
Abstract
Study success includes the successful completion of a first degree in higher education to the largest extent, and the successful completion of individual learning tasks to the smallest extent. Factors affecting study success range from individual dispositions (e.g., motivation, prior academic performance) to characteristics of the educational environment (e.g., attendance, active learning, social embeddedness). Recent developments in learning analytics, which are a socio-technical data mining and analytic practice in educational contexts, show promise in enhancing study success in higher education, through the collection and analysis of data from learners, learning processes, and learning environments in order to provide meaningful feedback and scaffolds when needed. This research reports a systematic review focusing on empirical evidence, demonstrating how learning analytics have been successful in facilitating study success in continuation and completion of students’ university courses. Using standardised steps of conducting a systematic review, an initial set of 6220 articles was identified. The final sample includes 46 key publications. The findings obtained in this systematic review suggest that there are a considerable number of learning analytics approaches which utilise effective techniques in supporting study success and students at risk of dropping out. However, rigorous, large-scale evidence of the effectiveness of learning analytics in supporting study success is still lacking. The tested variables, algorithms, and methods collected in this systematic review can be used as a guide in helping researchers and educators to further improve the design and implementation of learning analytics systems.
Similar content being viewed by others

Introduction
To date, the study of learning analytics has tended to evolve exponentially from the early 2010s in the areas of education and psychology, as well as computing and data science (Prieto et al. 2019). As a result, while the concept of learning analytics is vaguely defined, it sees a plethora of conceptual variations, including school analytics (Sergis and Sampson 2016), teacher or teaching analytics (Sergis and Sampson 2017), academic analytics (Long and Siemens 2011), assessment analytics (Nouira et al. 2019), social learning analytics (Buckingham Shum and Ferguson 2012), or multimodal learning analytics (Blikstein and Worsley 2016). For this systematic literature review with a specific focus on learning analytics in higher education and its link to study success, learning analytics are defined as “the use, assessment, elicitation and analysis of static and dynamic information about learners and learning environments, for the near real-time modelling, prediction and optimisation of learning processes, and learning environments, as well as for educational decision-making” (Ifenthaler 2015, p. 447).
The success of learning analytics in improving students’ learning has yet to be proven systematically and empirically (Lodge and Corrin 2017). There have been a number of research efforts, some of which focused on various learning analytics tools (Atif et al. 2013), some on practices (Sclater et al. 2016) and policies (Tsai et al. 2018), and some, which related to learning analytics system adoption at school-level, within higher education institutions, and at national level (Buckingham Shum and McKay 2018; Ifenthaler 2017). Thus, the increased importance of data in education has led to an upsurge in primary research publications in learning analytics (Prieto et al. 2019), which indicate that the analysis of digital traces of learning and teaching may reveal benefits for learners, teachers, learning environments, or the organisation (Gašević et al. 2015). Although there are initial systematic reviews on learning analytics, such as on policy recommendations for learning analytics (Ferguson et al. 2016), identification of learning analytics research objectives and challenges (Papamitsiou and Economides 2014), learning analytics in the context of distance education (Kilis and Gulbahar 2016), and more recently on the efficiency of learning analytics interventions (Larrabee Sønderlund et al. 2018), there exists no current and comprehensive systematic review focusing on learning analytics for supporting study success.
Study success includes the successful completion of a first degree in higher education to the largest extent, and the successful completion of individual learning tasks to the smallest extent (Sarrico 2018). Factors affecting study success range from individual dispositions and characteristics such as age, gender, motivation or prior academic performance to features of the educational environment, such as curriculum design, learning tasks or social components (Bijsmans and Schakel 2018; Tinto 2005). The essence of study success is to capture any positive learning satisfaction, improvement, or experience during learning. Pistilli and Arnold (2010) have been among the first researchers to identify the potentials of learning analytics for supporting study success.
However, it is difficult for educational researchers, practitioners, and decision makers to develop and implement learning analytics strategies and systems that provide the greatest student success (Gašević et al. 2016). Therefore, the purpose of this article is to identify empirical evidence demonstrating how learning analytics have been successful in facilitating study success in higher education.
Theoretical framework
Study success
Even though many academic support programmes have been implemented (Padgett et al. 2013), and research on study success is extensive (Attewell et al. 2006; Bijsmans and Schakel 2018; Morosanu et al. 2010; Schmied and Hänze 2015), dropout rates in higher education remain at about 30% in the Organization for Economic Cooperation and Development member countries (OECD 2019). Student dropout has consequences on different levels, such as for the individual, the higher education institution, and for society (Larsen et al. 2013). For example, dropouts often represent a waste of resources for the individual and society, as well as reflecting poorly on the quality of the higher education institution (In der Smitten and Heublein 2013).
Hence, the success of students at higher education institutions has been a global concern for many years (Tinto 2005). Factors that contribute to student success, which may influence a student’s decision to discontinue higher education are various and complex (Tinto 1982, 2005). Important factors for dropouts that have been consistently found in international studies include the choice of the wrong study programme, lack of motivation, personal circumstances, an unsatisfying first-year experience, lack of university support services, and academic unpreparedness (Heublein 2014; Thomas 2002; Willcoxson et al. 2011; Yorke and Longden 2008). Moreover, there are several theoretical perspectives and models of student success in higher education (Bean and Metzner 1985; Rovai 2003; Tinto 1982), and many share common factors, even though their emphasis varies. Such common factors, which are related to study success include students’ sociodemographic factors (e.g., gender, ethnicity, family background), cognitive capacity, or prior academic performance (e.g., grade point average [GPA]), and individual attributes (e.g., personal traits, and motivational or psychosocial contextual influences) as well as course related factors such as active learning and attention or environmental factors related to supportive academic and social embeddedness (Bijsmans and Schakel 2018; Brahm et al. 2017; Remedios et al. 2008; Tinto 2017). To sum up, the essence of study success is to capture any positive learning satisfaction, academic improvement, or social experience in higher education. The possibility to collect and store data for the above mentioned factors and combining them in (near) real-time analysis opens up advanced evidence-based opportunities to support study success utilising meaningful interventions (Pistilli and Arnold 2010).
Learning analytics
Early approaches of learning analytics were limited in analysing trace-data or web-statistics in order to describe learner behaviour in online learning environments (Veenman 2013). With increased investigation of educational data, potentials for a broader educational context have been recognised, such as the identification of potential dropouts from study programmes (Sclater et al. 2016). Meanwhile, an extensive diversification of the initial learning analytics approaches can be documented (Prieto et al. 2019). These learning analytics approaches apply various methodologies, such as descriptive, predictive, and prescriptive analytics to offer different insights into learning and teaching (Berland et al. 2014). Descriptive analytics use data obtained from sources such as course assessments, surveys, student information systems, learning management system activities and forum interactions mainly for reporting purposes. Predictive analytics utilise similar data from those sources and attempt to measure onward learning success or failure. Prescriptive analytics deploy algorithms mainly to predict study success and whether students will complete courses, as well as recommending any immediate interventions necessary (Baker and Siemens 2015). The main motivations of utilising learning analytics for higher education institutions include (a) improving students’ learning and motivation, thus reducing dropout rate (or inactivity) (Colvin et al. 2015; Glick et al. 2019), and (b) attempting to improve the learner’s learning process by providing adaptive learning pathways toward specific goals set by the curriculum, teacher, or student (Ifenthaler et al. 2019). However, the success of learning analytics in improving higher education students’ learning and success has yet to be proven systematically. Only a few studies have tried to address this but limited evidence is shown (Suchithra et al. 2015). Nevertheless, higher education institutions are collecting and storing educational data (i.e., factors related to study succuss) which may be utilised through learning analytics systems for supporting study success.
Purpose of this systematic review and research questions
Rigorous empirical evidence on the successful usage of learning analytics for supporting and improving students’ learning and success in higher education is lacking for the large-scale adoption of learning analytics (Marzouk et al. 2016). While higher education institutions still lack the organisational, technical, and staff capabilities for the sustainable and effective implementation of learning analytics systems (Ifenthaler 2017; Leitner et al. 2019), only very few empirically-tested learning analytics systems exist (Rienties et al. 2016). Another serious concern related to learning analytics is the ethically responsible and appropriate use of educational data (Scholes 2016; Slade and Prinsloo 2013; West et al. 2016), respecting data protection regulations (e.g., EU-GDPR) and privacy principles of all involved stakeholders (Ifenthaler and Schumacher 2016, 2019; Pardo and Siemens 2014). Another well advanced line of research in learning analytics focuses on the design of dashboards or broader visualisations of information from data analytics for supporting learning and teaching (Park and Jo 2015; Roberts et al. 2017). However, neither research includes a complete and detailed review of existing evidence on how learning analytics may contribute toward study success at higher education institutions.
Therefore, the purpose of this systematic literature review was to identify empirical evidence demonstrating how learning analytics have been successful in facilitating study success in the continuation and completion of students’ learning. In order to guide the systematic review, the following research questions were formulated:
-
1.
What study success factors have been operationalised in relation to learning analytics?
-
2.
What factors from learning analytics systems contribute toward study success?
-
3.
Are there specific learning analytics interventions for supporting study success?
Method
The preparation of the systematic review followed the eight steps proposed by Okoli and Schabram (2010). In order to produce a scientifically rigorous systematic review, all eight steps are essential (Okoli 2015): (1) identity the purpose; (2) draft protocol and train the team; (3) apply practical screen; (4) search for literature; (5) extract data; (6) appraise quality; (7) synthesise studies; (8) write the review.
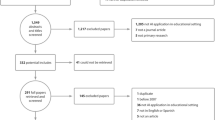
Figure 1 shows the flow diagram of conducting the systematic review. The purpose of the systematic review has been presented above, including three research questions. The research team developed a research protocol, which described the individual steps of conducting the systematic review. In order to validate the research protocol, a training session was conducted which focused on database handling, reviewing, and note-taking techniques. The practical screening followed the previously outlined inclusion criteria in the research protocol, namely (a) studies were situated in the higher education context, (b) were published between January 2013 and December 2018 (2013 marks the rise of learning analytics research publications), (c) were published in English language, (d) had an abstract available, (e) presented either qualitative or quantitative analyses and findings, and (f) were peer-reviewed. Concerning overall consistency, the research team exchanged their findings for critical reflections. The literature search strictly followed the pre-defined research protocol, which included several steps:
-
(a)
Identification of international databases: GoogleScholar, ACM Digital Library, Web of Science, Science Direct, ERIC (Education Resources Information Center), and DBLP (computer science bibliography). The initial search results included peer-reviewed journal articles, peer-reviewed conference papers, and peer-reviewed chapters.
-
(b)
Specific search in relevant scientific peer-reviewed journals following the top 20 ranked educational technology journals in GoogleScholar: Computers & Education, British Journal of Educational Technology, The International Review of Research in Open and Distributed Learning, The Internet and Higher Education, Journal of Educational Technology & Society, Journal of Computer Assisted Learning, Education and Information Technologies, Educational Technology Research and Development, Language Learning & Technology, Interactive Learning Environments, TechTrends, The Turkish Online Journal of Educational Technology, Learning@Scale, Learning, Media and Technology, International Journal of Artificial Intelligence in Education Computer Assisted Language Learning, IEEE Transactions on Learning Technologies International Conference on Technological Ecosystems for Enhancing Multiculturality, Australasian Journal of Educational Technology, as well as three additional pertinent journals—Journal of Learning Analytics, Computers in Human Behavior, and Technology, Knowledge and Learning. In addition, the Proceedings of the International Conference on Learning Analytics And Knowledge were included, as they include peer-reviewed contributions of the learning analytics community.
-
(c)
The searches were conducted using the search terms ‘learning analytics’ in combination with ‘study success’, ‘retention’, ‘dropout prevention’, ‘course completion’, and ‘attrition’ in titles, keywords, abstracts, and full texts. A total of N = 6220 publications were located.
-
(d)
The detailed analysis of all identified publications included the removal of duplicates or publications with irrelevant topics (N = 3057) and an in-depth abstract search (focussing on relevant concepts, e.g., learning analytics in combination with study success factors) resulted in a final set of N = 374 publications.
-
(e)
The full text analysis of the remaining publications focused on the theoretical rigor of the key concepts (i.e., learning analytics, study success factors), substantiality of sampling technique and methodological procedure, and the empirical evidence presented resulted in a final sample of N = 46 key publications for the systematic review (this included step six of conducting systematic reviews, i.e., appraise quality). Copies of all publications were stored and organised in a digital literature database.

Flow diagram of the systematic literature review process
Following the three research questions, relevant information was extracted from the key publications and organised in an annotated table. The research team used a quantitative and qualitative content analysis as well as reflective exchange to extract the findings of the key studies. This synthesis of key publications followed the triangulation approach, as the final studies included quantitative and qualitative studies (Okoli 2015). The final step of conducting the systematic review included the dissemination of the findings through the writing of this paper, which documents the findings and discussion of implications as well as limitations.
Results
Summary of key publications
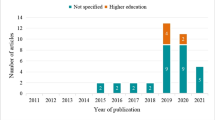
The 46 key publications included in this systematic review were conducted in the USA (n = 13), Australia (n = 5), UK (n = 3), Spain (n = 3), Brazil (n = 3), Ireland (n = 2), Taiwan (n = 2), The Netherlands (n = 2), South Korea (n = 2), China (n = 1), Columbia (n = 1), Czech Republic (n = 1), France (n = 1), Greece (n = 1), India (n = 1), Israel (n = 1), Japan (n = 1), Pakistan (n = 1), Saudi Arabia (n = 1) and Sweden (n = 1). Most articles were published in 2017 (16), followed by eight articles in 2018, 2016 (5), 2015 (6), 2014 (8), and three in 2013. The average sample size of all key studies was M = 15,981.74 (SD = 67,388.72; Min = 29; Max = 447,977).
The key publications utilised data analytics methods, such as binary logistic regression, decision tree analysis, support vector machines, logistic regression and classification systems. Many of the key studies applied several statistical methods in order to determine which one would achieve the most accurate prediction of the intended outcome variable. The main predictions forecasted in the key publications were on course completion, grades to be obtained, and dropout rates. Table 1 provides a summary of the key publications focusing on learning analytics for supporting study success and includes information about the author(s), the country in which the study was conducted, study sample characteristics, measurement variables, the key aim of the study, operationalisation of study success measure, and applied interventions. The research team also evaluated the overall research rigour (categorised as weak; moderate; strong) of each of the key publications with regard to the definition of study success and learning analytics (theoretical rigour), the tested sample, variables and methods (methodological rigour), rigour of findings and implications (see Table 1). The average evaluation of the individual categories resulted in the overall research rigour score. None of the key publications were rated as strong research rigour (11 weak; 35 moderate), mainly because of the missing operationalisation of study success, lack of precise methodological approaches or limited sample size.
Conceptualisation of study success
Study success was the central element in our systematic review and we included only those papers that were centred on supporting study success, as can be observed by our search terms ‘study success’ or ‘course completion’ as positive aspects of increasing study success and ‘attrition’ or ‘dropout’ as negative aspects which require the reduction thereof. Different conceptualisations of study success were provided in the articles, including the more precise descriptions, with positive factors of study success defined, for example, as ‘course completion’ (n = 7) and ‘student retention’ (n = 1) and negative factors utilising terms relating to attrition or dropout, such as ‘student at-risk’ or ‘dropout’ (n = 14), ‘loss of academic status’ (n = 2), and ‘attrition’ (n = 1). Other generalised or more abstract terms indicating study success (or lack thereof) were also utilised, and predicted factors including ‘student performance’ (n = 9), ‘student learner behaviour’ (n = 1), ‘low performance’, ‘under-achieving students’ (n = 4), ‘students’ achievements and failures’ (n = 1), ‘student (dis)engagement and learning outcomes’ (n = 6), ‘success’ (n = 1), ‘student online behaviour’ (n = 1), ‘academic achievement’ (n = 1), ‘correctness of answers’ (n = 1), and ‘grades’ (n = 1).
In the key publications, the above-mentioned study success factors are presented mainly in the keywords, or briefly in the abstract and introduction. The remainder of the articles are focused on utilising different data analytics methods in order to make accurate predictions. Analysis and evaluations are presented accordingly and are finalised with how accurate the algorithms were. Overall, throughout the articles, the publications lack an in-depth discussion on the relevance of the obtained findings in relation to study success factors. In the articles’ implications and conclusions, study success is again, rarely reinstated and discussed. Instead, the focus tends to be on the accuracy of the algorithms.
Factors contributing toward study success
A number of factors have been identified in the key publications as contributing to study success and can be organised in two categories: (1) predictors and (2) visualisation.
Predictors for study success
The application of predictive algorithms forms a significant part of the key publications (see Table 1). One set of predictors is based on data collected through online behaviour, mainly logfiles and trace-data. This includes forum interactions (e.g., posts, replies, length of posts) (Andersson et al. 2016; Cambruzzi et al. 2015; Guerrero-Higueras et al. 2018; Seidel and Kutieleh 2017), engagement with learning artefacts (e.g., ePortfolio, lecture slides, videos, tasks, self-assessments) (Aguiar et al. 2014; Carter et al. 2015; Conijn et al. 2018; Gong et al. 2018; Okubo et al. 2017), and overall interaction with a digital learning environment based on logfiles (Hu et al. 2014; Labarthe et al. 2016). For example, Chai and Gibson (2015) use login frequency, access of materials, submission of assignments, and enrolment data for predicting a student’s attrition risk. Similarly, data from websites or learning management systems (e.g., event-based timestamps) are used in combination with grades to predict students at risk of dropping out (Cohen 2017; Conijn et al. 2017; Elbadrawy et al. 2015; Jo et al. 2014; Manrique et al. 2018; Nespereira et al. 2015; Nguyen et al. 2017; Saqr et al. 2017), with the detailed analysis of clickstream or trace-data also being used to predict student dropout (Whitehill et al. 2017), student retention (Wolff et al. 2013), or student performance (Yang et al. 2017).
As shown in Table 1, another set of data used for predicting study success is based on students’ background information, such as demographics (e.g., age, gender), socio-economic status (e.g., family income, background, expenditure), prior academic experience and performance (Daud et al. 2017; Djulovic and Li 2013; Guarrin 2013). For example, Lacave et al. (2018) use enrolment age, prior choice of subject and information on scholarships in order to predict student dropouts. In addition to demographic variables (Aulck et al. 2017; Sarker 2014), the student’s academic self-concept, academic history and work-related data are used to predict student performance (Mitra and Goldstein 2015), while others use GPA, academic load, and access to counselling (Rogers et al. 2014), the student’s financial background (Thammasiri et al. 2014), or academic performance history (Bydzovska and Popelinsky 2014; Sales et al. 2016; Srilekshmi et al. 2016) as predictors of students at risk.
Other studies focus on data collected through surveys, such as students self-reporting on expected grades (Zimmerman and Johnson 2017), motivation, or academic and technological preparedness (Bukralia et al.2014).
Several predictive algorithms are formed on a multimodal basis (Blikstein and Worsley 2016), i.e., they draw data from various sources, such as logfiles or trace-data (non-reactive data collection), assessments, survey data (reactive data collection), as well as from aggregated information or historical data.
Visualisation for study success
In a number of studies retrieved for the systematic review (see Table 1), it was noted that visualisation was important in supporting study success. Visualisation is realised through optical signals (Arnold and Pistilli 2012) and learning analytics features, which are distinguishing elements for supporting individual learning processes (Few 2013) or aiming to facilitate reflection (Dorodchi et al. 2018). Learning analytics features are implemented on web-based dashboards—customisable control panels displaying data which adapt to the learning process in (near) real time or on a summative basis.
The findings of an experiment conducted by Kim et al. (2016) found that a dashboard can be beneficial for learners of different motivation and achievement levels. For example, students who received dashboard analysis obtained a higher final score than those who did not. However, high academic achievers who received dashboard analysis showed lower satisfaction with the dashboard, i.e., it was less useful for them academically. He et al. (2015) used visualisations for documenting the student’s individual probability of failure, which could be problematic as this information may be wrongly attributed by the learners.
In summary, visualisation for study success is best realised with dashboards including meaningful information about learning tasks and the progress of learning towards specific goals.
Learning analytics interventions for supporting study success
A recent systematic review of 11 publications on the efficacy of learning analytics interventions in higher education documents visual signals and other dashboard features as dominant elements (Larrabee Sønderlund et al. 2018). Beyond these findings, our systematic review adds further insight into interventions for supporting study success (see Table 1). For example, alerts to teachers enable them to give more individual attention to students (Darlington 2017; Dawson et al. 2017; Gkontzis et al. 2018; Lu et al. 2017; Yang et al. 2017). Other interventions focus on facilitating peer-to-peer communication (Cohen 2017; Seidel and Kutieleh 2017), as well as on recommendations for adaptive learning materials, prior knowledge building, reduction of test anxiety, or student–teacher perceptions.
In summary, the key publications only exhibited a few intervention strategies (Cambruzzi et al. 2015; Carroll and White 2017; Casey and Azcona 2017). However, the effects found when various interventions for supporting study success were applied, may be biased, as other variables may contribute to the overall effects identified.
Discussion
Different learning analytics measures, visualisations, and intervention strategies need to be set in place to individualise support services for various learner needs, as reasons for study success vary significantly (Tinto 2017). In addition, distinctive measures, visualisations, and intervention strategies may work in specific contexts for some and not for others (Mah 2016). Whilst learning analytics are mainly implemented as a data-driven method for detecting at-risk students (Chai and Gibson 2015; Okubo et al. 2017; Rogers et al. 2014), higher education institutions need to supply an additional and supplementary support system to encourage and lead these students back onto the track of study success (Viberg et al. 2018). For some students, personal and interactive discussions are necessary to resolve obstacles and barriers to the studies (concerning more complex personal barriers). For other students, perhaps their obstacles were due to simpler barriers, such as the misunderstanding of previous concepts or topics, or missed information due to absence, or requiring more time and effort for completion (Tinto 2005). In such cases, personalised learning paths and encouraging interventions can be the answer to leading these students back onto their learning track (Howell et al. 2018).
Implications
Our systematic review indicates that a wider adoption of learning analytics systems is needed, as well as work towards standardised measures, visualisations, and interventions, which can be integrated into any digital learning environment to reliably predict at-risk students and to provide personalised prevention and intervention strategies. While standards for data models and data collection, such as xAPI (Experience API), exist (Kevan and Ryan 2016), learning analytics research and development need to clearly define standards for reliable and valid measures, informative visualisations, and design guidelines for pedagogically effective learning analytics interventions (Seufert et al. 2019). In particular, personalised learning environments are increasingly in demand and are valued in higher education institutions for creating tailored learning packages optimised for each individual learner based on their personal profile, containing information such as their geo- and socio-demographic backgrounds (Lacave et al. 2018), previous qualifications (Daud et al. 2017), their engagement in the recruitment journey (Berg et al. 2018), activities on websites (Seidel and Kutieleh 2017), and tracking information on their searches (Macfadyen and Dawson 2012).
The key publications of this systematic review indicate the different valid factors that could be applied in learning analytics as being a combination of learners’ background information, behaviour data from digital platforms (e.g., learning management systems, games and simulations), formative and summative assessment data, and information collected through surveys. Hence, measures for learning analytics need to include reactive and non-reactive data collection, i.e., multimodal data for supporting learning, teaching, and study success (Blikstein and Worsley 2016).
A prerequisite for defining such a multimodal or holistic data set for learning analytics is a strong theoretical foundation of learning analytics (Marzouk et al. 2016). Self-regulated learning, affective (motivation and emotion), and social constructivism theories are widely discussed in the context of learning analytics research (Azevedo et al. 2010; Tabuenca et al. 2015). Initial work, which will form the basis for future investigations, has been conducted on how to facilitate educational research by employing learning theories to guide data collection and examine learning analytics (Prieto et al. 2019). Despite the awareness of a stronger theory-informed learning analytics practice, the findings of this systematic review document an obvious weakness in defining key constructs such as study success or retention, and operationalising key factors for reliable and valid measurements. Further, the predominant methodological approach identified in this systematic review on learning analytics and study success is of correlational nature (Wong et al. 2019). Hence, a significant weakness of learning analytics research is the lack of large-scale, longitudinal, and experimental research focusing on how learning analytics impact learning and teaching in higher education. In addition, the identified lack of a clearly defined and empirically tested holistic data set remains a major challenge for learning analytics research to come.
From an instructional design perspective, visualisations, features, and interventions currently being implemented in learning analytics dashboards are of a simplistic nature, i.e., they provide statistics which are less informative for supporting learning processes (He et al. 2015). As documented by Larrabee Sønderlund et al. (2018) and in this systematic review, learning analytics interventions need to enable active learning, such as through adaptive scaffolds or by helping teachers to curate and act on data about their students (Arthars et al. 2019; Darlington 2017; Dawson et al. 2017). This includes the provision of a better understanding of students’ expectations of learning analytics features to support learning processes and warrant study success (Schumacher and Ifenthaler 2018).
Challenges ahead
Fully automated adaptive learning analytics support systems may reduce a learner’s self-regulation and perceived autonomy. Therefore, learning analytics need to provide opportunities for personalisation, i.e., learners may adjust (customise) the information and support provided at any time. For example, a learner may not need support in a topic where she has prior-knowledge and a high interest, but may, on the other hand require scaffolding while working in an unfamiliar domain. At the same time, the learner may want competitive elements (e.g., group comparison of achievement) in some situations, and collaborators to exchange ideas in others.. Other lesser observed instructional design components in learning analytics are the social impact on learning (Buckingham Shum and Ferguson 2012) and the means of collaborative learning (Gašević et al. 2019).
Given the promising opportunities of learning analytics for supporting study success, Leitner et al. (2019) present the challenges likely to be faced in further research, including (1) a shortage of learning analytics leadership at higher education institutions, (2) a shortage of equal engagement among all stakeholders, (3) a shortage of pedagogy-based approaches informing learning analytics practice, (4) a shortage of sufficient professional learning for learning analytics, (5) a shortage of rigorous studies empirically validating the impact of learning analytics, and (6) a shortage of policies specific to learning analytics.
To sum up, more educational data does not always make better educational decisions. Learning analytics have obvious limitations and data collected from various educational sources can have multiple meanings (d’Aquin et al. 2014). As not all educational data is relevant and equivalent, the reliability and validity of data and its accurate and bias-free analysis is critical for the generation of useful summative, real-time or formative, and predictive or prescriptive insights for learning and teaching. While the key publications identified in this systematic review had access to a wide range of data from students and their associated learning interactions and contexts, limited access to educational data (e.g., from distributed networks outside the institution) may generate disadvantages for involved stakeholders (e.g., students, teachers). For example, invalid forecasts may lead to inefficient (or false) decisions for pedagogical interventions (Arthars et al. 2019). In addition, ethical and privacy issues are associated with the use of educational data for learning analytics (Prinsloo and Slade 2015). This implies how personal data is collected and stored as well as the way in which it is analysed and presented to different stakeholders (West et al. 2016). Consequently, higher education institutions need to address ethics and privacy issues linked to learning analytics: They need to define who has access to which data, where and for how long the data will be stored, and which procedures and algorithms should be implemented if further use is to be made of the available educational data and analysis results (Ifenthaler and Schumacher 2019; Ifenthaler and Tracey 2016).
Limitations and recommendations for future research
Systematic reviews are a good way to synthesise findings from quantitative and qualitative research on a topic, but they cannot include results from all available research. The research methodology of this systematic review followed the eight steps suggested by Okoli (2015). The accurate execution of these steps is indispensable for the production of valid findings of a systematic review. However, even if keywords are applied, databases approached, and specific journals searched, some important research studies may still have been neglected. As shown in the initial dataset, although more than 6000 publications were identified, not all qualified to be included in this systematic review. Thus, the systematic review does not reflect all research on learning analytics and study success. In addition, this systematic review only included articles published in the English language. Hence, important findings from articles published in other languages may have been overlooked. However, as learning analytics research matures further, it is expected that meta-analyses will emerge, which may provide further empirical insights, including effect size estimates on how learning analytics impact study success.
Research on learning analytics is fast evolving. Hence, while writing this systematic review, further studies may have been published which could provide additional insights into the impact of learning analytics on study success. Accordingly, a continuing meta discussion of findings is required while the research area matures. Thus, further systematic reviews on learning analytics will help to identify important trends in the literature and suggest avenues for future research.
In order to add more rigour to future systematic reviews, experts in the field of learning analytics may be consulted in addition to standardised screening and search procedures. These experts may suggest studies in progress or publications in press which may inform the research questions accordingly and in a more timely manner. Such a procedure will add another step to the eight steps of conducting systematic reviews suggested by Okoli (2015).
Another issue found in the key publications of this systematic review is the theoretical clarity of the key constructs, such as definitions of study success, student retention, or learning analytics. When clear definitions are missing, operationalisations of these constructs become blurred and their valid measurement becomes impossible. This issue has been documented through the evaluated research rigour (i.e., theoretical rigour, methodological rigour, and rigour of findings and implications) for each of the key publications (11 weak; 35 moderate; 0 strong). Future research in learning analytics needs not only to clearly define the key constructs addressed, but also to adopt the standards of empirical research methodology for producing valid findings (Campbell and Stanley 1963). Moreover, in order to produce generalisable and transferable findings, future learning analytics research requires a stronger methodological focus on large-scale, longitudinal, and experimental research designs.
Finally, empirical evidence from articles which were not eligible in forming the key publications in this systematic review (e.g., due to incomplete work or lack of depth) are available. These studies provide additional supporting evidence as to the ways in which learning analytics can be used to increase study success. A further investigation of these publications would overwhelm the current research group. In order to invite additional researchers, a database including all identified studies and their initial classifications will be created to provide broader access to the findings.
Conclusion
Learning analytics are a socio-technical data-mining and analytic practice in educational contexts. Rigorous large-scale evidence to support the effectiveness of learning analytics in supporting study success is still lacking (Ifenthaler 2017; Ifenthaler et al. 2019). The tested variables, algorithms, and methods can be used as a guide in helping researchers and educators to further improve the design and implementation of learning analytics systems. One suggestion is to leverage existing learning analytics research by designing large-scale, longitudinal, or quasi-experimental studies with well-defined and operationalised constructs, hence connecting learning analytics research with decades of previous research in education. Further documented evidence on learning analytics demonstrates that learning analytics cannot be used as a one-size-fits-all approach, but that it requires precise analysis of institutional and individual characteristics to best facilitate learning processes for study success (Ifenthaler 2020). Also, teachers need to be encouraged to further their educational data literacy—the ethically responsible collection, management, analysis, comprehension, interpretation, and application of data from educational contexts. While further advances in empirical evidence are being achieved, higher education institutions need to address required change management processes which facilitate the adoption of learning analytics, an institution-wide acceptance of learning analytics, as well as the development of rigorous guidelines and policies focusing on data protection and ethics for learning analytics systems.
References
Aguiar, E., Chawla, N., Brockman, J., Ambrose, G., & Goodrich, V. (2014). Engagement vs performance: Using electronic portfolios to predict first semester engineering student retention. In I. Molenaar, X. Ochoa, & S. Dawson (Eds.), Proceedings of the fourth international learning analytics & knowledge conference (pp. 103–112). New York, NY: ACM.
Andersson, U., Arvemo, T., & Gellerstedt, M. (2016). How well can completion of online courses be predicted using binary logistic regression? Paper presented at the Information Systems Research Seminar in Scandinavia, Ljungskile, 07–08–2016.
Arnold, K. E., & Pistilli, M. D. (2012). Course signals at Purdue: Using learning analytics to increase student success. Paper presented at the 2nd International Conference on Learning Analytics and Knowledge, Vancouver, BC, Canada.
Arthars, N., Dollinger, M., Vigentini, L., Liu, D. Y., Kondo, E., & King, D. M. (2019). Empowering teachers to personalize learning support. In D. Ifenthaler, D.-K. Mah, & J. Y.-K. Yau (Eds.), Utilizing learning analytics to support study success (pp. 223–248). Cham: Springer.
Atif, A., Richards, D., Bilgin, A., & Marrone, M. (2013). Learning analytics in higher education: A summary of tools and approaches. In H. Carter, M. Gosper, & J. Hedberg (Eds.), Electric Dreams. Proceedings of ascilite 2013 (pp. 68–72). Sydney, NSW: Ascilite.
Attewell, P. A., Lavin, D. E., Domina, T., & Levey, T. (2006). New evidence on college remediation. The Journal of Higher Education, 77(5), 886–924. https://doi.org/10.1353/jhe.2006.0037.
Aulck, L., Aras, R., Li, L., L’Heureux, C., Lu, P., & West, J. (2017). Stemming the tide: Predicting STEM attrition using student transcript data. Paper presented at the Machine Learning for Education, Halifax, Nova Scotia, Canada.
Azevedo, R., Johnson, A., Chauncey, A., & Burkett, C. (2010). Self-regulated learning with MetaTutor: Advancing the science of learning with metacognitive tools. In M. S. Khine & I. M. Saleh (Eds.), New science of learning (pp. 225–247). New York: Springer.
Baker, R. S., & Siemens, G. (2015). Educational data mining and learning analytics. In R. K. Sawyer (Ed.), The Cambridge handbook of the learning sciences (2nd ed., pp. 253–272). Cambridge, UK: Cambridge University Press.
Bean, J. P., & Metzner, B. S. (1985). A conceptual model of nontraditional undergraduate student attrition. Review of Educational Research, 55(4), 485–540.
Berg, A. M., Branka, J., & Kismihók, G. (2018). Combining learning analytics with job market intelligence to support learning at the workplace. In D. Ifenthaler (Ed.), Digital workplace learning. Bridging formal and informal learning with digital technologies (pp. 129–148). Cham: Springer.
Berland, M., Baker, R. S., & Bilkstein, P. (2014). Educational data mining and learning analytics: Applications to constructionist research. Technology, Knowledge and Learning, 19(1–2), 205–220. https://doi.org/10.1007/s10758-014-9223-7.
Bijsmans, P., & Schakel, A. H. (2018). The impact of attendance on first-year study success in problem-based learning. Higher Education, 76, 865–881. https://doi.org/10.1007/s10734-018-0243-4.
Blikstein, P., & Worsley, M. (2016). Multimodal learning analytics and education data mining: Using computational technologies to measure complex learning tasks. Journal of Learning Analytics, 3(2), 220–238. https://doi.org/10.18608/jla.2016.32.11.
Brahm, T., Jenert, T., & Wagner, D. (2017). The crucial first year: A longitudinal study of students’ motivational development at a Swiss Business School. Higher Education, 73(3), 459–478.
Buckingham Shum, S., & Ferguson, R. (2012). Social learning analytics. Educational Technology & Society, 15(3), 3–26.
Buckingham Shum, S., & McKay, T. A. (2018). Architecting for learning analytics Innovating for sustainable impact. EDUCAUSE Review, 53(2), 25–37.
Bukralia, R., Deokar, A., & Sarnikar, S. (2014). Using academic analytics to predict dropout risk in e-Learning courses. In L. S. Iyer & D. J. Power (Eds.), Reshaping society through analytics, collaboration and decision support (pp. 67–93). Cham: Springer.
Bydzovska, H., & Popelinsky, L. (2014). The influence of social data on student success prediction. Paper presented at the International Database Engineering & Applications Symposium.
Cambruzzi, W., Rigo, S., & Barbosa, J. (2015). Dropout prediction and reduction in distance education courses with the learning analytics. Multi-trail approach. Journal of Computer Science, 21(1), 23–47.
Campbell, D. T., & Stanley, J. C. (1963). Experimental and quasi-experimental designs for research. Boston, MA: Houghton Mifflin Company.
Carroll, P., & White, A. (2017). Identifying patterns of learner behaviour: What Business Statistics students do with learning resources. INFORMS Transactions on Education, 18(1), 1–13.
Carter, A., Hundhausen, C., & Adesope, O. (2015). The normalized programming state model: Predicting student performance in computing courses based on programming behavior. Paper presented at the International Conference on Computing Education Research.
Casey, K., & Azcona, D. (2017). Utilising student activity patterns to predict performance. Journal of Educational Technology in Higher Education, 14(4), 1–15. https://doi.org/10.1186/s41239-017-0044-3.
Chai, K. E. K., & Gibson, D. C. (2015). Predicting the risk of attrition for undergraduate students with time based modelling. In D. G. Sampson, J. M. Spector, D. Ifenthaler, & P. Isaias (Eds.), Proceedings of cognition and exploratory learning in the digital age (pp. 109–116). Maynooth, Ireland: IADIS Press.
Cohen, A. (2017). Analysis of student activity in web-supported courses as a tool for predicting dropout. Educational Technology Research and Development, 65(5), 1–20.
Colvin, C., Rodgers, T., Wade, A., Dawson, S., Gasevic, D., Buckingham Shum, S., et al. (2015). Student retention and learning analytics: A snapshot of Australian practices and a framework for advancement. Canberra, ACT: Australian Government Office for Learning and Teaching.
Conijn, R., Snijders, C., Kleingeld, A., & Matzat, U. (2017). Predicting student performance from LMS data: A comparison of 17 blended courses using Moodle LMS. IEEE Transactions on Learning Technologies, 10(1), 17–29.
Conijn, R., Van den Beemt, A., & Cuijpers, P. (2018). Predicting student performance in a blended MOOC. Journal of Computer Assisted Learning, 34, 615–628. https://doi.org/10.1111/jcal.12270.
d’Aquin, M., Dietze, S., Herder, E., Drachsler, H., & Taibi, D. (2014). Using linked data in learning analytics. eLearning Papers, 36, 1–9.
Darlington, W. (2017). Predicting underperformance from students in upper level engineering courses. Rochester: Rochester Institute of Technology.
Daud, A., Aljohani, N., Abbasi, R., Lytras, M., Abbas, F., & Alowibdi, J. (2017). Predicting student performance using advanced learning analytics. Paper presented at the Conference on World Wide Web Companion.
Dawson, S., Jovanović, J., Gašević, D., & Pardo, A. (2017). From prediction to impact: Evaluation of a learning analytics retention program. In I. Molenaar, X. Ochoa, & S. Dawson (Eds.), Proceedings of the seventh international learning analytics & knowledge conference (pp. 474–478). New York, NY: ACM.
Djulovic, A., & Li, D. (2013). Towards freshman retention prediction: A comparative study. International Journal of Information and Educational Technology, 3(5), 494–500.
Dorodchi, M., Benedict, A., Desai, D., Mahzoon, M., Macneil, S., & Dehbozorgi, N. (2018). Design and implementation of an activity-based introductory Computer Science Course (CS1) with periodic reflections validated by learning analytics. Paper presented at the IEEE Frontiers In Education.
Elbadrawy, A., Studham, R., & Karypis, G. (2015). Collaborative multi-regression models for predicting students’ performance in course activities. In I. Molenaar, X. Ochoa, & S. Dawson (Eds.), Proceedings of the fifth international learning analytics & knowledge conference (pp. 103–107). New York, NY: ACM.
Ferguson, R., Brasher, A., Clow, D., Cooper, A., Hillaire, G., Mittelmeier, J., et al. (2016). Research evidence on the use of learning analytics - Implications for education policy. Retrieved from https://publications.jrc.ec.europa.eu/repository/bitstream/JRC104031/lfna28294enn.pdf.
Few, S. (2013). Information dashboard design: Displaying data for at-a-glance monitoring. Burlingame, CA: Analytics Press.
Gašević, D., Dawson, S., Rogers, T., & Gašević, D. (2016). Learning analytics should not promote one size fits all: The effects of instructional conditions in predicting academic success. Internet and Higher Education, 28, 68–84.
Gašević, D., Dawson, S., & Siemens, G. (2015). Let’s not forget: Learning analytics are about learning. TechTrends, 59(1), 64–71. https://doi.org/10.1007/s11528-014-0822-x.
Gašević, D., Joksimović, S., Eagan, B. R., & Shaffer, D. W. (2019). SENS: Network analytics to combine social and cognitive perspectives of collaborative learning. Computers in Human Behavior, 92, 562–577. https://doi.org/10.1016/j.chb.2018.07.003.
Gkontzis, A., Kotsiantis, S., Tsoni, R., & Verykios, V. (2018). An effective LA approach to predict student achievement. Paper presented at the Pan-Hellenic Conference.
Glick, D., Cohen, A., Festinger, E., Xu, D., Li, Q., & Warschauer, M. (2019). Predicting success, preventing failure. In D. Ifenthaler, D.-K. Mah, & J. Y.-K. Yau (Eds.), Utilizing learning analytics to support study success (pp. 249–273). Cham: Springer.
Gong, L., Liu, Y., & Zhao, W. (2018). Using learning analytics to promote student engagement and achievement in blended learning: An empirical study. Paper presented at the International Conference on E-Education, E-Business and E-Technology.
Guarrin, C. (2013). Data mining model to predict academic performance at the Universidad Nacional de Colombia. Bogota, Columbia: University of Colombia.
Guerrero-Higueras, A. M., DeCastro-Garci, N., Matellan, V., & Conde-Gonzalez, M. (2018). Predictive models of academic success: A case study with version control systems. Paper presented at the International Conference on Technological Ecosystems for Enhancing Multiculturality.
He, J., Bailey, J., Rubinstein, B., & Zhang, R. (2015). Identifying at-risk students in Massive Open Online Courses. Paper presented at the International Conference on Artificial Intelligence.
Heublein, U. (2014). Student drop-out from German higher education institutions. European Journal of Education, 49(4), 497–513.
Howell, J. A., Roberts, L. D., Seaman, K., & Gibson, D. C. (2018). Are we on our way to becoming a “helicopter university”? Academics’ views on learning analytics. Technology, Knowledge and Learning, 23(1), 1–20. https://doi.org/10.1007/s10758-017-9329-9.
Hu, Y., Lo, C., & Shih, S. (2014). Developing early warning systems to predict students’ online learning performance. Computers in Human Behavior, 36, 469–478.
Ifenthaler, D. (2015). Learning analytics. In J. M. Spector (Ed.), The SAGE encyclopedia of educational technology (Vol. 2, pp. 447–451). Thousand Oaks, CA: Sage.
Ifenthaler, D. (2017). Are higher education institutions prepared for learning analytics? TechTrends, 61(4), 366–371. https://doi.org/10.1007/s11528-016-0154-0.
Ifenthaler, D. (2020). Change management for learning analytics. In N. Pinkwart & S. Liu (Eds.), Artificial intelligence supported educational technologies (pp. 261–272). Cham: Springer.
Ifenthaler, D., Mah, D.-K., & Yau, J. Y.-K. (2019). Utilising learning analytics for study success. Reflections on current empirical findings. In D. Ifenthaler, J. Y.-K. Yau, & D.-K. Mah (Eds.), Utilizing learning analytics to support study success (pp. 27–36). Cham: Springer.
Ifenthaler, D., & Schumacher, C. (2016). Student perceptions of privacy principles for learning analytics. Educational Technology Research and Development, 64(5), 923–938. https://doi.org/10.1007/s11423-016-9477-y.
Ifenthaler, D., & Schumacher, C. (2019). Releasing personal information within learning analytics systems. In D. G. Sampson, J. M. Spector, D. Ifenthaler, P. Isaias, & S. Sergis (Eds.), Learning technologies for transforming teaching, learning and assessment at large scale (pp. 3–18). Cham: Springer.
Ifenthaler, D., & Tracey, M. W. (2016). Exploring the relationship of ethics and privacy in learning analytics and design: Implications for the field of educational technology. Educational Technology Research and Development, 64(5), 877–880. https://doi.org/10.1007/s11423-016-9480-3.
In der Smitten, S., & Heublein, U. (2013). Qualitätsmanagement zur Vorbeugung von Studienabbrüchen. Zeitschrift für Hochschulentwicklung, 8(2), 98–109.
Jo, I., Yu, T., Lee, H., & Kim, Y. (2014). Relations between student online learning behavior and academic achievement in higher education: A learning analytics approach. In G. Chen, V. Kumar, R. Huang, & S. Kong (Eds.), Emerging issues in smart learning (pp. 275–287). Berlin: Springer.
Kevan, J. M., & Ryan, P. R. (2016). Experience API: Flexible, decentralized and activity-centric data collection. Technology, Knowledge and Learning, 21(1), 143–149. https://doi.org/10.1007/s10758-015-9260-x.
Kilis, S., & Gulbahar, Y. (2016). Learning analytics in distance education: A systematic literature review. Paper presented at the 9th European Distance and E-learning Network (EDEN) Research Workshop, Oldenburg, Germany.
Kim, J., Jo, I.-H., & Park, Y. (2016). Effects of learning analytics dashboard: Analyzing the relations among dashboard utilization, satisfaction, and learning achievement. Asia Pacific Education Review, 17(1), 13–24.
Labarthe, H., Bouchet, F., Bachelet, R., & Yacef, K. (2016). Does a peer recommender foster students’ engagement in MOOCs? Paper presented at the International Conference on Educational Data Mining.
Lacave, C., Molina, A., & Cruz-Lemus, J. (2018). Learning analytics to identify dropout factors of Computer Science studies through Bayesian networks. Behaviour & Information Technology, 37(10–11), 993–1007. https://doi.org/10.1080/0144929X.2018.1485053.
Larrabee Sønderlund, A., Hughes, E., & Smith, J. (2018). The efficacy of learning analytics interventions in higher education: A systematic review. British Journal of Educational Technology, 50(5), 2594–2618. https://doi.org/10.1111/bjet.12720.
Larsen, M. S., Kornbeck, K. P., Larsen, M. B., Kristensen, R. M., & Sommersel, H. (2013). Dropout phenomena at universities: What is dropout? Why does dropout occur? What can be done by the universities to prevent or reduce it? A systematic review. Copenhagen: Danish Clearinghouse for Educational Research.
Leitner, P., Ebner, M., & Ebner, M. (2019). Learning analytics challenges to overcome in higher education institutions. In D. Ifenthaler, J. Y.-K. Yau, & D.-K. Mah (Eds.), Utilizing learning analytics to support study success (pp. 91–104). Cham: Springer.
Lodge, J. M., & Corrin, L. (2017). What data and analytics can and do say about effective learning. npj Science of Learning, 2(1), 5. https://doi.org/10.1038/s41539-017-0006-5.
Long, P. D., & Siemens, G. (2011). Penetrating the fog: Analytics in learning and education. EDUCAUSE Review, 46(5), 31–40.
Lu, O., Huang, J., Huang, A., & Yang, S. (2017). Applying learning analytics for improving students’ engagement and learning outcomes in an MOOCs enabled collaborative programming course. Interactive Learning Environments, 25(2), 220–234.
Macfadyen, L., & Dawson, S. (2012). Numbers are not enough. Why e-Learning analytics failed to inform an institutional strategic plan. Educational Technology & Society, 15(3), 149–163.
Mah, D.-K. (2016). Learning analytics and digital badges: Potential impact on student retention in higher education. Technology, Knowledge and Learning, 21(3), 285–305. https://doi.org/10.1007/s10758-016-9286-8.
Manrique, R., Nunes, B., Marino, O., Casanova, M., & Nurmikko-Fuller, T. (2018). An analysis of student representation, representative features and classification algorithms to predict degree dropout. Paper presented at the International Conference on Learning Analytics and Knowledge.
Marzouk, Z., Rakovic, M., Liaqat, A., Vytasek, J., Samadi, D., Stewart-Alonso, J., et al. (2016). What if learning analytics were based on learning science? Australasian Journal of Educational Technology, 32(6), 1–18. https://doi.org/10.14742/ajet.3058.
Mitra, S., & Goldstein, Z. (2015). Designing early detection and intervention techniques via predictive statistical models—A case study on improving student performance in a business statistics course. Communications in Statistics: Case Studies, Data Analysis and Applications, 1, 9–21.
Morosanu, L., Handley, K., & O'Donovan, B. (2010). Seeking support: Researching first-year students’ experiences of coping with academic life. Higher Education Research & Development, 29(6), 665–678. https://doi.org/10.1080/07294360.2010.487200.
Nespereira, C., Vilas, A., & Redondo, R. (2015). Am I failing this course?: Risk prediction using e-learning data. Paper presented at the Conference on Technological Ecosystems for enhancing Multiculturality.
Nguyen, Q., Rienties, B., Toetenel, L., Ferguson, R., & Whitelock, D. (2017). Examining the designs of computer-based assessment and its impact on student engagement, satisfaction, and pass rates. Computers in Human Behavior, 76, 703–714.
Nouira, A., Cheniti-Belcadhi, L., & Braham, R. (2019). An ontology-based framework of assessment analytics for massive learning. Computer Applications in Engineering Education. https://doi.org/10.1002/cae.22155.
OECD. (2019). Education at a glance 2019: OECD indicators. Paris: OECD Publishing.
Okoli, C. (2015). A guide to conducting a standalone systematic literature review. Communications of the Association for Information Systems Research, 37(43), 879–910. https://doi.org/10.17705/1CAIS.03743.
Okoli, C., & Schabram, K. (2010). A guide to conducting a systematic literature review of information systems research. Sprouts: Workind Paper on Information Systems, 10(26), 1–49.
Okubo, F., Yamashita, T., Shimada, A., & Ogata, H. (2017). A neural network approach for students' performance prediction. Paper presented at the International Conference on Learning Analytics and Knowledge.
Padgett, R. D., Keup, J. R., & Pascarella, E. T. (2013). The impact of first- year seminars on college students’ life-long learning orientations. Journal of Student Affairs Research and Practice, 50(2), 133–151.
Papamitsiou, Z., & Economides, A. (2014). Learning analytics and educational data mining in practice: A systematic literature review of empirical evidence. Educational Technology & Society, 17(4), 49–64.
Pardo, A., & Siemens, G. (2014). Ethical and privacy principles for learning analytics. British Journal of Educational Technology, 45(3), 438–450. https://doi.org/10.1111/bjet.12152.
Park, Y., & Jo, I.-H. (2015). Development of the learning analytics dashboard to support students' learning performance. Journal of Universal Computer Science, 21(1), 110–133.
Pistilli, M. D., & Arnold, K. E. (2010). Purdue signals: Mining real-time academic data to enhance student success. About Campus: Enriching the student learning experience, 15(3), 22–24.
Prieto, L. P., Rodríguez-Triana, M. J., Martínez-Maldonado, R., Dimitriadis, Y., & Gašević, D. (2019). Orchestrating learning analytics (OrLA): Supporting inter-stakeholder communication about adoption of learning analytics at the classroom level. Australasian Journal of Educational Technology, 35(4), 14–33. https://doi.org/10.14742/ajet.4314.
Prinsloo, P., & Slade, S. (2015). Student privacy self-management: Implications for learning analytics. Paper presented at the Fifth International Conference on Learning Analytics and Knowledge, New York, NY, USA.
Remedios, L., Clarke, D., & Hawthorne, L. (2008). The silent participant in small group collaborative learning contexts. Active Learning in Higher Education, 9(3), 201–216.
Rienties, B., Boroowa, A., Cross, S., Kubiak, C., Mayles, K., & Murphy, S. (2016). Analytics4Action evaluation framework: A review of evidence-based learning analytics interventions at the Open University UK. Journal of Interactive Media in Education, 2(1), 1–11.
Roberts, L. D., Howell, J. A., & Seaman, K. (2017). Give me a customizable dashboard: Personalized learning analytics dashboards in higher education. Technology, Knowledge and Learning, 22(3), 317–333. https://doi.org/10.1007/s10758-017-9316-1.
Rogers, T., Colvin, C., & Chiera, B. (2014). Modest analytics: using the index method to identify students at risk of failure. In A. Pardo & S. D. Teasley (Eds.), Proceedings of the fourth international conference on learning analytics and knowledge (pp. 118–122). New York, NY: ACM.
Rovai, A. P. (2003). In search of higher persistence rates in distance education online programs. Internet and Higher Education, 6, 1–16.
Sales, A., Balby, L., & Cajueiro, A. (2016). Exploiting academic records for predicting student drop out: A case study in Brazilian higher education. Journal of Information and Data Management, 7(2), 166–181.
Saqr, M., Fors, U., & Tedre, M. (2017). How learning analytics can early predict under-achieving students in a blended medical education course. Medical Teacher, 39(7), 757–767.
Sarker, F. (2014). Linked data technologies to support higher education challenges: Student retention, progression and completion. Dissertation University of Southampton.
Sarrico, C. S. (2018). Completion and retention in higher education. In P. Nuno Teixeira & J. Shin (Eds.), Encyclopedia of international higher education systems and institutions. Dordrecht: Springer.
Schmied, V., & Hänze, M. (2015). The effectiveness of study skills courses: Do they increase general study competences? Zeitschrift für Hochschulentwicklung, 10(4), 176–187.
Scholes, V. (2016). The ethics of using learning analytics to categorize students on risk. Educational Technology Research and Development, 64(5), 939–955. https://doi.org/10.1007/s11423-016-9458-1.
Schumacher, C., & Ifenthaler, D. (2018). Features students really expect from learning analytics. Computers in Human Behavior, 78, 397–407. https://doi.org/10.1016/j.chb.2017.06.030.
Sclater, N., Peasgood, A., & Mullan, J. (2016). Learning analytics in higher education: A review of UK and international practice. Bristol: JISC.
Seidel, E., & Kutieleh, S. (2017). Using predictive analytics to target and improve first year student attrition. Australasian Journal of Educational Technology, 61(2), 200–218.
Sergis, S., & Sampson, D. G. (2016). School analytics: A framework for supporting school complexity leadership. In J. M. Spector, D. Ifenthaler, D. G. Sampson, & P. Isaias (Eds.), Competencies in teaching, learning and educational leadership in the digital age (pp. 79–122). Cham: Springer.
Sergis, S., & Sampson, D. G. (2017). Teaching and learning analytics to support teacher inquiry: A systematic literature review. In A. Peña-Ayala (Ed.), Learning analytics: Fundaments, applications, and trends (pp. 25–63). Cham: Springer.
Seufert, S., Meier, C., Soellner, M., & Rietsche, R. (2019). A pedagogical perspective on big data and learning analytics: A conceptual model for digital learning support. Technology, Knowledge and Learning, 24(4), 599–619. https://doi.org/10.1007/s10758-019-09399-5.
Slade, S., & Prinsloo, P. (2013). Learning analytics: Ethical issues and dilemmas. American Behavioral Scientist, 57(10), 1510–1529. https://doi.org/10.1177/0002764213479366.
Srilekshmi, M., Sindhumol, S., Chatterjee, S., & Bijani, K. (2016). Learning analytics to identify students at-risk in MOOCs Paper presented at the International Conference on Technology for Education.
Suchithra, R., Vaidhehi, V., & Iyer, N. E. (2015). survey of learning analytics based on purpose and techniques for improving student performance. International Journal of Computer Applications, 111(1), 22–26.
Tabuenca, B., Kalz, M., Drachsler, H., & Specht, M. (2015). Time will tell: The role of mobile learning analytics in self-regulated learning. Computers & Education, 89, 53–74.
Thammasiri, D., Delen, D., Meesad, P., & Kasap, N. (2014). A critical assessment of imbalanced class distribution problem: The case of predicting freshmen student attrition. Expert Systems with Applications, 41(2), 321–330.
Thomas, L. (2002). Student retention in higher education: The role of institutional habitus. Journal of Education Policy, 17(4), 423–442. https://doi.org/10.1080/02680930210140257.
Tinto, V. (1982). Limits of theory and practice in student attrition. The Journal of Higher Education, 53(6), 687–700.
Tinto, V. (2005). Reflections on student retention and persistence: Moving to a theory of institutional action on behalf of student success. Studies in Learning, Evaluation, Innovation and Developmental Psychology, 2(3), 89–97.
Tinto, V. (2017). Through the eyes of students. Journal of College Student Retention: Research, Theory and Practice, 19(3), 254–269.
Tsai, Y.-S., Moreno-Marcos, P. M., Jivet, I., Scheffel, M., Tammets, K., Kollom, K., et al. (2018). The SHEILA framework: Informing institutional strategies and policy processes of learning analytics. Journal of Learning Analytics, 5(3), 5–20. https://doi.org/10.18608/jla.2018.53.2.
Veenman, M. V. J. (2013). Assessing metacognitive skills in computerized learning environments. In R. Azevedo & V. Aleven (Eds.), Onternational handbook of metacognition and learning technologies (pp. 157–168). New York: Springer.
Viberg, O., Hatakka, M., Bälter, O., & Mavroudi, A. (2018). The current landscape of learning analytics in higher education. Computers in Human Behavior, 89, 98–110. https://doi.org/10.1016/j.chb.2018.07.027.
West, D., Huijser, H., & Heath, D. (2016). Putting an ethical lens on learning analytics. Educational Technology Research and Development, 64(5), 903–922. https://doi.org/10.1007/s11423-016-9464-3.
Whitehill, J., Mohan, K., Seaton, D., Rosen, Y., & Tingley, D. (2017). MOOC dropout prediction: how to measure accuracy? Paper presented at the ACM Conference on Learning @ Scale.
Willcoxson, L., Cotter, J., & Joy, S. (2011). Beyond the first-year experience: The impact on attrition of student experiences throughout undergraduate degree studies in six diverse universities. Studies in Higher Education, 36(3), 331–352.
Wolff, A., Zdrahal, Z., Andriy, N., & Pantucek, M. (2013). Improving retention: Predicting at-risk students by analysing clicking behaviour in a virtual learning environment. In I. Molenaar, X. Ochoa, & S. Dawson (Eds.), Proceedings of the third international learning analytics & knowledge conference (pp. 145–149). New York, NY: ACM.
Wong, J., Baars, M., de Koning, B. B., van der Zee, T., Davis, D., Khalil, M., et al. (2019). Educational theories and learning analytics: From data to knowledge. In D. Ifenthaler, J. Y.-K. Yau, & D.-K. Mah (Eds.), Utilizing learning analytics to support study success (pp. 3–25). Cham: Springer.
Yang, T., Brinton, C., Wong, C., & Chiang, M. (2017). Behavior-based grade prediction for MOOCs via time series neural networks. IEEE Journal of Selected Topics in Signal Processing, 11(5), 716–728.
Yorke, M., & Longden, B. (2008). The first-year experience of higher education in the UK. New York: The Higher Education Academy.
Zimmerman, W., & Johnson, G. (2017). Exploring factors related to completion of an online undergraduate-level introductory statistics course. Online Learning, 21(3), 19–205.
Acknowledgements
Open Access funding provided by Projekt DEAL. The authors acknowledge the financial support by the Federal Ministry of Education and Research of Germany (BMBF, Project Number 16DHL1038).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
All the authors declared that they have no conflict of interest.
Ethical approval
All procedures performed in studies involving human participants were in accordance with the ethical standards of the institutional and/or national research committee and with the 1964 Helsinki declaration and its later amendments or comparable ethical standards.
Informed consent
Informed consent was obtained from all individual participants included in the study. Additional informed consent was obtained from all individual participants for whom identifying information is included in this article.
Research involving human and animal rights
This article does not contain any studies with animals performed by any of the authors.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Ifenthaler, D., Yau, J.YK. Utilising learning analytics to support study success in higher education: a systematic review. Education Tech Research Dev 68, 1961–1990 (2020). https://doi.org/10.1007/s11423-020-09788-z
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11423-020-09788-z