
Abstract
Training deep learning model is a time-consuming job since it usually uses a large amount of data. To reduce the training time, most practitioners train the models in a GPU cluster environment in a distributed way. The synchronous stochastic gradient descent, which is one of the widely used distributed training algorithms, has fast convergence rate with the use of multiple GPU workers; but its speed is tied to the slowest worker, i.e., straggler. In a heterogeneous environment, a static straggler, which has not been mainly focused before, has more impact on the performance than randomly occurring straggler. However, most existing studies for straggler mitigation usually consider a homogeneous environment, so their approaches are limited in practice. In this paper, we scrutinize the straggler problem under heterogeneous environment and define static and dynamic straggler from empirical results. Based on this, we propose a novel approach called batch orchestration algorithm (BOA) for straggler mitigation. It adaptively balances the amount of mini-batch data according to the speed of workers. Therefore, BOA can mitigate both static and dynamic straggler in a modern GPU cluster. BOA uses a Min–Max Integer programming to find the optimal mini-batch size, with the hardware-agnostic performance models. For verification, several experiments are conducted on a cluster having up to six GPUs with three types: GTX 1080, GTX 1060 and Quadro M2000. The results show BOA mitigates both types of stragglers and accelerates the training speed with synchronous SGD compared to other straggler mitigation method.








Similar content being viewed by others
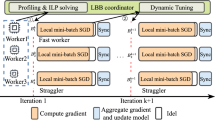


References
Abadi M, Barham P, Chen J, Chen Z, Davis A, Dean J, Devin M, Ghemawat S, Irving G, Isard M, Kudlur M, Levenberg J, Monga R, Moore S, Murray DG, Steiner B, Tucker P, Vasudevan V, Warden P, Wicke M, Yu Y, Zheng X (2016) Tensorflow: a system for large-scale machine learning. In: Proceedings of the 12th USENIX Conference on Operating Systems Design and Implementation, OSDI’16, Berkeley, CA, USA. USENIX Association, pp 265–283
Boyd S, Mattingley J (2007) Branch and bound methods. Notes for EE364b, Stanford University, pp 2006–2007
Chen J, Pan X, Monga R, Bengio S, Jozefowicz R (2016) Revisiting distributed synchronous SGD. arXiv preprint arXiv:1604.00981
Chetlur S, Woolley C, Vandermersch P, Cohen J, Tran J, Catanzaro B, Shelhamer E (2014) cudnn: efficient primitives for deep learning. arXiv preprint arXiv:1410.0759
Coates A, Huval B, Wang T, Wu D, Catanzaro B, Andrew N (2013) Deep learning with COTS HPC systems. In: International Conference on Machine Learning, pp 1337–1345
Dean J, Corrado G, Monga R, Chen K, Devin M, Mao M, Senior A, Tucker P, Yang K, Le QV et al (2012) Large scale distributed deep networks. In: Advances in neural information processing systems, pp 1223–1231
Diamond S, Boyd S (2016) CVXPY: a python-embedded modeling language for convex optimization. J Mach Learn Res 17(83):1–5
Ferdinand N, Gharachorloo B, Draper SC (2017) Anytime exploitation of stragglers in synchronous stochastic gradient descent. In: 2017 16th IEEE International Conference on Machine Learning and Applications (ICMLA), pp 141–146
Google. grpc
Goyal P, Dollár P, Girshick R, Noordhuis P, Wesolowski L, Kyrola A, Tulloch A, Jia Y, He K (2017) Accurate, large minibatch SGD: training imagenet in 1 hour. arXiv preprint arXiv:1706.02677
Harlap A, Cui H, Dai W, Wei J, Ganger GR, Gibbons PB, Gibson GA, Xing EP (2016) Addressing the straggler problem for iterative convergent parallel ML. In: Proceedings of the Seventh ACM Symposium on Cloud Computing, SoCC’16, New York, NY, USA. ACM, pp 98–111
He K, Zhang X, Ren S, Sun J (2016) Deep residual learning for image recognition. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp 770–778
Iandola FN, Moskewicz MW, Ashraf K, Keutzer K (2016) Firecaffe: near-linear acceleration of deep neural network training on compute clusters. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp 2592–2600
Jeon M, Venkataraman S, Qian J, Phanishayee A, Xiao W, Yang F (2018) Multi-tenant GPU clusters for deep learning workloads: analysis and implications. Technical report
Jiang J, Cui B, Zhang C, Yu L (2017) Heterogeneity-aware distributed parameter servers. In: Proceedings of the 2017 ACM International Conference on Management of Data, SIGMOD’17, New York, NY, USA. ACM, pp 463–478
Krizhevsky A, Hinton G (2009) Learning multiple layers of features from tiny images. Technical report, Citeseer
Krizhevsky A, Sutskever I, Hinton GE (2012) Imagenet classification with deep convolutional neural networks. In: Advances in neural information processing systems, pp 1097–1105
LeCun Y, Bengio Y, Hinton G (2015) Deep learning. Nature 521(7553):436
LeCun Y, Bottou L, Bengio Y, Haffner P (1998) Gradient-based learning applied to document recognition. Proc IEEE 86(11):2278–2324
Merkel D (2014) Docker: lightweight linux containers for consistent development and deployment. Linux J 2014(239):2
Robbins H, Monro S (1951) A stochastic approximation method. The annals of mathematical statistics, pp 400–407
Tandon R, Lei Q, Dimakis AG, Karampatziakis N (2017) Gradient coding: avoiding stragglers in distributed learning. In: Precup D, Teh YW (eds) Proceedings of the 34th International Conference on Machine Learning, volume 70 of Proceedings of Machine Learning Research, PMLR. International Convention Centre, Sydney, Australia, 06–11 Aug 2017, pp 3368–3376
Yan F, Ruwase O, He Y, Chilimbi T (2015) Performance modeling and scalability optimization of distributed deep learning systems. In: Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. ACM, pp 1355–1364
Yang E, Kim S, Kim T, Jeon M, Park S, Youn C (2018) An adaptive batch-orchestration algorithm for the heterogeneous GPU cluster environment in distributed deep learning system. In: 2018 IEEE International Conference on Big Data and Smart Computing (BigComp), pp 725–728
Zhang C, Ré C (2014) Dimmwitted: a study of main-memory statistical analytics. Proc VLDB Endow 7(12):1283–1294
Zinkevich M, Weimer M, Li L, Smola AJ (2010) Parallelized stochastic gradient descent. In: Advances in neural information processing systems, pp 2595–2603
Acknowledgements
This research was supported by the National Research Council of Science & Technology (NST) grant by the Korea government (MSIT) (No. CAP-17-03-KISTI).
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Yang, E., Kang, DK. & Youn, CH. BOA: batch orchestration algorithm for straggler mitigation of distributed DL training in heterogeneous GPU cluster. J Supercomput 76, 47–67 (2020). https://doi.org/10.1007/s11227-019-02845-2
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11227-019-02845-2