
Abstract
This study proposes new statistical tools to analyze the counts of the daily coronavirus cases and deaths. Since the daily new deaths exhibit highly over-dispersion, we introduce a new two-parameter discrete distribution, called discrete generalized Lindley, which enables us to model all kinds of dispersion such as under-, equi-, and over-dispersion. Additionally, we introduce a new count regression model based on the proposed distribution to investigate the effects of the important risk factors on the counts of deaths for OECD countries. Three data sets are analyzed with proposed models and competitive models. Empirical findings show that air pollution, the proportion of obesity, and smokers in a population do not affect the counts of deaths for OECD countries. The interesting empirical result is that the countries with having higher alcohol consumption have lower counts of deaths.
Similar content being viewed by others

Introduction
The first case of the COVID-19 (coronavirus disease 2019) was reported in Wuhan, China, in December 2019. The World Health Organization (WHO) has declared that the COVID-19 is a pandemic on the date of March 11, 2020. After this date, all countries have increased their measures to decrease the spread rate of the COVID-19 by closing schools, shopping centers, airlines, and also their borders. As of date May 17, 2020, the counts of COVID-19 cases are over 4.72 million and the counts of deaths are 313, 221. This number may be of little importance to anyone, but almost half the population of Luxembourg.
The researchers and academicians have spent their time finding medical solutions such as drugs and vaccines to return our normal life. Besides these medical researchers, the researchers have also focused on the mathematical and statistical modeling of the COVID-19 outbreak. For instance, [1] predicted the needed hospital beds and personnel for Italy under the exponential trend. [2] used autoregressive time-series models based on the two-piece scale mixture normal distributions to forecast the recovered and confirmed COVID-19 cases. [3] predicted the daily new COVID-19 cases in China by using the mathematical model, called SIR. As in [3, 4] also used the SIR model to predict COVID-19 cases. Caccavo [5] introduced the SIRD compartmental model to predict COVID-19 cases in China and Italy. Ayyoubzadeh et al. [6] predicted COVID-19 cases in Iran by using long short-term memory (LSTM) which is a deep-learning method.
This study aims to model the daily new cases and deaths of the COVID-19 employing a new statistical tool. To achieve this aim, we introduce a new flexible two-parameter discrete model, called as discrete analogous of the generalized Lindley, shortly DsGLi, distribution. The generalized Lindley distribution was introduced by Nedjar [7] and modified by Messaadia [8]. We introduce the DsGLi distribution by applying the survival discretization method of [9]. The question may come to mind of anyone: Why do we need this distribution? In primary data analysis, we have realized that most of the existing probability distributions do not provide acceptable results for modeling the COVID-19 cases. The reason is that the counts of deaths or daily new cases exhibit excessive over-dispersion (see Sect. 2 for the definition of the over-dispersion). At this point, we see the advantage of DsGLi distribution over other distributions, because the proposed distribution, DsGLi, provides a new opportunity to model all kinds of dispersed count data sets. Some important properties of the DsGLi distribution can be summarized as follows: (1) It has closed-form expressions for its statistical properties, (2) it has increasing hazard rate function (hrf), and (3) it can be used to model both skewed and leptokurtic count data sets. Additionally, a new count regression model is defined based on the DsGLi distribution to analyze the effects of explanatory variables such as smoking, obesity, air pollution on the daily cases, and deaths of the COVID-19 outbreak.
The remaining parts of the presented study are organized as follows: Sect. 2 deals with the statistical properties of the DsGLi distribution. In Sect. 3, we discuss the parameter estimation process of the DsGLi distributions with maximum likelihood estimation method, and the performance of the estimation method is investigated by a simulation study for its finite sample size behavior. In Sect. 4, we introduce the DsGLi regression model and clarify its parameter estimation process and residual analysis. Section 5 contains three applications to COVID-19 data sets. The empirical results obtained in Sect. 5 are discussed in Sect. 6 in detail. Sect. 7 contains some important remarks about the presented study.
Discrete analogue of GLi distribution
[9] introduced a new method to generate a new discrete distribution based on the survival function of any continuous probability distribution. This method is called a survival discretization method. Let the continuous random variable X has the survival function (sf) \(S(x;\mathbf {\xi })=\Pr (X>x)\), then the probability mass function (pmf), corresponding to \(S(x;\mathbf {\xi })=\Pr (X>x)\), is
This approach has been received considerable attention over the recent years, for instance, [10,11,12,13,14,15,16,17,18,19,20,21] and references cited therein. Note that there are some different discretization methods in order to construct new discrete distribution for modeling count data. Some of them are presented in [22] and [23].
Nedjar [7] proposed a new probability distribution for modeling data, in the so-called gamma Lindley (GLi) distribution. It is a mixture of a gamma(\(2,\theta \)) and Lindley(\(\alpha \)) distribution. The pdf of GLi distribution can be expressed as
Unfortunately, Eq. (2) is not a proper PDF, because it can be negative for some values of the parameters \(\alpha >0\) and \(\theta >0\). [8] modified the parameter space to be \(\alpha \ge \frac{\theta }{1+\theta }\) and \(\theta >0\), and consequently, the proper pdf of GLi model can be written as
The sf corresponding to Eq. (3) is
where \(\alpha \ge \frac{\theta }{1+\theta }\) and \(\theta >0\). Using the survival discretization method and sf of GLi distribution, we define the rf of the DsGLi given as follows:
where \(\alpha \ge \frac{-\ln \eta }{1-\ln \eta }\), \(0<\eta <1\), and \( {\mathbb {N}} _{0}=\left\{ 0,1,2,3,\ldots ,k\right\} \) for \(0<k<\infty \). The pmf and cumulative distribution function (cdf) of the DsGLi distribution are given, respectively, by
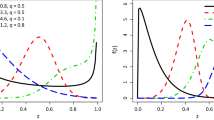
where \(x\in {\mathbb {N}}_{0}\). The pmf in (6) is log-concave, where \(\frac{P_{x}(x+1;\alpha ,\eta )}{P_{x}(x;\alpha ,\eta )}\) is a decreasing function in x for all values of the model parameters. Figure 1 shows the pmf plots for different values of the model parameters. From Fig. 1, the pmf of the DsGLi distribution is unimodal and right-skewed.

The pmf plots of the DsGLi distribution
The hrf of the DsGLi is expressed as
where \(h(x;\alpha ,\eta )=\frac{P_{x}(x;\alpha ,\eta )}{S(x-1;\alpha ,\eta )}\). Figure 2 shows the hrf plots of the DsGLi distribution. It is noted that the shape of the hrf is increasing. Further, the value of failure rate decreases with \(\eta \longrightarrow 1\) for fixed value of \(\alpha \).

The hrf plots of the DsGLi distribution
Properties
The statistical properties of the DsGLi distribution are obtained and reported in this section. Let X be random variable having a pmf in (6). The probability generating function (pgf) of X is
By replacing z by \(e^{z}\) in (9), one can obtain the moment generating function (mgf) of X which is given by
The similar relation is also valid between the mgf and characteristic function (cf). The cf function of X is obtained by replacing \(e^z\) by \(e^{iz}\). Then, we have
The partial derivatives of (10) according to z at \(z=0\) give raw moments of X. Using this property, the first two moments of the DsGLi model are given, respectively, by
The variance of the DsGLi distribution can be calculated by using \(\text {Var}\left( X\right) =\text {E}\left( X^2\right) -\text {E}\left( X\right) ^2\). The skewness and kurtosis measures of the DsGLi can be also easily calculated by using well-known relations. The other important measure of any discrete distribution is dispersion index (DI) which is defined as \(\text {DI}=\text {Var}\left( X\right) / \text {E}\left( X\right) \). The flexibility of the DI measure is important to model different types of data sets such as over-dispersed (\(\text {DI}>1\)), equi-dispersed (\(\text {DI}=1\)), and under-dispersed (\(\text {DI}<1\)). The statistical measures of the DsGLi distribution are computed and reported in Tables 1 and 2. To interpret the individual effects of the parameters \(\alpha \) and \(\eta \), the results are calculated for fixed \(\alpha =0.9\) and \(\eta =0.01\). As seen from Table 1, the mean, variance, and DI are the increasing function of the parameter \(\eta \) for fixed \(\alpha =0.90\), whereas the skewness and kurtosis decrease when the parameter \(\eta \) increases. As given in Table 2, the mean and variance are the increasing function of \(\alpha \). The DI, skewness, and kurtosis decrease when the parameter \(\alpha \) increases. As seen from these results, the DsGLi distribution has flexible DI which can be over or under one. So, the DsGLi distribution can be an appropriate choice in modeling all types of count data.
Estimation
The unknown parameters of the DsGLi distribution are obtained by the maximum likelihood estimation (MLE) method. This method is based on the maximization of the log-likelihood function for a given data set. Let us assume that we have a sample that comes from the DsGLi distribution, denoted as \(X_{1},X_{2},\ldots ,X_{n}\). Then, we have the following log-likelihood function for the DsGLi distribution
We have two choices to obtain the MLEs of the parameters \(\alpha \) and \(\eta \). The first way, we can use (14) to direct maximization of the log-likelihood to get the MLEs of the parameters, say \({\hat{\alpha }}\), and \({\hat{\eta }}\). The second way, the score vectors, given below, can be simultaneously solved for zero.
In this study, we prefer the first choice, direct maximization of (14) by means of constrOptim function of R. To obtain the asymptotic standard errors and confidence intervals, the observed information matrix is used evaluated at \({\hat{\alpha }}\) and \({\hat{\eta }}\). The observed information matrix can be numerically calculated by hessian function of R software.
Simulation
We assess the finite sample performance of the MLE method in estimating the unknown parameters of the DsGLi distribution. Therefore, we conduct a simulation study. The simulation replication number, N, is taken as 1, 000. The true parameter values are used as \(\alpha =0.5\) and \(\eta =0.5\). There is no specific reason to use these parameter values. Different parameter settings can be used. We generate random samples from the DsGLi distribution with \(n=50,55,60,\ldots ,300\) sample sizes. The simulation results are interpreted based on the estimated biases, mean square errors (MSEs), and mean relative errors (MREs). The required mathematical formulations of these metrics can be found in the works of [24, 25]. We expect to see that biases and MSEs are near the zero and MREs are near the one for sufficiently large sample sizes. The simulation results are graphically summarized and displayed in Fig. 3. These results confirm our expectation that the estimated biases and MSEs are near the zero for nearly all samples of sizes. Also, the estimated MREs are near the one, as expected. These results also show that the MLEs of the parameters of the DsGLi distribution are asymptotically unbiased and consistent. The similar results are obtained for different parameter settings, but not reported here for the sake of simplicity.

The simulation results of the DsGLi distribution
DsGLi regression model
When modeling the discrete response variable with associated covariates, the Poisson regression model is the first thing come to mind. However, it is well known that the Poisson regression produces inaccurate results when the response variable is over-dispersed or under-dispersed, except equi-dispersion. In this study, we propose an alternative model to provide new opportunities in predicting the over-dispersed counts. Let Y be a random variable following a DsGLi density. Using the below re-parametrization
we have
where
The density in (18) is denoted as \(Y\sim \text {DsGLi}\left( \alpha ,\mu \right) \). After this re-parametrization, the mean of the random variable is \(\text {E}\left( Y\right) =\mu \) and its variance is
The parameter \(\eta \) is a dispersion parameter of the re-parametrized DsGLi distribution. Now, using the density in (18), we propose a new count regression model. Let the response variable Y follow the density in (18) and consider the regression structure given as follows:
where \({\mathbf {x}}_i^T=\left( x_{i1},x_{i2},\ldots ,x_{ik}\right) \) is the explanatory variable vector and \(\varvec{\beta }=\left( \beta _0,\beta _1,\ldots ,\beta _k\right) \) is the vector of regression parameters. The function in (21) is known as link function. The link functions play an important role in generalized linear models to construct a bridge between predictors and the mean of the response variable. The suitable choice of the link function depends on the domain the response variable. Since the response variable is defined on \({\mathbb {Z}}_{+}\), the log-link function is used.
Estimation process
The log-link is defined as \(\mu _i =\exp \left( {\mathbf {x}}_i^T\varvec{\beta }\right) \). Using the log-link function, the log-likelihood function of the DsGLi regression model is given by
where n is the sample size, \(\eta \) is the unknown dispersion parameter, and \(\varvec{\beta }\) is the unknown regression parameters. Let \(\varvec{\gamma }=\left( \eta ,\varvec{\beta }\right) \) be an unknown parameter vector. Under the regularity conditions of the MLE, the asymptotic distribution of the \(\varvec{\gamma }-\varvec{{\hat{\gamma }}}\) is the \(\left( k+2\right) \)-variate normal distribution with zero mean and variance–covariance matrix, \(\Sigma _{(k+2)\times (k+2)}\) which is obtained by the inverse of observed information matrix, \(I_{(k+2)\times (k+2)}\) calculated at the MLE of the \(\varvec{\beta }\), \(\varvec{{\hat{\beta }}}\). To estimate the unknown parameter vector, \(\varvec{\gamma }\), the below estimation process is implemented.
-
1.
First, the underlying data set is fitted by Poisson regression model to get the initial parameter vector of the \(\varvec{\beta }\) for DsGLi regression model.
-
2.
Next, using the estimated regression parameters of the Poisson regression model as an initial parameter vector for the \(\varvec{\beta }\) and setting the initial value of \(\eta =0.5\), the minus log-likelihood function, \(-\ell \left( {\eta ,\varvec{\beta } }\right) \) in (22), is minimized by constrOptim function in R since the parameter \(\eta \in \left( 0,1\right) \).
-
3.
Then, using the hessian function in R, we obtain the observed information matrix, \(I_{(k+2)\times (k+2)}\), calculated at \(\varvec{{\hat{\gamma }}}\).
Residual analysis
Residual analysis is carried out to be sure about the accuracy of the DsGLi regression model for the used data set. The randomized quantile residual (rqr) is used for this purpose. Let the random variable Y have a cdf \(F\left( y;\eta ,\mu \right) \) which is the cdf of the re-parametrized DsGLi distribution. Then, the rqr is defined as
where \({u_i} = F\left( {{y_i};{{{\hat{\alpha }}, \mu }_i}} \right) \). Note that the rqr is distributed as \(N\left( 0,1\right) \) when the model is acceptable for the used data.
Data analysis
The empirical importance of the proposed models is proved by three applications to COVID-19 data sets. The proposed models are compared with some competitive models to see its competitive power. The competitive models are listed in the following.
In the first two empirical studies, we compare the fit of the DsGLi distribution with competitive models listed in Table 3. The goodness-of-fit test and Kolmogorov–Smirnov (\({K-S}\)) are implemented to select a best-fitted model for COVID-19 data sets. The models having p value higher than 0.05 are evaluated as possible accurate models, and the information criteria, listed below, are used to decide best-fitted model in final stage. The data source is https://www.worldometers.info/coronavirus/. In the third application, we assess the performance of the DsGLi regression model by applying the model to the COVID-19 data set of the OECD countries.
- \(\bullet \):
-
Akaike information criterion (AIC).
- \(\bullet \):
-
Hannan–Quinn information criterion (HQIC).
- \(\bullet \):
-
Bayesian information criterion (BIC).
- \(\bullet \):
-
Corrected Akaike information criterion (CAIC).
South Korea
In the first application, we consider the daily new deaths in South Korea. The data are available at https://www.worldometers.info/coronavirus/country/south-korea/ and contain the daily new deaths between February 15 and December 14, 2020.
This data set is modeled with DsGLi and other competitive models. Table 4 contains the estimated parameters and their corresponding standard errors (SEs) as well as confidence intervals (CIs) for all fitted models. The results of the information criteria and goodness-of-fit test are given in Table 5. The best-fitted model should have the lowest values of these statistics. From Table 5, we conclude that the DsGLi model is the best-performed model among others since it has the lowest values of AIC, BIC, CAIC, HQIC, and K–S test statistic. The higher value of the p value of the KS test shows the better-fitted model. If the p value is less than 0.05, it means that the model cannot be used to predict the counts of COVID-19 cases. According to the modeled data set, DsGLi and DsLi distributions have p values higher than 0.05. However, the p value of DsGLi distribution is higher than those of DsLi distribution. Therefore, the proposed model is the best choice for modeling the data used.
Figure 4 displays the estimated pmfs and probability–probability (PP) plots of the fitted models. These figures prove the suitability of the DsGLi distribution for modeling the counts of COVID-19 deaths South Korea.

The estimated pmf (top) and PP plots (bottom) for South Korea data set
Table 6 lists the theoretical values of the mean, variance, and DI measures of the DsGLi distribution obtained under the estimated parameters. The empirical mean, variance, and DI of the used data set are 1.918, 4.180, and 2.179, respectively. The theoretical mean, variance, and DI are closed to empirical ones.
Armenia
In the second application, we consider the daily new deaths in Armenia. The data are available at https://www.worldometers.info/coronavirus/country/armenia/ and contain the daily new cases between February 15 and October 4, 2020.
The above data set is modeled with DsGLi and other competitive models, and the estimated parameters and goodness-of-fit results are reported in Tables 7 and 8, respectively. According to the results in Table 8, we conclude that the DsGLi distribution is the best choice among other competitive models since it has the lowest values of the goodness-of-fit statistics. Additionally, the only distribution having the p value higher than 0.05 is DsGLi. Therefore, the proposed model is the best choice for modeling the data used.
Figure 5 displays the estimated pmfs and PP plots of the fitted models. From these figures, it is concluded that the DsGLi model provides acceptable modeling performance for the used data.

The estimated pmf (top) and PP plots (bottom) for Armenia data set
Additionally, the theoretical values of the mean, variance, and DI measures of the DsGLi distribution are reported in Table 9 for Armenia data set. The empirical mean, variance, and DI of the used data set are 4.207, 19.783, and 4.703, respectively. The theoretical mean and skewness are closed to empirical ones.
OECD
In the third application, the counts of deaths due to the COVID-19 are modeled for the OECD countries by the DsGLi regression model. The predictive performance of the DsGLi regression model is compared with Poisson regression. The response variable is the counts of deaths up to the date May 16, 2020. According to the Health at a Glance report (see OECD [30]), the important risk factors on health are the use of smoking and alcohol, overweight (obese), and air pollution. These variables are available in [30] and measured in the year 2019. We try to explain the variability in the counts of deaths (\(y_i\)) due to the coronavirus with covariates, smoking (\(x_{i1}\), % population aged \(15+\)), alcohol (\(x_{i2}\), % population aged \(15+\)), and overweight (\(x_{i3}\), % population with BMI \(\ge 25\) for population aged \(15+\)). We also consider the population size for each country as an explanatory variable. The population size is transformed in three-level categorical variable and two dummy variables are created: the population size between 7 and 35 million (\(x_{i5}\), 1 = yes, 0 = no) and the population size over 35 million \(x_{i6}\), 1 = yes, 0 = no). The population size lower than 7 million is considered as a baseline category. To avoid the extreme outlier observations, we exclude the countries having less than 1 million population and over 100 million population sizes. The regression model in (24) is fitted by DsGLi and Poisson regression models.
The estimated regression parameters and their corresponding standard errors (SEs), as well as p values, are listed in Table 10. The mean and variance of the response variable are 5391.4 and 104275974, which shows that it is highly over-dispersed. Because of the over-dispersed response variable, the Poisson regression model produces inaccurate results with higher AIC and BIC values than the DsGLi regression model. There are dramatic differences between the AIC and BIC values of two regression models. The DsGLi regression model enables to model over-dispersed response variable on the contrary to the Poisson regression model.
Figure 6 displays the results of the residual analysis of the DsGLi regression model. As seen from these figures, there is no observation to be evaluated as an outlier observation since all plotted points are in the envelopes.

The residual results of DsGLi regression model
Discussion of empirical results
In this section, the empirical results are interpreted in detail. The first two applications are based on the modeling of the counts of daily deaths of South Korea and Armenia, respectively. Using the estimated model parameters, some probabilities can be calculated. For instance, a researcher wants to know what is the probability that 3 or more deaths will occur in South Korea and Armenia in one day. To answer these research question, the estimated parameters of the DsGLi distribution and its cdf can be used. The probabilities related to this research question are calculated for different values of the count of deaths and reported in Table 11.
The counts of deaths in OECD countries are modeled with some covariates by using the DsGLi and Poisson regression models in the third application. According to the estimated regression parameters, we conclude the following results.
- \(\bullet \):
-
The proportion of smokers in the population does not affect the counts of deaths.
- \(\bullet \):
-
In a kind of funny way, the countries having more alcohol consumption have lower counts of deaths.
- \(\bullet \):
-
The proportion of obese individuals in the population does not affect the counts of deaths.
- \(\bullet \):
-
The air pollution does not affect the counts of deaths.
- \(\bullet \):
-
The countries with a population of over 35 million have \(\exp (4.2760)=71.9521\) times more counts of deaths than countries with a population below 7 million.
- \(\bullet \):
-
The countries with a population of 7–35 million have \(\exp (2.0978)=8.1482\) times more counts of deaths than countries with a population below 7 million.
Conclusion remarks
COVID-19 is still an unclear infectious disease. Each country’s social and policy responsibility is affected by the COVID-19 outbreak. In this paper, our aim is to try to serve humanity in this difficult situation by modeling this outbreak by utilizing a new probability distribution, and therefore, we have proposed a new two-parameter discrete gamma Lindley distribution for modeling such these count data. Some important statistical properties have been derived in closed forms which makes this model more flexible in practical fields. The model parameters have been estimated by using the maximum likelihood approach which gives a unique estimator. The flexibility of the proposed model has been explained by utilizing three COVID-19 data sets in different countries.
Statistical modeling is very important to combat such epidemics. With the help of the models proposed in this study, the expected number of new cases and deaths during the epidemic can be predicted. Thus, controlling the epidemic can be achieved more quickly. The modeling phase can also be divided into cities or smaller settlements instead of the whole country. We hope that the results obtained here will be useful for researchers, politicians, and healthcare organizations.
References
Remuzzi, A., Remuzzi, G.: COVID-19 and Italy: what next? The Lancet 395(10231), 1225–1228 (2020)
Maleki, M., Mahmoudi, M.R., Wraith, D., Pho, K.H. (2020). Time series modelling to forecast the confirmed and recovered cases of COVID-19. Travel Medicine and Infectious Disease 101742
Nesteruk, I.: Statistics-based predictions of coronavirus epidemic spreading in mainland China. Innov. Biosyst. Bioeng. 4(1), 13–18 (2020)
Batista, M.: Estimation of the Final Size of the Coronavirus Epidemic by the SIR model. Online paper, ResearchGate (2020)
Caccavo, D.: Chinese and Italian COVID-19 outbreaks can be correctly described by a modified SIRD model. medRxiv (2020)
Ayyoubzadeh, S.M., Ayyoubzadeh, S.M., Zahedi, H., Ahmadi, M., Kalhori, S.R.N.: Predicting COVID-19 incidence through analysis of Google trends data in iran: data mining and deep learning pilot study. JMIR Public Health Surveill. 6(2), e18828 (2020)
Nedjar, S., Zeghdoudi, H.: On gamma Lindley distribution: properties and simulations. J. Comput. Appl. Math. 298, 167–174 (2016)
Messaadia, H., Zeghdoudi, H.: Around gamma Lindley distribution. J. Modern Appl. Stat. Methods 16(2), 23 (2017)
Roy, D.: The discrete normal distribution. Commun. Stat. Theory Methods 32(10), 1871–1883 (2003)
Gómez-Déniz, E., Calderín-Ojeda, E.: The discrete Lindley distribution: properties and applications. J. Stat. Comput. Simul. 81(11), 1405–1416 (2011)
Bebbington, M., Lai, C.D., Wellington, M., Zitikis, R.: The discrete additive Weibull distribution: a bathtub-shaped hazard for discontinuous failure data. Reliab. Eng. Syst. Saf. 106, 37–44 (2012)
Nekoukhou, V., Alamatsaz, M.H., Bidram, H.: Discrete generalized exponential distribution of a second type. Statistics 47(4), 876–887 (2013)
Bakouch, H.S., Aghababaei, M., Nadarajah, S.: A new discrete distribution. Statistics 48(1), 200–240 (2014)
Alamatsaz, M., Dey, H., Dey, S., Harandi, T., Shams, S.: Discrete generalized Rayleigh distribution. Pak. J. Stat. 32(1), 1–20 (2016)
El-Morshedy, M., Eliwa, M.S., Nagy, H.: A new two-parameter exponentiated discrete Lindley distribution: properties, estimation and applications. J. Appl. Stat. 47(2), 354–375 (2020a)
El-Morshedy, M., Eliwa, M.S., Altun, E.: Discrete Burr–Hatke distribution with properties, estimation methods and regression model. IEEE Access 8, 74359–74370 (2020b)
El-Morshedy, M., Eliwa, M.S., El-Gohary, A., Khalil, A.A.: Bivariate exponentiated discrete Weibull distribution: statistical properties, estimation, simulation and applications. Math. Sci. 14(1), 29–42 (2020c)
Eliwa, M.S., Alhussain, Z.A., El-Morshedy, M.: Discrete Gompertz-G family of distributions for over-and under-dispersed data with properties, estimation, and applications. Mathematics 8(3), 358 (2020a)
Eliwa, M.S., Altun, E., El-Dawoody, M., El-Morshedy, M.: A new three-parameter discrete distribution with associated INAR (1) process and applications. IEEE Access 8, 91150–91162 (2020b)
Eliwa, M.S., El-Morshedy, M. (2020a). A one-parameter discrete distribution for over-dispersed data: statistical and reliability properties with estimation approaches and applications. J. Appl. Stat. (Forthcoming to be published)
Eliwa, M.S., El-Morshedy, M.: Bayesian and non-Bayesian estimation of four-parameter of bivariate discrete inverse Weibull distribution with applications to model failure times, football, and biological data. Filomat 34(8), 1–22 (2020b)
Farbod, D., Gasparian, K.V.: On the confidence intervals of parametric functions for distributions generated by symmetric stable laws. Statistica 72(4), 405–413 (2012)
Farbod, D.: Some statistical inferences for two frequency distributions arising in bioinformatics. Appl. Math. E Notes 14, 151–160 (2014)
Altun, E.: A new model for over-dispersed count data: Poisson quasi-Lindley regression model. Math. Sci. 13(3), 241–247 (2019)
Altun, E.: A new generalization of geometric distribution with properties and applications. Commun. Stat. Simul. Comput. 49(3), 793–807 (2020)
Krishna, H., Pundir, P.S.: Discrete Burr and discrete Pareto distributions. Stat. Methodol. 6(2), 177–188 (2009)
Para, B.A., Jan, T.R.: Discrete version of log-logistic distribution and its applications in genetics. Int. J. Modern Math. Sci. 14(4), 407–422 (2016)
Jazi, M.A., Lai, C.D., Alamatsaz, M.H.: A discrete inverse Weibull distribution and estimation of its parameters. Stat. Methodol. 7(2), 121–132 (2010)
Hussain, T., Ahmad, M.: Discrete inverse Rayleigh distribution. Pak. J. Stat. 30(2), 203–222 (2014)
OECD: Health at a Glance 2019: OECD Indicators. OECD Publishing, Paris (2019) https://doi.org/10.1787/4dd50c09-en
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
El-Morshedy, M., Altun, E. & Eliwa, M.S. A new statistical approach to model the counts of novel coronavirus cases. Math Sci 16, 37–50 (2022). https://doi.org/10.1007/s40096-021-00390-9
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40096-021-00390-9
Keywords
- COVID-19
- Discrete distribution
- Gamma Lindley distribution
- Maximum likelihood estimation
- Regression
- Simulation