
Abstract
The use of neural machine translation (NMT) in a professional scenario implies a number of challenges despite growing evidence that, in language combinations such as English to Spanish, NMT output quality has already outperformed statistical machine translation in terms of automatic metric scores. This article presents the result of an empirical test that aims to shed light on the differences between NMT post-editing and translation with the aid of a translation memory (TM). The results show that NMT post-editing involves less editing than TM segments, but this editing appears to take more time, with the consequence that NMT post-editing does not seem to improve productivity as may have been expected. This might be due to the fact that NMT segments show a higher variability in terms of quality and time invested in post-editing than TM segments that are ‘more similar’ on average. Finally, results show that translators who perceive that NMT boosts their productivity actually performed faster than those who perceive that NMT slows them down.


















Similar content being viewed by others

Notes
This is approximated using the difflib library (see https://docs.python.org/3/library/difflib.html), which measures the difference between two strings, rather than the minimum number of edits required to transform one string to another.
A quartile is a kind of quantile. It’s a descriptive measure. The first quartile (Q1) is the middle value of a range between the smallest value and the median. The median corresponds to the second quartile (Q2). The third quartile (Q3) corresponds to the 75% of the range, and the fourth quartile (Q4) to the 100%. Quartiles help describing the distribution of the population of the sample.
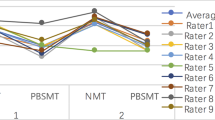
The Q2 value and the average of the MT set are very close to each other and are lower than those of TM under 80% set.
The interquartile range (IQR) measures statistical dispersion. A low IQR stands for a low level of variability.
References
Alabau V, Bonk R, Buck C, Carl M, Casacuberta F, García-Martínez M, González J, Koehn P, Leiva L, Mesa-Lao B, Ortiz D, Saint-Amand H, Sanchis G, Tsoukala C (2013) CASMACAT: an open source workbench for advanced computer aided translation. Prague Bull Math Linguist 100:101–112
Cadwell P, Castilho S, O’Brien S, Mitchell L (2016) Human factors in machine translation and post-editing among institutional translators. Transl Spaces 5(2):222–243
Castilho S, Moorkens J, Gaspari F, Calixto I, Tinsley J, Way A (2017) Is neural machine translation the new state of the art? Prague Bull Math Linguist 108:109–120
Castilho S, Moorkens J, Gaspari F, Sennrich R, Way A, Georgakopoulou P (2018) Evaluating MT for massive open online courses. Mach Transl 32(3):255–278
Flournoy R, Duran C (2009) Machine translation and document localization at Adobe: from pilot to production. In: Proceedings of MT summit XII, pp 425–428
Forcada M, Esplà-Gomis M, Sánchez-Martínez F, Specia L (2017) One-parameter models for sentence-level post-editing effort estimation. In: Proceedings of MT summit XVI, vol 1: Research Track, pp 132–143
Klubička F, Toral A, Sánchez-Cartagena VM (2017) Fine-grained human evaluation of neural versus phrase-based machine translation. Prague Bull Math Linguist 108(1):121–132
Koehn P, Knowles R (2017) Six challenges for neural machine translation. In: Proceedings of the first workshop on neural machine translation, Vancouver, Canada, pp 28—39
Krings HP (2001) Repairing texts: empirical investigations of machine translation post-editing process. The Kent State University Press, Kent
Läubli S, Fishel M, Massey G, Ehrensberger-Dow M, Volk M (2013) Assessing post-editing efficiency in a realistic translation environment. In: O’Brien S, Simard M, Specia L (eds) Proceedings of MT summit XIV workshop on post-editing technology and practice. Nice, pp 83–91
Levenshtein VI (1966) Binary codes capable of correcting deletions, insertions and reversals. Sov Phys Doklady 10(8):707–710
Lommel A, DePalma D (2016) Europe’s leading role in machine translation. Common sense advisory—cracker project
Martín-Mor A, Piqué Huerta R, Sánchez-Gijón P (2016) Tradumàtica: Tecnologies de la traducció. Eumo Editioral, Vic
Moorkens J (2017) Under pressure: translation in times of austerity. Perspectives 25(3):464–477
Moorkens J (2018) Eye-tracking as a measure of cognitive effort for post-editing of machine translation. In: Walker C, Federici F (eds) Eye tracking and multidisciplinary studies on translation. John Benjamins, Amsterdam, pp 55–69
Moorkens J, Way A (2016) Comparing translator acceptability of TM and SMT outputs. Balt J. Mod Comput 4(2):141–151
Moorkens J, O’Brien S, Silva IAL, Fonseca N, Alves F (2015) Correlations of perceived post-editing effort with measurements of actual effort. Mach Transl 29(3–4):267–284
Moorkens J, Lewis D, Reijers W, Vanmassenhove E, Way A (2016) Translation resources and translator disempowerment. In: Proceedings of ETHI-CA2 2016: ETHics in corpus collection, annotation and application, pp 49–53
O’Brien S (2012) Translation as human-computer interaction. Transl Spaces 1:101–122
Papineni K, Roukos S, Ward T, Zhu WJ (2002) BLEU: a method for automatic evaluation of machine translation. In: Proceedings of the 40th annual meeting of the association for computational linguistics, Philadelphia, Pennsylvania, pp 311–318
Pinnis M, Kalnis R, Skandis R, Skadina I (2016) What can we really learn from post-editing. In: Proceedings of AMTA 2016 vol 2: MT Users’ Track, pp 86–91
Plitt M, Masselot F (2010) A productivity test of statistical machine translation post-editing in a typical localization context. Prague Bull Math Linguist 93:7–16
Rossetti A, Gaspari F (2017) Modelling the analysis of translation memory use and post-editing of raw machine translation output: a pilot study of trainee translators’ perceptions of difficulty and time effectiveness. In: Hansen-Schirra S, Czulo O, Hoffmann S (eds) Empirical modelling of translation and interpreting. Language Science Press, Berlin, pp 41–67
Sánchez-Gijón P (2016) La posedición: hacia una definición competencial del perfil y una descripción multidimensional del fenómeno. Sendebar 27:151–162
Sánchez-Torrón M, Koehn P (2016) Machine translation quality and post-editor productivity. Proceedings of AMTA 2016:16
Shterionov D, Superbo R, Nagle P, Casanellas L, O’Dowd T, Way A (2018) Human versus automatic quality evaluation on NMT and PBSMT. Mach Transl 32(3):217–235
Specia L, Blain F, Astudillo RF, Logacheva V, Martins A (2018) Findings of the WMT 2018 shared task on quality estimation. In: Proceedings of the third conference on machine translation (WMT), vol 2: Shared Task Papers, Belgium, Brussels, pp 689–709
Teixeira CSC, Moorkens J, Turner D, Vreeke J, Way A (2019) Creating a multimodal translation tool and testing machine translation integration using touch and voice. In: Macken L, Daems J, Tezcan A (eds) Informatics 6(1):13 Special Issue on Advances in Computer-Aided Translation Technology https://www.mdpi.com/2227-9709/6/1/13
Torres-Hostench O, Presas M, Cid P et al (2016). El uso de traducción automática y posedición en las empresas de servicios lingüísticos españolas: informe de investigación ProjecTA 2015. https://ddd.uab.cat/record/148361
Way A (2018) Quality expectations of machine translation. In: Moorkens J, Castilho S, Gaspari F, Doherty S (eds) Translation quality assessment. Springer, Berlin, pp 159–178
Acknowledgements
This work has been supported by the ProjecTA-U project, Grant Number FFI2016-78612-R (MINECO/FEDER/UE), and by the ADAPT Centre for Digital Content Technology which is funded under the SFI Research Centres Programme (Grant 13/RC/2016) and is co-funded under the European Regional Development Fund.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations
Appendix
Appendix
Segment distribution into two sets:
# | Origin | Number of words |
|---|---|---|
1–1 | MT | 12 |
1–2 | TM (fuzzy match under 80%) | 5 |
1–3 | MT | 21 |
1–4 | TM (fuzzy match over 90%) | 24 |
1–5 | MT | 12 |
1–6 | TM (fuzzy match from 80 to 89%) | 25 |
1–7 | MT | 16 |
1–8 | TM (fuzzy match from 80 to 89%) | 23 |
1–9 | MT | 33 |
1–10 | TM (fuzzy match from 80 to 89%) | 21 |
1–11 | MT | 15 |
1–12 | TM (fuzzy match from 80 to 89%) | 35 |
1–13 | MT | 17 |
1–14 | TM (fuzzy match from 80 to 89%) | 10 |
1–15 | MT | 11 |
1–16 | TM (fuzzy match from 80 to 89%) | 16 |
1–17 | MT | 13 |
1–18 | TM (fuzzy match from 80 to 89%) | 16 |
1–19 | MT | 25 |
1–20 | TM (fuzzy match from 80 to 89%) | 17 |
1–21 | MT | 17 |
1–22 | TM (fuzzy match over 90%) | 24 |
1–23 | MT | 26 |
1–24 | TM (fuzzy match from 80 to 89%) | 16 |
1–25 | MT | 22 |
1–26 | TM (fuzzy match from 80 to 89%) | 20 |
1–27 | MT | 10 |
1–28 | TM (fuzzy match from 80 to 89%) | 7 |
1–29 | MT | 16 |
1–30 | TM (fuzzy match from 80 to 89%) | 10 |
2–1 | TM (fuzzy match from 80 to 89%) | 16 |
2–2 | MT | 25 |
2–3 | TM (fuzzy match from 80 to 89%) | 22 |
2–4 | MT | 63 |
2–5 | TM (fuzzy match under 80%) | 7 |
2–6 | MT | 15 |
2–7 | TM (fuzzy match over 90%) | 29 |
2–8 | MT | 19 |
2–9 | TM (fuzzy match from 80 to 89%) | 14 |
2–10 | MT | 17 |
2–11 | TM (fuzzy match under 80%) | 21 |
2–12 | MT | 17 |
2–13 | TM (fuzzy match under 80%) | 22 |
2–14 | MT | 16 |
2–15 | TM (fuzzy match under 80%) | 17 |
2–16 | MT | 68 |
2–17 | TM (fuzzy match from 80 to 89%) | 23 |
2–18 | MT | 12 |
2–19 | TM (fuzzy match under 80%) | 18 |
2–20 | MT | 11 |
2–21 | MT | 12 |
2–22 | TM (fuzzy match under 80%) | 5 |
2–23 | MT | 24 |
2–24 | TM (fuzzy match over 90%) | 18 |
2–25 | MT | 19 |
2–26 | TM (fuzzy match over 90%) | 27 |
2–27 | MT | 26 |
2–28 | TM (fuzzy match over 90%) | 16 |
2–29 | MT | 6 |
Rights and permissions
About this article

Cite this article
Sánchez-Gijón, P., Moorkens, J. & Way, A. Post-editing neural machine translation versus translation memory segments. Machine Translation 33, 31–59 (2019). https://doi.org/10.1007/s10590-019-09232-x
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10590-019-09232-x