
Abstract
Recent research has shown that accuracy and speed of human translators can benefit from post-editing output of machine translation systems, with larger benefits for higher quality output. We present an efficient online learning framework for adapting all modules of a phrase-based statistical machine translation system to post-edited translations. We use a constrained search technique to extract new phrase-translations from post-edits without the need of re-alignments, and to extract phrase pair features for discriminative training without the need for surrogate references. In addition, a cache-based language model is built on \(n\)-grams extracted from post-edits. We present experimental results in a simulated post-editing scenario and on field-test data. Each individual module substantially improves translation quality. The modules can be implemented efficiently and allow for a straightforward stacking, yielding significant additive improvements on several translation directions and domains.
















Similar content being viewed by others


Notes
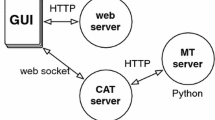
We will use the term post-editing instead of the more generic term CAT when our attention is focused on the interaction between human translator and MT system, disregarding the influence of other components available in a CAT tool, such as translation memories and terminology dictionaries.
The sample document is set0 of the English–Italian Information Technology task; see Sect. 5 for more details.
We used language-specific stop word lists to filter for content words, making our approach slightly language-dependent.
Details about the xml-input option can be found in the Moses official documentation (http://www.statmt.org/moses/manual/manual.pdf).
The usage of either modes do not introduce new features.
The source code of the local cache-based translation model and language model is available in the branch “dynamic-models” under the official GitHub repository of Moses toolkit, directly accessible from this URL:
https://github.com/moses-smt/mosesdecoder/tree/dynamic-models.
Other scoring functions have been tested in preliminary experiments, but no significant differences were observed. Details of additional scoring functions as well as usage instructions can be found in (Bertoldi 2014).
An implementation is available from https://github.com/pks/bold_reranking.
This phrase pair feature can only be used if the re-ranking is combined with one of the TM adaptations, as it is a newly created phrase pair.
The selected Eurovoc codes, as reported in the original documents, are 1338 and 4040. The corresponding selected documents are 32005R0713 and 52005PC0110 from class 1338, and 52005PC0687 from class 4040.
International Patent Classification is a hierarchical patent classification scheme. Details can be found here: http://www.wipo.int/classifications/ipc/en.
The coefficient of determination \(R^2\) of linear regression equals to 0.92.
It is worth recalling that BLEU is an accuracy metric, i.e. “the higher, the better”, whereas TER is an error metric, i.e. “the lower, the better”.
References
Bertoldi N (2014) Dynamic models in Moses for online adaptation. Prague Bull Math Linguist 101:7–28
Bertoldi N, Cettolo M, Federico M, Buck C (2012) Evaluating the learning curve of domain adaptive statistical machine translation systems. In: Proceedings of the seventh workshop on statistical machine translation. Montréal, Canada, pp 433–441
Bertoldi N, Cettolo M, Federico M (2013) Cache-based online adaptation for machine translation enhanced computer assisted translation. In: Proceedings of the MT summit XIV, Nice, France, pp 35–42
Bisazza A, Ruiz N, Federico M (2011) Fill-up versus interpolation methods for phrase-based SMT adaptation. In: Proceedings of the international workshop on spoken language translation (IWSLT). San Francisco, California, USA, pp 136–143
Cesa-Bianchi N, Lugosi G (2006) Prediction, learning, and games. Cambridge University Press, Cambridge
Cesa-Bianchi N, Reverberi G, Szedmak S (2008) Online learning algorithms for computer-assisted translation. Technical report, SMART (www.smart-project.eu)
Cettolo M, Federico M, Bertoldi N (2010) Mining parallel fragments from comparable texts. In: Proceedings of the international workshop on spoken language translation (IWSLT), Paris, France, pp 227–234
Cettolo M, Bertoldi N, Federico M (2011) Methods for smoothing the optimizer instability in SMT. In: Proceedings of the MT summit XIII, Xiamen, China, pp 32–39
Chiang D, Marton Y, Resnik P (2008) Online large-margin training of syntactic and structural translation features. In: Proceedings of the conference on empirical methods in natural language processing (EMNLP), Honolulu, Hawaii, USA, pp 224–233
Clark JH, Dyer C, Lavie A, Smith NA (2011) Better hypothesis testing for statistical machine translation: controlling for optimizer instability. In: Proceedings of the 49th annual meeting of the Association for Computational Linguistics: Human Language Technologies (ACL-HLT): short papers, vol 2, Portland, Oregon, USA, pp 176–181
Collins M (2002) Discriminative training methods for hidden markov models: theory and experiments with perceptron algorithms. In: Proceedings of the conference on empirical methods in natural language processing (EMNLP), Philadelphia, Pennsylvania, USA, pp 1–8
Denkowski M, Dyer C, Lavie A (2014) Learning from post-editing: online model adaptation for statistical machine translation. Proceedings of the 14th conference of the European chapter of the Association for Computational Linguistics (EACL’14), Gothenburg, Sweden, pp 395–404
Federico M, Bertoldi N, Cettolo M (2008) IRSTLM: an open source toolkit for handling large scale language models. In: Proceedings of interspeech, Brisbane, Australia, pp 1618–1621
Federico M, Cattelan A, Trombetti M (2012) Measuring user productivity in machine translation enhanced computer assisted translation. In: Proceedings of the tenth conference of the Association for Machine Translation in the Americas (AMTA), San Diego, California, USA
Foster G, Kuhn R (2007) Mixture-model adaptation for SMT. In: Proceedings of the second workshop on statistical machine translation. Prague, Czech Republic, pp 128–135
Green S, Heer J, Manning C (2013) The efficacy of human post-editing for language translation. In: Proceedings of the SIGCHI conference on human factors in computing systems. Paris, France, pp 439–448
Hardt D, Elming J (2010) Incremental re-training for post-editing SMT. In: Proceedings of the conference of the Association for Machine Translation in the Americas (AMTA), Denver, Colorado, USA, pp 217–237
Koehn P (2010) Statistical machine translation. Cambridge University Press, Cambridge
Koehn P, Schroeder J (2007) Experiments in domain adaptation for statistical machine translation. In: Proceedings of the second workshop on statistical machine translation. Prague, Czech Republic, pp 224–227
Koehn P, Hoang H, Birch A, Callison-Burch C, Federico M, Bertoldi N, Cowan B, Shen W, Moran C, Zens R, Dyer C, Bojar O, Constantin A, Herbst E (2007) Moses: open source toolkit for statistical machine translation. In: Proceedings of the 45th annual meeting of the Association for Computational Linguistics companion volume proceedings of the demo and poster sessions. Prague, Czech Republic, pp 177–180
Kuhn R, De Mori R (1990) A cache-based natural language model for speech recognition. IEEE Trans Pattern Anal Machine Intell 12(6):570–582
Läubli S, Fishel M, Massey G, Ehrensberger-Dow M, Volk M (2013) Assessing post-editing efficiency in a realistic translation environment. In: Proceedings of the MT summit XIV workshop on post-editing technology and practice, Nice, France, pp 83–91
Levenberg A, Callison-Burch C, Osborne M (2010) Stream-based translation models for statistical machine translation. In: Proceedings of the 2010 annual conference of the North American chapter of the Association for Computational Linguistics (HLT-NAACL), Los Angeles, California, USA, pp 394–402
Levenberg A, Dyer C, Blunsom P (2012) A Bayesian model for learning SCFGs with discontiguous rules. In: Proceedings of the 2012 joint conference on empirical methods in natural language processing and computational natural language learning (EMNLP-CoNLL), Jeju Island, Korea, pp 223–232
Liang P, Bouchard-Côté A, Klein D, Taskar B (2006) An end-to-end discriminative approach to machine translation. In: Proceedings of the 21st international conference on computational linguistics and 44th annual meeting of the Association for Computational Linguistics, Sydney, Australia, pp 761–768
Liu L, Cao H, Watanabe T, Zhao T, Yu M, Zhu C (2012) Locally training the log-linear model for SMT. In: Proceedings of the 2012 joint conference on empirical methods in natural language processing and computational natural language learning (EMNLP-CoNLL), Jeju Island, Korea, pp 402–411
López-Salcedo FJ, Sanchis-Trilles G, Casacuberta F (2012) Online learning of log-linear weights in interactive machine translation. In: Proceedings of Iber speech, Madrid, Spain, pp 277–286
Martínez-Gómez P, Sanchis-Trilles G, Casacuberta F (2012) Online adaptation strategies for statistical machine translation in post-editing scenarios. Pattern Recognit 45(9):3193–3202
Nepveu L, Lapalme G, Langlais P, Foster G (2004) Adaptive language and translation models for interactive machine translation. In: Proceedings of the conference on empirical methods in natural language processing (EMNLP), Barcelona, Spain, pp 190–197
Noreen EW (1989) Computer intensive methods for testing hypotheses: an introduction. Wiley Interscience, New York
Och FJ (2003) Minimum error rate training in statistical machine translation. In: Proceedings of the 41st annual meeting of the Association for Computational Linguistics. Sapporo, Japan, pp 160–167
Ortiz-Martínez D, García-Varea I, Casacuberta F (2010) Online learning for interactive statistical machine translation. In: Proceedings of the 2010 annual conference of the North American chapter of the Association of Computational Linguistics (HLT-NAACL), Los Angeles, pp 546–554
Papineni K, Roukos S, Ward T, Zhu WJ (2002) BLEU: a method for automatic evaluation of machine translation. In: Proceedings of the 40th annual meeting of the Association of Computational Linguistics (ACL). Philadelphia, Pennsylvania, USA, pp 311–318
Snover M, Dorr B, Schwartz R, Micciulla L, Makhoul J (2006) A study of translation edit rate with targeted human annotation. In: Proceedings of the 5th conference of the Association for Machine Translation in the Americas (AMTA). Cambridge, Massachusetts, USA, pp 223–231
Steinberger R, Pouliquen B, Widiger A, Ignat C, Erjavec T, Tufiş D, Varga D (2006) The JRC-Acquis: a multilingual aligned parallel corpus with 20+ languages. In: Proceedings of the 5th international conference on language resources and evaluation (LREC). Genoa, Italy, pp 2142–2147
Tiedemann J (2010) Context adaptation in statistical machine translation using models with exponentially decaying cache. In: Proceedings of the 2010 ACL workshop on domain adaptation for natural language processing, Uppsala, Sweden, pp 8–15
Tiedemann J (2012) Parallel data, tools and interfaces in OPUS. Proceedings of the 8th international conference on language resources and evaluation (LREC), Istanbul, Turkey, pp 2214–2218
Wäschle K, Riezler S (2012) Analyzing parallelism and domain similarities in the MAREC patent corpus. Proceedings of the 5th information retrieval facility conference (IRFC), Vienna, Austria, pp 12–27.
Wäschle K, Simianer P, Bertoldi N, Riezler S, Federico M (2013) Generative and discriminative methods for online adaptation in SMT. In: Proceedings of the MT summit XIV, Nice, France, pp 11–18
Acknowledgments
FBK researchers were supported by the MateCat project, funded by the EC under FP7; researchers at Heidelberg University by DFG grant “Cross-language Learning-to-Rank for Patent Retrieval”.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Bertoldi, N., Simianer, P., Cettolo, M. et al. Online adaptation to post-edits for phrase-based statistical machine translation. Machine Translation 28, 309–339 (2014). https://doi.org/10.1007/s10590-014-9159-7
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10590-014-9159-7