtained as [84]
where we have used the spectral decomposition of A in the last line.
Let us consider \(\hbar =1\) and \(K=\dfrac{1}{2}M\omega ^{3}\). Then, [84]
Remark 9
In [84] it is remarked that
which indicates that the Estrada index represents the sum of the excitations started at every node of a graph, which propagate throughout the network before coming back to the same node and being annihilated in a network of quantum harmonic oscillators.
11.2 Classical oscillators
Here we consider a system S like the one described before but obeying the laws of classical mechanics. In this case we can write the Hamiltonian of the system by considering only the potential energy (for justification see [84]):
where \(x=\left( x_{1},x_{2},\ldots ,x_{n}\right) ^{T}\) and I is the \(n\times n\) identity matrix.
We can now diagonalize A as before and by taking a sufficiently large value of the constant K, we can make all eigenvalues \(\lambda _{\mu }\) positive. By defining a new set of variables \(y_{\mu }\) as \(y=Ox\) and \(x=O^{T}y\), we can transform the Hamiltonian in the form
Here again we focus of the quantification of those oscillations that start at a given ball of the system, navigates the whole system and return to the corresponding ball. Namely,
where the partition function is given by
where the integral is n-fold.
Now, because the Jacobian of the orthogonal matrix O is unity we have \(\prod _{i}dx_{i}=\prod _{\mu }dy_{\mu }.\) Therefore, the multi-fold integration in the partition function is decoupled to give
which can be written in matrix form as
Since we have made all the eigenvalues of \(\left( KI-A\right) \) positive, its determinant is positive. Similarly, we have
In the integrand, odd functions with respect to \(y_{\mu }\) vanish. Therefore, only the terms of \(y_{\sigma }^{2}\) survive after integration in the expansion of the square parentheses in the integrand. This gives
Comparing this expression with that of the partition function we have [84]
Remark 10
In [84] it is remarked that if \(K=n-1\) then we have
which indicates that the resolvent Estrada index represents the sum of the excitations started at every node of a graph, which propagate throughout the network before coming back to the same node in a network of classical harmonic oscillators.
12 Estrada indices and epidemics on networks
In continuation with the previous line of research in which the Estrada index is derived from a given dynamical systems context we analyze here its connection with epidemiological models on networks. The field of mathematical epidemiology has a long tradition in applied mathematics (see for instance [7, 34, 169]. In 2001, the authors of the seminal work [179] discovered the tremendous influence of network topology on epidemic spreadings. Since then, the use of network-theoretic approaches together with epidemiological models have become a necessary combination [143, 149]. Here we will show that such networked epidemiological models have a clear connection with the Estrada index of a graph.
For that we will briefly introduce the Susceptible/Infected (SI) model on networks. The reader should be aware that this is a generalist model that can be used in many different scenarios, not only on the analysis of diseases propagating on a network. Let G be a graphs whose nodes can be in either of two states: either susceptible or infected one. An infected node can transmit the infection to any other node in the graph to which it interacts with. Then, if \(\zeta \) is the rate at which such infection is transmitted between nodes, and if \(s_{v}\left( t\right) \) and \(x_{v}\left( t\right) \) are the probabilities that the node v is susceptible or get perturbed at time t, respectively, we can write the dynamics [170]:
where \(A_{vw}\) are the entries of the adjacency matrix of the graph for the pair of nodes v and w, and \({\mathcal {N}}\) is the set of nearest neighbors of v. In matrix-vector form becomes [170]:
with initial condition \(x\left( 0\right) =x_{0}.\)
The SI model can be rewritten as
which is equivalent to
where \(y_{v}\left( t\right) \,{:}{=}\,g\left( x_{v}\left( t\right) \right) =-\log \left( 1-x_{v}\left( t\right) \right) \in \left[ 0,\infty \right] \), \(f\left( y\right) \,{:}{=}\,1-e^{-y}=g^{-1}\left( y\right) \).
Lee et al. [155] have considered the following linearized version of the previous nonlinear equation
where \({\hat{x}}\left( t\right) =f\left( {\hat{y}}\left( t\right) \right) \) in which \({\hat{x}}\left( t\right) \) is the approximate solution to the SI model, \({\hat{y}}\left( t_{0}\right) =g\left( x\left( t_{0}\right) \right) \) and \(b\left( x\right) \,{:}{=}\,x+\left( 1-x\right) \log \left( 1-x\right) .\) They have found that the solution to this linearized model is [155]:
When \(t_{0}=0\), \(x_{i}\left( 0\right) =c/N\), \(i=1,2,\ldots ,N\) for some c, the previous equation is transformed to
where \(\gamma =1-c/N\) and \(\mathbf {1}\) is the all-ones vector. In [155] the authors proved that this solution is an upper bound to the exact solution of the SI model.
Therefore, if we take the sum of the entries of \({\hat{y}}\left( t\right) \) at a given t we have
where \(C_{1}=\left( 1/\gamma -1\right) \) and \(C_{2}=\left( 1/\gamma -1+\log \left( \gamma \right) \right) .\) Obviously the first term in the square bracket is the Estrada index of the graph in which edges are weighted by \(\gamma \zeta t\). This term represents the circulability of the infection around the nodes of the graph, while the term \(\text {tr}\left( \left( J-I\right) \left( e^{\gamma \zeta tA}\right) \right) \), where J is the all-ones matrix, accounts for the transmissibility of the disease between the nodes.
12.1 Fractional SI model on networks
In recent years there have been an explosion of works in which the classical derivatives used in the epidemiological models have been substituted by fractional ones [8, 11, 12, 133, 192]. There have been several reasons for adopting fractional epidemiological models. They include for instance
-
1.
the fact that the fractional parameter can be tuned to adjust the output of the model to real data [8] and so they can be more accurate that models using standard derivatives;
-
2.
the fact that a fractional differential operators may be derived from epidemiological models whenever the recovery time from the disease is power-law distributed [11];
-
3.
the fact that fractional derivatives capture the history of the variable, that is, they have memory, and the effect of recent memory is more important than the effect of older memory [12, 192].
In general, fractional derivatives are nowadays widely used to model biological processes [136] to incorporate different aspects of the dynamics in such systems. Here, we will describe a model which naturally gives rise to the Mittag–Leffler Estrada index in the context of epidemiological models.
We proceed by considering fractional time-derivatives in the modified SI model proposed in [155]. That is, in [1] the authors considered the following linearized fractional SI equation
where \({\hat{x}}\left( t\right) =f\left( {\hat{y}}\left( t\right) \right) \) in which \({\hat{x}}\left( t\right) \) is an approximate solution to the fractional SI model, \({\hat{y}}\) is the solution of (12.9) with initial condition \({\hat{y}}\left( 0\right) =g\left( x\left( 0\right) \right) \) and \(b\left( x\right) :=x+\left( 1-x\right) \log \left( 1-x\right) .\) Here \(D_{t}^{\alpha }f\left( t\right) \) is the fractional time derivative in the Caputo formulation [37], which was previously given in Eq. (10.3).
For convenience, we write \(\varOmega :=\text {diag}\left( 1-x_{0}\right) ,\) and \({\hat{A}}=A\varOmega .\) It was then proved that this solution is an upper bound to the exact fractional SI model.
Let us fix the following notation. Let x and y be two vectors of the same length n. Then, we say that \(x\preceq y\) is \(x_{i}\le y_{i}\) for all \(i=1,\ldots n\). Let \({\tilde{x}}(t)\) be the solution of the linearized fractional models of the form: \(D_{t}^{\alpha }{\tilde{x}}(t)=\zeta A{\tilde{x}}(t)\), which is exponential unstable.
Theorem 36
[1] For any \(t\ge 0\), we have
under the same initial conditions \(x_{0}:=x(0)={\hat{x}}(0)={\tilde{x}}(0),\) where the solution \({\hat{y}}\) of (12.9) is given by
Furthermore, \(\Vert {\hat{x}}(t)-x(t)\Vert \rightarrow 0\) and \(\Vert {\tilde{x}}(t)-x(t)\Vert \rightarrow \infty \) as t goes to infinity.
Corollary 5
[1] Let \(x_{0}\preceq 1\), \(x_{0}=\frac{c}{N}\) where \(c\in {\mathbb {R}}^{+},\) let \(\gamma =1-x_{0}.\) Then
where \(E_{\alpha ,1}\Bigl (.\Bigr )\) is the Mittag–Leffler matrix function of the corresponding matrix.
Therefore, here again if we take the sum of the entries of \({\hat{y}}\left( t\right) \) at a given t we have
Thus, again the Mittag–Leffler Estrada index, which is the first term in the squared bracket, represents the circulability of the infection around the nodes of the graph in the fractional SI model, while the second term represents the transmissibility of the disease between the nodes.
13 Estrada indices from piecewise walk penalization
In the same work [75] in which the author proposed the use of the matrix \(\varPsi \) functions as a way to increase the penalization of longer walks in graphs, a different strategy was proposed to drop such penalization relative to the exponential matrix function. This strategy can be formulated as a piecewise penalization as follows. Suppose that we do not want to penalize the walks of lengths smaller than certain value \(t\in {\mathbb {Z}}\). Then, we define the following stepwise function:
such that the piecewise Estrada index of the graph G is defined as:
In the case that the adjacency matrix has no unity eigenvalue we can write this Estrada index as [75]:
For computational purposes this expression can be adapted for any network as follows. Let r be a constant sufficiently close to one, such that \(r\ne 1/\lambda \) for all \(\lambda \), which are the eigenvalues of A. Then,
14 Nonlocal adjacency, Harary Estrada index and beyond
There are physical situations in which the entities of a system not only interact if they are nearest neighbors, but also through nonlocal interactions. These long-range interactions have been documented in physical, chemical and biological systems [3, 39, 148, 164, 177, 194, 195, 235, 240]. In a physical context, like the tight-binding kind of models described before, these nonlocal interactions corresponds to the case where the Hamiltonian of the system describes not only NN interactions but also next-nearest-neighbor (NNN) and other interactions beyond them [31, 168, 174, 193]:
In this framework we have that the system can be described by the weighted sum of higher-order adjacency matrices:
where \(A_{2}\) is a matrix with entries \(\left( A_{2}\right) _{ij}\) equal to one if i and j are not adjacent and are separated by two edges or zero otherwise. We can extend this concept to any other separation, such that [77]
where \(d_{ij}\) is the length of the shortest path between the two nodes. The parameters \(t_{NN}\), \(t_{NNN}\), etc. are expected to decay with the length of the separation between the corresponding entities. That is, the strength of the interaction decays with a given law of their separation d, i.e., \(f\left( d\right) \). In this way we can write [72, 218]
where diam is the diameter of the graph. Let us see how we can construct \({\hat{\mathcal {H}}}\).
Here we will use a min-plus algebra to define what otherwise is the shortest path distance matrix of the graph. We do that because it is a mathematically elegant approach, which may also open some possibilities for studying other kinds of functions for graphs.
Let \(\left( {\mathbb {R}}\cup \left\{ +\infty \right\} ,\oplus ,\otimes \right) \) be the min tropical semiring with the operations [32, 131, 139]:
The identity element for \(\oplus \) is \(+\infty \) and that for \(\otimes \) is 0. Then, we can define the tropical adjacency matrix power as
where \(A^{\otimes 0}={\hat{I}}\), which is the tropical identity matrix, i.e., a matrix with zeros in the main diagonal and \(\infty \) outside it.
Let us fix any \(\alpha \) with \(0<\alpha \le \infty \) and let us define the matrix \(M=\left[ m_{ij}\right] :m_{ij}\in \left( -\alpha ,\alpha \right) \) for all \(i,j=1,\ldots ,n\). Let \({\tilde{f}}\) be a real function on the open interval \(\left( -\alpha ,\alpha \right) .\) We define the pseudo-entrywise (pseudo-Hadamard) matrix function \({\tilde{f}}\left( M\right) \) as
Here, the function f could be an exponential, a trigonometric function or simply the power function. Let us hereafter focus only on the negative power function, such that \(\left( -s\right) \) represents the entrywise power. We can now write:
The tropical sum is carried out up to infinity as it converges in all cases where there are no negative cycles in the graph. A negative cycle is a cycle where the product of the weights of all its edges is negative. Typically, except for signed graphs, we consider positive edge weights, which always avoid such negative cycles. The infinite sum \(\bigoplus _{k=0}^{\infty }A^{\otimes k}\) is known as the Kleene star operator of A [32, 131, 139]. Obviously, \(\mathscr {{\mathcal {A}}}_{s}=\left[ {\mathcal {A}}_{ij}\left( s\right) \right] \), where [72, 218]
which are the entry-wise powers of all nondiagonal entries of the shortest path distance matrix of the graph. The parameter s accounts for the strength of the nonlocal interaction. Notice that
Here again, in the statistical physics context, the partition function of the system containing nonlocal interactions is:
where \(\tau \) is the inverse temperature as before. Because the parameters \(t_{NN},\) \(t_{NNN},\) etc., are negative we have that
Then, using the same definitions as the ones given before we can define the entropy, enthalpy and free energy of the system having local and nonlocal interactions.
It is important to notice that
which implies that
Let \({{\tilde{\mathcal {A}}}}_{s}\,{:}{=}\,\sum _{d=2}^{diam}d^{-s}A_{d}\). Then, because A and \({{\tilde{\mathcal {A}}}}_{s}\) do not commute in general, we have according to the Golden-Thompson inequality that
When \(s=1\), the corresponding matrix \(\mathscr {{\mathcal {A}}}_{s=1}\) is known in mathematical chemistry as the Harary matrix [137, 167, 181] in honor to mathematician Frank Harary (1921–2005).Footnote 8
Nowadays there are not many results about the HEE index. Hereafter we collect some of the existing ones for simple graphs [109], \(HEE\left( G\right) =EE\left( \mathscr {{\mathcal {A}}}_{s=1},\tau =1\right) .\)
Theorem 37
[109] Let G be a simple graph with n vertices and m edges. Then, the Harary Estrada index of G is bounded as
with equalities attained if and only if \(G\cong {\bar{K}}_{1}\).
Theorem 38
[138] Let G be a simple graph with \(n\ge 2\) vertices and let \(\kappa =\tfrac{1}{2}\text {tr} \left( \mathscr {{\mathcal {A}}}_{s=1}^{2}\right) \). Then, the Harary Estrada index is bounded as
14.1 Numerical analysis
In Fig. 15 we illustrate the histograms of the relative deviations of the lower bounds given in Theorem 37 and in Theorem 38 as well as of the upper bound given in Theorem 37. We consider all connected graphs with 8 nodes.
For both lower bounds, the values obtained with these bounds are about 20–40 times smaller than the actual values. The mean relative deviations are, respectively \(93.16\pm 2.19\) and \(96.591\pm 1.52\). The upper bound is as average \(10^{19}\) times bigger than the actual \(HEE\left( G\right) \) indices for these small graphs, which is an extremely poor performance of this bound.

In Table 10 we give the values of the bounds previously considered for the five real-world networks analyzed here as well as the actual values of \(HEE\left( G\right) \). As can be seen both lower and upper bounds are extremely far from the actual values of the Harary Estrada indices of these real-world networks. In particular, the upper bound is extremely higher than the actual values.
15 Laplacian Estrada index and backward diffusion
In the study of graph properties, the function \({\mathscr {K}}\left( G\right) =\left( e^{-tL}\right) \), where L is the graph Laplacian, has found many applications [22, 45, 150, 236]. The name “Laplacian” honors mathematician Pierre–Simon Laplace (1749–1827).Footnote 9 The function \({\mathscr {K}}\left( G\right) \) is known as the heat kernel of the graph [125, 191] and appears naturally in the solution \(u\left( t\right) =\exp \left( -t{\mathscr {D}}L\right) u_{0}\) of the diffusion equation on graphs:
where \({\mathscr {D}}\) is the diffusivity (see Sect. 16). Therefore, the trace of the heat kernel would correspond to a sort of diffusion Estrada index. However, in [92] the following index was proposed and named “the Laplacian Estrada index” of the graph
where \(\mu _{j}\) are the corresponding eigenvalues of L. Therefore, what the authors of [92] have proposed can be though as an index related to the solution of the backward diffusion equation, i.e., negative time, or as a diffusion equation with negative diffusivity \({\mathscr {D}}<0\) [65]. There are physical situations in which such negative diffusivity appears [48, 140, 173, 225, 226]. For instance, in the simultaneous diffusion of boron and point defect in silicon, the diffusivities of interstitial could be negative [225]. That is, the diffusion process of interstitial or vacancy could be a backward diffusion in silicon. In other scenarios, a backward diffusive model is used to detect the potential location of sources in spreading processes.
In [92] the authors proved the following result.
Proposition 2
Let G be a simple graph with n nodes and m edges. Let \(Z=\sum _{i}k_{i}^{2}\) be the first Zagreb index of G. Then,
with equality if and only if \(G\cong {\bar{K}}_{n}\).
Further, in [249] the authors proved the following results.
Proposition 3
Let G be a simple graph with n nodes and m edges. Let \(Z=\sum _{i}k_{i}^{2}\) be the first Zagreb index of G. Then,
with equality if and only if \(G\cong K_{2}\cup {\bar{K}}_{n-2}\) or \(G\cong {\bar{K}}_{n}\).
Proposition 4
Let G be a simple graph with n nodes and m edges. Then,
with equality if and only if \(G\cong {\bar{K}}_{n}\).
Other bounds were obtained in [248] on the basis of the degree sequence of a graph.
Proposition 5
Let G be a simple graph with n nodes and m edges. Let \(k_{max},k_{2},\ldots ,k_{min}\) be the nonincreasing ordering of the node degrees of G. Then,
with equality if and only if \(G\cong S_{n}\).
Proposition 6
Let G be a simple graph with n nodes and m edges. Let \(k_{max},k_{2},\ldots ,k_{min}\) be the nonincreasing ordering of the node degrees of G. Then,
with equality if and only if G is a vertex disjoint union of complete subgraphs.
Several bounds have been proposed on the basis of the maximum and minimum degrees of a graph. We resume some of them here.
Theorem 39
[160] Let G be a simple graph with n nodes and m edges. Let \(k_{max}\) and \(k_{min}\) be the maximum and minimum node degrees of G. Then,
with equality if and only if \(G\cong K_{n}\) or \(G\cong S_{n}\).
Theorem 40
[40] Let G be a simple graph with n nodes and m edges. Let \(k_{max}\) and \(k_{min}\) be the maximum and minimum node degrees of G. Then,
with equality if and only if \(G\cong 2K_{1}\vee K_{n-2}\) or \(G\cong K_{1,n-1}\) or \(G\cong K_{\left( n-1\right) /2}\cup K_{\left( n-1\right) /2}\) (n is odd).
Theorem 41
[161] Let G be a simple graph with n nodes and m edges. Let \(k_{max}\) and \(k_{min}\) be the maximum and minimum node degrees of G. Then,
with equality if and only if \(G\cong {\bar{K}}_{n}\).
The following is an upper bound found in [163].
Theorem 42
Let G be a simple graph with n nodes and m edges. Then,
with equality if and only if \(G\cong K_{n}\) or \(G\cong K_{n}-e\).
Finally, we present the estimation made in [100] for the Laplacian Estrada index of Erdős–Rényi random graphs.
Theorem 43
Let \(G_{n,p}\) be an Erdős–Rényi random graph with n nodes and probability p. Then, the Laplacian Estrada index is given by
In [132] the authors find estimations for the Laplacian Estrada index of random multipartite graphs.
Remark 11
Other bounds and estimations have been reported for the Laplacian Estrada index of specific graphs, or based on other graph parameters not considered here. Some non-exhaustive examples are: [20, 58, 60, 61, 117, 135, 145, 162, 207, 242, 243, 251].
Remark 12
The normalized Laplacian Estrada index defined as
where K is the diagonal matrix of node degree has been studied in [47, 123, 158, 203, 207].
Remark 13
The signless Laplacian Estrada index defined as
has been also studied in [16, 117, 227].
15.1 Numerical analysis
In Fig. 16 we illustrate the histograms of the relative deviations (in %) of the lower bounds (Proposition 2), (Proposition 4) (Proposition 5), (Proposition 6), (Theorem 40) and (Theorem 41) for all connected graphs with 8 nodes. The best performance is obtained from the bound (Proposition 6) followed by (Proposition 5).

We also analyzed the upper bounds given in Proposition 2, Proposition 3, Theorem 41 and Theorem 42 for the same set of graphs. In these cases the best performances were obtained for Theorem 41 and Theorem 42, while 2 give very high upper bounds (Fig. 17).

In Table 11 we give the lower bounds for the Laplacian Estrada index of five real-world networks. In general, the bounds (Proposition 5), (Proposition 6) and (Theorem 40) perform very well, while (Proposition 2), (Proposition 4) and (Proposition 41) are several orders of magnitude below the actual values of the Laplacian Estrada indices of these networks.
The case of the upper bound is much more contrasting with values several orders of magnitude over the actual values of the Laplacian Estrada indices of these five networks. We have used variable-precision floating-point arithmetic” (VPA) to evaluate each element of the symbolic input in Matlab for these calculations. It is used to evaluate symbolic inputs with variable-precision floating-point arithmetic, calculating values to 32 significant digits.
The results are given in Table 12.
The following bounds based on the largest Laplacian eigenvalue \(\mu _{1}\) perform very well for the four real-world networks analyzed as can be seen in Table 13. The reason is that the largest eigenvalue of the Laplacian matrix dominates the spectrum of this matrix, i.e., it is very large and separated from the second largest eigenvalue.
16 Radius of gyration and distance Estrada index
When presenting the diffusion equation on graphs, Eq. (15.1), we mentioned in passing the diffusion coefficient \({\mathscr {D}}\), which appears in the equation and in its solution. The diffusion coefficient is related to the radius r of the spherical particle diffusing on a medium of viscosity \(\eta \) by the Stokes-Einstein equation [66]:
where \(\tau \) is the inverse temperature. In the case of small molecules like drugs, or macromolecular systems like proteins, the particles cannot longer be considered spherical. In these cases it is customary to replace the radius of the spherical particle by the radius of gyration of the corresponding molecule [94, 107, 126, 152, 171]. The radius of gyration is defined as follows. Let \({\mathcal {S}}=\left( p_{1},\ldots ,p_{n}\right) \) be a system formed by n particles or points \(p_{i}\), which are located in a given region of the three-dimensional Euclidean space. Let \(r_{ij}\) be the Euclidean distance between the particles \(p_{i}\) and \(p_{j}\). Then, the radius of gyration of \({\mathcal {S}}\) is defined as \(R_{{\mathcal {S}}}^{2}=\dfrac{1}{2n^{2}}\sum _{i,j}r_{ij}^{2}\) [94]. However, it has been shown that even when the radius of gyration based on Euclidean distances is used, there are cases of undesired degeneration of the index for pairs of clusters [74]. That is, there are pairs of nonisomorphic clusters which have the same radius of gyration. Some examples in 2- and in 3-dimensions are given in Fig. 18.

Examples of Euclidean objects in 2- (a, b) and 3-dimensions (c, d), which have the same radius of gyration: (a, b) \(R_{{\mathcal {S}}}^{2}=\tfrac{1}{4}\), (c, d) \(R_{{\mathcal {S}}}^{2}=\tfrac{3}{16}\). Every edge has length equal to one in each of the objects
The radius of gyration is widely used in organic chemistry, polymer sciences, proteins, and RNA, in general, for the study of their compactness. Most of these molecular systems can be represented as graphs. For instance, molecules are typically represented by molecular graphs [217], proteins can be represented by “protein residue networks” [76, 212], and the secondary structure of RNA is also represented by graphs [147]. Then, it is important to extend the concept of “radius of gyration” to graphs.
Definition 22
Let G be a simple graph. Let \(d_{ij}\) be the shortest path distance between the nodes i and j. The graph radius of gyration is defined as
Let D be the shortest path distance matrix of G. Then, it is straightforward to realize that
Then, if \(\sigma _{1}\ge \sigma _{2}\ge \cdots \ge \sigma _{n}\) are the eigenvalues of D, the graph radius of gyration is the second spectral moment of D, i.e.,
Therefore, we can say that the second moment of the shortest path distance matrix is a measure of the packing of the graph. In the case of the graph we can have a similar degeneracy of the index \(R_{G}^{2}\) for nonisomorphic graphs. For instance in Fig. 19 we give an example of four nonisomorphic graphs with the same value of \(R_{G}^{2}=\frac{9}{50}.\)

Example of four nonisomorphic graphs with the same value of \(R_{G}^{2}\)
In order to ameliorate this degeneracy problem we can think on extending the packing measure to higher moments of D as
Let us include the term \(c_{0}\text {tr}\left( D^{0}\right) +c_{1}\text {tr}\left( D^{1}\right) \) (the first is the weighted number of vertices and the second is zero in simple graphs) and let us consider \(c_{k}=\left( k!\right) ^{-1}\). Then, we get the following index, first defined in [108].
Definition 23
Let G be a simple graph. Let D be the shortest path distance matrix of G with eigenvalues \(\sigma _{1}\ge \sigma _{2}\ge \cdots \ge \sigma _{n}\). Then the distance Estrada index of the graph is
which is an index of the packing of the graph.
For instance, for the graphs in Fig. 19 we obtain the following values: \(DEE\left( a\right) \approx 318.467\), \(DEE\left( b\right) \approx 300.616,\) \(DEE\left( c\right) \approx 284.917\), and \(DEE\left( d\right) \approx 281.697\). This means that among the graphs in Fig. 19, (d) is the most “packed” one in terms of its shortest path distance and the one in (a) is the least packed.
Several bound have been obtained for the distance Estrada index, some of which are resumed below.
Theorem 44
[108] Let G be a simple graph with n nodes and m edges. Then, if the diameter is \(d_{max}\), the distance Estrada index is bounded as
where equalities are attained if and only if \(G\cong K_{1}\).
Theorem 45
[202] Let G be a simple graph with n nodes and m edges. Then, if \(d_{max}\), \(\mathscr {{\mathcal {G}}}=\left( \prod _{i}D_{i}\right) ^{1/n}\) and \(W=\sum _{ij}d_{ij}\) stand for the diameter, the geometric mean of the graph distances and the Wiener index of G, the distance Estrada index is bounded as
where upper bound is attained if and only if \(G\cong K_{1}\) and the lower one if and only if \(G\cong K_{n}.\)
Theorem 46
[204] Let G be a simple graph with n nodes with maximum and second maximum degress \(k_{max}\) and \(k_{max_{2}}\) and diameter \(d_{max}\). Then, the distance Estrada index is bounded as
where equality is attained if and only if \(G\cong K_{2}\).
Theorem 47
[204] Let G be a simple graph with n nodes and m edges, the distance Estrada index is bounded as
where equality is attained if and only if \(G\cong K_{2}\).
16.1 Random graphs
The distance Estrada index has been studied for random graphs where some bounds have been reported in [205, 209].
Theorem 48
Let \(G_{n,p}\) be an Erdős–Rényi random graph with n nodes and probability p. Then, the distance Estrada index is bounded as
almost surely (a.s).
Theorem 49
Let \(G_{n_{1},n_{2},p}\) be an Erdős–Rényi random bipartite graph with \(n=n_{1}+n_{2}\) nodes and probability p. If \(n_{1}=\varTheta \left( n_{2}\right) ,\) then the distance Estrada index is bounded as
asymptotically almost surely (a.a.s.) which, when \(n_{1}=n_{2}\) becomes
16.2 Numerical analysis
We analyze here the lower bounds in Theorems 44, 45, 46 and 47. The relative deviations (in %) are illustrated in Fig. 20. As can be seen the closest values are obtained by the bound given in Theorem 45. The distributions of the relative deviations for Theorems 46 and 47 appears to show some dependencies with the structure of the graphs, which produce the multi-peak structures observed in the histograms.

We also considered the upper bounds given in Theorems 44, 45 and 46 were we observe that these bounds are several order of magnitude over the actual values of \(DEE\left( G\right) \) even for small graphs like the ones studied here (Fig. 21).

In Table 14 we give the values of the lower and upper bounds as well as the actual values calculated with very precise arithmetic (vpa) in Matlab for the five real-world networks studied. As can be seen in the Table 14 the bound given in Theorem 45 gives the best lower and upper estimates of the distance Estrada index. It is also interesting to remark that the network of the western USA power grid displays an extremely large value of \(DEE\left( G\right) \), indicating that it is a very poorly packed network. Indeed, this network is planar as the power stations are embedded in the landscape of the western USA
The results obtained for Erdős–Rényi random graphs \(G_{n,p}\) with \(1000\le n\le 4000\) and \(p=0.5\) are illustrated in Table 15, showing good agreement between the actual values and those predicted by Theorem 48. The values were computed in [209] using variable-precision floating-point arithmetic (VPA) in Matlab.
17 Conclusions
We presented an account of the many different facets of the Estrada indices of graphs. Starting from the “classical” Estrada index we give several interpretations of the index based on (i) combinatorics of subgraphs, (ii) statistical mechanics, (iii) marginal probability in a quantum system, (iv) oscillations models on networks, and (v) epidemiological models on networks. Then we move forward to the analysis of other kinds of Estrada indices. First we contextualize these indices originally introduced in an ad hoc way in the mathematical literature. For instance, the Seidel Estrada index is placed in the context of signed graphs, the theory of balance and the concept of network bipartivity. The resolvent Estrada index is analyzed as a case of Mittag–Leffler Estrada indices which appear in the context of fractional epidemiological models on graphs. The Harary Estrada index is understood as a particular case of nonlocal operator on graphs. The Laplacian Estrada index is now pondered on the basis of the diffusion equation with negative diffusivity or a backward diffusive process. Finally, the distance Estrada index is considered in the context of the radius of gyration of a graph, which can be connected to the diffusion coefficient of graphs via the Stokes-Einstein equation. In all cases we have provided numerical analysis of several of the bounds and estimations made for these indices. Such results have revealed the necessity of investigating more robust bounds, particularly upper bounds, for most of the indices studied. In many cases the bounds, although correct, are very far away from the actual values of the indices, which leaves large rooms for improvements. We encourage authors searching for new bounds to compare them with the existing ones with the challenge of improving them for general classes of graphs.
Finally, we have not considered many of the results obtained in the literature for specific classes of graphs, which would make this paper too long to be digested. We advice the reader that such bounds exist for several of the indices described in this paper and for several classes of graphs of importance in specific areas of applications.
Notes
\(\tau \) is typically represented by \(\beta \) in statistical physics, but this letter is already reserved here for a different variable.
Physicists call these edges “frustrating” edges.
In the study of social signed networks, positive edges are used for friendship relations and negative ones for enmities.
A biography of Johan Jacob Seidel can be found at: https://mathshistory.st-andrews.ac.uk/Biographies/Seidel_Jaap/.
A biography of Lars Onsager can be found at: https://www.nobelprize.org/prizes/chemistry/1968/onsager/biographical/.
A biography of Carl Friedrich Gauss can be found at: https://mathshistory.st-andrews.ac.uk/Biographies/Gauss/.
A biography of Gösta Mittag-Leffler can be found at: https://mathshistory.st-andrews.ac.uk/Biographies/Mittag-Leffler/.
A biography of Frank Harary can be found at: https://mathshistory.st-andrews.ac.uk/Biographies/Harary/.
A biography of Pierre–Simon Laplace can be found at: https://mathshistory.st-andrews.ac.uk/Biographies/Laplace/.
References
Abadias, L., Estrada-Rodriguez, G., Estrada, E.: Fractional-order susceptible-infected model: definition and applications to the study of covid-19 main protease. Fract. Calc. Appl. Anal. 23(3), 635–655 (2020)
Acharya, B.D.: Spectral criterion for cycle balance in networks. J. Graph Theory 4(1), 1–11 (1980)
Ala-Nissila, T., Ferrando, R., Ying, S.: Collective and single particle diffusion on surfaces. Adv. Phys. 51(3), 949–1078 (2002)
Aleksić, T., Gutman, I., Petrović, M.: Estrada index of iterated line graphs. Bulletin (Académie serbe des sciences et des arts. Classe des sciences mathématiques et naturelles. Sciences mathématiques), pp. 33–41 (2007)
Alhomaidhi, A., Al-Thukair, F., Estrada, E.: Gaussianization of the spectra of graphs and networks. theory and applications. J. Math. Anal. Appl. 470(2), 876–897 (2019)
Alhomaidhi, A., Al-Thukair, F., Estrada, E.: Double gaussianization of graph spectra. Appl. Math. Model. 93, 134–147 (2021)
Allen, L.J., Brauer, F., Van den Driessche, P., Wu, J.: Mathematical Epidemiology, vol. 1945. Springer, New York (2008)
Almeida, R., da Cruz, A.M.B., Martins, N., Monteiro, M.T.T.: An epidemiological MSEIR model described by the caputo fractional derivative. Int. J. Dyn. Control 7(2), 776–784 (2019)
Alon, N., Yuster, R., Zwick, U.: Finding and counting given length cycles. Algorithmica 17(3), 209–223 (1997)
Andrade, E., Lenes, E., Mallea-Zepeda, E., Robbiano, M., Rodríguez, J.: Extremal graphs for Estrada indices. Linear Algebra Appl. 588, 54–73 (2020)
Angstmann, C., Henry, B., McGann, A.: A fractional order recovery sir model from a stochastic process. Bull. Math. Biol. 78(3), 468–499 (2016)
Arenas, A.J., Gonzalez-Parra, G., Chen-Charpentier, B.M.: Construction of nonstandard finite difference schemes for the SI and SIR epidemic models of fractional order. Math. Comput. Simul. 121, 48–63 (2016)
Arrigo, F., Durastante, F.: Mittag–Leffler functions and their applications in network science. arXiv preprint arXiv:2103.12559 (2021)
Ashrafi, A., Fath-Tabar, G.H.: Bounds on the Estrada index of ISR (4, 6)-fullerenes. Appl. Math. Lett. 24(3), 337–339 (2011)
Asratian, A.S., Denley, T.M., Häggkvist, R.: Bipartite Graphs and their Applications, vol. 131. Cambridge University Press, Cambridge (1998)
Ayyaswamy, S.K., Balachandran, S., Venkatakrishnan, Y.B., Gutman, I.: Signless Laplacian Estrada index. MATCH Commun. Math. Comput. Chem. 66(3), 785–794 (2011)
Baird, D., Ulanowicz, R.E.: The seasonal dynamics of the Chesapeake bay ecosystem. Ecol. Monogr. 59(4), 329–364 (1989)
Ballini, F., Deniskin, N.: Vertex distinction with subgraph centrality: a proof of Estrada’s conjecture and some generalizations. Linear Algebra Appl. 612, 334–344 (2021)
Bamdad, H.: New lower bounds for Estrada index. Bull. Malays. Math. Sci. Soc. 39(2), 683–688 (2016)
Bamdad, H., Ashraf, F., Gutman, I.: Lower bounds for Estrada index and Laplacian Estrada index. Appl. Math. Lett. 23(7), 739–742 (2010)
Barabási, A.-L., Albert, R.: Emergence of scaling in random networks. Science 286(5439), 509–512 (1999)
Barlow, M.T.: Random Walks and Heat Kernels on Graphs, vol. 438. Cambridge University Press, Cambridge (2017)
Beaudin, L., Ellis-Monaghan, J., Pangborn, G., Shrock, R.: A little statistical mechanics for the graph theorist. Discrete Math. 310(13–14), 2037–2053 (2010)
Beineke, L.W., Wilson, R.J., Cameron, P.J., et al.: Topics in Algebraic Graph Theory, vol. 102. Cambridge University Press, Cambridge (2004)
Belyayev, Y.N.: On the calculation of functions of matrices. Math. Notes 94(1), 177–184 (2013)
Benzi, M.: A note on walk entropies in graphs. Linear Algebra Appl. 445, 395–399 (2014)
Benzi, M., Boito, P.: Quadrature rule-based bounds for functions of adjacency matrices. Linear Algebra Appl. 433(3), 637–652 (2010)
Benzi, M., Boito, P.: Matrix functions in network analysis. GAMM-Mitteilungen 43(3), e202000012 (2020)
Berge, C.: The Theory of Graphs (trans. alison doig). Methuen & Co., London (1962)
Biggs, N., Biggs, N.L., Norman, B.: Algebraic Graph Theory, vol. 67. Cambridge University Press, Cambridge (1993)
Binder, K., Landau, D.: Phase diagrams and critical behavior in Ising square lattices with nearest-and next-nearest-neighbor interactions. Phys. Rev. B 21(5), 1941 (1980)
Bouillard, A., Boyer, M., Le Corronc, E.: Deterministic Network Calculus: From Theory to Practical Implementation. Wiley (2018)
Bozkurt, ŞB., Adiga, C., Bozkurt, D.: On the energy and Estrada index of strongly quotient graphs. Indian J. Pure Appl. Math. 43(1), 25–36 (2012)
Brauer, F.: Mathematical epidemiology: past, present, and future. Infect. Dis. Model. 2(2), 113–127 (2017)
Braun, S., Ronzheimer, J.P., Schreiber, M., Hodgman, S.S., Rom, T., Bloch, I., Schneider, U.: Negative absolute temperature for motional degrees of freedom. Science 339(6115), 52–55 (2013)
Canning, A., Wang, L., Williamson, A., Zunger, A.: Parallel empirical pseudopotential electronic structure calculations for million atom systems. J. Comput. Phys. 160(1), 29–41 (2000)
Caputo, M.: Linear models of dissipation whose q is almost frequency independent-II. Geophys. J. Int. 13(5), 529–539 (1967)
Carmona, J.R., Rodríguez, J.: An increasing sequence of lower bounds for the Estrada index of graphs and matrices. Linear Algebra Appl. 580, 200–211 (2019)
Chen, L., Painter, K., Surulescu, C., Zhigun, A.: Mathematical models for cell migration: a non-local perspective. Philos. Trans. R. Soc. B 375(1807), 20190379 (2020)
Chen, X., Hou, Y.: Some results on Laplacian Estrada index of graphs. MATCH Commun. Math. Comput. Chem. 73, 149–162 (2015)
Chen, X., Qian, J.: On resolvent Estrada index. MATCH Commun. Math. Comput. Chem 73, 163–174 (2015)
Chen, Y., Du, J., Xiong, M., Guo, H., Jinnai, H., Kaneko, T.: Perforated block copolymer vesicles with a highly folded membrane. Macromolecules 40(13), 4389–4392 (2007)
Chen, Z., Fan, Y.-Z., Du, W.-X.: Estrada index of random graphs. MATCH Commun. Math. Comput. Chem. 68, 825–834 (2012)
Chu, R., Pei, W., Takei, J., Bai, Y.: Relationship between the native-state hydrogen exchange and folding pathways of a four-helix bundle protein. Biochemistry 41(25), 7998–8003 (2002)
Chung, F.: The heat kernel as the pagerank of a graph. Proc. Natl. Acad. Sci. 104(50), 19735–19740 (2007)
Chung, F.R., Graham, F.C.: Spectral Graph Theory, vol. 92. American Mathematical Society, Providence (1997)
Clemente, G.P., Cornaro, A.: Novel bounds for the normalized Laplacian Estrada index and normalized Laplacian energy. MATCH Commun. Math. Comput. Chem. 77(3), 673–690 (2017)
Corli, A., Malaguti, L.: Wavefronts in traffic flows and crowds dynamics. In: Anomalies in Partial Differential Equations, pp. 167–189. Springer (2021)
Cox, L.A., Jr., Popken, D.A., Sun, R.X., et al.: Causal Analytics for Applied Risk Analysis. Springer, New York (2018)
Cvetkovic, D., Cvetković, D.M., Rowlinson, P., Simic, S.: Eigenspaces of Graphs, vol. 66. Cambridge University Press, Cambridge (1997)
Cvetkovic, D.M.: Applications of graph spectra: an introduction to the literature. Appl. Graph Spectra 13(21), 7–31 (2009)
Cvetkovic, D.M., Dragos, M. et al. Spectra of Graphs. Theory and Application (1980)
Das, K.C., Lee, S.-G.: On the Estrada index conjecture. Linear Algebra Appl. 431(8), 1351–1359 (2009)
de la Peña, J.A., Gutman, I., Rada, J.: Estimating the Estrada index. Linear Algebra Appl. 427(1), 70–76 (2007)
Deng, H.: A note on the Estrada index of trees. Match 62(3), 607 (2009)
Deng, H.: A proof of a conjecture on the Estrada index. Match 62(3), 599 (2009)
Deng, H., Radenkovic, S., Gutman, I.: The Estrada index. Applications of Graph Spectra, Math. Inst., Belgrade, pp. 123–140 (2009)
Deng, H., Zhang, J.: A note on the Laplacian Estrada index of trees. MATCH Commun. Math. Comput. Chem. 63(3) (2010)
Dias, J.R.: Molecular Orbital Calculations Using Chemical Graph Theory, vol. 19. Springer, New York (1993)
Du, Z.: More on Laplacian Estrada indices of trees. Filomat 26(1), 197–206 (2012)
Du, Z., Liu, Z.: On the Estrada and Laplacian Estrada indices of graphs. Linear Algebra Appl. 435(8), 2065–2076 (2011)
Du, Z., Zhou, B.: The Estrada index of trees. Linear Algebra Appl. 435(10), 2462–2467 (2011)
Du, Z., Zhou, B.: On the Estrada index of graphs with given number of cut edges. Electron. J. Linear Algebra 22 (2011)
Du, Z., Zhou, B.: The Estrada index of unicyclic graphs. Linear Algebra Appl. 436(9), 3149–3159 (2012)
Dung, V.B., Van Thien, D.: The equation of backward diffusion and negative diffusivity. J. Phys. Conf. Ser. 537, 012011 (2014)
Edward, J.T.: Molecular volumes and the Stokes–Einstein equation. J. Chem. Educ. 47(4), 261 (1970)
Enns, A., Becker, T.W., Schmeling, H.: The dynamics of subduction and trench migration for viscosity stratification. Geophys. J. Int. 160(2), 761–775 (2005)
Erdos, P., Rényi, A.: On the evolution of random graphs. Publ. Math. Inst. Hung. Acad. Sci 5(1), 17–60 (1960)
Essam, J.W.: Graph theory and statistical physics. Discrete Math. 1(1), 83–112 (1971)
Estrada, E.: Characterization of 3d molecular structure. Chem. Phys. Lett. 319(5–6), 713–718 (2000)
Estrada, E.: Characterization of the folding degree of proteins. Bioinformatics 18(5), 697–704 (2002)
Estrada, E.: Generalized graph matrix, graph geometry, quantum chemistry, and optimal description of physicochemical properties. J. Phys. Chem. A 107(38), 7482–7489 (2003)
Estrada, E. Characterization of the amino acid contribution to the folding degree of proteins. Proteins Struct. Funct. Bioinform. 54(4), 727–737 (2004)
Estrada, E.: Point scattering: a new geometric invariant with applications from (nano) clusters to biomolecules. J. Comput. Chem. 28(4), 767–777 (2007)
Estrada, E.: Generalized walks-based centrality measures for complex biological networks. J. Theor. Biol. 263(4), 556–565 (2010)
Estrada, E.: Universality in protein residue networks. Biophys. J. 98(5), 890–900 (2010)
Estrada, E.: Path Laplacian matrices: introduction and application to the analysis of consensus in networks. Linear Algebra Appl. 436(9), 3373–3391 (2012)
Estrada, E.: The Structure of Complex Networks: Theory and Applications. Oxford University Press, Oxford (2012)
Estrada, E.: Rethinking structural balance in signed social networks. Discrete Appl. Math. 268, 70–90 (2019)
Estrada, E., Alhomaidhi, A.A., Al-Thukair, F.: Exploring the “middle earth” of network spectra via a gaussian matrix function. Chaos 27(2), 023109 (2017)
Estrada, E., Benzi, M.: Walk-based measure of balance in signed networks: detecting lack of balance in social networks. Phys. Rev. E 90(4), 042802 (2014)
Estrada, E., Gómez-Gardeñes, J.: Network bipartivity and the transportation efficiency of European passenger airlines. Phys. D Nonlinear Phenom. 323, 57–63 (2016)
Estrada, E., Hatano, N.: Statistical-mechanical approach to subgraph centrality in complex networks. Chem. Phys. Lett. 439(1–3), 247–251 (2007)
Estrada, E., Hatano, N., Benzi, M.: The physics of communicability in complex networks. Phys. Rep. 514(3), 89–119 (2012)
Estrada, E., Higham, D.J.: Network properties revealed through matrix functions. SIAM Rev. 52(4), 696–714 (2010)
Estrada, E., José, A., Hatano, N.: Walk entropies in graphs. Linear Algebra Appl. 443, 235–244 (2014)
Estrada, E., Rodríguez-Velázquez, J.A.: Spectral measures of bipartivity in complex networks. Phys. Rev. E 72(4), 046105 (2005)
Estrada, E., Rodriguez-Velazquez, J.A.: Subgraph centrality in complex networks. Phys. Rev. E 71(5), 056103 (2005)
Estrada, E., Silver, G.: Accounting for the role of long walks on networks via a new matrix function. J. Math. Anal. Appl. 449(2), 1581–1600 (2017)
Faloutsos, M., Faloutsos, P., Faloutsos, C.: On power-law relationships of the internet topology. In: The Structure and Dynamics of Networks, pp. 195–206. Princeton University Press (2011)
Fath-Tabar, G., Ashrafi, A.: New upper bounds for Estrada index of bipartite graphs. Linear Algebra Appl. 435(10), 2607–2611 (2011)
Fath-Tabar, G., Ashrafi, A., Gutman, I.: Note on Estrada and l-Estrada indices of graphs. Bulletin (Académie serbe des sciences et des arts. Classe des sciences mathématiques et naturelles. Sciences mathématiques), pp. 1–16 (2009)
Festinger, L.: The analysis of sociograms using matrix algebra. Hum. Relat. 2(2), 153–158 (1949)
Fixman, M.: Radius of gyration of polymer chains. J. Chem. Phys. 36(2), 306–310 (1962)
Fowler, P.: Hückel spectra of möbius \(\pi \) systems. Phys. Chem. Chem. Phys. 4(13), 2878–2883 (2002)
Fowler, P.W.: Möbius systems and the Estrada index. MATCH Commun. Math. Comput. Chem. 66, 751–764 (2011)
Frommer, A., Simoncini, V.: Matrix functions. In: Model Order Reduction: Theory, Research Aspects and Applications, pp. 275–303. Springer, New York (2008)
Fukui, K.: The role of frontier orbitals in chemical reactions (nobel lecture). Angew. Chem. Int. Ed. Engl. 21(11), 801–809 (1982)
Fukui, K., Yonezawa, T., Shingu, H.: A molecular orbital theory of reactivity in aromatic hydrocarbons. J. Chem. Phys. 20(4), 722–725 (1952)
Gao, N., Hu, D., Liu, X., Zhang, S.: Laplacian spectral moment and Laplacian Estrada index of random graphs. J. Math. Anal. Appl. 461(2), 1299–1307 (2018)
Gao, N., Qiao, L., Ning, B., Zhang, S.: Coulson-type integral formulas for the Estrada index of graphs and the skew Estrada index of oriented graphs. MATCH Commun. Math. Comput. Chem. 73, 133–148 (2015)
Garrappa, R., Popolizio, M.: Computing the matrix Mittag–Leffler function with applications to fractional calculus. J. Sci. Comput. 77(1), 129–153 (2018)
Ghorbani, M.: On the energy and Estrada index of Cayley graphs. Discrete Math. Algorithms Appl. 7(01), 1550005 (2015)
Ginosar, Y., Gutman, I., Mansour, T., Schork, M.: Estrada index and Chebyshev polynomials. Chem. Phys. Lett. 454(4–6), 145–147 (2008)
Godsil, C., Royle, G.F.: Algebraic Graph Theory, vol. 207. Springer Science & Business Media (2001)
Godsil, C.D., McKay, B.D.: Feasibility conditions for the existence of walk-regular graphs. Linear Algebra Appl. 30, 51–61 (1980)
Gordon, P.A.: Characterizing isoparaffin transport properties with Stokes–Einstein relationships. Ind. Eng. Chem. Res. 42(26), 7025–7036 (2003)
Güngör, A., Bozkurt, S.: On the distance Estrada index of graphs. Hacettepe J. Math. Stat. 38(3), 277–283 (2009)
Güngör, A.D., Cevik, A.S.: On the Harary energy and Harary Estrada index of a graph. MATCH Commun. Math. Comput. Chem. 64(1), 281–296 (2010)
Gutman, I.: Lower bounds for Estrada index. Publ. Inst. Math. 83(97), 1–7 (2008)
Gutman, I., Borovicanin, B.: Nullity of graphs: an updated survey. Zbornik Radova 14(22), 137–154 (2011)
Gutman, I., Deng, H., Radenkovic, S.: The Estrada index: an updated survey. Selected Topics on Applications of Graph Spectra, Math. Inst., Beograd, pp. 155–174 (2011)
Gutman, I., Estrada, E., Rodríguez-Velázquez, J.A.: On a graph-spectrum-based structure descriptor. Croat. Chem. Acta 80(2), 151–154 (2007)
Gutman, I., Furtula, B., Chen, X., Qian, J.: Resolvent Estrada index-computational and mathematical studies. MATCH Commun. Math. Comput. Chem. 74, 431–440 (2015)
Gutman, I., Furtula, B., Marković, V., Glišić, B.: Alkanes with greatest Estrada index. Zeitschrift für Naturforschung A 62(9), 495–498 (2007)
Gutman, I., Graovac, A.: Estrada index of cycles and paths. Chem. Phys. Lett. 436(1–3), 294–296 (2007)
Gutman, I., Medina, L., Pizarro, P., Robbiano, M.: Graphs with maximum laplacian and signless laplacian Estrada index. Discrete Math. 339(11), 2664–2671 (2016)
Gutman, I., Radenković, S.: Estrada index of benzenoid hydrocarbons. Zeitschrift für Naturforschung A 62(5–6), 254–258 (2007)
Gutman, I., Radenkovic, S.: A lower bound for the Estrada index of bipartite molecular graphs. Kragujevac J. Sci. 29, 67–72 (2007)
Gutman, I., Radenkovic, S.: A lower bound for the Estrada index of bipartite molecular graphs. Kragujevac J. Sci. 29, 67–72 (2007)
Gutman, I., Radenković, S., Furtula, B., Mansour, T., Schork, M.: Relating Estrada index with spectral radius. J. Serb. Chem. Soc. 72(12), 1321–1327 (2007)
Hakimi-Nezhaad, M., Ghorbani, M.: On the Estrada index of Seidel matrix. Math. Interdiscip. Res. 5(1), 43–54 (2020)
Hakimi-Nezhaad, M., Hua, H., Ashrafi, A.R., Qian, S.: The normalized Laplacian Estrada index of graphs. J. Appl. Math. Inform. 32(1–2), 227–245 (2014)
Hall, G.: On the eigenvalues of molecular graphs. Mol. Phys. 33(2), 551–557 (1977)
Hambly, B.M., Kumagai, T.: Diffusion processes on fractal fields: heat kernel estimates and large deviations. Probab. Theory Relat. Fields 127(3), 305–352 (2003)
He, L., Niemeyer, B.: A novel correlation for protein diffusion coefficients based on molecular weight and radius of gyration. Biotechnol. Prog. 19(2), 544–548 (2003)
Higham, N.J.: Functions of Matrices: Theory and Computation. SIAM, Philadelphia (2008)
Hofman, M.A.: Size and shape of the cerebral cortex in mammals (part 1 and 2). Brain Behav. Evol. 27(1), 28–40 (1985)
Holm, D., Schneider, D., Coath, C.D.: Age and deformation of early proterozoic quartzites in the southern lake superior region: implications for extent of foreland deformation during final assembly of laurentia. Geology 26(10), 907–910 (1998)
Holme, P., Liljeros, F., Edling, C.R., Kim, B.J.: Network bipartivity. Phys. Rev. E 68(5), 056107 (2003)
Hook, J.: Min-plus algebraic low rank matrix approximation: a new method for revealing structure in networks. arXiv preprint arXiv:1708.06552 (2017)
Hu, D., Li, X., Liu, X., Zhang, S.: The Laplacian energy and Laplacian Estrada index of random multipartite graphs. J. Math. Anal. Appl. 443(2), 675–687 (2016)
Huo, J., Zhao, H.: Dynamical analysis of a fractional sir model with birth and death on heterogeneous complex networks. Phys. A Stat. Mech. Appl. 448, 41–56 (2016)
Ilić, A., Stevanović, D.: The Estrada index of chemical trees. J. Math. Chem. 47(1), 305–314 (2010)
Ilic, A., Zhou, B.: Laplacian Estrada index of trees. arXiv preprint arXiv:1106.3041 (2011)
Ionescu, C., Lopes, A., Copot, D., Machado, J.T., Bates, J.H.: The role of fractional calculus in modeling biological phenomena: a review. Commun. Nonlinear Sci. Numer. Simul. 51, 141–159 (2017)
Ivanciuc, O., Balaban, T.-S., Balaban, A.T.: Design of topological indices. Part 4. Reciprocal distance matrix, related local vertex invariants and topological indices. J. Math. Chem. 12(1), 309–318 (1993)
Jahanbani, A.: New bounds for the Harary energy and Harary Estrada index of graphs. Mati 1(1), 40–51 (2019)
Joswig, M., Schröter, B.: Parametric shortest-path algorithms via tropical geometry. arXiv preprint arXiv:1904.01082 (2019)
Kamenkovich, I., Berloff, P., Haigh, M., Sun, L., Lu, Y.: Complexity of mesoscale eddy diffusivity in the ocean. Geophys. Res. Lett. 48(5), e2020GL091719 (2021)
Katz, L.: A new status index derived from sociometric analysis. Psychometrika 18(1), 39–43 (1953)
Kazu, R.S., Maldonado, J., Mota, B., Manger, P.R., Herculano-Houzel, S.: Cellular scaling rules for the brain of artiodactyla include a highly folded cortex with few neurons. Front. Neuroanat. 8, 128 (2014)
Keeling, M.J., Eames, K.T.: Networks and epidemic models. J. R. Soc. Interface 2(4), 295–307 (2005)
Ketterson, J.B.: The Physics of Solids. Oxford University Press, Oxford (2016)
Khosravanirad, A.: A lower bound for Laplacian Estrada index of a graph. MATCH Commun. Math. Comput. Chem. 70, 175–180 (2013)
Kim, B.J., Hong, H., Choi, M.: Netons: vibrations of complex networks. J. Phys. A Math. Gen. 36(23), 6329 (2003)
Kim, N., Fuhr, K. N., Schlick, T.: Graph applications to RNA structure and function. In: Biophysics of RNA Folding, pp. 23–51. Springer (2013)
King, A.E., Turner, M.S.: Non-local interactions in collective motion. R. Soc. Open Sci. 8(3), 201536 (2021)
Kiss, I.Z., Miller, J.C., Simon, P.L., et al.: Mathematics of Epidemics on Networks, p. 598. Springer, Cham (2017)
Kloster, K., Gleich, D.F.: Heat kernel based community detection. In: Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pp. 1386–1395 (2014)
Kloster, K., Sullivan, B.D., et al.: Walk entropy and walk-regularity. Linear Algebra Appl. 546, 115–121 (2018)
Kok, C.M., Rudin, A.: Relationship between the hydrodynamic radius and the radius of gyration of a polymer in solution. Die Makromol. Chem. Rapid Commun. 2(11), 655–659 (1981)
König, D.: Über graphen und ihre anwendung auf determinantentheorie und mengenlehre. Math. Ann. 77(4), 453–465 (1916)
Kutzelnigg, W.: What i like about Hückel theory. J. Comput. Chem. 28(1), 25–34 (2007)
Lee, C.-H., Tenneti, S., Eun, D.Y.: Transient dynamics of epidemic spreading and its mitigation on large networks. In: Proceedings of the Twentieth ACM International Symposium on Mobile Ad Hoc Networking and Computing, Mobihoc ’19, pp. 191–200. Association for Computing Machinery, New York (2019)
Li, B.: New bounds for Estrada index. MATCH Commun. Math. Comput. Chem. 77, 701–706 (2017)
Li, F., Wei, L., Zhao, H., Hu, F., Ma, X.: On the Estrada index of cactus graphs. Discrete Appl. Math. 203, 94–105 (2016)
Li, J., Guo, J.-M., Shiu, W.C.: The normalized Laplacian Estrada index of a graph. Filomat 28(2), 365–371 (2014)
Li, J., Li, X., Wang, L.: The minimal Estrada index of trees with two maximum degree vertices. MATCH Commun. Math. Comput. Chem. 64, 799–810 (2010)
Li, J., Shiu, W.C., Chan, W.H.: Note on the Laplacian Estrada index of a graph. MATCH Commun. Math. Comput. Chem. 66, 777–784 (2011)
Li, J., Shiu, W.C., Chang, A.: On the Laplacian Estrada index of a graph. Appl. Anal. Discrete Math. 3, 147–156 (2009)
Li, J., Zhang, J.: On the Laplacian Estrada index of unicyclic graphs. MATCH Commun. Math. Comput. Chem. 68(3), 835–842 (2012)
Li, J., Zhang, J.: Characterizing graphs with maximal Laplacian Estrada index. Linear Algebra Appl. 465, 312–324 (2015)
Linderoth, T.R., Horch, S., Lægsgaard, E., Stensgaard, I., Besenbacher, F.: Surface diffusion of pt on pt (110): Arrhenius behavior of long jumps. Phys. Rev. Lett. 78(26), 4978 (1997)
Liu, J.-B., Pan, X.-F., Cao, J.: Some properties on Estrada index of folded hypercubes networks. In: Abstract and Applied Analysis, vol. 2014. Hindawi (2014)
Liu, J.-P., Liu, B.-L.: Bounds of the Estrada index of graphs. Appl. Math. A J. Chin. Univ. 25(3), 325–330 (2010)
Lučić, B., Miličević, A., Nikolić, S., Trinajstić, N.: Harary index-twelve years later. Croat. Chem. Acta 75(4), 847–868 (2002)
Majumdar, C.K., Ghosh, D.K.: On next-nearest-neighbor interaction in linear chain. I. J. Math. Phys. 10(8), 1388–1398 (1969)
Martcheva, M.: An Introduction to Mathematical Epidemiology, vol. 61. Springer, New York (2015)
Mei, W., Mohagheghi, S., Zampieri, S., Bullo, F.: On the dynamics of deterministic epidemic propagation over networks. Annu. Rev. Control 44, 116–128 (2017)
Miyamoto, S., Shimono, K.: Molecular modeling to estimate the diffusion coefficients of drugs and other small molecules. Molecules 25(22), 5340 (2020)
Mugnolo, D.: Dynamical systems associated with adjacency matrices. Discrete Contin. Dyn. Syst. B 23(5), 1945–1973 (2018)
Nag, B., Chattopadhyay, D.: Negative electron diffusivity in high electric fields. Solid-State Electron. 21(1), 303–307 (1978)
Nagatani, T.: Stabilization and enhancement of traffic flow by the next-nearest-neighbor interaction. Phys. Rev. E 60(6), 6395 (1999)
Nasiri, R., Ellahi, H., Gholami, A., Fath-Tabar, G., Ashrafi, A.: Resolvent Estrada and signless Laplacian Estrada indices of graphs. MATCH Commun. Math. Comput. Chem. 77(1), 157–176 (2017)
Nguyen, A.Q., Anh, N.T., Nguyên, T.A.: Frontier Orbitals: A Practical Manual. Wiley, New York (2007)
Ninomiya, H., Tanaka, Y., Yamamoto, H.: Reaction, diffusion and non-local interaction. J. Math. Biol. 75(5), 1203–1233 (2017)
Onsager, L.: Statistical hydrodynamics. Il Nuovo Cimento (1943–1954) 6(2), 279–287 (1949)
Pastor-Satorras, R., Vespignani, A.: Epidemic spreading in scale-free networks. Phys. Rev. Lett. 86(14), 3200 (2001)
Pisanski, T., Randić, M.: Use of the Szeged index and the revised Szeged index for measuring network bipartivity. Discrete Appl. Math. 158(17), 1936–1944 (2010)
Plavšić, D., Nikolić, S., Trinajstić, N., Mihalić, Z.: On the Harary index for the characterization of chemical graphs. J. Math. Chem. 12(1), 235–250 (1993)
Pope, M., Swenberg, C.E., et al.: Electronic Processes in Organic Crystals and Polymers, vol. 39. Oxford University Press on Demand (1999)
Popolizio, M.: On the matrix Mittag–Leffler function: theoretical properties and numerical computation. Mathematics 7(12), 1140 (2019)
Powell, B.J.: An introduction to effective low-energy hamiltonians in condensed matter physics and chemistry. arXiv preprint arXiv:0906.1640 (2009)
Rad, N.J., Jahanbani, A., Hasni, R.: Pentacyclic graphs with maximal Estrada index. Ars Combin. 133, 133–145 (2017)
Rad, N.J., Jahanbani, A., Mojdeh, D.A.: Tetracyclic graphs with maximal Estrada index. Discrete Math. Algorithms Appl. 9(03), 1750041 (2017)
Rashid, M.A., Ahmad, S., Siddiqui, M.K., Jahanbani, A., Sheikholeslami, S., Shao, Z.: New bounds for the Estrada index of phenylenes. Polycyclic Aromatic Compounds, pp. 1–17 (2020)
Robbiano, M., Jimenez, R., Medina, L.: The energy and an approximation to Estrada index of some trees. Match 61(2), 369 (2009)
Rodríguez, J.: A note on new bounds for the Estrada index. Linear Algebra Appl. 580, 121–127 (2019)
Rodríguez, J., Aguayo, J.L., Carmona, J.R., Jahanbani, A.: A note lower bounds for the Estrada index. Discrete Math. 344(4), 112303 (2021)
Saloff-Coste, L.: The heat kernel and its estimates. In: Probabilistic Approach to Geometry, pp. 405–436. Mathematical Society of Japan (2010)
Sardar, T., Rana, S., Bhattacharya, S., Al-Khaled, K., Chattopadhyay, J.: A generic model for a single strain mosquito-transmitted disease with memory on the host and the vector. Math. Biosci. 263, 18–36 (2015)
Sasaki, K.-I., Shimomura, Y., Takane, Y., Wakabayashi, K.: Hamiltonian decomposition for bulk and surface states. Phys. Rev. Lett. 102(14), 146806 (2009)
Schunack, M., Linderoth, T.R., Rosei, F., Lægsgaard, E., Stensgaard, I., Besenbacher, F.: Long jumps in the surface diffusion of large molecules. Phys. Rev. Lett. 88(15), 156102 (2002)
Senft, D.C., Ehrlich, G.: Long jumps in surface diffusion: one-dimensional migration of isolated adatoms. Phys. Rev. Lett. 74(2), 294 (1995)
Shang, Y.: The Estrada index of random graphs. Sci. Magna 7, 79–81 (2011)
Shang, Y.: Perturbation results for the Estrada index in weighted networks. J. Phys. A Math. Theor. 44(7), 075003 (2011)
Shang, Y.: Lower bounds for the Estrada index. Electron. J. Linear Algebra 23, 664–668 (2012)
Shang, Y.: On the Estrada index of Ramanujan graphs. J. Combin. Inf. Syst. Sci. 37(1), 69 (2012)
Shang, Y.: Estrada index of general weighted graphs. Bull. Aust. Math. Soc. 88(1), 106–112 (2013)
Shang, Y.: Lower bounds for the Estrada index using mixing time and Laplacian spectrum. Rocky Mt. J. Math. 43(6), 2009–2016 (2013)
Shang, Y.: Estimating the distance Estrada index. arXiv preprint arXiv:1407.5248 (2014)
Shang, Y.: More on the normalized Laplacian Estrada index. Appl. Anal. Discrete Math. 8, 346–357 (2014)
Shang, Y.: Bounds of distance Estrada index of graphs. arXiv preprint arXiv:1511.06132 (2015)
Shang, Y.: Distance Estrada index of random graphs. Linear Multilinear Algebra 63(3), 466–471 (2015)
Shang, Y.: Estrada index of random bipartite graphs. Symmetry 7(4), 2195–2205 (2015)
Shang, Y.: Laplacian Estrada and normalized Laplacian Estrada indices of evolving graphs. PLoS One 10(3), e0123426 (2015)
Shang, Y.: On the number of spanning trees, the Laplacian eigenvalues, and the Laplacian Estrada index of subdivided-line graphs. Open Math. 14(1), 641–648 (2016)
Shang, Y.: Further results on distance Estrada index of random graphs. Bull. Malays. Math. Sci. Soc. 41(2), 537–544 (2018)
Shang, Y.: Lower bounds for gaussian Estrada index of graphs. Symmetry 10(8), 325 (2018)
Sladek, V., Harada, R., Shigeta, Y.: Protein dynamics and the folding degree. J. Chem. Inf. Model. 60(3), 1559–1567 (2020)
Sladek, V., Tokiwa, H., Shimano, H., Shigeta, Y.: Protein residue networks from energetic and geometric data: are they identical? J. Chem. Theory Comput. 14(12), 6623–6631 (2018)
Spielman, D.: Spectral graph theory. Combinatorial Scientific Computing, chapter 18. CRC Press, Boca Raton (2012)
Stanić, Z.: Inequalities for Graph Eigenvalues, vol. 423. Cambridge University Press, Cambridge (2015)
Trinajstić, N.: Hückel theory and topology. In: Semiempirical Methods of Electronic Structure Calculation, pp. 1–28. Springer, New York (1977)
Trinajstić, N.: Graph theory and molecular orbitals, pp. 235–275. Introduction and Fundamentals, Mathematical Chemistry Series, Chemical Graph Theory (1991)
Trinajstic, N.: Chemical Graph Theory. Routledge, New York (2018)
Tsuji, Y., Estrada, E.: Influence of long-range interactions on quantum interference in molecular conduction. A tight-binding (Hückel) approach. J. Chem. Phys. 150(20), 204123 (2019)
Tsuji, Y., Estrada, E., Movassagh, R., Hoffmann, R.: Quantum interference, graphs, walks, and polynomials. Chem. Rev. 118(10), 4887–4911 (2018)
Van Der Hofstad, R.: Random Graphs and Complex Networks, vol. 43. Cambridge University Press, Cambridge (2017)
van Lint, J.H., Seidel, J.J.: Equilateral point sets in elliptic geometry. Indag. Math. 28(3), 335–348 (1966)
Verde-Star, L.: Functions of matrices. Linear Algebra Appl. 406, 285–300 (2005)
Von Collatz, L., Sinogowitz, U.: Spektren endlicher grafen. In: Abhandlungen aus dem Mathematischen Seminar der Universität Hamburg, vol. 21, pp. 63–77. Springer, New York (1957)
Von Mering, C., Krause, R., Snel, B., Cornell, M., Oliver, S.G., Fields, S., Bork, P.: Comparative assessment of large-scale data sets of protein–protein interactions. Nature 417(6887), 399–403 (2002)
Vu, B.D., Tong, B.T. et al.: Dynamics of negative diffusivity and uphill diffusion in ternary and single systems. In: EPJ Web of Conferences, vol. 206, p. 09015. EDP Sciences (2019)
Wang, F., Stuart, J.: Instability of Hagen–Poiseuille flow for non-axisymmetric mode. Appl. Math. Mech. 10(5), 407–417 (1989)
Wang, K., Pan, X., Ning, W.: On the signless Laplacian Estrada index of cacti. Discrete Appl. Math. 254, 189–195 (2019)
Wang, L., Fan, Y.-Z., Wang, Y.: Maximum Estrada index of bicyclic graphs. Discrete Appl. Math. 180, 194–199 (2015)
Wang, L.-W., Zunger, A.: Solving Schrödinger’s equation around a desired energy: application to silicon quantum dots. J. Chem. Phys. 100(3), 2394–2397 (1994)
Wang, W.L., Yazyev, O.V., Meng, S., Kaxiras, E.: Topological frustration in graphene nanoflakes: magnetic order and spin logic devices. Phys. Rev. Lett. 102(15), 157201 (2009)
Watts, D.J., Strogatz, S.H.: Collective dynamics of ‘small-world’ networks. Nature 393(6684), 440–442 (1998)
White, J.G., Southgate, E., Thomson, J.N., Brenner, S., et al.: The structure of the nervous system of the nematode Caenorhabditis elegans. Philos. Trans. R. Soc. Lond. B Biol. Sci. 314(1165), 1–340 (1986)
Wigner, E.P.: The unreasonable effectiveness of mathematics in the natural sciences. In: Mathematics and Science, pp. 291–306. World Scientific (1990)
Woodward, R.B., Hoffmann, R.: Stereochemistry of electrocyclic reactions. J. Am. Chem. Soc. 87(2), 395–397 (1965)
Wrigley, J.D., Twigg, M.E., Ehrlich, G.: Lattice walks by long jumps. J. Chem. Phys. 93(4), 2885–2902 (1990)
Xiao, B., Hancock, E.R., Wilson, R.C.: Graph characteristics from the heat kernel trace. Pattern Recognit. 42(11), 2589–2606 (2009)
Yamamoto, K., Yoshikura, H.: Relation between genomic and capsid structures in RNA viruses. Nucleic Acids Res. 14(1), 389–396 (1986)
Yang, Y., Sun, L., Bu, C.: A note on some bounds of the Estrada index of graphs. Adv. Math. Phys. 2020, 3972789 (2020)
Yates, K.: Hückel Molecular Orbital Theory. Elsevier, Amsterdam (2012)
Yu, C., Guan, J., Chen, K., Bae, S.C., Granick, S.: Single-molecule observation of long jumps in polymer adsorption. ACS Nano 7(11), 9735–9742 (2013)
Zaslavsky, T.: A mathematical bibliography of signed and gain graphs and allied areas. Electron. J. Combin. (2012)
Zhang, H., Wang, Y.: On the maximum Laplacian Estrada index of graphs. Linear Algebra Appl. 492, 68–77 (2016)
Zhang, H., Wang, Y.: On the maximum Laplacian Estrada index of graphs. Linear Algebra Appl. 492, 68–77 (2016)
Zhang, J., Zhou, B., Li, J.: On Estrada index of trees. Linear Algebra Appl. 434(1), 215–223 (2011)
Zhao, H., Jia, Y.: On the Estrada index of bipartite graph. Match 61(2), 495 (2009)
Zhao, T., Qiu, D.: One-pot synthesis of highly folded microparticles by suspension polymerization. Langmuir 27(21), 12771–12774 (2011)
Zhou, B.: On Estrada index. MATCH Commun. Math. Comput. Chem. 60, 485–492 (2008)
Zhou, B.: On sum of powers of Laplacian eigenvalues and Laplacian Estrada index of graphs. arXiv preprint arXiv:1102.1144 (2011)
Zhou, B., Gutman, I.: More on the Laplacian Estrada index. Appl. Anal. Discrete Math. 3(2), 371–378 (2009)
Zhou, B., Trinajstic, N.: Estrada index of bipartite graphs. Int. J. Chem. Model. 1(3/4), 387–394 (2008)
Zhu, B.-X.: On the Laplacian Estrada index of graphs. MATCH Commun. Math. Comput. Chem. 66(3), 769–776 (2011)
Zhu, Z., Tan, L., Qiu, Z.: Tricyclic graph with maximal Estrada index. Discrete Appl. Math. 162, 364–372 (2014)
Acknowledgements
The author thanks financial support from Ministerio de Ciencia, Innovacion y Universidades, Spain for the grant PID2019-107603GB-I00 “Hubs-repelling/attracting Laplacian operators and related dynamics on graphs/networks”. The author thanks the referees for exhaustive and construtive revision of the manuscript.
Funding
Open Access funding provided thanks to the CRUE-CSIC agreement with Springer Nature.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix
Appendix
The following result allows the calculation of the 21 different subgraphs which are used in the expressions of spectral moments of the adjacency matrix.
Theorem 50
Let \(k_{i}\) and \(t_{i}\) be the degree and the number of triangles at the node i. Then, the number of subgraphs illustrated in Fig. 1 are obtained as follow:
where
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Estrada, E. The many facets of the Estrada indices of graphs and networks. SeMA 79, 57–125 (2022). https://doi.org/10.1007/s40324-021-00275-w
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40324-021-00275-w