
Abstract
Continuing the discussion of how children can modify and regularize linguistic inputs from adults, we present a new interpretation of existing algorithms to model and investigate the process of a learner learning from an inconsistent source. On the basis of this approach is a (possibly nonlinear) function (the update function) that relates the current state of the learner with an increment that it receives upon processing the source’s input, in a sequence of updates. The model can be considered a nonlinear generalization of the classic Bush–Mosteller algorithm. Our model allows us to analyze and present a theoretical explanation of a frequency boosting property, whereby the learner surpasses the fluency of the source by increasing the frequency of the most common input. We derive analytical expressions for the frequency of the learner, and also identify a class of update functions that exhibit frequency boosting. Applications to the Feature-Label-Order effect in learning are presented.








Similar content being viewed by others


References
Andersen RW (1983) Pidginization and creolization as language acquisition. ERIC
Bendor J, Diermeier D, Ting M (2003) A behavioral model of turnout. Am Polit Sci Rev 97(02):261–280
Bendor J, Mookherjee D, Ray D (2001) Aspiration-based reinforcement learning in repeated interaction games: an overview. Int Game Theory Rev 3(02n03):159–174
Berko J (1958) The child’s learning of english morphology. Word 14(2–3):150–177
Botvinick MM, Niv Y, Barto AC (2009) Hierarchically organized behavior and its neural foundations: a reinforcement learning perspective. Cognition 113(3):262–280
Busemeyer JR, Pleskac TJ (2009) Theoretical tools for understanding and aiding dynamic decision making. J Math Psychol 53(3):126–138
Bush RR, Mosteller F (1955) Stochastic models for learning. Wiley, Hoboken
Camerer C (2003) Behavioral game theory: experiments in strategic interaction. Princeton University Press, Princeton
Duffy J (2006) Agent-based models and human subject experiments. Handb Comput Econ 2:949–1011
Erev I, Roth AE (1998) Predicting how people play games: reinforcement learning in experimental games with unique, mixed strategy equilibria. Am Econ Rev 88:848–881
Fedzechkina M, Jaeger TF, Newport EL (2012) Language learners restructure their input to facilitate efficient communication. Proc Natl Acad Sci 109(44):17897–17902
Fiorillo CD, Tobler PN, Schultz W (2003) Discrete coding of reward probability and uncertainty by dopamine neurons. Science 299(5614):1898–1902
Flache A, Macy MW (2002) Stochastic collusion and the power law of learning a general reinforcement learning model of cooperation. J Confl Resolut 46(5):629–653
Fowler JH (2006) Habitual voting and behavioral turnout. J Polit 68(2):335–344
Hsu AS, Chater N, Vitányi P (2013) Language learning from positive evidence, reconsidered: a simplicity-based approach. Top Cogn Sci 5(1):35–55
Izquierdo LR, Izquierdo SS, Gotts NM, Polhill JG (2007) Transient and asymptotic dynamics of reinforcement learning in games. Games Econ Behav 61(2):259–276
Kam CLH, Newport EL (2009) Getting it right by getting it wrong: when learners change languages. Cogn Psychol 59(1):30–66
Lieberman E, Michel J-B, Jackson J, Tang T, Nowak MA (2007) Quantifying the evolutionary dynamics of language. Nature 449(7163):713–716
Ma T, Komarova N (2017) Feature-label-order effect: a mathematical framework (in preparation)
Mandelshtam Y, Komarova NL (2014) When learners surpass their models: mathematical modeling of learning from an inconsistent source. Bull Math Biol 76(9):2198–2216
Monaghan P, White L, Merkx MM (2013) Disambiguating durational cues for speech segmentation. J Acoust Soc Am 134(1):EL45–EL51
Mookherjee D, Sopher B (1994) Learning behavior in an experimental matching pennies game. Games Econ Behav 7(1):62–91
Mookherjee D, Sopher B (1997) Learning and decision costs in experimental constant sum games. Games Econ Behav 19(1):97–132
Mühlenbernd R, Nick JD (2013) Language change and the force of innovation. In: Student sessions at the European summer school in logic, language and information. Springer, pp 194–213
Narendra KS, Thathachar MA (2012) Learning automata: an introduction. Courier Dover Publications, Mineola
Niv Y (2009) Reinforcement learning in the brain. J Math Psychol 53(3):139–154
Niyogi P (2006) The computational nature of language learning and evolution. MIT Press, Cambridge
Norman M (1972) Markov processes and learning models. Academic Press, New York
Nowak MA, Komarova NL, Niyogi P (2001) Evolution of universal grammar. Science 291(5501):114–118
Ramscar M, Hendrix P, Love B, Baayen R (2013) Learning is not decline: the mental lexicon as a window into cognition across the lifespan. Ment Lex 8(3):450–481
Ramscar M, Yarlett D, Dye M, Denny K, Thorpe K (2010) The effects of feature-label-order and their implications for symbolic learning. Cogn Sci 34(6):909–957
Rescorla R, Wagner A (1972) A theory of pavlovian conditioning: variations in the effectiveness of reinforcement and nonreinforcement. In: Black A, Prokasy W (eds) Classical conditioning II: current research and theory. Appleton-Century-Crofts, New York
Rescorla RA (1968) Probability of shock in the presence and absence of CS in fear conditioning. J Comp Physiol Psychol 66(1):1
Rescorla RA (1988) Pavlovian conditioning: it’s not what you think it is. Am Psychol 43(3):151
Ribas-Fernandes JJ, Solway A, Diuk C, McGuire JT, Barto AG, Niv Y, Botvinick MM (2011) A neural signature of hierarchical reinforcement learning. Neuron 71(2):370–379
Rische JL, Komarova NL (2016) Regularization of languages by adults and children: a mathematical framework. Cogn Psychol 84:1–30
Roth AE, Erev I (1995) Learning in extensive-form games: experimental data and simple dynamic models in the intermediate term. Games Econ Behav 8(1):164–212
Roy DK, Pentland AP (2002) Learning words from sights and sounds: a computational model. Cogn Sci 26(1):113–146
Schultz W (2006) Behavioral theories and the neurophysiology of reward. Annu Rev Psychol 57:87–115
Schultz W (2007) Behavioral dopamine signals. Trends Neurosci 30(5):203–210
Seidl A, Johnson EK (2006) Infant word segmentation revisited: edge alignment facilitates target extraction. Dev Sci 9(6):565–573
Senghas A (1995) The development of Nicaraguan sign language via the language acquisition process. In: Proceedings of the 19th annual Boston University conference on language development. Cascadilla Press, Boston, pp 543–552
Steels L (2000) Language as a complex adaptive system. In: International conference on parallel problem solving from nature. Springer, pp 17–26
Sutton RS, Barto AG (1998) Reinforcement learning: an introduction, vol 1. Cambridge University Press, Cambridge
Van de Pol M, Cockburn A (2011) Identifying the critical climatic time window that affects trait expression. Am Nat 177(5):698–707
Author information
Authors and Affiliations
Corresponding author
Appendices
Appendix 1: Comparing the VIM and the MCM
This section will discuss the comparison of the two methods in two respects: symmetric and asymmetric.

(Color figure online) Comparison of a VIM and b MCM where we ran them for 500,000 time steps over various frequency of the source, \(\nu \), from 0 to 1, with \(F(X/L)=(X/L)^{0.4}\). And \(L=100\). Plot of c relative error and d absolute error between VIM and MCM
1.1 Symmetric Algorithm
To compare the symmetric version methods, we plot the average values of the learner for various \(\nu \) values from 0 to 1 in Fig. 9. The average value is noted as approximately the steady state of the learner. Power functions will be used for the remainder of the discussion.
In Fig. 9, both methods produce similar shaped plots. The absolute error for each \(\nu \) between the methods are also plotted in Fig. 9; note that the absolute error is no more than 0.012 and that the relative error decreases as \(\nu \) increases.
1.2 Asymmetric Algorithm
We now introduce an asymmetric version of VIM and MCM, where the increments and decrements are different depending on whether the source’s input value matches the highest propensity, or preferred form, of the learner.
Let F be defined as above in the formulation of VIM. Let us define the preferred form of the learner as form m, that is \(x_m=\max _{i=1,2}\{x_i\}\). Suppose that \(x_m=x_1\), if the source emits form 1, then we have the following updates for the VIM version of the algorithm:
where \(F^+\) and \(F^-\) are some functions of one variable on [0, 1]. The rules above can be rewritten for the probability to utter form 2, \(x_2=1-x_1\):
where s and p are values between 0 and 1. The MCM asymmetric algorithm is just the translation of the VIM asymmetric algorithm into a Markov walk as described in Sect. 2.2 with the transition matrix, P, and function F.
For simplicity, we will refer to the asymmetric version of VIM and MCM as AVIM and AMCM, respectively. To compare AVIM and AMCM, we executed each algorithm with a fixed s and p value, given function \((x^{0.4})\) and calculated the average learner values as we did with the symmetric case. Figures 10 and 11 are the contour plots comparing both methods over various s and p values.

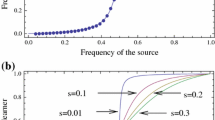
(Color figure online) Plot of a AVIM and b AMCM, with \(\nu =0.8\), and initial \(X=[0.6,0.4]\). \(s,p \in [0.1,0.2,\dots , 1]\). Along with the plots of the c relative and d absolute error between AVIM and AMCM
1.2.1 Observation: Differences in Initial Learner Values
An important observation here is that updates occur more frequently for certain values of s and p when the learner is reassured; otherwise, updates occur less frequently. Figure 10 is the plot of AVIM and AMCM where the learner and the source both prefers form 1. We can see that when \(s\gg p\), the learner will experience frequency boosting to nearly 1. This is due to the fact that in the algorithm, we use the “preferred” update when the source utters a form that coincides with the preferred form of the learner; the learner is reassured and takes a much bigger increment of update for its frequency of usage than it would otherwise.

(Color figure online) Plot of a AVIM and b AMCM, with \(\nu =0.8\), and initial \(X=[0.3,0.7]\). \(s,p\in [0.1,0.2,\dots ,1]\). Along with plots of c relative and d absolute errors of AVIM and AMCM
Figure 11 is the plot of AVIM and AMCM when the learner and the source prefer different forms. Again, we can see that when \(s \gg p\), updates are performed when the learner is reassured that its preferred form is used by the source; otherwise, the frequencies are updated by a significantly smaller amount.
1.2.2 Observation: Varying the Value of L
The discretization parameter, L, has a role in the stochastic behavior of the updates and ultimately determines when both methods are the same. Note that VIM (and AVIM) algorithm is updating with \(\Delta x = F/L\); which is L times slower than MCM (and AMCM). Thus, the updates for VIM and AVIM are relatively small increments as opposed to the increments of MCM and AMCM. In Fig. 12a, the plots of AVIM have small increments for updates of \(x_1\) and will oscillate around 0.38. The values for \(X_1\), however, may oscillate around 0.4 in the early stages but will eventually reach 0.5 given some random probability which then means that the learner’s preferred form will be the same as the source and experience the observations in 1. This is also the cause of the discrepancy in the relative and absolute error seen in Fig. 11.

(Color figure online) Plot of AVIM and AMCM for \(s=0.6\), \(p=0.1\) over a 6000 time steps with \(L=100\), and b 60,000 time steps with \(L=500\)
Figure 12b is AVIM and AMCM with a bigger L value. Since L was increased then \(X_1\) now updates with constant increments of a much smaller expectancy than before, and thus, the frequency stabilizes around the same value as what is exhibited in AVIM.
Figure 13 is a plot of the max relative and absolute error of the results for AVIM and AMCM when we vary L over all \(s,p\in [0,1]\). We see that as L increases, then we have that the relative error between AVIM and AMCM decreases. Thus, as \(L\rightarrow \infty \), the resulting learner values from the two algorithms coincide.

(Color figure online) Plot of L versus a relative and b absolute error of AVIM and AMCM
Appendix 2: Proof of Frequency Boosting Theorem
1.1 Proof of the Theorem for a Particular Example
Here, we set \(L=2\) and prove the theorem in this simple case. The general proof is provided in “The general case in Appendix 2.” We will use the convenient notation
We want to show that \(\nu _\mathrm{learn} > \nu \) when \(\nu > \frac{1}{2}\). Thus, with the notation above, it suffices to show that \(\nu _\mathrm{learn}> \frac{\lambda }{1+\lambda }\), when \(\lambda >1\). That is
For \(L=2\), the LHS of (23) becomes:
So we want to show that
Which is true if and only if
Which is equivalent to
After some algebra, we can simplify the expression to
Note that \(\lambda >1\), so it suffices to show that
That is we want to show that
From the definition of a function that is concave down as was described in Sect. 3.1, we can conclude that we have (26) and thus have (23) is true when \(L=2\).
1.2 The General Case
Now to the proof of the theorem for a general integer L.
Proof
Expanding out (23) we have that the frequency boosting property now becomes
which is equivalent to
Simplifying we get,
Combining like terms, we get,
For notation, let
Note that \(1-\frac{C_L^1}{L}= \frac{(L-1)+1}{L}C_L^{(L-1)+1} -\frac{L-(L-1)}{L}C_L^{L-1}=\alpha _{(L-1)+1}=\alpha _L\). So then (28) becomes
Since \(\alpha _L=1-\frac{C_L^1}{L}\), then by similar reasoning as in the \(L=2\) case, with \(x=1\) and \(y=L\), in (26), we have that \(\frac{C_L^1}{L}<1\), that is \(\alpha _L>0\). Since \(\lambda >1\), and \(\alpha _L>0\), we have that \(\lambda ^{L-1} \alpha _L > \alpha _L\), thus to show (28), it suffices to show
With the notation of (9), we can make more simplifications to (30). Note that \(C_L^{L-k}=C_L^k\), thus we have that (29) becomes
which can also be written as
From (29), by replacing the \(k+1\) with \(L-k\), we have that
Thus
Therefore, (30) simplifies into two cases, when L is even or odd.
Suppose first that \(L=2j\) for some integer j. Then using (34), we have that (30) simplifies to showing that
Which is equivalent to showing
Similarly when \(L=2j+1\) for some integer j. Then (30) simplifies to showing that
Note that since \(L=2j+1\), we have that \(\alpha _{L-j}=\alpha _{j+1}\) and that \(\alpha _{L-j}=-\alpha _{j+1}\) from (34), thus \(\alpha _{j+1}=0\). Thus for the odd case, (30) simplifies to showing that
Thus for either L is even or odd, from (35) and (36), it suffices to show that
for \(i=2,3,\dots , j\), since \(1-\lambda ^m <0\) for any m, because \(1<\lambda \).
From (9), we can also write
Thus, after simplification we have that (29) becomes
Because \(F(x)>0\) for all \(x>0\), then \(C_L^{i-1}>0\), then it suffices to show that
That is, it suffices to show that
for \(i=2,3,\dots ,j\), where \(L=2j\) or \(L=2j+1\).
Using the same argument made in the \(L=2\) case, we have (37) and therefore can conclude that \(\alpha _i <0\), for \(i=2,3,\dots , j\) where \(L=2j\) or \(L=2j+1\), and therefore can conclude (35, 36) and thus have (30). Hence, (23) is true for any integer L and for a function F that satisfies the properties listed in Sect. 3.1. \(\square \)
Rights and permissions
About this article

Cite this article
Ma, T., Komarova, N.L. Mathematical Modeling of Learning from an Inconsistent Source: A Nonlinear Approach. Bull Math Biol 79, 635–661 (2017). https://doi.org/10.1007/s11538-017-0250-0
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11538-017-0250-0