
Abstract
Time series averaging is an important subroutine for several time series data mining tasks. The most successful approaches formulate the problem of time series averaging as an optimization problem based on the dynamic time warping (DTW) distance. The existence of an optimal solution, called sample mean, is an open problem for more than four decades. Its existence is a necessary prerequisite to formulate exact algorithms, to derive complexity results, and to study statistical consistency. In this article, we propose sufficient conditions for the existence of a sample mean. A key result for deriving the proposed sufficient conditions is the Reduction Theorem that provides an upper bound for the minimum length of a sample mean.
Similar content being viewed by others
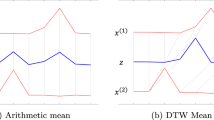

References
Abanda, A., Mori, U., Lozano, J.A.: A review on distance based time series classification. Data Mining and Knowledge Discovery (2018)
Abdulla, W.H., Chow, D., Sin, G.: Cross-words reference template for DTW based speech recognition systems. Conference on Convergent Technologies for Asia-Pacific Region (2003)
Aghabozorgi, S., Shirkhorshidi, A.S., Wah, T.Y.: Time-series clustering – a decade review. Inf. Syst. 53, 16–38 (2015)
Bagnall, A., Lines, J., Bostrom, A., Large, J., Keogh, E.: The great time series classification bake off: a review and experimental evaluation of recent algorithmic advances. Data Min. Knowl. Disc. 31(3), 606–660 (2017)
Bhattacharya, R., Patrangenaru, V.: Large sample theory of intrinsic and extrinsic sample means on manifolds. Ann. Stat. 31(1), 1–29 (2003)
Brill, M., Fluschnik, T., Froese, V., Jain, B., Niedermeier, R, Schultz, D.: Exact mean computation in dynamic time warping spaces. Data Mining and Knowledge Discovery (2019)
Bulteau, L., Froese, V., Niedermeier, R.: Hardness of Consensus Problems for Circular Strings and Time Series Averaging. arXiv:1804.02854(2018)
Cuturi, M., Blondel, M.: Soft-DTW: a differentiable loss function for time-series. International Conference on Machine Learning (2017)
Ding, H., Trajcevski, G., Scheuermann, P., Wang, X., Keogh, E.: Querying and mining of time series data: experimental comparison of representations and distance measures. Proc. VLDB Endowment 1(2), 1542–1552 (2008)
Dryden, I.L., Mardia, KV: Statistical shape analysis. Wiley, New York (1998)
Feragen, A., Lo, P., De Bruijne, M., Nielsen, M., Lauze, F.: Toward a theory of statistical tree-shape analysis. IEEE Trans. Pattern Anal. Mach. Intell. 35, 2008–2021 (2013)
Fletcher, P.T., Lu, C., Pizer, S.M., Joshi, S.: Principal geodesic analysis for the study of nonlinear statistics of shape. IEEE Trans. Med. Imaging 23(8), 995–1005 (2004)
Fréchet, M.: Les éléments aléatoires de nature quelconque dans un espace distancié. Annales de l’,institut Henri Poincaré 10, 215–310 (1948)
Ginestet, C.E.: Strong Consistency of Fré,chet Sample Mean Sets for Graph-Valued Random Variables. arXiv:1204.3183 (2012)
Hautamaki, V., Nykanen, P., Franti, P.: Time-series clustering by approximate prototypes. International Conference on Pattern Recognition (2008)
Jain, B.J.: Generalized gradient learning on time series. Mach. Learn. 100(2-3), 587–608 (2016)
Jain, B.J.: Statistical analysis of graphs. Pattern Recogn. 60, 802–812 (2016)
Jain, B.J., Schultz, D.: On the existence of a sample mean in dynamic time warping spaces. arXiv:1610.04460 (2016)
Jain, B.J., Schultz, D.: Asymmetric learning vector quantization for efficient nearest neighbor classification in dynamic time warping spaces. Pattern Recogn. 76, 349–366 (2018)
Jain, B.: Revisiting Inaccuracies of Time Series Averaging under Dynamic Time Warping. Pattern Recogn. Lett. 125, 418–424 (2019)
Kendall, D.G.: Shape manifolds, procrustean metrics, and complex projective spaces. Bull. Lond. Math. Soc. 16, 81–121 (1984)
Kohonen, T., Somervuo, P.: Self-organizing maps of symbol strings. Neurocomputing 21(1-3), 19–30 (1998)
Liu, Y., Zhang, Y., Zeng, M.: Adaptive Global Time Sequence Averaging Method Using Dynamic Time Warping. IEEE Trans. Signal Process. 67(8), 2129–2142 (2019)
Petitjean, F., Ketterlin, A., Gancarski, P.: A global averaging method for dynamic time warping, with applications to clustering. Pattern Recogn. 44(3), 678–693 (2011)
Petitjean, F., Forestier, G., Webb, G.I., Nicholson, A.E., Chen, Y., Keogh, E.: Faster and more accurate classification of time series by exploiting a novel dynamic time warping averaging algorithm. Knowl. Inf. Syst. 47(1), 1–26 (2016)
Rabiner, L.R., Wilpon, J.G.: Considerations in applying clustering techniques to speaker-independent word recognition. J. Acoust. Soc. Am. 66(3), 663–673 (1979)
Sakoe, H., Chiba, S.: Dynamic programming algorithm optimization for spoken word recognition. IEEE Trans. Acoust. Speech Signal Process. 26(1), 43–49 (1978)
Schultz, D., Jain, B.: Nonsmooth analysis and subgradient methods for averaging in dynamic time warping spaces. Pattern Recogn. 74, 340–358 (2018)
Soheily-Khah, S., Douzal-Chouakria, A., Gaussier, E.: Generalized k-means-based clustering for temporal data under weighted and kernel time warp. Pattern Recogn. Lett. 75, 63–69 (2016)
Somervuo, P., Kohonen, T.: Self-organizing maps and learning vector quantization for feature sequences. Neural. Process. Lett. 10(2), 151–159 (1999)
Sverdrup-Thygeson, H.: Strong law of large numbers for measures of central tendency and dispersion of random variables in compact metric spaces. Ann. Stat. 9(1), 141–145 (1981)
Tan, C.W., Webb, G.I., Petitjean, F.: Indexing and classifying gigabytes of time series under time warping. International Conference on Data Mining (2017)
Wilpon, J.G., Rabiner, L.R.: A Modified K-Means Clustering Algorithm for Use in Isolated Work Recognition
Ziezold, H.: On expected figures and a strong law of large numbers for random elements in quasi-metric spaces. Transactions of the Seventh Prague Conference on Information Theory, Statistical Decision Functions Random Processes and of the 1974 European Meeting of Statisticians. (1977)
Acknowledgements
B. Jain was funded by the DFG Sachbeihilfe JA 2109/4-2.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix
A Proof of Example 9
Proof
From the Reduction Theorem follows that it is sufficient to consider candidate solutions of length one and two. Thus, it is sufficient to consider the restricted Fréchet functions F1 and F2. In addition, it is sufficient to assume that all warping paths are compact (see Example 25). Then the set §Pm,n with m,n ∈ {1,2} consists of exactly one warping path. Suppose that x = (x1), y = (y1,y2) and z = (z1,z2). Then the squared DTW distances are of the form δ(x,z)2 = d(x1,z1) + d(x1,z2)δ(y,z)2 = d(y1,z1) + d(y2,z2).
We proceed with considering a slightly modified setting using the local distance function \(d^{\prime }(a, a^{\prime }) = (a-a^{\prime })^{2}\) for all \(a, a^{\prime } \in \mathcal {A}\). Under this setting, we denote the DTW distance by \(\delta ^{\prime }\) and the restricted Fréchet functions by \(F^{\prime }_{1}\) and \(F^{\prime }_{2}\). The function \(F^{\prime }_{1}(x)\) at time series x = (x1) is of the form
For a given x = (x1,x2), a similar calculation with
Next, we assume the original local distance function d on §A as defined in Example 9. Again, we first consider time series x = (x1) of length one. Then we have \(F_{1}(x) = F^{\prime }_{1}(x)\) if x1≠ 0 and F1(x) = 4 if x1 = 0. Thus, z = (0.5) is the restricted sample mean of \(\mathcal {X}\) on \(\mathcal {T}_{1}\) with Fréchet variation F1(z) = 3.
Now, we consider time series of length two. Let xε = (1,ε) for some \(\varepsilon \in \mathbb {R}\). Then
Rights and permissions
About this article

Cite this article
Jain, B., Schultz, D. Sufficient conditions for the existence of a sample mean of time series under dynamic time warping. Ann Math Artif Intell 88, 313–346 (2020). https://doi.org/10.1007/s10472-019-09682-2
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10472-019-09682-2