
Abstract
The question of how the probabilistic opinions of different individuals should be aggregated to form a group opinion is controversial. But one assumption seems to be pretty much common ground: for a group of Bayesians, the representation of group opinion should itself be a unique probability distribution (Madansky [44]; Lehrer and Wagner [34]; McConway Journal of the American Statistical Association, 76(374), 410–414, [45]; Bordley Management Science, 28(10), 1137–1148, [5]; Genest et al. The Annals of Statistics, 487–501, [21]; Genest and Zidek Statistical Science, 114–135, [23]; Mongin Journal of Economic Theory, 66(2), 313–351, [46]; Clemen and Winkler Risk Analysis, 19(2), 187–203, [7]; Dietrich and List [14]; Herzberg Theory and Decision, 1–19, [28]). We argue that this assumption is not always in order. We show how to extend the canonical mathematical framework for pooling to cover pooling with imprecise probabilities (IP) by employing set-valued pooling functions and generalizing common pooling axioms accordingly. As a proof of concept, we then show that one IP construction satisfies a number of central pooling axioms that are not jointly satisfied by any of the standard pooling recipes on pain of triviality. Following Levi (Synthese, 62(1), 3–11, [39]), we also argue that IP models admit of a much better philosophical motivation as a model of rational consensus.
Similar content being viewed by others

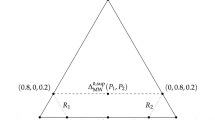
Notes
Here we use IP as a general term, abstracting from the important distinction Isaac Levi makes between what he calls imprecise and indeterminate probability, or what Walley calls the Bayesian sensitivity analysis and direct interpretations, respectively. Roughly speaking, according to the first interpretation, while an agent is normatively committed to or descriptively in a state of numerically precise judgments of credal probability, these precise judgments may not be precisely elicited or introspected. On the second interpretation, imprecision is a feature of the credal state itself and is not attributable to imperfect elicitation or introspection. It is possible, of course, for a credal state to be imprecise in both senses, that is, an indeterminate credal state could be incompletely elicited.
For completeness, we include the probability axioms. A probability function is a mapping \(\boldsymbol {p}: \mathcal {A} \to \mathbb {R}\) that satisfies the following conditions:
-
(i)
p(A)≥0 for any \(A \in \mathcal {A}\);
-
(ii)
p(Ω)=1;
-
(iii)
p(A∪B) = p(A) + p(B) for any \(A, B \in \mathcal {A}\) such that A∩B = ∅.
If, in addition, \(\mathcal {A}\) is a σ-algebra and p satisfies the following condition, p is called countably additive:
-
(iv)
If \({\{A_{n}\}}_{n=1}^{\infty } \subseteq \mathcal {A}\) is a collection of pairwise disjoint events, then \(\boldsymbol {p}({\bigcup }_{n=1}^{\infty } A_{n})= {\sum }_{n=1}^{\infty } \boldsymbol {p}(A_{n})\).
In this paper, we assume countable additivity for convenience, not because we take it to be rationally mandatory.
-
(i)
\(\mathcal {A}^{\prime }\) is a boolean subalgebra of \(\mathcal {A}\) if \(\mathcal {A}^{\prime } \subseteq \mathcal {A}\) and \(\mathcal {A}^{\prime }\), with the distinguished elements and operations of \(\mathcal {A}\), is a boolean algebra. That is, the operations must be the restrictions of the operations of the whole algebra; being a subset that is a boolean algebra is not sufficient for being a subalgebra of \(\mathcal {A}\) [26].
An unweighted geometric pool of n numerical values is given by \(\sqrt [n]{x_{1}{\cdots } x_{n}} = x_{1}^{\frac {1}{n}}{\cdots } x_{n}^{\frac {1}{n}}\).
Rather than assuming regularity or that the algebra contains the elements of Ω, we could make the weaker restriction to the domain of profiles of pmfs such that there is some ω∈Ω for which p i (ω)>0 for all i=1,…,n. And pmfs allow us to obtain measures defined on general algebras on Ω.
We include a proof of the observation because we appeal to it several times in the other proofs, because it is a simple special case (but all we need) of a more general result concerning convexity [53], and because some readers may not have a conceptual handle on the property.
This binary case of irrelevance can be generalized to non-binary partitions. Let A 1,…,A k be a partition of Ω. In Levi’s setup, a question is represented as a partion, each element of which is a potential answer. Information B is pairwise irrelevant to A 1,…,A k if B is irrelevant to each cell of the partition.
Pedersen and Wheeler show how logically distinct independence concepts are teased apart in the context of imprecise probabilities. They write, “there are several distinct concepts of probabilistic independence and [...] they only become extensionally equivalent within a standard, numerically determinate probability model. This means that some sound principles of reasoning about probabilistic independence within determinate probability models are invalid within imprecise probability models” [50, p. 1307]. So IP provides a more subtle setting in which to investigate independence concepts.
We thank the referee for suggesting that we include a result along these lines.
We suspect that Nau is not targeting consensus because his models of pooling involve game-theoretic bargaining scenarios pitting the opinions to be aggregated against each other.
The problem being raised is similar to one in the literature on AGM belief revision. The principle of categorical matching requires that the output of a belief revision operator be of the same format as the input. Otherwise, the account of belief revision, constructed for a certain input format, is silent about iterated belief revision [18]. In the case of convex IP pooling functions, dynamics of pooling are defined so long as we are never pooling sets of probabilities.
References
Aczél, J. (1948). On mean values. Bulletin of the American Mathematical Society, 54(4), 392–400.
Aczél, J., & Oser, H. (2006). Lectures on functional equations and their applications. Courier Corporation.
Arló-Costa, H., & Helzner, J. (2010). Ambiguity aversion: the explanatory power of indeterminate probabilities. Synthese, 172(1), 37–55.
Bacharach, M. (1972). Scientific disagreement. Unpublished manuscript.
Bordley, R.F. (1982). A multiplicative formula for aggregating probability assessments. Management Science, 28(10), 1137–1148.
Bradley, S. (2014). Imprecise probabilities, In Zalta, E.N. (Ed.), The Stanford Encyclopedia of Philosophy (Winter 2014 ed.)
Clemen, R.T., & Winkler, R.L. (1999). Combining probability distributions from experts in risk analysis. Risk Analysis, 19(2), 187–203.
Cozman, F. (1998). Irrelevance and independence relations in quasi-bayesian networks, Proceedings of the fourteenth conference on uncertainty in artificial intelligence. Morgan Kaufmann Publishers Inc (pp. 89–96).
Cozman, F.G. (2000). Credal networks. Artificial Intelligence, 120(2), 199–233.
de Campos, L.M., & Moral, S. (1995). Independence concepts for convex sets of probabilities, Proceedings of the eleventh conference on uncertainty in artificial intelligence. Morgan Kaufmann Publishers Inc. (pp. 108–115).
de Finetti, B. (1931). Sul concetto di media. Giornale dell’Istituto Italiano degli Attuari, 2, 369– 396.
de Finetti, B. (1964). Foresight: its logical laws, its subjective sources, In Kyburg, H.E., & Smoklery, H.E. (Eds.) Studies in Subjective Probability. Wiley.
Dietrich, F. (2010). Bayesian group belief. Social Choice and Welfare, 35(4), 595–626.
Dietrich, F., & List, C. (2014). Probabilistic opinion pooling. In Hájek, A., & Hitchcock, C. (Eds.), Oxford Handbook of Probability and Philosophy. Oxford University Press.
Ellsberg, D. (1963). Risk, ambiguity, and the savage axioms. The Quarterly Journal of Economics, 77(2), 327–336.
French, S. (1985). Group consensus probability distributions: a critical survey. In Bernardo, D.L.J.M., DeGroot, M.H., & Smith, A. (Eds.), Bayesian statistics: proceedings of the second valencia international meeting. North-Holland, (Vol. 2 pp. 183–201).
Gaifman, H., & Snir, M. (1982). Probabilities over rich languages, testing and randomness. The Journal Of Symbolic Logic, 47(03), 495–548.
Gärdenfors, P., & Rott, H. (1995). Handbook of logic in artificial intelligence and logic programming: epistemic and temporal reasoning Vol. 4. Oxford: Oxford University Press. Chapter Belief Revision.
Gärdenfors, P., & Sahlin, N.-E. (1982). Unreliable probabilities, risk taking, and decision making. Synthese, 53(3), 361–386.
Genest, C. (1984). A characterization theorem for externally bayesian groups. The Annals of Statistics.
Genest, C., McConway, K.J., & Schervish, M.J. (1986). Characterization of externally Bayesian pooling operators. The Annals of Statistics.
Genest, C., & Wagner, C.G. (1987). Further evidence against independence preservation in expert judgement synthesis. Aequationes Mathematicae, 32(1), 74–86.
Genest, C., & Zidek, J.V. (1986). Combining probability distributions: a critique and an annotated bibliography. Statistical Science.
Gilboa, I., & Schmeidler, D. (1989). Maxmin expected utility with non-unique prior. Journal of Mathematical Economics, 18(2), 141–153.
Girón, F.J., & Ríos, S. (1980). Quasi-bayesian behaviour: a more realistic approach to decision making? Trabajos de Estadý de Investigació,n Operativa, 31 (1), 17–38.
Halmos, P.R. (1963). Lectures on boolean algebras. Princeton: Van Nostrand.
Herron, T., Seidenfeld, T., & Wasserman, L. (1997). Divisive conditioning: further results on dilation. Philosophy of Science.
Herzberg, F. (2014). Aggregating infinitely many probability measures. Theory and Decision.
Kaplan, M. (1996). Decision theory as philosophy. Cambridge: Cambridge University Press.
Kolmogorov, A.N. (1930). Sur la notion de la moyenne. Atti della R. Academia Nazionale dei Lincei, 12(9), 388–391.
Kyburg, H.E. (1998). Interval-valued probabilities. Imprecise Probabilities Project.
Kyburg, H.E., & Pittarelli, M. (1992). Some problems for convex bayesians, Proceedings of the eighth international conference on uncertainty in artificial intelligence. Morgan Kaufmann Publishers Inc. (pp. 149–154).
Kyburg, H.E., & Pittarelli, M. (1996). Set-based Bayesianism. IEEE Transactions on Systems, Man and Cybernetics, Part A: Systems and Humans, 26(3), 324–339.
Lehrer, K., & Wagner, C. (1981). Rational consensus in science and society: a philosophical and mathematical study Vol. 21. Springer.
Lehrer, K., & Wagner, C. (1983). Probability amalgamation and the independence issue: a reply to laddaga. Synthese, 55(3), 339–346.
Levi, I. (1974). On indeterminate probabilities. The Journal of Philosophy, 71 (13), 391–418.
Levi, I. (1978). Irrelevance, Foundations and applications of decision theory. Springer (pp. 263–273).
Levi, I. (1980). The enterprise of knowledge. Cambridge: MIT Press.
Levi, I. (1985). Consensus as shared agreement and outcome of inquiry. Synthese, 62(1), 3–11.
Levi, I. (1986a). Hard choices: Decision making under unresolved conflict. Cambridge: Cambridge University Press.
Levi, I. (1986b). The paradoxes of allais and ellsberg. Economics and Philosophy, 2(1), 23–53.
Levi, I. (1990). Pareto unanimity and consensus. The Journal of Philosophy, 87(9), 481–492.
Levi, I. (2009). Why indeterminate probability is rational. Journal of Applied Logic, 7(4), 364–376.
Madansky, A. (1964). Externally Bayesian Groups. Santa Monica, CA: RAND Corporation . http://www.rand.org/pubs/research_memoranda/RM4141.html. Also available in print form.
McConway, K.J. (1981). Marginalization and linear opinion pools. Journal of the American Statistical Association, 76(374), 410–414.
Mongin, P. (1995). Consistent bayesian aggregation. Journal of Economic Theory, 66(2), 313–351.
Moral, S., & Del Sagrado, J. (1998). Aggregation of imprecise probabilities, In Bouchon-Meunier, B. (Ed.), Aggregation and fusion of imperfect information. Springer (pp. 162–188).
Nau, R.F. (2002). The aggregation of imprecise probabilities. Journal of Statistical Planning and Inference, 105(1), 265–282.
Ouchi, F. (2004). A literature review on the use of expert opinion in probabilistic risk analysis. Washington, DC: World Bank.
Pedersen, A.P., & Wheeler, G. (2014). Demystifying dilation. Erkenntnis, 79 (6), 1305–1342.
Pedersen, A.P., & Wheeler, G. (2015). Dilation, disintegrations, and delayed decisions, Proceedings of the 9th.
Ramsey, F.P. (1931). Truth and probability. The Foundations of Mathematics and Other Logical Essays.
Rockafellar, R.T. (1970). Convex analysis. Number 28. Princeton: Princeton University Press.
Savage, L. (1972 Originally published in 1954). The foundations of statistics. New York: Wiley.
Seidenfeld, T. (1993). Outline of a theory of partially ordered preferences. Philosophical Topics, 21(1), 173–189.
Seidenfeld, T., Kadane, J.B., & Schervish, M.J. (1989). On the shared preferences of two bayesian decision makers. The Journal of Philosophy, 86(5), 225–244.
Seidenfeld, T., Schervish, M.J., & Kadane, J.B. (2010). Coherent choice functions under uncertainty. Synthese, 172(1), 157–176.
Seidenfeld, T., & Wasserman, L. (1993). Dilation for sets of probabilities. The Annals of Statistics, 21(3), 1139–1154.
Smith, C.A.B. (1961). Consistency in statistical inference and decision. Journal of the Royal Statistical Society. Series B (Methodological), 23(1), 1–37.
Stewart, R.T., & Ojea Quintana, I. (MS2). Learning and pooling, pooling and learning. Unpublished manuscript.
Stone, M. (1961). The opinion pool. The Annals of Mathematical Statistics, 32(4), 1339–1342.
Wagner, C. (2009). Jeffrey conditioning and external bayesianity. Logic Journal of IGPL, 18(2), 336–345.
Walley, P. (1982). The elicitation and aggregation of beliefs. Technical report 23, Department of Statistics, University of Warwick, Coventry CV4 7AL, England.
Walley, P. (1991). Statistical reasoning with imprecise probabilities. London: Chapman and Hall.
Wasserman, L. (1993). Review: statistical reasoning with imprecise probabilities by Peter Walley. Journal of the American Statistical Association, 88(422), 700–702.
Wasserman, L., & Seidenfeld, T. (1994). The dilation phenomenon in robust bayesian inference. Journal of Statistical Planning and Inference, 40(2), 345–356.
Acknowledgments
Several people gave us very helpful feedback on the ideas in this paper. Thanks to Robby Finley and Yang Liu for their comments on a presentation given to the Formal Philosophy reading group at Columbia University, and to members of the audiences at the Columbia Graduate Student Workshop, the Probability and Belief Workshop organized by Hans Rott at the University of Regensburg, and a presentation at CUNY organized by Rohit Parikh. We are grateful to Arthur Heller, Michael Nielsen, Teddy Seidenfeld, Reuben Stern, and Mark Swails for their excellent comments on drafts of the paper. We would like to especially thank Isaac Levi for extensive discussion of the content of this paper and comments on drafts and a presentation. Finally, thanks to both the editor and the anonymous referee. The referee provided engaged and thorough feedback that has undoubtedly improved the essay in a number of ways.
Author information
Authors and Affiliations
Corresponding author
Appendix: Proofs
Appendix: Proofs
1.1 Proof of Proposition 1
Proof
We carry out McConway’s proof with minimal adjustments made for our framework (pp. 411–412 [45], Theorem 3.1).
WSFP ⇒ MP. Assume that \(\mathcal {F}\) has the WSFP, i.e., there is a function \(\mathcal {G}{\kern -1.5pt}:{} \mathcal {A}{\kern -.3pt}\times {\kern -1.5pt} [0,1]^{n} {\kern -1.5pt}\to {}\mathcal {P}([0,1])\) suchthat \(\mathcal {F}(\boldsymbol {p}_{1}, \ldots , \boldsymbol {p}_{n})(A) = \mathcal {G}(A, \boldsymbol {p}_{1}(A), \ldots , \boldsymbol {p}_{n}(A))\). By WSFP, we have \(\mathcal {F}([\boldsymbol {p}_{1} {\upharpoonright }_{\mathcal {A}^{\prime }}], \ldots , [\boldsymbol {p}_{n}\upharpoonright _{\mathcal {A}^{\prime }}])(A) = \mathcal {G}(A, [\boldsymbol {p}_{1}\upharpoonright _{\mathcal {A}^{\prime }}](A), \ldots , [\boldsymbol {p}_{n}\upharpoonright _{\mathcal {A}^{\prime }}](A))\). Since \(\mathcal {G}\) isafunctionand \(\boldsymbol {p}_{i}(A) = [\boldsymbol {p}_{i} \upharpoonright _{\mathcal {A}^{\prime }}](A)\) forany \(A \in \mathcal {A}^{\prime }\) (all such \(A \in \mathcal {A}^{\prime }\) are also in \(\mathcal {A}\)), it follows that \(\mathcal {G}(A, [\boldsymbol {p}_{1}\upharpoonright _{\mathcal {A}^{\prime }}](A), \ldots , [\boldsymbol {p}_{n}\upharpoonright _{\mathcal {A}^{\prime }}](A)) = \mathcal {G}(A, \boldsymbol {p}_{1}(A), \ldots , \boldsymbol {p}_{n}(A)) = \mathcal {F}(\boldsymbol {p}_{1}, \ldots , \boldsymbol {p}_{n})(A)\).Hence,\( \mathcal {F}(\boldsymbol {p}_{1}, \ldots , \boldsymbol {p}_{n})(A) = \mathcal {F}([\boldsymbol {p}_{1}\upharpoonright _{\mathcal {A}^{\prime }}], \ldots , [\boldsymbol {p}_{n}\upharpoonright _{\mathcal {A}^{\prime }}])(A)\).
MP ⇒ WSFP. Assume that \(\mathcal {F}\) has the MP. Let \(A \in \mathcal {A}\). We want to show that \(\mathcal {F}(\boldsymbol {p}_{1}, \ldots , \boldsymbol {p}_{n})(A)\) depends only on A and p i (A),i=1,…,n.
First, if A = ∅ or A=Ω, then, since the range of \(\mathcal {F}\) is \(\mathcal {P}(\mathbb {P}), \mathcal {F}(\boldsymbol {p}_{1}, \ldots , \boldsymbol {p}_{n})(A) \) depends only on A and p i (A),i=1,..,n, for any profile because, setting \(\mathcal {F}(\boldsymbol {p}_{1}, \ldots , \boldsymbol {p}_{n})(A) \,=\, \mathcal {G}(A, \boldsymbol {p}_{1}(A), \ldots , \boldsymbol {p}_{n}(A))\) and \(\mathcal {F}(\boldsymbol {p}_{1}^{\prime }, \ldots , \boldsymbol {p}_{n}^{\prime })(A) \,=\, \mathcal {G}(A, \boldsymbol {p}_{1}^{\prime }\) \((A), \ldots , \boldsymbol {p}_{n}^{\prime }(A))\), it follows that \(\mathcal {G}(A, \boldsymbol {p}_{1}(A), \ldots , \boldsymbol {p}_{n}(A)) = \mathcal {G}(A, \boldsymbol {p}_{1}^{\prime }(A),\ldots , \boldsymbol {p}_{n}^{\prime } (A))\).
Next, suppose that ∅≠A≠Ω. Consider the σ-algebra \(\mathcal {A}^{\prime } = \{\emptyset , A, A^c, {\Omega }\}\). \(\mathcal {A}\) contains A and has \(\mathcal {A}^{\prime }\) as a sub-algebra. By MP, then
\(\mathcal {A}^{\prime }\) is uniquely defined by A and any probability over \(\mathcal {A}^{\prime }\) is uniquely determined by the probability of A under that distribution. So the righthand side of the equation above is determined by A and \(\boldsymbol {p}_{i}\upharpoonright _{\mathcal {A}^{\prime }}(A) = [\boldsymbol {p}_{i}\upharpoonright _{\mathcal {A}^{\prime }}](A) = \boldsymbol {p}_{i}(A)\). □
1.2 Proof of Lemma 1
Proof
Let \(Y = \{\boldsymbol {p} : \boldsymbol {p} = {\sum }_{i=1}^{n} \alpha _{i}\boldsymbol {p}_{i}\) such that α i ≥0 for i=1,…,n and \({\sum }_{i=1}^{n} \alpha _{i} = 1\}\). We want to show the following:
The first equality we have by definition. In order to show the second equality, we have to show that Y is the smallest convex set containing {p i :i=1,…,n}. To show convexity, we show that for any two functions in Y, any convex combination of those functions is in Y. Suppose that p,p ′∈Y. By assumption, \(\boldsymbol {p} = {\sum }_{i = 1}^{n} \alpha _{i} \boldsymbol {p}_{i}\) and \(\boldsymbol {p}^{\prime } = {\sum }_{i = 1}^{n} \beta _{i} \boldsymbol {p}_{i}\). Consider \(\boldsymbol {p}^{\star } = \gamma \boldsymbol {p} + (1 - \gamma ) \boldsymbol {p}^{\prime } = \gamma ({\sum }_{i = 1}^{n} \alpha _{i} \boldsymbol {p}_{i}) + (1 - \gamma ) {\sum }_{i = 1}^{n} \beta _{i} \boldsymbol {p}_{i}\).
where δ j = γ α j +(1−γ)β j . δ j ≥0 for j=1,…,n because every term is nonnegative. \({\sum }_{j = 1}^{n} \delta _{j} = {\sum }_{i = 1}^{n} [\gamma \alpha _{i} + (1 - \gamma ) \beta _{i}] = {\sum }_{i = 1}^{n} \gamma \alpha _{i} + {\sum }_{i = 1}^{n} (1 - \gamma ) \beta _{i} = \gamma {\sum }_{i = 1}^{n} \alpha _{i} + (1 - \gamma ) {\sum }_{i = 1}^{n} \beta _{i} = \gamma (1) + (1-\gamma )1 = 1\). Hence, p ⋆∈Y, so Y is convex. If Y were not the smallest such set, then there would be some convex \(Z \subsetneq Y\) such that {p i :i=1,…,n}⊆Z. But for any p∈Y,p is a convex combination of the elements in {p i :i=1,…,n}. Since Z is convex and contains the p i , it follows that p∈Z, which is a contradiction. □
1.3 Proof of Proposition 2
Proof
Since \(\mathcal {F}(\boldsymbol {p}_{1}, \ldots , \boldsymbol {p}_{n})(A) = \{\boldsymbol {p}(A): \boldsymbol {p} \in \mathcal {F}(\boldsymbol {p}_{1}, \ldots , \boldsymbol {p}_{n})\}\), we let \(\mathcal {G}\) of the SSFP be the convex hull operation applied to {p i (A):i=1,…,n}. It is clear that \(\mathcal {G}\) depends just on the individual probabilities for A. We need to show that
Trivially, the lefthand side includes {p i (A):i=1,…,n}. Suppose \(\boldsymbol {p}(A), \boldsymbol {p}^{\prime }(A) \in \{\boldsymbol {p}(A): \boldsymbol {p} \in \mathcal {F}(\boldsymbol {p}_{1}, \ldots , \boldsymbol {p}_{n})\}\). Since \(\mathcal {F}(\boldsymbol {p}_{1}, \ldots , \boldsymbol {p}_{n})\) is convex, it follows immediately that any convex combination of p(A),p ′(A) is in \(\{\boldsymbol {p}(A): \boldsymbol {p} \in \mathcal {F}(\boldsymbol {p}_{1}, \ldots , \boldsymbol {p}_{n})\}\). Finally, suppose that there is some convex \(Z \subsetneq \{\boldsymbol {p}(A): \boldsymbol {p} \in \mathcal {F}(\boldsymbol {p}_{1}, \ldots , \boldsymbol {p}_{n})\}\) which contains {p i (A):i=1,…,n}. But for any \(\boldsymbol {p}(A) \in \{\boldsymbol {p}(A): \boldsymbol {p} \in \mathcal {F}(\boldsymbol {p}_{1}, \ldots , \boldsymbol {p}_{n})\}\), p(A) is a convex combination of the p i (A) since every \(\boldsymbol {p} \in \mathcal {F}(\boldsymbol {p}_{1}, \ldots , \boldsymbol {p}_{n})\) is such a convex combination of the p i (Lemma 1). Hence, p(A)∈Z, contrary to our supposition. So, the equality holds and the SWFP is satisfied.
But since SWFP clearly implies WSFP, WSFP is satisfied, too. By Proposition 1, it follows immediately that \(\mathcal {F}\) has the MP.
Because \(\mathcal {F}(\boldsymbol {p}_{1}, \ldots , \boldsymbol {p}_{n})\) is a set of probability functions, \(\mathcal {F}(\boldsymbol {p}_{1}, \ldots , \boldsymbol {p}_{n})(\emptyset ) = \{0\}\). Let p i (A)=0, i=1,…,n. Since there is a function, \(\mathcal {G}\), such that \(\mathcal {F}(\boldsymbol {p}_{1}, \ldots , \boldsymbol {p}_{n})(A) = \mathcal {G}(\boldsymbol {p}_{1}(A), \ldots , \boldsymbol {p}_{n}(A))\), we have it that
So, ZPP follows from SWFP.
For any profile \((\boldsymbol {p}_{1}, \ldots , \boldsymbol {p}_{n}) \in \mathbb {P}^{n}\), if all p i are identical, then the convex hull is just {p i }. So \(\mathcal {F}\) satisfies unanimity preservation. □
1.4 Proof of Lemma 2
We generalize a proof of a result due originally to Girón and Rios and Levi [25, 37] for updating on an event to updating on a common likelihood function.
Proof
We want to show that \(\mathcal {F}^{\lambda }(\boldsymbol {p}_{1}, \ldots , \boldsymbol {p}_{n})\) is convex. That is, given any two members, \(\boldsymbol {p}^{\lambda }, \boldsymbol {p}^{\prime \lambda } \in \mathcal {F}^{\lambda }(\boldsymbol {p}_{1}, \ldots , \boldsymbol {p}_{n})\) and α∈[0,1], p ⋆ = α p λ+(1−α)p ′λ is in \(\mathcal {F}^{\lambda }(\boldsymbol {p}_{1}, \ldots , \boldsymbol {p}_{n})\). If there is a convex combination of p and p ′, p ⋆, such that p ⋆λ = p ⋆, then the convexity of \(\mathcal {F}^{\lambda }(\boldsymbol {p}_{1}, \ldots , \boldsymbol {p}_{n})\) is established as a consequence of the convexity of \(\mathcal {F}(\boldsymbol {p}_{1}, \ldots , \boldsymbol {p}_{n})\). Where \(\boldsymbol {p}^{\star \lambda }(\cdot ) = \frac {\boldsymbol {p}_{\star }(\cdot )\lambda (\cdot )}{{\sum }_{\omega ^{\prime } \in {\Omega }}\boldsymbol {p}_{\star }(\omega ^{\prime })\lambda (\omega ^{\prime })} = \frac {\beta \boldsymbol {p}(\cdot )\lambda (\cdot )+(1-\beta ) \boldsymbol {p}^{\prime }(\cdot )\lambda (\cdot )}{\beta {\sum }_{\omega ^{\prime } \in {\Omega }}\boldsymbol {p}(\omega ^{\prime })\lambda (\omega ^{\prime })+(1-\beta ) {\sum }_{\omega ^{\prime } \in {\Omega }}\boldsymbol {p}^{\prime }(\omega ^{\prime })\lambda (\omega ^{\prime })}\), for any α we want to find some β such that
For \(\beta =\frac {\alpha {\sum }_{\omega ^{*} \in {\Omega }}\boldsymbol {p}^{\prime }(\omega ^{*})\lambda (\omega ^{*})}{\alpha {\sum }_{\omega ^{*} \in {\Omega }} \boldsymbol {p}^{\prime }(\omega ^{*})\lambda (\omega ^{*})+(1-\alpha ) {\sum }_{\omega ^{*} \in {\Omega }}\boldsymbol {p}(\omega ^{*})\lambda (\omega ^{*})}\), the equality is verifiable with some tedious algebra. □
1.5 Proof of Proposition 3
Proof
We must show that convex IP pooling functions are externally Bayesian, i.e., \(\mathcal {F}(\boldsymbol {p}_{1}^{\lambda }, \ldots , \boldsymbol {p}_{n}^{\lambda }) = \mathcal {F}^{\lambda }(\boldsymbol {p}_{1}, \ldots , \boldsymbol {p}_{n})\) (provided the relevant profiles are in the domain of \(\mathcal {F}\)).
\(\mathcal {F}(\boldsymbol {p}_{1}^{\lambda }, \ldots , \boldsymbol {p}_{n}^{\lambda }) \subseteq \mathcal {F}^{\lambda }(\boldsymbol {p}_{1}, \ldots , \boldsymbol {p}_{n})\). Trivially, for each i=1,…,n, \(\boldsymbol {p}_{i}^{\lambda } \in \mathcal {F}^{\lambda }(\boldsymbol {p}_{1}, \ldots , \boldsymbol {p}_{n})\). By Lemma 2, \(\mathcal {F}^{\lambda }(\boldsymbol {p}_{1}, \ldots , \boldsymbol {p}_{n})\) is convex. It follows that \(conv\{\boldsymbol {p}_{i}^{\lambda } : i =1, \ldots , n\} = \mathcal {F}(\boldsymbol {p}_{1}^{\lambda }, \ldots , \boldsymbol {p}_{n}^{\lambda }) \subseteq \mathcal {F}^{\lambda }(\boldsymbol {p}_{1}, \ldots , \boldsymbol {p}_{n})\).
\(\mathcal {F}^{\lambda }(\boldsymbol {p}_{1}, \ldots , \boldsymbol {p}_{n}) \subseteq \mathcal {F}(\boldsymbol {p}_{1}^{\lambda }, \ldots , \boldsymbol {p}_{n}^{\lambda })\). By Lemma 1, any \(\boldsymbol {p} \in \mathcal {F}(\boldsymbol {p}_{1}, \ldots , \boldsymbol {p}_{n})\) can be expressed as the convex combination of the n extreme points generating \(\mathcal {F}(\boldsymbol {p}_{1}, \ldots , \boldsymbol {p}_{n})\), i.e., \(\boldsymbol {p} = {\sum }_{i=1}^{n} \alpha _{i} \boldsymbol {p}_{i}\) where α i ≥0 for i=1,…,n and \({\sum }_{i=1}^{n}\alpha _{i}=1\). By definition,
We show that any member of \(\mathcal {F}^{\lambda }(\boldsymbol {p}_{1}, \ldots , \boldsymbol {p}_{n})\) is identical to some member of \(\mathcal {F}(\boldsymbol {p}_{1}^{\lambda }, \ldots , \boldsymbol {p}_{n}^{\lambda })\).
where \(\beta _{j} = \frac {\alpha _{j} \cdot {\sum }_{\omega ^{\prime } \in {\Omega }} \boldsymbol {p}_{j}(\omega ^{\prime }) \lambda (\omega ^{\prime })}{{\sum }_{\omega ^{\prime } \in {\Omega }} {\sum }_{i=1}^{n}\alpha _{i} \boldsymbol {p}_{i}(\omega ^{\prime }) \lambda (\omega ^{\prime })}\) with β j ≥0 for all j=1,…,n and \({\sum }_{j=1}^{n} \beta _{j} = 1\). □
1.6 Proof of Proposition 4
Proof
We provide a very simple type of counterexample to individualwise Bayesianity, though counterexamples are plentiful. Consider the profile (p 1,p 2) for n=2 agents such that p 1 = p 2. Individualwise Bayesianity requires that \(\mathcal {F}(\boldsymbol {p}_{1}, \boldsymbol {p}_{2}^{\lambda }) = \mathcal {F}^{\lambda }(\boldsymbol {p}_{1}, \boldsymbol {p}_{2})\) (provided both (p 1,p 2) and \((\boldsymbol {p}_{1}, \boldsymbol {p}_2^{\lambda })\) are in the domain of \(\mathcal {F}\)). By Proposition 3 (external Bayesianity), it follows that \(\mathcal {F}^{\lambda }(\boldsymbol {p}_{1}, \boldsymbol {p}_{2}) = \mathcal {F}(\boldsymbol {p}_{1}^{\lambda }, \boldsymbol {p}_{2}^{\lambda })\). But since p 1 = p 2, it follows that \(\boldsymbol {p}_{1}^{\lambda } = \boldsymbol {p}_{2}^{\lambda }\). By unanimity (Proposition 2), then, we have \(\mathcal {F}(\boldsymbol {p}_{1}^{\lambda }, \boldsymbol {p}_{2}^{\lambda }) = \{\boldsymbol {p_{i}}^{\lambda }\},\) where \(\boldsymbol {p}_{i}^{\lambda } = \boldsymbol {p}_{1}^{\lambda } = \boldsymbol {p}_{2}^{\lambda }\). However, in general \(\boldsymbol {p}_{i} \neq \boldsymbol {p}_{i}^{\lambda }\) and so \(\mathcal {F}(\boldsymbol {p}_{1}, \boldsymbol {p}_{2}^{\lambda })\) is not a singleton. It follows that, in general, \(\mathcal {F}(\boldsymbol {p}_{1}, \boldsymbol {p}_{2}^{\lambda }) \neq \mathcal {F}^{\lambda }(\boldsymbol {p}_{1}, \boldsymbol {p}_{2})\). □
1.7 Proof of Proposition 5
Proof
Suppose that p i (A|B) = p i (A) for i=1,…,n. We want to show that \(\mathcal {F}(\boldsymbol {p}_{1}, \ldots , \boldsymbol {p}_{n})(A) = \mathcal {F}^{B}(\boldsymbol {p}_{1}, \ldots , \boldsymbol {p}_{n})(A)\). Consider \(\boldsymbol {p}^{\star }(A) \in \mathcal {F}(\boldsymbol {p}_{1}, \ldots , \boldsymbol {p}_{n})(A)\) and \(\boldsymbol {p}_{\star }(A) \in \mathcal {F}^{B}(\boldsymbol {p}_{1}, \ldots , \boldsymbol {p}_{n})(A)\). By Lemma 1, \(\boldsymbol {p}^{\star }(A) = {\sum }_{i = 1}^{n} \alpha _{i} \boldsymbol {p}_{i}(A)\), for appropriate α i . By Proposition 3 (external Bayesianity), \(\mathcal {F}^{B}(\boldsymbol {p}_{1}, \ldots , \boldsymbol {p}_{n})(A) = \mathcal {F}(\boldsymbol {p}_{1}^{B}, \ldots , \boldsymbol {p}_{n}^{B})(A)\) (Proposition 3 holds for standard conditionalization since standard conditionalization is a special case of updating on a likelihood function, as noted in the body of the paper). So, we have \(\boldsymbol {p}_{\star }(A) = {\sum }_{i = 1}^{n} \beta _{i} \boldsymbol {p}_{i}^{B}(A)\), for appropriate β i , again by Lemma 1. By hypothesis \(\boldsymbol {p}_{i}^{B}(A) = \boldsymbol {p}_{i}(A)\) for i=1,…,n. Hence, \(\boldsymbol {p}_{\star }(A) = {\sum }_{i = 1}^{n} \beta _{i} \boldsymbol {p}_{i}^{B}(A) = {\sum }_{i=1}^{n} \beta _{i} \boldsymbol {p}_{i}(A)\). Letting α i = β i , it follows that \(\mathcal {F}(\boldsymbol {p}_{1}, \ldots , \boldsymbol {p}_{n})(A) = \mathcal {F}^{B}(\boldsymbol {p}_{1}, \ldots , \boldsymbol {p}_{n})(A)\). □
1.8 Proof of Proposition 6
Proof
We show first that \(\mathcal {M}_{n}(\boldsymbol {p}_{1}, \ldots , \boldsymbol {p}_{n}) \subseteq conv(\boldsymbol {p}_{1}, \ldots , \boldsymbol {p}_{n})\) for all \((\boldsymbol {p}_{1}, \ldots , \boldsymbol {p}_{n}) \in \mathbb {P}^{n}\). Since there are at least three disjoint events, \(A_{1}, A_2, A_3 \in \mathcal {A}\), following Lehrer and Wagner [34, Theorems 6.4, 6.7] and McConway [45, Theorem 3.3], we can exploit techniques and results for functional equations. For any numbers a i ,b i ∈[0,1] with a i + b i ∈[0,1], define a sequence of probability measures, p i , i=1,…,n by setting
Since it is the case that \(\mathfrak {m}\left (\boldsymbol {p}_{1}(\cdot ), \ldots , \boldsymbol {p}_{n}(\cdot )\right ) \in \mathbb {P}\) for all \((\boldsymbol {p}_{1}, \ldots , \boldsymbol {p}_{n}) \in \mathbb {P}^{n}\) and every \(\mathfrak {m}\left (\boldsymbol {p}_{1}(\cdot ), \ldots , \boldsymbol {p}_{n}(\cdot )\right ) \in \mathcal {M}_{n}(\boldsymbol {p}_{1}, \ldots , \boldsymbol {p}_{n})\), we have it that \(\mathfrak {m}\left (\boldsymbol {p}_{1}(A), \ldots , \boldsymbol {p}_{n}(A)\right )=\boldsymbol {p}(A),\) for some \(\boldsymbol {p} \in \mathbb {P}\) and all \(A \in \mathcal {A}\). Now, by the additivity of probability measures, p(A 1∪A 2) = p(A 1) + p(A 2). Hence, \(\mathfrak {m}(a_{1}+b_{1}, \ldots , a_{n} + b_{n}) = \mathfrak {m}\left (a_{1}, \ldots , a_{n}\right ) + \mathfrak {m}\left (b_{1}, \ldots , b_{n}\right )\). So, \(\mathfrak {m}\) satisfies Cauchy’s multivariable functional equation. For each i=1,…,n, define \(\mathfrak {m}_{i}(a) = \mathfrak {m}(0, \ldots , a, \ldots , 0),\) where a occupies the i-th position of the vector (0,…,a,…,0). It is clear that \(\mathfrak {m}_{i}(a + b) = \mathfrak {m}_{i}(a) + \mathfrak {m}_{i}(b)\) for all a,b∈[0,1] with a + b∈[0,1]. Because \(\mathfrak {m}\) is nonnegative, so is \(\mathfrak {m}_{i},\ i = 1, \ldots , n\). By Theorem 3 of [2, p. 48], it follows that there exists a nonnegative constant α i such that \(\mathfrak {m}_{i}(a) = \alpha _{i} a\) for all a∈[0,1]. By the Cauchy equation we have
So we have \(\mathfrak {m}(a_{1}, \ldots , a_{n}) = \mathfrak {m}_{1}(a_{1}) + {\ldots } + \mathfrak {m}_{n}(a_{n}) = \alpha _{1} a_{1} + {\ldots } + \alpha _{n} a_{n}\). And since \(\mathfrak {m}(1, \ldots , 1)=1\) (by consideration of the probability of Ω), it follows that \({\sum }_{i=1}^{n} \alpha _{i}=1\). Thus, \(\mathfrak {m}\) is a convex combination.
Now, we want to show that \(conv(\boldsymbol {p}_{1}, \ldots , \boldsymbol {p}_{n}) \subseteq \mathcal {M}_{n}(\boldsymbol {p}_{1}, \ldots , \boldsymbol {p}_{n})\). Let p be an element of c o n v(p 1,…,p n ). It is clear that there exists an \(\mathfrak {m} \in \mathfrak {M}_{n}(\boldsymbol {p}_{1}, \ldots , \boldsymbol {p}_{n})\) such that \(\mathfrak {m}\left (\boldsymbol {p}_{1}(\cdot ), \ldots , \boldsymbol {p}_{n}(\cdot )\right ) = \boldsymbol {p}\). And since p is just a convex combination, there exist weights α 1,…,α n ∈[0,1] such that \({\sum }_{i=1}^{n} \alpha _{i} = 1\) and \(\boldsymbol {p} = {\sum }_{i=1}^{n} \alpha _{i}\boldsymbol {p}_{i}\). But for any other profile \((\boldsymbol {q}_{1}, \ldots , \boldsymbol {q}_{n}) \in \mathbb {P}^{n}\), taking any convex combination yields a probability measure. In particular, \({\sum }_{i=1}^{n} \alpha _{i}\boldsymbol {q}_{i} \in \mathbb {P}\). It follows that \(\mathfrak {m} \in \bigcap _{\vec {\boldsymbol {q}} \in \mathbb {P}^{n}} \mathfrak {M}_{n}(\vec {\boldsymbol {q}})\). So, \(\boldsymbol {p} = \mathfrak {m}\left (\boldsymbol {p}_{1}(\cdot ), \ldots , \boldsymbol {p}_{n}(\cdot )\right ) \in \mathcal {M}_{n}(\boldsymbol {p}_{1}, \ldots , \boldsymbol {p}_{n}),\) as desired.
The two inclusions above show that \(\mathcal {M}_{n}(\boldsymbol {p}_{1}, \ldots , \boldsymbol {p}_{n}) = conv(\boldsymbol {p}_{1}, \ldots , \boldsymbol {p}_{n})\). Hence, \(\mathcal {F}(\boldsymbol {p}_{1}, \ldots , \boldsymbol {p}_{n}) = conv(\boldsymbol {p}_{1}, \ldots , \boldsymbol {p}_{n})\) is equivalent to \(\mathcal {F}(\boldsymbol {p}_{1}, \ldots , \boldsymbol {p}_{n}) = \mathcal {M}_{n}(\boldsymbol {p}_{1}, \ldots , \boldsymbol {p}_{n})\). □
Rights and permissions
About this article

Cite this article
Stewart, R.T., Quintana, I.O. Probabilistic Opinion Pooling with Imprecise Probabilities. J Philos Logic 47, 17–45 (2018). https://doi.org/10.1007/s10992-016-9415-9
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10992-016-9415-9