
Abstract
Three popular application domains of sentiment and emotion analysis are: 1) the automatic rating of movie reviews, 2) extracting opinions and emotions on Twitter, and 3) inferring sentiment and emotion associations of words. The textual elements of these domains differ in their length, i.e., movie reviews are usually longer than tweets and words are obviously shorter than tweets, but they also share the property that they can be plausibly annotated according to the same affective categories (e.g., positive, negative, anger, joy). Moreover, state-of-the-art models for these domains are all based on the approach of training supervised machine learning models on manually annotated examples. This approach suffers from an important bottleneck: Manually annotated examples are expensive and time-consuming to obtain and not always available. In this paper, we propose a method for transferring affective knowledge between words, tweets, and movie reviews using two representation techniques: Word2Vec static embeddings and BERT contextualized embeddings. We build compatible representations for movie reviews, tweets, and words, using these techniques, and train and evaluate supervised models on all combinations of source and target domains. Our experimental results show that affective knowledge can be successfully transferred between our three domains, that contextualized embeddings tend to outperform their static counterparts, and that better transfer learning results are obtained when the source domain has longer textual units than the target domain.







Similar content being viewed by others

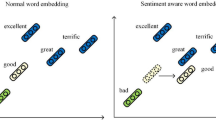

Notes
We use the term “affect” to encompass both sentiment and emotions.
In this work, we make the assumption that tweets are usually formed by a single sentence.
We do not study emotions at the document level due to the lack of annotated data to experiment with.
References
Cambria E. Affective computing and sentiment analysis. IEEE Intell Syst. 2016;31(2):102–7.
Cambria E, Hussain A. Sentic computing. Cogn Comput. 2015;7(2):183–5.
Joyce B, Deng J. Sentiment analysis of tweets for the 2016 US presidential election. In 2017 IEEE mit undergraduate research technology conference (urtc) 2017 Nov 3 (pp. 1-4). IEEE.
Suhariyanto Firmanto A, Sarno R. Prediction of movie sentiment based on reviews and score on rotten tomatoes using sentiwordnet. In: 2018 International Seminar on Application for Technology of Information and Communication; 2018. pp. 202–206.
Pelletier FJ. The principle of semantic compositionality. Topoi. 1994;13(1):11–24.
Harris ZS. Distributional structure Word. 1954;10(2–3):146–62.
Amir S, Astudillo R, Ling W, Martins B, Silva MJ, Trancoso I. Inesc-id: A regression model for large scale twitter sentiment lexicon induction. In: Proceedings of the 9th International Workshop on Semantic Evaluation (SemEval 2015), 2015;pp. 613–618
Nguyen H, Nguyen M. A deep neural architecture for sentence-level sentiment classification in twitter social networking. In: Hasida K, Pa WP, (eds.) Computational Linguistics - 15th International Conference of the Pacific Association for Computational Linguistics, PACLING 2017, Yangon, Myanmar, August 16-18, 2017, Revised Selected Papers, Communications in Computer and Information Science; 2017. vol. 781, pp. 15–27. Springer. https://doi.org/10.1007/978-981-10-8438-6_2.
Behdenna S, Barigou F, Belalem G. Sentiment analysis at document level. In: Unal A, Nayak M, Mishra DK, Singh D, Joshi A, editors. Smart Trends in Information Technology and Computer Communications. Singapore: Springer Singapore; 2016. p. 159–68.
Mohammad SM. Word affect intensities. In: Proceedings of the 11th Edition of the Language Resources and Evaluation Conference (LREC-2018). Miyazaki, Japan. 2018.
Mohammad S, Bravo-Marquez F. WASSA-2017 shared task on emotion intensity. In: Proceedings of the 8th Workshop on Computational Approaches to Subjectivity, Sentiment and Social Media Analysis. 2017;pp. 34–49. Association for Computational Linguistics, Copenhagen, Denmark. https://www.aclweb.org/anthology/W17-5205.
Bravo-Marquez F, Frank E, Pfahringer B. Transferring sentiment knowledge between words and tweets. Web Intelligence 2018;16(4), 203–220. https://doi.org/10.3233/WEB-180389.
Pan SJ, Yang Q. A survey on transfer learning. IEEE Trans Knowl Data Eng. 2010;22(10), 1345–1359. https://doi.org/10.1109/TKDE.2009.191.
Esuli, A, Sebastiani, F. Determining the semantic orientation of terms through gloss classification. In: Proceedings of the 14th ACM International Conference on Information and Knowledge Management. 2005;pp. 617–624. ACM.
Mikolov T, Sutskever I, Chen K, Corrado GS, Dean J. Distributed representations of words and phrases and their compositionality. In: Burges CJC, Bottou L, Ghahramani Z, Weinberger KQ, (eds.) Advances in Neural Information Processing Systems 26: 27th Annual Conference on Neural Information Processing Systems 2013. Proceedings of a meeting held December 5-8, 2013, Lake Tahoe, Nevada, United States; 2013. pp. 3111–3119. http://papers.nips.cc/paper/5021-distributed-representations-of-words-and-phrases-and-their-compositionality.
Devlin J, Chang M, Lee K, Toutanova K. BERT: pre-training of deep bidirectional transformers for language understanding. In: Burstein J, Doran C, Solorio T, (eds.) Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT 2019, Minneapolis, MN, USA, June 2-7, 2019, Volume 1 (Long and Short Papers), 2019;pp. 4171–4186. Association for Computational Linguistics. https://doi.org/10.18653/v1/n19-1423.
Zhu Y, Kiros R, Zemel RS, Salakhutdinov R, Urtasun R, Torralba A, Fidler S. Aligning books and movies: Towards story-like visual explanations by watching movies and reading books. 2015. http://arxiv.org/abs/1506.06724.
Cambria E, Li Y, Xing FZ, Poria S, Kwok K. Senticnet 6: Ensemble application of symbolic and subsymbolic ai for sentiment analysis. CIKM-20. 2020.
Pennington J, Socher R, Manning CD. Glove: Global vectors for word representation. In: Moschitti A, Pang B, Daelemans W, (eds.) Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing, EMNLP 2014, October 25-29, 2014, Doha, Qatar, A meeting of SIGDAT, a Special Interest Group of the ACL; 2014. pp. 1532–1543. ACL. https://doi.org/10.3115/v1/d14-1162.
Camacho-Collados J, Pilehvar MT. From word to sense embeddings: A survey on vector representations of meaning. J Artif Intell Res. 2018;63:743–788. https://doi.org/10.1613/jair.1.11259.
Yu L, Wang J, Lai KR, Zhang X. Refining word embeddings for sentiment analysis. In: Palmer M, Hwa R, Riedel S, (eds.) Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, EMNLP 2017, Copenhagen, Denmark; 2017. pp. 534–539. Association for Computational Linguistics. https://doi.org/10.18653/v1/d17-1056.
Zou WY, Socher R, Cer DM, Manning CD. Bilingual word embeddings for phrase-based machine translation. In: Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, EMNLP 2013, 18-21 October 2013, Grand Hyatt Seattle, Seattle, Washington, USA, A meeting of SIGDAT, a Special Interest Group of the ACL; 2013. pp. 1393–1398. ACL. https://www.aclweb.org/anthology/D13-1141/.
Kim Y. Convolutional neural networks for sentence classification. In: Moschitti A, Pang B, Daelemans W, (eds.) Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing, EMNLP 2014, October 25-29, 2014, Doha, Qatar, A meeting of SIGDAT, a Special Interest Group of the ACL, pp. 1746–1751. ACL 2014. https://doi.org/10.3115/v1/d14-1181.
Yang Z, Dai Z, Yang Y, Carbonell JG, Salakhutdinov R, Le QV. Xlnet: Generalized autoregressive pretraining for language understanding. In: H.M. Wallach, H. Larochelle, A. Beygelzimer, F. d’Alché-Buc, E.B. Fox, R. Garnett (eds.) Advances in Neural Information Processing Systems 32: Annual Conference on Neural Information Processing Systems 2019, NeurIPS 2019, 8-14 December 2019, Vancouver, BC, Canada; 2019. pp. 5754–5764. http://papers.nips.cc/paper/8812-xlnet-generalized-autoregressive-pretraining-for-language-understanding.
Peters ME, Neumann M, Iyyer M, Gardner, M, Clark C, Lee K, Zettlemoyer L. Deep contextualized word representations. In: Walker MA, Ji H, Stent A, (eds.) Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT 2018, New Orleans, Louisiana, USA, June 1-6, 2018; 2018. Volume 1 (Long Papers), pp. 2227–2237. Association for Computational Linguistics. https://doi.org/10.18653/v1/n18-1202.
Vaswani A, Shazeer N, Parmar N, Uszkoreit J, Jones L, Gomez AN, Kaiser L, Polosukhin I. Attention is all you need. In: I. Guyon, U. von Luxburg, S. Bengio, H.M. Wallach, R. Fergus, S.V.N. Vishwanathan, R. Garnett (eds.) Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, 4-9 December 2017, Long Beach, CA, USA; 2017. pp. 5998–6008. http://papers.nips.cc/paper/7181-attention-is-all-you-need.
Trinh TH, Dai AM, Luong T, Le QV. Learning longer-term dependencies in rnns with auxiliary losses. 2018. http://arxiv.org/abs/1803.00144.
Radford A, Narasimhan K, Salimans T, Sutskever I. Improving language understanding by generative pre-training. 2018. https://s3-us-west-2.amazonaws.com/openai-assets/researchcovers/languageunsupervised/languageunderstandingpaper.pdf.
Wu N, Green B, Ben X, O’Banion S. Deep transformer models for time series forecasting: The influenza prevalence case. 2020. https://arxiv.org/abs/2001.08317.
Sanh V, Debut L, Chaumond J, Wolf T. Distilbert, a distilled version of BERT: smaller, faster, cheaper and lighter. 2019. http://arxiv.org/abs/1910.01108.
Liu Y, Ott M, Goyal N, Du J, Joshi M, Chen D, Levy O, Lewis M, Zettlemoyer L, Stoyanov V. Roberta: A robustly optimized BERT pretraining approach. 2019. http://arxiv.org/abs/1907.11692.
Zhang Z, Han X, Liu Z, Jiang X, Sun M, Liu Q. ERNIE: Enhanced language representation with informative entities. In: Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics; 2019. pp. 1441–1451. Association for Computational Linguistics, Florence, Italy. https://www.aclweb.org/anthology/P19-1139.
Cañete J, Chaperon G, Fuentes R, Ho JH, Kang H, Pérez J. Spanish pre-trained bert model and evaluation data. In: Practical ML for Developing Countries Workshop@ ICLR 2020.
Clark, K., Luong, M., Le, Q.V., Manning, C.D.: ELECTRA: pre-training text encoders as discriminators rather than generators. In: 8th International Conference on Learning Representations, ICLR 2020, Addis Ababa, Ethiopia. 2020. OpenReview.net. https://openreview.net/forum?id=r1xMH1BtvB.
Glorot X, Bordes A, Bengio Y. Domain adaptation for large-scale sentiment classification: A deep learning approach. In: Getoor L, Scheffer T, (eds.) Proceedings of the 28th International Conference on Machine Learning, ICML 2011, Bellevue, Washington, USA. 2011;pp. 513–520. Omnipress. https://icml.cc/2011/papers/342_icmlpaper.pdf.
Miller GA, Beckwith R, Fellbaum C, Gross D, Miller K. Wordnet: An on-line lexical database. Int J Lexicogr. 1990;3:235–44.
He R, Lee WS, Ng HT, Dahlmeier D. Exploiting document knowledge for aspect-level sentiment classification. 2018. http://arxiv.org/abs/1806.04346.
Sindhwani V, Melville P. Document-word co-regularization for semi-supervised sentiment analysis. In: Proceedings of the 8th IEEE International Conference on Data Mining (ICDM 2008), December 15-19, 2008, Pisa, Italy; 2008. pp. 1025–1030. IEEE Computer Society. https://doi.org/10.1109/ICDM.2008.113.
Melville P, Gryc W, Lawrence RD. Sentiment analysis of blogs by combining lexical knowledge with text classification. In: IV JFE, Fogelman-Soulié F, Flach PA, Zaki MJ, (eds.) Proceedings of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Paris, France; 2009; pp. 1275–1284. ACM. https://doi.org/10.1145/1557019.1557156.
Socher R, Perelygin A, Wu J, Chuang J, Manning CD, Ng AY, Potts C. Recursive deep models for semantic compositionality over a sentiment treebank. In: Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, EMNLP 2013, 18-21 October 2013, Grand Hyatt Seattle, Seattle, Washington, USA, A meeting of SIGDAT, a Special Interest Group of the ACL; 2013. pp. 1631–1642. ACL. https://www.aclweb.org/anthology/D13-1170/.
Chalil, R.P., Selvaraju, S., Mahalakshmi, G.S.: Twitter sentiment analysis for large-scale data: An unsupervised approach. Cogn. Comput. 2015;7(2), 254–262. https://doi.org/10.1007/s12559-014-9310-z.
Xia Y, Cambria E, Hussain A, Zhao H. Word polarity disambiguation using bayesian model and opinion-level features. Cogn Comput. 2014;7. https://doi.org/10.1007/s12559-014-9298-4..
Ma Y, Peng H, Khan T, Cambria E, Hussain A. Sentic LSTM: a hybrid network for targeted aspect-based sentiment analysis. Cogn. Comput. 2018;10(4), 639–650. https://doi.org/10.1007/s12559-018-9549-x.
Poria S, Cambria E, Winterstein G, Huang G. Sentic patterns: Dependency-based rules for concept-level sentiment analysis. Knowl Based Syst. 2014;69,45–63. https://doi.org/10.1016/j.knosys.2014.05.005.
Susanto Y, Livingstone AG, Ng BC, Cambria E. The hourglass model revisited. IEEE Intell Syst. 2020;35(5):96–102. https://doi.org/10.1109/MIS.2020.2992799.
Akhtar MS, Ekbal A, Cambria E. How intense are you? predicting intensities of emotions and sentiments using stacked ensemble [application notes]. IEEE Comput Intell Mag. 2020;15(1):64–75.
Rani S, Kumar P. Deep learning based sentiment analysis using convolution neural network. Arab J Sci Eng. 2019;44(4):3305–14.
Maas AL, Daly RE, Pham PT, Huang D, Ng AY, Potts C. Learning word vectors for sentiment analysis. In: Lin D, Matsumoto Y, Mihalcea R, (eds.) The 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies, Proceedings of the Conference, 19-24 June, 2011, Portland, Oregon, USA, pp. 142–150. The Association for Computer Linguistics; 2011. https://www.aclweb.org/anthology/P11-1015/.
Rosenthal S, Ritter A, Nakov P, Stoyanov V. Semeval-2014 task 9: Sentiment analysis in twitter. In: Nakov P, Zesch T, (eds.) Proceedings of the 8th International Workshop on Semantic Evaluation, SemEval@COLING 2014, Dublin, Ireland; 2014. pp. 73–80. The Association for Computer Linguistics. https://doi.org/10.3115/v1/s14-2009.
Bravo-Marquez F, Frank E, Pfahringer B. From unlabelled tweets to twitter-specific opinion words. In: Baeza-Yates R, Lalmas M, Moffat A, Ribeiro-Neto BA, (eds.) Proceedings of the 38th International ACM SIGIR Conference on Research and Development in Information Retrieval, Santiago, Chile; 2015. pp. 743–746. ACM. https://doi.org/10.1145/2766462.2767770.
Wilson T, Wiebe J, Hoffmann P. Recognizing contextual polarity in phrase-level sentiment analysis. In: HLT/EMNLP 2005, Human Language Technology Conference and Conference on Empirical Methods in Natural Language Processing, Proceedings of the Conference, 6-8 October 2005, Vancouver, British Columbia, Canada; 2005 pp. 347–354. The Association for Computational Linguistics. https://www.aclweb.org/anthology/H05-1044/.
Liu B. Sentiment analysis and opinion mining. Synthesis lectures on human language technologies. 2012;5(1):1–167.
Nielsen FÅ. A new ANEW: evaluation of a word list for sentiment analysis in microblogs. In: Rowe M, Stankovic M, Dadzie A, Hardey M (eds.) Proceedings of the ESWC2011 Workshop on ’Making Sense of Microposts’: Big things come in small packages, Heraklion, Crete, Greece, May 30, 2011, CEUR Workshop Proceedings; 2011 vol. 718, pp. 93–98. CEUR-WS.org. http://ceur-ws.org/Vol-718/paper_16.pdf.
Mohammad S, Turney PD. Crowdsourcing a word-emotion association lexicon. Comput Intell. 2013;29(3), 436–465. https://doi.org/10.1111/j.1467-8640.2012.00460.x.
Petrović S, Osborne M, Lavrenko V. The Edinburgh twitter corpus. In: Proceedings of the NAACL HLT 2010 Workshop on Computational Linguistics in a World of Social Media; 2010. pp. 25–26. Association for Computational Linguistics, Los Angeles, California, USA. https://www.aclweb.org/anthology/W10-0513.
Bravo-Marquez F, Frank E, Mohammad SM, Pfahringer B. Determining word-emotion associations from tweets by multi-label classification. In: 2016 IEEE/WIC/ACM International Conference on Web Intelligence, WI 2016, Omaha, NE, USA, October 13-16, 2016, 2016;pp. 536–539. IEEE Computer Society. https://doi.org/10.1109/WI.2016.0091.
Van der Maaten L, Hinton G. isualizing data using t-sne. J Mach Learn Res. 2008;9(11).
Hall M, Frank E, Holmes G, Pfahringer B, Reutemann P, Witten IH. The weka data mining software: an update. ACM SIGKDD Explorations Newsletter. 2009;11(1):10–8.
Fan RE, Chang KW, Hsieh CJ, Wang XR, Lin CJ. Liblinear: A library for large linear classification. J Mach Learn Res. 2008;9:1871–4.
McCann B, Keskar NS, Xiong C, Socher R. The natural language decathlon: Multitask learning as question answering. 2018. arXiv preprint arXiv:1806.08730.
Yang Z, Dai Z, Yang Y, Carbonell JG, Salakhutdinov R, Le QV. Xlnet: Generalized autoregressive pretraining for language understanding. In: H.M. Wallach, H. Larochelle, A. Beygelzimer, F. d’Alché-Buc, E.B. Fox, R. Garnett (eds.) Advances in Neural Information Processing Systems 32: Annual Conference on Neural Information Processing Systems 2019, NeurIPS 2019, 8-14 December 2019, Vancouver, BC, Canada; 2019. pp. 5754–5764. http://papers.nips.cc/paper/8812-xlnet-generalized-autoregressive-pretraining-for-language-understanding.
Funding
This work was funded by ANID FONDECYT grant 11200290, U-Inicia VID Project UI-004/20, and ANID - Millennium Science Initiative Program - Code ICN17_002.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of Interest
The authors declare that they have no conflict of interest.
Informed Consent
Informed consent was not required as no human or animals were involved
Ethical Approval
This article does not contain any studies with human participants or animals performed by any of the authors.
Rights and permissions
About this article

Cite this article
Bravo-Marquez, F., Tamblay, C. Words, Tweets, and Reviews: Leveraging Affective Knowledge Between Multiple Domains. Cogn Comput 14, 388–406 (2022). https://doi.org/10.1007/s12559-021-09923-9
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s12559-021-09923-9